开篇词|从熟练到精通:开启你的Go语言进阶之旅
你好,我是 Tony Bai,一名在 Go 领域深耕多年的布道师。
也许你已经完成了我的 《Go语言第一课》,或者通过其他途径掌握了 Go 的基础语法和常用库。但你可能正面临这样的困惑:
-
感觉到了瓶颈? 写了不少 Go 代码,但总觉得离“精通”还差一口气,想写出更优雅、更高性能的代码却不知从何下手?
-
设计能力跟不上? 面对复杂的业务需求,如何进行合理的项目布局、包设计、接口设计?如何选择合适的并发模型?
-
工程实践经验不足? 知道要测试、要监控、要优化,但具体到 Go 项目,如何搭建可观测性体系?如何进行有效的故障排查和性能调优?如何保证代码质量和线上稳定?
-
……
如果你有这些疑问,那么这门“Go 语言进阶课”正是为你量身打造的。
现在是进阶 Go 的最佳时机吗?
如果你还在观望:Go语言还值得深入吗?前景如何?我的答案是:现在正是学习和进阶 Go 的最佳时机!
Go 正迎来它的黄金十年
如果你关注近些年的主流语言应用趋势,不难发现,从国外的Google、特斯拉,到国内的腾讯(连续两年内部最热门语言)、字节跳动(超55%服务用Go实现,并开源了Kitex、Hertz等框架),再到越来越多的中小和初创公司,都在生产环境大规模使用Go。为什么? Go 语言是生产力与执行效率的最佳结合,尤其在云原生、微服务、中间件领域优势明显,能实实在在的降本增效。
各大行业榜单也是稳中有进。无论是关注工程师需求的IEEE Spectrum,追踪社区热度的RedMonk,衡量开源项目量的GitHub Octoverse,还是搜索热度的TIOBE,Go语言都呈现出稳步上升甚至屡创新高的态势。特别是在TIOBE榜单上,Go 已稳定在第 7 名,并且 在 2025 年 4 月榜中,其份额首次超过 3%,达到 3.02%。
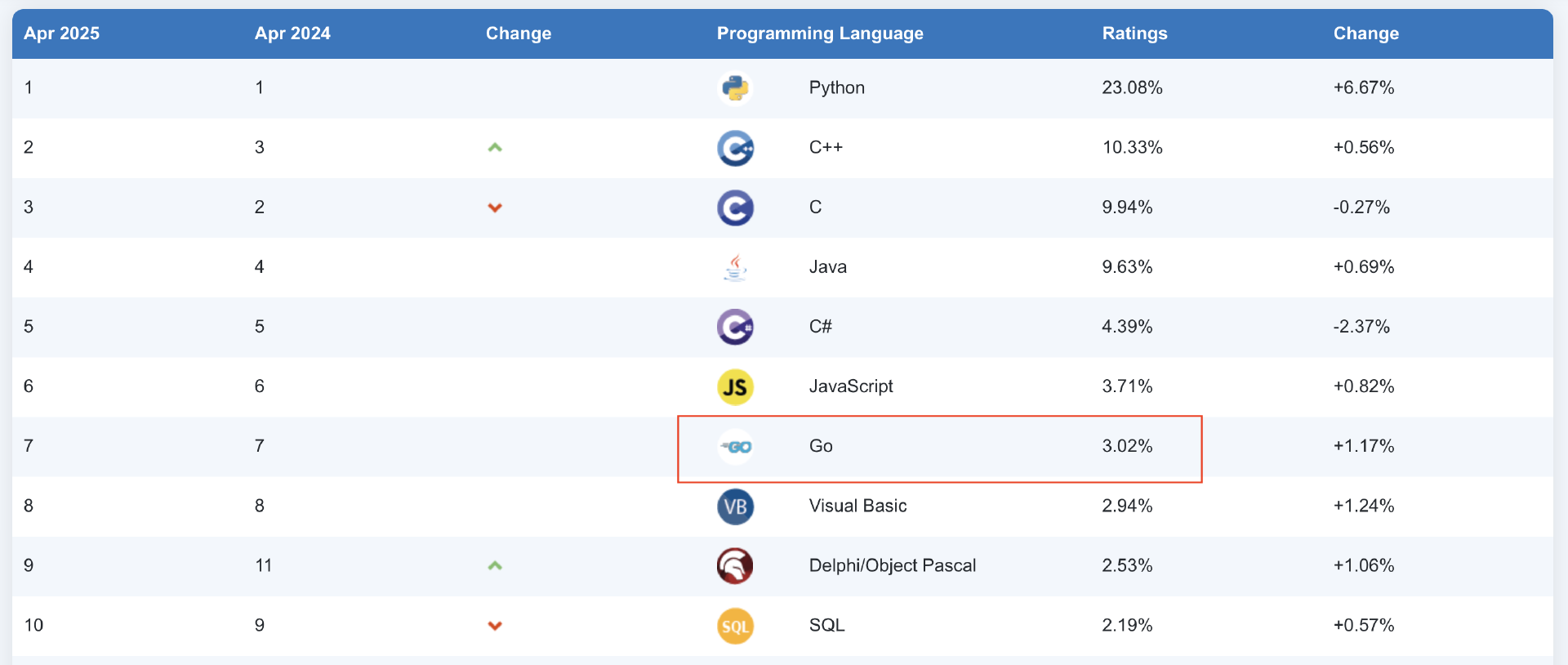
从全球开发者社区来看的话,热度不减。新冠疫情后,全球GopherCon大会和Meetup纷纷回归线下,国内GopherChina甚至一年两办,连非洲也迎来了首届GopherCon。 这背后是 Go 开发者生态的持续繁荣。
开发者基数扩大、优秀项目涌现是排名上升的基础。2025年伊始,我们看到 TypeScript 编译器项目向 Go 移植,各大主流大模型厂商纷纷推出官方Go SDK项目,Ollama成为本地运行大模型工具的事实标准,我们还看到 Grafana 基于 Go 构建 MCP Server( mcp-grafana),GitHub 更是 用 Go 重写了其 MCP Server(替换原有 JS 版本)……这些都展示了Go社区的活力以及Go在AI生态中的快速渗透和发展,也预示着 Go 在构建下一代 AI 应用(特别是与大模型交互相关的组件)方面将扮演越来越重要的角色。
结合技术成熟度曲线来看,Go语言已经走出了“泡沫破裂谷底期”,稳步迈入“光明期”。正如我在 《Go 语言第一课》 结束语中预测的,Go 正迎来它的黄金十年。
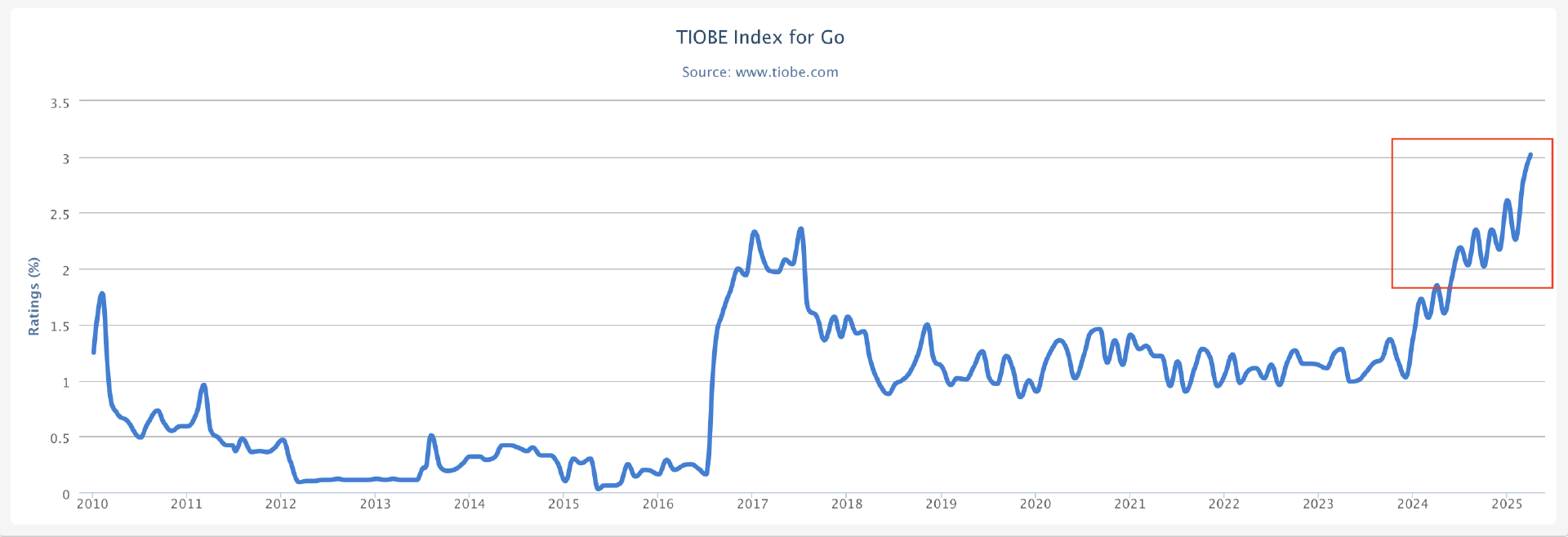
Go 持续进化,能力更强大
另外,Go语言并非一成不变,它在保持简洁和兼容性的同时,也在积极地吸纳社区反馈,不断进行自我完善和能力增强。近些年,Go语言迎来了许多重要的里程碑,为开发者提供了更现代、更高效的工具集。
-
泛型落地(Go 1.18): 这无疑是近年来最重大的语言特性更新,解决了无数 Gopher 的“心头痛”,极大地提升了代码的复用性和表达力,让编写类型安全的通用数据结构和函数成为可能。
-
兼容性承诺与演进策略(Go 1.x & math/rand/v2): Russ Cox 明确“不会有 Go 2”,并强调兼容性是 Go 最重要的特性,给开发者吃下了定心丸。同时,通过 math/rand/v2 包的发布,Go 团队也展示了如何在保持兼容性的前提下,对标准库进行版本化演进,为未来的改进铺平了道路。
-
性能优化持续发力(PGO & Runtime): Profile-Guided Optimization (PGO) 从 Go 1.20 的技术预览,到 Go 1.21 正式可用,并在 Go 1.22 中进一步增强了去虚拟化(devirtualization)的能力,Go 1.23 则显著降低了 PGO 的编译开销。这些改进能为典型 Go 应用带来 3-7% 甚至更高的性能提升。运行时的垃圾收集元数据优化也在持续进行,以降低 CPU 和内存开销。
-
语言层面精益求精(Loopvar Fix & Function Iterators): Go 团队勇于修正历史包袱。例如,长期困扰开发者的 for 循环变量共享问题在 Go 1.22 中得到了历史性的修正,每次迭代都会获得独立的变量实例。Go 1.23 则引入了对自定义函数迭代器的支持(range over func),让 for range 语句可以优雅地遍历用户自定义的集合类型,提升了语言的灵活性。
-
工程化与标准库能力显著增强:
-
标准库: 新增了如 log/slog 结构化日志包,采用泛型实现的 slices、maps、cmp 包,用于处理唯一值的 unique 包,以及支持函数迭代器的 iter 包等。net/http.ServeMux 的路由能力在 Go 1.22 中也得到了大幅增强,支持方法谓词、路径变量和通配符。
-
工具链: 推出了官方安全漏洞扫描工具 govulncheck,加强了软件供应链安全。Go 1.23 正式引入了官方遥测系统(Telemetry),用于收集匿名的使用数据以指导 Go 的未来发展。go work 对 vendor 的支持、go mod tidy -diff 等改进也提升了日常开发效率。godebug 指示符的引入使得在 go.mod 中管理实验性特性或行为调整更为便捷。
-
这些变化并非孤立的补丁,它们共同构成了 Go 语言持续进步的图景: 更强的表达力、更高的性能、更完善的工具链、更丰富的标准库以及对开发者痛点的积极响应。
正是因为 Go 语言这种务实、持续进化的态度,我们有理由相信,现在学习和掌握 Go 的进阶知识,将为你未来的技术生涯注入强大的动力。
大势所趋,Go 高级技能需求迫切
我们正处在一个 云原生、微服务、分布式系统 成为技术基础设施核心的时代。而Go语言,凭借其出色的并发性能、简洁的语法、高效的编译部署以及对网络编程的良好支持,已经成为构建这些现代系统的 首选语言之一。
这意味着什么?
应用场景深化: Go不再仅仅用于编写简单的API服务或工具。它被广泛应用于构建复杂的中间件(如服务网格、消息队列)、高性能网关、容器编排(Kubernetes生态)、可观测性系统(如Prometheus、VictoriaMetrics、VictoriaLogs等)、分布式数据库(如CockroachDB等)等核心基础设施。大型语言模型(LLM)应用的兴起带来了新的架构挑战。构建复杂的AI Agent、RAG(Retrieval-Augmented Generation)系统或多模型编排应用,往往需要一个强大的后端来处理业务逻辑、协调对不同模型/API/工具的调用、管理状态和并发。Go的并发模型和性能优势,使其成为构建这类复杂、高并发AI应用后端的有力竞争者。
对工程师能力要求提升: 要在这些关键领域构建稳定、高效、可扩展的系统,仅仅掌握Go的基础语法是远远不够的。企业迫切需要那些深刻理解 Go 并发模型、内存管理、性能调优、具备良好系统设计能力和工程实践经验的高级工程师。
职业价值凸显: 掌握Go的进阶知识和实践技能,意味着你能够胜任更具挑战性、更有价值的工作岗位,解决更复杂的工程问题。这直接关系到你的职业竞争力和发展空间。
总结来说,行业的技术发展方向与Go语言的优势高度契合,这催生了对真正掌握 Go 进阶技能人才的巨大需求。仅仅“会用” Go 已经不足以应对挑战,市场需要的是能够“精通”并能解决复杂问题的Go专家。
这门课能带给你什么?
作为一名在Go领域深耕多年的布道师和一线技术负责人(你可以在 tonybai.com 找到我的博客),目前,我带领团队使用Go语言构建的车云平台产品,已经成功服务于国内外多家知名车企的量产车型。
在将产品从0到1、再到服务生产环境的过程中,我们踩过坑,也积累了丰富的Go语言实战经验,尤其是在 系统设计、工程化实践和性能优化 方面。我深知Go开发者从“入门”到“熟练”,再到“精通”需要跨越哪些障碍。
过去几年,我将这些经验和思考在团队内部分享,并带到了GopherChina大会的“Go 高级工程师必修课”培训中,收到了非常积极的反馈。因此,我决定再推出一门进阶课,希望能系统性地帮助更多Gopher突破瓶颈。
提升能力的三个核心维度
那么这门课是如何设计的呢?
进阶课摒弃了简单罗列知识点的方式,聚焦于 Go 工程师能力提升的三个核心维度,为你精心设计了三大模块。
模块一:夯实基础,突破语法认知瓶颈
这里我们不满足于“知道”,而是追求“理解”。深入类型系统、值与指针、切片与map陷阱、接口与组合、context、泛型等核心概念的底层逻辑与设计哲学,让你写出更地道、更健壮的Go代码,彻底告别“语法坑”。
模块二:设计先行,奠定高质量代码基础
从宏观的项目布局、包设计,到具体的并发模型选择、接口设计原则,再到实用的错误处理策略和API设计规范。这一模块将提升你的软件设计能力,让你能驾驭更复杂的项目。
模块三:工程实践,锻造生产级Go服务
聚焦于将Go代码变成可靠线上服务的关键环节。如何构建应用骨架(初始化、依赖注入、优雅退出)?如何实现核心组件(配置、日志、插件化)?如何落地可观测性(Metrics、Logging、Tracing)?如何进行高效的故障排查、测试组织、性能调优、云原生部署以及与AI大模型集成?这里全是硬核干货。
此外,我们还安排了 实战串讲项目,带你将前面学到的知识融会贯通,亲手构建并完善一个真实的Go服务。
通过这门课程的学习,你不仅可以掌握Go的高级特性和用法,更能 建立起 Go 语言的设计思维和工程思维,真正具备驾驭大型Go项目、解决复杂工程问题的能力,完成从“Go 熟练工”到“Go 专家”的蜕变。
你准备好了吗?让我们一起,开启这段激动人心的Go语言进阶之旅!
类型系统:理解Go语言独特设计哲学的关键钥匙
你好,我是Tony Bai。
欢迎来到“Tony Bai·Go语言进阶课”的第一讲!
这门课不同于入门课程,我会假设你已经具备一定的 Go 语言基础。如果你是 Go 新手,我推荐你先学习我的《 Go语言第一课》专栏,那里是扎实基础的好起点。
今天,作为“语法强化篇”这个模块的开篇,我们要深入探讨 Go 语言的一个核心基石: 类型系统。
提到类型系统,你是不是也和我一样,有种“最熟悉的陌生人”的感觉?
熟悉,是因为我们每天都在和各种类型打交道,比如 int、string、struct、interface{}… 它们是我们构建程序的砖瓦。陌生,则是因为一旦加上 系统 二字,它就变得抽象起来。
很多人可能并不清楚,类型系统到底是什么,它在 Go 这门静态强类型语言中扮演着怎样至关重要的角色。
在Go的世界里,几乎每一行代码都离不开 类型。它是编译器检查我们代码的依据,是运行时保证程序安全的基础,更是我们理解 Go 诸多特性(比如接口、组合、泛型)的关键。
可以说, 对 Go 类型系统认知的高度,直接决定了你 Go 编程能力的深度。不深入理解它,你可能会在类型转换、接口使用、泛型约束等方面遇到各种“坑”。
那么,这节课,我们就来揭开Go类型系统的神秘面纱。我将带你一起探索:
-
编程语言中为什么需要类型这个抽象?
-
类型系统究竟是什么,它有哪些分类?
-
Go的类型系统有哪些独特的设计选择?它的规则和机制是怎样的?
准备好了吗?让我们先从最根本的问题开始:为什么要有类型?
类型的存在意义:编程语言为何需要它?
作为有经验的 Gopher,你肯定知道 Go 提供了丰富的内置类型(布尔、整型、浮点、复数、字符串、函数等),复合类型(数组、切片、map、struct、channel),代表行为抽象的接口类型,以及指针类型。我们还能通过 type 关键字自定义新类型或定义类型别名。
但你有没有想过:为什么编程语言需要类型?它究竟带来了什么好处?
回顾编程语言的发展史,我们会发现一个关键点: 类型是高级语言区别于机器语言和汇编语言的重要抽象。
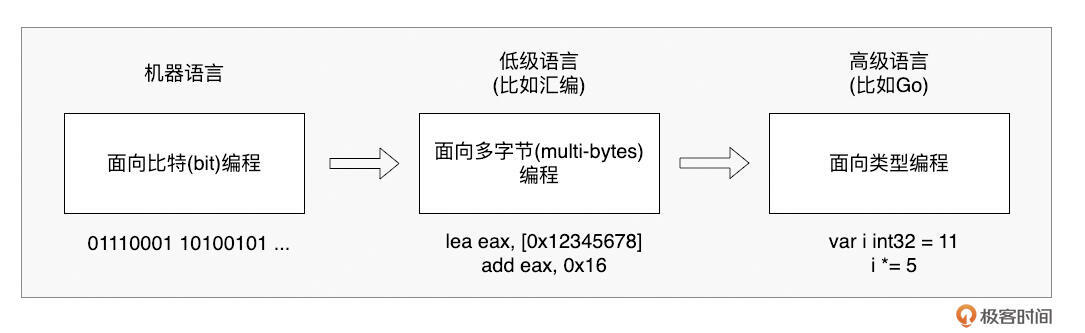
在机器眼中,一切数据都是 0 和 1。直接用机器码编程,复杂、低效且极易出错。汇编语言稍好一些,它操作的是固定长度的字节,比如 movb 操作 1 字节, movl 操作 4 字节,但它依然不关心这些字节代表的真正含义,只是在地址间搬运数据。
高级语言的“高级”之处,很大程度上就体现在类型这个抽象上。
类型,为开发者屏蔽了底层数据的复杂表示。 我们不再需要关心某个值在内存中具体是多少位、字节序如何,只需要跟类型打交道。类型告诉我们:
-
这个值能存储什么范围的数据(比如 int8 vs int64)?
-
能对它进行哪些操作(比如字符串拼接 vs 整数加法)?
-
它需要多少存储空间?
-
它如何与其他类型互动(转换、组合、实现接口等)?
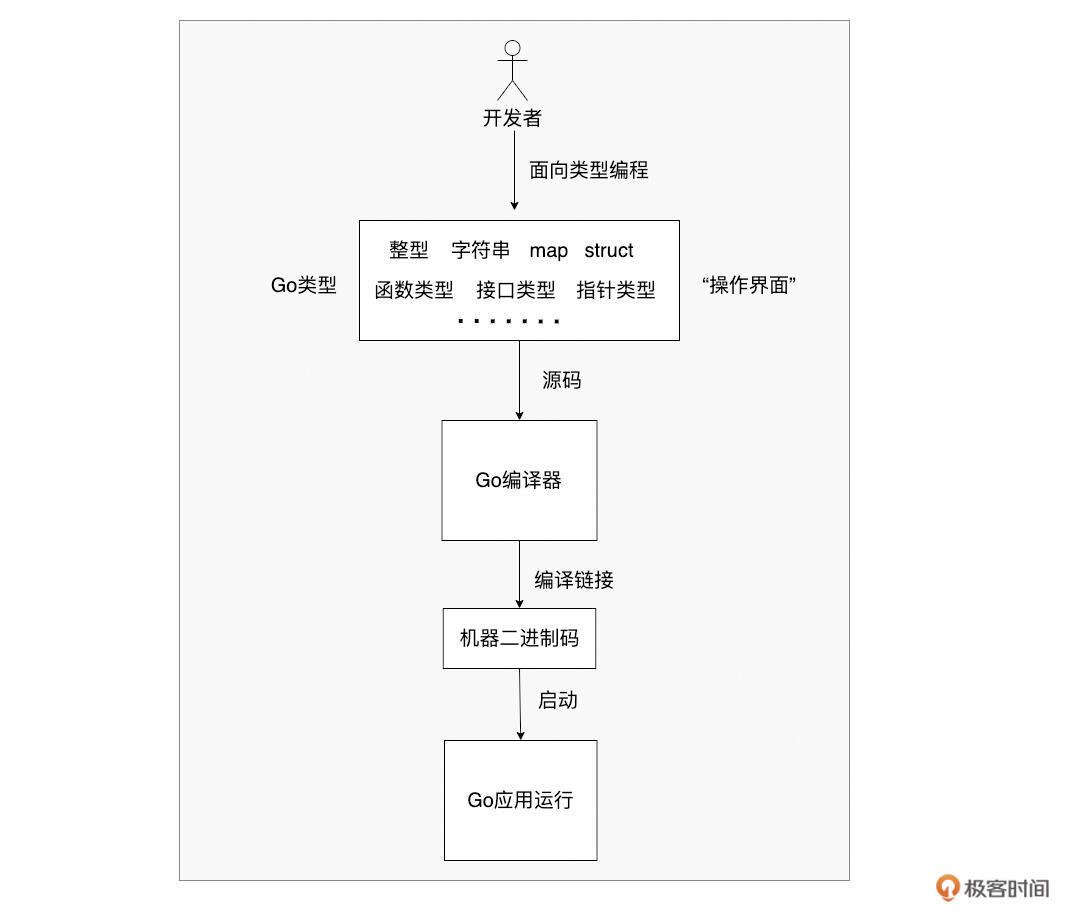
可以说, 类型成为了开发者与编译器之间高效沟通的“操作界面”。我们面向类型编程,遵循类型的规则,而类型之下的复杂比特和字节操作,则由编译器和运行时帮我们处理。
那么,是谁赋予了类型这些能力和规则呢?答案就是—— 类型系统。
类型系统概览:约束与表达力
类型系统,并不是一个看得见摸得着的实体,而是围绕类型建立的一整套规则和机制。它贯穿于语言规范、编译器和运行时,共同定义、管理和约束着类型的使用。
-
语言规范层面:定义类型的种类、层次、语法语义、使用约束等,给开发者提供明确指引。
-
编译器层面:执行类型检查,确保类型兼容性、转换有效性等,在编译期捕捉大量潜在错误。
-
运行时层面:支持多态(根据实际类型动态绑定方法)、动态类型检查(如类型断言)等。
简单来说, 类型系统通过赋能和管理类型,来保证程序的正确性、安全性和可靠性。
当然,不同语言的类型系统设计差异很大。主要的区别在于检查类型的时机和检查的严格程度。
- 按检查时机分:
-
静态类型系统:尽可能在 编译期间 进行类型检查。变量类型在编译时确定,能及早发现类型错误。代表:Go、C、C++、Java 以及 Rust 等。
-
动态类型系统:主要在 运行时 进行类型检查。变量类型可变,更灵活,但错误可能到运行时才暴露。代表:Python、JavaScript 以及 Ruby 等。
-
- 按检查严格程度分:
-
强类型系统:类型检查严格,不允许隐式或不合理的类型混合操作和转换。强调类型安全。代表:Go、Java、Rust、C++(相对于其他强类型语言,其类型检查严格程度略弱一些)、Python(注意 Python 是动态强类型)等。
-
弱类型系统:类型检查相对宽松,允许一定程度的隐式类型转换和混合操作。更便利,但可能隐藏类型风险。代表:C、JavaScript、PHP 等。
-
下面我们再用一张示意图,直观地展示这些主流编程语言的类型系统在“检查时机”和“检查严格程度”象限图中的位置。
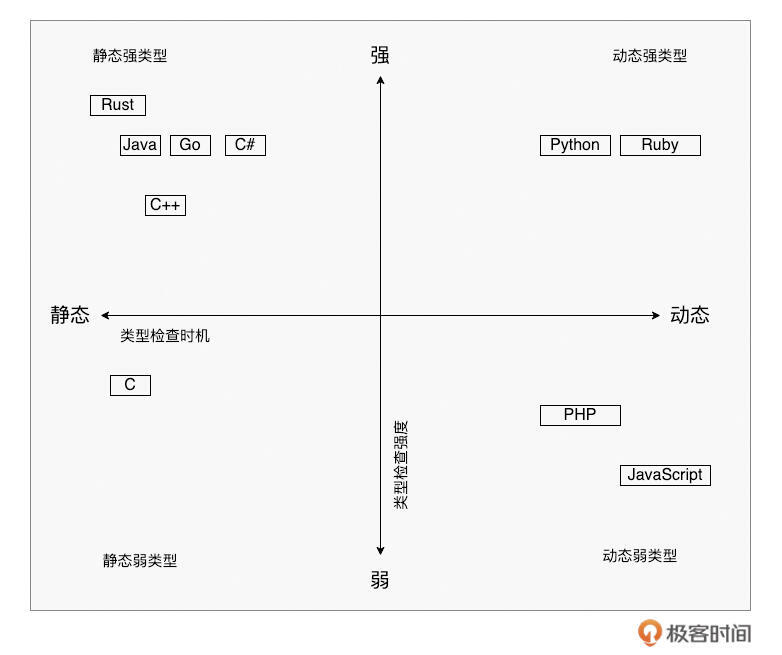
了解了这些分类,我们就清楚了 Go 的定位: Go 拥有一个静态强类型系统。这意味着它倾向于在编译阶段就发现尽可能多的类型错误,并且对类型的匹配和转换要求非常严格。
接下来,让我们聚焦 Go,看看它的类型系统具体有哪些独特的设计和规则。
Go语言类型系统的独特设计与选择
要理解 Go 的类型系统,关键在于弄懂它围绕类型建立的具体规则。我们从类型定义、类型推断、类型检查和类型连接这几个方面来看。
类型定义:内置与自定义
类型是开发者用来抽象现实世界的工具。Go 内置了丰富的类型,我们通过一张示意图来看一下 Go 类型系统中的类型:
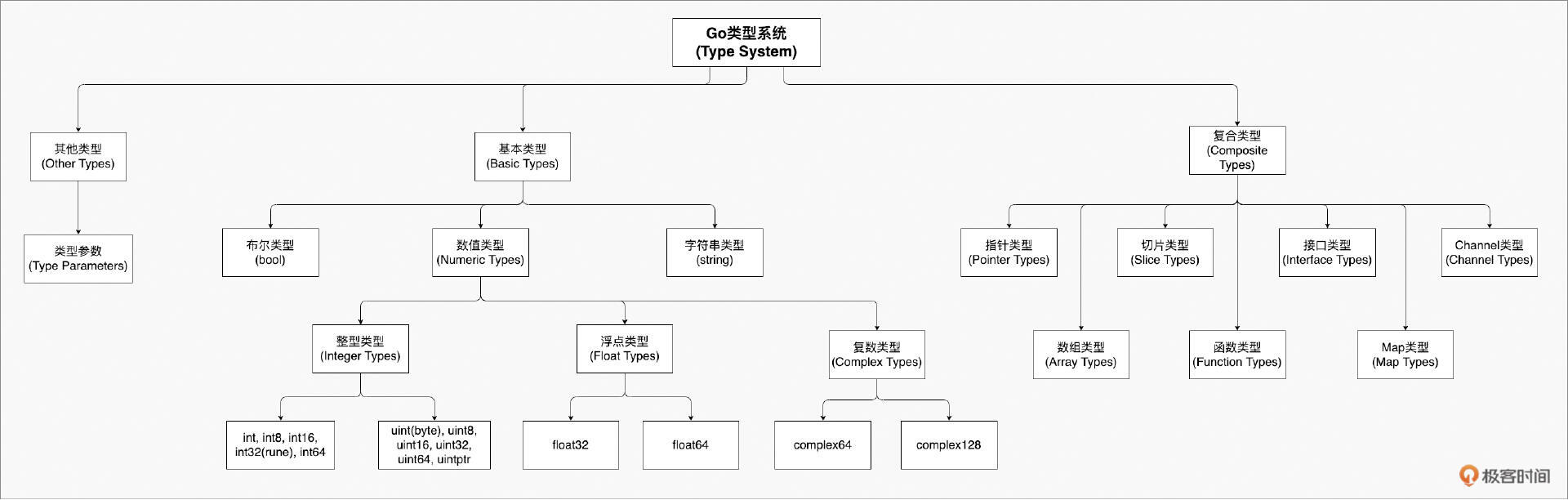
从图中我们看到,Go 语言的类型系统主要包含基本类型和复合类型。
其中,内置的基本类型包括布尔类型 bool(表示 true 和 false),以及多种数值类型:整数类型 int8、int16、int32、int64、uint8、uint16、uint32、uint64、int、uint、uintptr,浮点类型 float32、float64,以及复数类型 complex64、complex128。
byte 是 uint8 的别名,rune 是 int32 的别名。此外,还有字符串类型 string,表示不可变的字节序列。
复合类型则包括数组类型、切片类型、结构体类型、指针类型、函数类型、接口类型、Map 类型以及 Channel 类型。
除了这些,我们还可以使用 type 关键字来创造自己的类型:
// 定义一个新类型 T,其底层类型是 U
type T U
这里的 U 被称为 T 的底层类型(underlying type)。这是一个非常重要的概念! 类型系统会认为自定义类型 T 和它的底层类型 U 是两个完全不同的类型。这是编译期类型检查的基础规则之一。
type MyInt int // MyInt 是一个新类型,底层类型是 int
type S struct { // S 是一个新类型
a int
b string
}
Go 1.9 之后,还引入了 类型别名(type alias):
// 定义 P 作为 Q 的别名
type P = Q
注意,这里并 没有 创建新类型。 P 和 Q 在类型系统看来是完全等价并可以互换的。别名机制的引入主要是为了方便代码重构。
秉承“简单”的设计哲学,Go 类型系统并未内置支持其他语言中常见的几种类型。
第一种是 联合体类型(union)。在这种类型中,其所有字段共享同一个内存空间,比如下面 C 语言例子代码中 num 类型:
union num {
int m;
char ch;
double f;
};
union num a, b, c; // 声明三个union类型变量
这段 C 代码定义了一个名为 num 的联合体类型,其三个成员 m、ch 和 f 共享同一个内存空间,C 编译器会以最大的字段的 size 为 num 类型的变量分配内存空间。
另外一种Go语言不支持的是 枚举类型(enum)。Go 没有原生的 enum 关键字。但我们可以通过 常量(通常配合 iota)和 自定义类型 来模拟基础的枚举行为(值仅限布尔、数值或字符串)。
// C语法枚举
enum Weekday {
SUNDAY,
MONDAY,
TUESDAY,
WEDNESDAY,
THURSDAY,
FRIDAY,
SATURDAY
};
// Go模拟实现Weekday
type Weekday int
const (
Sunday Weekday = iota
Monday
Tuesday
Wednesday
Thursday
Friday
Saturday
)
对于像 Rust 语言实现的新式枚举类型(见下面例子),Go 类型系统目前是无能为力的。Rust 中的枚举可以包含关联的数据,每个枚举成员可以有不同的数据类型,并且可以使用 match 表达式对枚举进行模式匹配,处理每个可能的枚举成员和关联的数据。
// Rust的枚举示例
enum Shape {
Circle(f64), // 圆形,关联半径 (f64 类型)
Rectangle(f64, f64), // 矩形,关联宽度和高度 (两个 f64 类型)
Triangle(f64, f64, f64), // 三角形,关联三条边的长度 (三个 f64 类型)
}
fn main() {
let circle = Shape::Circle(3.14);
let rectangle = Shape::Rectangle(2.0, 4.0);
let triangle = Shape::Triangle(3.0, 4.0, 5.0);
// 使用 match 表达式匹配枚举成员并访问关联数据
match circle {
Shape::Circle(radius) => {
println!("Circle with radius: {}", radius);
},
_ => {}
}
match rectangle {
Shape::Rectangle(width, height) => {
println!("Rectangle with width: {} and height: {}", width, height);
},
_ => {}
}
match triangle {
Shape::Triangle(a, b, c) => {
println!("Triangle with sides: {}, {}, {}", a, b, c);
},
_ => {}
}
}
最后一种 Go 类型系统不支持的类型是 元组类型(tuple)。元组类型是一种用于组合多个值的数据结构。它是一个有序的集合,其中的每个元素可以具有不同的类型。元组允许将多个值绑定在一起,形成一个逻辑上相关的单元,可以作为单个实体进行传递、返回或操作。
元组的长度是固定的,一旦定义,就不能添加或删除元素。元素可以通过索引来访问,通常使用点号(.)或类似的语法来访问元组的成员。下面是 Rust 中关于元组使用的一个示例:
fn get_person_info() -> (String, u32, bool) { // 返回一个元组类型
let name = String::from("Alice");
let age = 30;
let is_employed = true;
(name, age, is_employed)
}
fn main() {
let person = get_person_info();
let name = person.0; // 通过索引来访问元组中的元素
let age = person.1;
let is_employed = person.2;
println!("Name: {}", name);
println!("Age: {}", age);
println!("Employed: {}", is_employed);
}
虽然没有内置支持元组类型,但在 Go 中我们可以通过以下方式来实现类似元组的功能。
我们可以定义一个结构体,其中的字段对应元组中的各个元素。每个字段可以具有不同的类型。例如:
type Tuple struct {
First int
Second string
Third bool
}
使用结构体可以方便地将多个值组合在一起,并通过访问结构体的字段来获取和操作元组的元素。
我们还可以使用数组或切片来模拟元组类型。可以定义一个固定长度的数组,其中的每个元素对应元组中的一个元素,类型为 interface{}。例如:
tuple := [3]interface{}{42, "Hello", true}
这里使用了一个 interface{} 类型的数组,其中的元素可以是任意类型。通过索引来访问数组的元素,就可以获取和操作元组中的元素。
需要注意的是,上面使用结构体、数组/切片方式仅是模拟元组,不同方式模拟得到的“元组”会丧失一些元组类型的特性,例如固定长度、类型安全或索引访问等。
Go 1.18 引入了 泛型,通过 类型参数(type parameter) 极大地增强了语言的表达力,也给类型系统带来了新的维度。我们可以定义泛型函数、泛型类型以及它们的约束。
// 定义一个泛型约束 (Go 1.21及以后可用cmp.Ordered的预定义约束)
type Ordered interface {
~int | ~int8 | ~int16 | ~int32 | ~int64 |
~uint | ~uint8 | ~uint16 | ~uint32 | ~uint64 |
~float32 | ~float64 |
~string
}
// 泛型函数
func Max[T Ordered](x, y T) T { /* ... */ }
// 泛型类型
type Stack[T any] struct { items []T }
// 泛型类型的方法
func (s *Stack[T]) Push(item T) { /* ... */ }
func (s *Stack[T]) Pop() (T, bool) { /* ... */ }
泛型无疑让 Go 更强大,但也增加了类型系统的复杂性。关于泛型的深入探讨,可以回顾 《 Go语言第一课》 专栏的泛型篇,或关注本专栏后续可能涉及的泛型实践内容。
类型推断:简洁之道
Go 从一开始就支持基本的类型推断(type inference),编译器能自动推导出变量或常量的类型,让我们少写很多代码:
var s = "hello" // 编译器推断 s 为 string 类型
a := 128 // 编译器推断 a 为 int 类型
const f = 4.3567 // 编译器推断 f 为 untyped float, 默认 float64
泛型引入后,类型推断能力进一步增强,编译器通常能自动推断出调用泛型函数或实例化泛型类型时所需的 类型实参(type argument):
import "slices"
nums := []int{3, 1, 4}
slices.Sort(nums) // 无需写 slices.Sort[[]int, int](nums)
strs := []string{"b", "a", "c"}
slices.Sort(strs) // 无需写 slices.Sort[[]string, string](strs)
无论是普通变量还是泛型参数的类型推断,都起到了 语法糖 的作用,减少了代码的冗余,提高了可读性。
类型检查:编译与运行时的守护
作为静态语言,Go 要求变量在使用前必须声明类型。编译器和运行时会进行 类型检查(type checking),确保我们对变量的操作是合法的,遵守类型系统的规则,从而保障 类型安全(type safety)。
Go 是强类型语言,严格限制 隐式类型转换(implicit type conversion)。绝大多数情况下,不同类型之间的转换必须通过 显式类型转换(explicit type conversion) 来完成,并且只有在 底层类型(underlying type) 兼容时才允许转换:
type T1 int
type T2 struct{}
type MyInt int // 新类型,底层是 int
var i int = 5
var t1 T1
var s T2
var mi MyInt
// t1 = i // 错误:类型不匹配 (T1 和 int 是不同类型)
t1 = T1(i) // 正确:显式转换,底层类型 (int) 兼容
// s = T2(t1) // 错误:底层类型不兼容 (struct{} 和 int)
// mi = i // 错误:类型不匹配 (MyInt 和 int 是不同类型)
mi = MyInt(i) // 正确:显式转换
// i = mi // 错误:类型不匹配
i = int(mi) // 正确:显式转换
但是,有一个重要的“例外”规则与赋值有关!
思考一下这个例子:
type MyInt int
type MyMap map[string]int
var x MyInt
var y int
// x = y // 报错: cannot use y (type int) as type MyInt in assignment
x = MyInt(y) // ok
var m1 MyMap
var m2 map[string]int
m1 = m2 // 不报错!
m2 = m1 // 也不报错!
为什么 MyInt 和 int 之间赋值需要显式转换,而 MyMap 和 map[string]int 之间可以直接赋值?
关键在于具定义类型(defined type)这个概念(在引入类型别名前也叫named type)。
Go语言规范规定:如果变量 x 的类型 V 与类型 T 具有相同的底层类型,并且 V 和 T 中至少有一个不是 defined type,那么 x 就可以直接赋值给类型为 T 的变量。
那么,哪些是 defined type?Go 语言规范给出的定义如下:
-
所有通过
type NewType BaseType定义的新类型都是 defined type (如MyInt,MyMap)。 -
Go 内置类型中,所有数值类型(int, float64 等)、string 类型、bool 类型都是defined type。
注意:map、slice、array、channel、func 这些复合类型本身不是 defined type!
现在再来看看上面的例子:
-
MyInt是 defined type,int也是 defined type。两者底层类型相同,但都不是“非defined type”,所以赋值需要显式转换。 -
MyMap是 defined type,但它的底层类型map[string]int不是 defined type。满足了“至少有一个不是 defined type”的条件,因此它们之间可以直接赋值。
理解 defined type 和赋值规则对于深入掌握Go类型系统至关重要。
除了编译期的静态检查,Go 类型系统还提供了运行时的动态类型检查:
-
接口类型检查:运行时检查存入接口变量的实际值是否真的实现了该接口的所有方法。
-
数组/切片下标检查:运行时检查访问的索引是否越界,越界则
panic。 -
类型断言(type assertion):在运行时检查接口变量底层存储的具体类型,并可以获取该类型的值。
var x interface{} = 42
// 安全的类型断言
if i, ok := x.(int); ok {
fmt.Printf("x is an int with value %d\n", i)
} else {
fmt.Println("x is not an int")
}
// 非安全的类型断言 (如果 x 不是 int 会 panic)
// j := x.(int)
当然,Go也提供了打破类型系统约束的“后门”—— unsafe.Pointer 和 反射(reflection)。
unsafe.Pointer 允许你在不同类型的指针间进行转换,直接操作内存,完全绕过类型检查。
标准库 math.Float64frombits 就是一个例子:
// $GOROOT/src/math/unsafe.go
func Float64frombits(b uint64) float64 {
// 将 uint64 的内存解释为 float64
return *(*float64)(unsafe.Pointer(&b))
}
反射允许在运行时检查类型信息、获取和设置值、调用方法等,也能在一定程度上绕过编译期类型检查。
import "reflect"
type MyStruct struct{ Field int }
func main() {
s := MyStruct{Field: 10}
v := reflect.ValueOf(&s).Elem() // 获取可设置的 Value
f := v.FieldByName("Field")
if f.CanSet() {
f.SetInt(20) // 通过反射修改了MyStruct的字段值
}
fmt.Println(s) // Output: {20}
}
警告: 使用 unsafe 和反射是非常危险的,它们破坏了Go的类型安全保证,可能导致程序崩溃或难以预料的行为。除非你完全清楚自己在做什么,并且没有其他更安全的方法,否则, 强烈建议避免使用。
类型连接:组合优于继承
Go 并非经典的面向对象语言。它没有类(class),没有继承(inheritance)层级,也没有构造函数。
在 Go 的类型系统中,类型之间建立连接的主要方式是 组合(composition),通常通过 类型嵌入(type embedding) 实现。我们可以将一个类型(接口或非接口)嵌入到另一个类型(通常是struct)中,从而“借用”或“聚合”其字段和方法。
下面示例中 Server 直接使用了其嵌入的类型 *Logger 的 Log 方法:
type Logger struct { Verbose bool }
func (l *Logger) Log(msg string) { fmt.Println(msg) }
type Server struct {
*Logger // 嵌入 Logger 类型 (指针形式)
Addr string
}
func main() {
s := Server{
Logger: &Logger{Verbose: true},
Addr: ":8080",
}
s.Log("Server starting...") //可以直接调用嵌入类型的 Log 方法
fmt.Println(s.Verbose) // 也可以直接访问嵌入类型的字段
}
Go 的多态性主要通过接口(interface)实现。接口定义了一组行为(方法签名),任何类型只要实现了接口要求的所有方法,就被视为 隐式地(implicitly) 实现了该接口,无需像 Java 或 C# 那样显式声明 implements。
type Speaker interface {
Speak() string
}
type Cat struct{}
func (c Cat) Speak() string { return "Meow" }
type Human struct{}
func (h Human) Speak() string { return "Hello" }
func MakeSpeak(s Speaker) {
fmt.Println(s.Speak())
}
func main() {
var c Speaker = Cat{} // Cat 实现了 Speaker 接口
var h Speaker = Human{} // Human 也实现了
MakeSpeak(c) // Output: Meow
MakeSpeak(h) // Output: Hello
}
这种隐式实现让 Go 的接口非常灵活和解耦。
此外,Go 中的 函数是一等公民,可以赋值给变量、作为参数传递、作为返回值。这使得函数类型本身也展现出一种形式的多态性:一个函数类型的变量可以在运行时指向不同的函数实现,从而表现出不同的行为。
type FilterFunc func(string) bool
func IsLong(s string) bool { return len(s) > 5 }
func HasPrefixA(s string) bool { return strings.HasPrefix(s, "A") }
func FilterStrings(strs []string, filter FilterFunc) []string {
var result []string
for _, s := range strs {
if filter(s) {
result = append(result, s)
}
}
return result
}
func main() {
words := []string{"Apple", "Banana", "Ant", "Orange", "Apricot"}
longWords := FilterStrings(words, IsLong)
fmt.Println(longWords) // Output: [Banana Orange Apricot]
aWords := FilterStrings(words, HasPrefixA)
fmt.Println(aWords) // Output: [Apple Ant Apricot]
}
小结
好了,关于 Go 类型系统的第一课就到这里。我们来快速回顾一下核心要点。
-
类型是关键抽象:它屏蔽了底层细节,是开发者与编译器沟通的界面,提高了编程效率和代码可读性。
-
类型系统是规则集:围绕类型建立,贯穿编译和运行时,保证类型安全。Go 拥有静态、强类型系统,强调编译期检查和严格性。
-
Go 类型定义:内置丰富类型,支持 type 定义新类型(产生不同类型,关注底层类型)和 type alias 定义别名(类型等价)。不支持 union、enum、tuple,但可模拟。Go 1.18 加入 泛型 增强了表达力。
-
Go 类型推断:编译器能自动推断变量、常量及泛型参数类型,简化代码。
-
Go 类型检查:编译期严格检查,限制隐式转换,需 显式转换。运行时检查接口实现、数组/切片越界、类型断言。理解 defined type 对掌握赋值规则很重要。unsafe 和反射可绕过检查,但需极度谨慎。
-
Go 类型连接:摒弃继承,采用组合(通过类型嵌入)和接口(隐式实现)来构建类型关系和实现多态。函数作为一等公民也提供了一种多态形式。
总的来说,Go 的类型系统设计简洁、一致,以 可读性 和 类型安全 为优先考量。虽然有时需要开发者编写更明确的代码(如显式转换),但这有助于构建更健壮、更易于维护的系统。
对于想要在Go编程道路上进阶的你来说,花时间深入理解 Go 类型系统的设计哲学和具体规则,是非常有价值的。它将为你后续学习 Go 的并发、接口设计、错误处理、泛型应用等打下坚实的基础。
如果小伙伴对编程语言的类型系统理论感兴趣,这里推荐阅读一下《 编程与类型系统》这本书。
思考题
Go 语言选择了静态强类型系统。相比之下,像 Python 这样的动态类型语言将许多类型检查推迟到运行时。请你思考一下:
-
Go 采用静态强类型系统,主要的优点是什么?它给开发者带来了哪些好处?
-
同时,这种选择可能带来哪些挑战或不便之处(相比动态类型语言)?
欢迎在留言区分享你的思考和见解!也欢迎你把这节课分享给更多对 Go 类型系统感兴趣的朋友。我是Tony Bai,我们下节课见!
Go兼容性:你的代码能在未来版本运行吗?
你好,我是 Tony Bai。
上一讲,我们深入了 Go 语言类型系统的设计哲学。一个好的类型系统是构建可靠软件的基石,但要让我们的 Go 程序经受住时间的考验,光有类型安全还不够。
Go 语言本身也在不断进化,新版本、新特性层出不穷。这就引出了一个对所有工程师都至关重要的问题: 我的 Go 代码,在未来的 Go 版本中还能跑吗?反过来,我用了新特性的代码,能在旧环境编译运行吗?
这背后,就是兼容性(Compatibility)的问题。对任何一门被广泛应用的语言来说,兼容性都是生命线。你肯定不希望每次 Go 升级,都意味着大量的代码修改和潜在的生产事故。
幸运的是,Go 从诞生之初就极其重视兼容性。著名的 Go 1 兼容性承诺 像定海神针一样,保证了语言和标准库核心 API 的稳定性,这是 Go 能在工业界快速普及的关键因素之一。
但 Go 的兼容性策略不止于此。它还创造性地引入了 向前兼容 的概念,并通过 GODEBUG 和 GOEXPERIMENT 这两个环境变量提供了更精细的控制手段。这种“ 向后保稳定 + 向前可管理 + 实验有控制”的组合拳,让 Go 得以在稳健发展的同时,又能拥抱变化,持续创新。
那么这节课,我们就来彻底搞懂 Go 的兼容性大法。我将带你:
- 深入理解 Go 1 向后兼容性承诺的具体内容和适用范围。
- 弄清楚 Go 向前兼容性是什么,以及 Go 1.21 后引入的新机制(如 go 指令语义变化、toolchain 指令、GOTOOLCHAIN 环境变量)如何工作。
- 掌握如何使用 GODEBUG 和 GOEXPERIMENT 来微调运行时行为和尝鲜实验性特性。
- 最后,我会在小结里给你一些编写高兼容性 Go 代码的实用建议。
理解 Go 的兼容性策略,不仅能让你更有信心地管理项目的 Go 版本依赖,还能让你更深刻地理解 Go 团队的演进哲学。让我们开始吧!
向后兼容性保证
Go 1 兼容性承诺是什么?
在 Go 1.0 发布前,Go 语言处于快速迭代期,语言规范和标准库 API 频繁变动,给早期使用者带来了不小的痛苦。为了改变这一局面,Go 团队在发布 1.0 版本时,郑重地做出了 Go 1 兼容性承诺。
这份承诺的核心内容,记录在官方文档 Go 1 and the Future of Go Programs 中(这里直接将摘录的核心片段译为了中文):
按照 Go 1 规范编写的程序将在该规范的整个生命周期内继续正确编译和运行,无需更改。在某个不确定的时间点,可能会出现 Go2 规范,但在此之前,即使出现 Go 1 的未来“点”版本(Go 1.1、Go 1.2 等),今天可以运行的 Go 程序也应该可以继续运行。
这个承诺意味着什么?意味着 稳定!开发者可以放心地使用 Go 1.x 版本进行开发,不必担心下一个小版本升级(比如从 1.18 到 1.19)会导致现有代码无法编译或运行。这极大地降低了采用和维护 Go 项目的成本,是 Go 能够在生产环境中被广泛应用的关键基石。
那么,这个承诺具体涵盖哪些内容呢?它的边界又在哪里呢?
Go 1 兼容性规则的适用范围
首先要明确这个承诺是 源代码层面 的,不保证不同 Go 版本编译出的二进制包(如 .a 文件)互相兼容。
其次,承诺并非覆盖所有方面,主要针对以下两个核心领域。
- 语言规范(Language Specification)
Go 保证 Go 1.x 系列中的 语法和语义 是稳定的。只要你的代码符合某个 Go 1.x 版本的规范,它就应该能在所有后续的 Go 1.x 版本中正确编译和运行。这个保证主要由 Go 团队维护的官方编译器 gc(以及 gccgo)来兑现。
自 Go 1 发布以来,语言规范确实只做了微小的、向后兼容的调整。例如,Go 1.9 引入 类型别名(type alias),Go 1.18 引入 泛型(generics),这些都是对语言的扩展,并没有破坏现有代码的兼容性。
- 标准库(Standard Library)
Go 保证标准库中公开 API(exported API)的行为是稳定的。如果你只使用了标准库公开的函数、类型、变量、常量,那么在后续 Go 1.x 版本中,它们的行为应该保持一致。
例如,Go 1.16 虽然将 io/ioutil 包标记为废弃,并将其功能迁移到 io 和 os 包,但 io/ioutil 包依然存在且可用,只是不推荐继续使用。需要注意: Go1 兼容性承诺不适用于标准库的内部实现。 Go 团队可以自由修改内部实现细节,只要不影响公开 API 的行为。
当然,凡事皆有例外。Go 1 兼容性承诺也并非绝对的“铁板一块”。在极其特殊的情况下,为了修复严重问题,Go 团队可能会做出不兼容的更改。官方文档列举了一些可能导致不兼容的情况。
- 安全问题:修复严重安全漏洞可能需要破坏兼容性。
- 规范错误:修正语言规范中的明显错误或不一致。
- 编译器/库 Bug:修复违反了规范的实现 Bug。
- 依赖未定义行为:代码如果依赖了规范中未明确定义的行为,后续版本行为可能改变。
- 结构体字面值(省略字段名):如果标准库结构体新增了导出字段,使用
pkg.T{val1, val2}形式的代码会编译失败。推荐使用带字段名的字面值pkg.T{FieldA: val1, FieldB: val2},Go 团队保证这种方式的兼容性。 - 向非接口类型添加方法:在某些嵌入场景下,新增的方法可能与现有方法冲突,导致编译失败。这种情况无法完全避免。
- 点导入(import . “path”):标准库后续新增的导出标识符可能与你的代码冲突。 不建议在非测试代码中使用点导入。
- 使用 unsafe 包:依赖 unsafe 包的代码可能依赖了 Go 的内部实现细节,这些细节不受兼容性保护,升级后可能失效。
一个近期的例子是 Go 1.22 对 for 循环变量语义的修改。Go 1.22 之前,循环变量在整个循环中只有一个实例,Go 1.22 改为每次迭代创建一个新实例。这确实改变了某些依赖旧行为的代码的语义。但 Go 团队认为旧行为是语言规范的“遗留错误”,其修正在兼容性承诺允许的范围内。我们后续课程会详细讨论这个变化。
尽管存在这些例外,Go 团队始终极其谨慎地对待不兼容变更。在绝大多数情况下,你的 Go 1.x 代码都能在不同版本间平滑迁移。
理解了 Go 的向后兼容性,我们再来看看另一个重要维度: 向前兼容性。
Go如何处理向前兼容性?
为什么需要向前兼容性?
向后兼容保证了旧代码能在新环境运行,但解决不了新代码在旧环境运行的问题。
在 Go 1.21 之前,go.mod 文件中的 go 指令(比如 go 1.20)更多的是一个 建议,而非强制约束。你可以用 Go 1.19 甚至 Go 1.15 的工具链去尝试编译一个声明了 go 1.20 的模块。
这会带来什么问题?
- 如果代码恰好没用到 Go 1.20 的新特性,编译可能成功,但隐藏了潜在风险。
- 如果代码用到了新特性,低版本编译器可能会报出一些莫名其妙、难以理解的错误。
- 更糟的是,有时编译“侥幸”通过(比如依赖库的某个内部实现变化),但运行时行为却与预期不符。
这种不确定性很麻烦,尤其是在管理复杂的依赖关系时。你可能自己很小心,但无法保证你依赖的所有库都没有偷偷使用更高版本的特性。
为了解决这个问题,Go 1.21 版本对向前兼容性机制进行了重大改进,让 Go 版本要求更加明确和可靠。
Go 的向前兼容性机制 (Go 1.21+)
Go 1.21及以后版本,通过以下几个关键机制增强了向前兼容性,我们来逐一看一下。
1. go.mod 中 go 指令的语义强化
在 Go 1.21 之前,go.mod 文件中的 go 指令只用于提示开发者该项目的最低 Go 版本要求,但 go 指令并不影响 Go 工具链的选择,无论 go.mod 文件中指定的版本是什么,Go 都会使用当前安装的 Go 版本的工具链来构建。
从 Go 1.21 开始, go.mod 文件中的 go 指令,比如 go 1.21.0,不再仅仅是提示, 而是明确表示编译该模块所需的最低 Go 版本。
这意味着,如果你用 Go 1.21.0 的工具链去编译一个声明了 go 1.21.1 的模块, go 命令会直接拒绝编译,并提示版本过低。这从根本上避免了旧工具链尝试编译新代码时可能出现的各种混乱。
2. 内置工具链管理
强制执行最低版本要求,会不会导致开发者需要频繁手动升级 Go?为了解决这个问题,Go 1.21 引入了 内置的工具链管理 功能(类似于 Node.js 的 nvm 或 Rust 的 rustup),支持在本地“安装”多个版本的 Go 工具链,并根据 go.mod 中的要求使用对应版本的 Go 工具链。
具体来说,当 go 命令(如 go build)发现当前使用的 Go 版本低于 go.mod 中要求的最低版本时,它会 自动下载 所需的、符合要求的 Go 工具链版本,并使用新下载的工具链来执行命令。
例如,你当前环境是 Go 1.21.0,但项目 go.mod 写着 go 1.21.3。运行 go build 时,go工具链会执行如下动作:
- Go 1.21.0 发现版本不够。
- 自动下载 Go 1.21.3 工具链(如果本地缓存没有)。
- 使用下载的 Go 1.21.3 工具链重新执行
go build。
注意:自动下载的工具链通常存储在你的 module cache 目录中(GOMODCACHE),并不会替换你系统全局安装的 Go 版本。
3. 新增 toolchain 指令
除了 go 指令, go.mod 中还可以添加一个 toolchain 指令,用来指定一个 建议使用的工具链版本。这在你希望团队成员使用某个特定版本(可能高于最低要求版本)进行开发时很有用。
module example.com/mymodule
go 1.18 // 最低要求 Go 1.18
toolchain go1.21.4 // 建议使用 Go 1.21.4 或更高版本开发
- toolchain 指令主要影响开发环境,对依赖该模块的其他模块没有影响。
- 通常,toolchain 版本会高于或等于 go 版本。
- 如果未显式设置 toolchain,它会隐式地等于 go 指令指定的版本。
toolchain default表示使用默认行为(基于 go 指令)。
4. 新增 GOTOOLCHAIN 环境变量
为了更精细地控制工具链的选择行为,Go 1.21 还引入了 GOTOOLCHAIN 环境变量。它有多种设置,常用的包括:
- GOTOOLCHAIN=local 强制使用本地安装的 Go 工具链(即你当前运行的 go 命令对应的版本),即使它低于
go.mod的要求。如果版本不满足,则报错。适用于需要严格控制构建环境或离线工作的情况。 - GOTOOLCHAIN=go1.X.Y (例如
GOTOOLCHAIN=go1.21.0)强制使用特定版本的 Go 工具链。go 命令会先在 PATH 环境变量中查找版本为go1.21.0的可执行文件,如果找不到,会尝试下载并使用。适用于需要固定构建版本以保证可重复性的场景。 - GOTOOLCHAIN=auto (或 local+auto,这是默认值)最智能的模式。go 命令会根据
go.mod中的 toolchain 指令(优先)或 go 指令来决定是否需要切换到更新的工具链。切换时,优先使用本地已有的(在 PATH 中找到的),找不到再尝试自动下载。 - GOTOOLCHAIN=go1.X.Y+auto(例如
GOTOOLCHAIN=go1.21.1+auto)类似 auto,但指定了一个默认的基础工具链go1.X.Y。如果这个基础版本不够,再按 auto 的规则尝试升级。 - GOTOOLCHAIN=go1.X.Y+path(或 local+path)类似
go1.X.Y+auto,但禁用自动下载。如果默认或本地路径中找不到满足要求的工具链,则报错。
根据上述 Go 向前兼容性的各种新增和变更的机制,我们来总结一下 Go 工具链的选择过程,以 GOTOOLCHAIN=auto 为例。
-
初始工具链:
go命令开始执行时,会有一个初始的工具链(通常是你安装的 Go 版本)。 -
读取
go.mod:go命令读取go.mod文件,获取go指令和toolchain指令(如果有)。 -
比较版本
a. 如果
toolchain指令存在,且指定的工具链版本比初始工具链新,则进入下一步。b. 如果
toolchain指令不存在(或为default),但go指令指定的版本比初始工具链新,则进入下一步。c. 否则,使用初始工具链,结束选择过程。
-
寻找工具链
a. 根据
toolchain或go指令,确定需要使用的工具链版本(例如go1.23.1)。b. 在
PATH环境变量中查找该版本的工具链(例如查找版本为go1.23.1的可执行文件)。c. 如果找到,使用找到的工具链,结束选择过程。
d. 如果未找到,进入下一步。
-
下载工具链(仅在
auto模式下):a. 从官方网站下载所需版本的工具链。
b. 将下载的工具链存储在 module cache 中。
c. 使用下载的工具链,结束选择过程。
不得不说,上面的 Go 工具链选择过程还是蛮复杂的,不过幸运的是,从 Go 1.24 版本开始,你可以通过 GODEBUG=toolchaintrace=1 来跟踪 go 命令的工具链选择过程,比如:
$GODEBUG=toolchaintrace=1 go build
go: upgrading toolchain to go1.24.1 (required by toolchain line in go.mod; upgrade allowed by GOTOOLCHAIN=auto)
go: downloading go1.24.1 (darwin/amd64)
... ...
通过这些机制的结合,Go 1.21+ 在向前兼容性上实现了巨大飞跃,让开发者能更清晰、更可靠地管理 Go 版本依赖。
基于GODEBUG和GOEXPERIMENT的可控实验
除了宏观的兼容性策略,Go 还提供了两个环境变量,让我们能在更细粒度上控制 Go 的行为,特别是在处理新旧特性切换或尝试实验功能时。
GODEBUG:运行时行为的微调
GODEBUG 用于在运行时控制 Go 程序的行为。它像一个临时的开关面板,让你可以在不修改代码、不重新编译的情况下,调整某些内部机制,主要用于:
-
调试与诊断:开启或关闭特定的运行时跟踪信息,如垃圾回收(
gctrace=1)、调度器(schedtrace=1000)等。 -
兼容性控制:临时启用某个旧版本的行为,以帮助诊断因版本升级引起的问题。例如,Go 1.21 改变了
panic(nil)的行为,如果需要恢复旧行为来排查问题,可以设置GODEBUG=panicnil=1。
设置方式为逗号分隔的键值对:
GODEBUG=name1=value1,name2=value2,... ./your_program
每个 Go 版本支持的 GODEBUG 选项都不同,具体请查阅官方文档 GODEBUG history。
GOEXPERIMENT:实验性特性的尝鲜
与 GODEBUG 控制运行时不同,GOEXPERIMENT 用于在编译时告诉 Go 编译器启用 哪些实验性特性(experimental features)。这些特性是 Go 团队正在探索的新功能或优化,尚未正式发布,通过 GOEXPERIMENT 开放给社区进行测试和反馈。
设置方式为逗号分隔的特性名称,用在 go build、 go run 等编译命令之前:
GOEXPERIMENT=name1,name2,... go build
例如,Go 1.23 引入了一个实验性特性,允许类型别名带有类型参数。要启用它,可以这样编译:
GOEXPERIMENT=aliastypeparams go build
重要提示: GOEXPERIMENT 启用的特性是不稳定的,它们可能在未来版本中发生重大变化,甚至被完全移除(比如曾经在 Go 1.20 中引入的arena包实验)。因此,不建议在生产环境中使用依赖 GOEXPERIMENT 的特性。它仅适用于本地实验和向 Go 团队提供反馈。
小结
这一讲我们深入了解了 Go 语言精心设计的兼容性策略,它远不止简单的“向后兼容”。现在我们来总结一下关键点,并列举几条关于编写高兼容性代码的建议。
-
Go 1 向后兼容性承诺:这是 Go 稳定性的基石。保证了符合 Go 1 规范的代码能在后续 Go 1.x 版本中无需修改即可编译运行(主要针对语言规范和标准库公开 API)。理解其适用范围和少数例外情况很重要。
-
Go 向前兼容性机制(Go 1.21+):解决了新代码在旧环境运行的问题。核心机制包括:
a. go.mod 中 go 指令语义强化(最低版本要求)。
b. 内置工具链管理(自动下载)。
c. 可选的 toolchain 指令(建议开发版本)。
d. 灵活的 GOTOOLCHAIN 环境变量(控制工具链选择行为)。
-
可控实验机制
a. GODEBUG:运行时开关,用于调试、诊断和临时兼容性调整。
b. GOEXPERIMENT:编译时开关,用于尝鲜不稳定的实验性特性,不应用于生产。
-
编写高兼容性代码建议
a. 遵循规范:严格按照 Go 1 规范编码,避免依赖未定义行为和 unsafe。
b. 明确版本:合理设置
go.mod中的 go 指令。c. 拥抱默认:通常使用默认的 GOTOOLCHAIN=auto。
d. 谨慎实验:仅在必要时使用 GODEBUG,避免在生产中使用 GOEXPERIMENT。
e. 善用工具:使用
go vet等工具检查潜在问题。f. 阅读文档:关注每个 Go 版本的 Release Notes,了解兼容性相关的变更。
Go 团队在兼容性上付出的巨大努力,为我们开发者创造了一个既稳定又持续进化的生态。理解并善用这些兼容性策略和工具,能帮助我们编写出更健壮、更易于维护的 Go 代码,从容应对 Go 语言的发展和项目版本的演进。
思考题
最后,留给你两个问题思考:
- 你认为 Go 1 兼容性承诺对 Go 语言的生态系统(比如库的开发、社区的形成)产生了哪些深远的影响?
- 在你的实际 Go 项目开发中,是否遇到过因为 Go 版本升级或版本不匹配导致的兼容性问题?你是如何定位和解决的(可以结合 go 指令、GOTOOLCHAIN 或 GODEBUG 的使用经历来谈谈)?
欢迎在评论区分享你的经验和看法!我是 Tony Bai,我们下节课见。
值传递vs指针传递:深入Go数据操作的底层逻辑与性能考量
你好,我是 Tony Bai。
从这一节课开始,我们将进入 Go 语法细节。作为 Go 进阶者,你一定已经用过值类型(如 int、float64 以及自定义结构体类型)和指针类型(如 *int、*T)。你可能也知道什么时候用值、什么时候用指针,会对程序的性能和行为产生影响。
但你是否真正思考过:
- 当我们说“值”时,在计算机内存层面,它到底意味着什么?
- Go 语言中“一切皆值”的理念,具体是如何体现的?
- Go 的函数参数传递,到底是“值传递”还是“引用传递”?为什么传递指针和传递切片看起来效果不同?
- 在性能和程序正确性之间,我们该如何明智地选择使用值还是指针?
这些问题看似基础,却直击 Go 数据操作的本质。 不深入理解值与指针的底层机制,你可能只是“知其然”,但在面对性能瓶颈、内存问题或复杂的共享状态时,会“不知其所以然”,难以写出真正高质量的 Go 代码。
这节课,我们就来彻底厘清这些概念,我们就将从计算机如何存储数据的底层原理出发,由浅入深、层层推进地讨论 Go 语言中的值类型、指针类型,以及它们在数据传递中的行为表现。同时也会介绍一些在使用值和指针时需要注意的事项。
掌握了这些,你对 Go 的数据操作将有更深刻的认识,为后续学习方法、接口、并发等打下坚实基础。
从计算机内存看“值”的本质
我们人类通过抽象来理解世界,比如数量、大小、颜色、文本。计算机要解决现实问题,也需要对这些概念进行表示。它如何做到的呢?答案是:通过内存中的 有界比特序列(bounded bit sequence)。
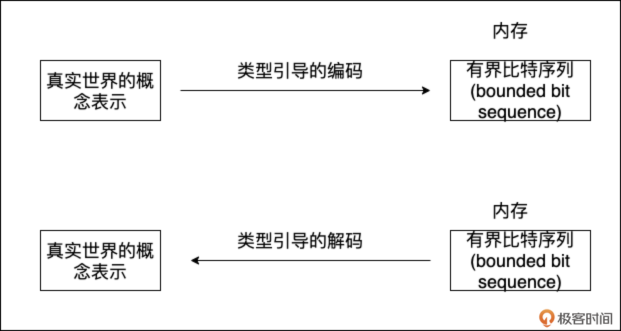
无论是整数 1000,还是字符串 “hello”,或者一个复杂的结构体,当它们存储在计算机内存中时,本质上都是一连串的 0 和 1。 这串有界的 0 和 1,我们就可以称之为“一个值(value)”。
而类型(type),则赋予了这段比特序列以含义。同一段比特序列,用不同的类型去“解码 (decode)”,会得到完全不同的结果。
比如,内存中有这样 16 个比特: 0000 0011 1110 1000
- 如果用 uint16 类型去解释,它代表整数 1000。
- 如果用 [2]byte(长度为 2 的字节数组)类型去解释,它可能代表两个字节,数值分别是 3 和 232。
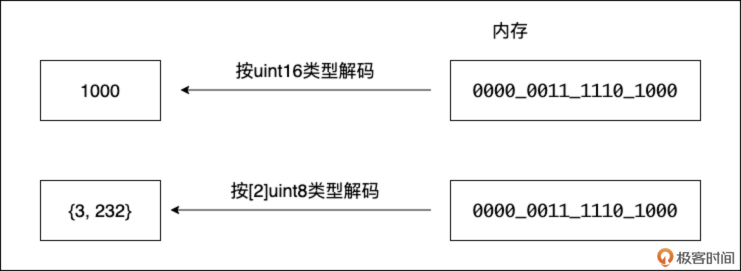
为了方便编程,高级语言引入了 标识符(identifier)(如变量名、常量名)来与内存地址建立关联。我们说变量持有(hold)一个值,实际上是指这个变量名对应着某个内存地址,该地址上存储着那个值的比特序列。
当然,也存在不与任何标识符绑定的值,我们称之为 字面值(literal),常用于初始化变量或常量:
var a int = 17 // 用字面值17初始化变量a
s := "hello" // 用字面值"hello"初始化变量s
const f float64 = 3.14 // 用字面值3.14初始化常量f
fmt.Println(42) // 42是一个整型字面值
原生类型的字面值,可以简单理解为汇编中的立即数;而复杂类型(比如结构体)的字面值,则一般是临时存储在栈上的有界比特序列。
“一切皆值”:Go 语言的核心理念
根据上面关于值的定义,我们可以认为, 在 Go 语言中,所有类型的实例都是以值的形式存在的:包括基本类型,如整数、浮点数、布尔等,以及复杂的数据类型,如结构体、数组、切片、map、channel 等。
到这里你可能会问:“不对吧?我听说 map 和 channel 是引用类型,传递它们更像是传递指针?”别急,要解答这个问题,我们就要来先看看值的分类。
值的分类:不止基本类型
Go 中的值大致可分为三类。
- 基本类型值
基本类型是 Go 语言中最基础的数据类型,它们是直接由语言定义的。基本类型的值通常是简单的值,比如整数、浮点数、布尔值等。在 Go 语言中,基本类型的值可以进行各种运算和比较操作。
- 复合类型值
复合类型则是由基本类型组成的更复杂的数据类型。它们的值由多个基本类型值或复合类型值组合而成,并且可以使用结构化的方式进行访问和操作。
在 Go 语言中,复合类型包括数组、切片、map、结构体、接口、channel 等多种类型。这些复合类型在不同的场景下都有不同的用途,可以用于表示不同的数据结构或者实现不同的算法。
注意,字符串在 Go 中是一个特殊的存在,从 Go 类型角度来看,它应该属于原生内置的基本类型,但从值的角度考虑,由于在运行时字符串类型表示为一个两字段的结构(这在《 Go语言第一课》专栏中有讲过,在后续的课程我们还会提到),因此,我们可将其归为 复合类型值 范畴。
- 指针类型值
有一类值十分特殊,它自身是一个基本类型值,更准确的说是一个整型值, 但这个整型值的含义却是另外一个值所在内存单元的地址。如下图所示:
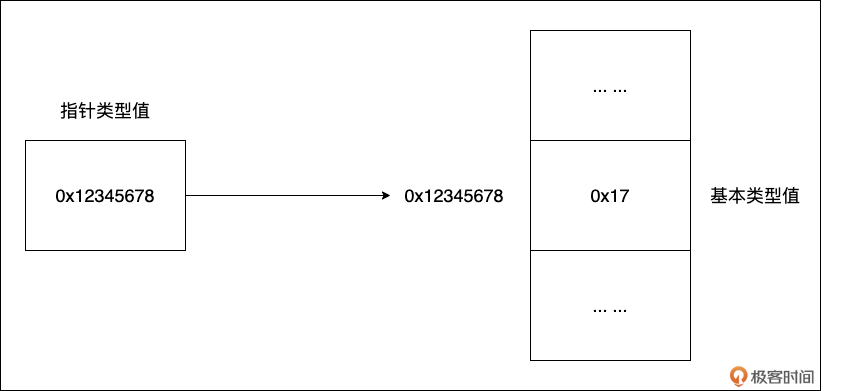
我们看到:指针类型值为 0x12345678,这个值是另外一个内存块(值为0x17)的地址。指针类型值在 Go 语言以及 C、C++ 这一的静态语言中扮演着极其重要的角色。
现在我们可以回答前面的问题了: map 和 channel 是值吗?
是的,它们是值。 更准确地说,从 Go 运行时的角度看,一个 map 变量或 channel 变量,其本身存储的值是一个指针,这个指针指向了运行时在堆上分配的、用于实现 map 或 channel 功能的内部数据结构(比如哈希表、缓冲区等)。
所以, 当你传递一个 map 或 channel 变量时,你实际上是在按值传递这个指针。这就是为什么在函数内部对 map 或 channel 进行操作(如添加键值对、发送接收数据)会影响到函数外部的原始变量——因为它们指向的是同一个底层的运行时数据结构。
值的可变性:并非所有值都能修改
虽然从物理内存角度看,内存单元的数据都可以被改写,但在编程语言和操作系统层面,对值的可变性做了限制。
- 内存段限制:操作系统将虚拟内存划分为不同段,如代码段(只读)、数据段、BSS 段、堆、栈等。存储在只读段(如代码段)的值是不可变的。
- 语言层面限制
- 常量(const)定义的值是不可变的。
- 字符串(string)类型的值在 Go 中也是不可变的。尝试修改字符串内容会导致编译错误或创建新字符串。
- 其他大部分类型(如 int、struct 的字段,slice 或 array 的元素)的值,如果它们不在只读内存段且不是常量,则是可变(mutable)的。
指针:特殊的值,重要的工具
针对指针这类值,编程语言抽象出了一种类型: 指针类型,写作 *T。指针类型的变量与指针类型值绑定,它内部存储的是另外一个内存单元的地址。这样就衍生出通过指针读取和更新指针指向的值的操作方法:
var a int = 5 // 基础类型值
var p = &a // p为指针类型变量(*int),其值为变量a的地址。
println(*p) // 通过指针读取其指向的变量a的值
*p = 15 // 通过指针更新其指向的变量a的值
当一个指针变量存储的地址是另外一个指针变量的地址时,我们就有了多级指针:
var x int = 1
var y int = 2
var p *int = &x // p是指向变量x的指针
var q *int = &y // q是指向变量y的指针
var pp **int = &p // pp是指向指针p的指针,即int**类型
可以通过下面的方式来访问和修改多级指针的指向:
fmt.Println(**pp) // 输出1,相当于两次间接访问
pp = &q
fmt.Println(**pp) // 输出2,相当于两次间接访问
**pp = 3 // 相当于y=3,即修改y的值为3
fmt.Println(y) // 输出3
通过多级指针,我们可以实现对同一份数据的多层间接访问和操作。这在某些场景下很有用,最典型的,比如在函数中修改上层函数的局部指针变量的指向:
func changePointer(pp **int) {
var nv = 20
*pp = &nv
}
func main() {
var v = 10
var p = &v
var pp = &p
fmt.Println("Before:", **pp) // 输出 Before: 10
changePointer(pp)
fmt.Println("After:", **pp) // 输出 After: 20
}
需要注意的是,多级指针的使用会增加代码的复杂度,在实际编程中要根据需要适度使用,过度使用反而会降低代码的可读性。
指针更大的好处就在于传递开销低,且传递后,接收指针的函数/方法体中依然可以修改指针指向的内存单元的值。接下来,我们就来详细说一下值的传递。
剖析值传递与指针传递的机制
无论是赋值还是传参,Go 语言中所有值传递的方法都是值拷贝,也称为逐位拷贝(bitwise copy)。不过即便是值拷贝,也会带来三种不同效果,我们逐一来看一下。
- 传值:你是你,我是我
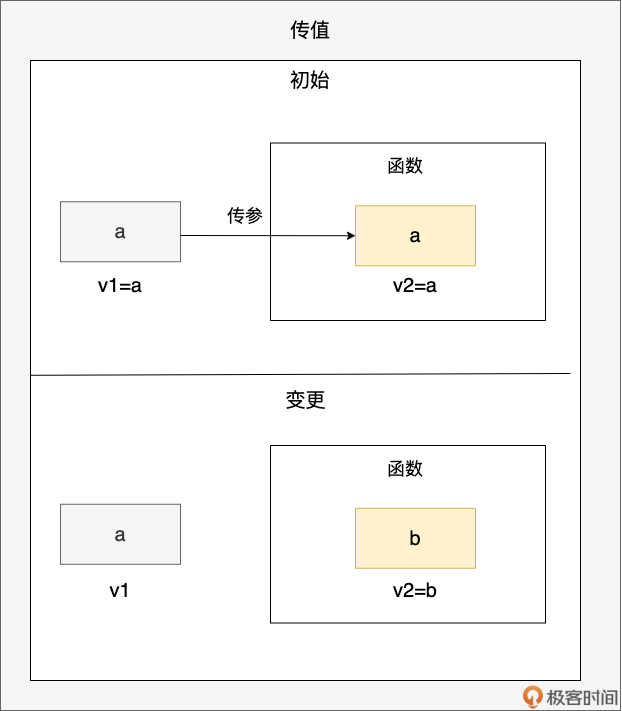
通过上面传值的示意图,我们看到值变量 v1(初值为 a)被传递到函数参数 v2 中,之后函数内 v2 的值更新为 b,但并不影响 v1,v1 的值仍为 a,用代码表示即为:
func foo(v2 int) {
b := 2
v2 = b // 传递后的v2独立更新为b
_ = v2
}
func main() {
a := 1
v1 := a
println(v1) // 1
foo(v1)
println(v1) // v1值仍为1
}
日常开发中,像传整型、浮点型、布尔值等都属于这种类型的传值。
- 传指针:你是你,我是我,但我们共同指向他
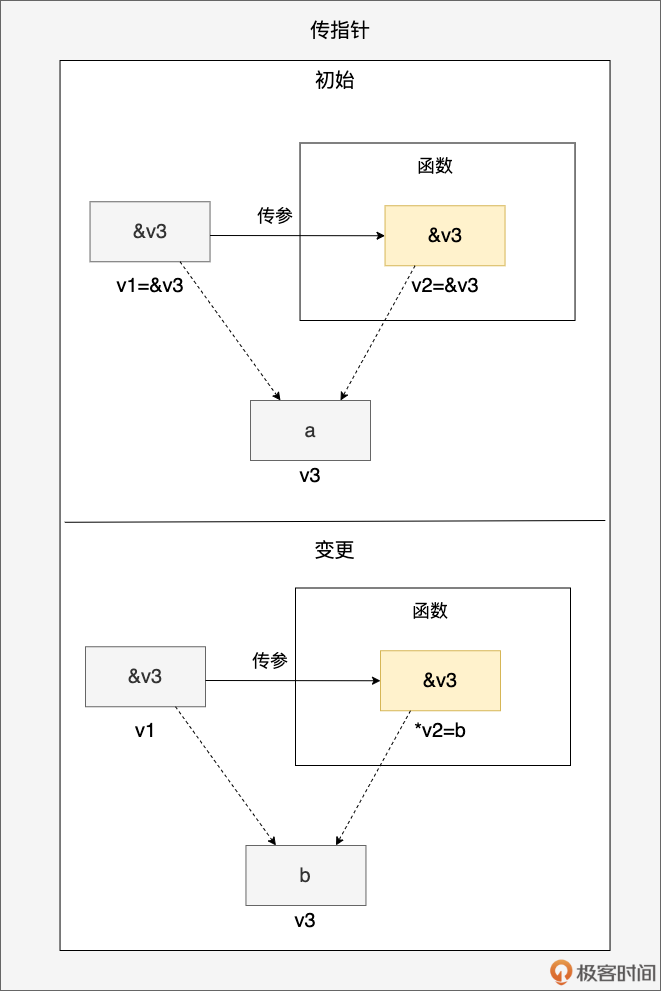
通过上面传指针的示意图,我们看到指针变量 v1(初值为 v3 的地址)被传递到函数参数 v2 中,v1 和 v2 拥有相同的指针值,都指向 v3 变量所在的内存块(初值为 a)。当函数通过 v2 指针解引用修改 v3 的值为 b 后,v1 也能感受到相同的变化。用代码表示即为:
func foo(v2 *int) {
b := 2
*v2 = b
}
func main() {
a := 1
v3 := a
v1 := &v3
println(*v1) // 1
foo(v1)
println(*v1) // 2
}
日常开发中,传递 *T 指针类型变量,以及那些在 Go runtime 层面本质是一个指针的类型的实例时,比如 map、channel 等,都归属于这一类型。
- 传“引用”:你是你,我是我,但我们有一部分共同指向他
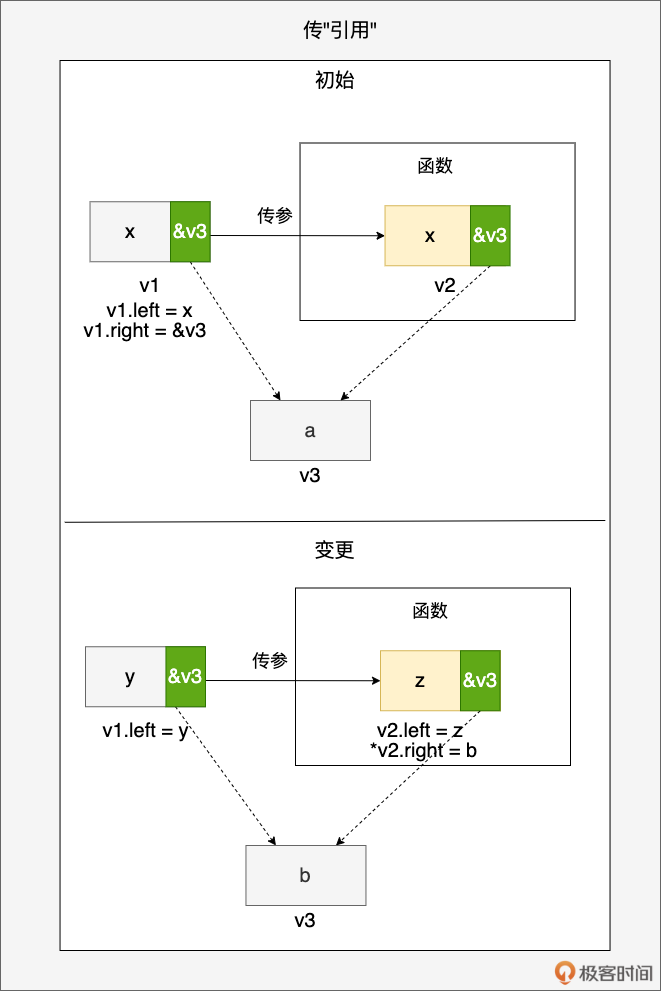
首先要注意,Go 语言规范中没有“引用类型”这一表述。其次,也不要将这里的“引用”与其他语言的“引用类型”相提并论。
这里传“引用”的效果是:传递前后的变量一部分是独立更新互不影响的,一部分则是有共同指向,相互影响的。示例图很好理解,这里就不赘述了。
最典型的例子就是切片。 当我们将切片传入函数后,函数内对切片的更新操作会影响到原切片,包括更新切片元素的值、向切片追加元素等。尤其是向切片追加(append)元素后,会导致传递前后的两个切片出现“不一致”,比如下面的示例:
func foo(sl []int) {
sl = append(sl, 5)
sl = append(sl, 6)
fmt.Println(sl, len(sl), cap(sl)) // [1 2 3 4 5 6] 6 8
}
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
func main() {
sl := make([]int, 4, 8)
sl[0] = 1
sl[1] = 2
sl[2] = 3
sl[3] = 4
foo(sl)
fmt.Println(sl, len(sl), cap(sl)) // [1 2 3 4] 4 8
p0 := unsafe.SliceData(sl)
p := (*[8]int)(unsafe.Pointer(p0))
fmt.Println(*p) // [1 2 3 4 5 6 0 0]
}
我们看到:foo 函数实际上已经修改了 sl 对应的底层数组(见最后一行输出结果),但由于传递前的 sl 中的 Len 和 Cap 值并没有变更(如果你尚不清楚切片的 len 和 cap 是什么,可以重温一下《 Go语言第一课》专栏),因此出现了不一致的情况。
因此, 当切片作为函数参数时,我们通常会将修改后的切片作为返回值返回出来,这样就能保持传递前后修改的一致,就像下面代码中那样:
func foo(sl []int) []int {
sl = append(sl, 5)
sl = append(sl, 6)
fmt.Println(sl, len(sl), cap(sl)) // [1 2 3 4 5 6] 6 8
return sl
}
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
func main() {
sl := make([]int, 4, 8)
sl[0] = 1
sl[1] = 2
sl[2] = 3
sl[3] = 4
sl = foo(sl)
fmt.Println(sl, len(sl), cap(sl)) // [1 2 3 4 5 6] 6 8
}
这里之所以使用“引用”来形容这种效果,主要是像切片这样的类型与我们熟知的其他语言中的引用(reference)很像,它们都是以“值”的形态传递,但却能干着“指针”的活儿。
值 vs 指针:选择场景与注意事项
零值:Go的默认与安全
Go 中,变量在声明但未显式初始化时,会被自动赋予其类型的零值。
- 数值类型:
0 - 布尔类型:
false - 字符串类型:
""(空字符串) - 指针、接口、切片、map、channel、函数类型:
nil - 数组、结构体:每个元素或字段都是其类型的零值
零值机制保证了 Go 变量总是有个确定的初始状态,避免了未初始化变量带来的风险。
注意:对 nil 指针、 nil map、 nil slice 等进行解引用或访问操作通常会导致运行时 panic。使用前务必检查是否为 nil(或确保它们已被正确初始化)。
一个特殊用法是零长度数组 [0]T,它的实例不占用内存,常用来使结构体不可比较(因为函数类型不可比较):
type NonComparable struct {
_ [0]func() // 包含不可比较类型,使整个结构体不可比较
Data int
}
// var nc1, nc2 NonComparable
// fmt.Println(nc1 == nc2) // 编译错误
值的比较:并非都能“==”
不是所有 Go 类型都支持使用 == 或 != 运算符进行比较:
func main() {
var sl1 []int
var sl2 []int
var m1 map[string]int
var m2 map[string]int
var f1 = func() {}
var f2 = func() {}
fmt.Println(sl1 == sl2) // invalid operation: sl1 == sl2 (slice can only be compared to nil)
fmt.Println(sl1 != sl2) // invalid operation: sl1 != sl2 (slice can only be compared to nil)
fmt.Println(m1 == m2) // invalid operation: m1 == m2 (map can only be compared to nil)
fmt.Println(m1 != m2) // invalid operation: m1 != m2 (map can only be compared to nil)
fmt.Println(f1 == f2) // invalid operation: f1 == f2 (func can only be compared to nil)
fmt.Println(f1 != f2) // invalid operation: f1 != f2 (func can only be compared to nil)
}
Go 中的切片、map 和函数类型只支持与 nil 进行相等或不等比较。
针对除此之外的其他不同类型,Go 执行的比较操作也是不同的。
- 对于基本类型(如 int、float、bool 等)以及指针类型,只需要比较它们的值的二进制表示就可以了。
- 对于结构体类型(不包含不支持比较的类型的字段),需要逐一比较它们的每个字段。
- 对于数组类型(元素类型不是不可比较类型),需要逐一比较它们的每个元素。
- 对于接口类型,需要判断它们是否指向同一个动态类型以及动态值是否相等。
下面还有一些值比较的注意事项,你也要了解一下。
- 对于浮点数类型,不能使用 “==” 运算符进行比较相等性,因为浮点数的精度问题可能导致比较结果不正确,可以使用 math 包中的函数进行比较。
- 对于结构体和数组类型,如果其中包含不可比较的字段(如切片、map、函数等),则整个结构体和数组类型也是不可比较的。
- 对于切片类型,可以使用 reflect 包中的函数 DeepEqual 进行比较。
- 对于指针类型,需要注意空指针的情况,应该先判断指针是否为 nil,再进行比较。
传值还是传指针:性能与语义的权衡
传值还是传指针是我们日常 Go 编程时经常需要考虑的一个问题。我总结了一下,选择传值还是传指针主要取决于以下三个因素:
- 对象的大小
如果对象的大小较小(例如一个简单的结构体或者基本类型值),建议使用传值的方式,因为这种情况下复制对象的开销相对较小。相反,如果对象的大小较大(例如一个庞大的结构体或者大的数组),建议使用传指针的方式,这样可以避免复制整个对象,从而节省内存和 CPU 开销。
// 传值示例
type SmallStruct struct {
A int
B bool
}
func updateValue(s SmallStruct) SmallStruct {
s.A = 42
s.B = true
return s
}
// 传指针示例
type LargeStruct struct {
Data [1024]byte
}
func updatePointer(s *LargeStruct) {
for i := range s.Data {
s.Data[i] = byte(i % 256)
}
}
- 对象的可变性
如果需要在函数内部修改对象的值,则必须使用传指针的方式,其原因在前面讲解不同传值方式的效果时已经阐明了。如果使用传值的方式,函数内部对对象的修改将不会影响到原始对象。
- 对象是否支持复制
如果对象包含一些不支持或语义上不允许复制的字段(例如 sync.Mutex 等),则必须使用传指针的方式,因为这些字段在复制时会导致编译错误或运行时的非预期结果。
上述的三个因素也同样适用于方法的 receiver 参数类型选择,但还有一个因素会制约 method receiver 的选型,那就是考虑 T 或 *T 是否需要实现某个接口类型。关于 method receiver 的类型选择问题,我们会在后面的课程中有系统的讲解,这里就不赘述了。
总的来说,在选择传值还是传指针时,需要根据对象的大小、可变性和是否支持复制等因素进行权衡,合理选择可以提高程序的性能和可读性。
类型转换与内存解释:unsafe的力量与风险
前面说过,值是一个“有界比特序列”,按照不同类型进行解码,得到的结果也是不同的。我们可以通过 unsafe.Pointer 来进行不同的解码。比如下面例子中,将一个 uint32 的值分别按 [2]uint16 和 [4]uint8 数组类型进行解码后的结果:
package main
import (
"fmt"
"unsafe"
)
func main() {
var a uint32 = 0x12345678
b := (*[2]uint16)(unsafe.Pointer(&a))
c := (*[4]uint8)(unsafe.Pointer(&a))
fmt.Println(*b) // [22136 4660] 按[2]uint16做内存解释
fmt.Println(*c) // [120 86 52 18] 按[4]uint8做内存解释
}
再次强调:unsafe 包的使用非常危险,它打破了 Go 的类型安全,可能导致难以追踪的错误和程序崩溃。只应在绝对必要且完全理解其后果的情况下使用(通常在与 C 库交互或进行底层性能优化时)。
深拷贝 vs 浅拷贝:复制的陷阱
在编码过程中,当我们复制一个对象时,会涉及到两种不同的复制方式:浅拷贝(Shallow Copy)和深拷贝(Deep Copy)。 这两种方式的主要区别在于它们如何处理对象内部包含的指针(或引用)类型字段。
浅拷贝只复制对象本身。如果对象内部包含指针,那么副本中的指针将与原始对象中的指针指向同一块内存地址。这意味着,如果通过副本修改了指针指向的数据,原始对象也会受到影响。
深拷贝则不同,它不仅复制对象本身,还会递归地复制对象内部所有指针指向的数据。深拷贝完成后,副本与原始对象是完全独立的,它们没有任何共享的内存。
我们来看一个示例:
package main
import "fmt"
type Address struct {
City string
}
type Person struct {
Name string
Age int
Address *Address // 指针类型字段
}
// DeepCopy 方法实现了 Person 类型的深拷贝
func (p Person) DeepCopy() Person {
newPerson := p // 先复制值类型字段
if p.Address != nil {
newAddress := *p.Address // 复制指针指向的Address对象
newPerson.Address = &newAddress //新对象指针指向新地址
}
return newPerson
}
func main() {
// 浅拷贝示例
p1 := Person{Name: "Alice", Age: 30, Address: &Address{City: "New York"}}
p2 := p1 // 浅拷贝
p2.Address.City = "Los Angeles"
fmt.Println(p1.Address.City) // 输出 "Los Angeles",p1也被修改了
// 深拷贝示例
p3 := Person{Name: "Bob", Age: 25, Address: &Address{City: "Chicago"}}
p4 := p3.DeepCopy() // 深拷贝
p4.Address.City = "Seattle"
fmt.Println(p3.Address.City) // 输出 "Chicago",p3未受影响
}
对于包含指针字段的类型,实现深拷贝和浅拷贝的方式有所不同。浅拷贝很简单,直接赋值即可。Go 会自动复制结构体中的所有字段,包括指针字段。但如前所述,这种复制只是指针值的复制,而不是指针指向的数据的复制。
要实现深拷贝,则需要手动编写代码或使用第三方库。 对于包含指针字段的结构体,一种常见的做法是定义一个 DeepCopy 方法,在该方法中创建新的指针,并复制指针指向的数据。
在这个例子中,Person 结构体包含一个 Address 类型的指针字段。针对该结构体类型变量的浅拷贝操作是直接赋值(p2 := p1),这样两个变量 p1 和 p2 中的指针类型字段 Address 指向同一个内存对象,当通过 p2 将 City 改为 “Los Angeles”,p1 中的 Adress.City 也会随之改变。
深拷贝则使用了自定义的 DeepCopy 方法,DeepCopy 首先复制了 Person 结构体中的值类型字段(Name 和 Age),然后检查 Address 指针是否为 nil。如果不为 nil,则创建一个新的 Address 对象,并复制原始 Address 对象的值,最后将新 Person 对象的 Address 字段指向这个新的 Address 对象。这样就实现了 Person 对象的深拷贝。
在 Go 语言中,深拷贝有其特定的应用场景。 由于 Go 中的赋值操作(包括函数参数传递)默认是浅拷贝,这在某些情况下可能会导致意料之外的副作用。
例如,当你希望修改一个对象的副本,但不希望影响原始对象时,或者当你需要将一个对象的状态保存为一个快照,以备后续恢复时,都需要用到深拷贝。另外,在并发编程中,为了避免多个 goroutine 之间的数据竞争,通常也需要对共享数据进行深拷贝。
不过即便如此,某些情况下,手工实现一个 DeepCopy 方法也是很难的,甚至是不可能的,比如当有循环引用或某些类型不支持拷贝(比如 sync.Mutex)的情况时。
小结
这一讲,我们从底层内存表示出发,重新审视了 Go 语言中看似基础却至关重要的“ 值”与“ 指针”。现在,我们来梳理一下核心要点。
-
值的本质:内存中的一段有界比特序列,其含义由类型决定。
-
Go 核心理念:一切皆值。所有类型实例(包括 map、channel 等)在内存中都以值的形式存在。map/channel 变量的值是指向运行时内部数据结构的指针。
-
指针类型:存储其他值内存地址的特殊值。通过 & 获取地址,通过解引用访问/修改指向的值。
-
唯一传递方式:Go 只有值传递(按位拷贝)。
-
不同传递效果源于拷贝内容
a. 拷贝基本类型/无指针 struct -> 纯值传递效果(隔离)。
b. 拷贝指针值 -> 指针传递效果(共享修改)。
c. 拷贝含指针的结构(如 slice header) -> 部分共享效果(底层数据共享,结构本身隔离)。
-
实用考量
a. 理解零值保证了变量的确定性。
b. 掌握值比较规则,知道哪些类型可比,哪些不可比。
c. 传值 vs 传指针需权衡数据大小(性能)、修改需求(语义)和拷贝语义。
d. 深拷贝 vs 浅拷贝在处理包含指针的对象复制时非常关键。
深入理解值和指针,以及 Go 唯一的值传递机制,是编写出高效、正确、符合 Go 语言习惯代码的关键一步。它能帮助你避免常见的内存共享错误,做出更优的性能决策,并为你理解后续更复杂的概念(如方法接收者、接口实现、并发内存模型)打下坚实的基础。
思考题
结合本节课对值传递三种效果的讨论(纯值效果、指针效果、切片效果),请你动手编写一个 Go 程序示例,要求:
- 定义一个函数
modifyValues。 - 在这个函数内部,尝试修改传入的三个不同类型的参数:一个 int,一个 *int(指向一个int),一个 []int(切片)。
- 在
main函数中,调用modifyValues,并打印调用前后这三个原始变量的值(对于指针,打印指向的值;对于切片,打印切片内容、长度、容量),清晰地展示出这三种传递效果的不同。
欢迎将你的代码示例和观察结果分享在留言区!我是 Tony Bai,我们下节课见。
数组与切片:性能、灵活与陷阱,如何做出最佳选择?
你好,我是 Tony Bai。
上一讲我们深入学习了值与指针以及 Go 的值传递机制。今天,我们要聚焦 Go 语言中使用频率最高的两种复合类型: 数组(array)和切片(slice)。相信你对它们已经不陌生了。
数组是由相同类型元素组成的复合类型,Go 会为每个数组类型实例分配一块连续的内存。一旦创建,数组的元素个数和大小就固定不变。
而切片可以理解为动态数组,它的元素类型也是相同的,但其底层数组(underlying array)的大小会随着调用 append 函数添加元素而自动扩展。所有这些操作都由 Go 运行时自动完成,程序员无需显式干预。
在日常 Go 开发中,切片以其无与伦比的灵活性,在很多场景下取代了数组,成为处理同构(相同类型)元素集合的首选。
但切片的这种灵活性并非没有“代价”。你是否思考过:
- 数组的“死板”背后,隐藏着哪些性能优势?
- 切片的“灵活”背后,又有哪些潜在的性能开销和不易察觉的“陷阱”?
- 比如,
nil切片和空切片有何不同?append导致底层数组“分家”是怎么回事?for range遍历切片时有什么坑? - 在追求性能和追求灵活性之间,我们应该如何明智地选择使用数组还是切片?
这节课,我们就来深入剖析数组和切片的核心差异、性能权衡以及常见的陷阱。掌握这些,你才能真正驾驭好数组和切片这两个Go 语言的利器。
数组 vs 切片:固定与动态的权衡分析
我们可以先从几个维度来对比数组和切片的优劣:
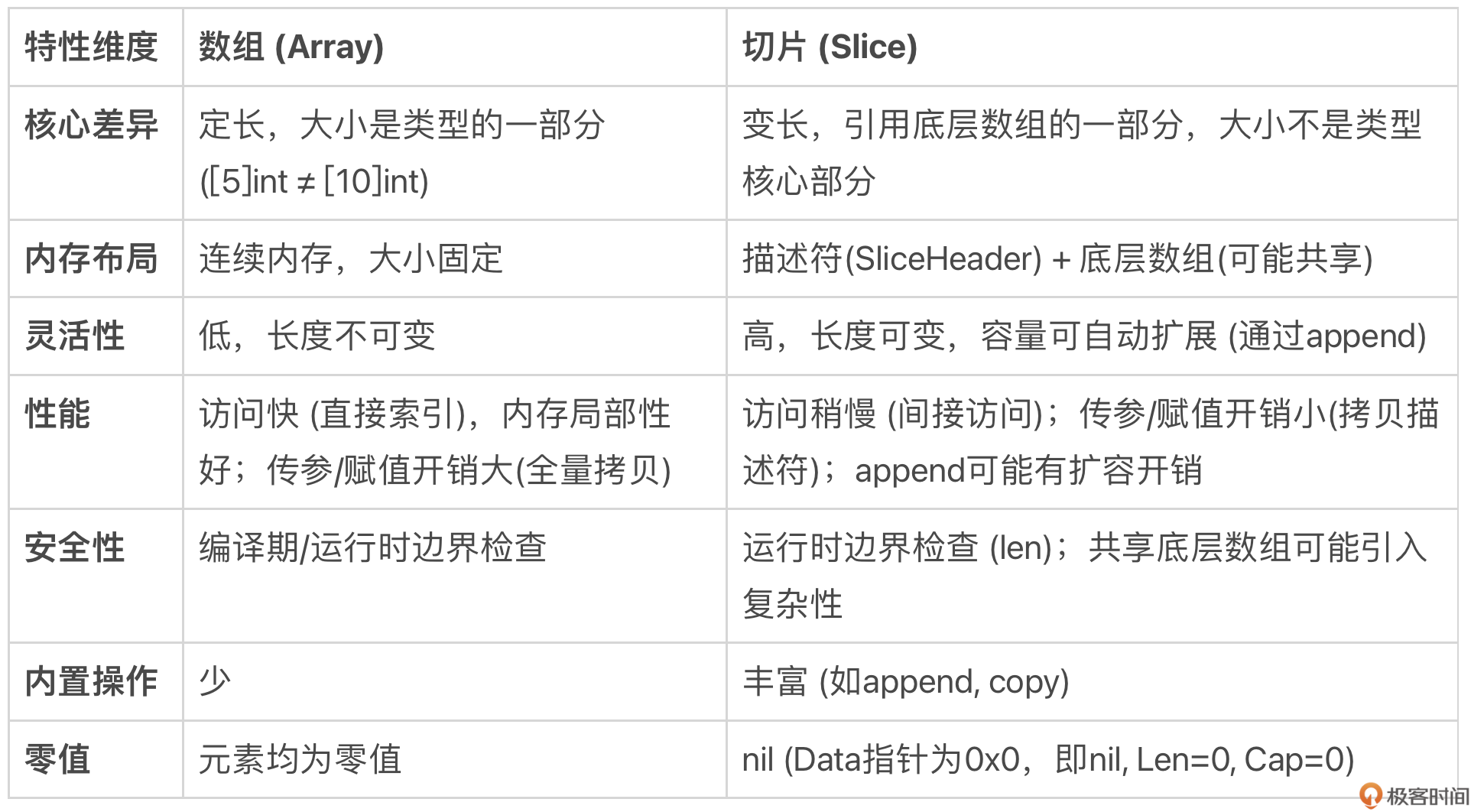
总结来说,核心的权衡在于:
- 数组:胜在性能稳定、内存布局简单、类型强约束带固定长度;劣在不够灵活、传参拷贝代价高。适用于大小固定且对性能有极致要求的场景,或作为其他数据结构的底层存储。
- 切片:胜在灵活、方便、传参代价低;劣在性能有波动(扩容)、内存管理相对复杂、存在一些使用陷阱。是 Go 中处理序列数据的首选和惯用方式。
在同构元素数据结构上,Go 语言的设计者更倾向于灵活性和实用性,因此切片的使用远比数组广泛。但理解切片灵活性的“代价”,是避免踩坑、写出高质量代码的关键。
切片的灵活性:背后的性能“代价”与常见陷阱
切片的易用性背后,隐藏着一些需要我们深入理解的机制和潜在问题。
nil 切片 vs 空切片
有过 Go 语言开发经验的小伙伴估计大多都知道空切片(empty slice)与 nil 切片(nil slice)比较的梗,这也是 Go 面试中的一道高频题:
var sl1 = []int{}
var sl2 []int
在上面代码中,sl1 是空切片,而 sl2 是 nil 切片。要理解这两种切片的区别,离不开运行时的切片表示。我们知道切片在运行时由三个字段构成,标准库 reflect 包中有切片在运行时中表示的具体定义:
// $GOROOT/src/reflect/value.go
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
基于这个定义我们来理解空切片和 nil 切片就容易多了。我们用一段代码来看看这两种切片的差别:
package main
import (
"fmt"
"reflect"
"unsafe"
)
func main() {
var sl1 = []int{}
ph1 := (*reflect.SliceHeader)(unsafe.Pointer(&sl1))
fmt.Printf("empty slice's header is %#v\n", *ph1)
var sl2 []int
ph2 := (*reflect.SliceHeader)(unsafe.Pointer(&sl2))
fmt.Printf("nil slice's header is %#v\n", *ph2)
}
在这段代码中,我们通过 unsafe 包以及 reflect.SliceHeader 输出了空切片与 nil 切片在内存中的表示,即 SliceHeader 各个字段的值。我们运行一下上述代码(使用 -gcflags ‘-l -N’ 可关闭 Go 编译器的优化):
$go run -gcflags '-l -N' dumpslice.go
empty slice's header is reflect.SliceHeader{Data:0xc000092eb0, Len:0, Cap:0}
nil slice's header is reflect.SliceHeader{Data:0x0, Len:0, Cap:0}
通过输出结果,我们看到 nil 切片在运行时表示的三个字段值都是 0;而空切片的 len、cap 值为 0,但 data 值不为 0。如果将 sl1 和 sl2 分别与 nil 进行等值比较,会得到如下与我们预期一致的结果:
println(sl1 == nil) // false
println(sl2 == nil) // true
那么 data 值不为 0,是否意味着 Go 已经给空切片分配了额外的内存空间了呢?并没有!
data 的值实际上是一个栈上的内存单元的地址,Go 编译器并没有在堆上额外分配新的内存空间作为切片 sl 的底层数组。如果你输出上面代码对应的汇编代码,你会发现在汇编代码中并没有调用 growslice 或 newobject 等在堆上分配底层数组的调用。
接下来,我们再来看看切片的自动扩容特性在底层内存管理上给我们带来的理解复杂性。
关于自动扩容
这里要提醒你: 只有通过 Go 预定义的 append 函数向切片追加元素的过程中,才会触发切片实例的自动扩容。如果仅仅是对切片进行下标操作,比如下面使用下标对切片元素的读取和赋值是不会触发自动扩容的。如果下标越界,即超出切片的长度,那么还会引发运行时的 panic。
var sl = make([]int, 8)
sl[0] = 10
... ...
sl[7] = 17
println(sl[3])
sl[8] = 18 // panic: runtime error: index out of range [8] with length 8
针对上面示例中的 sl,如果还要向其中存入数据,可以通过 append 函数,就像这样:
println(cap(sl)) // 8
sl = append(sl, 18)
println(sl[8]) // 18
println(cap(sl)) // 16
我们看到通过 append 向切片变量 sl 追加元素,append 前后的切片容量发生了自动扩充,由 append 前的 8 增加到 16,即一旦切片容量满(len==cap),append 就会重新分配一块更大的底层数组,然后将当前切片元素 copy 到新底层数组中。
通常在切片容量较小的情况下,append 都会按 2 倍切片的容量进行扩容,就像这个例子中的从 8 到 16。对于切片容量较大的情况(Go 1.17 及以前版本,容量超过 1024 归于此类,而从 Go 1.18 开始,这一上限值改为 256 了),那么 Go 便不会按 2 倍容量扩容。
下面是 Go 1.18 版本中的切片扩容算法:
// $GOROOT/src/runtime/slice.go
func growslice(et *_type, old slice, cap int) slice {
... ...
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
const threshold = 256
if old.cap < threshold {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
// Transition from growing 2x for small slices
// to growing 1.25x for large slices. This formula
// gives a smooth-ish transition between the two.
newcap += (newcap + 3*threshold) / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
... ...
}
和 Go 1.17 及以前版本相比,Go 1.18 在处理超过门限值(上面代码中的 threshold)的切片容量扩容前后的变化不会那么剧烈,而是使变化更为平滑一些。不过这个扩容算法也不是一成不变的,也许将来的某个版本 Go 中会有更为科学合理的切片扩容算法。
不过,自动扩容会带来一个“副作用”,进而导致代码中的潜在错误,那就是切片扩容后的新老切片彻底分家。这是什么意思呢?我们来看下面的示例:
package main
import "fmt"
func F(sl []int, elems ...int) []int {
sl = append(sl, elems...)
sl[0] = 11
return sl
}
func main() {
var sl = []int{1, 2}
fmt.Printf("origin sl = %v, addr of first element: %p\n", sl, &sl[0])
sl1 := F(sl, 3, 4, 5, 6)
fmt.Printf("after invoke F, sl = %v, addr of first element: %p\n", sl, &sl[0])
fmt.Printf("after invoke F, sl1 = %v, addr of first element: %p\n", sl1, &sl1[0])
}
在这个示例中,我们有一个整型切片 sl,其初始元素值有两个,1 和 2。我们将其传给函数 F,该函数在向切片追加元素后,会将第一个元素的值更新为 11。对这个示例,很多人的预期结果是原 sl 的第一个元素值也会被改为 11,但事实真的是这样吗?
我们来看看这段示例程序的执行结果:
origin sl = [1 2], addr of first element: 0xc00018a010
after invoke F, sl = [1 2], addr of first element: 0xc00018a010
after invoke F, sl1 = [11 2 3 4 5 6], addr of first element: 0xc0001a2000
我们看到,由于 F 函数中 append 元素数量超出了原切片的容量,Go 对切片进行了扩容,分配了新的底层数组,这样扩容前后的切片的底层数组就“分家”了,后续对切片第一个元素的更新,影响的仅仅是分家后的新切片及其底层数组,原切片中第一个元素值并未受到影响。
这个“分家”现象直接影响了我们在函数中处理切片的方式,即当切片作为函数参数时,我们该如何考量这个函数的设计。
函数设计
我们知道切片算是“半个”零值可用的类型,为什么这么说呢?当我们声明一个空切片时,我们不能直接对其做下标操作,比如:
var sl []int
sl[0] = 5 // 错误:引发panic
但是我们可以通过 Go 内置的 append 函数对其进行追加操作,即便 sl 目前的值为 nil:
var sl []int
sl = append(sl, 5) // ok
细心的小伙伴到这里可能会问: 为什么 append 函数要通过返回值返回切片结果呢?再泛化一点:当你在函数设计环节遇到要传入传出切片类型时,你会如何设计函数的参数与返回值呢?下面我们就来探讨一下。
我们在 $GOROOT/src/builtin/builtin.go 中找到了 append 预置函数的原型:
func append(slice []Type, elems ...Type) []Type
显然参照 append 函数的设计, 通过参数传入切片,通过返回值传出更新过的切片肯定是一个正确的方案,比如下面的第一版 MyAppend 函数:
func myAppend1(sl []int, elems ...int) []int {
return append(sl, elems...)
}
func main() {
var in = []int{1, 2, 3}
fmt.Println("in slice:", in) // 输出:in slice: [1 2 3]
fmt.Println("out slice:", myAppend1(in, 4, 5, 6)) // 输出:out slice: [1 2 3 4 5 6]
}
到这里,有些小伙伴会提出:切片不是动态数组吗?是不是可以既作为输入参数,又兼作输出参数呢?我理解提出这个问题的小伙伴们希望设计出像下面这样的函数原型:
func myAppend2(sl []int, elems ...int)
这里 sl 作为输入参数传入 myAppend2,然后在 myAppend2 对其进行 update 后,myAppend2 函数的调用者将得到更新后的 sl。但实际情况是这样的吗?我们来看一下:
unc myAppend2(sl []int, elems ...int) {
sl = append(sl, elems...)
}
func main() {
var arr = [6]{1,2,3}
var inOut = arr[:3:6] // 构建一个len=3,cap=6的切片
fmt.Println("in slice:", inOut)
myAppend2(inOut, 4, 5, 6)
fmt.Println("out slice:", inOut)
}
运行这段程序,我们得到如下结果:
in slice: [1 2 3]
out slice: [1 2 3]
我们看到 myAppend2 并未如我们预期的那样工作,传入的切片并未在 myAppend2 中得到预期的更新,这是为什么呢?首先这是与切片在运行时的表示有关的,在前面我们已经提过这一点了,切片在运行时由三个字段构成(见上面的 SliceHeader 结构体)。
此外,Go 函数采用“值拷贝”的参数传递方式,这意味着 myAppend2 传递的切片 sl 实质上仅仅传递的是切片“描述符” —— SliceHeader。myAppend2 函数体内改变的是形参 sl 的各个字段的值,但 myAppend2 的实参并未受到任何影响,即执行完 myAppend2 后,inOut 的 len 和 cap 依旧保持不变。
而其底层数组是否改变了呢?在这个例子中肯定是“改变”了,但改变的是 inOut 长度(len)范围之外,cap 之内的元素,通过对 inOut 的常规访问是无法获取到这些元素的。
那么我们该如何让 slice 作为 in/out 参数呢?答案是使用指向切片的指针,我们来看下面的例子:
func myAppend3(sl *[]int, elems ...int) {
(*sl) = append(*sl, elems...)
}
func main() {
var inOut = []int{1, 2, 3}
fmt.Println("in slice:", inOut) // in slice: [1 2 3]
myAppend3(&inOut, 4, 5, 6)
fmt.Println("out slice:", inOut) // out slice: [1 2 3 4 5 6]
}
我们看到 myAppend3 函数使用 *[]int 类型的形参,的确解决了切片参数作为输入输出参数的问题:myAppend3 对切片的更改操作都反映到 inOut 变量所代表的这个 slice 上了,即便在 myAppend3 内切片进行了动态扩容,inOut 也能“捕捉”到这点。
不过使用切片指针类型作为函数参数并非 Go 惯用法,我在 Go 标准库中查找了一下,使用指向切片的指针作为参数的函数“少得可怜”:
$grep "*\[\]" */*go|grep func
grep: cmd/cgo: Is a directory
grep: cmd/go: Is a directory
grep: runtime/cgo: Is a directory
log/log.go:func itoa(buf *[]byte, i int, wid int) {
log/log.go:func (l *Logger) formatHeader(buf *[]byte, t time.Time, file string, line int) {
regexp/onepass.go:func mergeRuneSets(leftRunes, rightRunes *[]rune, leftPC, rightPC uint32) ([]rune, []uint32) {
regexp/onepass.go: extend := func(newLow *int, newArray *[]rune, pc uint32) bool {
runtime/mstats.go:func readGCStats(pauses *[]uint64) {
runtime/mstats.go:func readGCStats_m(pauses *[]uint64) {
runtime/proc.go:func saveAncestors(callergp *g) *[]ancestorInfo {
综上,当我们在函数设计中遇到切片类型数据时,如果要对切片做更新操作,优先还是要参考 append 函数的设计方案,即通过切片作为输入参数和返回值的方式实现该操作逻辑,必要时也可以使用指向切片的指针的方式传递切片,就像 myAppend3 那样。
预分配容量
既然自动扩容有性能开销(内存分配 + 数据拷贝),那么如果我们在创建切片时就能预估到它最终大概需要多大容量,就可以提前分配,从而避免或减少后续 append 触发的扩容次数。
我们可以使用带容量参数的 make 函数:
sl := make([]T, length, capacity)
例如,如果你知道一个切片最终会存储约 1000 个元素:
// 方式一:无预分配容量
var sl1 []int
for i := 0; i < 1000; i++ {
sl1 = append(sl1, i) // 可能触发多次扩容
}
// 方式二:预分配容量
sl2 := make([]int, 0, 1000) // 长度为0,容量为1000
for i := 0; i < 1000; i++ {
sl2 = append(sl2, i) // 基本不会触发扩容 (除非1000次append中途有其他操作改变了容量)
}
我们看一下这两种方式的性能基准测试情况:
package main
import (
"testing"
)
func BenchmarkAppendWithoutCap(b *testing.B) {
for i := 0; i < b.N; i++ {
var sl []int
for j := 0; j < 1000; j++ {
sl = append(sl, j)
}
}
}
func BenchmarkAppendWithCap(b *testing.B) {
for i := 0; i < b.N; i++ {
sl := make([]int, 0, 1000)
for j := 0; j < 1000; j++ {
sl = append(sl, j)
}
}
}
在这个基准测试中,我们分别测试了使用 cap 创建的切片和未使用 cap 创建的切片的追加元素操作的开销,测试结果如下:
$go test -bench . benchmark_test.go
cpu: Intel(R) Core(TM) i5-8257U CPU @ 1.40GHz
BenchmarkAppendWithoutCap-8 355918 3378 ns/op
BenchmarkAppendWithCap-8 2456326 485.1 ns/op
PASS
结果显示, 预分配容量的方式性能提升显著(近 7 倍!)。
由此可以得出使用预分配的两个场景。
- 当你能比较准确地估计出切片所需的最大容量时。
- 在性能敏感的代码路径中,频繁的小切片
append操作可能成为瓶颈。
警惕内存泄露
切片支持在使用 append 追加元素时进行自动扩容, 但却不会自动缩容。也就是说在切片容量初始分配较大,或者是在扩容为大内存之后依然长期持有,即便不再使用这些扩容后的内存,这些内存也不会被释放,而会长期占用着内存资源。
下面是一个模拟此种状况的代码示例:
package main
import (
"fmt"
"math/rand"
"runtime"
"sync"
"time"
)
const (
poolSize = 10
maxSliceSize = 1000000
duration = 30 * time.Second
)
type SlicePool struct {
pool chan []int
}
func NewSlicePool(size int) *SlicePool {
return &SlicePool{
pool: make(chan []int, size),
}
}
func (p *SlicePool) Get() []int {
select {
case slice := <-p.pool:
return slice[:0] // 重置切片长度,但保留容量
default:
return make([]int, 0, 10) // 如果池空,创建新切片
}
}
func (p *SlicePool) Put(slice []int) {
select {
case p.pool <- slice:
default:
// 如果池满,丢弃
}
}
func smallWorker(id int, pool *SlicePool, wg *sync.WaitGroup, done <-chan struct{}) {
defer wg.Done()
for {
select {
case <-done:
return
default:
slice := pool.Get()
// 只使用前10个元素
for i := 0; i < 10; i++ {
if i < len(slice) {
slice[i] = i
} else {
slice = append(slice, i)
}
}
// 模拟使用切片
time.Sleep(100 * time.Millisecond)
pool.Put(slice)
}
}
}
func largeWorker(id int, pool *SlicePool, wg *sync.WaitGroup, done <-chan struct{}) {
defer wg.Done()
for {
select {
case <-done:
return
default:
slice := pool.Get()
size := rand.Intn(maxSliceSize)
for i := 0; i < size; i++ {
slice = append(slice, i)
}
// 模拟使用切片
time.Sleep(1 * time.Second)
pool.Put(slice)
}
}
}
func main() {
pool := NewSlicePool(poolSize)
var wg sync.WaitGroup
done := make(chan struct{})
// 启动小型worker
for i := 0; i < 8; i++ {
wg.Add(1)
go smallWorker(i, pool, &wg, done)
}
// 启动大型worker
for i := 8; i < 10; i++ {
wg.Add(1)
go largeWorker(i, pool, &wg, done)
}
// 定时打印内存使用情况
ticker := time.NewTicker(1 * time.Second)
timeout := time.After(duration)
for {
select {
case <-ticker.C:
printMemUsage("当前内存使用")
case <-timeout:
close(done) // 通知所有worker停止
ticker.Stop()
wg.Wait() // 等待所有worker结束
printMemUsage("结束时内存使用")
return
}
}
}
func printMemUsage(msg string) {
var m runtime.MemStats
runtime.ReadMemStats(&m)
fmt.Printf("%s - 使用的内存: %v MB\n", msg, m.Alloc/1024/1024)
}
在这个示例程序中,我们创建了一个切片池,池的大小为 10。我们启动了两类 worker goroutine,一类 worker goroutine 不断从切片池中取出切片,但仅使用其中很少的空间,然后再放回池子中;而另外一类 worker goroutine 则每秒从池中获取切片,随机扩展切片大小(最大为 1000000 个元素),然后将切片归还到池中。主 goroutine 每秒打印一次内存使用情况,持续 30 秒后程序结束。
我们运行这个程序,可以看到类似如下的输出结果:
$go run large_mem_hold.go
当前内存使用 - 使用的内存: 9 MB
当前内存使用 - 使用的内存: 14 MB
当前内存使用 - 使用的内存: 14 MB
当前内存使用 - 使用的内存: 14 MB
当前内存使用 - 使用的内存: 14 MB
当前内存使用 - 使用的内存: 22 MB
... ...
当前内存使用 - 使用的内存: 22 MB
当前内存使用 - 使用的内存: 22 MB
结束时内存使用 - 使用的内存: 22 MB
我们会看到内存使用量在开始时快速增长,然后保持在一个较高的水平,即使大部分时间 goroutine 可能只使用了切片池很小的一部分容量。这是由于切片扩容后,底层数组仍然占用着之前扩容的大量内存,这部分内存无法被释放,因为切片仍在池中被重复使用,导致程序内存占用居高不下。
如何缓解?
- 按需创建:如果可能,尽量在需要时创建大小合适的切片,而不是复用可能过大的切片。
- 显式复制:如果只需要大切片中的一小部分数据,并且希望释放大数组内存,可以显式地释放原切片,并创建一个新切片,并将所需数据拷贝过去。
largeSlice := getLargeSliceFromPool()
var smallSlice []int
tooLarge := (cap(largeSlice) >= 1000)
if tooLarge {
// 创建新切片并拷贝,不再引用大数组
largeSlice = nil // 释放大切片
smallSlice = make([]int, len(yourData))
} else {
smallSlice := largeSlice[:len(yourData)]
}
copy(smallSlice, neededData)
useSmallSlice(smallSlice) // 使用独立的小切片
像上面这样的由于切片在运行时的独特表示以及自动扩容特性所带来的潜在的问题还有一些,接下来我们再来看一个,那就是当 for range 和切片一起使用时可能会出现的问题。
for range 陷阱
切片与 for range 一起使用的方法我们再熟悉不过了,这里不再回顾 for range 的语法,而是直接给出一个 for range 与切片联合使用的代码示例,你先猜猜最终输出的 cnt 值是多少呢?
package main
import "fmt"
func main() {
a := make([]int, 5, 8)
cnt := 0
for i := range a {
cnt++
if i == 1 {
a = append(a, 6, 7, 8)
}
}
fmt.Println("cnt=", cnt)
}
有人说是 8!这些小伙伴的理由估计是这样的:在 i 为 1 时,代码又向切片 a 附加了 3 个新元素,使得切片的长度变为了 8。于是 for range 迭代 8 次,cnt 计数到 8。
下面我们实际运行一下这段代码,看看输出的结果究竟是多少:
cnt= 5
我们看到最终 cnt 的值为 5。为什么会这样呢?这与切片在运行时的表示以及 for range 后面的表达式的含义不无关系!
当我们使用 for range 去迭代切片变量 a 时,实际上 for range 后面的 a 是切片变量 a 的副本(以下以 a’ 代替),就像将一个切片变量以参数的形式传给一个函数一样,这是一个值拷贝的过程。
在 for range 循环过程中,切片 a 的副本 a’ 始终未变更过,它的长度始终为 5,因此 for range 一共就迭代了 5 次,所以 cnt 为 5。而循环体中通过 append 追加的元素实际上是追加到了原切片 a 上了。即便 a 和 a’ 仍然共享底层数组,但由于 a’ 的长度是 5,for range 就只能迭代 5 次。
数组与切片相互转换
最后,我们再来看看数组和切片间的转换。
虽然数组和切片是 Go 语言中不同的类型,但在实际开发中,我们经常需要在它们之间进行转换。理解如何高效地进行转换,避免不必要的内存分配,对于编写高性能的 Go 代码至关重要。
我们先来看看数组转切片。
将数组转换为切片非常简单,Go 语言提供了切片操作符 [:] 来实现这一目的,并且这种转换方式是 零拷贝 的。也就是说,它不会创建新的底层数组,而是直接引用原数组的底层存储。我们看下面示例:
package main
import (
"fmt"
"reflect"
"unsafe"
)
func main() {
arr := [5]int{1, 2, 3, 4, 5}
// 数组转切片
slice := arr[:]
// 验证切片与数组共享底层存储
fmt.Printf("Array address: %p\n", &arr[0])
fmt.Printf("Slice address: %p\n", &slice[0])
// 修改切片元素,观察数组是否受影响
slice[0] = 10
fmt.Println("Array after slice modification:", arr)
//获取数组和切片底层信息
ph1 := (*reflect.SliceHeader)(unsafe.Pointer(&slice))
fmt.Printf("slice's header is %#v\n", *ph1)
ph2 := (*[5]int)(unsafe.Pointer(ph1.Data))
fmt.Printf("slice's underlying array is %#v\n", *ph2)
}
运行这段程序,我们得到如下结果:
Array address: 0xc0000201b0
Slice address: 0xc0000201b0
Array after slice modification: [10 2 3 4 5]
slice's header is reflect.SliceHeader{Data:0xc0000201b0, Len:5, Cap:5}
slice's underlying array is [5]int{10, 2, 3, 4, 5}
从输出结果可以看出,切片 slice 和数组 arr 共享相同的底层存储地址。修改切片的元素也会影响到数组的元素。这种零拷贝的转换方式非常高效。
接下来,我们再来看看切片转数组。
与数组转切片不同的是,Go 并没有提供直接从切片创建数组的语法糖,因为切片是动态的,而数组是固定大小的。但在某些情况下,我们可能希望以数组的方式来操作切片的底层数据。但在 Go 1.17 之前,我们没有办法直接将切片转为数组,只能通过 unsafe 方式得到切片的底层数组的地址。
Go 1.17 增加了切片转数组指针的语法,Go 1.20 版本又增加了将切片转为数组的语法,我们通过下面示例来看一下这两种转换的使用:
package main
import (
"fmt"
"unsafe"
)
func main() {
// 原始切片
slice := []int{1, 2, 3, 4, 5}
fmt.Println("Original slice:", slice)
// 方法1: 标准语法 - Go 1.17+
arrayPtr := (*[5]int)(slice)
fmt.Println("Array pointer (standard):", *arrayPtr)
// 方法2: 使用unsafe的等价形式,不推荐,这里只是为了演示
unsafeArrayPtr := (*[5]int)(unsafe.Pointer(&slice[0]))
fmt.Println("Array pointer (unsafe):", *unsafeArrayPtr)
// 验证两者指向相同的内存
fmt.Printf("Standard array pointer: %p\n", arrayPtr)
fmt.Printf("Unsafe array pointer: %p\n", unsafeArrayPtr)
// 修改通过指针获取的数组,验证它影响原切片
(*arrayPtr)[2] = 30
fmt.Println("Slice after modifying through array pointer:", slice)
// 方法1: 标准语法 - Go 1.20+
slice[2] = 3 // 恢复原值
array := [5]int(slice)
fmt.Println("Array (standard):", array)
// 方法2: 使用unsafe的等价形式
// 另一种unsafe方式(不推荐,这只是为了演示)
unsafeArray := *(*[5]int)(unsafe.Pointer(&slice[0]))
fmt.Println("Array (unsafe deref):", unsafeArray)
// 验证标准转换创建了新的副本
array[2] = 300
fmt.Println("Original slice after modifying array:", slice)
fmt.Println("Modified array:", array)
}
运行这段程序,我们得到如下结果:
Original slice: [1 2 3 4 5]
Array pointer (standard): [1 2 3 4 5]
Array pointer (unsafe): [1 2 3 4 5]
Standard array pointer: 0xc00012e000
Unsafe array pointer: 0xc00012e000
Slice after modifying through array pointer: [1 2 30 4 5]
Array (standard): [1 2 3 4 5]
Array (unsafe deref): [1 2 3 4 5]
Original slice after modifying array: [1 2 3 4 5]
Modified array: [1 2 300 4 5]
从结果我们可以看到,通过转换后的数组指针,我们可以获得切片的底层数组的访问,并且对数组指针的修改也会影响到原切片。而通过 Go 1.20 的切片转数组语法,则是创建了一个新数组,并将切片的数据复制到了新数组中。因此,对新数组的修改不会影响到原来的切片。
Go 1.17 和 Go 1.20 提供了从切片到数组的更安全、更便捷的转换方式,这些方式避免了通过 unsafe 包直接操作指针,降低了出错的风险。同时 Go 1.17 的切片转数组是零拷贝的,非常高效。不过我们也要注意: 如果切片的长度小于数组的长度,会引发运行时 panic。
小结
在本讲中,我们深入对比了 Go 语言的数组和切片,探讨了它们在性能与灵活性上的核心权衡,并重点揭示了使用切片时可能遇到的性能“代价”与常见“陷阱”。
-
核心权衡:数组提供性能稳定和内存可预测性,但缺乏灵活性;切片提供极高的灵活性和便捷性,但性能有波动且隐藏着更多复杂性。
-
切片的“代价”与陷阱
- nil vs 空切片:底层
Data指针不同,影响== nil判断和某些场景(如JSON)。 - 自动扩容:
append超出容量时触发,涉及内存分配和拷贝开销;可能导致新老切片底层数组 “分家”。 - 函数设计:修改切片(尤其长度/容量)的函数,应返回新切片,而非依赖副作用或使用不常用的
*[]T参数。 - 预分配容量:使用
make([]T, len, cap)能显著减少扩容开销,提升性能。 - 内存持有:切片不自动缩容,复用大切片可能导致内存浪费,需警惕。
for range行为:迭代开始时拷贝切片头,循环次数固定,循环体内修改切片长度不影响迭代次数。
- nil vs 空切片:底层
-
数组切片转换:数组转切片是零拷贝;切片转数组指针(1.17+)是零拷贝;切片转数组(1.20+)是拷贝。
如何做出最佳选择?
- 默认使用切片:对于大多数需要处理序列数据的场景,切片的灵活性和易用性使其成为首选。
- 性能敏感且大小固定?考虑数组:如果集合大小在编译期已知,且是性能瓶颈点,数组可能是更好的选择。
数组和切片是 Go 数据结构的基础。深刻理解它们的特性、权衡和陷阱,是写出高效、健壮、地道 Go 代码的必经之路。
思考题
假设你正在设计一个函数,需要接收一个 []byte 切片,对其内容进行某种转换(可能会改变元素值,但不会改变切片的长度),然后返回转换后的结果。
请问,这个函数签名最好设计成以下哪种形式?并说明理由。
func Transform(data []byte)(无返回值,直接修改传入的切片)func Transform(data []byte) []byte(传入切片,返回一个新的切片)func Transform(data *[]byte)(传入指向切片的指针)
欢迎在留言区分享你的选择和思考!我是 Tony Bai,我们下节课见。
字符串:不只是字节序列,揭秘rune、UTF-8与高效操作
你好,我是 Tony Bai。
在 Go 语言中,string 是我们几乎每天都要打交道的基本数据类型。但你是否真正理解它的“内心世界”?
Go 的字符串就像一首精妙的“二重奏”:有时,它表现为一串连续的字节(bytes),你可以对它进行索引、切片,就像操作字节数组一样;有时,它又展现为一串字符(characters),你可以用 for range 优雅地遍历其中的字符,无论它们占多少字节。
这种两面性是如何实现的呢?此外:
- 当我们处理包含中文、日文或其他非 ASCII 字符的文本时,如何确保正确性?
- Go 是如何在底层表示字符串和字符的?rune 类型到底是什么?
- UTF-8 编码在其中扮演了什么角色?
- string 和 []byte 之间频繁转换,性能开销如何?Go 编译器又为我们做了哪些“零拷贝”优化?
- 拼接大量字符串时,用原生连接操作符
+和用 strings.Builder 有多大差别?
如果你对这些问题还有模糊之处,那么这节课就是为你准备的。 不深入理解字符串的“二重奏”本质,就可能在处理多语言文本时踩坑,或者在性能敏感的场景写出低效的代码。
这节课我们将深入学习 Go 字符串的内部实现、字符编码,以及如何高效地操作字符串,理解它“二重奏”的精髓。掌握了这些,你就能更自信、更高效地驾驭 Go 字符串这个强大的工具。
字节与字符:字符串的“两面性”
Go 语言的字符串有一个核心特性: 不可变性(immutability)。一旦创建,字符串的内容就不能被修改。在这个前提下,我们可以从两个视角来看待它。
视角一:字符串是字节序列
从这个角度看,字符串(s)表现得像一个只读的字节数组。
- 可按字节索引
你可以通过下标访问特定位置的字节,下标范围是 0 到 len(s)-1。
s := "hello"
fmt.Printf("s[0]: %c (byte value: %d)\n", s[0], s[0]) // 输出 s[0]: h (byte value: 104)
注意:如果示例中的 s 包含多字节字符(比如中文字符),s[i] 访问的只是其中的一个字节。
- 可按字节切片
你可以使用切片操作 s[low:high] 来获取一个新的字符串,它引用了原始字符串底层字节序列的一部分。 这个操作非常高效,因为它们共享底层字节数组,不会创建新的数据副本。
s := "hello, world"
s1 := s[:5] // 获取 "hello"
s2 := s[7:] // 获取 "world"
fmt.Println(s1, s2) // 输出 hello world
视角二:字符串是字符序列
从这个角度看,字符串代表了一连串的 Unicode 字符。
- 可按字符迭代
使用 for range 循环可以遍历字符串中的每一个 Unicode 字符(rune),无论这个字符由多少个字节组成。
s := "你好,世界!" // 包含中文字符和全角标点
for index, char := range s {
// index 是字符起始字节的索引
// char 是 rune 类型的值 (Unicode 码点)
fmt.Printf("字节索引 %d, 字符 %c, Unicode码点 %U\n", index, char, char)
}
上面代码输出结果如下:
字节索引 0, 字符 你, Unicode码点 U+4F60
字节索引 3, 字符 好, Unicode码点 U+597D
字节索引 6, 字符 ,, Unicode码点 U+FF0C
字节索引 9, 字符 世, Unicode码点 U+4E16
字节索引 12, 字符 界, Unicode码点 U+754C
字节索引 15, 字符 !, Unicode码点 U+FF01
注意观察 index 的变化,它不是连续递增的,因为每个中文字符和全角标点占用了 3 个字节。
- 原生 Unicode 支持
Go 字符串在设计上天然支持 Unicode。你可以使用标准库 unicode/utf8 中的函数来精确计算字符数量、进行 utf8 编解码等,下面是一个示例:
import "unicode/utf8"
s := "Hello, 世界!你好,Go"
fmt.Println("字节长度 (len):", len(s)) // 输出 27 (bytes)
fmt.Println("字符数量 (RuneCountInString):", utf8.RuneCountInString(s)) // 输出 15 (runes/characters)
// 也可以通过转换为 []rune 来获取字符数量
fmt.Println("字符数量 ([]rune):", len([]rune(s))) // 输出 15
这两种视角看似不同,实则都源于 Go 字符串的底层表示和编码方式。要理解这种统一,我们需要先看看字符串在内存中到底长什么样,以及 rune 到底是什么。
rune 类型:Go 如何表示 Unicode 字符?
虽然我们在源码层面感觉字符串像字符序列或字节序列,但在 Go 的运行时,一个 string 变量实际上是一个简单的结构体,包含两个字段:
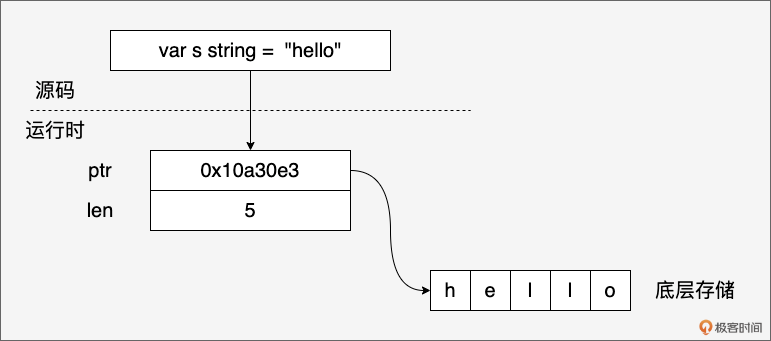
// $GOROOT/src/runtime/string.go
type stringStruct struct {
str unsafe.Pointer
len int
}
其中:
- str 指针指向一块内存,这块内存存储了字符串的字节序列。
- len 字段表示字符串的字节长度,而不是字符数量。
这种设计的关键在于: 字符串是不可变的字节序列。当我们创建一个字符串时,Go 会分配一块内存来存储字符串的字节数据,并将 ptr 指向这块内存的起始地址。由于字符串不可变,多个字符串变量可以共享同一个底层字节数组,从而节省内存空间。例如:
s1 := "hello"
s2 := s1
s1 和 s2 会共享同一个底层字节数组,如下图所示:
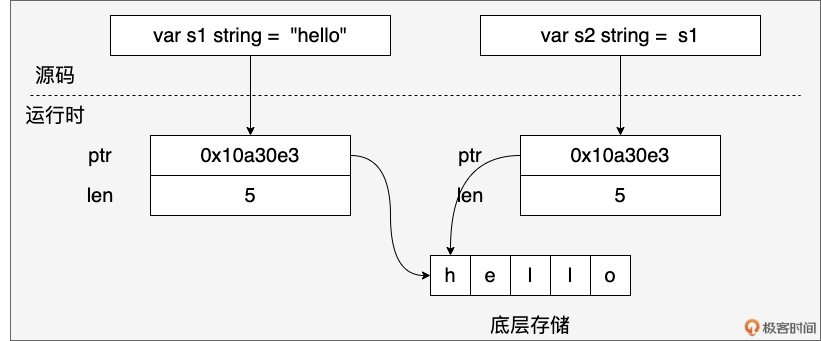
如果基于 s1 获取子字符串 s3,s3 也与 s1 共享同一块底层内存。
s3 := s1[1:4] // s3 ("ell") 也指向 s1 的部分内存
字符串底层是一个字节数组,那字符在哪里呢?接下来,我们就来看看 Go 语言是如何表示一个字符的。
Go 语言使用的是 Unicode 字符,无论是英文字母、数字、中文汉字或是其他符号等,在 Go 中都是一个 Unicode 字符,比如:
c1 := 'a'
c2 := '世'
c3 := '☺'
在 Go 源码层面,每个 Unicode 字符是由一个 rune 类型表示的,也就是说上面代码中的 c1、c2 和 c3 都是 rune 类型的变量。在 Go 中,rune 类型本质是一个 int32 类型,在 $GOROOT/src/go/builtin/builtin.go 中,你可以看到下面代码:
// $GOROOT/src/builtin/builtin.go
// rune is an alias for int32 and is equivalent to int32 in all ways. It is
// used, by convention, to distinguish character values from integer values.
type rune = int32
我们看到 rune 类型是 int32 类型的一个别名(alias),rune 类型变量(比如 c1)中存储的值是一个 Unicode 码点(code point)。
码点就是 Unicode 字符在 Unicode 字符表中的唯一序号,序号是一个数字,如下图:
我们可以通过将字符串转换为 []rune 的方式,来获取其包含的所有字符的码点序列:
import "encoding/hex"
s := "中国人"
runes := []rune(s) // 转换为 rune 切片
for i, r := range runes {
// %c 打印字符,%U 打印 Unicode 码点表示 (U+XXXX)
fmt.Printf("Index %d: Char '%c', Rune %d, Code Point %U\n", i, r, r, r)
}
fmt.Println(hex.Dump([]byte(s)))
输出:
Index 0: Char '中', Rune 20013, Code Point U+4E2D
Index 1: Char '国', Rune 22269, Code Point U+56FD
Index 2: Char '人', Rune 20154, Code Point U+4EBA
00000000 e4 b8 ad e5 9b bd e4 ba ba |.........|
现在问题来了:我们看到字符的码点(如 20013)和字符串底层存储的字节(如上面的 e4 b8 ad …)并不一样。
这说明, Go 字符串并没有直接存储码点,而是将码点进行了编码(encoding),然后存储编码后的字节序列。Go 选择的编码方式,正是大名鼎鼎的 UTF-8。
接下来,我们就来看看这种使用最为广泛的 Unicode 字符编码方式。
UTF-8 编码:字符串的底层存储奥秘
Unicode 字符编码就是将抽象的 Unicode 码点(一个整数)转换为用于存储或传输的具体字节序列的过程。反过来,将字节序列转换回码点的过程称为解码(decoding)。
下图展示了 Unicode 字符从抽象的码点(code point)到具体的内存表示(字节序列)之间的转换过程。
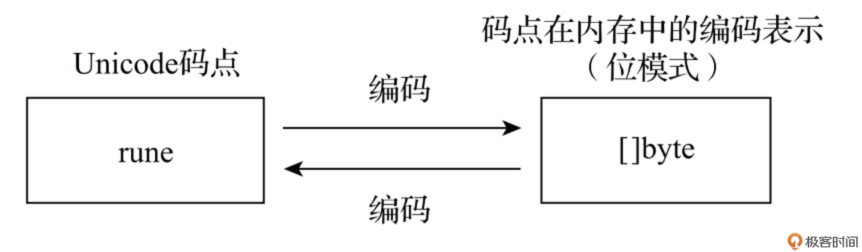
Unicode 字符有很多种编码方案,比如:UTF-8、UTF-16、UTF-32 等,其中 UTF-8 编码方案是应用最为广泛的一种,Go 默认使用 UTF-8 编码来存储 Unicode 字符。
上面示例中输出的 e4 b8 ad e5 9b bd e4 ba ba 就是字符串"中国人"经过 UTF-8 编码后得到的字节序列,即内存表示。
UTF-8 是一种可变长度编码,对于 ASCII 字符使用 1 个字节,对于其他字符使用 2~4 个字节,上面的中文字符使用的就是 3 字节的编码。
这种编码方式具有兼容性好(比如完全兼容 ASCII 字符)、节省空间(对于英文和其他拉丁字母的文本,UTF-8 使用的字节数较少,仅 1 字节)等优点。
正是因为 UTF-8 编码的存在,我们才需要区分遍历字符串的字节和字符。 前面我们已经展示了用 for range 遍历字符串的字符序列,那么如何遍历字符串的字节序列呢?
要遍历字节序列,需要使用到经典的三段式 for 循环:
package main
import (
"fmt"
)
func main() {
s := "中国人"
for i := 0; i < len(s); i++ {
fmt.Printf("%d: %x\n", i, s[i])
}
}
该示例输出结果如下:
0: e4
1: b8
2: ad
3: e5
4: 9b
5: bd
6: e4
7: ba
8: ba
注意,示例中的 len 函数返回的是字符串的字节数量,而不是字符数量。从输出结果也可以看到:"中国人"这个字符串的 UTF-8 编码占用了 9 个字节。
理解了 Go 字符串和字符的表示和编码后,我们再来看一个非常重要的实践环节:字符串与字节切片([]byte)的相互转换。我们将深入探讨这两种类型之间的转换机制,以及 Go 编译器在背后所做的优化工作。
零拷贝优化:字符串与字节切片的转换
在 Go 编程中,我们经常需要在 string 和 []byte 之间进行转换。
- 字符串转字节切片
s := "hello"
b := []byte(s) // 分配新的字节切片,并将"hello"的内容复制到切片中
b[0] = 'H'
fmt.Println(s) // 输出"hello",s不变
- 字节切片转字符串
b := []byte{'h', 'e', 'l', 'l', 'o'}
s := string(b) // 分配新的字符串,并将b的内容复制到字符串中
b[0] = 'H'
fmt.Println(s) // s不变,输出"hello",
上面的字符串和字节切片之间的转换看似简单,但在底层却可能涉及内存分配和数据拷贝。为什么呢?
字符串是不可变的,而字节切片是可变的。这意味着每次将字节切片转换为字符串时,Go 运行时都需要分配一块新的内存来存储字符串数据,并将字节切片的内容复制到新分配的内存中。
反之,将字符串转换为字节切片时,也需要分配新的字节切片内存,并复制字符串的数据。这种频繁的内存分配和数据拷贝会带来以下问题。
- 性能开销:内存分配和数据拷贝是相对耗时的操作,会占用 CPU 周期,降低程序性能。
- 内存占用:频繁的内存分配会导致内存碎片,增加垃圾回收(GC)的压力,甚至可能导致程序内存占用过高。
- GC 压力:大量的临时对象(如新分配的字符串和字节切片)会增加 GC 的负担,导致 GC 暂停时间变长,影响程序的响应速度。
为了解决这些问题,Go 编译器在特定场景下会对字符串和字节切片之间的转换进行优化,避免不必要的数据拷贝。这种优化被称为“零拷贝”(Zero-Copy)。
通过零拷贝,Go 编译器可以减少内存分配、降低 CPU 使用率、减轻 GC 压力,从而提高程序的性能和效率。
那么在哪些情况下,Go 编译器会进行优化,避免数据拷贝,实现零拷贝转换呢?下面我们就来全面地看一下。
零拷贝的核心思想是: 如果编译器能确定转换后的结果不会被修改,或者只是临时使用,那么就可以让转换后的类型直接共享原始类型的底层字节数据,从而避免内存分配和数据拷贝。
接下来,我们来看一下编译器进行零拷贝优化的常见场景。为了验证“零拷贝”的场景,我们先来准备一个测试工具函数,用来检查内存分配情况:
const (
testStringSmall = "hello, world"
testStringLarge = "Go is an open source programming language that makes it easy to build simple, reliable, and efficient software. Go语言是一种开源编程语言,它能让我们能够轻松地构建简单、可靠且高效的软件。"
)
func testAllocs(t *testing.T, name string, f func()) {
t.Helper()
n := testing.AllocsPerRun(100, f)
t.Logf("%-40s %f allocs/op", name, n)
if n > 0 {
t.Logf("⚠️ %s: 有内存分配发生", name)
} else {
t.Logf("✅ %s: 零内存分配", name)
}
}
testAllocs 利用 testing 包的 AllocsPerRun 函数来执行被测函数的内存分配情况, testing.AllocsPerRun(100, f) 这行代码的作用是运行函数 f 100 次,并计算在这些运行过程中发生的内存分配次数。
如果 n > 0,表示在执行函数 f 时发生了内存分配,日志中将输出一个警告信息。如果 n == 0,则说明函数在执行过程中没有发生任何内存分配,日志中将输出成功的信息。
接下来,我们将对 Go 编译器如何对字符串和字节切片互转场景进行零拷贝优化做一个全面的整理与分析。
使用 range 遍历 string 转换为 []byte 的场景
// ch05/zerocopy_test.go
func TestRangeOverConvertedBytes(t *testing.T) {
s := testStringLarge
testAllocs(t, "Range over []byte(string)", func() {
sum := 0
for _, v := range []byte(s) {
sum += int(v)
}
_ = sum
})
}
优化原理:Go 编译器检测到该 []byte 只用于遍历,不会被修改,因此可以直接使用原字符串的底层数据,无需额外分配内存。
使用 []byte 转换为 string 作为 map 键的场景
// ch05/zerocopy_test.go
func TestMapKeyConversion(t *testing.T) {
m := make(map[string]int)
m[testStringLarge] = 42
b := []byte(testStringLarge)
testAllocs(t, "Map lookup with string([]byte) key", func() {
v := m[string(b)]
_ = v
})
}
优化原理:Go 编译器检测到该 string([]byte) 仅用于 map 查找,只需要一个临时字符串,可以直接使用原字节切片的数据,无需复制。
append([]byte, string…) 操作
// ch05/zerocopy_test.go
func TestAppendStringToBytes(t *testing.T) {
dst := make([]byte, 0, 100)
s := testStringSmall
testAllocs(t, "append([]byte, string...)", func() {
result := append(dst[:0], s...)
_ = result
})
}
优化原理:Go 编译器将直接从 string 读取数据追加到 []byte 中,而不需要先将 string 转换为 []byte。
copy([]byte, string) 操作
// ch05/zerocopy_test.go
func TestCopyStringToBytes(t *testing.T) {
s := testStringLarge
dst := make([]byte, len(s))
testAllocs(t, "copy([]byte, string)", func() {
n := copy(dst, s)
_ = n
})
}
优化原理:Go 编译器直接将字符串内容复制到目标 []byte,避免中间临时 []byte 的创建。
字符串比较操作:string([]byte) == string
// ch05/zerocopy_test.go
func TestCompareStringWithBytes(t *testing.T) {
s := testStringLarge
b := []byte(s)
testAllocs(t, "Compare: string([]byte) == string", func() {
equal := string(b) == s
_ = equal
})
testAllocs(t, "Compare: string([]byte) != string", func() {
notEqual := string(b) != s
_ = notEqual
})
b1 := []byte(testStringLarge)
b2 := []byte(testStringLarge)
testAllocs(t, "Compare: string([]byte) == string([]byte)", func() {
equal := string(b1) == string(b2)
_ = equal
})
}
优化原理:Go 编译器检测到该操作只需要比较内容,可以直接比较字节切片和字符串、两个字节切片的内容,无需创建临时字符串。
bytes 包函数的 string 类型参数
// ch05/zerocopy_test.go
func TestBytesPackageWithString(t *testing.T) {
s := testStringSmall
testAllocs(t, "bytes.Contains([]byte, []byte(string))", func() {
c := bytes.Contains([]byte("hello world"), []byte(s))
_ = c
})
}
优化原理:bytes 包是专门用于处理字节切片的,当我们使用 []byte(s) 将字符串转换为字节切片时,编译器可以识别出这种模式,并进行优化。
for 循环遍历 string 转换为 []byte 的场景
// ch05/zerocopy_test.go
func TestForLoopOverConvertedBytes(t *testing.T) {
s := testStringLarge
testAllocs(t, "for loop over []byte(string)", func() {
bs := []byte(s)
sum := 0
for i := 0; i < len(bs); i++ {
sum += int(bs[i])
}
_ = sum
})
}
优化原理:虽然这里有 []byte(s) 的转换,但如果 bs 没有被修改,编译器还是可能直接使用底层数组。
switch 语句中使用 string([]byte)
// ch05/zerocopy_test.go
func TestSwitchWithConvertedBytes(t *testing.T) {
b := []byte(testStringSmall)
testAllocs(t, "switch with string([]byte)", func() {
switch string(b) {
case "hello":
// 不执行
case "world":
// 不执行
default:
// 执行
}
})
}
优化原理:编译器可以优化 switch 语句中的 string(b) 转换,避免创建临时字符串。
我们看到,零拷贝优化的核心是 Go 编译器会尽可能地避免在 string 和 []byte 之间转换时进行数据拷贝,前提是转换后的结果不会被修改,或者转换只是临时性的。
优化的场景主要集中在使用 []byte 转换为 string 的场景,且转换后的 string 不会被修改,或者只是用于读取、比较、map 键等操作。 只要涉及对 []byte 或 string 的修改,就无法进行零拷贝优化。
当然,我们也可以使用 unsafe 包进行强制的零拷贝转换,比如下面示例中的 byteToStringUnsafe 和 stringToByteUnsafe 函数:
// ch05/zerocopy_test.go
func byteSliceToStringUnsafe(b []byte) string {
return *(*string)(unsafe.Pointer(&reflect.StringHeader{
Data: uintptr(unsafe.Pointer(&b[0])),
Len: len(b),
}))
}
func stringToByteSliceUnsafe(s string) []byte {
return *(*[]byte)(unsafe.Pointer(&reflect.SliceHeader{
Data: (*reflect.StringHeader)(unsafe.Pointer(&s)).Data,
Len: len(s),
Cap: len(s),
}))
}
func TestUnsafeConversions(t *testing.T) {
b := []byte(testStringLarge)
s := testStringLarge
testAllocs(t, "Unsafe []byte to string", func() {
s2 := byteSliceToStringUnsafe(b)
_ = s2
})
testAllocs(t, "Unsafe string to []byte", func() {
b2 := stringToByteSliceUnsafe(s)
_ = b2
})
}
但这是不安全的,并且,reflect.StringHeader 和 reflect.SliceHeader 也已经被 Go 设置为废弃。除非你非常清楚自己在做什么,否则不建议使用。
Go 1.21 引入了新 unsafe 函数,它提供了更清晰的 API,来执行之前需要使用 reflect.StringHeader 和 reflect.SliceHeader的操作。这些新函数是:
- unsafe.String(ptr *byte, len int) string —— 从字节指针和长度创建字符串
- unsafe.StringData(s string) *byte —— 获取字符串数据的指针
- unsafe.Slice(ptr *T, len int) []T —— 从指针和长度创建切片
- unsafe.SliceData(slice []T) *T —— 获取切片数据的指针
这些操作可以用来实现零拷贝的转换,比如:
// ch05/zerocopy_test.go
// 使用unsafe.String将字节切片转换为字符串
func byteSliceToStringUnsafeGo121(b []byte) string {
return unsafe.String(unsafe.SliceData(b), len(b))
}
// 使用unsafe.Slice将字符串转换为字节切片
func stringToByteSliceUnsafeGo121(s string) []byte {
return unsafe.Slice(unsafe.StringData(s), len(s))
}
func TestUnsafeConversionsGo121(t *testing.T) {
b := []byte(testStringLarge)
s := testStringLarge
testAllocs(t, "Unsafe []byte to string(Go1.21)", func() {
s2 := byteSliceToStringUnsafeGo121(b)
_ = s2
})
testAllocs(t, "Unsafe string to []byte(Go1.21)", func() {
b2 := stringToByteSliceUnsafeGo121(s)
_ = b2
})
}
这些操作虽然实现了零拷贝,但有严格的安全要求:
- 字符串不可变性:使用 unsafe.Slice(unsafe.StringData(s), len(s)) 将字符串转换为字节切片后,绝对不能修改字节切片的内容,否则会破坏 Go 的字符串不可变性保证,可能导致程序崩溃或不可预期的行为。
- 内存生命周期:使用 unsafe.String(unsafe.SliceData(b), len(b)) 将字节切片转换为字符串时,必须确保原始字节切片在字符串使用期间不被回收或修改。
- 并发安全:这些操作不保证并发安全,在并发环境中使用时需要额外同步措施。
提醒大家要注意的是:编译器的优化策略可能会随着 Go 版本的更新而变化,因此在不同的 Go 版本中,零拷贝优化的具体情况可能会有所不同。
通过上面的全面整理与分析,你应该对 Go 编译器在字符串和字节切片转换时的零拷贝优化有了更深入的理解。在实际编程中,了解这些优化机制可以帮助我们编写出更高效的 Go 代码。
最后,我们再来看看另外一个最常见的字符串操作: 字符串拼接,了解一下哪种拼接方式最为高效。
高效字符串拼接:告别低效的 +
字符串拼接是另一个常见操作。最直接的方式是使用 + 或 += 运算符:
s1 := "hello"
s2 := "world"
s3 := s1 + ", " + s2 // 简单直接
但是,在循环或需要拼接大量字符串片段的场景下,使用 + 会非常低效。为什么呢?
因为字符串是不可变的。每次执行 result = result + fragment,Go 运行时都需要:
- 分配一块新的内存,大小为
len(result) + len(fragment)。 - 将
result的内容拷贝到新内存。 - 将
fragment的内容拷贝到新内存。 - 让
result指向这块新内存。 - 旧
result的内存成为垃圾,等待回收。
如果在一个循环中执行 N 次拼接,就会产生 N-1 个临时的、马上被丢弃的字符串对象,以及大量的内存分配和拷贝操作,性能开销巨大。
推荐方案: strings.Builder。
strings.Builder 类型是专门为高效构建字符串设计的。它内部维护一个可变的字节缓冲区( []byte)。
import "strings"
var fragments = []string{"Go", " ", "is", " ", "fast", "!"}
// 低效方式
var resultPlus string
for _, frag := range fragments {
resultPlus += frag
}
// 高效方式
var builder strings.Builder
// 可选:预估总长度,减少缓冲区扩容
builder.Grow(15) // 估算一个大概长度
for _, frag := range fragments {
builder.WriteString(frag) // 追加到内部缓冲区,可能触发扩容,但比每次都分配新string高效得多
}
resultBuilder := builder.String() // 最后一次性生成最终字符串
fmt.Println(resultPlus)
fmt.Println(resultBuilder)
strings.Builder 的优势:
WriteString方法直接将字符串的字节追加到内部缓冲区,避免创建大量临时字符串。- 内部缓冲区会按需扩容,但扩容策略通常比
+运算符导致的频繁分配更高效。 - 可以通过
Grow方法预先分配缓冲区大小,进一步减少扩容次数。 - 最后调用
String()方法时,它会返回一个指向内部缓冲区字节数据(或其副本,取决于实现细节和优化)的新字符串。
下面我们写一个 benchmark 测试,直观地对比一下 Builder 与 + 操作符的字符串连接速度,benchmark 测试的代码如下:
// ch05/benchmark_test.go
package main
import (
"strings"
"testing"
)
const numStrings = 1000
func BenchmarkPlus(b *testing.B) {
for i := 0; i < b.N; i++ {
s := ""
for j := 0; j < numStrings; j++ {
s += "hello"
}
}
}
func BenchmarkStringBuilder(b *testing.B) {
for i := 0; i < b.N; i++ {
var sb strings.Builder
for j := 0; j < numStrings; j++ {
sb.WriteString("hello")
}
_ = sb.String() // 获取最终字符串,防止编译器优化
}
}
运行该 benchmark 测试,结果如下:
$go test -bench .
goos: darwin
goarch: amd64
pkg: demo
BenchmarkPlus-8 3109 382385 ns/op
BenchmarkStringBuilder-8 280808 4136 ns/op
PASS
ok demo 2.445s
我们看到在这个特定场景下,Builder 的字符串连接性能要远远超过原生的 + 操作符。
那么何时使用 strings.Builder 呢?我建议是在 需要拼接多个(通常 3 个或以上)字符串片段时,尤其是在循环中构建字符串时。 而对于仅拼接两三个短字符串的简单情况,直接使用 + 操作符仍然是可读性最好、也足够快的选择。
小结
这一讲,我们深入探索了 Go 字符串的“二面性”世界,理解了它为何既像字节序列又像字符序列。
- 两面性:字符串是不可变的字节序列,支持按字节索引和切片;同时也是 Unicode 字符序列,可通过 for range 按字符(rune)迭代。
- 底层表示:运行时由
stringStruct(指向字节数据的指针str+ 字节长度len)表示。 rune类型:int32 的别名,用于表示一个 Unicode 码点。- UTF-8 编码:Go 默认使用 UTF-8 存储字符串,是可变长度编码,兼容 ASCII,能表示所有 Unicode 字符。
string与[]byte转换:通常涉及拷贝以保证不可变性。但 Go 编译器在多种只读、临时使用的场景下进行零拷贝优化,直接共享底层数据,提升性能。应优先依赖编译器优化,避免使用unsafe进行强制零拷贝,除非极度必要且能控制风险。- 高效拼接:在拼接多个字符串片段(尤其在循环中)时,应使用
strings.Builder替代+运算符,以避免大量临时对象分配和数据拷贝,显著提高性能。
掌握 Go 字符串的这些核心概念和实践技巧,对于正确处理全球化文本、优化 I/O 操作、提升程序整体性能至关重要。
思考题
我们知道 for range s 可以遍历字符串 s 中的 Unicode 字符 ( rune),而 for i := 0; i < len(s); i++ 遍历的是字节 ( byte)。
请思考:在什么情况下,我们可能需要放弃 for range 的便利性,而选择手动地、按字节 ( for i := 0; ...) 来处理一个字符串?举一个或多个你认为合理的场景。
欢迎在留言区分享你的想法!我是 Tony Bai,我们下节课见。
Map:不仅是键值对,掌握哈希表的高效用法与并发陷阱
你好,我是 Tony Bai。
前面几讲我们“强化”了 Go 中的原生序列类型,如数组、切片和字符串。它们擅长处理有序数据,但如果我们需要快速根据一个“键”找到对应的“值”呢?这时,Go 的另一个内置法宝—— map 就登场了。
map 本质上是哈希表(hash table)的一种实现。它的核心“魅力”在于,无论你的数据集有多大,查找、插入、删除一个键值对的操作,平均时间复杂度都能达到惊人的 O(1),也就是常数时间!这使得 map 成为 Go 中使用频率最高、也最实用的数据结构之一,无论是做缓存、去重,还是建立数据间的关联,都离不开它。
但是,强大的工具往往伴随着复杂性。map 的使用并非“傻瓜式”操作,一不小心就可能掉进各种“陷阱”:
- 并发读写 map 为何会导致程序崩溃?如何安全地在 goroutine 间共享 map?
- 为什么不能直接获取 map 中元素的地址?修改 map 中的结构体字段为何会报错?
nilmap 和空 map 有何区别?误用为何会导致 panic?- 为何不能直接用
==比较两个 map 是否相等? - map 的遍历顺序为何是随机的?
如果你对这些问题还存在疑惑,那么这节课就是为你量身定制的。 不深入理解 map 的特性、约束和常见陷阱,就可能写出有并发风险、性能低下甚至隐藏Bug 的代码。
本节课我们将深入探讨 map 的用法、特性、陷阱和优化技巧,让你能够充分发挥 map 的优势,避免常见的错误。
并且,Go map 的实现依然在优化,Go 1.24 版本中引入了基于 swiss table 的新 map 实现,在本节课末尾,我也会对新 map 的实现做简单介绍,对新旧 map 实现做个简单对比。我们的目标很明确: 让你不仅会用 map,更能用好 map,充分发挥其威力,规避其风险。
map 基础回顾
我们先快速过一遍 map 的基础,确保大家都在同一起跑线上。
创建 Map: make vs 字面量
声明一个 map 变量:
var m map[KeyType]ValueType
KeyType 必须是可比较(comparable)的类型,支持 == 和 !=,如 int、string、指针、 struct(所有字段都可比较)等,但 slice、func、map 本身不行。ValueType 可以是任意类型。
但仅仅这样声明的 map 还不行,因为其值是 nil。 对 nil map 进行写操作会导致 panic! 因此,必须初始化 map 才能使用。下面是两种常用的初始化 map 的方式:
- 使用
make函数
// 创建一个空的 map
m1 := make(map[string]int)
// 创建时预估容量 (后面会讲为何重要)
m2 := make(map[string]int, 100) // 预分配大约100个元素的空间
make 是创建空 map 或需要动态添加元素时的常用选择。
- 使用字面量(Literal)
// 创建并初始化
m3 := map[string]int{
"apple": 1,
"banana": 2,
}
// 创建一个空的 map (等效于 make)
m4 := map[string]int{}
如果创建时就知道初始内容,使用字面量创建并初始化 map 的方式更简洁。
核心操作
map 的核心操作包括:
- 增/ 改(Set)
使用赋值 m[key] = value。键存在则更新,不存在则添加。
m := make(map[string]int)
m["one"] = 1 // 增
m["one"] = 11 // 改
- 删(Delete)
使用内置 delete(m, key) 函数。如果 key 不存在,该操作无效果,不会报错。
delete(m, "one")
delete(m, "not_exist") // 安全,无操作
- 查(Get)
使用索引 value := m[key]。如果 key 不存在,会返回 ValueType 的零值!这可能导致混淆,无法区分值恰好是零值还是键不存在,因此推荐使用 “comma ok” idiom 判断键是否存在,如下面示例:
value, ok := m["one"]
if ok {
fmt.Println("Key 'one' exists, value:", value)
} else {
fmt.Println("Key 'one' does not exist")
}
遍历 Map: for range 与随机性
Go 支持使用 for range 遍历 map:
m := map[string]int{"a": 1, "b": 2, "c": 3}
for key, value := range m {
fmt.Println(key, ":", value)
}
切记: Map 的遍历顺序是随机的! 每次运行 for range,你得到的键值对顺序可能都不同。这是 Go 团队故意设计的,目的是防止开发者依赖任何隐式的迭代顺序。
如果需要按特定顺序(如按键排序)遍历,标准做法是:
- 提取所有键到一个切片。
- 对切片进行排序。
- 遍历排序后的切片,用键从 map 中取值。
import "sort"
// ... (m 定义同上)
keys := make([]string, 0, len(m))
for k := range m {
keys = append(keys, k)
}
sort.Strings(keys) // 排序 keys
for _, k := range keys {
fmt.Println(k, ":", m[k]) // 按 key 排序输出
}
nil Map vs 空 Map 再强调
- nil map (
var m map[K]V)
nil map 的值为 nil,不能进行写操作(包括赋值和 delete),否则会 panic。不过,对 nil map 进行读操作( len、 range 和查找)是安全的。
var m map[int]int
// m[1] = 1 // panic
println(m[1]) // 0
for k, v := range m {
_ = k
_ = v
}
println(len(m)) // 0
- **空 map** (`make(map[K]V)` 或 `map[K]V{}`)
空 map 的值不是`nil`,但其长度为 0,可以安全进行读写操作。
var m = make(map[int]int)
m[1] = 1
println(m[1]) // 1
for k, v := range m {
_ = k
_ = v
}
println(len(m)) //1
同时我们看到:使用内置的 len(m) 可以获取 map 中当前键值对的数量,而对 nil map 调用 len 则返回 0。在并发环境中也可以使用 len 函数获取 map 大小,但如果在 map 上进行写操作(如添加或删除键值对)时,其他 goroutine 调用 len 可能会得到不一致的结果。
为了避免踩坑,我建议大家总是初始化 map 再使用,避免使用 nil map。
上面我们回顾了 map 的基本操作,包括声明、初始化、增删改查以及遍历。这些操作构成了 map 日常使用的基础。然而,要真正掌握 map,避免在使用过程中踩坑,我们还需要深入了解 map 的一些高级特性和潜在问题。
接下来,我们将探讨 map 的并发安全性、键值类型的限制、性能优化等进阶话题,帮助你更好地驾驭 map 这个强大的工具。
进阶:并发、约束、优化与避坑指南
回顾了 map 的基本用法后,我们来学习 map 的进阶使用技巧,包括如何避免常见的陷阱,以及如何优化 map 的性能。要用好 map,必须了解以下几点。
并发安全:原生 Map 的“致命弱点”
Go 的原生 map 类型不是并发安全的! 这意味着多个 goroutine 同时读一个 map 是安全的。但只要有一个 goroutine 在写(增、删、改),同时有其他 goroutine 在读或写,就极有可能导致 panic 或数据损坏,这是绝对禁止的。
那如何在并发环境中使用 map?有三种主要方案。
- 使用
sync.Mutex(互斥锁)
这是最简单直接的方式。在每次访问(读或写)map 前加锁,访问结束后解锁。保证同一时间只有一个 goroutine 能操作 map。
import "sync"
type SafeMap struct {
mu sync.Mutex
m map[string]int
}
func NewSafeMap() *SafeMap {
return &SafeMap{m: make(map[string]int)}
}
func (sm *SafeMap) Set(key string, value int) {
sm.mu.Lock()
defer sm.mu.Unlock()
sm.m[key] = value
}
func (sm *SafeMap) Get(key string) (int, bool) {
sm.mu.Lock()
defer sm.mu.Unlock()
val, ok := sm.m[key]
return val, ok
}
不过这个方案的缺点是锁的粒度太大,即使是读操作也要竞争锁,性能在读多写少场景下不高。
- 使用
sync.RWMutex(读写锁)
允许多个读操作并发进行,但写操作需要独占。 适用于读多写少的场景。
type SafeMap struct {
sync.RWMutex
m map[string]int
}
func (sm *SafeMap) Set(key string, value int) {
sm.Lock() // 写锁
defer sm.Unlock()
sm.m[key] = value
}
func (sm *SafeMap) Get(key string) (int, bool) {
sm.RLock() // 读锁
defer sm.RUnlock()
value, ok := sm.m[key]
return value, ok
}
该方案提高了读操作的并发性,但不足也有,那就是实现比使用 Mutex 略复杂,写操作仍然是阻塞的。
- 使用 sync.Map (Go 1.9+)
Go 1.9 标准库提供了内置并发安全的 map,可以安全地被多个 goroutine 并发使用,无需额外的加锁或协调。
import "sync"
var sm sync.Map // 直接声明即可使用
// 存储
sm.Store("key1", 100)
// 读取
if value, ok := sm.Load("key1"); ok {
fmt.Println("Loaded value:", value.(int)) // 注意类型断言
}
// 读取或存储 (如果key不存在则存储并返回新值)
actual, loaded := sm.LoadOrStore("key2", 200)
fmt.Println("LoadOrStore:", actual.(int), "Loaded?", loaded)
// 删除
sm.Delete("key1")
// 遍历 (注意 Range 的函数签名)
sm.Range(func(key, value interface{}) bool {
fmt.Println("Range:", key.(string), value.(int))
return true // 返回 true 继续遍历, false 停止
})
那么上述 3 种 map 并发安全方案该如何选择呢?
我们先来看 sync.Map。sync.Map 类型针对两种常见场景进行了优化:
- 对于给定键的条目只被写入一次但被读取多次的情况,例如只会增长的缓存。
- 多个 goroutine 读取、写入和覆盖不相交键集的条目。
在这两种情况下使用 sync.Map,可以显著减少与普通 Go map 结合使用 Mutex 或 RWMutex 的锁竞争。
如果确定不要用 sync.Map,而是用原生 map 类型,那么如果 map 的读写操作都比较频繁,或者读操作的临界区较大,建议使用 sync.Mutex。如果 map 的读操作远远多于写操作,且读操作的临界区较小,建议使用 sync.RWMutex。
Key 的约束:必须可比较
前面提到,map 的 KeyType 必须是可比较的类型。Go 语言规范中详细定义了可比较的类型和比较规则。
可比较的类型
- 布尔值
- 数值类型(整数、浮点数、复数)
- 字符串
- 指针
- 通道
- 接口类型
- 数组(元素类型必须可比较)
- 结构体(字段类型必须可比较)
不可比较的类型
- 切片
- 函数
- 包含切片或函数的结构体类型
将不可比较的类型作为 map 的键会导致编译错误。在日常编程过程中,大家可以参考下面的键类型选用建议:
- 优先使用内建类型(如整数、字符串)作为
map的键。 - 避免使用浮点数作为
map的键,因为浮点数的精度问题可能导致相等的键被认为是不同的。 - 如果需要使用结构体作为
map的键,确保结构体的所有字段都是可比较的。 - 如果需要使用自定义类型作为键,确保自定义类型是来自可比较类型或由可比较类型组合而成的。
说完 map 的键类型,我们再来看看 map 的值(Value)。
Value 的约束:不可寻址性
map 的元素是不可寻址的(not addressable),这意味着我们不能直接获取 map 元素的地址,也不能直接修改 map 元素的值(如果 value 是结构体类型)。
m := map[string]int{"a": 1}
// p := &m["a"] // 编译错误: cannot take address of m["a"]
type Point struct{ X, Y int }
points := map[string]Point{"origin": {0, 0}}
// points["origin"].X = 10 // 编译错误: cannot assign to struct field points["origin"].X in map
这是因为 map 在扩容(rehash)时,内部元素的位置可能会改变。如果允许获取元素地址,那么扩容后这个地址就会失效,变成悬空指针,非常危险。Go 语言从设计上禁止了这种操作。
那么如何修改 map 中结构体的值呢? 下面给出两种常见的方案。
- 取出副本 -> 修改副本 -> 存回 map
p := points["origin"] // 取出的是 Point 值的副本
p.X = 10 // 修改副本
points["origin"] = p // 将修改后的副本存回 map
这是最常用的方法,虽然看起来有点啰嗦,但保证了安全。
- 让 Value 成为指针类型
如果 map 的值本身就是指针,那么你可以直接修改指针指向的内容。
pointsPtr := map[string]*Point{"origin": {0, 0}} // 值是指针 *Point
pointsPtr["origin"].X = 10 // 合法!修改指针指向的 Point 结构体
选择哪种取决于你的数据模型和共享需求。如果结构体很大,或者需要在多处共享同一个结构体实例,使用指针可能更合适。
Map 的比较:为何不能用 ==?
map 类型本身是不可比较的(除了与 nil 比较)。
m1 := map[string]int{"a": 1}
m2 := map[string]int{"a": 1}
// fmt.Println(m1 == m2) // 编译错误: invalid operation: m1 == m2 (map can only be compared to nil)
这是因为 map 的内部实现中包含了指针,而指针的比较是基于指针地址的。即使两个 map 的键值对完全相同,它们的指针也可能不同。此外,浮点数作为值时,比较也存在精度问题。
那么,如何判断两个 map 是否逻辑相等呢?
我们可以自定义函数来遍历比较每个键值对,比如下面的 mapEqual 函数:
func mapEqual(m1, m2 map[string]int) bool {
if len(m1) != len(m2) { // 检查两个map的键值对数量是否相等
return false
}
for k, v1 := range m1 {
if v2, ok := m2[k]; !ok || v1 != v2 { // 检查 key 存在性和 value 相等性
return false
}
}
return true
}
Go 1.21 版本在标准库中增加了 maps 包,其中提供的 Equal 和 EqualFunc 两个泛型函数可以用来实现对任意类型的 map 的比较,比如下面这个示例:
package main
import (
"fmt"
"maps"
"strings"
)
func main() {
m1 := map[int]string{
1: "one",
10: "Ten",
1000: "THOUSAND",
}
m2 := map[int]string{
1: "one",
10: "Ten",
1000: "THOUSAND",
}
fmt.Println(maps.Equal(m1, m2))
m3 := map[int]string{
1: "one",
10: "Ten",
1000: "THOUSAND",
}
m4 := map[int][]byte{
1: []byte("One"),
10: []byte("Ten"),
1000: []byte("Thousand"),
}
eq := maps.EqualFunc(m3, m4, func(v1 string, v2 []byte) bool {
return strings.ToLower(v1) == strings.ToLower(string(v2))
})
fmt.Println(eq)
}
显然, 我们推荐使用 maps 包提供的函数对 map 进行比较。
性能优化:预估容量,减少扩容
map 的扩容(rehash)是其主要性能开销之一。当 map 中元素数量超过容量 × 加载因子(Go 中加载因子约为 6.5)时,就会触发扩容。扩容需要分配更大的内存,并将所有键值对重新计算哈希并迁移到新表中。
如果能在创建 map 时预估其最终大致会存储多少元素,可以通过 make 指定容量提示(capacity hint)。
// 预估最多会存 1000 个元素
m := make(map[string]MyType, 1000)
这会让 Go 运行时尝试分配一个足够容纳约 1000 个元素的底层哈希表(实际容量通常是接近的 2 的幂次方)。这样做可以显著减少甚至避免后续插入元素时触发的扩容次数,从而提升性能,尤其是在需要一次性插入大量元素的场景。
不过要注意:这只是一个提示,不是硬性限制。即使指定了容量,map 仍然可以在需要时自动扩容。
到这里,我们已经了解了 map 的一些高级用法和潜在的陷阱,包括并发安全、键值类型的限制以及性能优化技巧。那么,在实际应用中,我们应该如何选择合适的数据结构呢?
map 固然强大,但并非万能。接下来,我们将探讨 map 的适用场景、局限性,以及与其他数据结构的比较,帮助你在不同场景下做出最佳选择。
场景辨析:何时选择 Map,何时另寻他路?
Map 的核心优势在于快速键值查找(O(1) 平均)。因此,它最适用于:
- 按唯一标识符查找数据:如根据用户 ID 查找用户信息
map[UserID]UserInfo。 - 建立数据关联:如将订单 ID 映射到订单详情
map[OrderID]*Order。 - 缓存:缓存计算结果或常用数据,用输入参数或唯一键作 key。
- 集合(Set)实现:利用
map[KeyType]struct{}或map[KeyType]bool来存储一组唯一的元素,快速检查元素是否存在。struct{}是空结构体,不占内存,作 value 最优。 - 计数器:如统计单词频率
map[string]int。
Map 不适合的场景:
- 需要有序遍历:Map 遍历顺序随机。如果需要按插入顺序或键的排序顺序访问,应使用切片(slice),可能配合排序。
- 数据量小且固定:如果键值对数量很少且固定,直接使用数组(array)或结构体(struct)可能更简单、性能更好(无哈希计算和指针开销)。
- 频繁插入删除,查找次要:如果主要操作是不断添加和移除元素,对查找速度要求不高,简单的切片或链表(需自己实现或用库)可能更合适,避免哈希冲突和 rehash 开销。
选择数据结构时,要根据具体的操作需求(查找、插入、删除、遍历、排序的频率和性能要求)来权衡。
通过前面的讨论,我们已经对 map 的用法、特性、适用场景和局限性有了全面的了解。为了更深入地理解 map 的性能表现和行为特征,我们还可以从底层实现的角度进行探究。
接下来,我们将简要介绍 map 的底层数据结构——哈希表,以及 Go 语言中 map 实现的一些关键技术细节。请注意,这部分内容为可选阅读,旨在帮助你建立更深入的理解,不影响 map 的日常使用。
底层速览:新旧 map 实现的对比
为了更好地理解 map 的性能特点和使用限制,我们可以简单了解一下 map 的底层实现原理。
哈希表的基本原理
Go map 的底层实现是哈希表(hash table)。哈希表是一种通过哈希函数将键映射到值的数据结构。
-
哈希函数:将任意大小的键转换为固定大小的哈希值(hash code)。
-
哈希桶:哈希表中的一个存储单元,用于存储哈希值相同的键值对。
-
冲突解决:当不同的键具有相同的哈希值时,会发生哈希冲突。常见的冲突解决方式有:
- 链地址法(chaining):将哈希值相同的键值对存储在同一个链表中。
- 开放地址法(open addressing):当发生冲突时,探测哈希表中的下一个可用位置。
Go map 的扩容机制:加载因子、渐进式扩容
我的《 Go语言第一课》专栏中有关于 Go 1.24 之前 map 实现的说明,这里再用一幅示意图简要说明一下:
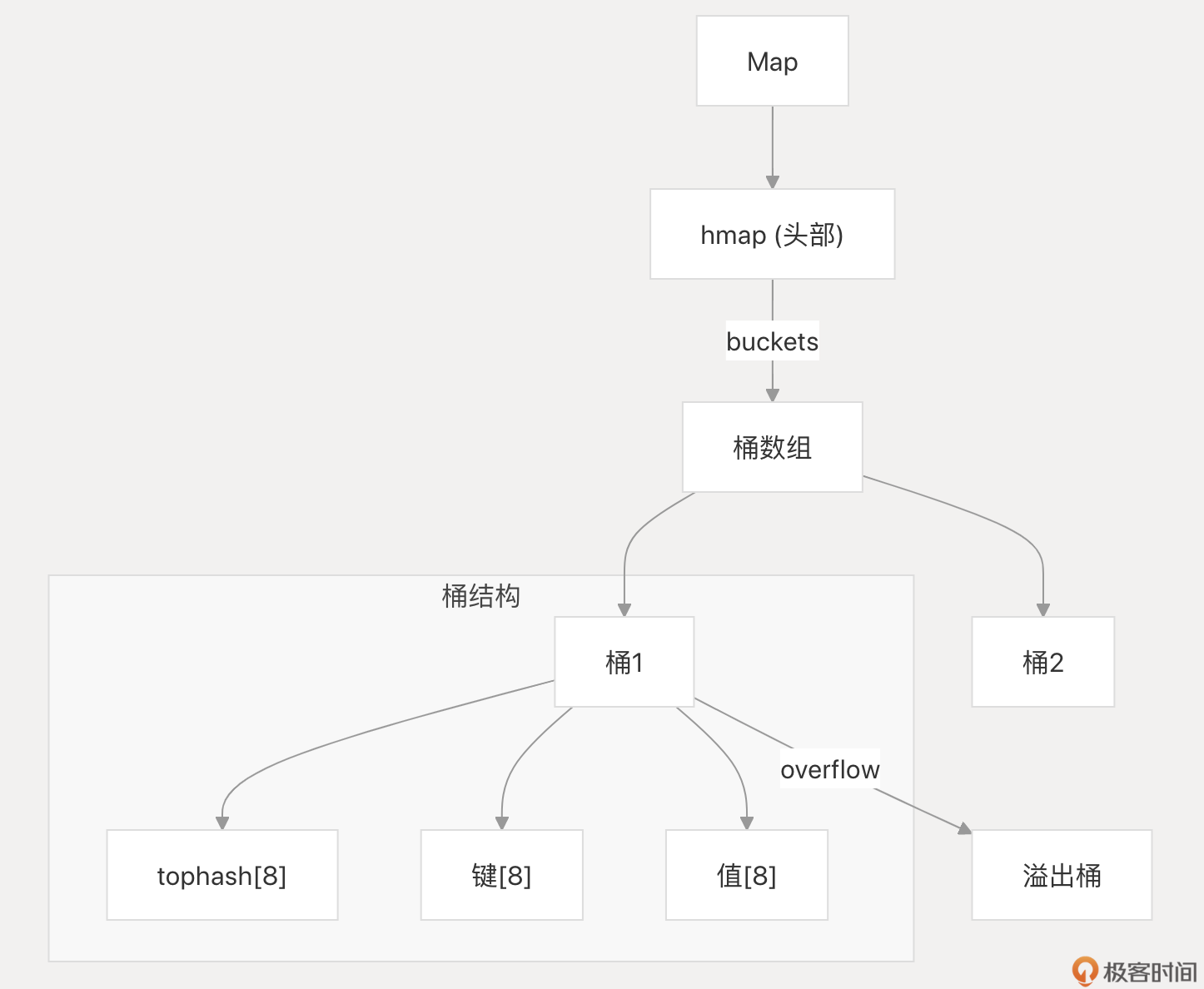
我们看到 Go 的老版 map 实现使用桶(bucket)数组存储键值对,并使用链地址法解决哈希冲突。每个哈希桶(暂称为正常桶)可以存储一定数量的哈希值相同的键值对。当哈希表中存储的数据过多,单个桶已经装满时就会使用溢出桶,溢出桶若再满了,还会创建新的溢出桶。这些桶通过末尾的 overflow 指针连接成一条链。
当 map 中的键值对数量达到容量的某个比例(装载因子,load factor)时, map 会自动扩容。Go map 早期的装载因子是 6.5。其扩容过程的步骤大致如下:
- 创建一个新的哈希表,大小是原哈希表的两倍。
- 将原哈希表中的键值对重新散列到新的哈希表中。
- 释放原哈希表的内存。
为了避免一次性迁移所有键值对导致的性能抖动,Go map 采用了渐进式扩容,即在插入值和删除值的操作过程中伴随实施扩容操作。在扩容过程中, map 会同时使用新旧两个哈希表,新的键值对会被插入到新的哈希表中,而旧的键值对会逐渐迁移到新的哈希表中。
新旧版本 map 实现的差异:Swiss Table 的引入
Go 语言的 map 实现在不断演进,以追求更高的性能和更低的内存占用。Go 1.24 版本引入了一项重大改进:基于 Swiss Table 的全新 map 实现。
Swiss Table 是 Google 于 2017 年提出的一种新型哈希表设计,并在 2018 年开源于 Abseil C++ 库中。它是一种开放寻址哈希表,通过优化探测序列和利用 SIMD(单指令多数据)指令,实现了比传统哈希表更快的查找、插入和删除速度。 Go 1.24 的 map 实现借鉴了 Swiss Table 的核心思想,但针对 Go 的特性做了特殊优化。下面是新 map 实现的示意图:
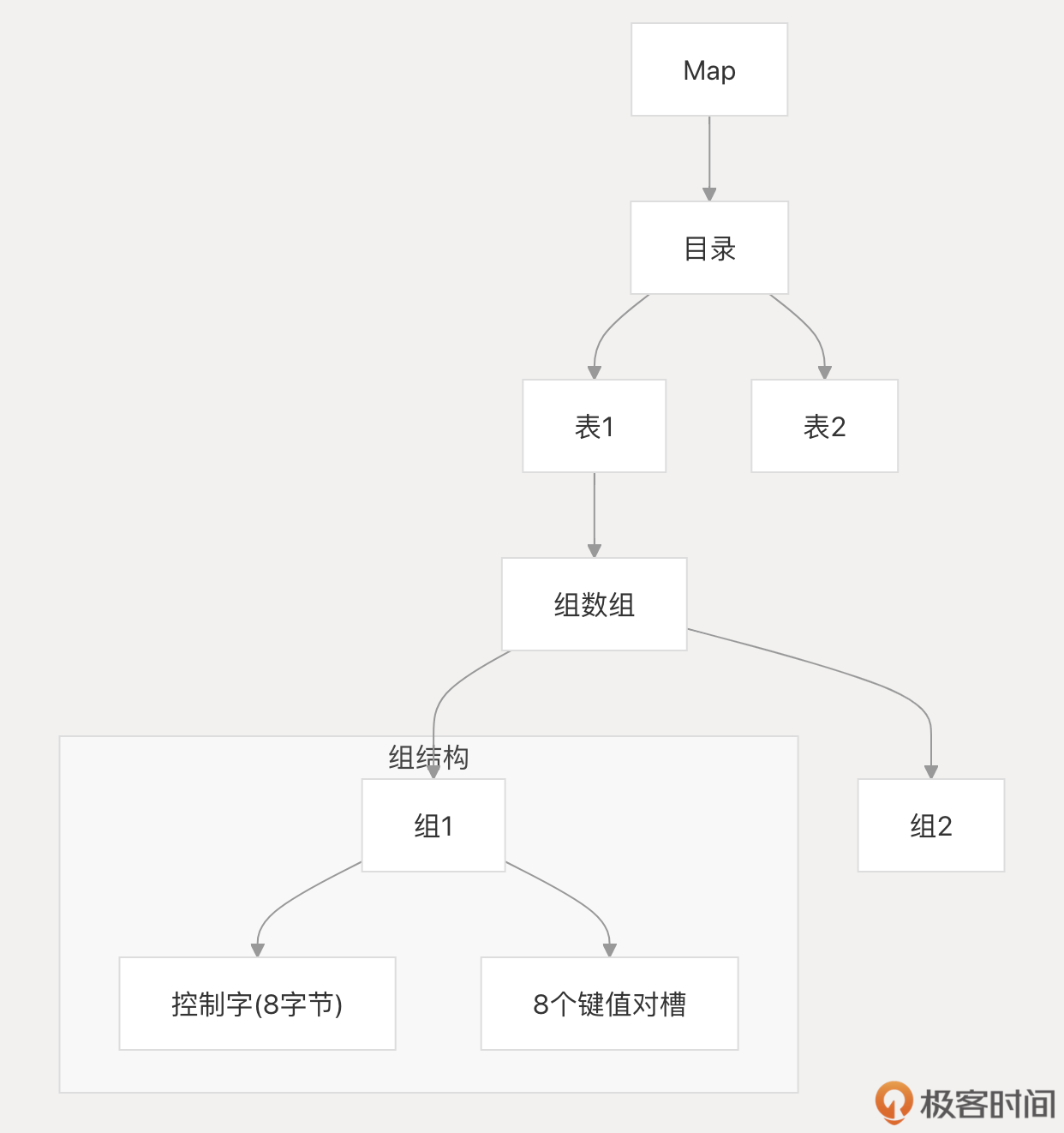
从图中我们看到新 map 实现的一些特点。
-
分组与控制字
a. Go map 将底层数组划分为多个逻辑组(group)(即图中的组数组),每个组包含 8 个槽位(slot)。
b. 每个组都有一个 64 位的控制字(control word),用于记录组内每个槽位的状态(空、已删除、已占用)以及已占用槽位中键的哈希值的低 7 位(h2)。
-
哈希值拆分
a. 计算键的哈希值
hash(key)。b. 将哈希值拆分为两部分:高 57 位(h1)和低 7 位(h2)。
c. h1 用于确定键所属的组,h2 用于在组内快速查找。
-
快速查找
a. 根据 h1 定位到组。
b. 利用控制字和 SIMD 指令(或等效的位运算),并行比较组内所有槽位的 h2 与目标键的 h2。
c. 如果 h2 匹配,再比较完整的键,以处理哈希冲突。
d. 如果 h2 不匹配或键不相等,则继续探测下一个组。
-
渐进式扩容
a. Go map 仍然采用增量扩容的方式来避免单次操作的巨大延迟。
b. 为了适应增量扩容,一个 map 被拆成多个独立的 Swiss Table,并使用目录(Directory)来管理这些表(如上图)。
c. 单个 table 的最大容量为 1024 个条目。
d. 在插入时,如果单个表需要扩容,它将一次性完成,但其他表不受影响。
-
迭代时修改
a. Go 语言规范允许在迭代
map时修改map。b. Go map 通过维护迭代器引用的旧表快照来实现这一特性,确保迭代顺序不受扩容影响。
c. 在返回元素前,会检查元素在新表中是否存在以及值是否被更新。
新实现具体以下优势:
- 更高的查找性能:通过分组、控制字和 SIMD 指令,减少了平均探测次数。
- 更高的加载因子:优化后的探测行为允许更高的加载因子(load factor),降低了平均内存占用。
- 更低的插入延迟:渐进式扩容将单次插入的最坏情况延迟限制在较小范围内。
Go 1.24 的 map 实现通过引入 Swiss Table 设计,显著提升了 map 的性能和效率。这一改进体现了 Go 语言对底层数据结构持续优化的承诺,也为开发者提供了更强大的工具来构建高性能应用。尽管具体的实现细节可能随版本迭代而变化,但理解这些基本原理有助于我们更好地利用 map 的特性,避免常见的性能陷阱。
小结
这一讲,我们深入探讨了 Go 语言的基石之一 —— map。我们不仅回顾了它的基本用法,更关键的是,揭示了它高效背后的机制,以及使用时必须注意的陷阱和优化点。
- 核心优势:基于哈希表,提供平均 O(1) 的键值查找、插入、删除效率。
- 基础操作:掌握
make/字面量创建、CRUD 操作(注意 comma ok)、for range遍历(随机顺序)、nilmap 与空 map 的区别。 - 并发安全:原生 map 非并发安全。需使用
sync.Mutex,sync.RWMutex或sync.Map(根据读写模式和场景选择)。 - 键值约束:Key 必须可比较;Value 不可寻址(修改需取出或用指针)。
- 比较:Map 不可用
==比较,需手动或用maps.Equal/maps.EqualFunc。 - 性能优化:通过
make预分配容量可显著减少扩容开销。 - 适用场景:快速查找、数据关联、缓存、集合模拟是强项;不适用于需要有序或频繁增删且查找次要的场景。
- 底层启示:哈希冲突、扩容开销、元素移动解释了性能特点和部分使用限制。
Map 功能强大,但理解其特性、遵循最佳实践至关重要。掌握了这些,你就能在 Go 程序中自信、高效、安全地使用 map 了。
思考题
假设你需要实现一个本地内存缓存,用于存储用户 ID(int)到用户信息 (一个较大的 struct UserInfo) 的映射。这个缓存会被多个 goroutine 并发访问,读操作非常频繁,写操作(新增或更新用户信息)相对较少。
你会选择哪种方案来实现这个并发安全的缓存?并简述你的理由。
- 原生
map[int]UserInfo+sync.Mutex - 原生
map[int]*UserInfo+sync.Mutex(UserInfo 使用指针) - 原生
map[int]UserInfo+sync.RWMutex - 原生
map[int]*UserInfo+sync.RWMutex sync.Map(存储UserInfo或*UserInfo)
欢迎在留言区分享你的选择和权衡过程!我是 Tony Bai,我们下节课见。
函数与方法:理解Go面向对象的不同方式,何时选择其一?
你好,我是 Tony Bai。
经过前面几讲对 Go 数据类型的强化学习,我们现在转向探讨类型的“行为”部分。在 Go 语言中,封装和复用代码的主要手段就是函数(function)和方法(method)。
你可能已经注意到, Go 中的函数和方法在形式上非常相似,甚至可以说,Go 在设计时有意模糊了两者的界限。这并非疏忽,而是一种深思熟虑的选择,旨在:
- 简化类型系统。
- 提供更大的灵活性。
- 鼓励使用组合而非继承来实现代码复用和多态。
这与 Go 整体简洁、正交的设计哲学一脉相承。
但这种相似性也可能带来困惑:它们到底有什么本质区别?仅仅是语法上多了一个“接收者”吗?在实际开发中,我应该将一段逻辑实现为函数,还是某个类型的方法?错误的选择会带来什么后果?
不理解函数与方法的本质区别和适用场景,可能会让你写出不够“地道”的 Go 代码,甚至在面对接口实现、状态修改、代码组织等问题时做出次优的设计决策。
这节课,我们就来深入辨析 Go 中的函数与方法。我将带你:
- 理解函数作为“一等公民”的含义及其应用。
- 掌握方法的本质——为类型绑定行为,并重点区分“值接收者”和“指针接收者”的差异与影响。
- 明确在不同场景下,选择函数还是方法的判断依据。
下面先让我们一起走进函数的世界。
函数:Go 中的一等公民与代码复用
函数,简单来说,就是一段封装了特定功能的、可以被重复使用的代码块。它接收输入(参数),执行一系列操作,并可能返回输出(返回值)。函数是模块化编程的基础,能极大地提高代码的可读性和复用性。
在 Go 语言中,函数不仅仅是代码行为的组织单元之一,它还有着特殊的地位——函数是“一等公民(First-Class Citizen)”。这意味着什么呢?意味着函数和其他普通的数据类型(如 int、string、struct)一样,拥有同等的权利:
- 可以被赋值给变量。
- 可以作为参数传递给其他函数(高阶函数)。
- 可以作为另一个函数的返回值。
- 可以存储在数据结构中(如切片、map)。
函数的声明与调用
我们使用 func 关键字来声明一个函数:
func 函数名(参数列表) (返回值列表) {
// 函数体:实现功能的代码
return 返回值 // 如果有返回值
}
例如,一个简单的加法函数:
func add(a int, b int) int { // 参数a, b都是int类型,返回值是int类型
result := a + b
return result
}
调用函数很简单,使用函数名加上括号和实际参数:
sum := add(5, 3) // 调用add函数,将结果8赋值给sum
fmt.Println(sum)
函数的本质:函数类型
从 Go 的类型系统角度看,每个函数都有其特定的函数类型。这个类型由函数的参数类型列表和返回值类型列表共同决定(函数名本身不属于类型的一部分)。
上面的 add 函数,它的类型就是 func(int, int) int。
我们可以像声明普通变量一样,用函数字面量(匿名函数)来声明一个函数类型的变量:
var myAdd func(int, int) int // 声明一个函数类型的变量myAdd
myAdd = func(x int, y int) int { // 将一个匿名函数赋值给myAdd
return x + y
}
sum := myAdd(10, 20) // 通过变量调用函数
fmt.Println(sum) // 输出 30
这清晰地展示了函数作为“值”的特性。 func myAdd(...) {...} 这种常见的函数声明,本质上就是声明了一个名为 myAdd 的变量,其类型是函数类型,其值是函数体定义的那个函数。
函数的参数与返回值
Go 函数的设计在参数和返回值方面相当灵活。
- 类型简写:如果连续多个参数类型相同,可以只在最后一个参数后写类型。
func process(id string, count, limit int, verbose bool) { /* ... */ }
// count 和 limit 都是 int 类型
- 多返回值:函数可以返回多个值,非常方便,例如函数可以同时返回结果和错误状态。
// 返回商和余数
func divide(dividend, divisor int) (int, int, error) {
if divisor == 0 {
return 0, 0, fmt.Errorf("division by zero")
}
quotient := dividend / divisor
remainder := dividend % divisor
return quotient, remainder, nil // 返回三个值
}
q, r, err := divide(10, 3)
if err == nil {
fmt.Printf("Quotient: %d, Remainder: %d\n", q, r) // 输出 3, 1
}
// 如果只关心部分返回值,可以用空白标识符 _ 忽略
q, _, err := divide(10, 0)
if err != nil {
fmt.Println("Error:", err)
}
- 具名返回值(Named Return Values):可以给返回值命名。它们就像在函数顶部预先声明的变量,默认值为其类型的零值。在函数体内可以直接给它们赋值,最后的
return语句可以省略操作数,它会自动返回这些命名变量的当前值,这也称为“裸 return”。
func divideNamed(dividend, divisor int) (quotient int, remainder int, err error) {
if divisor == 0 {
err = fmt.Errorf("division by zero")
// 此时 quotient 和 remainder 保持它们的零值 0
return // 裸 return,返回 quotient(0), remainder(0), err(非nil)
}
quotient = dividend / divisor
remainder = dividend % divisor
// 此时 err 保持其零值 nil
return // 裸 return,返回计算后的 quotient, remainder, 和 nil error
}
注意:具名返回值虽然有时能让代码更简洁(尤其在涉及 defer 修改返回值时),但也可能降低可读性。过度使用 return 可能让函数实际返回的值不够清晰。建议谨慎使用,明确的 return value1,value2 通常更易理解。
- 可变参数(Variadic Parameters):函数可以接受不定数量的同类型参数。可变参数必须是函数签名中的最后一个参数,类型前加
...。在函数内部,可变参数表现为一个该类型的切片。
func sumAll(numbers ...int) int { // numbers 是一个 []int 切片
total := 0
for _, num := range numbers {
total += num
}
return total
}
fmt.Println(sumAll(1, 2, 3)) // 输出 6
fmt.Println(sumAll(5, 10, 15, 20)) // 输出 50
// 也可以将一个切片展开传入可变参数
nums := []int{10, 20, 30}
fmt.Println(sumAll(nums...)) // 输出 60 (注意切片后的 ...)
匿名函数与闭包
Go 支持匿名函数,即没有名字的函数。它们可以直接定义并赋值给变量,或者直接作为参数传递。
// 直接调用匿名函数
result := func(a, b int) int {
return a + b
}(5, 3) // 定义后立即调用
fmt.Println(result) // 输出 8
匿名函数最强大的能力在于它可以形成 闭包(closure)。闭包是指一个函数值,它引用了其函数体之外的变量。简单来说,闭包 = 函数 + 其引用的外部环境。
func sequenceGenerator() func() int {
i := 0 // 这个 i 被下面的匿名函数引用了
return func() int { // 返回一个匿名函数(闭包)
i += 1
return i // 每次调用都访问并修改同一个 i
}
}
func main() {
nextInt := sequenceGenerator() // nextInt 现在是一个闭包
fmt.Println(nextInt()) // 输出 1
fmt.Println(nextInt()) // 输出 2
fmt.Println(nextInt()) // 输出 3
newInts := sequenceGenerator() // newInts 是另一个闭包,有自己的 i
fmt.Println(newInts()) // 输出 1
}
在这个例子中, sequenceGenerator 返回的匿名函数“捕获”了它外部的变量 i。即使 sequenceGenerator 函数执行完毕,只要返回的闭包 nextInt 或 newInts 还存在,它们所引用的那个 i 变量也会一直存在。每个闭包实例都有自己独立的环境。
闭包在 Go 中非常常用,例如实现计数器、生成器、事件处理回调、goroutine 传参等。理解闭包对于掌握 Go 的函数式编程特性和并发编程至关重要。
方法:为类型附加行为
看完了独立的函数,我们再来看与类型紧密关联的 方法(method)。
方法是与特定类型关联的函数。在 Go 语言中,我们可以为自定义类型定义方法。这里的自定义类型包括:
- 使用
type关键字定义的类型(如结构体、自定义的整型、自定义的字符串类型等)。 - 基于已存在类型创建的类型别名(type alias)( 注意:类型别名和原类型共享底层类型和方法集)。
但需要注意的是:
- 我们不能直接为内置类型(如
int、string、float64等)定义方法。 - 我们不能跨越包的边界为外部包中定义的类型声明方法。
需要强调的是,Go 语言虽然支持面向对象编程的某些特性(如通过方法实现数据和行为的封装), 但它并不是一种典型的面向对象(OO)语言。 Go 并没有类、继承、虚函数等传统面向对象语言的典型特征。
相比于传统的基于继承的类型层次结构,Go 更倾向于使用组合(Composition)来组织代码。Go 鼓励通过将小的、独立的类型组合成更大的、更复杂的类型,而不是通过继承来构建类型体系。
这种设计哲学使得 Go 代码更灵活、更易于维护和扩展。因此,过度的、传统的 OOP 风格在 Go 语言中往往不是最佳实践。
方法的声明与调用
方法的声明与函数类似,但在 func 关键字和方法名之间,多了一个 接收者(receiver) 的声明:
func (接收者变量 接收者类型) 方法名(参数列表) (返回值列表) {
// 方法体,可以使用接收者变量访问类型的数据
}
- 接收者类型:必须是当前包内定义的某个类型
T或其指针*T(不能是接口、指针本身或内置类型)。 - 接收者变量:方法体内用来指代调用该方法的那个类型实例。
下面我们看一个为 Point 结构体定义一个计算距离的方法的示例:
import "math"
type Point struct {
X, Y float64
}
// Distance 是 Point 类型的一个方法
// p 是接收者变量,类型是 Point (值接收者)
func (p Point) Distance(q Point) float64 {
// 方法体内可以通过 p 访问 Point 实例的 X 和 Y 字段
dx := p.X - q.X
dy := p.Y - q.Y
return math.Sqrt(dx*dx + dy*dy)
}
从本质上讲,Go 语言中的方法就是一种特殊的函数,它的特别之处在于:
- 隐式的第一个参数: 方法的接收者实际上是作为隐式的第一个参数传递给方法的。在上面的
Distance方法中,p就是隐式的第一个参数。 - 类型绑定: 方法与特定的类型绑定。这意味着,方法只能通过该类型或该类型的指针来调用。
- 方法名作用域: 虽然 Go 规范中并没有显式说明,但方法名和函数名一样,都是包级作用域,不同的是函数可以被直接调用,而方法则需要通过其关联的接收者类型的实例或指针进行间接调用。这意味着不同的类型可以拥有相同名称的方法而不会冲突。例如,类型 TypeA 和类型 TypeB 可以各自拥有名为 String 的方法。只有通过具体的类型实例(或类型指针的实例)才能确定调用的是哪个 String 方法。
方法的调用是通过接收者来实现的:
p := Point{3, 4}
q := Point{0, 0}
distance := p.Distance(q) // 调用 Point 类型的方法 Distance
fmt.Println(distance) // 输出 5
在这个例子中,我们创建了两个 Point 类型的变量 p 和 q,并通过 p 来调用 Distance 方法。
如前所述,方法的接收者是作为第一个参数隐式传递给方法的。在上面的例子中, p.Distance(q) 实际上等价于 Point.Distance(p, q)(注意:这种写法也叫方法表达式,在本节课后面会详细讲解)。
此外,在包外,导出的方法名不会受限于其关联的类型是否为导出的,即便其关联类型并非导出的,我们也可以调用其导出的方法,比如下面示例:
u := mypkg.NewUnexportedType() // 通过工厂函数获得实例(但无法显式声明u的类型)
result := u.ExportedMethod() // 调用未导出类型的导出方法
通过将方法与类型绑定,Go 语言实现了数据和行为的封装。 这使得我们可以像操作对象一样操作自定义类型的值,使代码更具表达力和可读性。
值接收者 vs 指针接收者
在声明方法时,接收者的类型可以设置为值类型 T 或指针类型 *T。这两类接收者在使用上有一些区别。但无论选择哪种方式,接收者的基类型 T(Base Type)都必须满足以下条件:
- 必须是自定义类型: 接收者的基类型不能是内置类型(如
int、string等),不能是指针类型,也不能是接口类型(interface)。 - 不能是(多层)指针类型: 接收者类型可以直接为类型
T的指针,比如*T。但不能是多层指针,例如**T。 - 类型定义必须在同一个包内: 定义方法的类型和方法的声明必须在同一个包内。
在此基础上,我们可以选择使用值接收者或指针接收者。
当接收者是一个值类型时,方法内部会对接收者的副本进行操作,而不是直接操作原始的接收者。
type Point struct {
X, Y float64
}
func (p Point) MoveTo(x, y float64) {
p.X = x
p.Y = y
}
func main() {
p := Point{3, 4}
p.MoveTo(0, 0)
fmt.Println(p) // 输出 {3, 4},p 的值没有改变
}
在这个例子中, MoveTo 方法的接收者是一个值类型 Point。在方法内部,我们修改了 p 的 X 和 Y 字段,但这个修改并不会影响到原始的 p 变量,因为方法内部操作的是 p 的副本。
当接收者是一个指针类型时,方法内部可以通过指针直接操作原始的接收者。
type Point struct {
X, Y float64
}
func (p *Point) MoveTo(x, y float64) {
p.X = x
p.Y = y
}
func main() {
p := Point{3, 4}
p.MoveTo(0, 0)
fmt.Println(p) // 输出 {0, 0},p 的值被修改了
}
在这个例子中, MoveTo 方法的接收者是一个指针类型 *Point。在方法内部,我们通过指针 p 修改了原始的 Point 变量的值。
需要注意的是,无论方法的接收者是一个指针类型,还是值类型,我们既可以使用指针类型的变量来调用方法,也可以使用值类型的变量来调用方法。Go 语言的编译器会自动进行取地址或解引用的操作:
p := Point{3, 4}
p.MoveTo(0, 0) // 值类型的变量可以直接调用指针接收者的方法
q := &Point{3, 4}
q.MoveTo(0, 0) // 指针类型的变量可以调用指针接收者的方法
那么,我们该如何选择接收者类型呢?
在定义方法时,我们需要根据实际情况选择合适的接收者类型。通常情况下,可以遵循以下几个原则:
-
如果方法需要修改接收者的值,应该使用指针接收者。值接收者操作的是接收者的副本,无法修改原始值。
-
如果接收者是一个大型的对象(如大型结构体),使用指针接收者可以避免每次方法调用时都进行对象拷贝,提高性能。
-
如果接收者类型中包含接口类型字段,且当值接收者的方法内部调用了该接口类型字段的方法时,编译器无法在编译时完全确定该方法的具体实现是否会导致值接收者副本或其内部字段的地址以某种方式“逃逸”出去,即在方法返回后仍被引用。
为了内存安全,编译器在这种不确定的情况下,可能会采取保守策略,在堆上分配这个副本,而不是在通常更快的栈上。堆分配会带来额外的性能开销(分配本身和后续的垃圾回收)。
使用指针接收者通常可以避免接收者本身因为这种接口方法调用而逃逸到堆上,因为传递的是指针,编译器更容易追踪其生命周期。
-
如果类型需要实现某个接口,要注意该类型的方法集。
a. 类型
T的方法集仅包含所有 receiver 为T的方法。b. 类型
*T的方法集包含了所有 receiver 为T和*T的方法。c. 因此如果接口中定义的方法,只有 receiver 为
*T的方法才实现了该接口,那么类型T的实例将不能赋值给该接口变量,而类型*T的实例则可以。 -
如果你不确定使用哪种类型的接收者,建议使用指针接收者,因为指针接收者更通用,可以覆盖更多的场景。
这里提到了影响接口实现与否的一个重要概念:方法集(method set),到底什么是方法集呢?下面我们来详细说明一下。
方法集
每个类型都有一个与之关联的方法集,方法集定义了该类型可以调用的所有方法的集合。
对于类型 T,它的方法集包含所有接收者类型为 T 的方法。而对于类型 *T,它的方法集既包含所有接收者类型为 *T 的方法,也包含所有接收者类型为 T 的方法。
下面是一个示例:
type T struct{}
func (t T) M1() {}
func (t *T) M2() {}
func main() {
var t T
var pt *T = &t
t.M1() // ok,T 类型的方法集中包含 M1
t.M2() // ok,*T 类型的方法集中包含 M2,Go 自动将 t 转换为 &t
pt.M1() // ok,*T 类型的方法集中包含 M1
pt.M2() // ok,*T 类型的方法集中包含 M2
}
在这个例子中,类型 T 的方法集只包含 M1 方法,类型 *T 的方法集包含 M1 和 M2 两个方法。
方法集在 Go 语言的接口和类型断言中起着重要的作用。一个类型只有实现了接口中定义的所有方法,才能认为该类型实现了该接口。在进行类型断言时,也需要考虑方法集的规则。
在 Go 语言中,除了通过类型变量或指针调用方法外,方法也可以像函数一样被赋值给变量,或者作为参数传递给其他函数。这种特性称为方法值(method value),我们也可以直接通过类型调用方法,这种称为方法表达式(method expression)。下面我们来详细看看这两个特性的用法。
方法值与方法表达式
方法值是一个绑定了特定接收者实例的函数值。当我们通过一个接收者调用方法时,可以不立即传入参数,而是先将方法赋值给一个变量,稍后再通过这个变量来调用方法。
type Point struct {
X, Y float64
}
func (p Point) Add(q Point) Point {
return Point{p.X + q.X, p.Y + q.Y}
}
func main() {
p := Point{1, 2}
add := p.Add // 方法值,将 p.Add 赋值给 add 变量
fmt.Println(add(Point{3, 4})) // 通过 add 变量调用方法,输出 {4, 6}
}
在这个例子中, p.Add 就是一个方法值,它将 Add 方法绑定到了接收者 p 上。 add 变量的类型是 func(Point) Point,它是一个函数类型。
方法值实际上是一个闭包,它保存了接收者的值和方法的地址。当我们通过方法值调用方法时,Go 语言内部会将接收者作为第一个参数传递给方法。
方法表达式(method expression)是一种通过类型来调用方法的语法。它可以将方法转换为一个普通的函数,该函数的第一个参数是方法的接收者。
type Point struct {
X, Y float64
}
func (p Point) Add(q Point) Point {
return Point{p.X + q.X, p.Y + q.Y}
}
func main() {
p := Point{1, 2}
add := Point.Add // 方法表达式,将 Point 类型的 Add 方法赋值给 add 变量
fmt.Println(add(p, Point{3, 4})) // 通过 add 变量调用方法,输出 {4, 6}
}
在这个例子中, Point.Add 就是一个方法表达式,它表示 Point 类型的 Add 方法。 add 变量的类型是 func(Point, Point) Point,它是一个函数类型。
设计抉择:何时定义函数,何时定义方法?
理解了函数和方法的区别后,我们回到最初的问题:何时用函数,何时用方法?
核心判断依据是: 这个操作是与某个特定类型的数据紧密相关,还是一个更通用的、独立的操作。
-
优先考虑方法,如果:
a. 操作需要访问或修改该特定类型实例的内部状态(字段)。这是最主要的原因。
b. 操作逻辑上属于该类型的核心职责或行为。例如,
File类型的Read,Write,Close方法。c. 希望该类型实现某个接口,接口定义了该操作。
d. 你想利用面向对象的封装特性,将数据和操作绑定在一起。
-
优先选择函数,如果:
a. 操作是通用的,可以应用于多种类型,或者不依赖于任何特定类型的状态。例如,标准库中的
sort.Strings,fmt.Println,math.Abs等。b. 操作逻辑上不属于任何单一类型的职责,更像是一个工具函数或辅助函数。
c. 你想实现纯粹的函数式编程风格。
d. 操作需要处理多个不同类型的主要对象,将其定义为某个单一类型的方法会显得不自然。例如,
diff(obj1, obj2)可能比obj1.Diff(obj2)更合适。
抉择前,你可以做一个简单的自问:这个功能是 T 类型“应该能做”的事情,还是一个“可以对 T 类型做”的事情? 前者倾向于方法,后者倾向于函数。
例如,“计算一个 Rectangle 的面积”显然是 Rectangle 应该能做的事,适合用方法 rect.Area()。而“将两个 Rectangle 按面积排序”是一个可以对 Rectangle 做的通用操作,更适合用函数 sortRectanglesByArea(rects []Rectangle)。
小结
这一讲,我们辨析了 Go 语言中函数和方法的异同与选择:
- 函数是“一等公民”:可以赋值、传递、返回,是灵活的代码组织单元。理解其类型、参数(含可变)、返回值(含具名)、匿名函数和闭包是基础。
- 方法是与类型绑定的函数:通过接收者将行为附加到特定类型上,实现了类似面向对象的封装。理解其本质(带隐式接收者参数的函数)很重要。
- 值接收者 vs 指针接收者:核心区别在于方法内部操作的是副本还是原始实例。选择依据包括是否修改状态、性能开销(大对象拷贝)、潜在的堆分配以及接口实现(方法集规则)。通常指针接收者更常用和推荐。
- 方法集:决定了类型
T和*T分别能调用哪些方法,以及它们能满足哪些接口。*T的方法集包含T的方法集。 - 方法值与方法表达式:提供了将方法作为函数值使用的两种方式。
- 设计抉择:根据操作与类型的关联紧密程度、是否需要访问内部状态、是否属于核心职责、以及是否满足接口来决定使用函数还是方法。
Go 语言通过这种函数与方法的灵活设计,鼓励开发者编写清晰、可复用、易于组合的代码。理解它们的差异和适用场景,是写出地道、高质量 Go 代码的关键一步。
思考题
假设你正在为一个图形库编写代码,定义了一个 Circle 结构体:
type Circle struct {
Radius float64
}
现在你需要实现两个功能:
- 计算圆的面积。
- 比较两个圆的大小(基于半径)。
你会将这两个功能分别实现为函数还是 Circle 类型的方法?为什么?请给出你的函数/方法签名。
欢迎在留言区分享你的设计和理由!我是 Tony Bai,我们下节课见。
结构体与接口:掌握Go语言组合优于继承的设计哲学
你好!我是 Tony Bai。
在之前的课程中,我们已经接触了 Go 的基础类型和函数/方法。今天,我们要深入探讨 Go 语言构建复杂程序的两大基石: 结构体(struct)和接口(interface)。
如果你有其他面向对象语言(如Java, C++,Python)的背景,你可能习惯于使用继承(inheritance)来实现代码复用和构建类型层次(比如“is-a”关系)。但你会发现,Go 语言走了一条不同的路——它不支持传统意义上的继承。
这不禁让人疑问:
- 没有继承,Go 如何实现代码复用和多态?
- 为什么 Go 的设计者选择了“组合优于继承”的哲学?组合到底好在哪里?
- 结构体和接口在 Go 的“组合之道”中扮演了怎样的角色?我们又该如何运用它们来构建灵活、可维护的系统?
不理解 Go 的组合哲学,不掌握结构体和接口的精髓, 你就很难真正领会 Go 设计的优雅之处,也难以写出符合 Go 语言习惯、易于扩展和维护的代码。
这节课,我们将一起:
- 快速回顾结构体和接口的核心概念与关键特性。
- 探讨 Go 为何“抛弃”继承,以及组合的核心优势。
- 深入学习如何利用结构体组合、接口组合,以及两者结合的方式,在 Go 中实践组合。
- 明确 Go 如何通过组合模拟继承的部分效果,以及何时选择不同的组合方式。
掌握了这些,你将能更深刻地理解 Go 的设计思想,并运用组合这一利器构建出更优秀的 Go 程序。
快速回顾核心特性
在我们深入探讨组合之前,先快速回顾一下结构体和接口这两个核心概念。
结构体(struct):数据的聚合与载体
结构体是 Go 中用于将不同类型的字段(数据成员)聚合在一起,形成一个自定义数据类型的主要方式。它让我们能够根据现实世界的模型来组织数据。下面是一个典型的结构体定义和初始化方式的示例:
// 定义一个名为Person的结构体
type Person struct {
Name string
Age int
Address string
}
// 1. 按字段顺序初始化
p1 := Person{"Alice", 30, "123 Main St"}
// 2. 使用字段名初始化(推荐,更清晰)
p2 := Person{Age: 25, Name: "Bob", Address: "456 Elm St"}
// 3. 零值初始化 + 逐字段赋值
var p3 Person
p3.Name = "Charlie"
p3.Age = 40
在上面示例中展示了三种初始化结构体的方式,Go 更推荐使用第二种方式: 使用字段名进行初始化。这种方式不需要遵循字段定义的顺序,可以随意排列字段,方便在需要时只初始化部分字段,可以有效避免方式一因字段顺序错误导致的赋值错误。
同时,如果将来结构体添加了新字段,使用字段名初始化的代码无需修改已有的赋值顺序,减少了代码维护的复杂性。并且,未显式初始化的字段会自动使用零值,使用字段名初始化可以更清楚地看到哪些字段被赋值,哪些字段使用了默认值。
Go 结构体的字段在内存中是连续排列的。Go 编译器会进行内存对齐,以提高访问效率。这意味着字段之间可能会有填充(padding)。我们可以通过 unsafe.Sizeof 和 unsafe.Offsetof 函数来查看结构体的大小和字段偏移量:
var p Person
fmt.Println("sizeof Person =", unsafe.Sizeof(p)) // sizeof Person = 40
fmt.Println("Name's offset=", unsafe.Offsetof(p.Name)) // Name's offset= 0
fmt.Println("Age's offset=", unsafe.Offsetof(p.Age)) // Age's offset= 16
fmt.Println("Address's offset=", unsafe.Offsetof(p.Address)) // Address's offset= 24
关于 Go 结构体字段的对齐方法,我在专栏《 Go语言第一课》中有更为全面的说明,感兴趣的小伙伴可以去阅读一下。
结构体还有一个独特的特性:匿名字段。匿名字段是指在结构体中只声明类型而不声明字段名。通过匿名字段,我们可以实现结构体的嵌入(embedding),这是 Go 语言实现组合(composition)的关键。我们看下面示例:
type Contact struct {
Phone string
Email string
}
type Employee struct {
Name string
Age int
Contact // 匿名嵌入Contact 类型
}
在这个例子中,Employee 结构体通过匿名嵌入 Contact 类型,获得了 Contact 的所有字段( Phone 和 Email)。我们可以直接通过 Employee 类型的实例访问这些字段,就好像它们是 Employee 自己的字段一样:
e := Employee{Name: "Eve", Age: 28,
Contact: Contact{Phone: "123-456", Email: "eve@example.com"}}
fmt.Println(e.Phone) // 输出: 123-456
这种“ 字段提升”的特性,使得我们可以非常方便地将一个类型的属性和行为“组合”到另一个类型中。在本讲后面,我们还会详细说明如何利用这一特性实现灵活的组合。
Go 语言支持一种特殊的结构体:空结构体,即 struct{}。空结构体不包含任何字段,因此不占用任何内存空间( unsafe.Sizeof(struct{}{}) 的结果为 0),并且所有空结构体变量的地址都相同:
var es1 = struct{}{}
var es2 = struct{}{}
fmt.Printf("0x%p, 0x%p\n", &es1, &es2) // 0x0x57ffc0, 0x0x57ffc0
空结构体的主要用途包括:
- 实现集合(Set): 利用 map 的键不能重复的特性,可以将 map 的值类型设置为空结构体。
- 通道信号: 作为通道(channel)的元素类型,用于传递信号,而不传递任何数据。
- 仅包含方法的类型: 如果一个类型只需要方法而不需要字段,可以使用空结构体作为接收者。
回顾完结构体类型,我们再看看接口类型。
接口(interface):行为的抽象与契约
接口定义了一组方法的集合(方法签名)。 它描述了对象应该具有什么行为,但不关心这些行为是如何实现的,也不关心对象本身是什么类型。
接口是 Go 实现多态和解耦的关键。 接口(interface)是 Go 语言实现多态性(polymorphism)的关键。下面是在 Go中使用最为频繁的两个接口,来自 io 包的 Reader 和 Writer:
type Reader interface {
Read(p []byte) (n int, err error)
}
type Writer interface {
Write(p []byte) (n int, err error)
}
Go 语言的接口实现是隐式的。 只要一个类型实现了接口中定义的所有方法,它就被认为是实现了该接口,而不需要显式声明。这种方式在业界被称为 Duck Typing:“如果它走起来像鸭子,叫起来像鸭子,那么它就是鸭子”。
下面示例中的 File 类型隐式地实现了上面的 Reader 和 Writer 接口:
type File struct {
// ...
}
func (f *File) Read(p []byte) (n int, err error) { /* ... */ return }
func (f *File) Write(p []byte) (n int, err error) { /* ... */ return }
隐式实现接口带来了极大的灵活性和解耦性:
- 定义与实现分离: 接口的定义和实现可以位于不同的包中。
- 类型无需修改: 我们可以为一个已有的类型实现新的接口,而无需修改该类型的代码。
- 多重实现: 一个类型可以实现多个接口,一个接口也可以被多个类型实现。
那么,这么灵活的接口类型在运行时是如何表示和实现的呢?我们来看看 接口的底层表示。
Go 语言的接口类型在底层有两种表示形式: iface(用于非空接口)和 eface(用于空接口)。下面是这两种形式在 Go 运行时的表示,简单来说,它们都包含两个指针。
iface(非空接口)
type iface struct {
tab *itab // 接口类型和具体类型信息
data unsafe.Pointer // 数据指针
}
其中, tab 是指向一个 itab 结构体的指针, itab 中包含了接口类型和具体类型的信息,以及实现接口的方法的函数指针。 data 也是一个指针,指向的是实际存储数据的内存地址。
eface(空接口)
type eface struct {
_type *_type // 具体类型信息
data unsafe.Pointer // 数据指针
}
其中, _type 指向具体类型的类型信息。 data 指向的是实际存储数据的内存地址。
Go 接口在底层通过 iface 和 eface 结构实现。 iface 用于包含类型信息的接口, eface 用于空接口。它们的核心在于 iface.tab 和 eface._type 分别存储了接口的具体类型和方法信息(对于 iface)以及数据的类型信息。这使得 Go 能够实现动态分派,即在运行时根据实际类型调用相应的方法,从而实现多态。
类型断言也依赖于检查这些类型信息是否与目标类型匹配。 虽然底层实现细节(如 itab 生成、缓存、内存分配)较为复杂。
目前,我们只需理解接口是如何利用这些内部结构来存储类型和方法信息,知道这种存储方式支持动态派发和类型断言功能,就足以满足你进阶之用了。
通过对结构体和接口核心概念及高级特性的回顾,我们已经了解到它们各自的强大之处: 结构体提供了数据聚合与组合的能力,而接口则实现了行为的抽象与多态。
特别是结构体的匿名字段和嵌入机制,为 Go 语言的组合奠定了基础。同时,接口的隐式实现和底层表示,又赋予了 Go 语言极大的灵活性和动态性。正是这些特性,使得 Go 语言能够以一种独特的方式处理代码复用和类型关系的问题。
那么,在拥有了结构体和接口这两大利器之后,Go 语言又是如何看待并处理传统面向对象编程中“继承”这一核心概念的呢?接下来,我们就将深入探讨 Go 语言为何不支持继承,以及它所推崇的组合机制是如何运作的。
Go 语言为何摒弃继承?
在传统的面向对象语言中,继承通常用于表达一种 “is-a” 的关系,即子类“是一个”父类。例如在 Java 中,我们可以定义一个 Animal 类,然后定义一个 Dog 类继承自 Animal 类,这样我们就说 Dog “是一个” Animal。
// Java 代码示例
class Animal {
public void eat() {
System.out.println("Animal is eating");
}
}
class Dog extends Animal {
public void bark() {
System.out.println("Dog is barking");
}
}
在这个例子中, Dog 类继承了 Animal 类的 eat 方法,同时又定义了自己的 bark 方法。这样, Dog 类的实例就同时具有了 eat 和 bark 两种行为。
但 Go 没有 extends 关键字,没有父类子类的概念,也没有 is-a 这样的类型关系。那么,Go 是如何处理类型间关系的呢?
Go 的设计者们认为,传统的类继承机制虽然提供了一种代码复用方式,但也带来了诸多问题,这些问题在大型项目中尤为突出。
- 强耦合:子类与父类的实现细节紧密耦合。父类的内部实现变化可能无意中破坏子类的行为(脆弱基类问题)。子类也可能需要了解父类的实现细节才能正确地覆盖方法。
- 层次僵化:继承关系在编译时就固定下来,形成一个树状结构。现实世界的关系往往更复杂,单一继承难以模拟,而多重继承又会引入“菱形问题”(一个类继承自两个具有共同祖先的类时产生的歧义)。
- 封装性破坏:子类可以访问父类的受保护成员(protected),破坏了父类的封装。
- 臃肿的基类:为了适应各种子类的需求,基类可能变得越来越庞大和复杂。
Go 的设计哲学推崇简洁、清晰、显式。设计者们希望避免继承带来的复杂性和潜在问题,转而寻求一种更灵活、更松耦合的方式来组织代码和实现复用。这个方式就是组合。
那么组合究竟有哪些优势呢?我们下来就来看一下。
组合带来了哪些核心优势?
“组合优于继承(Composition over Inheritance)”是软件设计中一个广为人知的原则,Go 语言将其奉为圭臬。组合的核心思想是: 通过将简单的、功能单一的对象组装在一起来构建更复杂的对象,而不是扩展一个已有的复杂对象。
组合相比继承,主要有以下优势:
- 松耦合:对象之间的关系是通过接口或持有其他对象的实例来建立的,而不是通过继承关系。修改一个对象的内部实现通常不会影响到使用它的其他对象(只要接口不变)。
- 高灵活性:可以在运行时动态地改变对象的组成部分(例如,通过接口注入不同的实现),而继承关系是静态的。组合还可以更容易地混合和匹配来自不同“谱系”的功能。比如下面这个示例就通过接口轻松地将 Walker 和Swimmer 两个“谱系”的动物以及它们的行为混合到一起:
package main
import (
"fmt"
)
// 定义行为接口
type Walker interface {
Walk() string
}
type Swimmer interface {
Swim() string
}
// 定义具体的行为
type Dog struct{}
func (d Dog) Walk() string {
return "Dog is walking."
}
type Fish struct{}
func (f Fish) Swim() string {
return "Fish is swimming."
}
// 组合动物
type Animal struct {
Walker
Swimmer
}
func main() {
// 创建一个动物实例,组合狗和鱼的行为
dog := Dog{}
fish := Fish{}
animal := Animal{
Walker: &dog,
Swimmer: &fish,
}
fmt.Println(animal.Walk()) // 输出: Dog is walking.
fmt.Println(animal.Swim()) // 输出: Fish is swimming.
}
- 更好的封装性:每个对象只负责自己的功能,其内部实现对外部是隐藏的。外部对象只能通过其公开的接口进行交互。
- 避免继承层次问题:没有复杂的继承树,没有多重继承的烦恼。代码结构更扁平、更清晰。
- 更清晰的关系表达(“has-a” vs “is-a”):组合通常表达的是 “has-a”(有一个)或 “uses-a”(使用一个)的关系,这在很多情况下比继承表达的 “is-a”(是一个)关系更贴切、更灵活。
Go 语言通过其类型系统(特别是结构体嵌入和接口)为组合提供了强大的原生支持。下面我们再来看看在 Go 中实践组合的几种方式。
在 Go 中实践组合:结构体嵌入与接口的威力
在 Go 语言中,结构体和接口是实现组合的两种主要方式,我们逐一来看一下。
结构体的组合
结构体的组合是指在一个结构体中嵌入其他类型的字段,从而将这些类型的字段和方法组合到新的结构体中。
type Engine struct {
Type string
Power int
}
// 为 Engine 类型添加一个方法
func (e Engine) Start() {
fmt.Println("Engine", e.Type, "started with power", e.Power)
}
type Car struct {
Engine // 匿名嵌入Engine类型
Brand string
Model string
}
func main() {
c := Car{
Engine: Engine{
Type: "V8",
Power: 300,
},
Brand: "BMW",
Model: "M3",
}
fmt.Println(c.Type) // 输出 V8,直接访问 Engine 的 Type 字段
fmt.Println(c.Power) // 输出 300,直接访问 Engine 的 Power 字段
c.Start() // 输出 Engine V8 started with power 300, 直接调用 Engine 的 Start 方法
}
在这个例子中,我们不仅定义了 Engine 和 Car 两个结构体,并在 Car 中嵌入了 Engine 类型,还为 Engine 类型添加了一个 Start 方法。
通过匿名嵌入 Engine 类型, Car 类型的实例不仅获得了 Engine 的 Type 和 Power 字段,还获得了 Engine 的 Start 方法。我们可以直接通过 c.Start() 来调用这个方法,就像它是 Car 自身的方法一样。这就是 方法提升(Method Promotion),即将 Engine 自身的方法提升到外层类型 Car 中。
通过组合,我们可以将不同的类型组合在一起,创建出更复杂的类型。这种方式比继承更加灵活,因为我们可以自由地选择需要组合的类型,而不是受限于单一的继承链。而且,被嵌入类型的字段和方法也被提升到外层类型,实现了数据与行为的复用。
但是,我们也需要明确一点: 这并不是真正的继承,而只是字段和方法的提升。
接口的组合
接口的组合是指在一个接口中嵌入其他接口,从而将这些接口的方法组合到新的接口中。下面例子中的 ReadWriter 就是一个典型的组合接口(示例代码仅是代码片段):
type Reader interface {
Read(p []byte) (n int, err error)
}
type Writer interface {
Write(p []byte) (n int, err error)
}
type ReadWriter interface {
Reader // 匿名嵌入 Reader 接口
Writer // 匿名嵌入 Writer 接口
}
type File struct {
// ...
}
func (f *File) Read(p []byte) (n int, err error) {
// ...
return
}
func (f *File) Write(p []byte) (n int, err error) {
// ...
return
}
func main() {
var rw ReadWriter = &File{}
var r Reader = rw // ReadWriter 接口可以赋值给 Reader 接口
var w Writer = rw // ReadWriter 接口可以赋值给 Writer 接口
r.Read(...)
w.Write(...)
}
在这个例子中,我们定义了 Reader、 Writer 和 ReadWriter 三个接口。 ReadWriter 接口通过匿名嵌入 Reader 和 Writer 接口,将它们的方法组合在一起。这样, ReadWriter 接口就同时具有了 Read 和 Write 两个方法。
File 类型实现了 Read 和 Write 方法,因此它同时实现了 Reader、 Writer 和 ReadWriter 三个接口。我们可以将 File 类型的实例赋值给这三个接口类型的变量。
通过接口的组合,我们可以创建出具有更丰富功能的接口,而不需要修改已有的接口。这种方式符合“开闭原则”,即对扩展开放,对修改关闭。在后面讲“接口设计”的课程中,我们还会对此进行详细的说明。
结构体与接口的组合
结构体和接口的组合是 Go 语言中最常用的组合方式。通过在结构体中嵌入接口类型的字段,我们可以实现对不同类型的抽象和解耦。
type Reader interface {
Read(p []byte) (n int, err error)
}
type Writer interface {
Write(p []byte) (n int, err error)
}
type ReadWriter struct {
Reader // 匿名嵌入 Reader 接口
Writer // 匿名嵌入 Writer 接口
}
type File struct {
// ...
}
func (f *File) Read(p []byte) (n int, err error) {
// ...
return
}
func (f *File) Write(p []byte) (n int, err error) {
// ...
return
}
func main() {
rw := ReadWriter{
Reader: &File{}, // 嵌入 Reader 接口的实现类型
Writer: &File{}, // 嵌入 Writer 接口的实现类型
}
rw.Read(...)
rw.Write(...)
}
在这个例子中, ReadWriter 结构体通过匿名嵌入 Reader 和 Writer 接口,将它们组合在一起。在创建 ReadWriter 类型的实例时,我们可以传入任何实现了 Reader 和 Writer 接口的类型。
这种组合方式的优势在于,它将接口的定义和实现解耦了。 ReadWriter 结构体只依赖于 Reader 和 Writer 接口,而不依赖于具体的实现类型。
设计抉择:何时以及如何运用组合?
既然组合是 Go 的核心,我们应该如何以及何时使用它?
- 需要复用代码(行为或数据)时:
- 如果想复用另一个类型的“数据字段”和/或“方法”,优先考虑结构体匿名嵌入。这是最接近“继承”效果的方式,但本质是组合。
- 如果只想使用另一个类型的功能,但不希望其字段和方法被“提升”,那么将另一个类型的实例作为结构体的成员字段即可。
- 需要实现多态或解耦时:
- 定义接口来抽象行为。
- 让具体的类型实现这些接口(隐式)。
- 在代码中依赖接口而不是具体类型(如结构体持有接口字段,函数参数使用接口类型)。这是实现依赖注入和策略模式等设计模式的基础。
- 构建更复杂的行为契约时:
- 使用接口嵌入来组合多个简单的接口,形成一个功能更丰富的接口。
总原则: 优先考虑组合。思考类型之间的关系是 “has-a” 还是 “uses-a”,并选择合适的组合方式(结构体嵌入、持有接口字段)。避免试图在 Go 中模拟复杂的类继承层次(“is-a”)。
小结
这一讲,我们深入探讨了 Go 语言独特的“组合之道”,以及结构体和接口在其中的核心作用。
-
回顾基础:结构体用于聚合数据(字段),接口用于抽象行为(方法集)。结构体的匿名字段嵌入和接口的隐式实现是关键特性。
-
Go 不选择继承:避免了传统继承带来的强耦合、层次僵化、封装破坏等问题。
-
组合的优势:松耦合、高灵活性、更好的封装性、避免继承层次问题,更清晰地表达 “has-a” 或 “uses-a” 关系。
-
组合实践:
a. 结构体嵌入(匿名/非匿名):实现数据和行为的复用,方法提升模拟了部分继承效果。
b. 接口嵌入:组合行为契约,构建更丰富的接口。
c. 结构体持有接口字段:实现依赖注入,是解耦和实现多态的核心手段。
-
选择指南:根据代码复用需求、解耦需求、多态需求以及关系表达的清晰度,选择合适的组合方式。
掌握组合是理解和精通 Go 语言设计的关键。通过灵活运用结构体和接口进行组合,我们可以构建出简洁、清晰、可维护、易于扩展的 Go 应用程序,充分发挥 Go 语言的设计优势。
思考题
假设你正在设计一个系统,需要处理不同类型的通知发送,例如邮件通知(EmailNotifier)、短信通知(SMSNotifier)和应用内推送通知(PushNotifier)。这些通知器都需要一个 Send(message string) 方法。
现在你希望有一个统一的 NotificationService,它可以根据配置或上下文选择使用哪种通知器来发送通知。
请思考: 你会如何使用结构体和/或接口来设计这个 NotificationService 以及相关的通知器类型,以实现良好的解耦和灵活性?画出核心类型和它们之间关系的草图(或用代码片段描述)。
欢迎在评论区分享你的设计思路!我是 Tony Bai,我们下节课见。
放假说明:提前祝各位同学端午安康!我们的课程会暂停2期,于6月4日零点恢复更新,感谢理解,敬请期待解锁更多新内容。
控制结构:for循环的进化与新语义
你好,我是Tony Bai。
在Go的世界里,如果你想重复执行一段代码,只有一个选择——那就是 for 循环。不像其他语言提供了 while、 do-while 等多种循环,Go的设计者们选择了“少即是多”,用一种统一的 for 结构来应对所有循环场景。
这种简洁性是Go的魅力之一,但并不意味着 for 循环就一成不变、毫无“坑”点。恰恰相反,作为Go程序逻辑的核心骨架, for 循环自身也在不断“进化”:
-
你是否曾被
for range中那个难以捉摸的“循环变量重用”问题困扰过?甚至因此写出过隐藏的bug? -
Go 1.22版本对
for循环的语义做了哪些关键的修正?这对我们的日常编码意味着什么? -
最新的Go 1.23版本又为
for range带来了什么激动人心的新能力——自定义迭代器?它将如何改变我们遍历数据的方式?
不理解 for 循环的这些“陷阱”和“进化”,你可能会在并发编程中踩坑,或者错过利用新特性提升代码表达力和灵活性的机会。
这节课,我们就来深入剖析Go的 for 循环,从基础到演进,彻底搞懂它。我们将一起:
-
回顾
for循环的基础用法和常见模式,并点出历史遗留的“陷阱”。 -
理解 Go 1.22+ 对循环变量语义的关键变更及其影响。
-
探索 Go 1.23+ 引入的
range over func(自定义迭代器)这一强大的新特性。
掌握 for 循环的过去、现在与未来,才能更好地驾驭Go的控制流。
for 循环基础:常见模式与历史陷阱
虽然Go只有一个 for 关键字,但它足够灵活,可以模拟其他语言中的多种循环模式。
基础形式回顾
- 三段式
for(类C风格)
这是最经典、最完整的for循环形式,包含初始化、条件和后置语句。
// 计算 0 到 9 的和
sum := 0
for i := 0; i < 10; i++ { // 初始化; 条件; 后置语句
sum += i
}
fmt.Println(sum) // 输出 45
- 条件式
for(类while风格)
这种for语句形式省略了初始化和后置语句,只保留条件判断。
n := 1
for n < 5 { // 只有条件
n *= 2
}
fmt.Println(n) // 输出 8 (1 -> 2 -> 4 -> 8)
- 无限循环(
for {})
这种形式for循环省略了三段式for循环形式的所有部分,形成一个无限循环,通常需要配合 break 或 return 语句来退出。
for {
fmt.Println("Looping forever... (or until break/return)")
// if someCondition { break }
time.Sleep(1 * time.Second) // 避免CPU空转
// break // 示例,实际需要退出条件
}
for range循环
这是Go中最常用的循环形式之一,也是用于迭代各种数据集合(数组、切片、字符串、map、channel)的利器。
// 迭代切片
items := []string{"apple", "banana", "cherry"}
for index, value := range items {
fmt.Printf("Index: %d, Value: %s\n", index, value)
}
// 迭代字符串 (按 rune)
str := "Go语言"
for index, char := range str { // index 是字节索引, char 是 rune
fmt.Printf("Byte Index: %d, Char: %c\n", index, char)
}
// 迭代 map (顺序随机)
m := map[string]int{"one": 1, "two": 2}
for key, value := range m {
fmt.Printf("Key: %s, Value: %d\n", key, value)
}
// 迭代 channel (直到关闭)
ch := make(chan int, 2) // 带缓冲channel,不会导致下面语句执行阻塞
ch <- 1
ch <- 2
close(ch)
for value := range ch {
fmt.Printf("Received from channel: %d\n", value)
}
Go 1.22版本还增加了for range对int的迭代支持,前面三段式for形式的示例,可以改写为下面等价的形式:
for i := range 10 { // [0, 10)
sum += i
}
fmt.Println(sum) // 45
我们看到: for i:= range n 将从0迭代到n-1。如果只是需要迭代n次,而不需要循环变量,也可以写为:
for range 10 {
//... ...
}
for range 的历史陷阱(Go 1.22 之前)
for range 虽然方便,但在 Go 1.22 版本之前,存在一个非常容易让人掉坑的设计: 循环变量重用(Loop Variable Reuse)。
简单来说, for index, value := range collection 这句声明中的 index 和 value 变量,在整个循环过程中 只会被创建一次。每次迭代时,Go 只是将集合中当前元素的值 赋给 这两个已经存在的变量。
这在同步代码中通常没问题,但一旦涉及到并发(启动 goroutine)或闭包(创建匿名函数),并且这些 goroutine 或闭包捕获了循环变量时,问题就来了。
下面就是一个经典的并发陷阱的示例:
func main() {
var wg sync.WaitGroup // 使用 WaitGroup 等待 goroutine 完成
values := []string{"a", "b", "c"}
for _, v := range values {
wg.Add(1)
// 启动 goroutine,它捕获了循环变量 v
go func() {
defer wg.Done()
time.Sleep(10 * time.Millisecond) // 模拟一些延迟,让循环先跑完
fmt.Println(v) // 打印 v 的值
}()
}
wg.Wait() // 等待所有 goroutine 执行完毕
}
在 Go 1.22 之前运行,你很可能会看到输出:
c
c
c
为什么呢?因为所有三个 goroutine 都引用了 同一个 变量 v。当这些 goroutine 真正开始执行 fmt.Println(v) 时(由于 Sleep,循环通常已经结束),变量 v 存储的是最后一次迭代的值,也就是 “c”。
下面再来看一个与for range有关的经典闭包陷阱的示例:
func main() {
var funcs []func()
for i := 0; i < 3; i++ {
// 创建闭包,捕获循环变量 i
funcs = append(funcs, func() {
fmt.Println(i)
})
}
// 执行这些闭包
for _, f := range funcs {
f()
}
}
在 Go 1.22 之前运行,输出是:
3
3
3
原因同上:所有三个闭包都引用了同一个 变量 i。当它们被调用执行时,循环早已结束,变量 i 的最终值是 3。
在Go 1.22之前,为了解决这个问题,开发者们不得不在循环体内显式地创建一个循环变量的副本,比如:
// 并发示例规避
for _, v := range values {
v := v // 创建 v 的副本,goroutine 捕获的是这个副本
wg.Add(1)
go func() { /* ... use v ... */ }()
}
// 闭包示例规避
for i := 0; i < 3; i++ {
i := i // 创建 i 的副本
funcs = append(funcs, func() { fmt.Println(i) })
}
这种 v := v 或 i := i 的写法虽然有效,但看起来有点奇怪,也容易忘记。这个长期存在的“坑”给无数 Go 开发者带来了困扰。幸运的是,Go 团队终于在 1.22 版本解决了它。
关键变更:理解 Go 1.22+ 循环变量新语义
Go 1.22 版本带来了一个对 for 循环(包括三段式 for 和 for range)语义十分重大、也是开发者期待已久的变更: 从 Go 1.22 开始,每次循环迭代都会创建循环变量的新实例。 这意味着,不再有“循环变量重用”的问题了! 下面是新语义带来的一些影响。
- 并发代码更符合直觉
现在,前面那个并发陷阱的示例代码,在 Go 1.22+ 环境下运行,会输出 a、 b、 c 的某种排列组合(具体顺序取决于 goroutine 调度),因为每个 goroutine 捕获的是其创建时那次迭代的、独立的 v 变量副本。
- 闭包代码更符合直觉
同样,前面闭包陷阱的示例代码,在 Go 1.22+ 下运行,会输出:
0
1
2
因为每个闭包捕获的是其创建时那次迭代的、独立的 i 变量副本。
- 不再需要手动创建副本
类似 v := v 或 i := i 这种为了规避旧语义陷阱的写法,在 Go 1.22+ 中不再需要了。新语义本身就保证了每次迭代变量的独立性。
不过,考虑到向后兼容性,为了不破坏依赖旧语义的现有代码,这个新的循环变量语义是 选择性启用的。它只对满足以下条件的包生效:该包所在的 Go 模块,其 go.mod 文件中声明了 Go 1.22 或更高的版本(例如 Go 1.22 或 Go 1.23)。
如果你的 go.mod 文件写的是 Go 1.21 或更低版本,即使你使用 Go 1.22 或更高版本的编译器编译,循环变量的行为仍然是旧的、重用的语义。这给了项目逐步迁移到新语义的缓冲期。
Go 1.22 的这项改进,极大地简化了在循环中编写并发和闭包代码的复杂度,消除了一个长期存在的痛点,让 Go 代码更安全、更符合直觉。对于新项目或已迁移到 Go 1.22+ 的项目,这是一个非常受欢迎的变化。
range over func:探索 Go 1.23+ 函数迭代器
Go 1.22 解决了历史遗留问题,而 Go 1.23 则为 for range 带来了令人兴奋的新功能: 支持对函数进行 range 迭代,也就是所谓的自定义迭代器(Custom Iterators)或函数迭代器(Function Iterators)。
在 Go 1.23 之前, for range 只能用于内置的几种类型(整型 - Go 1.22+、数组、切片、字符串、map、channel)。现在,我们可以让 for range 遍历任何我们想遍历的序列,只要我们提供一个符合特定规范的 迭代器函数。
什么是迭代器函数?
简单来说,迭代器函数是一个特殊的函数,它负责生成序列中的下一个元素,并通过一个回调函数(通常命名为 yield)将元素“产出”给 for range 循环。
Go 1.23 在新的标准库 iter 包中定义了迭代器函数的标准签名:
package iter
// Seq[V] 代表一个产生 V 类型值的迭代器函数
type Seq[V any] func(yield func(V) bool)
// Seq2[K, V] 代表一个产生 K, V 类型键值对的迭代器函数
type Seq2[K, V any] func(yield func(K, V) bool)
我们看到迭代器函数本身( Seq 或 Seq2)接受一个 yield 函数作为参数。 yield 函数则是由 for range 循环隐式提供的。迭代器函数负责在内部逻辑中调用 yield 来“推送”元素给循环。
yield 函数返回一个 bool 值。返回 true 表示循环应该继续接收下一个元素;返回 false 表示循环请求提前停止(例如因为循环内部执行了 break)。迭代器函数收到 false 后应该立即停止产生元素并返回。
如何创建和使用自定义迭代器?
让我们看一个具体的例子。假设我们想让 for range 能够逆序遍历一个切片:
package main
import (
"fmt"
"iter" // 导入 iter 包
)
// Backward 返回一个逆序遍历切片的迭代器函数
func Backward[E any](s []E) iter.Seq2[int, E] {
// 返回符合 iter.Seq2 签名的函数
return func(yield func(int, E) bool) {
// 从后往前遍历
for i := len(s) - 1; i >= 0; i-- {
// 调用 yield "产出" 索引和元素
// 如果 yield 返回 false,立即停止迭代
if !yield(i, s[i]) {
return
}
}
}
}
func main() {
data := []string{"a", "b", "c"}
// 使用 for range 遍历我们自定义的 Backward 迭代器
for i, s := range Backward(data) {
fmt.Printf("Index: %d, Value: %s\n", i, s)
if i == 1 { // 演示提前 break
break
}
}
}
运行这个示例,你将看到如下输出:
Index: 2, Value: c
Index: 1, Value: b
究竟发生了什么?我们通过下面“分解动作”来理解一下for range与函数迭代器的工作原理:
-
Backward(data)返回了一个闭包(迭代器函数)。 -
for range接收到这个函数。 -
for range内部创建了一个yield函数,并调用我们返回的迭代器函数,将yield传给它。 -
迭代器函数内部开始执行
for循环(从后往前)。 -
第一次迭代(
i=2),调用yield(2, "c")。yield内部将2和"c"赋值给for range左侧的i和s,执行循环体fmt.Println(...)。yield返回true。 -
第二次迭代(
i=1),调用yield(1, "b")。同样,赋值、执行循环体。循环体执行了break。yield函数感知到break,于是返回false。 -
迭代器函数内部检查到
yield返回false,执行return,迭代结束。
实际上,Go编译器是将for range循环:
for i, s := range Backward(data) {
fmt.Printf("Index: %d, Value: %s\n", i, s)
if i == 1 { // 演示提前 break
break
}
}
重写为了下面的代码:
Backward(data)(func(i int, x string) bool {
i, x := #p1, #p2
fmt.Printf("Index: %d, Value: %s\n", i, x)
if i == 1 {
return false
}
return true
})
我们看到原for range代码中的break语句将终止循环的运行,那么转换为yield函数后,就相当于yield返回false。
如果for range中有return语句呢?Go编译器会如何转换for range代码呢?我们改造一下示例代码:
data := []string{"a", "b", "c"}
for i, s := range Backward(data) {
fmt.Printf("Index: %d, Value: %s\n", i, s)
if i == 1 {
return
}
}
Go编译器会将上述代码转换为类似下面的代码:
{
var #next int
Backward(data)(func(i int, x string) bool {
i, x := #p1, #p2
fmt.Printf("Index: %d, Value: %s\n", i, x)
if i == 1 {
#next = -1
return false
}
return true
})
if #next == -1 {
return
}
}
我们看到,由于yield函数只是传给iterator的输入参数,它的返回不会影响外层函数的返回,于是转换后的代码会设置一个标志变量(这里为#next),对于有return的for range,会在yield函数中设置该变量的值,然后在Backward调用之后,再次检查一下该变量,以决定是否调用return从函数中返回。
如果for range的body中有defer调用,那么Go编译器会又是如何做代码转换的呢?我们看下面示例:
data := []string{"a", "b", "c"}
for i, s := range Backward(data) {
defer fmt.Printf("Index: %d, Value: %s\n", i, s)
}
我们知道defer的语义是在函数return之后按“先进后出”的次序执行,那么直接将上述代码转换为如下代码是否ok呢?
Backward(data)(func(i int, x string) bool {
i, x := #p1, #p2
defer fmt.Printf("Index: %d, Value: %s\n", i, x)
})
这显然不行!这样转换后的代码,deferred function会在每次yield函数执行完就执行了,而不是在for range所在的函数返回前执行!为此,Go团队在runtime层增加了一个deferprocat函数,用于代码转换后的deferred函数执行。上面的示例将被Go编译器转换为类似下面的代码:
var #defers = runtime.deferrangefunc()
Backward(data)(func(i int, x string) bool {
i, x := #p1, #p2
runtime.deferprocat(func() { fmt.Printf("Index: %d, Value: %s\n", i, x) }, #defers)
})
到这里,我们所举的代码示例,其实都还是比较简单的情况!还有很多复杂的情况,比如break/continue/goto+label的、嵌套loop、loop中代码panic以及iterator自身panic等,是不是想想就复杂呢!更多复杂的转换代码这里不展开了,展开的也很可能不对,这本来就是Go编译器的事情。如果哪个小伙伴要了解转换的复杂逻辑,可以自行阅读Go项目库中的 cmd/compile/internal/rangefunc/rewrite.go。
Pull 迭代器 vs Push 迭代器
我们上面定义的 iter.Seq 和 iter.Seq2 属于 Push 风格 的迭代器:迭代器主动控制流程,将元素“推送”给 yield。
还有另一种 Pull 风格 的迭代器,它更像传统的迭代器模式:由调用者控制流程,每次调用 Next() 方法来“拉取”下一个元素。在一些其他语言中,Pull迭代器也被称为外部迭代器(External Iterator),即主动通过迭代器提供的类next方法从中获取数据。
Go标准库 iter 包提供了 Pull 函数,可以将 Push 迭代器转换为 Pull 迭代器:
// 将 Push 迭代器 s 转换为 Pull 迭代器
// next() 返回下一个元素和是否有效的布尔值
// stop() 用于提前释放迭代器可能持有的资源 (如果有的话)
next, stop := iter.Pull(s)
defer stop() // 推荐使用 defer stop()
for {
value, ok := next()
if !ok { // 没有更多元素了
break
}
// 处理 value
}
Pull 迭代器在需要更精细控制迭代(如并行处理、合并多个序列)时很有用,但Pull迭代器是不能直接对接for range的。此外要注意的是Pull/Pull2返回的next、stop不能在多个Goroutine中使用。Russ Cox很早就在其个人博客上对Go iterator的实现方式进行了铺垫,他的这篇 Coroutines for Go 对Go各类iterator的实现方式做了早期探讨,感兴趣的小伙伴儿可以移步阅读一下。
迭代器的组合与标准库支持
函数迭代器的强大之处在于它们的可组合性。我们可以编写“适配器”函数,接收一个或多个迭代器,返回一个新的迭代器,实现过滤、映射、组合等操作。
我们来看一个示例:
package main
import (
"iter"
"slices"
)
// Filter returns an iterator over seq that only includes
// the values v for which f(v) is true.
func Filter[V any](f func(V) bool, seq iter.Seq[V]) iter.Seq[V] {
return func(yield func(V) bool) {
for v := range seq {
if f(v) && !yield(v) {
return
}
}
}
}
// 过滤奇数
func FilterOdd(seq iter.Seq[int]) iter.Seq[int] {
return Filter[int](func(n int) bool {
return n%2 == 0
}, seq)
}
// Map returns an iterator over f applied to seq.
func Map[In, Out any](f func(In) Out, seq iter.Seq[In]) iter.Seq[Out] {
return func(yield func(Out) bool) {
for in := range seq {
if !yield(f(in)) {
return
}
}
}
}
// Add 100 to every element in seq
func Add100(seq iter.Seq[int]) iter.Seq[int] {
return Map[int, int](func(n int) int {
return n + 100
}, seq)
}
var sl = []int{12, 13, 14, 5, 67, 82}
func main() {
for v := range Add100(FilterOdd(slices.Values(sl))) {
println(v)
}
}
这个示例定义了两个适配器:Filter和Map,然后通过多个iterator的组合实现了对一个切片的元素的过滤与重新映射:先是过滤掉奇数,然后又在每个元素值的基础上加100。这有点其他语言支持那种函数式的链式调用的意思,但从代码层面看,还不是那么优雅。
我们也可以改造一下上述代码,让for range后面的迭代器的组合更像链式调用一些:
package main
import (
"fmt"
"iter"
"slices"
)
// Sequence 是一个包装 iter.Seq 的结构体,用于支持链式调用
type Sequence[T any] struct {
seq iter.Seq[T]
}
// From 创建一个新的 Sequence
func From[T any](seq iter.Seq[T]) Sequence[T] {
return Sequence[T]{seq: seq}
}
// Filter 方法
func (s Sequence[T]) Filter(f func(T) bool) Sequence[T] {
return Sequence[T]{
seq: func(yield func(T) bool) {
for v := range s.seq {
if f(v) && !yield(v) {
return
}
}
},
}
}
// Map 方法
func (s Sequence[T]) Map(f func(T) T) Sequence[T] {
return Sequence[T]{
seq: func(yield func(T) bool) {
for v := range s.seq {
if !yield(f(v)) {
return
}
}
},
}
}
// Range 方法,用于支持 range 语法
func (s Sequence[T]) Range() iter.Seq[T] {
return s.seq
}
// 辅助函数
func IsEven(n int) bool {
return n%2 == 0
}
func Add100(n int) int {
return n + 100
}
func main() {
sl := []int{12, 13, 14, 5, 67, 82}
for v := range From(slices.Values(sl)).Filter(IsEven).Map(Add100).Range() {
fmt.Println(v)
}
}
这样看起来是不是更像链式调用了!
运行上述示例,我们将得到如下结果:
112
114
182
Go 1.23还在 slices 和 maps 包中添加了返回迭代器的“适配器”函数,方便实现自定义迭代器组合:
-
slices.All(s):返回iter.Seq2[int, E](索引, 值) -
slices.Values(s):返回iter.Seq[E](值) -
maps.All(m):返回iter.Seq2[K, V](键, 值) -
maps.Keys(m):返回iter.Seq[K](键) -
maps.Values(m):返回iter.Seq[V](值)
以及将迭代器元素收集回来的函数:
-
slices.Collect(seq):将iter.Seq[E]收集到[]E -
maps.Collect(seq2):将iter.Seq2[K, V]收集到map[K]V
目前Go官方也正在策划 golang.org/x/exp/xiter 包,其中就有很多工具函数可以帮我们实现iterator的组合。
性能考量
函数迭代器非常灵活强大,但也引入了函数调用的开销。虽然Go编译器会尽力内联和优化,但在性能极其敏感的热点路径中,其开销可能比直接使用原生 for range(针对内置类型)或手动编写的循环要高一些。
我们来实测一下iterator带来的额外的开销:
// benchmark_iterator_test.go
package main
import (
"slices"
"testing"
)
var sl = []string{"go", "java", "rust", "zig", "python"}
func iterateUsingClassicLoop() {
for i, v := range sl {
_, _ = i, v
}
}
func iterateUsingIterator() {
for i, v := range slices.All(sl) {
_, _ = i, v
}
}
func BenchmarkIterateUsingClassicLoop(b *testing.B) {
for range b.N {
iterateUsingClassicLoop()
}
}
func BenchmarkIterateUsingIterator(b *testing.B) {
for range b.N {
iterateUsingIterator()
}
}
我们对比一下使用传统for range + slice和for range + iterator的benchmark结果(基于Go 1.24.0的编译执行):
$go test -bench . benchmark_iterator_test.go
goos: darwin
goarch: amd64
cpu: Intel(R) Core(TM) i5-8257U CPU @ 1.40GHz
BenchmarkIterateUsingClassicLoop-8 414234890 2.838 ns/op
BenchmarkIterateUsingIterator-8 291626221 4.104 ns/op
PASS
ok command-line-arguments 3.095s
我们看到:虽然有优化,但iterator还是带来了一定的开销,这说明在性能敏感的系统中还是要考虑iterator带来的开销的。
因此,在追求极致性能的场景,需要进行基准测试,权衡使用自定义迭代器的便利性与可能的性能损耗。对于大多数非性能瓶颈的代码,自定义迭代器带来的代码清晰度和可组合性优势通常更重要。
小结
这一讲,我们深入探索了Go语言核心控制结构 for 循环的“进化”之路。
-
基础与陷阱:回顾了
for的多种形式,并重点剖析了 Go 1.22 之前for range循环中因循环变量重用导致的并发和闭包陷阱。 -
关键语义变更:理解了 Go 1.22+ 版本如何通过为每次迭代创建新的循环变量实例来彻底解决重用问题,让代码行为更符合直觉(需
go.mod声明 Go 1.22+ 启用)。 -
range over func(Go 1.23+):学习了 自定义迭代器 这一强大的新特性。我们了解了迭代器函数的签名 (iter.Seq、iter.Seq2)、yield机制、Push/Pull 风格、迭代器的组合(适配器)以及标准库slices、maps包的新增支持,并了解了使用迭代器带来的额外的性能开销。
for 循环的这些演进,体现了Go语言在保持简洁的同时,不断提升表达力、修复历史问题、拥抱现代编程范式的努力。理解这些变化和新特性,将帮助我们编写出更安全、更灵活、也更具表现力的Go代码。
思考题
自定义迭代器( range over func)为 for range 打开了新的大门。请思考一下:
-
除了逆序遍历切片,你还能想到哪些场景或自定义数据结构适合使用自定义迭代器来实现
for range遍历?例如:树的遍历?分页数据的遍历?生成器…… -
与直接返回一个包含所有元素的切片相比,使用迭代器(尤其是处理大数据集时)的主要优势是什么?
欢迎在留言区分享你的想法和创意!我是Tony Bai,我们下节课见。
泛型:超越interface{},哪些场景应该优先考虑泛型?
你好,我是Tony Bai!
在Go语言发展的十多年历程中,有一个特性始终牵动着无数开发者和社区的心弦,引发了无数的讨论甚至争论,它就是—— 泛型(Generics)。
在Go 1.18版本之前,如果你想编写一段可以处理多种不同类型数据的代码,通常只有2种选择:
-
为每种类型写一份几乎重复的代码(如
maxInt、maxFloat64)。 -
使用空接口
interface{},配合运行时类型断言。
但这2种方式都有明显的痛点:前者代码冗余、难以维护;后者则牺牲了编译时的类型安全,带来了运行时的性能开销和潜在的 panic 风险。
这不禁让人疑问:
-
为什么以简洁著称的Go语言,会长期“固执”地不引入泛型?这背后有哪些设计上的权衡?
-
Go 1.18最终引入的泛型,究竟解决了
interface{}的哪些核心痛点? -
泛型的核心语法(类型参数、类型约束)该如何理解和使用?
-
在哪些场景下,泛型能真正发挥威力,让我们写出更优雅、更安全,可能也更高效的代码?
-
泛型是银弹吗?它自身的局限性和潜在的性能考量是什么?我们何时要避免使用它?
不理解泛型的设计动机、核心语法和适用边界,你可能会错过利用它简化代码的机会,也可能在不合适的场景滥用它,反而增加了代码的复杂度和潜在的性能问题。
这节课,我们就来深入探讨Go泛型的来龙去脉和实践之道。具体来说,我们将一起探讨以下内容:
-
回顾泛型要解决的核心痛点,理解Go引入泛型的历史背景。
-
掌握泛型的核心语法:类型参数、类型约束和类型推导。
-
探索泛型的典型应用场景,感受其威力。
-
分析泛型的局限性和性能影响,明确何时应该优先考虑,何时应该谨慎使用。
让我们揭开Go泛型的面纱,看看它如何帮助我们“超越 interface{}”。
解决痛点:为什么十多年后泛型才落地?
在Go 1.18之前漫长的“无泛型”时代,开发者们主要依靠 interface{} 来实现一定程度的通用编程。但这种方式存在几个难以忽视的痛点,我们一起来看下。
- 类型不安全:使用
interface{}意味着放弃了编译时的类型检查。你需要通过类型断言value.(ConcreteType)在运行时检查和转换类型。如果类型不匹配,程序就会panic。这使得错误暴露得更晚,增加了调试难度。具体的示例如下:
// interface{} 版本的通用容器 (简化)
type Container struct{ items []interface{} }
func (c *Container) Add(item interface{}) { c.items = append(c.items, item) }
func (c *Container) Get(index int) interface{} { return c.items[index] }
func main() {
// 使用时
c := Container{}
c.Add(10) // 存入 int
c.Add("hello") // 存入 string
// 取出时需要类型断言
val1 := c.Get(0).(int) // 如果存入的不是 int,这里会 panic
_ = val1
// 安全的方式
if val2, ok := c.Get(1).(string); ok {
fmt.Println("Got string:", val2)
} else {
fmt.Println("Item at index 1 is not a string")
}
}
-
性能开销:
interface{}在运行时会涉及类型的装箱(将具体类型包装成接口值)和拆箱(从接口值中取出具体类型)。接口方法的调用也是动态派发,通常比直接调用具体类型的方法要慢。这些都带来了额外的性能损耗。 -
代码冗余与可读性差:类型断言的
switch或if/else语句往往让代码变得冗长、笨重,降低了可读性。为了处理不同类型,你可能需要写很多重复的检查和转换逻辑。 -
无法对通用操作施加编译期约束:比如,你想写一个通用的
Sum函数,对一个数字切片求和。使用interface{},你无法在编译期保证传入的一定是数字类型,也无法直接使用+运算符,必须在运行时进行类型判断和转换。
那么, Go为何迟迟不加入泛型呢? Go团队的确对此非常谨慎,主要出于以下考量:
-
简洁性:泛型会显著增加语言的复杂性(新的语法、类型系统规则、编译器实现难度)。Go的核心哲学之一就是保持简单。
-
编译速度:担心泛型的实现(如代码生成方式)会拖慢Go引以为傲的快速编译。
-
运行时开销:如何在提供泛型能力的同时,尽量减少对运行时性能的影响。
-
设计完美方案:Go团队希望找到一种既能解决核心痛点,又与Go现有设计哲学契合,且易于理解和使用的泛型方案。这需要漫长的探索和社区讨论。
最终,经过多年的设计迭代和社区反馈,Go 1.18推出的泛型方案被认为在表达力、简洁性、类型安全和性能之间取得了较好的平衡,能够有效解决 interface{} 的核心痛点,同时尽可能地保持了Go的风格。
泛型的引入使得我们可以编写出这样的代码:
// 泛型版本的 Max 函数
import "cmp" // Go 1.21+
func Max[T cmp.Ordered](a, b T) T { // T 是类型参数,cmp.Ordered 是约束
if a > b { // 可以直接比较,因为约束保证了 T 支持 >
return a
}
return b
}
// 泛型版本的 Stack
type Stack[T any] struct { // T 可以是任意类型 (any 是 interface{} 的别名)
items []T
}
func (s *Stack[T]) Push(item T) { s.items = append(s.items, item) }
func (s *Stack[T]) Pop() (T, bool) {
if len(s.items) == 0 {
var zero T // 返回类型的零值
return zero, false // 使用 bool 类型表示是否成功
}
index := len(s.items) - 1
item := s.items[index]
s.items = s.items[:index]
return item, true
}
func main() {
maxInt := Max(10, 5) // T 推导为 int
maxFloat := Max(3.14, 2.71) // T 推导为 float64
fmt.Println(maxInt, maxFloat)
intStack := Stack[int]{} // 显式指定 T 为 int
intStack.Push(100)
// intStack.Push("hello") // 编译错误!类型安全
val, _ := intStack.Pop()
fmt.Println(val)
}
这段代码既通用,又保证了编译时的类型安全,还避免了 interface{} 的运行时开销,这就是泛型带来的核心价值。
了解了Go在十多年后落地泛型的原因后,我们进入Go泛型的核心语法。
语法核心:类型参数、类型约束与类型推断
要使用Go泛型,需要掌握三个核心概念:类型参数、类型约束以及类型推导。接下来,我们分别来强化一下。
类型参数(Type Parameters)
就像函数有值参数一样,泛型函数或泛型类型可以有 类型参数。类型参数在声明时放在函数名或类型名后面的方括号 [] 中,通常用单个大写字母表示(如 T、 K、 V)。
// 泛型函数声明
func PrintSlice[T any](s []T) { /* ... */ } //类型参数 T,约束为 any (任意类型)
// 泛型类型声明
type Node[T any] struct { // Node 是一个泛型类型
Value T
Next *Node[T] // 可以引用自身,但类型参数需一致
}
在函数体或类型定义内部,类型参数 T 可以像普通类型一样使用(比如用作变量类型、参数类型、返回值类型、字段类型等)。
类型约束(Type Constraints)
类型参数不能是“凭空”存在的,它必须有所约束,这种约束就是 类型约束。类型约束可以限制类型参数,明确告知可以使用哪些类型来实例化泛型。同时,类型参数也提供操作许可,编译器根据约束知道能在泛型代码中对类型参数(比如 T) 的值执行哪些操作(如调用方法、使用运算符)。
在Go中,类型约束是通过 接口类型 来定义的,示例代码如下:
// T 必须满足约束 MyConstraint
func GenericFunc[T MyConstraint](arg T) { /* ... */ }
// MyConstraint 是一个接口类型,定义了 T 必须具备的能力
type MyConstraint interface {
// 约束可以包含:
// 1. 方法集:要求 T 必须实现某些方法
// SomeMethod() string
// 2. 类型列表 (Type List):限制 T 必须是列表中的某种类型,或其底层类型 (~)
// ~int | ~string // T 的底层类型必须是 int 或 string
// 3. 嵌入其他约束接口
// AnotherConstraint
// 4. 预定义的 comparable 约束 (类型支持 == 和 !=)
// comparable
}
下面是几类常用的类型约束:
-
any:即interface{},表示T可以是任何类型。这是最宽松的约束,但意味着你对T的操作知之甚少,几乎不能做任何特定操作。 -
comparable:Go预定义的约束,表示T必须支持==和!=比较。常用于需要比较键或值的场景(如查找函数、map键)。 -
基于方法的约束:定义一个包含所需方法的接口。
type Stringer interface { String() string }
func Print[T Stringer](val T) { fmt.Println(val.String()) } // T 必须有 String() 方法
- 基于类型集合的约束(Type Set / Union):使用
|连接一组允许的类型,可以使用~表示允许底层类型匹配。
// 约束 T 的底层类型必须是某种整数或浮点数
type Number interface {
~int | ~int8 | ~int16 | ~int32 | ~int64 |
~uint | ~uint8 | ~uint16 | ~uint32 | ~uint64 | ~uintptr |
~float32 | ~float64
}
func Add[T Number](a, b T) T { return a + b } // 可以用 +,因为约束保证了 T 是数值类型
对于一些常用的类型集合约束,无需自己定义。Go团队维护的golang.org/x/exp/constraints包已经准备好了一些常用的“预定义”约束,我们直接使用即可,示例如下:
// golang.org/x/exp/constraints
type Integer interface {
Signed | Unsigned
}
type Signed interface {
~int | ~int8 | ~int16 | ~int32 | ~int64
}
type Unsigned interface {
~uint | ~uint8 | ~uint16 | ~uint32 | ~uint64 | ~uintptr
}
type Float interface {
~float32 | ~float64
}
type Complex interface {
~complex64 | ~complex128
}
cmp.Ordered(Go 1.21+):标准库cmp包提供的约束,包含了所有支持排序操作符 (<,<=,>,>=) 的内置类型,是编写通用比较函数的常用约束。该约束最初也定义在golang.org/x/exp/constraints中,后被挪到Go标准库中。
import "cmp"
func SortSlice[T cmp.Ordered](s []T) { sort.Slice(s, func(i, j int) bool { return s[i] < s[j] }) }
- 混合约束:接口可以同时包含方法和类型列表。
// 定义混合约束
type MyConstraint interface {
~int | ~string // 类型列表:允许底层类型为 int 或 string
MyMethod() // 方法:必须实现 MyMethod() 方法
}
类型推导(Type Inference)
在调用泛型函数时,Go编译器通常能根据传入的值参数的类型,自动推导出类型参数的具体类型,我们无需显式指定,示例代码如下:
func Print[T any](val T) { fmt.Println(val) }
Print(10) // 编译器推导出 T 为 int
Print("hello") // 编译器推导出 T 为 string
Print([]int{1, 2}) // 编译器推导出 T 为 []int
这种基于函数实参类型推断类型参数的方式是最常见的。此外,如果约束中包含类型参数关系(如 U []T),则可以互相推导,比如下面的示例:
func ProcessPair[T any, S []T](first T, second S) {}
ProcessPair(10, []int{1, 2})
在这个例子中,编译器根据10推导T=int,然后根据[]int{…} 推导 S=[]int,并验证 S 的元素类型 T 确实是 int。
当然类型推导也不是“无所不能”的,也有自身的一些限制,比如:
- 无法基于返回值推导,也就是说不能仅根据期望的返回值类型来推导类型参数,示例如下:
func Zero[T any]() T { var zero T; return zero }
// var x = Zero() // 编译错误:cannot infer T
var x = Zero[string]() // 需要显式指定 T 为 string
- 实例化泛型类型时通常需要显式指定:
// type Pair[T any] struct { First, Second T }
// p := Pair{1, 2} // 编译错误:cannot use generic type Pair without instantiation
p := Pair[int]{1, 2} // 必须显式指定 Pair[int]
未来Go版本可能会放宽对泛型类型实例化的推导限制,但目前通常需要显式指定。总的来说,类型推导极大地简化了泛型函数的使用,让代码看起来更自然。
应用场景:泛型在数据结构和算法中的威力
泛型最能发挥威力的领域,是编写通用的数据结构和算法。
通用数据结构
有了泛型后,我们不再需要为 int、 string、 float64 等分别实现 List、 Stack、 Queue、 Set。用泛型可以一次搞定,且类型安全。例如,泛型栈 Stack[T] 示例:
type Stack[T any] struct { items []T }
func (s *Stack[T]) Push(item T) { /* ... */ }
func (s *Stack[T]) Pop() (T, bool) { /* ... */ }
intStack := Stack[int]{}
intStack.Push(1)
// intStack.Push("a") // 编译错误
strStack := Stack[string]{}
strStack.Push("hello")
Go编译器保证了 intStack 只能存 int, strStack 只能存 string。
通用算法函数
我们可以使用泛型编写适用于多种类型序列的通用算法,如查找、排序、映射、过滤、归约等。
下面是一个通用 Map 函数(将切片元素进行转换)的示例,该示例中Map泛型函数将一个整型切片“映射”为字符串切片:
// 将 []T 类型的切片 s,通过函数 f(T) U 转换为 []U 类型的新切片
func Map[T, U any](s []T, f func(T) U) []U {
result := make([]U, len(s))
for i, v := range s {
result[i] = f(v)
}
return result
}
ints := []int{1, 2, 3}
strs := Map(ints, func(i int) string { return fmt.Sprintf("N%d", i) }) // T=int, U=string
fmt.Println(strs) // 输出 [N1 N2 N3]
再看一个通用 Filter 函数(过滤切片元素)的示例,这里通过Filter泛型函数将切片中小于0的数值过滤掉:
// 保留切片 s 中满足 predicate(T) bool 的元素
func Filter[T any](s []T, predicate func(T) bool) []T {
result := make([]T, 0, len(s)) // 预分配容量
for _, v := range s {
if predicate(v) {
result = append(result, v)
}
}
return result
}
numbers := []int{-2, -1, 0, 1, 2}
positives := Filter(numbers, func(n int) bool { return n > 0 }) // T=int
fmt.Println(positives) // 输出 [1 2]
Go 1.21+版本标准库中的 slices 和 maps 包就大量运用了泛型来实现这类通用操作,极大地丰富了Go处理集合类型数据的能力。
减少对 interface{} 的依赖
在很多原本需要使用 interface{} 和类型断言的场景,现在可以用类型更安全的泛型替代,例如:
-
需要一个函数接受多种数值类型并进行计算。
-
需要一个容器能存储多种相似结构但具体类型不同的对象(如果它们能满足某个泛型约束)。
这使得代码更健壮,错误能在编译期暴露,运行时性能通常也更好。
局限与性能考量:何时不适合用泛型?
Go泛型虽好,但并非万能药,它也有其自身的局限和需要考量的成本。
泛型的局限
第一是增加了复杂性,主要有以下3个方面:
-
语言层面:引入了新的语法概念(类型参数、约束),类型系统变得更复杂。
-
代码层面:泛型代码(尤其是带复杂约束的)可能比具体类型的代码更难阅读和理解,需要编写和维护类型约束接口。
-
认知负担:开发者需要学习新的概念和规则。
第二是增加了编译时间。 虽然Go编译器做了优化,但泛型的实例化和类型检查仍然会增加编译时间,尤其在大量使用泛型或泛型嵌套的场景。
第三是存在运行时开销,通常较小但存在。 Go泛型的实现(GC Shape Stenciling + Dictionaries)虽然旨在平衡性能和代码大小,但相比于非泛型、完全具体类型的代码,可能仍存在一些微小的运行时开销(比如通过字典进行类型相关操作)。在 《Go语言第一课》 泛型篇加餐中,我们有对泛型实现原理的简要说明,对泛型原理感兴趣的小伙伴可以去复习一下。
这通常远小于使用 interface{} 的开销,但在极端性能敏感的场景可能需要通过基准测试来评估。
第四是存在代码膨胀(Code Bloat)。 编译器需要为不同的类型参数组合(或GC Shape分组)生成代码。虽然Go的策略试图减少膨胀,但生成的二进制文件大小仍然可能比纯粹的非泛型代码更大。
第五是并非所有场景都需要泛型。
-
只处理单一具体类型:如果你的函数或数据结构明确只需要处理一种类型,没必要强行泛型化。
-
interface{}足够好且性能可接受:有些场景,interface{}的灵活性和动态性就是你需要的,且性能不是瓶颈,那么继续使用interface{}完全没问题(例如标准库fmt.Println)。 -
代码生成可能是更好的选择:对于某些需要针对特定类型生成大量高度优化代码的场景,使用代码生成工具(如
go generate)可能比复杂的泛型更合适。
何时不适合用泛型(或需谨慎)?
了解了局限性,我们再来总结下不适合或需要谨慎使用泛型的场景。
-
为了泛型而泛型:不要仅仅因为Go有了泛型就到处使用。如果它不能带来明确的好处(代码复用、类型安全、性能提升),反而增加了复杂性,就不值得。
-
过度泛化:试图编写一个能处理“一切”的超级通用泛型函数/类型通常是坏主意,会导致约束复杂、难以使用和理解。保持泛型的目标明确、约束合理。
-
性能极端敏感且泛型引入开销:在需要压榨每一纳秒性能的热点路径,如果基准测试显示泛型带来了不可接受的开销,可能需要回退到具体类型实现或代码生成。
泛型是Go工具箱中一件强大的新武器,特别适用于编写通用的数据结构、算法以及需要类型安全的通用逻辑。但它并非没有成本。我们需要理解其优势和局限,在“代码复用、类型安全”与“增加的复杂性、潜在的性能影响”之间做出明智的权衡。
小结
这节课,我们深入探讨了Go语言姗姗来迟却意义重大的泛型特性。
-
解决了
interface{}的核心痛点:泛型通过在编译期处理类型,提供了类型安全,避免了运行时的类型断言和panic风险,同时通常具有更好的性能,代码也更简洁。 -
掌握了核心语法:理解了类型参数(泛型的变量)、类型约束(通过接口限制类型参数的能力和范围,包括
any、comparable、cmp.Ordered及自定义约束)以及类型推导(编译器自动推断类型参数,简化调用)是使用泛型的基础。 -
明确了核心应用场景:泛型在编写通用的数据结构(如Stack、List、Set)和算法(如Map、Filter、Reduce)时威力最大,能显著提高代码复用性和类型安全性。
-
认识了局限与性能考量:泛型也带来了复杂性增加、编译时间延长、可能的运行时微小开销(GC Shape Stenciling)和代码膨胀等问题。而且,它并非适用于所有场景,在使用时我们需要权衡利弊。
Go泛型的目标不是取代 interface{}(它们各有用途),而是提供一种新的、类型安全的通用编程方式。理解何时应该优先考虑泛型,何时保持简单或继续使用接口,是Go进阶开发者的重要能力。
思考题
假设你需要编写一个函数,用于从任意类型的切片中移除重复元素,并返回一个包含不重复元素的新切片。
-
你会考虑使用泛型来实现这个
Unique函数吗?为什么? -
如果使用泛型,这个函数的类型参数需要满足什么约束(提示:可以思考一下如何判断元素是否“重复”)?
-
请尝试写出这个泛型函数
Unique[T ???](input []T) []T的签名(只需签名,替换???为合适的约束)。
欢迎在留言区分享你的思考!我是Tony Bai,我们下节课见。
Go并发核心:goroutine、channel与Context的最佳实践
你好,我是Tony Bai!
Go语言之所以能在云计算和微服务时代迅速崛起,其简洁而强大的并发编程模型功不可没。如果你问一个Gopher,Go最吸引人的特性是什么?很多人会脱口而出: goroutine 和 channel!
这种基于 CSP(Communicating Sequential Processes)模型的并发原语,让编写并发程序变得前所未有的简单和直观。
但是,仅仅会用 go 关键字启动一个goroutine,或者知道用channel传递数据,就足够了吗?
-
goroutine 到底“轻量”在哪里?我们应该如何管理它们的生命周期,避免泄漏?
-
channel 除了基本的发送接收,还有哪些强大的用法和需要注意的死锁、关闭陷阱?
-
当我们需要处理更复杂的并发协调,比如多路监听、共享资源访问时,仅仅依靠 goroutine 和 channel 是否还够用?
select、sync包又扮演了什么角色? -
在跨越goroutine边界,甚至跨越网络请求时,如何优雅地传递请求相关的截止时间、取消信号以及上下文值?这时,
context包为何成为事实标准,我们又该如何用好它?
不深入理解Go并发的核心工具及其适用边界,你可能会写出低效、易出错,甚至资源泄漏的并发代码。 掌握 goroutine、channel、select、sync 和 context 的最佳实践,是编写高质量Go并发程序的基石。
这节课,我们就一起深入Go并发的核心地带。我们将一起:
-
领略Go并发模型的魅力:理解 goroutine 的轻量高效和 channel 的通信哲学,并关注其常见陷阱。
-
探讨超越基础原语的场景:了解何时以及如何使用
select、sync包的工具来应对更复杂的并发挑战。 -
详解
context包:掌握这个处理超时、取消和请求值传递的利器及其最佳实践。
接下来,就让我们一起开启Go并发进阶之旅,一起驾驭Go的并发之力!
Go并发模型的魅力:理解goroutine与channel的轻量与高效
Go的并发模型建立在两个核心概念之上:goroutine 和 channel。
Goroutine:为何如此轻量?
Goroutine 常被称为“轻量级线程”,这是Go并发模型的核心优势所在。但“轻量”具体体现在哪里呢?
极低的创建开销
启动一个goroutine所需的内存非常少,初始栈空间通常只有几KB。相比之下,操作系统线程(OS Thread)的创建通常需要分配数MB的栈空间。这意味着在Go程序中,我们可以轻松创建成千上万,甚至百万级别的goroutine,而不必过于担心资源耗尽的问题。
动态伸缩的栈
Goroutine的栈空间并非固定不变。它以一个较小的初始值(如2KB)开始,并且能够根据函数的调用深度和局部变量的需求,在运行时自动地增长(分配更大的栈段)和收缩(释放不使用的栈段)。这种按需分配的机制避免了像传统线程那样预先分配一个固定大栈(如8MB)可能带来的内存浪费。
不过,自Go 1.19起,Go运行时在分配初始goroutine栈时会更加智能,它会根据goroutine历史平均栈使用情况来决定初始大小。这种基于历史平均值的策略,旨在减少普通情况下早期栈增长和拷贝的需要,其代价是对于那些远低于平均栈使用量的goroutine,可能会浪费最多2倍的空间。
用户态调度与M:N模型
Goroutine的调度完全由Go运行时在用户空间进行管理,避免了进入和退出内核态的高昂成本。Go运行时实现了一个高效的 M:N调度模型:它将大量的用户级goroutine(M个)映射到少量的内核级OS线程(N个)上执行,并通过逻辑处理器(P)进行协调。当一个goroutine发生阻塞(如等待I/O、channel操作、锁)时,运行时会自动将其移出对应的OS线程,并让该线程去执行另一个就绪的goroutine,从而实现高效的CPU利用和并发执行。
我们可以用一个简化图来理解这个模型:
上图中,多个Goroutine(G)运行在逻辑处理器(P)上,P将工作调度到实际的OS线程(T)上执行。阻塞的G会暂时脱离P。
启动一个goroutine在语法上极其简单,只需在函数或方法调用前加上 go 关键字:
package main
import (
"fmt"
"time"
)
func simpleWorker(id int) {
fmt.Printf("Worker %d starting\n", id)
time.Sleep(50 * time.Millisecond)
fmt.Printf("Worker %d done\n", id)
}
func main() {
go simpleWorker(1) // 启动 goroutine
go simpleWorker(2)
fmt.Println("Main goroutine might exit before workers finish...")
// 如果 main 在这里直接结束,worker 可能没机会执行完
// time.Sleep(100 * time.Millisecond) // 等待一小段时间,但这也并不可靠!
}
上面这个例子故意突显了主goroutine退出会导致整个程序退出的问题。为了正确地等待goroutine完成,我们需要 同步机制, sync.WaitGroup 显然是最常用的一种。
package main
import (
"fmt"
"sync"
"time"
)
func workerWithWG(id int, wg *sync.WaitGroup) {
defer wg.Done() // 确保在 worker 退出前调用 Done
fmt.Printf("Worker %d starting\n", id)
time.Sleep(50 * time.Millisecond)
fmt.Printf("Worker %d done\n", id)
}
func main() {
var wg sync.WaitGroup
for i := 0; i < 3; i++ {
wg.Add(1) // 在启动前增加计数
go workerWithWG(i, &wg) // 传递 WaitGroup 指针
}
fmt.Println("Main waiting...")
wg.Wait() // 阻塞,直到计数器归零
fmt.Println("Main finished.")
}
这段代码使用 sync.WaitGroup 来同步多个 goroutine 的执行,确保主函数(main)在所有 worker goroutine 完成任务后才退出。
Goroutine的进阶提示与陷阱
虽然goroutine提供了难以置信的便利性和强大的并发能力,但“能力越大,责任越大”。像任何强大的工具一样,如果不了解其细微之处和潜在的陷阱,可能会适得其反。接下来,我们就探讨下Go开发者进阶需要特别注意的地方。
Goroutine 泄漏(Goroutine Leak)
Goroutine 泄漏是最常见的陷阱之一。如果一个goroutine因为某种原因(如等待一个永远不会关闭或发送数据的channel,或等待一个永远不会满足的锁)而永久阻塞,它就永远不会退出。它占用的内存(主要是栈空间)和运行时资源将无法被回收,日积月累会导致内存耗尽或性能下降。下面是一个因Channel阻塞导致goroutine泄漏的示例:
func leakExample() {
ch := make(chan int) // 无缓冲channel
go func() {
val := <-ch // 尝试从 ch 接收,但没有发送者,永久阻塞
fmt.Println("Received:", val) // 这行永远不会执行
}()
// ch 没有被写入或关闭,上面的 goroutine 将永远阻塞,造成泄漏
fmt.Println("Launched leaky goroutine...")
}
这是一个经典的例子,leakExample中启动的 goroutine会无限期地存在(直到程序退出),因为它被永远阻塞,试图从无缓冲通道 ch 接收数据。由于没有任何goroutine向 ch 发送值(并且 ch 从未关闭), <-ch 操作将永远阻塞,使 goroutine 保持活动状态。这就是 goroutine 泄漏的本质。此外,由于闭包,通道 ch 被匿名 goroutine 函数捕获。这意味着 goroutine 保留对 ch 的引用。因为 goroutine 泄漏了(永远不会终止),所以通道 ch 也将在程序的整个生命周期内保留在内存中。它不能被垃圾回收,因为泄漏的 goroutine 持有对它的引用。
因此,务必确保每个启动的goroutine都有 明确的、可达到的退出条件。使用 context 包来控制生命周期(我们稍后详述),或者确保channel会被关闭或有数据发送/接收。对于使用 sync.WaitGroup 的情况,确保 Done() 一定会被调用。
过多的Goroutine带来的开销
虽然单个goroutine很轻量,但启动过多(比如无限制地为每个入站请求启动多个goroutine)仍然会带来不可忽视的开销:
-
内存消耗:每个goroutine至少有几KB的栈,百万个goroutine就需要GB级别的内存。
-
调度器压力:Go运行时调度器需要管理所有活动的goroutine,过多的goroutine会增加调度的复杂度和开销,上下文切换虽然比线程切换快,但也不是零成本。
-
资源竞争:大量的goroutine可能同时竞争CPU、内存带宽、锁或其他资源,导致性能下降而非提升。
-
GC压力:更多的goroutine栈对象也需要GC扫描。
因此,在实际开发中,不建议无限制地创建goroutine。对于需要处理大量并发任务的场景,可使用 Worker Pool 模式来复用和限制goroutine的数量,或者使用带缓冲channel作为信号量来控制并发度。下面是一个用channel做信号量控制并发度的示例:
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
// 模拟一个耗时任务
func simulateTask(id int) {
duration := time.Duration(rand.Intn(3)) * time.Second // 模拟任务耗时 0-3 秒
fmt.Printf("Task %d: Starting, will take %s\n", id, duration)
time.Sleep(duration)
fmt.Printf("Task %d: Finished\n", id)
}
func main() {
rand.Seed(time.Now().UnixNano()) // 初始化随机数种子,确保每次运行结果不同
numTasks := 20 // 总任务数量
concurrencyLimit := 5 // 并发度限制
// 创建一个带缓冲的 channel 作为信号量
semaphore := make(chan struct{}, concurrencyLimit)
var wg sync.WaitGroup // 用于等待所有 goroutine 完成
for i := 1; i <= numTasks; i++ {
wg.Add(1) // 增加等待计数器
go func(taskID int) {
defer wg.Done() // goroutine 结束时减少等待计数器
// 获取信号量:向 channel 发送一个值(空结构体)
semaphore <- struct{}{} // 阻塞直到 channel 有空位
// 执行任务
simulateTask(taskID)
// 释放信号量:从 channel 接收一个值
<-semaphore
}(i)
}
wg.Wait() // 等待所有 goroutine 完成
fmt.Println("All tasks finished.")
}
示例中的semaphore channel就像一个许可证池。每个goroutine 在开始执行任务之前必须获得一个许可证(通过向 channel 发送数据)。当所有许可证都已发放时(channel 已满),新的 goroutine 必须等待,直到有许可证被释放 (通过从 channel 接收数据)。这确保了同时运行的 goroutine 的数量永远不会超过 concurrencyLimit。运行此程序,你会看到任务按批次启动,每批次最多 concurrencyLimit(5)个任务同时运行。程序会等待所有任务完成,然后退出。
主Goroutine退出问题(再强调)
主函数(main goroutine)的退出会导致整个程序的立即终止,不会等待其他goroutine完成,我们必须使用 sync.WaitGroup、channel 或其他同步机制来确保所有必要的goroutine都执行完毕。在前面的示例中已经演示了这一点,这里就不赘述了。
调度器与NUMA架构的不感知
当前的Go运行时调度器,在设计上 并未针对非一致性内存访问(NUMA)架构进行优化。
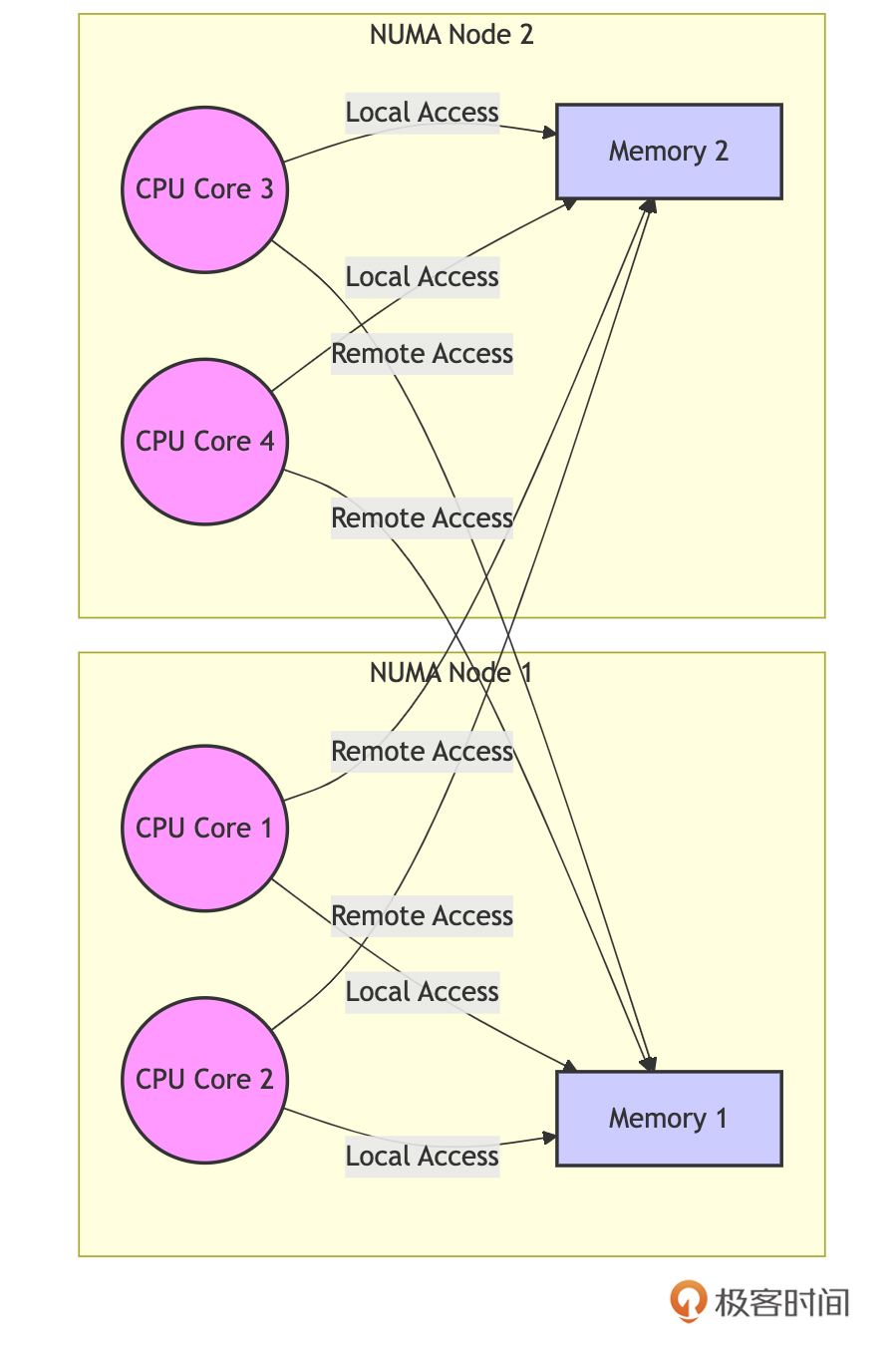
如上图所示,在拥有多个CPU插槽(socket)和各自独立内存区域的NUMA服务器上,Go调度器可能将一个goroutine调度到与它所需访问的内存关联的CPU节点不同的另一个CPU节点上运行。这种跨节点的内存访问延迟会显著高于访问本地内存,可能导致性能瓶颈。
对于性能极其敏感且部署在NUMA服务器上的应用,一些开发者会采用 手动绑核(CPU Affinity)的策略,尝试将特定的goroutine(或支撑它们的OS线程)绑定到特定的CPU核心或NUMA节点上,以确保计算和数据访问的局部性。这通常需要借助第三方库或操作系统提供的工具(不如numactl),是一种高级且需要谨慎使用的优化手段。
理解goroutine的轻量特性及其背后的实现机制,同时警惕这些潜在的陷阱和限制,是编写高效、健壮Go并发程序的基础。接下来,我们将探讨goroutine之间沟通的桥梁——channel。
Channel:不仅仅是管道
如果说goroutine是Go并发的执行单元,那么channel就是它们之间沟通的桥梁和同步的纽带。 Go推崇“通过通信来共享内存”,channel正是这一理念的具象化体现。
Channel提供了一种类型安全的方式,让goroutine可以发送和接收特定类型的值。更重要的是,channel的操作本身就包含了同步机制。
创建与类型
Go使用内置的 make 函数来创建channel:
// 创建一个只能传递 int 值的 channel
chInt := make(chan int) // 无缓冲 channel
// 创建一个可以缓冲 5 个 string 值的 channel
chStr := make(chan string, 5) // 带缓冲 channel
-
无缓冲(Unbuffered)Channel:容量为0。发送者(
ch <- val)和接收者(<-ch)必须 同时 准备好进行通信,否则先到达的一方会 阻塞 等待另一方。这种阻塞行为使得无缓冲channel成为一种强大的 同步 工具。 -
带缓冲(Buffered)Channel:拥有一个有限容量的队列。
-
发送操作只有在缓冲区 满 时才会阻塞。
-
接收操作只有在缓冲区 空 时才会阻塞。
-
它允许发送和接收在一定程度上 解耦 和 异步,可以用来平滑突发流量或作为简单的队列。
-
基本操作回顾
我们用一个简单的生产者-消费者示例回顾和强化一下Channel的基本操作:
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
func producer(id int, ch chan<- int, wg *sync.WaitGroup) { // chan<- 表示只发送channel
defer wg.Done()
for i := 0; i < 3; i++ {
data := id*10 + i
fmt.Printf("Producer %d sending: %d\n", id, data)
ch <- data // 发送数据
time.Sleep(time.Duration(rand.Intn(100)) * time.Millisecond)
}
}
func consumer(ch <-chan int, done chan struct{}) { // <-chan 表示只接收channel
// 使用 for range 优雅地接收,直到 channel 关闭
for data := range ch {
fmt.Printf("Consumer received: %d\n", data)
time.Sleep(time.Duration(rand.Intn(200)) * time.Millisecond)
}
fmt.Println("Consumer finished as channel closed.")
done <- struct{}{}
}
func main() {
ch := make(chan int, 3) // 带缓冲 channel
var wg sync.WaitGroup
var done = make(chan struct{})
go consumer(ch, done) // 启动消费者
numProducers := 2
wg.Add(numProducers)
for i := 0; i < numProducers; i++ {
go producer(i, ch, &wg) // 启动生产者
}
wg.Wait() // 等待生产者完成
close(ch)
<-done // 等待消费者完成
fmt.Println("Main finished.")
}
这段示例代码演示了使用带缓冲的 Channel 实现生产者-消费者模式。 多个生产者 goroutine 向 Channel 发送数据,一个消费者 goroutine 从 Channel 接收数据。 代码使用 sync.WaitGroup 来同步生产者和主 goroutine,并使用 close 函数关闭 Channel,通知消费者不再有新的数据。消费者goroutine与主goroutine的同步则是由一个无缓冲的 channel 充当的“信号”来实现的,当所有生产者退出后,主Goroutine关闭带缓冲的channel(ch)来通知消费者不再有新的数据发送到 Channel,然后主goroutine通过<-done等待消费者完成。消费者的for range 循环在接收到 Channel 关闭的信号后会退出。消费者通过done channel向主goroutine发送结束信号。
Channel的进阶提示与陷阱
Channel虽然优雅,但也隐藏着不少陷阱,尤其是在涉及阻塞、关闭和 nil channel时。下面我们逐一来看。
死锁:永久阻塞
这是最常见的channel问题。当一个goroutine尝试对一个channel进行操作(发送或接收),但永远没有其他goroutine来进行配对操作时,就会发生死锁。我们来看三个典型的死锁示例。
- 向无缓冲channel发送但无接收者,示例代码如下:
func deadlockSend() {
ch := make(chan int) // 无缓冲
ch <- 1 // 尝试发送,但没有接收者,永久阻塞 -> deadlock
fmt.Println("Sent?") // 不会执行
}
Go运行时能检测到这种所有 goroutine 都阻塞的情况并 panic (fatal error: all goroutines are asleep - deadlock!),下面要讲到的示例情况也是如此。
- 空channel接收但无发送者,示例代码如下:
func deadlockReceive() {
ch := make(chan int) // 无缓冲
val := <-ch // 尝试接收,但没有发送者,永久阻塞 -> deadlock
fmt.Println("Received:", val) // 不会执行
}
- 带缓冲channel死锁,示例代码如下:
func deadlockBuffered() {
ch := make(chan int, 1) // 容量为 1
ch <- 1 // 发送成功 (缓冲区未满)
ch <- 2 // 尝试发送,缓冲区已满,阻塞 -> deadlock
fmt.Println("Sent 2?") // 不会执行
}
因此,我们要确保channel的发送和接收操作能够匹配。对于无缓冲channel,发送和接收必须成对出现。对于带缓冲channel,要考虑缓冲区大小。使用 select 可以处理阻塞情况,这个在下面会有说明。
死锁:操作 nil Channel
对一个值为 nil 的channel进行发送或接收操作,会永久阻塞,同样导致死锁。
func deadlockNil() {
var ch chan int // ch is nil
// ch <- 1 // 发送操作,永久阻塞 -> deadlock
<-ch // 接收操作,永久阻塞 -> deadlock
}
因此,在使用channel前,务必确保它已经被 make 初始化。在 select 语句中,对 nil channel 的 case 永远不会被选中,可以利用这个特性来动态禁用某个 case,接下来也会说明。
Panic:关闭Channel相关的操作
以下关闭Channel的操作会导致运行时 panic:
-
关闭一个
nilchannel。 -
关闭一个已经被关闭的 channel。
-
向一个已经被关闭的 channel 发送数据。
下面是一个示例:
func panicClose() {
// var chNil chan int
// close(chNil) // panic: close of nil channel
ch := make(chan int, 1)
close(ch)
// close(ch) // panic: close of closed channel
// ch <- 1 // panic: send on closed channel
}
为此,我们要遵循 “不要从接收端关闭 channel,也不要关闭有多个并发发送者的 channel” 的原则。关闭操作应由唯一的发送者,或最后一个确定不再发送的发送者执行,或者像上面示例那样,当发送者都发送结束后,由主Goroutine执行关闭操作。
关闭 Channel 后的接收行为
对已关闭的channel进行接收操作是安全的,并且 不会阻塞。常用的从可能已关闭的channel中读取数据的操作语句如下:
val, ok := <-ch
如果 ch 的缓冲区中还有值,会依次接收这些值,并且 ok 为 true;当缓冲区为空后,后续的接收操作会立即返回该channel元素类型的 零值,并且 ok 为 false。
下面是一个具体的示例:
func receiveFromClosed() {
ch := make(chan int, 2)
ch <- 1
ch <- 2
close(ch)
val1, ok1 := <-ch
fmt.Println(val1, ok1) // 输出 1 true
val2, ok2 := <-ch
fmt.Println(val2, ok2) // 输出 2 true
val3, ok3 := <-ch
fmt.Println(val3, ok3) // 输出 0 false (零值, ok为false)
val4, ok4 := <-ch
fmt.Println(val4, ok4) // 输出 0 false (零值, ok为false)
// for range 会在 channel 关闭且读完所有缓冲值后自动结束
// for val := range ch { // 如果在这里用 for range,它会读完 1, 2 然后退出
// fmt.Println("Range received:", val)
// }
}
理解这个行为,对于使用 for range 遍历channel或需要判断channel是否已关闭并取完数据的场景至关重要。
Channel 的传递
Channel在运行是层面的表示,与map和slice类似,都存储的是指向底层数据结构的指针。将channel传递给函数时,传递的是这个指针的副本,它们指向同一个底层channel。因此,在函数内部对channel的操作(发送、接收、关闭)会影响到函数外部。下面示例演示了这一点:
func closeChan(ch chan int) {
close(ch) // 关闭操作会影响 main 中的 ch
}
func main() {
ch := make(chan int)
// go func(){ <-ch }() // 启动一个接收者避免死锁
closeChan(ch)
// ch <- 1 // 会 panic,因为 ch 已经被关闭
_, ok := <-ch // 接收会立即返回 0, false
fmt.Println("Channel closed?", !ok) // 输出 true
}
掌握channel的这些进阶用法和潜在陷阱,是利用它构建可靠、高效并发程序的关键。Channel虽然强大,但也需要谨慎使用,避免死锁和panic。
接下来,我们将看到当简单的goroutine和channel不足以应对更复杂的并发协调时,需要用到哪些更强大的工具。
超越基础原语:何时需要 select、sync 包与 Context?
Goroutine 和 Channel 构成了Go并发编程的基础,足以应对许多并发场景。但现实世界的并发问题往往更加复杂。当你需要处理以下情况时,就可能需要超越这两个基础原语了:
-
需要同时等待 多个 Channel 事件,并根据哪个先发生来采取不同行动?
-
需要保护 共享内存(如共享变量、数据结构)的访问,防止多个 goroutine 同时修改导致数据错乱?
-
某些简单的状态更新(如计数器、标志位)需要 无锁 的原子操作来保证效率和正确性?
-
需要一种机制来 协调 多个 goroutine,等待它们全部完成?
-
需要跨 goroutine 传递取消信号或截止时间?
Go 标准库为此提供了更强大的工具: select 语句、 sync 包以及 context 包。
select 语句:多路复用与超时控制
select 是 Go 语言在 channel 操作上的瑞士军刀。它允许你同时等待多个 channel 的发送或接收操作,并在其中任意一个操作就绪(可以执行而不会阻塞)时,执行相应的 case 分支。
基础用法回顾
我们用一个多channel的选择示例来回顾和强化一下select的基本操作:
package main
import (
"fmt"
"time"
)
func main() {
ch1 := make(chan string, 1)
ch2 := make(chan string, 1)
go func() { time.Sleep(100 * time.Millisecond); ch1 <- "from ch1" }()
go func() { time.Sleep(50 * time.Millisecond); ch2 <- "from ch2" }()
// 等待 ch1 或 ch2 先到达
select {
case msg1 := <-ch1:
fmt.Println("Received:", msg1)
case msg2 := <-ch2:
fmt.Println("Received:", msg2) // 这个会先执行
case <-time.After(200 * time.Millisecond): // 设置超时
fmt.Println("Timeout waiting for channels.")
// default: // 添加 default 使 select 非阻塞
// fmt.Println("No channel ready right now.")
}
}
这段代码使用 select 语句来同时监听多个 Channel,并在其中一个 Channel 接收到数据时执行相应的操作。它还使用了 time.After 函数(返回一个channel)来设置超时,防止程序无限期地等待。
select进阶提示与陷阱
select这把“军刀”虽然强大,但也隐藏着不少陷阱,尤其是在涉及channel选择、阻塞等行为时。下面我们逐一来看。
首先是随机选择(Random Selection)。 如果 select 语句在某一时刻有多个 case同时就绪,它会伪随机地选择其中一个执行。不能假设它会按代码顺序或其他任何固定顺序选择。下面这个示例很好地展示了这一点:
package main
import (
"fmt"
)
func selectRandom() {
ch1 := make(chan int, 1)
ch2 := make(chan int, 1)
ch1 <- 1
ch2 <- 2
// ch1 和 ch2 都已就绪
select {
case <-ch1:
fmt.Println("Received from ch1")
case <-ch2:
fmt.Println("Received from ch2")
}
}
func main() {
for range 5 {
selectRandom()
}
}
多次运行这个示例,你会发现有时输出 ch1,有时输出 ch2。因此,你在日常使用select时,务必注意不要依赖 select 的选择顺序来实现特定的逻辑。
然后是阻塞行为。 如果 select 中没有 default 分支,并且所有 case 上的 channel 操作都不能立即执行(即都会阻塞),那么整个 select 语句会阻塞,直到其中至少一个 channel 操作变得可以执行。比如下面这个示例:
func selectBlockingDeadlock() {
ch := make(chan int) // 无缓冲,也无发送者
fmt.Println("Waiting on select...")
select {
case <-ch: // 无法接收,阻塞
fmt.Println("Received something?")
}
// 如果没有其他 goroutine 向 ch 发送,这里会死锁
fmt.Println("Select finished?")
}
因此,在使用select时,我们要确保 select 监听的 channel 最终会有事件发生,或者提供 default 或超时 case 来避免永久阻塞。
接着是 nil Channel Case 的妙用。 对 nil channel 进行读或写操作的 case 永远不会被选中。我们可以利用这一点来动态地启用或禁用 select 中的某个 case。看下面示例:
package main
import (
"fmt"
)
func selectNilCase(sendData bool) {
dataCh := make(chan int, 1)
var sendCh chan<- int // 初始为 nil
if sendData {
sendCh = dataCh // 如果需要发送,让 sendCh 指向 dataCh
sendCh <- 100 // 发送数据 (如果 sendData 为 true)
}
select {
case val := <-dataCh: // 接收 case
fmt.Println("Received:", val)
case sendCh <- 200: // 发送 case, 如果 sendCh 为 nil,此 case 无效
fmt.Println("Sent 200")
default:
fmt.Println("Default case executed.")
}
}
func main() {
selectNilCase(true) // Received: 100
selectNilCase(false) // Default case executed.
}
我们看到如果 sendData 为 false,sendCh 为 nil,那发送 case 无效。如果 sendData 为 true,sendCh 指向 dataCh,缓冲区可能满,那发送 case 可能阻塞或执行。将channel变量设为 nil 是临时“关闭” select 中对应 case 的常用技巧,这种技巧可以用于动态控制 select 语句的行为、避免不必要的阻塞和优雅地处理错误。
最后是空 select (Empty Select)。 一个没有任何 case 的 select {} 语句会永久阻塞。这有时被用作一种让 goroutine 等待(例如,等待程序结束信号)的简单方式,虽然使用 channel 或 sync.WaitGroup 通常更清晰。
func selectEmptyBlock() {
fmt.Println("Entering empty select block...")
select {} // 永久阻塞当前 goroutine
// fmt.Println("This will never be printed.")
}
掌握 select 的上述这些行为特性,是编写复杂、健壮的 Go 并发程序的关键。
sync 与 atomic:当共享内存是必须时
虽然 Go 推崇通过 channel 通信,但现实中, 共享内存配合锁或原子操作仍然是解决许多并发问题的有效甚至更优的手段,尤其是在对性能要求极高或需要保护复杂数据结构状态的场景。Go同样提供了针对共享内存方案的原语支持,下面我们简单看一下。
sync.Mutex 与 sync.RWMutex
sync.Mutex 与 sync.RWMutex是最基础也是最重要的共享内存保护机制。
sync.Mutex (互斥锁) 保证同一时刻只有一个 goroutine 能进入被其保护的代码临界区。适用于任何需要独占访问共享资源的场景。
var counter int
var mu sync.Mutex // 保护 counter
func incrementCounter() {
mu.Lock() // 获取锁
counter++
mu.Unlock() // 释放锁
}
// 更安全的做法,保证 Unlock 总被调用
func safeIncrement() {
mu.Lock()
defer mu.Unlock() // 推荐使用 defer 释放锁
counter++
}
使用sync.Mutex时要注意以下事项:
-
锁的粒度:保护的代码范围应尽可能小,只包含必要的操作,避免持有锁时间过长影响并发度。
-
死锁:多个 goroutine 获取多个锁时,必须保证所有 goroutine 都按相同顺序获取锁,否则极易死锁。
-
不要拷贝:
Mutex包含内部状态,不能被拷贝。应传递其指针。
sync包提供了RWMutex用于 读多写少 的场景,该RWMutex允许多个“读”操作并发进行,但“写”操作会保证独占。RWMutex可以显著提高并发读的性能。下面是一个应用RWMutex的典型示例:
var configData map[string]string
var configMu sync.RWMutex // 保护 configData
func getConfig(key string) (string, bool) {
configMu.RLock() // 获取读锁 (共享)
defer configMu.RUnlock()
val, ok := configData[key]
return val, ok
}
func setConfig(key, value string) {
configMu.Lock() // 获取写锁 (独占)
defer configMu.Unlock()
configData[key] = value
}
RWMutex在使用上“门槛”略高于Mutex,并且 RWMutex 本身比 Mutex 复杂,开销略高。如果读写比例不悬殊,或者写竞争激烈, Mutex 可能反而性能更好。需要根据实际场景的benchmark再决定究竟使用哪种锁。和Mutex一样,RWMutex也有内部状态,同样不可拷贝。
atomic 包(原子操作)
对于非常简单的基础类型(各种 int、 uint、 uintptr、 unsafe.Pointer)的共享访问,如果操作本身是原子的(如简单的增减、比较并交换 CAS、加载、存储),使用 sync/atomic 包提供的函数通常比使用锁效率更高,因为它直接利用了 CPU 提供的原子指令,避免了锁的开销和可能的上下文切换。
import "sync/atomic"
var counter int64 // 必须是 int64 或 int32 等 atomic 支持的类型
func atomicIncrement() {
atomic.AddInt64(&counter, 1) // 原子增 1
}
func getCounterAtomic() int64 {
return atomic.LoadInt64(&counter) // 原子读
}
然而,在多核高并发环境下,原子操作的扩展性也并非没有“天花板”。 尽管单个原子指令执行很快,但当多个CPU核心高频地对 同一块内存(通常是同一个缓存行 Cache Line) 上的原子变量进行写操作时,CPU为了维护缓存一致性(例如通过MESI协议),会导致该缓存行在不同核心的缓存之间频繁同步和失效。这种现象,尤其是在“真共享(True Sharing)”争用下,会导致所谓的“缓存行乒乓(Cache Line Ping-Ponging)”,带来显著的内存访问延迟。
这意味着,一个简单的原子计数器在核心数非常多,且所有核心都在激烈竞争更新这同一个计数器时,其性能可能远不如预期,甚至成为瓶颈。这个问题不仅影响直接使用原子操作的代码,也可能间接影响依赖原子操作实现内部状态管理的标准库并发原语(例如 sync.RWMutex 内部的读者计数器,在高并发读场景下,其原子更新就可能因此产生争用,限制了读操作的扩展性)。
Go 社区也一直在关注和探索解决这类多核扩展性问题的方案,例如通过设计 per-P(Go调度器中的Processor)或 per-M(OS Thread)的数据结构(如一些提案中讨论的 ShardedValue、 PLocalCache、 MLocal 等思路),将数据分片或本地化,以减少跨核心的共享内存争用,从而更好地发挥 Go 在现代多核硬件上的并发潜力。
不过,即便有这些深层次的性能考量,原子操作的适用范围仍然是明确的:它们主要用于 atomic 包支持的类型和操作,无法保护复杂数据结构或多个操作的原子性。并且,对于复杂逻辑,使用原子操作可能比锁更难理解和维护。因此,在选择时,需要权衡简洁性、预期的并发级别、争用情况以及对极致性能的需求。
其他 sync 原语
sync 包还提供了一些辅助并发逻辑编写的原语,这里我们来简单说明一下它们各自的特点和适用场景。
首先是 sync.WaitGroup。
你可能已经很熟悉 sync.WaitGroup 了,它是我们用来等待一组 goroutine 完成任务的常用工具,前面也多次出现过它的身影。虽然好用,但其经典的 wg.Add(1), go func(){ defer wg.Done() ... }(), wg.Wait() 的三段式用法,虽然模式固定,但开发者(尤其是新手)偶尔会忘记调用 Done,或者错误地将 Add 放在了 goroutine 内部,导致潜在的死锁或 panic。
为了解决这些痛点,Go 社区有一个广受关注的提案( #63796),建议为 WaitGroup 增加一个 Go(f func()) 方法。这个方法会封装 Add(1),启动 goroutine 以及 defer Done() 的逻辑,使得启动和管理一个由 WaitGroup 追踪的 goroutine 变得异常简洁和安全,如 wg.Go(func() { /* 你的任务代码 */ })。这个提案已标记为 “Likely Accept”,我们很有可能在未来的 Go 版本(如 Go 1.25 或之后)中看到它成为标准库的一部分,进一步提升并发编程的体验。这一改进也得益于 Go 1.22 中 for 循环变量语义的修正,使得在闭包中直接使用循环变量更加安全。
如果你不仅需要等待一组 goroutine 完成,还关心它们是否出错,并希望在任何一个 goroutine 出错时能够 取消 其他 goroutine 的执行时, sync.WaitGroup 就显得力不从心了。这时, errgroup(位于 golang.org/x/sync/errgroup 包)就派上了大用场。
errgroup.Group 提供了类似 WaitGroup 的功能,但它额外处理了 错误传播 和基于 context 的 取消机制。你可以用 group.Go(func() error { ... }) 来启动一个任务,这个函数需要返回一个 error。 group.Wait() 会等待所有由 Go 方法启动的 goroutine 完成,并返回遇到的 第一个非nil错误。如果其中一个任务返回错误,或者传递给 errgroup.WithContext 的 context 被取消,那么与该 group 关联的 context 也会被取消,从而通知所有其他正在运行的任务尽快退出。 errgroup 的设计与我们前面讨论的 context 包完美结合,非常适合管理一组可能出错并需要级联取消的并发任务。许多流行的第三方库和实际项目中都能看到它的身影。
接着是 sync.Once。 sync.Once 可以确保某个初始化动作 只执行一次,即使在多个 goroutine 并发调用 Do 方法的情况下也是如此。这对于实现单例模式的延迟初始化、全局配置加载等场景非常有用,可以避免竞态条件和不必要的重复工作。
var once sync.Once
var config *MyConfig
func GetConfig() *MyConfig {
once.Do(func() {
// 这里的代码只会被执行一次
config = loadConfigFromSomewhere()
fmt.Println("Config loaded.")
})
return config
}
然后是 sync.Cond(条件变量)。 sync.Cond 是 Go 语言中提供的一种复杂的 goroutine 间同步机制,它允许 goroutine 等待某个特定条件的成立,并在条件变化时通知其他正在等待的 goroutine。使用 sync.Cond 时,通常会与一个 Locker(如 *sync.Mutex)一起使用,以确保条件判断和状态变更的原子性。
sync.Cond 提供了三个主要方法: Wait()、 Signal() 和 Broadcast()。其中, Wait() 方法会原子性地解锁其关联的 Locker,并将调用该方法的 goroutine 置于等待状态,直到被 Signal() 或 Broadcast() 唤醒。唤醒后, Wait() 会重新锁定 Locker。 Signal() 方法则用于唤醒一个正在等待该条件的 goroutine,而 Broadcast() 方法则用于唤醒所有正在等待该条件的 goroutine。
需要注意的是, sync.Cond 是一种相对底层的同步机制,使用时必须仔细管理锁和条件判断,以避免出现死锁或虚假唤醒(spurious wakeup)的情况,即 goroutine 被唤醒但条件仍未满足。在许多场景中,使用 channel 或其他更高级的同步原语可能会提供更简洁的解决方案。然而,对于那些需要精细控制等待和通知逻辑的复杂同步问题, sync.Cond 仍然是一个不可或缺的工具。
然后我们来看 sync.Pool。 sync.Pool 是 Go 语言中的一种原语,主要用于复用临时对象,以减轻垃圾收集器(GC)的压力。当需要频繁创建和销毁大量相同类型的、生命周期短暂的对象时,例如在处理网络请求时使用的缓冲区, sync.Pool 可以有效地缓存这些对象,从而减少内存分配和 GC 扫描的开销。
需要注意的是, sync.Pool 并不是一个通用的缓存工具。池中的对象可能会在没有任何通知的情况下被 GC 回收,尤其是在两次 GC 之间未被使用时。因此,它不适合用于存储有状态或必须持久化的对象。
总的来说, sync.Pool 是一个性能优化工具。是否使用它以及如何配置其 New 函数(用于在池为空时创建新对象),通常需要通过基准测试来验证其实际效益。合理地利用 sync.Pool 可以显著提高应用程序的性能,特别是在高频率对象创建和销毁的场景中。
最后我们来看 sync.Map。 这是 Go 1.9 引入的一个内置的并发安全的 map。与普通的 map 配合 sync.Mutex 或 sync.RWMutex 来保护并发访问相比, sync.Map 在某些特定场景下(主要是读多写少,或者大量不相交的写操作)能提供更好的性能,因为它采用了一些更细粒度的锁策略和无锁技术。
我们在 第 06 讲 中已经对 sync.Map 的适用场景和内部机制做过探讨,这里就不再赘述。
选择 sync 包还是 channel?
既生瑜何生亮!Go既提供了体现“通过通信来共享内存”哲学的channel,也提供了传统基于共享内存并发模型的sync包和原子操作,那么我们该如何选择使用哪种并发原语呢?
通常在需要传递数据或所有权或需要简单同步的场景中先考虑 channel。如果需要保护共享内存状态或实现临界区,又或者需要更高性能的并发,则更多使用 Mutex/RWMutex。对于需要高性能无锁更新简单计数器/标志的场景, atomic 则更为适合。而像 errgroup 这样的工具,则是在 WaitGroup 和 context 基础上,针对特定并发模式(如带错误传播和取消的goroutine组)的进一步封装和优化。
Context 包:超越同步,实现控制与传值
我们已经看到 select 可以处理多路 channel 和超时, sync 可以保护共享数据。但它们都难以解决跨越整个请求处理链路(可能涉及多个 goroutine、多个函数调用、甚至跨服务调用)的取消传播和截止时间控制的问题,也难以优雅地传递 请求范围的上下文信息(如 Request ID、用户认证信息)。
这正是 context 包的用武之地。它提供了一种标准化的方式来携带这些跨越 API 边界的信号和值。 Context 就像一根贯穿整个调用链的“指挥棒”,下游的函数和 goroutine 可以通过它:
-
检查是否应该提前取消工作(因为上游已经取消或超时)。
-
了解整个操作的最终截止时间。
-
获取与当前请求相关的特定值。
context 包是现代 Go Web 开发、微服务以及任何涉及复杂异步流程的标准实践。它的引入极大地提升了 Go 程序在处理超时、取消以及传递请求元数据方面的健壮性和优雅性。
由于 context 的重要性和其独特的设计,我们在接下来的内容中会对其进行更详细的探讨,学习它的核心接口、实现机制和最佳实践。
context详解:优雅处理超时、取消与请求值传递
在了解了goroutine、channel以及更传统的 sync 原语后,我们再聚焦于Go并发编程中一个极其重要且独特的工具—— context 包。正如我们之前提到的,当简单的同步或数据传递不足以应对跨goroutine的请求生命周期管理、超时控制、取消传播以及请求范围的值传递时, context 就成了不二之选。
context 包自Go 1.7加入标准库以来,已成为编写健壮网络服务和并发程序的基石。它提供了一套标准的接口和机制,让我们能够优雅地处理这些复杂场景。那么, context 是如何做到这一切的呢?让我们深入它的核心设计。
核心接口:Context 的四个“能力”
context 包的核心就是 Context 接口类型,它定义了上下文应该具备的四种能力:
// $GOROOT/src/context/context.go
type Context interface {
// Deadline 返回工作应该被取消的时间。如果没有设置截止时间,ok 返回 false。
Deadline() (deadline time.Time, ok bool)
// Done 返回一个 Channel。当代表此上下文的工作被取消时,此 Channel 会被关闭。
// 如果此上下文永远不会被取消,Done 可能返回 nil。
Done() <-chan struct{}
// Err 在 Done 返回的 Channel 被关闭后,返回一个非 nil 的错误。
// 如果上下文被取消,返回 Canceled;如果上下文超时,返回 DeadlineExceeded。
Err() error
// Value 返回与此上下文关联的键 key 对应的值,如果不存在则返回 nil。
Value(key any) any
}
我们可以将这四个方法分为两类,对应 context 要解决的两大问题。
第一类:控制传递(Cancellation & Deadline)。 Deadline()、 Done()、 Err() 这三个方法共同构成了上下文的控制机制。
-
Done()是核心,它提供了一个只读channel。下游的goroutine应该监听这个channel。一旦它被关闭,就意味着收到了取消或超时的信号,应该停止当前工作并清理资源。 -
Err()用于在Done()关闭后,获取具体的取消原因(是手动取消context.Canceled还是超时context.DeadlineExceeded)。 -
Deadline()则允许获取设置的截止时间(如果有的话)。
第二类:值传递(Request-scoped Values)。 Value(key any) 方法用于在函数调用链或goroutine之间传递请求范围的值,如Trace ID、用户身份等。
仅仅定义接口是不够的。 context 包的精妙之处在于它提供了一系列函数来创建和派生具有不同能力的 Context 实例,并内置了这些接口的具体实现。
创建与派生 Context:构建上下文关系树
一个典型的Go程序中,Context通常形成一个树状结构。树的根节点通常是一个 “Background” Context,而后续的操作会基于父Context派生出子Context。这种树状结构是理解取消信号传播和值传递的关键。
根 Context( Background 与 TODO)
Go context包提供了两种创建根Context的方法。
-
context.Background():返回一个非nil、永不取消、没有值、没有截止时间的空Context。它通常用在main函数、初始化、或请求处理的最顶层,作为所有Context树的根。 -
context.TODO():功能与Background()完全相同。它的存在是为了提示开发者:当你还不确定应该使用哪个Context,或者当前函数未来计划接收一个Context参数时,可以临时用TODO()作为占位符。
这两个函数返回的都是内部类型 emptyCtx 的实例,它们本身不携带任何信息或控制能力,仅仅作为派生的起点。
派生 Context
基于一个父Context创建新的子Context。子Context会继承父Context的取消信号和值。下面是context包提供的常用的创建子Context的函数:
-
context.WithCancel(parent Context) (ctx Context, cancel CancelFunc):创建可手动取消的子Context。 -
context.WithDeadline(parent Context, d time.Time) (Context, CancelFunc):创建带截止时间的子Context。 -
context.WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc):创建带超时的子Context。 -
context.WithValue(parent Context, key, val any) Context:创建携带键值对的子Context。
Context 树状结构示例
为了更好地理解Context的树型结构,我绘制了一个Context 树状结构示意图,如下所示:
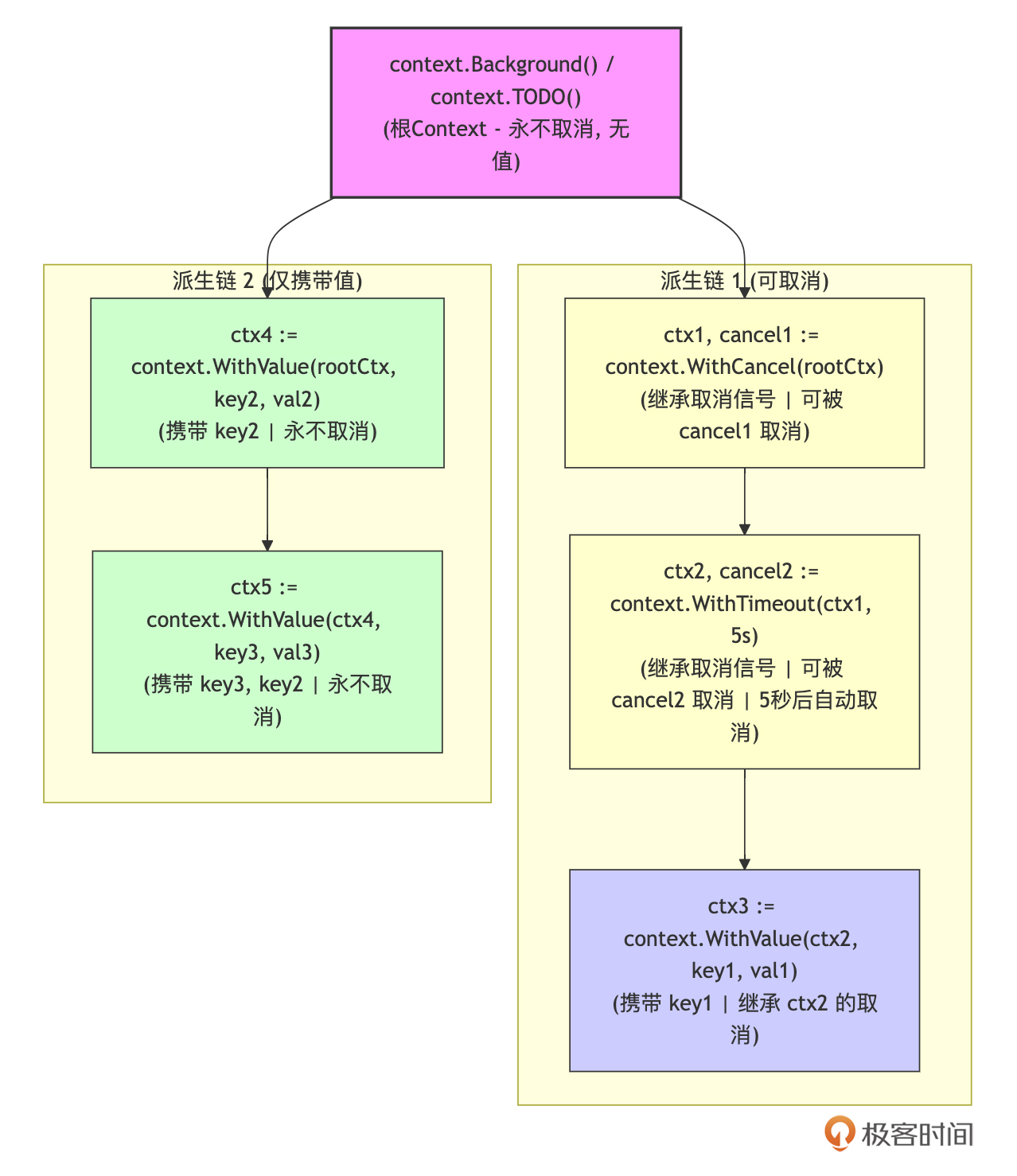
这张图展示了从根 Context 派生出不同类型子 Context 的关系。
-
rootCtx:代表树的根,由context.Background()或context.TODO()创建。 -
派生链1 展示了可取消Context的链式派生:
-
ctx1(通过WithCancel)可被手动取消。 -
ctx2(通过WithTimeout)继承ctx1的取消,并增加超时自动取消。 -
ctx3(通过WithValue)携带值(key1, val1),并继承ctx2的取消特性。取消信号会从rootCtx->ctx1->ctx2->ctx3向下传播。
-
-
派生链2 展示了仅携带值的派生:
-
ctx4和ctx5通过WithValue创建,它们携带值,但因为它们的祖先rootCtx永不取消,所以它们自身也无法被取消。 -
ctx5可以通过Value()方法访问到key3和key2的值(向上查找)。
-
理解这个树状结构和派生关系,对于掌握 Context 的取消传播和值传递机制至关重要。
关于cancel函数
对于 WithCancel、 WithDeadline 和 WithTimeout,它们都返回一个 cancel 函数。调用这个函数会:
-
关闭当前 Context 的
Done()channel。 -
递归地取消所有由当前 Context 派生出的子 Context。
-
释放当前 Context 占用的资源(如计时器)。
要注意,返回的 cancel 函数 务必要被调用,以避免资源泄漏。最常用的方式是使用 defer cancel()。
关于WithValue的key
前面说过,WithValue 函数是用于创建包含键值对的上下文的函数。它主要用于传递请求作用域的数据,并且应该避免滥用。 为了避免不同包之间的键冲突, WithValue 的 key 不应使用内置类型(如 string),而应该为上下文的键定义自己的类型。 通常使用 struct{} 作为键的类型,因为 struct{} 不占用任何内存,并且可以保证唯一性。
下面就是一个基于 struct{} 自定义WithValue键类型的示例:
package main
import (
"context"
"fmt"
)
// 定义一个上下文键类型
type requestIDKey struct{}
func main() {
// 创建一个根上下文
ctx := context.Background()
// 创建一个派生的上下文,并添加一个请求 ID
ctx = context.WithValue(ctx, requestIDKey{}, "12345")
// 从上下文中获取请求 ID
requestID := ctx.Value(requestIDKey{}).(string) // 需要类型断言
fmt.Println("Request ID:", requestID) // 输出:Request ID: 12345
// 传递上下文给其他函数
processRequest(ctx)
}
func processRequest(ctx context.Context) {
// 从上下文中获取请求 ID
requestID := ctx.Value(requestIDKey{}).(string)
fmt.Println("Processing request with ID:", requestID) // 输出:Processing request with ID: 12345
}
如何优雅地使用 Context
掌握了创建和派生的方法后,正确使用Context还需要遵循一些约定和模式。
第一,作为函数首参数,命名 ctx。 使用ctx算是Go社区的强约定,比如:
func ProcessData(ctx context.Context, data MyData) error
第二,显式传递,不存入结构体。 Context 代表的是一次调用或请求的上下文,它应该是流动的。将其存入结构体字段通常意味着设计上可能存在问题(除非该结构体本身就代表一个长期运行的任务,且需要用Context控制其生命周期,但这种情况也需谨慎)。
第三,监听 Done() Channel。 这是响应取消信号的核心。对于任何可能长时间运行或阻塞的操作(网络请求、数据库查询、等待channel、复杂计算等),都应该在操作前或操作中通过 select 检查 ctx.Done(),比如下面示例:
func longRunningTask(ctx context.Context) error {
ticker := time.NewTicker(1 * time.Second)
defer ticker.Stop()
for {
select {
case <-ctx.Done(): // 检查取消信号
slog.Info("Task canceled", "error", ctx.Err())
return ctx.Err()
case <-ticker.C:
slog.Info("Working...")
// 做一小部分工作
}
}
}
第四,及时调用 cancel()。 对于 WithCancel、 WithDeadline 和 WithTimeout 返回的 cancel 函数,使用 defer cancel() 是确保资源释放的最简单可靠的方式。
第五,向下传递,而非取代。 当调用下游函数或启动新goroutine时,将当前 ctx(或基于它派生的新 ctx)传递下去。不要在中间环节用 context.Background() 或 TODO() 重新创建一个根Context,这会切断取消信号和值的传播链条。
第六, Value 的克制使用。 牢记 WithValue 的设计初衷和限制。它不是通用的参数传递机制。如果一个值不是贯穿请求始终的上下文信息,最好还是通过函数参数显式传递。
通过遵循这些原则和实践, context 就能成为你手中处理并发控制和信息传递的利器,帮助你编写出更健壮、更可预测、更易于维护的Go程序。
小结
这一讲,我们深入探讨了Go并发编程的核心武器库,从基础的 goroutine、channel 到更高级的 select、sync 包原语,并重点详解了现代Go并发不可或缺的 context 包。
-
Go并发模型的魅力:我们理解了goroutine为何轻量(低创建开销、动态栈、用户态调度M:N模型),以及channel作为类型安全、内置同步的通信管道的核心地位。同时,我们也警惕了 goroutine 泄漏、过多 goroutine 的开销、主 goroutine 退出以及当前调度器对 NUMA 不敏感等潜在问题和陷阱,并掌握了 channel 操作可能导致的死锁和 panic 情况,以及 channel 关闭的最佳实践。
-
超越基础原语:我们认识到,在复杂场景下需要更强大的工具。
select提供了多路 channel 复用的能力,并能优雅地实现超时和非阻塞逻辑,但也需要注意其随机选择和nilchannel case 的行为。当需要保护共享内存时,sync包的Mutex和RWMutex是基础工具,需要注意锁粒度、死锁和拷贝问题;atomic包则为基本类型提供了高效的无锁操作。WaitGroup和Once也是常用的同步辅助工具。 -
Context 的核心价值:我们明确了
context主要解决了其他原语难以优雅处理的、跨越 goroutine 的取消传播、截止时间控制和请求范围值传递等几大核心问题。 -
Context 详解与实践:我们掌握了
Context接口的四个方法(Deadline、Done、Err、Value),以及如何通过Background、TODO、WithCancel、WithDeadline、WithTimeout和WithValue来创建和派生 Context,构建上下文关系树。重点强调了监听Done()channel 以响应取消信号,以及必须调用cancel()函数(通常用defer)以释放资源这两大核心实践。同时,我们也学习了WithValue传递请求范围值的正确姿势(使用非导出 key 类型、传递必要信息、注意性能)。
理解并熟练运用 goroutine、channel、select、sync 原语以及 context 包,是编写健壮、高效、可维护的Go并发程序的关键。它们共同构成了Go语言在现代并发编程领域的核心竞争力,使得开发者能够以相对简洁的方式应对复杂的并发挑战。
思考题
假设在一个需要向多个下游服务(比如服务A、服务B、服务C)并行发起 RPC 调用的场景中,要求:
-
整个操作有一个总的超时时间(比如 500ms)。
-
只要有一个下游服务调用失败,就应该尽快取消其他还在进行的调用。
-
需要将请求的 Trace ID 传递给所有下游调用。
你会如何结合使用 goroutine、channel、 sync.WaitGroup、 context.WithTimeout、 context.WithCancel 和 context.WithValue 来实现这个逻辑?描述一下大致的思路或关键代码结构。
欢迎在留言区分享你的设计!我是Tony Bai,我们下节课见。
垃圾回收:便利≠免费,GC开销分析与优化实践
你好!我是Tony Bai。
Go语言最吸引人的特性之一,无疑是其内置的垃圾回收(GC)机制。它将我们从繁琐的手动内存管理中解放出来,让我们能更专注于业务逻辑,这无疑是巨大的便利。Go语言替我们承担了内存分配和回收的责任,大多数时候我们似乎无需关心内存细节。
但是,这份便利并非免费。GC在后台的辛勤工作,必然伴随着资源的消耗。你是否真正思考过:
-
这份“自动挡”的便利,究竟需要我们付出哪些隐性的性能代价?
-
GC的工作(标记、清除、写屏障、标记辅助)具体是如何导致CPU消耗、内存占用增加和程序响应延迟的?
-
如何分析出自己程序中的GC开销有多大?哪些工具可以帮助我们?
-
更重要的是,作为进阶开发者,我们能采取哪些优化实践来编写“GC友好”的代码,在享受便利的同时,最大限度地降低其成本,构建真正高性能的Go应用?
仅仅享受GC的便利而不理解其成本,可能会让我们在面对性能问题时束手无策。 只有深入分析GC开销的来源,并掌握行之有效的优化实践,才能在便利和性能之间找到最佳平衡点。
这节课,我们就直面“便利≠免费”这一现实,一起深入理解GC的原理和使用成本,并学习优化使用成本的一些成熟业界实践。
GC 基本原理
首先,我们要明白Go的内存管理。虽然Go负责管理值的存储,但开发者通常不需要关心具体位置。不需要GC管理的内存(比如函数局部变量且不发生逃逸)通常分配在goroutine的栈(Stack)上,这部分内存分配和回收非常高效。但是,当编译器无法确定一个值的生命周期时(比如动态大小的数据,或者被多处引用可能存活更久),这个值就会逃逸(escape)到堆(Heap)上。堆内存的分配是动态的,编译器和运行时无法预知其确切的生命周期,这时就需要GC介入来自动回收不再使用的堆内存。因此,Go GC的核心任务就是 识别并回收堆上那些不再被程序使用的对象(垃圾)。
追踪式 GC:对内存对象的可达性分析
Go和其他许多现代编程语言类似,采用的都是追踪式GC。其核心思想是对堆上内存对象的可达性分析。这种分析通常包括如下要素与执行过程:
-
根对象(Roots):程序中明确内存对象是否“存活”的起始点,根对象一般包括全局变量、栈上的局部变量和指针、寄存器等。
-
对象图(Object Graph):堆上的对象以及它们之间的指针引用关系构成了一个图。
-
追踪: 从根对象出发,沿着指针引用关系遍历对象图。
-
标记: 所有能够从根对象访问到的对象,都被认为是存活(Live)的,并被标记下来。
-
回收: 所有遍历结束后仍未被标记的对象,就是不可达(Unreachable)的垃圾,它们占用的内存可以被回收。
追踪式GC的经典算法是标记-清除(Mark-Sweep)算法,该算法每次启动都要执行两个阶段的操作。
-
标记(Mark)阶段: 从根对象开始,递归遍历所有可达对象,打上标记。
-
清除(Sweep)阶段: 遍历整个堆,回收所有未标记的内存对象,即不可达对象。
并发三色标记和清除
不过传统Mark-Sweep算法的主要问题是,标记和清除阶段通常需要 暂停整个应用程序(Stop-The-World,STW),导致程序卡顿。Go 1.4及之前的版本使用的都是这种经典标记-清除算法。
为了解决STW过长的问题,Go GC采用了允许标记过程与应用程序并发执行的策略。为了保证并发标记的正确性(即不能错误回收存活对象),Go从1.5版开始设计和实现了 并发三色标记和清除(Concurrent Tri-Color Marking-Sweeping)的GC算法,一直沿用至今。
该算法在应用程序并发运行时,还能保证标记的正确性(即正确识别所有存活对象,不遗漏也不错杀)。那么Go GC是如何协调的呢?用来追踪并发标记过程状态的三色标记法又是如何定义对象状态,并在这些状态间转换的呢?接下来,我们就详细看一下。
内存对象的三色状态转换
Go GC使用的三色标记法将堆上内存对象逻辑上划分为三种状态(颜色)。
-
白色(White):代表对象尚未被GC访问过。在GC开始时,所有对象(除了初始的根对象集合)都是白色的。如果在标记阶段结束后,一个对象仍然是白色的,那么它就被认为是不可达的垃圾,将在清除阶段被回收。
-
灰色(Gray):代表对象已被GC访问过,但它引用的其他对象(子对象)尚未被完全处理。灰色对象是标记工作推进的“前线”。GC需要扫描灰色对象引用的对象,并将灰色对象自身标记为黑色。灰色对象是存活的,但GC的工作还没对它完成。
-
黑色(Black):代表对象已被GC访问过,并且它引用的所有对象也都被充分处理了(至少被标记为了灰色)。黑色对象是确定存活的对象,在本轮GC中不会被回收,并且GC不会再重新扫描黑色对象。
三色内存对象的状态转换示意图如下:
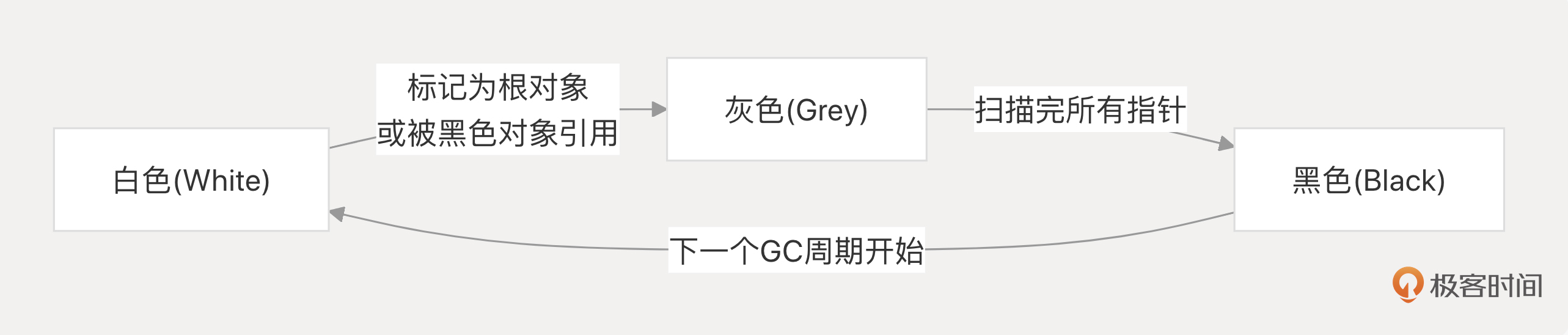
我们看到,在一个典型的GC标记周期中,对象颜色的转换遵循以下路径:
-
初始:所有对象皆白色。
-
开始:GC从根对象(全局变量、goroutine栈等)出发,将所有根对象直接引用的对象标记为灰色,放入待处理队列。
-
标记进行中:GC不断从灰色队列中取出对象。
-
灰色 -> 黑色:当GC处理完一个灰色对象,扫描了它引用的所有其他对象后,就将这个灰色对象标记为黑色。
-
白色 -> 灰色:在扫描一个灰色对象时,如果它引用了一个白色对象,那么这个白色对象会被标记为灰色,并放入待处理队列。同样,在并发标记过程中,如果应用程序(Mutator)修改了指针,使得一个黑色对象指向了一个白色对象,那么写屏障(Write Barrier)机制会介入,强制将这个被引用的白色对象标记为灰色,以防遗漏。
-
-
标记结束:当灰色队列为空时,并发标记阶段结束。此时堆上所有存活的对象都应该是黑色的。
-
下一周期:当下一轮GC开始时,所有对象(无论当前是什么颜色)的状态会重置为白色,开始新一轮的标记。
理解了这个三色标记模型和状态转换,我们就能更好地把握Go GC并发标记的核心逻辑,以及写屏障为何是必要的。接下来,我们再把这个模型放到实际的GC周期中,看看Go GC具体包含哪几个关键阶段。
Go GC的几个关键阶段
Go的垃圾回收器在一个GC周期内,大致会经历下图所示的几个关键阶段,这些阶段共同协作以回收不再使用的内存,同时力求将对应用程序运行的影响降至最低。理解这些阶段有助于我们认识GC的工作模式及其开销来源。
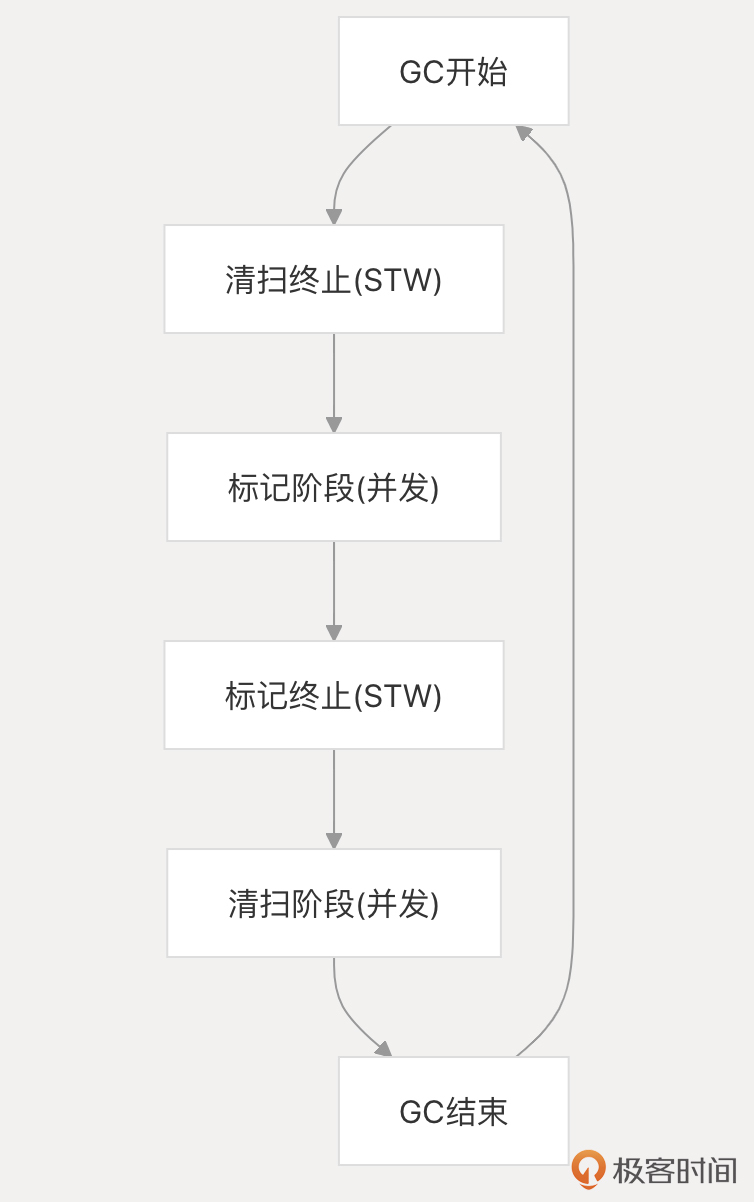
注:以下描述基于 Go 1.19+ 的 GC 实现,细节可能随版本演进。
首先是清扫终止(Sweep Termination)阶段。 这是一个短暂的Stop-The-World(STW)暂停,发生在新一轮GC标记开始之前。在此期间,所有应用程序的 goroutine 都会暂停。在这一阶段,GC的主要任务是确保上一轮循环中识别出的所有垃圾内存都已清扫完毕并可供分配器使用,同时初始化下一轮标记所需的内部状态,并开启写屏障(Write Barrier)。 写屏障是后续并发标记正确性的关键保障。 STW阶段的目标是极其短暂,通常在亚毫秒级别完成。
紧随其后的是标记阶段(Mark Phase),这是GC工作的主要部分,并且与应用程序并发执行。 在此阶段,写屏障处于激活状态,追踪应用程序对指针的修改。GC从根对象(全局变量、goroutine 栈等)出发,使用三色标记法递归地遍历对象图,标记所有可达的存活对象。如果应用程序分配内存的速度过快,超出了后台标记的速度,分配内存的goroutine可能会被要求执行标记辅助(Mark Assist),分担一部分标记工作,这会直接消耗应用程序的CPU时间。
当并发标记接近完成时,会进入第二个短暂的Stop-The-World(STW)阶段——标记终止(Mark Termination)。 此阶段的目标是最终完成所有标记工作,处理并发期间因写屏障记录的指针变更,并确保没有遗漏任何存活对象。 完成后,写屏障会被关闭,因为不再需要追踪后续的指针修改。同时,运行时会根据当前存活堆的大小计算并设定下一次GC的触发目标。这个 STW 同样力求短暂。
最后是清扫阶段(Sweep Phase),它也与应用程序并发执行。 在此阶段,GC遍历堆内存,将所有在标记结束后仍然是白色(未被标记)的对象所占用的内存空间回收,使其可用于未来的内存分配。这个过程通常是按需(惰性)和后台结合进行的,即应用程序在需要分配内存时可能会触发一小部分清扫,同时也有后台goroutine持续进行清扫工作。清扫的主要目的是让内存可重用,其本身的CPU开销相比标记阶段要小得多。
理解这四个阶段的交替进行、并发特性以及两个短暂的 STW 时刻,是我们分析Go GC行为和性能影响的基础。
但还有一个关键问题:GC 是在什么时候开始工作的?又是如何控制自己的节奏,避免过多影响应用程序的呢?这就涉及GC的触发与 Pacer 调速机制了。
GC 触发与 Pacer 调速:何时开始?如何进行?
Go GC并不会在每次内存分配后都运行,而是遵循一定的策略来决定何时启动新一轮的回收周期。我们来看下主要的触发时机。
基于堆大小阈值(GOGC)是最主要的触发方式。 Go运行时会监控程序分配的堆内存。一旦当前已分配的堆内存大小达到上一次GC结束后活动堆大小加上由GOGC百分比计算出的额外内存量这个目标时,就会触发新一轮GC。 GOGC 环境变量(或通过 debug.SetGCPercent 设置)控制了这个百分比,默认值是 100,意味着当堆大小增长到上次标记后活动对象大小的两倍时触发GC。
计算公式大致为:
Target heap memory = Live heap + (Live heap + GC roots) * GOGC / 100
- Target heap memory: 目标堆内存
- Live heap: 上次活动堆
这个机制是Go在CPU开销和内存占用之间进行权衡的核心参数。
基于时间也是主要的触发时机。 Go 运行时还有一个后台监控 goroutine(sysmon),它会定期(默认2分钟)检查是否需要强制触发一次GC,即使堆大小未达到阈值。这主要是为了防止在分配速率极低的程序中,内存无限期增长或者某些需要清理的资源(如 Finalizer)迟迟得不到处理。
我们再来看基于内存限制的触发时机。 在Go 1.19+版本中,开发者可以通过GOMEMLIMIT环境变量或debug.SetMemoryLimit函数设置一个Go程序内存使用的软上限。当Go运行时检测到程序使用的总内存(堆外内存+堆内存)接近这个限制时,会更积极地触发GC,甚至可能覆盖GOGC的设定,以尝试将内存控制在限制之下。
最后是手动触发时机。 调用runtime.GC()可以显式地强制执行一次GC。但这通常只用于调试或特定测试场景,不推荐在生产代码中常规使用。
一旦GC被触发(主要是基于GOGC阈值),Go运行时并不会简单地全速运行GC直到结束。为了平衡GC的执行效率和对应用程序性能的影响(特别是延迟),Go引入了Pacer机制来动态调整GC的步调。
Pacer的核心目标是: 在下一次堆大小达到触发阈值之前,平稳地完成当前的GC标记阶段,同时将GC本身消耗的CPU资源控制在一个合理范围内(默认目标是低于25%)。它通过持续监控应用程序的内存分配速率和GC自身的标记进度,动态地计算出需要在多长时间内完成标记,并据此调整后台标记工作量和标记辅助触发。
-
后台标记工作量:分配给专门的后台GC goroutine的标记任务量。
-
标记辅助(Mark Assist)触发:当应用程序分配内存过快,Pacer预测无法按时完成标记时,会要求分配内存的goroutine承担一部分“标记税”,即暂停业务逻辑去辅助GC进行标记。Pacer会根据需要动态调整触发标记辅助的阈值。
Pacer机制就像一个智能的巡航控制系统,它试图让GC过程尽可能平滑,避免因GC活动导致应用程序性能剧烈波动或长时间卡顿,是Go GC实现低延迟目标的关键技术之一。
理解了Go GC的基本原理——并发三色标记清除算法,以及其精巧的触发和Pacer调速机制后,我们就能更清晰地认识到Go GC与其他GC实现相比所展现出的独特 特点。这些特点正是Go语言在并发性能和低延迟方面表现出色的关键所在。接下来,我们就来具体看看Go GC的核心特性。
Go GC 的关键特点
理解了Go GC的基本原理,我们再来简单看看Go GC区别于其他一些GC实现的关键特点。
并发是Go GC设计的核心。 主要的标记和清除阶段都与应用程序goroutine并发执行,最大限度减少对程序运行的阻塞。
然后我们来看低延迟。 虽然大部分工作并发执行,Go GC仍需要在特定时刻短暂地暂停所有goroutine(Stop-The-World,STW)来完成一些关键同步操作。Go GC通过精心设计(如并发标记、并发栈扫描等)将STW的时间控制得非常短。
就像上面所描述的那样,目前一个GC周期通常仅包含两次短暂STW,一个是标记终止(Mark Termination),即并发标记结束后,短暂STW以完成标记并关闭写屏障。另外一个是清扫终止(Sweep Termination)/标记准备(Mark Setup):清除完成后,短暂STW以开启写屏障,为下一轮并发标记做准备。Go团队的目标是将这些STW的P99延迟控制在亚毫秒级别,这对低延迟应用至关重要。
为了保证并发标记的正确性(应用程序修改指针时不丢失存活对象),Go GC使用了写屏障(Write Barrier - Hybrid)。 写屏障是编译器插入的一小段代码,在指针写入时触发,用于通知GC可能需要重新扫描某些对象。Go 1.8引入的混合写屏障在保证正确性的前提下,尽量降低了写屏障的运行时开销。
下一个特点是非分代(Non-Generational)。 与Java等常见GC不同,Go GC不区分年轻代和老年代,每次GC都会扫描整个活动堆(Live Heap)。这个方案的优点是实现相对简单,避免了对象代际晋升的复杂性和开销。但缺点也很明显,那就是可能需要反复扫描生命周期很长的对象,增加了标记的工作量。
前面提到过,Go运行时使用Pacer机制来动态调整GC的节奏。它根据堆内存的增长速率、目标堆大小(由 GOGC 控制)等因素,计算出GC需要在何时完成标记阶段,并据此控制后台标记goroutine的数量和触发“标记辅助”(让业务goroutine参与标记)的频率。目标是在不显著影响应用性能(GC CPU占用率目标 < 25%)的前提下及时完成GC,防止内存无限增长。
上述这些特点共同构成了Go GC的核心竞争力: 以并发实现低延迟,并通过Pacer和写屏障等机制在效率和正确性之间取得平衡。
理解 GC 开销对程序性能的影响
我们已经知道,Go的自动内存管理带来了巨大的开发便利。垃圾收集器(GC)默默地承担了内存回收的重任,让开发者可以专注于业务逻辑。然而,这份便利并非没有代价。GC的运行必然会消耗系统资源,并对应用程序的性能产生影响。理解这些所谓的“GC开销”对于编写高性能Go应用和进行有效的性能调优至关重要。
GC开销最直接的体现是CPU消耗。 这部分开销主要来自几个方面。
首先,Go运行时会启动专门的后台goroutine来执行并发的标记和清除操作,这本身就会占用一部分CPU时间。
其次,也是对应用程序吞吐量影响更直接的因素,是标记辅助(Mark Assist)机制。当应用程序分配新内存的速度过快,以至于后台GC的标记工作跟不上时,为了防止堆内存失控,正在分配内存的业务goroutine会被运行时“征用”,暂停自己的工作,转而去帮助GC完成一部分标记任务。这种“标记税”是直接从业务goroutine的CPU时间里扣除的,分配越频繁、越快的goroutine,需要承担的辅助工作就越多。
最后,虽然Go GC力求缩短STW时间,但在两次短暂的STW(Stop-The-World)期间,应用程序完全暂停,CPU资源完全由GC接管,用于完成必要的同步和准备工作。
除了CPU,GC还会带来内存开销。
一方面,GC本身需要维护一些元数据,例如标记位图、对象类型信息等,这些元数据需要占用额外的内存空间。
另一方面,由于GC并非实时回收,而是在堆内存增长到一定阈值(由GOGC参数控制)时才触发,因此在两次GC周期之间,堆内存会持续增长。这意味着程序的峰值内存占用(RSS)会显著高于实际存活对象所需的内存(Live Heap)。调整GOGC参数实际上是在CPU开销(GC频率)和峰值内存占用之间进行空间换时间的权衡:更高的GOGC值意味着更低的GC频率和CPU开销,但更高的内存峰值。
最后,GC还会引入延迟开销(Latency)。最明显的是两次STW停顿,虽然Go力求将其控制在亚毫秒级,但对于延迟极其敏感的应用,这仍然是需要考量的因素,它直接影响了请求处理的最坏情况响应时间。此外,标记辅助也会导致业务goroutine的执行被短暂暂停,增加其处理延迟。同时,GC的后台工作和标记辅助任务也会与业务goroutine竞争CPU资源,可能对调度产生影响,间接增加延迟。不容忽视的还有写屏障开销,虽然混合写屏障已经过优化,但每次相关的指针写入操作仍会引入微小的CPU开销,对于指针操作密集的代码,这种累积效应可能变得显著。
那么,我们该如何观察和量化这些GC开销呢?
Go生态系统提供了多种工具。例如,通过设置GODEBUG=gctrace=1环境变量,可以在运行时获得详细的GC日志,了解GC频率、持续时间、STW时长、堆大小变化和GC CPU占比等关键信息。
程序内部也可以通过runtime.ReadMemStats()函数获取内存和GC的统计数据。更深入的分析则可以依赖runtime/pprof进行CPU和内存剖析,或者使用go tool trace进行细粒度的事件追踪。关于这些工具的使用方法和案例分析,我们将在后续工程实践篇中详尽讲解。现在最重要的是建立起GC并非零成本的意识,并了解其主要的开销维度。
理解了GC开销的来源和表现形式后,一个自然的问题是: 我们能做些什么来降低这些开销,让我们的Go程序运行得更高效呢?虽然可以通过调整GC参数(如 GOGC、 GOMEMLIMIT)来进行时空权衡,但这通常是最后的手段,且需要深厚的理解和充分的测试。对于大多数开发者来说,更有效、更安全、也更符合Go设计哲学的方式,是从源头做起——编写GC友好(GC-friendly)的代码。接下来,我们就探讨一些业界成熟的、通过改进编码实践来优化GC性能的方法。
编写 GC 友好代码
编写对GC友好的代码核心, 在于理解GC的主要工作负担来自于管理堆内存上的对象以及扫描其中的指针。因此,优化的关键思路就是尽可能地减少这两方面的工作量。
首先,最核心的优化方向是减少不必要的堆分配。分配在堆上的对象越少,GC需要标记、扫描和最终回收的工作量就越小,GC的触发频率也可能随之降低,因标记辅助(Mark Assist)而暂停业务逻辑的情况也会减少。
一种有效的策略是对象复用。 对于那些生命周期短但创建开销大的临时对象(比如网络连接中用于读写的缓冲区),可以使用 sync.Pool 来缓存和复用它们,避免在每次需要时都重新分配内存。
package main
import (
"bytes"
"fmt"
"sync"
)
// 创建一个用于缓存 bytes.Buffer 的 Pool
var bufferPool = sync.Pool{
New: func() interface{} {
fmt.Println("Allocating new buffer") // 打印日志观察分配次数
return new(bytes.Buffer)
},
}
func processRequest(data []byte) string {
buf := bufferPool.Get().(*bytes.Buffer) // 从 Pool 获取 Buffer
defer bufferPool.Put(buf) // 使用 defer 确保放回 Pool
buf.Reset() // 重置 Buffer 状态
buf.Write(data) // 使用 Buffer
// ... 其他处理 ...
return buf.String()
}
func main() {
// 模拟处理多个请求
processRequest([]byte("request 1 data"))
processRequest([]byte("request 2 data"))
// 如果并发量高,会看到 "Allocating new buffer" 打印次数远少于请求次数
}
其次,在处理字符串时,要特别注意高效的字符串操作。由于Go字符串是不可变的,在循环中使用 + 或 += 进行大量字符串拼接会导致频繁创建新的字符串对象和底层字节数组,产生大量需要GC回收的垃圾。正确的做法在之前的讲解中也提到过(这里就不再举例赘述了),那就是使用 strings.Builder 或预先分配足够容量的 []byte 缓冲区拼接,最后再一次性生成结果字符串。
另外,对于切片(slice)和map这两种常用的动态数据结构,预分配容量也是一个重要的GC优化手段。如果你能在创建它们时大致预估到最终需要存储多少元素,使用 make([]T, length, capacity) 或 make(map[K]V, size) 来指定初始容量,可以显著减少甚至避免后续因动态扩容而引发的内存重新分配和数据拷贝,从而降低GC压力。
除了减少堆分配,我们还可以尝试利用栈分配(Stack Allocation)。Go编译器会进行逃逸分析(Escape Analysis),判断一个变量的生命周期是否超出了其声明的函数范围。如果变量不“逃逸”,编译器会优先将其分配在函数调用栈上,栈内存的分配和回收非常快,且完全不需要GC介入。我们可以通过 go build -gcflags='-m' 命令来观察变量是否逃逸,并尝试调整代码(比如对于小型数据使用值传递而非指针传递、限制变量的作用域等)来促使变量留在栈上。
package main
import "fmt"
// Point 结构体较小
type Point struct {
X, Y int
}
// 返回值是指针,p 会逃逸到堆上
//go:noinline
func createPointPtr(x, y int) *Point {
p := Point{X: x, Y: y}
return &p // 返回了局部变量 p 的地址,p 必须逃逸
}
// 返回值是值,p 可能分配在栈上 (取决于调用者如何使用返回值)
//go:noinline
func createPointVal(x, y int) Point {
p := Point{X: x, Y: y}
return p
}
func main() {
p1 := createPointPtr(1, 2) // p1 指向堆上的 Point
p2 := createPointVal(3, 4) // p2 是栈上的 Point (在 main 的栈帧中)
fmt.Println(p1, p2)
}
针对上述示例,运行 go build -gcflags='-m' ./… ,可以看到 p moves/escapes to heap 的输出。
另一个减少GC工作量的角度是减少需要扫描的指针数量。 GC标记阶段的核心工作就是遍历对象图中的指针。如果我们的数据结构中包含的指针更少,GC扫描的工作量自然就减少了。例如,对于只包含基本类型(如 int、 float、 bool)而没有任何指针(包括slice、map、string、interface、channel以及指针类型字段)的结构体或数组,GC可以快速跳过它们的内部扫描。在设计数据结构时,如果可能,优先使用值类型而非指针,或者使用整数索引来代替指针引用数组/切片中的元素,都可以降低指针密度。将结构体中的指针字段集中声明在前面,也可能帮助GC在某些情况下提前结束对该结构体的扫描(依赖具体实现)。
package main
import "fmt"
// 结构体 A 包含指针 (string 内部有指针)
type StructA struct {
ID int
Name string // 指针类型
Data [10]int
}
// 结构体 B 不含指针
type StructB struct {
ID int
Flag bool
Data [10]int // 值类型数组
}
// 使用索引代替指针
type Node struct{ value int }
type Graph struct {
nodes []Node
edges [][]int // 存储索引,而非 *Node
}
func main() {
a := StructA{ID: 1, Name: "contains pointer"}
b := StructB{ID: 2, Flag: true}
// GC扫描 a 时需要检查 Name 字段指向的字符串数据
// GC扫描 b 时,检查完 Flag 就可以跳过 Data 数组内部(因为它不含指针)
fmt.Println(a.Name, b.Flag)
// 对于 Graph,GC 只需扫描 nodes 切片头和 edges 切片头及其内部的 int 切片头
// 无需深入扫描 Node 结构体内部或跟踪大量节点间指针
}
最后,虽然我们强调通过优化代码来改善GC性能是首选,但Go运行时确实提供了两个关键的调优参数——GOGC和GOMEMLIMIT——它们允许我们更直接地干预GC的行为,在时间和空间之间进行权衡。不过, 调整这些参数应被视为最后的手段,并且必须基于充分的理解、监控数据和性能测试。
GOGC这个参数控制着GC的触发频率。默认值是100,表示当新分配的堆内存达到上次GC后活动堆大小的100%时,触发新一轮GC。如图所示:
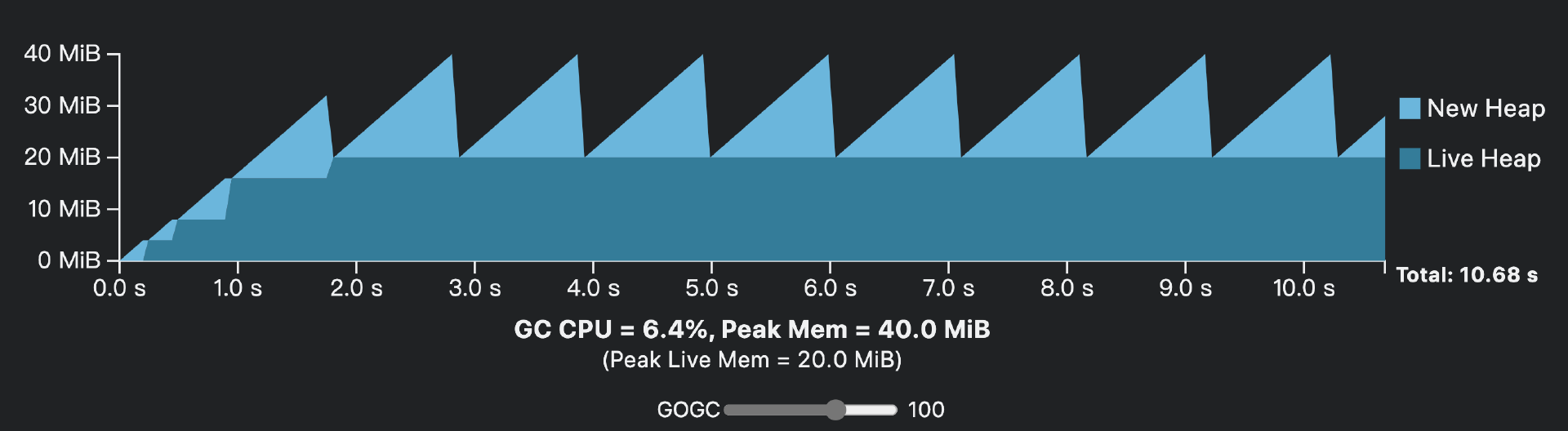
而 增大GOGC,比如设置为200会降低GC的触发频率,可以对比下图:
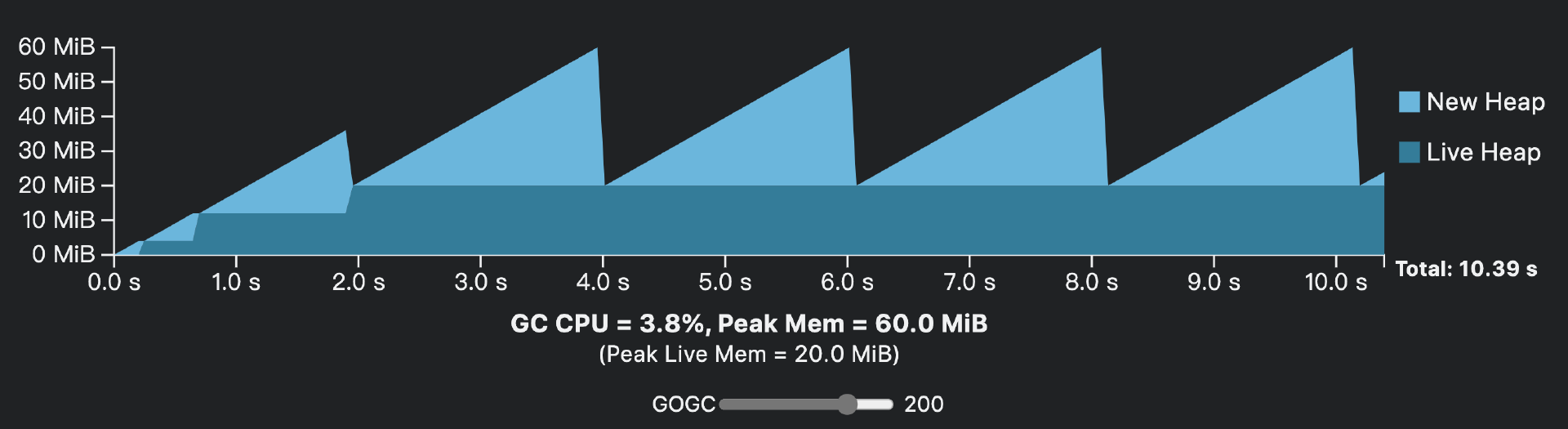
我们看到,增大GOGC可以减少GC的总CPU开销(包括STW时间、后台标记和标记辅助),GC CPU占用从6.4%下降为3.8%。但这是以 增加程序的峰值内存占用 为代价的(上面图中Peak Mem从40MB升高到60MB)。反之, 减小GOGC(比如设置为50)会增加GC频率和CPU开销,但能更早地回收内存,降低峰值内存占用。这是一个经典的时间(CPU)换空间(内存)的权衡。
Uber在其大规模实践中发现,许多Go服务配置的CPU与内存比例(如1:1或1:2)低于宿主机的比例(如1:5),这意味着服务有额外的内存空间可以利用。通过 动态地、基于实际内存使用情况和容器限制来调整GOGC,而不是使用固定的默认值或手动设置一个保守值, Uber成功地在30多个关键服务中节省了约7万个CPU核心的开销。他们的GOGCTuner库会根据容器的内存限制动态计算合适的GOGC值,旨在将堆内存使用率维持在一个目标百分比(如70%),从而在不超出内存限制的前提下,最大限度地降低GC频率。
GOMEMLIMIT(Go 1.19+)这个参数(或对应的环境变量)允许我们为Go程序设置一个内存使用软上限。它限制的是Go运行时可使用的总内存量(大致等于runtime.MemStats中的Sys - HeapReleased)。当程序总内存使用接近这个限制时,即使未达到GOGC设定的堆增长阈值,GC也会被更积极地触发,以尝试将内存控制在限制内,如下面示意图:
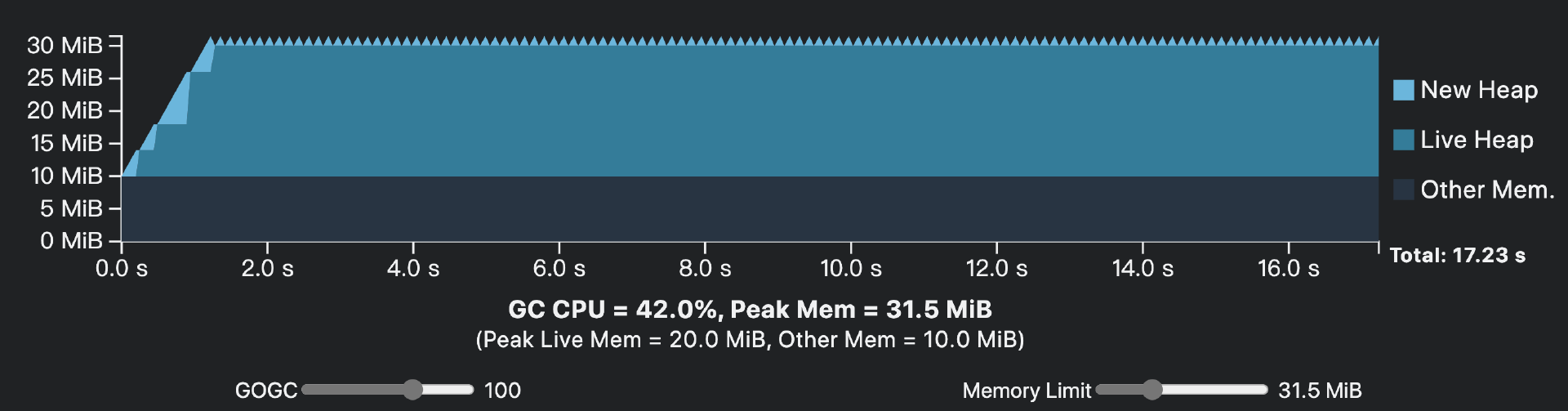
这个机制特别适用于容器化部署场景,可以帮助避免因内存超限而被容器运行时(如Kubernetes)OOM Kill。设置GOMEMLIMIT的经验法则是,将其设为容器内存限制的90%-95%,为Go运行时无法感知的其他内存开销(如CGO分配的内存、操作系统开销等)留出一些余地。需要注意的是,GOMEMLIMIT是一个软限制。为了避免应用程序因过于频繁的GC而完全卡死(称为 “Thrashing”),Go运行时设定了一个GC CPU使用率上限(大约50%)。如果内存压力极大,即使GC尽力回收,程序使用的内存仍可能短暂超过GOMEMLIMIT。在这种情况下,虽然避免了GC导致的完全饿死,但程序性能会显著下降(比如,上图中GC CPU占用已经达到了42%),甚至可能最终还是被OOM Kill。因此,不能完全依赖GOMEMLIMIT来防止OOM,它更多是作为一道防线,并鼓励GC在内存接近上限时更早介入。
ballast技术与GOMEMLIMIT的关系: 在GOMEMLIMIT出现之前,社区常用一种名为ballast(压舱石)的技术来间接控制GC频率。其原理是在程序启动时分配一个非常大但不实际使用的虚拟内存块(如 make([]byte, 10<<30))。由于Go GC将这个ballast视为活动堆的一部分,根据 GOGC=100 的规则,只有当新分配的内存也达到ballast那么大时才会触发GC,从而大大降低了GC频率。
func main() {
// Create a large heap allocation of 10 GiB
ballast := make([]byte, 10<<30)
// Application execution continues
// ...
runtime.KeepAlive(ballast) // make sure the ballast won't be collected
}
GOMEMLIMIT的引入在某种程度上提供了官方的、更健壮的替代方案。如果你希望达到类似ballast的效果(即只在内存接近某个硬限制时才GC),理论上可以将GOGC设为off(或-1),然后仅依赖GOMEMLIMIT来触发GC。然而,Go官方和Uber的实践都表明, 除非特殊情况,不建议完全关闭基于GOGC的常规GC。因为GOMEMLIMIT仅在内存接近上限时才介入,可能导致GC行为变得很不稳定,并且在内存压力大时仍有Thrashing风险。
更好的做法是, 同时设置一个合理的GOMEMLIMIT(如容器限制的90%) 和一个相对保守的GOGC值(可能仍是默认的100,或者根据应用的平均内存使用情况略微调高),让GOGC处理常规情况下的GC触发,而GOMEMLIMIT作为一道安全防线。
通过实践这些GC友好的编码方式和审慎的参数调整,我们可以从源头上减少GC的压力,在享受Go自动内存管理便利的同时,构建出性能更佳、资源利用更高效的应用程序。
小结
这节课,我们深入探讨了Go语言的垃圾回收机制,核心聚焦于“便利≠免费”这一主题,重点分析了GC的开销来源,并学习了切实可行的优化实践。
-
便利的代价: 我们认识到,Go GC提供的自动内存管理虽然极大地方便了开发,但其运行必然伴随着CPU消耗(后台标记、标记辅助、STW)、内存开销(元数据、堆增长)和潜在的 延迟影响(STW、调度干扰)。理解这些成本是进行优化的前提。
-
开销来源分析: 我们了解了这些开销产生的具体环节,包括并发标记和清除过程本身、保证并发安全的混合写屏障、以及为追赶分配速度而引入的标记辅助(Mark Assist)机制等。我们也知道了非分代设计意味着每次GC都需要全堆扫描。
-
优化实践核心: 最重要且对开发者最可控的优化手段,在于编写GC友好的代码。
-
减少堆分配: 这是降低GC压力的根本。通过对象复用(
sync.Pool)、高效字符串处理(strings.Builder)、预分配容量(make带cap)、利用栈分配(关注逃逸分析)等方式,从源头上减少需要GC管理的对象数量。 -
减少指针使用: GC的工作量与指针密度相关。合理使用值类型、索引替代指针、优化结构体字段布局(指针集中或无指针)有助于降低扫描成本。
-
(谨慎)调整GC参数:
GOGC和GOMEMLIMIT提供了时空权衡的手段,但应在充分理解和测试的基础上使用,通常作为代码优化的补充。
-
总的来说,虽然Go GC本身在不断进化和优化,但作为进阶开发者,我们不能完全依赖运行时。通过分析GC开销(利用 gctrace、 pprof 等工具)并积极采取优化实践(尤其是减少不必要的堆分配),我们可以在享受Go GC便利的同时,构建出性能表现更佳、资源利用更高效的应用程序。记住,对GC最好的优化,往往发生在GC之外——在我们的代码设计和内存使用习惯之中。
思考题
我们提到Go GC是非分代的,每次都会扫描整个活动堆。而像Java等语言的GC通常采用分代策略,更频繁地回收年轻代对象。
请思考:
-
你认为Go选择非分代GC可能有哪些优缺点(可以从实现复杂度、特定场景性能、内存碎片等方面考虑)?
-
在什么类型的Go应用程序或工作负载下,非分代GC可能会表现得相对更好?在什么情况下可能会成为劣势?
欢迎在留言区分享你的看法!我是Tony Bai,我们下节课见。
深入Go底层:驾驭反射(Reflection)与unsafe的双刃剑
你好!我是Tony Bai。
在Go语言简洁、静态类型和内存安全的“舒适区”之下,隐藏着两把威力巨大但也极其危险的“瑞士军刀”——反射(Reflection)和 unsafe 包。它们允许我们在某种程度上 突破Go的常规限制:反射让我们能在运行时动态地操作类型和值; unsafe 则让我们能直接操作内存、绕过类型系统的检查。
通常情况下,我们编写的Go代码都应该遵循语言提供的类型安全和内存安全保证。但总有一些特殊场景,比如:
-
需要编写能处理任意类型的通用框架(如JSON序列化、格式化输出、ORM等)。
-
需要与C语言或其他底层系统进行低级别交互。
-
在性能极端敏感的场景下,需要进行手动内存布局优化或避免某些运行时开销。
这时,反射和 unsafe 就可能进入我们的视野。然而,它们就像双刃剑:
-
威力:提供了强大的灵活性和底层操作能力,能实现常规Go代码难以完成的功能。
-
风险:使用不当极易导致代码难以理解、性能低下、类型不安全、甚至程序崩溃。
不理解反射和 unsafe 的原理、适用场景和风险,就可能在项目中误用或滥用它们,引入难以排查的Bug和性能问题。 对于进阶开发者而言,掌握这两把“双刃剑”的正确用法和安全边界至关重要。
这节课,我们将深入Go的底层地带,一起探索:
-
反射(Reflection):它是如何在运行时赋予我们动态操作类型和值的能力?核心概念是什么?
-
unsafe包:它提供了哪些“不安全”的操作?我们能用它来做什么,比如探索内存布局? -
双刃剑的代价:使用反射和
unsafe分别会带来哪些性能影响和安全风险? -
实践红线:明确何时以及如何(在保证安全的前提下)审慎地使用这两种高级特性。
接下来,就让我们一起学习如何驾驭这两把强大的底层工具吧。
反射:运行时动态操作类型与值
反射,简单来说就是程序在运行时检查自身结构(特别是类型信息)并进行操作的能力。Go的 reflect 包提供了这种能力。想象一下标准库的 fmt.Println 或 encoding/json.Marshal 函数,它们如何能接受任何类型的参数并正确处理?答案就是反射。反射在Go中主要用于编写需要处理未知类型数据的通用代码。
要理解Go反射,最重要的是掌握 reflect 中的 Type 和 Value 两个核心概念。
核心概念: reflect.Type 与 reflect.Value
Go语言的反射能力主要由标准库 reflect 包提供。要进入反射的世界,我们需要了解两个最核心的概念(也是 reflect 包中最重要的两个类型): reflect.Type 和 reflect.Value。它们就像是我们在运行时观察和操作Go程序内部结构的“透镜”和“机械臂”。
如何进入反射世界?
reflect 包提供了两个入口函数,让我们能够从普通的Go值(通常是 interface{} 类型,因为任何类型都可以赋值给它)得到对应的反射对象,并进入一个以反射对象为中心进行操作的世界——反射世界。
- reflect.TypeOf:获取类型信息
在Go语言中,我们可以使用reflect包的TypeOf函数来获取一个值的类型信息。TypeOf函数的签名如下:
func TypeOf(i any) Type
我们看到这个函数接收任何类型的值 i,并返回其动态类型的 reflect.Type 表示。 通过TypeOf进入反射世界的过程如下图所示:
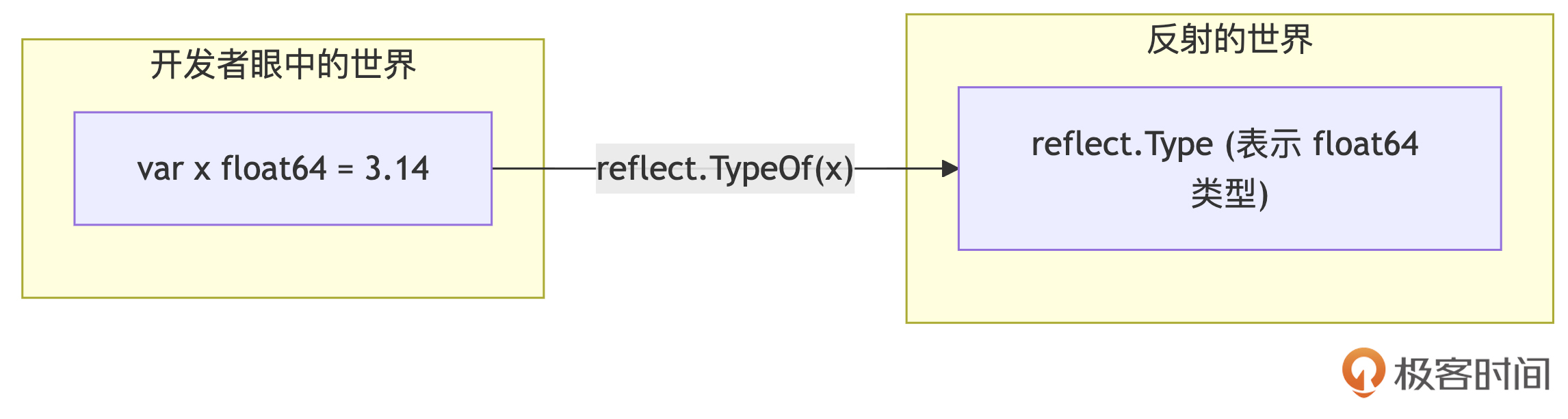
TypeOf专注于揭示值的类型信息。 下面是一个通过TypeOf函数获取一个float64类型值的类型信息的示例:
import (
"fmt"
"reflect"
)
func main() {
var x float64 = 3.14
t := reflect.TypeOf(x) // 获取 x 的类型信息
fmt.Println("Type:", t) // 输出: float64
fmt.Println("Name:", t.Name()) // 输出: float64 (类型名称)
fmt.Println("Kind:", t.Kind()) // 输出: float64 (类型种类)
fmt.Println("Size:", t.Size()) // 输出: 8 (占用的字节数)
}
可以看到,一旦通过TypeOf进入反射世界(拿到reflect.Type信息),我们就能掌握值的类型的很多重要信息,包括名称、种类以及大小等。
- reflect.ValueOf:获取值信息
在Go语言中,我们可以使用reflect包的ValueOf函数来获取一个值的Value信息。ValueOf函数的签名如下:
func ValueOf(i any) Value
我们看到,ValueOf函数接受一个任意类型的值作为参数,并返回该值的Value信息,即interface{}接口类型变量中存储的动态类型的值的信息,用reflect.Value表示。通过ValueOf进入反射世界的过程如下图所示:
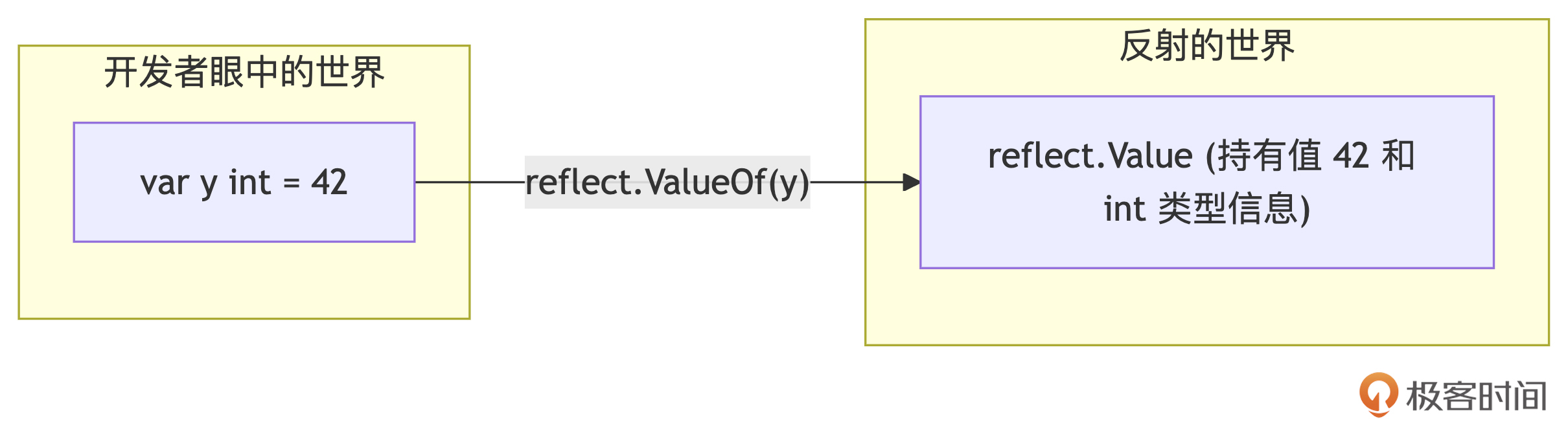
reflect.Value不仅包含了值本身,还包含了值的类型信息,并提供了操作这个值的方法。 下面是一个通过ValueOf函数获取一个int值的反射值信息示例:
import (
"fmt"
"reflect"
)
func main() {
var y int = 42
v := reflect.ValueOf(y) // 获取 y 的值信息
fmt.Println("Value:", v) // 输出: 42
fmt.Println("Type:", v.Type()) // 输出: int (Value 对象包含 Type 信息)
fmt.Println("Kind:", v.Kind()) // 输出: int
fmt.Println("Value as int:", v.Int()) // 输出: 42 (获取具体 int 值)
}
TypeOf 和 ValueOf 是我们从常规Go代码通往反射世界的两扇大门。一旦进入,我们主要就与 reflect.Type 和 reflect.Value 这两种反射对象打交道了。
reflect.Type:探索类型的静态信息
reflect.Type 对象就像一面镜子,可以照出任意Go值背后的类型信息。通过 reflect.TypeOf(x) 得到它之后,我们可以问它很多关于这个类型本身的问题。
最常用的就是询问它的种类(Kind)和名称(Name):
package main
import (
"fmt"
"reflect"
)
type MyInt int
type Person struct { Name string; Age int }
func main() {
var i int = 10
var mi MyInt = 20
var p Person
var s []string
var m map[string]bool
ti := reflect.TypeOf(i)
tmi := reflect.TypeOf(mi)
tp := reflect.TypeOf(p)
ts := reflect.TypeOf(s)
tm := reflect.TypeOf(m)
fmt.Printf("Type: %s, Kind: %s\n", ti.Name(), ti.Kind()) // 输出: Type: int, Kind: int
fmt.Printf("Type: %s, Kind: %s\n", tmi.Name(), tmi.Kind()) // 输出: Type: MyInt, Kind: int (Kind 是底层种类)
fmt.Printf("Type: %s, Kind: %s\n", tp.Name(), tp.Kind()) // 输出: Type: Person, Kind: struct
fmt.Printf("Type: %s, Kind: %s\n", ts.Name(), ts.Kind()) // 输出: Type: , Kind: slice (未命名类型 Name 为空)
fmt.Printf("Type: %s, Kind: %s\n", tm.Name(), tm.Kind()) // 输出: Type: , Kind: map
}
Kind() 返回的是类型的基础分类(如 int、struct、slice、map、ptr、func、interface等),这对于编写通用的反射代码非常重要,因为很多操作依赖于 Kind。而 Name() 返回的是类型的显式名称(如果它是已命名的类型)。
对于复合类型,我们可以进一步探索其内部结构:
// 对于 Struct
fmt.Println("Person NumField:", tp.NumField()) // 输出: 2
nameField, _ := tp.FieldByName("Name")
fmt.Printf(" Field Name: %s, Type: %s, Tag: '%s'\n", nameField.Name, nameField.Type, nameField.Tag)
// 输出: Field Name: Name, Type: string, Tag: '' (这里没加 tag)
// 对于 Slice, Array, Map, Chan, Ptr
fmt.Println("Slice Element Type:", ts.Elem()) // 输出: string
fmt.Println("Map Key Type:", tm.Key(), ", Map Value Type:", tm.Elem()) // 输出: string bool
// 对于 Func
fnType := reflect.TypeOf(func(a int, b string) bool { return false })
fmt.Println("Func Kind:", fnType.Kind()) // 输出: func
fmt.Println("Func NumIn:", fnType.NumIn()) // 输出: 2
fmt.Println("Func In(0):", fnType.In(0)) // 输出: int
fmt.Println("Func NumOut:", fnType.NumOut()) // 输出: 1
fmt.Println("Func Out(0):", fnType.Out(0)) // 输出: bool
Type 还提供了判断类型能力的方法,比如 Comparable()(是否可比较)、 Implements()(是否实现某接口)、 AssignableTo()(是否可赋值给某类型)等,这些在需要进行类型兼容性判断时很有用。
总的来说, reflect.Type 让我们能够在运行时静态地检视类型的定义和结构,它不关心具体的值是什么。
reflect.Value:持有值并与之交互
与 Type 不同, reflect.Value 代表的是一个具体的运行时值。它像一个万能容器,可以装下任何类型的值,并且提供了一套API来与这个值进行交互。
当然, Value 对象同样可以告诉我们它持有值的类型信息:
var pi float64 = 3.14159
vpi := reflect.ValueOf(pi)
fmt.Println("Value holds type:", vpi.Type()) // 输出: float64
fmt.Println("Value holds kind:", vpi.Kind()) // 输出: float64
更重要的是, Value 允许我们获取和设置(如果允许的话)它所持有的值。下面是获取值的示例:
// 获取值
fmt.Println("Value as float:", vpi.Float()) // 输出: 3.14159
// 还有 Int(), Uint(), String(), Bool(), Bytes(), Complex() 等对应 Kind 的方法
// 将 Value 转换回 interface{}
genericValue := vpi.Interface()
originalValue := genericValue.(float64) // 通过类型断言获取原始值
fmt.Println("Original value:", originalValue)
而通过 Value 对象来修改值,需要该值具有“可设置性(Settability)”。这是反射中最容易出错的地方之一。你不能直接修改通过 reflect.ValueOf(x) 得到的 Value,因为它持有的是 x 的一个副本。要想通过反射修改原始变量 x,必须:
-
获取
x的指针的reflect.Value。 -
调用
.Elem()方法获取指针指向的那个值的reflect.Value。 -
这个通过
.Elem()得到的Value才是可设置(Settable)的。
我们看下面的示例:
var count int = 10
vCount := reflect.ValueOf(count)
// vCount.SetInt(20) // 直接修改副本会 panic! panic: reflect: reflect.Value.SetInt using unaddressable value
vpCount := reflect.ValueOf(&count) // 1. 获取指针的 Value
veCount := vpCount.Elem() // 2. 获取指针指向的元素的 Value
fmt.Println("Is settable?", veCount.CanSet()) // 输出: true
veCount.SetInt(20) // 3. 修改成功
fmt.Println("New count:", count) // 输出: 20
从上述示例可以看出: 判断是否可设置非常重要,我们可以通过 CanSet() 方法检查。而对于结构体字段的设置,还需要该字段是可导出的(首字母大写)。下面我们再通过一个示例看一下通过Value操作结构体、数组、切片、map等复合类型内部值的方法:
type User struct {
ID int
Name string
Email string
IsActive bool
Tags []string
Props map[string]string
}
func main() {
user := User{
ID: 1,
Name: "Test",
Email: "test@example.com",
IsActive: true,
Tags: make([]string, 10),
Props: make(map[string]string),
}
vUser := reflect.ValueOf(&user).Elem() // 获取可设置的 User Value
// 访问和修改结构体字段
nameField := vUser.FieldByName("Name")
if nameField.IsValid() && nameField.CanSet() {
nameField.SetString("Updated Name")
}
fmt.Println("Updated User Name:", user.Name) // 输出: Updated Name
// 操作切片
tagsField := vUser.FieldByName("Tags")
tagsField.SetLen(3) // 设置长度
tagsField.Index(0).SetString("go") // 设置元素
fmt.Println("Tag 0:", tagsField.Index(0).String())
// 操作 Map
propsField := vUser.FieldByName("Props")
propsField.SetMapIndex(reflect.ValueOf("city"), reflect.ValueOf("London")) // 添加键值对
cityVal := propsField.MapIndex(reflect.ValueOf("city"))
if cityVal.IsValid() {
fmt.Println("City:", cityVal.String())
}
fmt.Println(user) // {1 Updated Name test@example.com true [go ] map[city:London]}
}
反射还可以动态地调用一个值的方法:
type Greeter struct{ Greeting string }
func (g Greeter) Greet(name string) string {
return g.Greeting + ", " + name + "!"
}
func main() {
g := Greeter{Greeting: "Hello"}
vg := reflect.ValueOf(g)
method := vg.MethodByName("Greet") // 获取 Greet 方法的 Value
if method.IsValid() {
args := []reflect.Value{reflect.ValueOf("World")} // 准备参数
results := method.Call(args) // 调用方法
if len(results) > 0 {
fmt.Println("Method result:", results[0].String()) // 输出: Hello, World!
}
}
}
我们看到,在反射世界里通过Value对象动态调用值的方法,方法的参数也需要使用“反射世界”的Value类型值(如上例中的args)。
reflect.Value 是反射机制中进行动态操作的核心。它像一个功能强大的通用“操作杆”,可以让你在运行时与几乎任何Go值进行交互,但前提是你必须小心翼翼地检查类型、种类和可设置性,以避免运行时错误。
反射三大定律
掌握了 reflect.Type 和 reflect.Value 这两个核心工具后,我们还需要理解它们之间相互作用的基本规则。Go语言官方博客上有一篇由 Rob Pike 撰写的著名文章,提出了“ 反射三大定律”,这三条定律清晰地阐述了Go反射机制的边界和核心交互方式,是安全、正确使用反射的基石。让我们来逐一理解它们。
这三条定律描述了普通类型值、 reflect.Type、 reflect.Value 以及 interface{} 之间的相互转换关系以及要遵循的原则。
定律一:反射可以将“接口类型变量”转换为“反射对象”( Type 或 Value)
任何一个Go值,都可以被赋给一个空接口 interface{}(或 any)类型的变量。上面已经详细介绍了 reflect 包提供的 TypeOf 和 ValueOf 函数,可以从这个接口值中提取出其底层包含的动态类型信息( reflect.Type)和动态值信息( reflect.Value),相信你已经理解了,我就不再举例赘述。
这条定律让我们能够探知任意变量在运行时的实际类型和值,并且规定了我们进入反射世界的入口。
定律二:反射可以将“反射对象”转换回“接口类型变量”
这是我们从反射世界“出来”的通道。当你拥有一个 reflect.Value 对象时,可以调用它的 Interface() 方法,将其转换回一个 interface{} 类型的值。这个接口值会持有反射对象所代表的那个原始的动态类型和动态值。
func main() {
vInt := reflect.ValueOf(123) // 得到 int 值的 Value
iFace := vInt.Interface() // 将 Value 转回 interface{}
// 现在 iFace 持有的是 int 类型的 123
fmt.Printf("Interface value: %v, type: %T\n", iFace, iFace) // 输出: Interface value: 123, type: int
// 可以通过类型断言获取原始值
originalInt := iFace.(int)
fmt.Println("Original int:", originalInt) // 输出: 123
}
这条定律允许我们将通过反射获得或操作的值,传递给需要 interface{} 参数的函数,或者通过类型断言恢复其原始类型。
定律三:要修改反射对象( reflect.Value),其值必须是“可设置的”
这是使用反射进行修改操作时最重要的规则,也是最容易出错的地方。并非所有的 reflect.Value 都允许你修改它所持有的值。一个 reflect.Value 是可设置的,必须满足两个条件:
-
可寻址(Addressable):这个
Value必须代表一个内存中可以获取地址的值。通常,通过获取一个变量的指针,再调用.Elem()得到的Value才是可寻址的。直接对一个普通变量(非指针)调用reflect.ValueOf()得到的是该变量值的副本,这个副本是不可寻址的。 -
非只读(Not Read-only):如果是结构体字段,该字段必须是可导出的(Exported,即首字母大写)。
前面介绍过,可以通过 reflect.Value 的 CanSet() 方法来检查一个值是否可设置,这里通过下面示例再强调一下这一点:
func main() {
var x float64 = 1.0
v := reflect.ValueOf(x) // v 持有 x 的副本,不可设置
fmt.Println("v CanSet:", v.CanSet()) // 输出: false
// v.SetFloat(2.0) // 直接修改会 panic: reflect: reflect.Value.SetFloat using unaddressable value
p := reflect.ValueOf(&x) // p 持有 x 的地址 (*float64)
fmt.Println("p CanSet:", p.CanSet()) // 输出: false (指针本身不可被设置成指向别处,除非p本身是通过指针获得的)
e := p.Elem() // e 是 p 指向的值 (x),它是可寻址的
fmt.Println("e CanSet:", e.CanSet()) // 输出: true
e.SetFloat(2.5) // 修改成功
fmt.Println("x is now:", x) // 输出: 2.5
// 结构体字段示例
type MyData struct { Public int; private int }
data := MyData{}
vData := reflect.ValueOf(&data).Elem()
fmt.Println("Public CanSet:", vData.FieldByName("Public").CanSet()) // 输出: true
// fmt.Println("private CanSet:", vData.FieldByName("private").CanSet()) // 输出: false (不可导出)
vData.FieldByName("Public").SetInt(100)
// vData.FieldByName("private").SetInt(200) // 会 panic
fmt.Println("data is now:", data) // 输出: {100 0}
}
定律三强调了反射操作的边界: 你可以检视几乎任何东西,但只能修改那些被允许修改的东西(可寻址且非只读)。理解并遵守这三大定律,是安全、有效地使用Go反射的前提。
反射的应用场景举例
虽然我们强调要谨慎使用反射,但它在某些场景下确实是不可或缺的利器。以下是一些典型的应用场景,我们来看一下。
序列化和反序列化(Serialization/Deserialization)
这是反射最广泛的应用之一。我们需要编写通用的代码,将任意结构体转换为某种格式(如JSON、XML、Gob)或从这些格式恢复成结构体,而无需为每种结构体编写特定的转换逻辑。
以下是简化版 JSON Marshal(仅处理简单结构体和基本类型)示例:
import (
"encoding/json" // 标准库 json 就大量使用了反射
"fmt"
"reflect"
"strings"
)
type Product struct {
Name string `json:"product_name"` // 使用 tag 指定 JSON 字段名
Price float64 `json:"price"`
Available bool `json:"-"` // tag 为 "-" 表示忽略此字段
secret string // 非导出字段,json 包默认会忽略
}
func simpleMarshal(v interface{}) (string, error) {
val := reflect.ValueOf(v)
// 如果是指针,获取其指向的元素
if val.Kind() == reflect.Ptr {
val = val.Elem()
}
// 必须是结构体
if val.Kind() != reflect.Struct {
return "", fmt.Errorf("only structs are supported")
}
typ := val.Type()
var parts []string
for i := 0; i < val.NumField(); i++ {
fieldVal := val.Field(i)
fieldTyp := typ.Field(i)
// 检查字段是否可导出
if !fieldVal.CanInterface() { // 另一种检查可导出的方式
continue
}
// 读取 json tag
jsonTag := fieldTyp.Tag.Get("json")
if jsonTag == "-" { // 忽略 tag 为 "-" 的字段
continue
}
fieldName := jsonTag
if fieldName == "" { // 如果没有 tag,使用字段名
fieldName = fieldTyp.Name
}
// 将字段值序列化为 JSON 字符串 (这里简化,只处理 string 和 float64)
var fieldStr string
switch fieldVal.Kind() {
case reflect.String:
fieldStr = fmt.Sprintf(`"%s": "%s"`, fieldName, fieldVal.String())
case reflect.Float64:
fieldStr = fmt.Sprintf(`"%s": %f`, fieldName, fieldVal.Float())
// ... 可以添加更多类型处理
default:
// 忽略不支持的类型
continue
}
parts = append(parts, fieldStr)
}
return "{" + strings.Join(parts, ", ") + "}", nil
}
func main() {
p := Product{Name: "Go Book", Price: 29.99, Available: true, secret: "hidden"}
jsonStr, err := simpleMarshal(&p) // 传入指针通常更好
if err != nil {
fmt.Println("Error:", err)
} else {
fmt.Println("Simple Marshal:", jsonStr)
// 输出: Simple Marshal: {"product_name": "Go Book", "price": 29.990000}
// 注意 Available 和 secret 被忽略了
}
// 对比标准库
stdJson, _ := json.Marshal(&p)
fmt.Println("Standard Marshal:", string(stdJson))
// 输出: Standard Marshal: {"product_name":"Go Book","price":29.99}
}
这个例子展示了如何使用反射遍历结构体字段、读取字段 tag、获取字段类型和值,并根据这些信息动态构建JSON字符串。标准库的实现远比这复杂,但核心原理是相似的。
格式化输出
标准库 fmt 包(如 fmt.Println、 fmt.Printf)能打印任意类型的值,也是基于反射实现的。它使用反射来探知传入参数的类型和内部结构,然后选择合适的格式进行输出。下面是一个使用反射进行简单地自定义格式化输出的示例:
import (
"fmt"
"reflect"
)
type Coordinates struct{ Lat, Lon float64 }
func main() {
c := Coordinates{Lat: 34.05, Lon: -118.24}
i := 123
s := "hello"
fmt.Println("--- Using fmt (relies on reflection) ---")
fmt.Printf("Default (%%v): %v, %v, %v\n", c, i, s)
// 输出: Default (%v): {34.05 -118.24}, 123, hello
fmt.Printf("With Fields (%%+v): %+v\n", c)
// 输出: With Fields (%+v): {Lat:34.05 Lon:-118.24}
fmt.Printf("Go Syntax (%%#v): %#v, %#v, %#v\n", c, i, s)
// 输出: Go Syntax (%#v): main.Coordinates{Lat:34.05, Lon:-118.24}, 123, "hello"
fmt.Println("\n--- Manual reflection for similar info ---")
printReflectInfo(c)
printReflectInfo(i)
printReflectInfo(s)
}
func printReflectInfo(x interface{}) {
v := reflect.ValueOf(x)
t := v.Type()
fmt.Printf("Value: %v, Type: %s, Kind: %s\n", v.Interface(), t.Name(), t.Kind())
if t.Kind() == reflect.Struct {
fmt.Printf(" Fields (%d):\n", t.NumField())
for i := 0; i < t.NumField(); i++ {
fieldT := t.Field(i)
fieldV := v.Field(i)
fmt.Printf(" - %s (%s): %v\n", fieldT.Name, fieldT.Type, fieldV.Interface())
}
}
}
这个例子对比了 fmt 的输出和我们手动用反射获取类似信息的过程,也可以帮助我们理解 fmt 内部的工作方式。
对象关系映射(ORM)
ORM框架需要将程序中的结构体映射到数据库表,并将结构体字段映射到表列。它使用反射来:
-
获取结构体名称(推断表名)。
-
遍历结构体字段,获取字段名、类型和
db等 tag(推断列名、类型、约束)。 -
动态地读取结构体字段的值,用于生成
INSERT或UPDATE语句的参数。 -
动态地将数据库查询结果(行数据)设置回结构体实例的字段中。
下面是一个基于反射实现的简化版 INSERT 语句生成的示例:
import (
"fmt"
"reflect"
"strings"
)
type Order struct {
OrderID int `db:"order_id,pk"` // pk 表示主键 (假设)
Customer string `db:"customer_name"`
Total float64 `db:"total_amount"`
Status string // 没有 db tag,可能会被忽略或按字段名映射
createdAt time.Time `db:"-"` // 忽略此字段
}
func generateInsertSQL(obj interface{}) (string, []interface{}, error) {
val := reflect.ValueOf(obj)
if val.Kind() == reflect.Ptr { val = val.Elem() }
if val.Kind() != reflect.Struct { return "", nil, fmt.Errorf("expected a struct or pointer to struct") }
typ := val.Type()
tableName := strings.ToLower(typ.Name()) // 简单推断表名
var fields []string
var placeholders []string
var values []interface{}
for i := 0; i < val.NumField(); i++ {
fieldTyp := typ.Field(i)
fieldVal := val.Field(i)
if !fieldVal.CanInterface() { continue } // 跳过非导出字段
dbTag := fieldTyp.Tag.Get("db")
if dbTag == "-" { continue } // 跳过忽略的字段
parts := strings.Split(dbTag, ",")
colName := parts[0]
if colName == "" { colName = strings.ToLower(fieldTyp.Name) } // 默认用字段名
// 简单处理,假设非主键都需要插入
isPK := false
for _, part := range parts[1:] {
if part == "pk" { isPK = true; break }
}
if !isPK { // 假设主键通常是自增或其他方式生成,不在 INSERT 中提供
fields = append(fields, colName)
placeholders = append(placeholders, "?") // 使用 ? 作为占位符
values = append(values, fieldVal.Interface())
}
}
if len(fields) == 0 { return "", nil, fmt.Errorf("no fields to insert for table %s", tableName) }
query := fmt.Sprintf("INSERT INTO %s (%s) VALUES (%s)",
tableName,
strings.Join(fields, ", "),
strings.Join(placeholders, ", "),
)
return query, values, nil
}
func main() {
order := Order{OrderID: 101, Customer: "ACME Corp", Total: 199.99, Status: "Pending"}
sql, args, err := generateInsertSQL(&order)
if err != nil {
fmt.Println("Error:", err)
} else {
fmt.Println("Generated SQL:", sql)
fmt.Println("Arguments:", args)
// 输出:
// Generated SQL: INSERT INTO order (customer_name, total_amount, status) VALUES (?, ?, ?)
// Arguments: [ACME Corp 199.99 Pending]
}
}
这个例子展示了ORM框架如何利用反射来检查结构体、读取tag,并动态生成SQL语句和参数列表。
以上这些场景充分体现了反射的强大之处,它使得编写能够适应不同数据类型和结构的通用代码成为可能。但同时,这种能力是以牺牲部分编译期安全性和性能为代价的,这个我们后面会有讲到。
反射允许我们在运行时与Go的类型系统进行交互,但在某些更极端的情况下,开发者可能需要完全绕过类型系统和内存安全保证,直接触及内存的底层。这时,我们就需要了解Go语言提供的另一把更锋利、也更危险的“双刃剑”—— unsafe 包。
unsafe包:探索内存布局,打破类型系统约束的场景
unsafe 包是Go标准库中一个非常特殊的存在。正如其名, 它提供的功能是不安全的,它允许我们执行一些打破Go语言常规类型检查和内存安全保障的操作。Go官方文档明确指出:“导入 unsafe 的包可能在可移植性上无法保证”。
为什么Go会提供这样一个“危险”的包呢?主要是为了满足一些非常底层的需求,这些需求通常由Go运行时自身、需要与C语言交互的代码(cgo),或者需要进行极致性能优化的库来承担。普通应用程序开发者极少需要直接使用 unsafe 包。
unsafe 包的核心在于提供了与内存地址和指针进行底层交互的能力,其中最关键的是 unsafe.Pointer 这个类型,它是unsafe包“危险”的主要来源!
unsafe.Pointer:通用指针,类型转换的桥梁
unsafe.Pointer 是一种特殊的指针类型,它可以指向任意类型的数据,类似于C语言中的 void*。它的存在主要是为了在 不同类型的指针之间进行转换,这是它最核心也最常用的功能,同时也是最“危险”的功能。
当然 unsafe.Pointer 本身也有着严格的使用限制,比如你不能对 unsafe.Pointer 进行算术运算(比如 p + 1),也不能直接引用 unsafe.Pointer 来获取它指向的数据。它遵循以下四条转换规则:
-
任何类型的指针
*T都可以转换为unsafe.Pointer。 -
unsafe.Pointer可以转换回任何类型的指针*T2。 -
uintptr类型的值可以转换为unsafe.Pointer。 -
unsafe.Pointer可以转换为uintptr类型的值。
我们在 第一节课类型系统 中曾提到过uintptr,它是一个无符号整数类型,其大小足以容纳一个内存地址(在32位系统上是4字节,64位系统上是8字节)。 它的唯一目的是用于指针的算术运算。
由于 unsafe.Pointer 不能直接进行加减运算,所以当我们需要根据内存偏移量访问数据时(比如访问结构体字段或数组元素),需要经历以下步骤:
*T1 -> unsafe.Pointer -> uintptr -> (进行加减运算得到新的地址整数) -> unsafe.Pointer -> *T2
下面就是一个结合 unsafe.Pointer 和 uintptr 访问结构体字段的示例。假设我们有一个结构体,并想通过计算偏移量来访问其字段( 注意:这是非常不推荐的实践,仅作原理演示):
package main
import (
"fmt"
"unsafe"
)
type Data struct {
Flag bool // 1 byte + 7 padding (on 64-bit)
Value float64 // 8 bytes
Counter int32 // 4 bytes + 4 padding
Label string // 16 bytes (pointer + length)
}
func main() {
d := Data{Flag: true, Value: 3.14, Counter: 10, Label: "example"}
// 1. 获取结构体实例的指针
ptrD := unsafe.Pointer(&d)
// 2. 计算 Value 字段的地址
// 将 ptrD 转为 uintptr 进行运算
// 加上 Flag 字段的偏移量 Offsetof(d.Flag) (通常是0)
// 再加上 Value 字段相对于 Flag 字段的偏移 (需要考虑对齐)
// 更可靠的方式是直接用 Offsetof(d.Value)
ptrValue := unsafe.Pointer(uintptr(ptrD) + unsafe.Offsetof(d.Value))
// 3. 将计算得到的通用指针转换为具体类型指针 *float64
valueField := (*float64)(ptrValue)
// 4. 访问或修改值
fmt.Println("Value field via unsafe:", *valueField) // 输出 3.14
*valueField = 2.71
fmt.Println("Value field after modification:", d.Value) // 输出 2.71
// 同样可以访问 Counter 字段
ptrCounter := unsafe.Pointer(uintptr(ptrD) + unsafe.Offsetof(d.Counter))
counterField := (*int32)(ptrCounter)
fmt.Println("Counter field via unsafe:", *counterField) // 输出10
}
这个例子展示了如何组合使用 unsafe.Pointer, uintptr 和 Offsetof 来访问结构体内部字段。再次强调,直接依赖 Offsetof 进行字段访问是极其脆弱和危险的,因为字段偏移量可能因编译器优化、Go版本更新、平台差异等因素而改变。
并且,unsafe.Pointer与uintptr联合使用进行指针算术运算,也是最容易导致误用并引发安全问题的场景。因为 uintptr 只是一个整数,它持有的是某个时刻内存地址的数值。Go的垃圾回收器不会跟踪 uintptr 值, 持有 uintptr 并不能保证其指向的内存对象不被GC回收或移动! 这意味着,将 unsafe.Pointer 转换为 uintptr 后,不应长期持有这个 uintptr 值。它通常只在临时的、一系列转换和运算的中间步骤中使用,并且最终必须转换回 unsafe.Pointer 才能安全地访问内存。
为此,Go官方文档(特别是在 unsafe 包的注释中)明确指出了使用 unsafe.Pointer 的六种被认为是合法的模式。任何超出这些模式的使用都可能导致不可移植或不安全的行为。理解这些模式是安全使用 unsafe 的前提。下面我们就来看一下这些安全模式!
unsafe 的安全使用模式
Go官方文档明确规定了 unsafe.Pointer 的几种合法使用模式。理解并严格遵守这些模式,是避免未定义行为、保证代码(相对)安全的关键。
模式1:将 *T1 转换为 unsafe.Pointer,再转换为 *T2 。 这种模式允许在不同类型的指针间转换,前提是你确信这种转换在内存层面是合理的(比如 T2 的大小不超过 T1,或者你知道如何正确解释 T1 的内存作为 T2)。
正确模式:
var f float64 = 3.14
// 将 float64 的地址解释为 uint64 的地址 (假设知道底层比特位含义)
bits := *(*uint64)(unsafe.Pointer(&f))
fmt.Printf("Float bits: 0x%x\n", bits)
错误/危险模式:
type MyStructSmall struct { a int32 }
type MyStructLarge struct { x, y, z int64 }
var small MyStructSmall
// 将小结构的指针强转为大结构的指针
// largePtr := (*MyStructLarge)(unsafe.Pointer(&small))
// *largePtr = MyStructLarge{1, 2, 3} // 写入会越界,破坏small变量之外的内存!错误!
模式2:将 unsafe.Pointer 转换为 uintptr 。 这种模式会返回指向该值的内存地址,并以整数形式表示。uintptr类型的通常用途是打印它。并且,一般来说,将uintptr转换回指针是无效的。即使uintptr保存了某个对象的地址,垃圾回收器也不会在该对象移动时更新该uintptr的值,也不会阻止该对象被回收。
正确模式:
var x int
ptrX := unsafe.Pointer(&x)
fmt.Println("Address as uintptr:", uintptr(ptrX)) // 仅做打印值
错误模式:
addrInt := uintptr(ptrX) // 错误:保存 uintptr 供后续使用
// ... 中间可能发生 GC,x 可能被移动 ...
// runtime.GC() // 模拟 GC
// ptrX_later := unsafe.Pointer(addrInt) // addrInt 可能已失效!错误!
// *(*int)(ptrX_later) = 10 // 可能访问无效内存
模式3:将 unsafe.Pointer 转为 uintptr 并进行算术运算,然后立即转回 unsafe.Pointer。这是进行指针运算的标准模式。整个转换、运算、再转换的过程必须在一个表达式中完成,且它们之间只能存在算术运算。
正确模式:
type DataPoint struct { timestamp int64; value float64 }
dp := DataPoint{1678886400, 98.6}
ptrDP := unsafe.Pointer(&dp)
offsetValue := unsafe.Offsetof(dp.value)
// 在单一语句中完成计算和转换
ptrValue := unsafe.Pointer(uintptr(ptrDP) + offsetValue)
value := *(*float64)(ptrValue)
fmt.Println("Value via offset:", value) // 输出 98.6
错误模式:
// 分解操作,中间保存 uintptr
addrDP_int := uintptr(ptrDP)
addrValue_int := addrDP_int + offsetValue
// ... 中间可能发生 GC ...
// runtime.GC() // 模拟 GC
ptrValue_invalid := unsafe.Pointer(addrValue_int) // addrValue_int 可能失效!错误!
// *(*float64)(ptrValue_invalid) = 100.0 // 危险操作
模式4:将 unsafe.Pointer 转换为 uintptr 以作为特定函数的参数。 某些特殊的底层函数(主要是 syscall 包中的函数)被设计为接收 uintptr 类型的参数来代表内存地址。将 unsafe.Pointer 转换为 uintptr 以便调用这些特定函数是合法的。但如果必须将指针参数转换为uintptr才能用作参数,则该转换必须出现在调用表达式本身当中。
import (
"syscall"
"unsafe"
// "reflect" // 如果要用 reflect.Value.SetPointer 等
)
var data [10]byte
func main() {
// 正确模式: unsafe.Pointer转为uintptr出现在syscall.Write的调用表达式本身当中
// 注意:这里 syscall.Write 的 fd 和 buf 参数类型都是 uintptr
// 这是一个简化示例,实际系统调用更复杂
syscall.Write(1 /* stdout fd */, uintptr(unsafe.Pointer(&data[0])), len(data))
// 错误模式 (同规则2): 将 uintptr 保存起来用于非特定函数调用或没有出现在调用表达式本身当中
// addrInt := uintptr(ptr)
// // ... 可能 GC ...
// someOtherFunc(addrInt) // 除非 someOtherFunc 明确设计处理 uintptr,否则危险
}
模式5:将 reflect.Value 的 Pointer() 或 UnsafeAddr() 方法返回的 uintptr 转换为 unsafe.Pointer 。 reflect.Value 提供了 Pointer()(用于指针、unsafe.Pointer、chan、map、func)和 UnsafeAddr()(用于获取变量地址,即使它不是指针类型,但必须可寻址)方法,它们都返回 uintptr 类型的值。这意味着结果很脆弱,必须在调用后立即转换为Pointer类型。
正确模式:
p := (*int)(unsafe.Pointer(reflect.ValueOf(new(int)).Pointer()))
错误模式:
u := reflect.ValueOf(new(int)).Pointer() // uintptr不应该被存储在临时变量里
p := (*int)(unsafe.Pointer(u))
模式6: unsafe.Pointer 与 reflect.SliceHeader 或 reflect.StringHeader 的 Data 字段( uintptr 类型)的相互转换。 这条规则是实现 string 和 []byte(或其他切片类型)之间底层数据访问和零拷贝转换的基础。 reflect 包定义的 SliceHeader 和 StringHeader 结构体,它们的 Data 字段被声明为 uintptr 类型。这主要是为了防止用户在不导入 unsafe 包的情况下,就能轻易地将这个字段转换为任意指针类型。
这个 Data 字段( uintptr)应被视为字符串或切片内部指针的另一种表示形式,而不是一个独立的、可以长期持有的整数地址。因此, SliceHeader 和 StringHeader 结构体只应在它们指向一个实际存在的、有效的字符串或切片值时才有意义。
正确模式:
- 获取底层数据指针:获取一个实际的字符串或切片的 Header 指针,然后将其
Data字段(uintptr)转换为unsafe.Pointer,以访问底层字节数据。
s := "hello"
hdr := (*reflect.StringHeader)(unsafe.Pointer(&s)) // 获取指向实际 s 的 Header 指针
dataPtr := unsafe.Pointer(hdr.Data) // 将 Data (uintptr) 转为 unsafe.Pointer
// firstByte := *(*byte)(dataPtr) // 合法地访问第一个字节
- 构建(或修改)Header以创建新的字符串或切片:用一个有效的
unsafe.Pointer(指向你想引用的字节数据)转换为uintptr,并赋给一个指向实际字符串或切片变量的Header的Data字段。
var s string // 准备一个 string 变量来接收结果
var p unsafe.Pointer = unsafe.Pointer(&someByteArray[0]) // p 指向某字节数据
n := len(someByteArray)
hdr := (*reflect.StringHeader)(unsafe.Pointer(&s)) // 获取 s 的 Header 指针
hdr.Data = uintptr(p) // 将 p 的地址赋给 Data
hdr.Len = n // 设置长度
// 现在 s 就引用了 someByteArray 的数据 (零拷贝)
错误模式:
- 直接声明或分配 Header 结构体:永远不要声明或分配一个独立的
SliceHeader或StringHeader结构体变量,然后试图填充它的字段来创建一个字符串或切片。因为这个独立的Header结构体变量本身与任何实际的字符串或切片值没有关联,其Data字段的uintptr不会像在实际的字符串/切片内部那样被GC正确跟踪。
// 错误模式: 直接声明 Header 变量
var hdr reflect.StringHeader // 无效:没有指向实际的 string 变量
var p unsafe.Pointer = unsafe.Pointer(&someData[0])
n := len(someData)
hdr.Data = uintptr(p) // 赋值给一个独立的 uintptr 字段
hdr.Len = n
// ... 在这里 p 指向的 someData 可能已经被 GC 回收 ...
// s := *(*string)(unsafe.Pointer(&hdr)) // 极其危险!hdr.Data 此时可能无效!
- 将从Header获取的
Data(uintptr)长期持有: 与规则 2、3 一样,从SliceHeader或StringHeader中取出的Data字段(uintptr)也不能保证其指向的对象存活。它只应在原字符串/切片仍然有效的情况下,用于临时的转换和访问。
严格遵循这六种模式是底线。任何试图“创造性”地使用 unsafe 的行为都极有可能引入难以发现的、与平台或版本相关的严重Bug。
我们已经看到, unsafe 包提供了直接操作内存的终极能力,它允许我们打破Go语言精心设计的类型和内存安全壁垒。这种能力在某些底层场景下是必要的,但其代价是巨大的安全风险和可移植性问题。与 unsafe 类似,反射虽然不直接操作原始内存地址,但它也在运行时层面绕过了编译期的静态类型检查,同样带来了性能和安全上的权衡。接下来,我们就来系统地审视一下使用反射和 unsafe 这两把“双刃剑”所需要付出的具体代价。
双刃剑的代价
选择使用反射或 unsafe,就如同选择挥舞一把双刃剑,它们在赋予我们强大能力的同时,也必然伴随着需要付出的代价,主要体现在性能和安全两个维度。
反射(Reflection)的代价,更多地体现在性能损耗和类型安全的延迟上。 由于反射操作是在运行时进行的,获取类型信息、查找字段或方法、动态调用函数以及进行值的转换和设置,都比直接的静态代码要慢得多,通常有数量级的差距。这意味着在性能敏感的代码路径(如热点循环或高频函数)中滥用反射会显著拖慢程序。同时,反射将本应在编译期完成的类型检查推迟到了运行时,类型错误(如错误的类型断言或不匹配的参数)直到运行时才会以 panic 的形式暴露出来,这无疑增加了调试的难度和线上风险。此外,充斥着类型检查、接口转换和动态调用的反射代码,往往也比结构清晰的静态代码更难阅读和维护。
而 unsafe 包的代价则更为根本和危险,它直接触及了Go语言赖以生存的内存安全基石。使用 unsafe,你将直面悬空指针( uintptr 不保证对象存活)、非法内存访问(指针计算错误导致越界或访问未对齐地址)、数据竞争( unsafe 操作非原子性,并发访问需手动同步)以及破坏类型系统(强制类型转换导致数据解释混乱,修改不可变数据如 string 则可能引发灾难)等严重风险。这些问题一旦发生,往往导致程序崩溃或出现极其诡异、难以复现的数据损坏。
更糟糕的是, unsafe 代码通常严重依赖特定平台的内存布局、大小和对齐方式,这使得代码可移植性极差,在不同的操作系统、CPU架构或Go版本之间可能完全失效,尤其是那些试图访问私有字段的技巧,更是极其脆弱。最后,由于绕过了编译器的保护, unsafe 代码的错误往往难以调试,其晦涩的意图也给代码维护带来了巨大挑战。
简单来说,反射牺牲了相当一部分性能和编译期安全,换来了运行时的动态灵活性;而 unsafe 则几乎是彻底放弃了Go的安全保障,以换取最底层的内存操作能力和(理论上可能的)极致性能,但风险极高。
认识到这两把“双刃剑”的沉重代价,我们才能更加清醒地判断,在何种情况下值得去承担这些风险,以及如何在使用时将风险降至最低。这正是我们接下来要讨论的实践红线。
实践红线:如何审慎地使用这两种高级特性
掌握了反射和 unsafe 的能力与风险后,一个关键问题摆在我们面前:在实际开发中,我们应该在什么情况下考虑使用它们?又该如何确保在使用时能最大限度地发挥其优势,同时将风险控制在最低水平呢?这需要我们划定清晰的“实践红线”。
对于反射(Reflection)而言,它的用武之地在于那些确实需要在运行时处理未知类型的场景。当你需要编写真正通用的代码,比如开发序列化/反序列化框架(像 encoding/json)、数据库 ORM、通用的打印或比较工具(如 fmt 包、 reflect.DeepEqual),或者构建依赖注入容器、插件系统这类需要动态发现和组装组件的系统时,反射往往是不可或缺的。然而,即便在这些场景下,我们也应 始终将反射视为最后的选择。如果问题可以通过接口、泛型(Go 1.18+)或其他静态类型机制解决,那么这些静态方案通常更安全、性能更好、代码也更易于理解和维护,应当优先采用。
决定使用反射后,务必遵循几条核心原则。
首先,绝对要避免在性能敏感的热点路径(如核心计算逻辑、高频调用的函数或紧密循环)中使用反射,因为它的性能开销相对较大。
其次,最好能将反射的复杂性封装起来,将其隐藏在特定的库或辅助函数内部,对上层调用者提供类型安全的、清晰的接口。
再者,由于反射操作可能在运行时引发 panic(例如类型断言失败、尝试修改不可设置的值),因此必须做好充分的错误处理和有效性检查(利用 recover 捕获 panic,或在使用 Value 的方法前检查 IsValid、 CanSet、 CanAddr 等)。
最后,如果你的公共API接受 interface{} 参数并内部使用了反射,清晰的文档至关重要,务必说明其行为、限制以及可能抛出的 panic。
相比之下, unsafe 包的使用场景要罕见得多,门槛也高得多。它几乎是为 Go 语言的“引擎室”准备的工具。考虑使用 unsafe 的情况通常只有以下几种:
-
与非 Go 代码(如 C 语言)进行底层交互(cgo)时,可能需要用
unsafe.Pointer进行类型转换。 -
需要直接与操作系统或硬件打交道,比如操作内存映射文件或访问特定硬件地址时(这通常发生在
syscall或运行时内部)。 -
或者是在实现标准库、运行时级别的底层数据结构(如
sync.Pool、sync.Map、reflect包自身)时,为了性能或特殊需求而使用。 -
最后一种可能的情况是,在进行了严格的性能剖析和基准测试,证明常规Go代码确实无法满足性能要求,且瓶颈明确指向内存布局或某些运行时开销之后,经验极其丰富的开发者 可能会考虑使用
unsafe进行高度针对性、局部化的极致优化(如实现零拷贝转换或手动内存布局)。
如果确实遇到了必须使用 unsafe 的极少数情况,那么必须遵循一系列严格的安全红线。使用的范围必须绝对最小化,仅限于别无选择的核心代码点。操作时必须严格遵守官方文档定义的六种合法转换模式,任何“自创”的用法都可能导致灾难。
同时, unsafe 代码必须被彻底地封装和隔离在最小的包或函数内部,绝不能让 unsafe.Pointer 或 uintptr 泄露到公共API中,上层必须通过类型安全的接口来调用。 详尽的注释和文档必不可少,需要解释清楚为何使用 unsafe 以及代码依赖的所有底层假设(内存布局、对齐、Go 版本等)。
此外,大量的、各种形式的测试(单元、集成、并发、跨平台)是必须的,并且 unsafe 代码必须经过团队中最有经验的成员进行严格的代码审查。最后,要时刻准备好,依赖 unsafe 的代码是脆弱的,Go版本更新或环境变化都可能导致其失效,需要持续维护甚至重写。
总而言之,反射是“运行时”的工具,而 unsafe 则是“绕过运行时”的工具。它们都属于高级特性,绝非日常编码的常规选择。我们应始终优先寻求静态类型、接口、泛型等更安全、更清晰的解决方案。只有在这些方法确实无法满足需求,并且我们完全理解并能够控制其风险与代价时,才应审慎地、有节制地考虑使用反射,并极度谨慎地、在严格约束下考虑使用 unsafe。驾驭它们需要深厚的知识和高度的责任感。
小结
这节课,我们深入Go语言的底层机制,探讨了反射( Reflection)和 unsafe 这两把强大,但必须审慎使用的“双刃剑”。
我们首先学习了反射。它赋予了我们在运行时检视类型( reflect.Type)、获取并操作值( reflect.Value)的动态能力。这种能力是构建通用框架(如序列化、ORM、依赖注入)的基石,使得代码可以处理在编译时未知的类型。然而,我们也清楚地认识到反射的代价:它牺牲了编译期的类型安全,将错误暴露推迟到运行时(可能导致 panic),带来了显著的性能开销,并且往往使代码变得更复杂、更难理解和维护。掌握反射的三大定律和核心API是基础,但更重要的是理解其适用边界,并始终优先考虑接口、泛型等静态类型方案,将反射作为最后的选择。
接着,我们探索了更为底层的 unsafe 包。它允许我们彻底绕过Go的类型系统和内存安全保障,通过 unsafe.Pointer(通用指针桥梁)和 uintptr(用于地址计算的整数)直接操作内存。这使得与C代码交互、进行极底层的系统操作或实现运行时内部机制成为可能,甚至在极少数情况下可用于压榨极致性能。但这种能力伴随着极高的风险:内存安全问题(悬空指针、越界访问)、数据竞争、类型系统破坏、极差的可移植性,以及极其困难的调试与维护。我们强调了必须严格遵守官方定义的六种安全使用模式,并将 unsafe 的使用严格限制在绝对必要的、最小化的范围内,由经验丰富的开发者在充分测试、封装隔离和详尽文档的前提下极度谨慎地应用。
总结来说,反射和 unsafe 都提供了超越Go常规类型和安全边界的能力,但它们付出的代价也十分高昂。 反射是以性能和部分编译期安全换取运行时的动态性;而 unsafe 几乎是以牺牲所有安全保障来换取最底层的控制力和理论上的性能极限。 两者都绝非日常编码的常规武器。
理解这两种高级特性的能力边界、风险所在,以及安全使用的准则,是Go进阶开发者的重要一课。不仅仅要学习如何使用它们,更重要的是学会判断何时应该使用,以及更常见的——何时应该坚决避免使用,转而寻求Go提供的更安全、更清晰、更易于维护的解决方案。驾驭好这两把“双刃剑”的关键,在于深刻理解其代价,并始终保持敬畏之心。
思考题
标准库的 encoding/json 包在进行 Marshal(编码)和 Unmarshal(解码)时大量使用了反射。
请思考:
-
为什么反射是实现通用
json.Marshal/Unmarshal功能的理想(甚至是必需)选择? -
既然反射有性能开销,那么对于性能要求极高的场景,如果需要处理JSON,有没有可以替代反射的方法?(提示:想想代码生成)
欢迎在评论区分享你的看法!我是Tony Bai,我们下节课见。
项目布局:构建清晰、可维护Go应用的基石
你好!我是Tony Bai。
欢迎来到模块二——设计先行,奠定高质量代码基础的第一节课!在模块一,我们强化了Go的语法细节,理解了类型、接口、并发原语等核心语法构建块。但仅仅掌握这些“砖瓦”还不够,要建造一座坚固、优雅、易于扩展的“软件大厦”,优秀的设计思维和实践至关重要。这个模块,我们将聚焦于如何在动手编码之前,运用良好的设计原则来规划我们的Go项目。
在这一模块中,我所讲解的设计不是指架构级别的设计,也不是服务、模块级别的,更多是代码层级的设计。
这部分设计甚至不需要文档化,可能只停留在我们大脑中。当然,如果能将其文档化,或以注释的形式放入源码文件中,自然最好。
我个人推崇“无设计不代码”,因此在这一模块中,我将围绕Go代码设计的六个主要方面进行系统地讲解:
而所有设计的起点,往往就是 项目结构布局(Project Layout)——我们如何组织代码文件和目录。一个清晰、合理的项目布局就像一座建筑的蓝图,它不仅能反映项目的组织方式和模块划分,更能极大地影响代码的可维护性、团队协作效率以及新成员的上手速度。
但Go项目的布局常常让人困惑:
-
是否存在官方的“标准答案”?
-
网上流传的各种“标准布局模板”靠谱吗?我们应该照搬吗?
-
像
cmd、internal、pkg这些目录,我们应该在什么时候以及如何正确使用它们? -
现代Go项目中的
go.mod和go.work又该如何与项目布局协同工作?
很多人可能没有机会从零设计项目结构,或者习惯遵循某种“约定俗成”的模板。但不理解项目布局背后的设计原则和Go语言自身的特点(比如对简洁性的推崇),可能会让我们陷入为了结构而结构、过度设计或组织混乱的困境。这节课,我们就深入探讨Go项目布局的设计之道,让你能根据项目的实际情况,做出明智、合理的布局决策。
我们将一起:
-
探讨一种 分层布局 的思考方式,帮你理清项目结构的不同关注点。
-
探索 主流的布局选择,辨析事实标准、社区惯例与需要警惕的反模式。
-
掌握 模块化管理 的最佳实践,特别是
go.mod与go.work的协同。
下面我们先来看看什么是分层布局,这可是我在Go项目布局设计方面的独创性思考哦。
分层布局:构建清晰应用的基础
在深入讨论具体的目录(如 cmd、 internal)之前,我们先建立一种 概念上的分层思维 来理解Go项目的结构。与其一开始就陷入目录细节,不如先从宏观上思考一个项目可能包含的不同层次的关注点。
Go项目布局的概念模型
借鉴Go社区的实践和思考,我们可以将一个Go项目的布局(尤其对于中大型项目)在概念上划分为三个层次:
这是一个思考Go项目布局的概念模型。最底层是所有项目都具备的最小布局,其上是可选的、按社区惯例组织的目录层,最上层是真正体现项目业务逻辑的包布局。我们逐一来看一下。
最小布局(Minimal Layout)
最小布局是任何一个Go Module的基础,构成了项目的“身份标识”和最核心的元数据。它通常只包含:
-
go.mod:定义模块路径、Go版本和依赖。 -
go.sum:依赖项的校验和。 -
LICENSE:项目的开源许可证,显然这是一个可选项,仅在你的项目是开源项目时有效。 -
README.md:项目的说明文档。无论是否是开源项目,我都建议你在项目中包含一份“项目的说明书”。
对于非常简单的库或工具,可能这就足够了。这与 Go官方布局指南 推荐的“从简单开始”不谋而合。
惯例布局(Conventional Layout)
在最小布局之上,随着项目变复杂,社区逐渐形成了一些组织代码的惯例目录。这些目录通常是可选的,用于解决特定的组织问题:
-
cmd:存放项目的可执行文件入口(main包)。当项目需要构建多个二进制文件时很有用。 -
internal:存放项目内部私有代码,Go工具链保证这里的包不能被外部模块导入。用于保护内部实现。 -
pkg:(有争议,但仍有项目使用)存放项目中可以被外部安全引用的公共库代码。 -
vendor:存放项目依赖的本地副本(通过go mod vendor生成)。
这一层提供了一种相对标准化的方式来组织不同类型的Go代码(应用程序入口 vs 内部实现 vs 公共库)。如果你对此有异议,别急,我们将在下一小节详细讨论这些目录的适用场景和注意事项。
业务布局(Business Layout)
这是项目最核心、最能体现其价值的部分,包含了实现项目特定功能的业务逻辑代码。这里的包组织方式应该完全由项目的领域、功能和架构决定,而非固定的模板。
-
对于Web服务项目,这里可能包含
api、service、handler、router、model、store等包。 -
对于命令行工具项目,这里可能是
command、parser、helper等。 -
对于数据库项目,这里可能是
engine、storage、query、parser等。 -
如果项目遵循DDD(领域驱动设计),可能是
domain、application、infrastructure等,体现领域模型、应用服务和基础设施的分离。 -
如果遵循 “Clean Architecture”(整洁架构),布局会强调依赖规则(依赖必须指向内层)。可能包含如
entities(核心领域模型)、usecases(应用逻辑,定义接口端口)、interfaces/adapters(包含controllers、presenters、gateways/repositories等适配器)以及infrastructure(具体外部依赖实现)等包,层层分离。 -
如果遵循 “六边形架构”(Hexagonal Architecture),布局会突出核心业务逻辑与外部世界的隔离。核心层定义所需端口(Ports,通常是接口),外部交互通过适配器(Adapters)实现,适配器会放在独立的包结构下,区分为驱动适配器(如
adapters/http、adapters/cli)和被驱动适配器(如adapters/database、adapters/messaging)。
这一层的关键在于:这些包的命名和组织方式应该反映业务本身和所选的架构风格,做到高内聚、低耦合。选择哪种架构风格应基于项目复杂度和团队熟悉度,并体现在“业务布局”的包组织上。
理解了这个概念分层模型,可以帮助我们更有条理地思考项目结构:先有基础(最小布局),再考虑是否需要引入社区惯例的组织方式(惯例布局),最后根据业务需求精心设计核心逻辑的包结构(业务布局)并决定将其置于何处。不过,你一定要做好区分: 这里我们讨论的“分层布局”是一种组织项目文件结构的概念模型,它不同于应用程序内部的“分层架构”(如Web应用中的表现层、业务层、数据访问层)。业务布局内部可能会实现这种分层架构(比如包含 api、 service、 store 包),但这只是业务布局的一种具体实现方式。
明确了这种分层的思考方式后,我们现在可以将目光聚焦到实践层面了。虽然Go官方没有强制规定布局,但社区在长期实践中,围绕着“惯例布局”层和如何组织“业务布局”层,逐渐形成了一些主流的选择和看法。接下来,我们就来探索这些主流的布局实践,辨析其中的事实标准、社区惯例,并警惕一些可能被误用的反模式。
主流选择:探索Go项目标准布局及变种
明确了概念上的分层布局思路后,我们现在可以将目光聚焦到实践层面。虽然Go官方并没有像某些语言那样强制规定一套详细的项目结构,但社区在长期的实践中,围绕着“惯例布局”层和如何组织“业务布局”层,逐渐形成了一些主流的选择和看法。当然,也伴随着一些需要警惕的、可能被误用的“反模式”。下面,我们就来探索这些主流的布局实践,帮助你理解不同结构选择背后的考量,辨析事实标准与社区惯例,从而为你的项目选择合适的起点。
有机生长,警惕“伪标准”与过度设计
在开始组织项目结构时,最重要的一点或许是心态。Go语言推崇简洁和实用主义。这意味着我们应该避免一开始就构建一个过于庞大和复杂的目录结构,尤其要警惕那些看似“标准”实则可能过度设计的模板。
你在网上可能经常看到 golang-standards/project-layout 这个GitHub仓库,它提供了一个非常详尽的目录结构。虽然它可以作为了解大型项目可能需要哪些组织的参考,但它绝非官方标准,且对于大多数项目而言过于复杂。直接套用这样的模板,很容易陷入“为了结构而结构”的陷阱,创建大量目前并不需要的空目录,或者在需求尚不明确时就进行不成熟的抽象和分层,这反而违背了Go的简洁哲学。
正确的做法应该是让项目结构“有机生长”。遵循Go官方在 Organizing a Go module 指南中传递的核心思想: 从最简单的结构开始,按需添加复杂性。一个简单的库可能只需要根目录下的几个 .go 文件;一个简单的命令行工具可能也只需要根目录下的 main.go。只有当项目规模增长、职责需要分离,或者需要明确区分内部与外部代码时,才逐步引入更复杂的结构。
核心惯例目录的审慎使用
随着项目复杂度的增加,一些具有特定含义的顶层目录(我们之前称之为“惯例布局”层的一部分)可能会被引入。理解它们的确切含义和适用场景至关重要,避免误用。我们首先来看看cmd目录。
cmd目录:可执行文件入口
在Go的惯例中,cmd目录用于存放项目的 可执行文件入口(即包含 main 函数的包)。如果一个项目有多个可执行文件,那么cmd目录下可以放置多个入口包。
Go官方建议,只有当你的代码仓库(module)同时包含可供导入的库包(library packages)和多个命令包(command packages)时,才使用 cmd 目录来存放这些命令包。这样做可以清晰地将应用程序入口与库代码分开。
myproject/
├── cmd/
│ ├── server/ # Web服务器入口
│ │ └── main.go
│ └── cli/ # 命令行工具入口
│ └── main.go
├── internal/
│ └── logic/
├── mylib/ # 可供外部导入的库包
│ └── mylib.go
└── go.mod
如果你的项目目标是创建一个可供其他项目导入使用的 Go 库,不包含任何可执行的 main 包,那么完全不需要 cmd 目录。所有的库代码(包括可能的子包)直接放在项目根目录或者根目录下的子目录中即可,比如下面这个示例:
mypubliclib/
├── internal/ # (可选) 存放内部实现细节
│ └── helper/
│ └── helper.go
├── subpkg/ # (可选) 公共的子包
│ └── feature.go
├── mypubliclib.go # 库的主要入口或核心功能
├── mypubliclib_test.go
├── go.mod
└── README.md
如果你的项目包含一些内部库或者一些公共库,但 最终只构建一个可执行文件,Go官方的建议是将这个 main 包(通常是 main.go)直接放在项目根目录下。比如下面这个示例:
mycli_tool/
├── internal/ # (可选) 内部库
│ └── core/
│ └── logic.go
├── utils/ # (可选) 公共库包 (放在根目录)
│ └── strutil.go
├── main.go # <--- 应用入口直接在根目录
├── main_test.go
├── go.mod
└── README.md
针对这样的项目,构建命令就是简单的 go build 或 go install github.com/user/mycli_tool。这种结构对于大多数单一应用程序或命令行工具来说,是最简洁明了的。
如果你的项目包含多个独立的可执行命令,但没有打算提供任何可被外部导入的库包(所有共享代码都放在 /internal 或不共享),Go官方指南倾向于直接在根目录下创建命令子目录:
my_multi_command_project/
├── internal/ # (可选) 共享的内部代码
│ └── shared/
│ └── common.go
├── command1/ # 命令1的目录
│ └── main.go
├── command2/ # 命令2的目录
│ └── main.go
├── go.mod
└── README.md
接下来,我们再说说internal目录。
internal目录:存放内部私有代码
internal目录用来存放项目内部私有的代码,这是Go工具链在Go 1.4版本引入的一个特殊规则: internal 目录下的包不能被项目外部的其他Go模块导入。
当你编写一个库供他人使用时,如果不希望暴露给用户的内部实现细节(如辅助函数、内部数据结构),则可以将这些细节放在 internal 下,这可以强制保护你的公共API边界。
mylib/
├── internal/
│ └── helper/
│ └── helper.go // 外部无法 import mylib/internal/helper
├── mylib.go // 公共 API
└── go.mod
一些大型应用程序,为了确保应用内部的核心模块(如业务逻辑、数据访问层)不被其他非核心或未来可能添加的模块意外依赖,也会将这些包放在internal下:
webapp/
├── internal/
│ ├── service/ // 核心服务
│ ├── store/ // 数据存储
│ └── auth/ // 认证逻辑
├── cmd/
│ └── server/
│ └── main.go // main 可以导入 internal/service 等
└── go.mod
不过要注意:internal只是限制了外部模块的导入,同一模块内的包(比如上例中的 /cmd/server)可以导入同一模块 internal 目录下的包。此外,如果你的项目只是一个独立的应用程序,并不作为库发布,使用 internal 的必要性相对较低,可以通过包设计和导出机制来管理可见性。
接下来,我们再来看看争议最大的pkg目录。
pkg目录:供外部项目导入和使用的公共包
如果你学习过我的《 Go语言第一课》,应该知道Go官方在1.4版本后不再使用顶层 pkg 存放源码,且其名称本身缺乏明确语义,但长期以来Go社区的一些项目还保留着pkg目录这一“惯例”,这也影响了很多Go开发者,以至于出现了所谓的“pkg目录”争议。
在Go社区惯例中,pkg目录用于存放项目中那些 明确希望可以被外部项目安全导入和使用的公共库代码,它试图与 internal(内部代码)和 cmd(应用程序入口)形成区分。
按Go社区惯例,当你的代码仓库(module)同时包含应用入口(在 cmd 下)和一些你想作为公共库提供的包时,可以将这些公共库放在 pkg 下。这与使用 cmd 的场景类似,都是为了在混合项目中区分不同类型的代码。
mytoolchain/
├── cmd/
│ ├── mytool1/
│ │ └── tool1.go
│ └── mytool2/
│ └── tool2.go
└── go.mod
├── internal/
│ └── corelogic/
├── pkg/
│ ├── parser/ // 可供外部使用的解析器库
│ │ └── parser.go
│ └── formatter/ // 可供外部使用的格式化库
│ └── formatter.go
└── go.mod
不过,Go官方布局指南中的确没有提及pkg目录,对于上面示例中的情况,官方更倾向于将parser、formatter直接放在顶层目录下:
mytoolchain/
├── cmd/
│ ├── mytool1/
│ │ └── tool1.go
│ └── mytool2/
│ └── tool2.go
└── go.mod
├── internal/
│ └── corelogic/
│── parser/ // 可供外部使用的解析器库
│ └── parser.go
│── formatter/ // 可供外部使用的格式化库
│ └── formatter.go
└── go.mod
我认为对于提供少量公共库包的项目,直接放在根目录下完全没问题,Go官方指南也推荐了这种方式。但对于一些拥有大量导出公共包的大型Go项目,将这些包都平铺到顶层目录下,值得商榷。对于这样的项目,我的第一感觉就是有些“凌乱”和不整洁。这时候,如果将这些导出公共包放到pkg目录下,可以让整个代码库显得相对整洁,虽然pkg这个名字的确没有任何明确的语义,更多是约定俗成。
因此,是否使用 pkg 目录需要团队内部达成共识,并理解其潜在的争议和历史包袱。如果决定要用pkg,那pkg内必须只放真正稳定且公开的库代码,这也是Go社区中一条不成文的共识。
综上,在“惯例布局”层,没有哪个目录是必须的。 cmd、 internal 和 pkg 都是为了解决特定组织问题而出现的可选惯例。理解它们的目的,并在项目确实需要时才引入它们,切记避免盲目跟风。
业务布局的实践原则
掌握了上述惯例目录的用法之后,我们终于来到了项目结构设计的核心目录。一个项目中最核心、最体现其价值的部分,始终是那些实现具体业务功能的,即如何组织真正实现项目功能的业务布局(Business Layout)。这部分的包划分和命名最能体现一个项目的设计质量和开发者的架构思考。
虽然没有固定的模板,但遵循一些重要的实践原则,可以帮助我们构建维护性、可扩展性和团队的开发效率:
-
避免“大杂烩”包(
utils、common等):这是最常见的反模式之一。这些包往往职责不清,最终变成难以维护、依赖混乱的“垃圾桶”。辅助函数应就近放置(如果只被一个包用),或者根据其具体功能领域(如strutil、httputil、config)组织成独立的、依赖层级低的包。 -
包名体现领域或职责:包的命名和划分应该清晰地反映其包含的代码所负责的业务领域(如
user、order、payment)或技术职责(如api、service、storage、middleware)。好的包名本身就是一种文档。 -
尊重依赖方向(DAG):Go强制要求包依赖必须形成有向无环图,禁止循环依赖。当出现循环依赖错误时,通常意味着架构设计或职责划分存在问题。应通过调整代码结构、提取接口或引入新包等方式从根本上解决,而不是试图用技巧绕过。
-
适度重复优于不当依赖:不要为了消除几行相似的代码而强行提取公共函数并引入复杂的包依赖关系。Go社区普遍认为,为了保持包的独立性和低耦合,接受适度的代码重复通常是更好的选择。在抽象和提取公共部分之前,仔细思考这些“重复”是否真的属于同一概念,以及它们未来的演化方向是否一致。
设计业务布局是一个需要根据项目具体情况不断权衡和演进的过程。保持简洁,聚焦于清晰的职责划分和依赖管理,是通往良好设计的关键。Go包设计方面的内容,我们将在下一节课系统讲解,这里就不赘述了。
确定了项目代码的物理组织结构(目录和包)之后,现代Go开发还有一个不可或缺的基础设施,那就是模块化管理。自Go 1.11引入Modules以来,go.mod 文件已成为定义项目身份、管理版本和依赖关系的核心,也是前面Go项目最小布局中必需要有的文件。而Go 1.18带来的go.work则进一步优化了多模块本地开发的体验。理解并善用这两个工具,对于维护健康的依赖关系、保证构建的可靠性,以及提升开发效率至关重要。下面,我们就来探讨 go.mod 和 go.work 的最佳实践。
模块化管理:go.mod与go.work的最佳实践
现代Go开发有一个不可或缺的基础设施,那就是模块化管理。自Go 1.11引入Modules以来, go.mod 文件已成为定义项目身份、管理版本和依赖关系的核心标准。如果你还在使用旧的GOPATH模式,强烈建议尽快迁移到Go Modules。
go.mod 文件通常位于项目的根目录,属于我们之前讨论的“最小布局”的一部分。 它的核心作用是定义模块的唯一路径(通常是版本控制仓库的路径,如 github.com/user/repo), 声明项目所需的最低Go版本,最重要的是精确记录项目所依赖的其他模块及其版本。Go工具链(如 go build、 go test、 go run)会依据 go.mod 文件来下载和使用正确的依赖版本,保证了构建的可重复性。
在日常开发中, 维护 go.mod 的最佳实践是让Go命令自动管理它。当你添加或移除导入语句时,运行 go mod tidy 命令会自动更新 go.mod 和 go.sum(校验和文件),添加新的必要依赖并移除不再使用的依赖。 我们通常不应手动编辑 go.mod 中的依赖版本列表。
不过, go.mod 也提供了两个需要谨慎使用的指令: replace 和 exclude。 replace 指令允许我们将某个依赖重定向到本地文件系统上的另一个模块或者一个不同的版本库/版本,这在本地开发和调试(虽然现在 go work 是更好的选择)或临时应用未发布的修复时有用,但需要注意 replace 指令只在当前主模块生效,不会被依赖你模块的其他项目继承。 exclude 指令则用于明确排除某个有问题的依赖版本。
当项目规模进一步扩大,或者你需要在本地同时开发和测试多个相互关联的Go模块时,Go 1.18 引入的 go work 和 go.work 文件就显得尤为重要。想象一下这种场景:你正在开发一个Web应用程序 myapp,它依赖于你团队维护的一个共享库 mylib。这两个项目是独立的Go模块,位于你本地文件系统的不同目录下。
示例项目布局(本地开发环境):
workspace/ <-- 你的工作区根目录 (任意名称)
├── myapp/ <-- 应用程序模块
│ ├── go.mod # module github.com/myorg/myapp
│ │ # require github.com/myorg/mylib v1.2.0
│ └── main.go # import "github.com/myorg/mylib"
│
└── mylib/ <-- 库模块
├── go.mod # module github.com/myorg/mylib
└── mylib.go # package mylib
现在,你需要在本地同时修改 myapp 和 mylib 的代码,并测试 myapp 使用你本地 mylib 修改后的效果。在没有 go work 之前,你可能需要在 myapp/go.mod 中添加一行 replace github.com/myorg/mylib => ../mylib。这种方式可行,但容易忘记移除 replace 指令,或者导致 go.mod 文件在不同开发者之间不一致。
go work 提供了一个更优雅的解决方案。你可以在 workspace 目录下(或者任何包含 myapp 和 mylib 的父目录)初始化一个工作区:
cd workspace
go work init ./myapp ./mylib # 或者先 init,再 use
# 这会在 workspace/ 目录下生成一个 go.work 文件
go.work 文件的内容大致如下:
go 1.21 // 指定工作区使用的 Go 版本
use (
./myapp
./mylib
)
有了这个 go.work 文件,当你在 myapp 目录内(或者 mylib 目录内,或 workspace 目录内)执行Go命令(如 go build、 go test)时,Go工具链会自动识别出 mylib 也在工作区中,并且会 优先使用本地 workspace/mylib 目录下的源码,完全忽略 myapp/go.mod 中对 github.com/myorg/mylib v1.2.0 的依赖声明。这使得多模块的本地开发和联调变得极其顺畅。
关于 go.work 文件,一个重要的最佳实践是 通常不应将其提交到版本控制系统(VCS)。因为它主要反映的是开发者的本地开发环境配置,不同开发者可能需要协同开发不同的模块组合。
当然,也有例外情况:如果你的代码仓库本身就是一个monorepo(单一仓库),即在一个仓库中包含 多个需要协同构建和发布的Go模块,那么将 go.work 文件纳入版本控制,可以确保所有开发者和CI/CD流程都使用一致的工作区配置,这在这种特定场景下是合理的。管理工作区也非常简单,可以使用 go work use ./path/to/module 添加模块,或者 go work edit -dropuse ./path/to/module 来移除。
总而言之,熟练掌握 go mod 系列命令来管理单个模块的依赖,并善用 go work 来优化多模块本地协同开发的流程,是现代Go项目开发中保证构建可靠性、维护健康依赖关系并提升开发效率的关键实践。
小结
为Go项目设计一个清晰、可维护的布局是项目成功的基石。尽管没有唯一的官方标准,但通过理解 Go 的设计哲学和社区的实践经验,我们可以遵循一些核心原则来指导我们的决策。
-
分层布局思考:从概念上区分项目的最小布局(基础文件)、惯例布局(可选的
cmd、internal、pkg等目录)和业务布局(核心功能包),有助于我们结构化地思考项目组织,从全局视角把握结构。 -
有机生长,警惕“伪标准”:遵循Go官方从简单开始的建议,让项目结构随着实际需求有机演化。警惕
golang-standards/project-layout这类大而全的模板,避免过度设计和不必要的复杂性。 -
审慎使用惯例目录:理解
cmd(多入口,或混合项目中的入口)、internal(内部保护)和pkg(可选公共库,需谨慎)的确切目的和适用场景。只在项目确实需要解决这些特定组织问题时才引入它们。 -
业务驱动核心布局:项目的核心“业务布局”应该反映其领域模型和架构设计,追求高内聚、低耦合。坚决避免
utils、common等“大杂烩”包,让包名体现职责,尊重Go的依赖方向规则(DAG),并在适度重复和不当依赖之间做出明智权衡。 -
善用模块化工具:熟练使用
go mod管理单个模块的依赖,利用go work优化多模块本地协同开发的流程,使其更加顺畅高效,并理解go.work文件通常不提交到VCS的原则(monorepo除外)。
最终,最好的项目布局并非照搬某个模板,而是那个能够清晰反映项目逻辑、易于团队协作、并能灵活适应未来变化的布局。保持简洁、价值驱动、让结构服务于内容,这或许就是Go项目布局的“大道至简”。
思考题
通过今天的学习我们知道,应避免创建名为 utils、 common、 shared 的“大杂烩”包。
假设你在开发一个Web服务时,发现多个 handler 包都需要用到一些关于解析HTTP请求头(比如获取 X-Request-ID)和设置通用响应头(比如 Content-Type: application/json)的辅助函数。
你会如何组织这些辅助函数,既能实现代码复用,又避免创建像 httputil 或 webutil 这样的潜在“杂烩”包?(提示:考虑这些辅助函数的具体功能、依赖关系,以及可能的组织方式,比如放在更具体的包内,或者创建一个非常专注的小包?)
欢迎在评论区分享你的布局方案和思考过程!我是Tony Bai,我们下节课见。
包设计:如何实践高内聚、低耦合与SOLID原则?
你好!我是Tony Bai。
上一节课我们讨论了宏观的项目布局,为代码找到了安放的“社区”和“街道”。但仅仅有好的布局还不够,项目的真正活力来自于构成它的基本单元——包(package)。可以说, Go应用的本质就是一组设计良好、协同工作的包的集合。如何设计出职责清晰、依赖合理、易于维护的包,是衡量Go代码质量的关键,也是我们设计先行模块的核心议题。
你可能会问:
-
Go的包在设计中到底扮演什么角色?仅仅是代码的容器吗?
-
人人都说“高内聚、低耦合”,在Go包设计中,这具体怎么落地?
-
经典的SOLID设计原则,对于没有继承、推崇组合的Go,还有效吗?如何用Go的方式实践它们?
-
有哪些常见的包设计“陷阱”或“反模式”是我们必须警惕和避免的?
不理解Go包设计的核心原则,可能会让我们创建出职责混乱、依赖纠缠、难以测试和扩展的“意大利面条式”代码。 掌握良好的包设计实践,是编写出地道、可维护、高质量Go代码的必经之路。
这节课,我们就来深入探讨Go包设计的艺术与科学。在我们深入包设计原则之前,我们先来重新认识Go包。
Go包的认知:基本的功能、编译和设计单元
我们知道Go包是Go编程语言中的一个重要概念,它是一组相关的Go源代码文件。并且,在Go中,每个Go源文件都必须属于一个包。但Go包又不仅仅是一个存放 .go 文件的目录,它在Go语言中承载着多重关键角色。
Go包是基本功能单元
Go包是一个逻辑上独立的单元,是Go的基本功能单元,用来做功能和职责边界的划分。比如标准库的 fmt 包负责格式化I/O, net/http 包负责HTTP客户端和服务端实现。一个设计良好的包,其名称( pkgname)和提供的API( pkgname.PublicSymbol)应该能清晰地反映它所承担的功能。这些基本功能单元的累加就构成了Go应用,因此Go应用的本质就是一组Go包的集合。
Go包这种功能独立的单元为Go开发者提供了“封装”和复用的便利。在Go中,Go包也是代码复用的基本单元,被用来管理和组织代码,上一节课 《Go项目布局》 本质上就是安排Go包的位置,使得代码更易于维护和重用。
Go包是基本编译单元
Go包还是编译时的最小单位。也就是说,Go编译器编译代码时会以包为单位进行编译,而不是以文件为单位。这意味着一个包中的所有源文件都将被编译成一个单独的目标文件(通常是 .a 归档文件),而不是多个目标文件。
使用包而不是文件作为编译单元,有助于提高编译效率和管理依赖关系。Go编译速度快是包这种设计“先进性”的一个表现,即便每次编译都是从零开始。Go编译速度快的几个原因与以包作为编译单元是密不可分的,具体体现在Go源文件在开头处显式地列出所有依赖包,编译器不必读取整个文件就可确定依赖包列表;Go包之间不能存在循环依赖,由于无环,包可以被单独编译,也可以并行编译;已编译的Go包的目标文件中记录了其所依赖包的导出符号信息。Go编译器在读取该目标文件时不需进一步读取其依赖包的目标文件。
Go包是基本设计单元
这个世界越来越复杂,软件系统同样变得日益复杂。无论你是什么编程语言的开发者,我们要面对的都是如何驯服这种复杂性。到目前为止,我们驯服这种复杂性的思路还很初级,无非是 对复杂性进行分解、分解、分解,并按照我们更容易理解的方式重新组合。
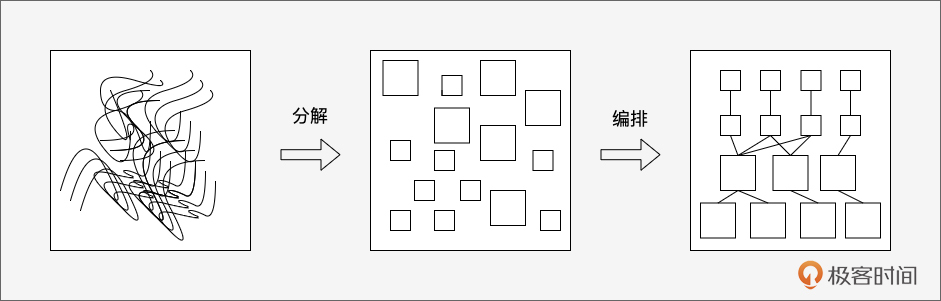
Go包是基本功能单元,对于Go开发者,我们要将复杂性分解为一个个包,然后以一种合理的方式将包组合在一起以实现我们要的系统,因此Go包也是我们面对一个系统时的基本设计单元。我们不仅要设计每个包肩负的职责,还要设计包与包之间的关系,以及每个包对外暴露的API(接口)。可以说, Go的系统设计很大程度上就是面向包进行的设计。
理解了包的这三重身份,我们就能更好地把握包设计的重要性,以及后续原则的出发点。接下来,我们就来看看Go包的设计思路。
Go包的设计思路:自然内聚性与最小耦合
即便你没写过Go程序,作为程序员你也应该知道“高内聚、低耦合”这个原则在软件系统设计中的分量。
以上面的复杂性分解和组合的示意图为例,高内聚是指导复杂性分解的原则:
而低耦合则是指导分解后的模块重新组合的原则:
这里我们就以这个原则作为“抓手”,展开看看Go包的设计思路。
高内聚、低耦合这个顶层原则,适用于所有编程语言的系统设计。但落到Go包设计上面,具体如何体现高内聚与低耦合呢?我们继续往下看。
功能选桶:包的自然内聚性
面对一个复杂系统,我们通常会做一些系统分析,比如用领域驱动设计的方式从需求中挖掘出一堆术语、事件、命令等(即便你不懂领域设计的纯正方法,你的实际操作过程也或多或少与领域设计的内容重叠)。之后,通常会分层、划分服务,每个服务又要划分模块或包。
在服务这一层次上哪些功能放到哪个包里呢?这个过程我称之为“功能选桶”,如下面示意图。
这让我想到了和孩子一起学习动物分类时的书中题目:
有这样一组动物:老虎、狮子、海马、大雁、熊猫、黄鹂、鲸鱼,这些动物能分为哪几个类别呢?
一个稍稍被启蒙了的孩子都会给出这样的分类:
陆地动物:老虎、狮子、熊猫
海洋动物:海马、鲸鱼
天空动物:大雁、黄鹂
而另外一个稍有一些生物学入门知识的大点的孩子可能会给出下面的分类:
哺乳动物:老虎、狮子、熊猫、鲸鱼
卵生动物:海马、大雁、黄鹂
无论哪种,这些分类都是基于动物行为特征的自然结合。第一种似乎更直观自然,第二种则需要有更“专业”的知识(领域知识)。Go包的“功能选桶”其实是一个道理,相关功能自然结合到一个包中,保证这个包的内聚性。
再比如这几个功能函数:Add、Subtract、Multiply、Divide、Sum、Average、Histogram,我们如何为它们选桶呢?
一种不那么内聚的作法是将上述所有函数都放入math包;而更自然内聚一些的作法则是将Add、Subtract、Multiply、Divide放入math包,将Sum、Average、Histogram等放入stats包(statistics,统计学),如下图所示。
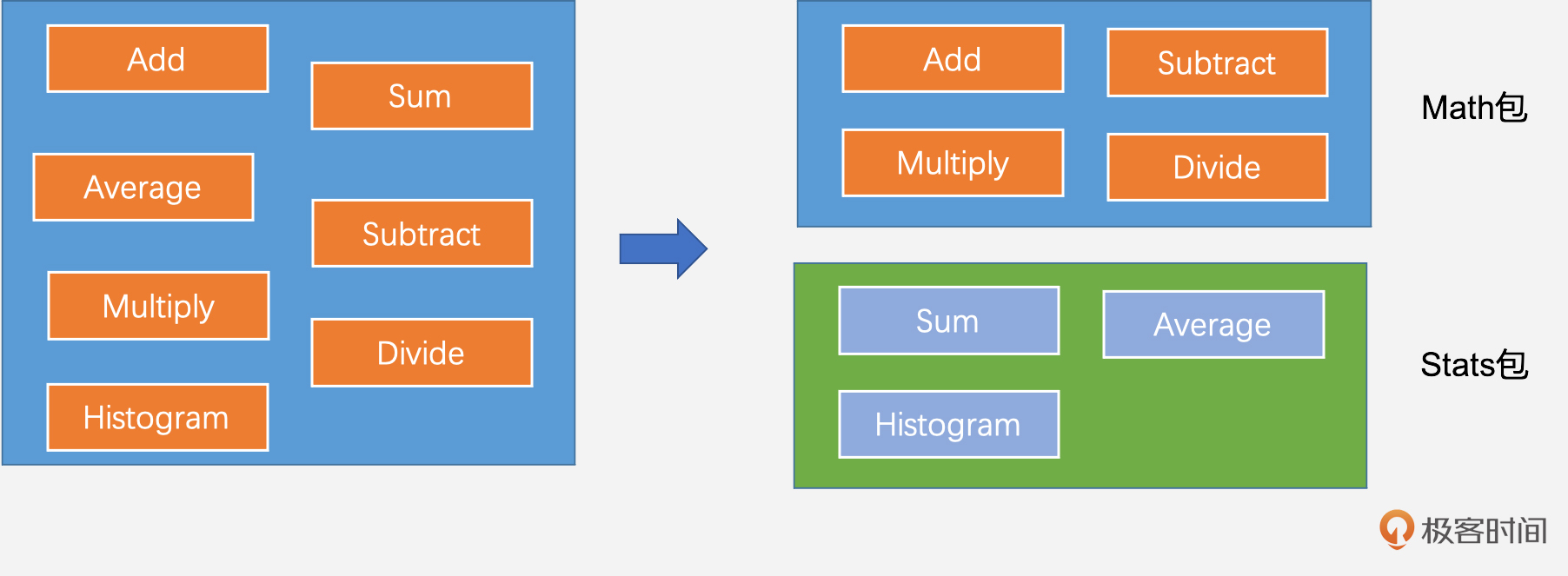
此外, 好的包名是内聚性的关键信号:一个内聚性好的包,通常能用一个 简洁、准确、具有描述性 的名字来概括其职责。标准库的 net/http、 os/exec、 encoding/json 都是好例子。反之,像 utils、 common、 helpers 和 shared 这样的包名,往往是 缺乏内聚性、职责不清 的信号,极易变成代码的“垃圾抽屉”,是需要极力避免的反模式。
此外,如果一个功能只被一个包使用,最好就近放在那个包里(可以不导出)。如果被多个包使用,我们要思考它真正属于哪个功能领域,并为其创建有意义的新包。
在进行“功能选桶”时,越符合我们对现实世界或问题领域的自然理解,划分出的包就越可能具有高内聚性,可读性和可理解性大概率就越好。
包间关系:最小耦合
功能选桶之后,我们再来看包与包之间的关系,通常我们称这种关系称为耦合。
用白话来理解耦合就是:当a变化时,b受到影响并随之变化,则说b与a之间存在耦合,即b依赖a。a是引发b变化的一个原因。
程序员都知道: 一种理想的耦合情况是正交,即你变你自变,我岿然不动。但现实中这很难达到,我们应该追求的是尽可能地降低包与包间的耦合。
在包依赖层面,Go强制要求不能存在循环依赖,即 Go包之间的耦合一定是有向无环的,这一定层度上也能帮助Go包之间降低耦合。
要降低包与包之间的耦合,我们首先要了解Go包间的最低耦合关系是什么。
在代码层面最低的耦合是接口耦合,在Go中,接口的实现是隐式的,即a包实现b包中定义的接口时是不需要显式导入b包的,我们可以在c包中完成对a包与b包的组装,这样c包依赖a包和b包,但a包与b包之间没有任何耦合。
那么负责组装a包与b包的c包能否在代码层面消除掉对a和b的依赖呢?这个就很难了。我们可以使用依赖注入技术,来消除在代码层面手动基于依赖进行初始化或创建时的复杂性,不过依赖注入技术也有“门槛”,它会让你的代码不那么直观,代码的可读性和可理解性会下降。
注:依赖注入在Go中并非是一种惯用法。Google开源了像 wire 这样的依赖注入框架(通过代码生成而实现的编译期依赖注入),更多是为了解决掉内部大型Go项目初始化时各种创建动作的复杂性。
我们可以参考软件界用于降低代码耦合的原则,比如由Robert C. Martin(通常被称为“Uncle Bob”)在 《敏捷软件开发》 一书中提出的,旨在帮助开发人员设计更加灵活、可扩展和可维护的软件系统的SOLID敏捷设计原则。那么,这些原则如何应用在Go上,或者在Go中如何体现呢?我们接着来看。
SOLID原则:在Go包设计中的应用
SOLID是由Robert C. Martin提出的五个面向对象设计原则的首字母缩写。虽然Go并非传统OO语言,但这些原则背后蕴含的设计思想对于编写高质量、可维护的Go代码(尤其是包的设计)仍然具有重要的指导意义。我们需要结合Go的特性来理解和应用它们。下面我们就逐一看一下如何将SOLID原则应用在Go包设计方面。
单一职责原则(SRP)
对于一个类而言,应该仅有一个原因会引起它的变化。在SRP的语境中,我们把职责定义为“变化的原因”(a reason for change)。如果你有超过一个的动机去改变一个类,那么这个类就具有多种职责。——《敏捷软件开发》
就像Uncle Bob在书中说的那样:“如果你有超过一个的动机去改变一个类,那么这个类就具有多种职责。有时,我们很难注意到这一点。我们习惯于以组(group)的形式去考虑职责”。
在Go包这一层次上,SRP更多体现在功能内聚上,就像前面举的math包和stats包的例子。
再比如我们有一个图形库,它可以绘制不同类型的图形,如矩形、圆形、三角形等。我们可能会定义一个graph包,里面定义了Graphics类型,它具有Draw方法,用于绘制图形。在不遵循SRP的情况下,graph包Graphics类型可能会包含绘制各种类型图形的代码,这会导致类不仅包含多个职责,而且功能不够内聚。
在遵循SRP的情况下,我们可以在graph包中定义Graphics接口,该接口具有Draw方法,然后在rectangle、circle、triangle包中分别定义Graphics接口的实现:Rectangle类型、Circle类型与Triangle类型:
graph/
- graph.go // 定义Graphics接口
- rectangle/
- rectangle.go // 定义Rectangle类型和其Draw方法
- circle/
- circle.go // 定义Circle类型和其Draw方法
- triangle/
- triangle.go // 定义Triangle类型和其Draw方法
这样,每个包都只负责一个图形类型,职责更加单一,也更容易维护和扩展。
开放-关闭原则(OCP)
软件实体(类、模块、方法等)应该对扩展开放,但是对修改关闭。——《敏捷软件开发》
还以上面的graph等包为例,OCP原则可以体现在两方面。
首先是扩展Graphics接口的实现。我们无法修改graph.go中的Graphics接口,但如果你要添加一个square包,定义Square类型并实现Draw方法,那么我们可以在graph包下面添加一个square包,这个包和circle等包位于同等位置,都实现了graph包的Draw方法。这样我们便很容易地扩展出一种新的“绘制正方形”的新功能。
其次是基于Graphics接口的组合。我们无法修改graph.go中的Graphics接口,但是我们可以基于graph.Graphics接口去组合出其他具有更多职责的接口或非接口类型,就像io包中的Reader、Writer接口被组合到ReaderCloser、ReadWriteCloser中一样。
OCP原则的关键是抽象,在Go中建立包与包之间关系抽象的最佳方法就是建立接口类型。前面说过,通过接口的耦合是最低的包间耦合,因此采用OCP原则对于降低包间耦合具有重要意义。
不过,Bob大叔在书中也说了:“遵循OCP的代价也是昂贵的。创建恰当的抽象是要花费时间和精力的。那些抽象也增加了软件设计的复杂性,开发人员有能力处理的抽象数量是有限的”。OCP原则的应用应该被限定在最可能发生的变化上。
里氏替换原则(LSP)
对于里氏替换原则(LSP),可以如此解释:子类型(subtype)必须能够替换掉它们的基类(base type)。——《敏捷软件开发》
Bob大叔在讲解LSP原则时使用的语言是C++和Java,对于这两种静态类型的OO语言来说,支持抽象和多态的关键机制之一是继承(inheritance)。也只有在继承的概念之上,采用基类和子类之分。
不过Go并非传统意义上的OO语言,它没有继承,没有类型层次体系。即便没有这些,Go也不乏抽象表达能力,最直接的就是接口这个行为的集合。
这样里氏替换原则(LSP)在Go中就可以如此解释: 接口I的所有实现都是可以相互替代的,因为它们履行了同样的契约。
接口隔离原则(ISP)
客户端程序不应该被迫依赖于它们不需要的方法。——《敏捷软件开发》
这在体现Go包与包关系层面不是那么明显,方法已经告诉你这种耦合是接口耦合,但究竟用的是什么样的接口呢?“胖接口”,不是!我们需要刚刚好,不多不少的接口。
来看一个例子,我们有如下一些接口定义:
type Printer interface {
Print()
}
type Scanner interface {
Scan()
}
type PrintSleeper interface {
Printer
Sleep()
}
type PrintScanSleeper interface {
Printer
Scanner
Sleep()
}
现在我们要实现一个打印机打印的API,我们最初的设计是:
func Print(p PrintScanSleeper, data []byte) error {
}
在这个设计中,Print函数依赖的是PrintScanSleeper,这意味着传入的合法参数类型必须要实现Print、Scan和Sleep三个方法,但我们的函数只是为了实现打印,它不需要调用Scanner的Scan方法,根据ISP原则,我们不应该强迫Print函数依赖它们本不需要的方法,于是第二版设计如下:
func Print(p Printer, data []byte) error {
}
这似乎无懈可击。但常识告诉我们,每次打印结束后,都需要让打印机休眠,显然仅依赖Printer接口又缺少了点东西,那么最终版的设计如下:
func Print(p PrintSleeper, data []byte) error {
}
对ISP原则的白话阐述就是:“不多不少,刚刚好”!
依赖倒置原则(DIP)
高层次的模块不应该依赖低层次的模块。两者都应该依赖抽象。抽象不应该依赖于细节,细节应该依赖于抽象。——《敏捷软件开发》
如果你的代码符合上面几条原则的话,那么到这里,你的代码很大可能也是符合DIP原则的。
一提到“依赖抽象”,你肯定想到的还是接口。在Go中,接口是抽象的主要代名词。
在包与包的关系层面上,DIP原则表现为:高层次包依赖接口,低层次的包实现接口。示例如下图:

因此,在同等条件下,采用DIP原则设计良好的Go程序的包导入图应该是宽而平的,而不是高而窄的:
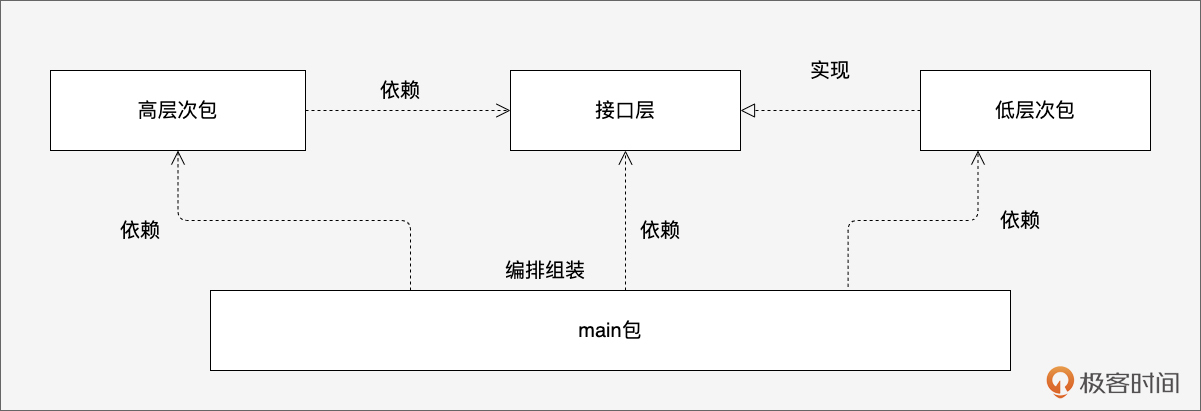
应用SOLID原则能帮助我们设计出更灵活、可维护、易于测试的Go包结构。
单包内部的设计要点
除了包与包之间的关系,单个包内部的设计也同样重要。我们来讲一些关键点。
包名
我们在引用某个包的导出标识符时使用的是:
pkgname.XXX
由此可见包名的重要性,它可以理解为 一个包的API的重要组成部分,因此 包设计的第一步就是要为包起个好名字。
给Go包起名字首先要注意简单达意,比如标准库的fmt、io、os等,并且包名按惯例应该与其目录名一致。同一工程内部包名最好是唯一的,避免工程内部出现名字碰撞。如果为了简洁而失去了包名的内聚性的内涵(功能和作用),比如utils、common这些名字基本无法表达包究竟担负的职责,那么莫不如将包名加长一些,点缀上能达意的单词,比如printutil而不仅仅是util。
最小化暴露表面积
这是最重要的原则之一。包应该只导出(Export)那些确实需要被外部使用的类型、函数、常量和变量(通常首字母大写)。所有仅供包内部使用的辅助类型、函数或状态,都应该保持非导出(unexported,首字母小写)。这样做的好处是:
-
封装:隐藏了实现细节,使得包的内部实现可以自由修改而不影响外部使用者(只要公共API不变)。
-
减少耦合:外部代码只能依赖于稳定的公共API,而不是脆弱的内部实现。
-
API清晰:公共API更少、更专注,更容易理解和使用。
package calculator
import "errors"
// Add 是公共 API,需要导出
func Add(a, b int) int {
return add(a, b) // 调用内部非导出函数
}
// add 是内部实现细节,不需要导出
func add(a, b int) int {
// ... 可能有一些内部逻辑 ...
return a + b
}
var errInternal = errors.New("internal error") // 非导出错误变量
避免包级状态
包级别的变量(尤其是可导出的)本质上是全局变量。全局状态会带来诸多问题:
-
隐藏依赖:函数的行为可能隐式地依赖于这些包级变量的状态,使得代码难以理解和推理。
-
测试困难:测试时需要管理和重置这些全局状态,测试用例之间可能相互影响。
-
并发问题:如果多个goroutine并发地读写包级变量而没有适当的同步,会导致数据竞争。
package config
// 反模式:使用包级变量存储配置
var DefaultConfig = map[string]string{"timeout": "10s"}
func Get(key string) string { return DefaultConfig[key] } // 隐式依赖全局状态
// 推荐模式:通过结构体封装状态,显式传递
type Config struct { settings map[string]string; mu sync.RWMutex }
func NewConfig() *Config { /* ... */ }
func (c *Config) Get(key string) string { c.mu.RLock(); defer c.mu.RUnlock(); return c.settings[key] }
// 使用者需要显式地创建和传递 Config 实例
尽量将状态封装在结构体中,并通过函数参数或方法接收者来传递。
接口定义位置再讨论
前面在ISP和DIP中提到,接口定义通常应靠近消费者(Consumer)。即,如果包 A 需要包 B 提供的某种能力,那么定义这个能力的接口最好放在包 A 中,然后让包 B 实现它。这样做的好处是:
-
包
A只依赖于自己定义的、满足自身最小需求的接口,符合ISP。 -
避免了包
B为了被A使用而反过来依赖A(如果接口定义在A中)。 -
使得包
B可以被更多不知道彼此存在的消费者使用(只要它们定义了相似需求的接口)。
当然,对于非常通用的、标准化的接口(如 io.Reader、 http.Handler),将它们定义在标准库或共享的基础库中是完全合理的。
main包应尽可能简洁
在Go中,main包是特殊的包,用于定义程序的入口函数main。在Go中,main函数应该尽可能简洁,它应该只负责装配其他包,调用其他函数或模块,不应该包含过多的代码逻辑。这样可以提高代码的可读性和可维护性。如果要对main函数进行单测的话,那么可以将main函数的逻辑放置到另外一个函数中,比如run,然后对run函数进行详尽的测试。
避免包设计的常见误区
最后,我们再总结一下除了前面提到的之外,还需要避免的一些包设计误区。
-
为了测试而扭曲设计:虽然可测试性很重要,但不应过度。为每个结构体都创建接口只为了方便Mock,可能会引入不必要的抽象,使生产代码更复杂。应优先考虑其他测试策略(如表驱动测试、测试辅助函数、使用真实依赖的集成测试等),仅在确实需要Mock复杂依赖或外部系统时才引入接口。
-
忽略包的循环依赖:再次强调,Go编译器禁止循环依赖。遇到此错误时,必须从结构上解决,而不是试图绕过。这通常意味着需要重新审视包的职责划分,或者提取公共依赖到新的包中,或者使用接口实现依赖倒置。
小结
包是Go语言的基石,良好的包设计是构建高质量Go应用的关键。这一节课,我们深入探讨了Go包设计的核心原则与实践。
-
Go包的多重身份:它是功能单元(封装职责)、编译单元(独立编译)和设计单元(组织结构)。
-
自然内聚性:设计包时应追求高内聚,将功能上紧密相关、服务于单一目的的代码组织在一起。好的包名是内聚性的直接体现,警惕
utils、common等“大杂烩”包。 -
SOLID原则在Go中的应用:虽然源于OO,但SOLID原则对Go包设计极具指导意义,主要通过接口来实践 OCP、LSP、ISP、DIP,通过单一职责来指导包的划分。
-
单包内部的设计要点:强调最小化暴露表面积以实现封装,避免包级状态以降低耦合和提高可测试性,并再次讨论了接口定义的位置以及main包的设计原则。
-
避免常见误区:警惕为了测试而过度设计、用技巧绕过循环依赖等问题。
最终,优秀的Go包设计并非遵循某个僵化的模板,而是理解这些原则背后的思想,并结合项目的具体需求,做出务实、简洁、灵活的决策。目标是创建出职责清晰、依赖合理、易于理解、测试和维护的包结构,支撑起整个应用的健康发展。
思考题
假设你在开发一个项目,需要一个处理配置加载的功能。配置可能来自多种来源:JSON文件、YAML文件、环境变量、甚至是远程配置中心。你希望提供一个统一的方式来读取这些配置项。
你会如何设计相关的包和接口来实现这个功能,并体现出本节课讨论的高内聚、低耦合以及SOLID原则,特别是OCP和DIP(可以简述包的划分、核心接口的设计以及它们之间的关系)?
欢迎在评论区分享你的设计思路!我是Tony Bai,我们下节课见。
并发设计:用并发思维构建Go应用的结构骨架
你好!我是Tony Bai。
在模块一的 第11节课,我们已经深入学习了Go并发编程的“兵器谱”——goroutine、channel、select、sync包以及context。我们了解了这些工具如何工作,以及它们的优势和潜在陷阱。现在,是时候将这些知识提升到设计层面了。
Go语言的并发特性不仅仅是为了让我们的程序跑得更快(并行),它更是一种强大的 构造和组织软件的方式。正如Go语言设计者之一Rob Pike 所言:“ Concurrency is not parallelism(并发不是并行)”。他强调,并发提供了一种编写简洁、清晰代码,并能良好地与现实世界复杂交互的途径。
那么,具体到Go项目设计中:
-
我们应该如何运用“并发的眼光”来审视和构建应用的整体结构骨架?
-
当外部请求涌入时,我们的应用应该采用哪种并发模型来接收和处理?是为每个请求启动一个goroutine,还是使用goroutine池,或者更底层的用户态多路复用?
-
在应用内部,当不同组件或处理阶段需要协作时,有哪些经典的并发模式(如Pipeline, Fan-in/out)可以借鉴?
-
最重要也是最容易被忽视的一点:我们启动的每一个goroutine,它的生命周期该如何管理?如何确保它们在不再需要时能够优雅地退出,而不是变成难以追踪的“幽灵”,耗尽系统资源(goroutine泄漏)?
不从并发结构和生命周期管理的角度去设计Go应用,就可能导致系统在高并发下表现脆弱、资源利用率低下,甚至因goroutine泄漏而最终崩溃。
这节课,我们将聚焦于如何运用并发思维来设计Go应用的结构,并重点探讨goroutine的生命周期管理。我们的目标是:让你不仅会写单个的goroutine,更能设计出结构清晰、行为可控、资源高效的并发Go应用。
并发真谛:不只是并行,更是构建清晰软件结构的方式
首先,我们需要再次明确Rob Pike关于并发与并行的经典论述。并行(Parallelism)指的是同时执行多个计算任务(通常利用多核CPU)。而并发(Concurrency)指的是 同时处理多个任务的能力,这些任务可能在时间上重叠,但不一定非要同时执行。并发是一种程序结构(structuring)层面的问题,而并行是一种执行(execution)层面的问题。
Go的goroutine和channel提供了一种优雅的方式,将复杂问题分解为多个独立的、并发执行的逻辑单元,并通过明确的通信(channel)来协调它们。这种方式带来的好处不仅仅是潜在的性能提升(通过并行),更重要的是:
-
提升代码清晰度和模块化:可以将不同的职责或处理阶段映射到不同的goroutine中,使得每个goroutine的逻辑更简单、更专注。
-
增强响应性:对于I/O密集型或需要等待外部事件的应用(如网络服务器),可以将耗时的操作放在独立的goroutine中,避免阻塞主处理流程,提高用户体验。
-
简化复杂状态管理:通过channel传递数据和控制信号,可以比使用复杂的锁和共享状态更容易地管理并发状态,减少数据竞争。
-
更好地模拟现实世界:现实世界本身就是并发的,用并发的思维来建模和解决问题,往往更自然、更直观。
因此,在设计Go应用时,我们应该主动思考:哪些部分可以独立出来并发执行?它们之间如何通信和同步?这种“并发的眼光”能帮助我们构建出更模块化、更具弹性、也更易于理解的系统结构。
当我们用并发的视角来审视一个应用程序的整体结构时,可以从几个关键的维度入手。首先是应用的入口,它如何接收和分发来自外部世界的请求或事件?其次是应用内部不同组件或处理流程之间如何高效、安全地并发协作?最后,也是至关重要的,是每一个并发执行单元(goroutine)的生命周期如何被妥善管理,确保其按预期启动、工作并最终干净地退出。这三个维度——入口并发模型、内部协作模式和生命周期管理——共同构成了Go并发设计的核心骨架。我们先从应用的“前门”开始看起。
面向外部请求:Go应用的入口并发模型选择
对于一个需要处理外部请求(如HTTP请求、RPC调用、消息队列消息)的Go应用,其入口处的并发模型至关重要,它直接影响到应用的吞吐量、延迟和资源消耗。
常见的入口并发模型有三种,如下图所示:
接下来,我们就逐一看看这三个并发模型各自的原理、特点与适用场景。
并发模型一:One Goroutine Per Request
One Goroutine Per Request(请求级并发)是Go net/http 包处理HTTP请求的默认模型。每当服务器接收到一个新的HTTP连接(或HTTP/2的流),它通常会启动一个新的goroutine来专门处理这个请求的完整生命周期。比如下面这个简化逻辑版的示例:
package main
import (
"context"
"fmt"
"log"
"net/http"
)
func process(context.Context, *http.Request) {
// 处理请求的实际逻辑
}
func handleRequest(w http.ResponseWriter, r *http.Request) {
// 这里的代码在一个独立的 goroutine 中执行
process(r.Context(), r) // 传递 context 很重要
fmt.Fprintf(w, "Request processed")
}
func main() {
http.HandleFunc("/hello", handleRequest)
fmt.Println("Server starting on :8080")
// http.ListenAndServe 内部会为每个请求启动一个goroutine
log.Fatal(http.ListenAndServe(":8080", nil))
}
在Go的并发模型中,“一请求一goroutine”模型的原理与优势显而易见。
首先,这种方法实现简单且直观。每个请求的处理逻辑都在一个独立的执行单元中,确保了状态的隔离性。此外,这种方式能够充分利用多核 CPU 的能力,只要有足够的CPU核心,服务器便可以同时处理多个请求,从而实现并行处理。
另一个重要的优势是,I/O 阻塞不会影响其他请求的处理。当某个请求的 goroutine 因为等待数据库或外部 API 而被阻塞时,其他请求的 goroutine 仍然可以被调度执行,这大大提高了系统的响应能力和资源利用率。
这种并发模型也适用于绝大多数 Web 服务和 API 网关等场景,能够有效应对高并发的请求处理需求。
然而,该模型也存在一些潜在问题需要考虑。如果并发请求量非常大,可能会创建大量的 goroutine。虽然我们在第11节课中说过单个 goroutine 的开销较小,但过多的 goroutine 仍会消耗内存(主要是栈空间),并增加调度器的压力,甚至可能导致系统资源的耗尽(如文件描述符的限制)。以一个goroutine分配2KB栈空间为例,100万个goroutine需要的内存就是2GB,并且实际运行时,goroutine的平均栈空间通常还要大于2KB。
此外,服务器的连接数也受到操作系统和配置的限制,这在高并发场景中可能成为瓶颈。因此,在设计系统时,必须综合考虑这些因素,以确保系统的稳定性和性能。
并发模型二:Goroutine Pool(工作协程池)
为了控制并发goroutine的数量,避免无限制增长,我们可以使用 goroutine池(worker pool)并发模式,即预先创建固定数量(或有上限的动态数量)的worker goroutine,然后将到来的连接或请求作为任务分发给这些worker。
为了有效管理资源和控制并发度,这种并发模型采用了限制最大 goroutine 数量的策略,其原理与优势在于能够防止资源耗尽,确保系统的稳定性。同时,通过复用 goroutine,可以避免频繁创建和销毁 goroutine 所带来的开销。虽然 Go 创建 goroutine 的速度很快,但在极高频率下,这种开销仍然会产生影响。此外,这种方式能够平滑地处理突发流量,从而提高系统的响应能力。
这种并发模型特别适用于需要处理大量短时任务的场景,尤其是在不希望 goroutine 数量失控的情况下。例如,后端任务处理和消息队列消费者都可以受益于这种设计。此外,对于需要精细控制并发度的场景,这种方法也提供了良好的解决方案。
下面是一个使用goroutine pool处理tcp客户端连接和请求的示例:
package main
import (
"bufio"
"errors"
"fmt"
"io"
"log"
"net"
"strings"
"sync"
"time"
)
const (
MaxWorkers = 5 // 池中 worker 的最大数量
RequestQueueSize = 100 // 请求队列的大小
)
// connHandler 代表一个可以处理网络连接的 worker
func connHandler(id int, jobs <-chan net.Conn, wg *sync.WaitGroup) {
defer wg.Done()
fmt.Printf("Worker %d started\n", id)
for conn := range jobs { // 从 jobs channel 接收连接
fmt.Printf("Worker %d processing connection from %s\n", id, conn.RemoteAddr().String())
handleConnection(conn) // 调用实际的处理函数
fmt.Printf("Worker %d finished connection from %s\n", id, conn.RemoteAddr().String())
conn.Close() // 处理完毕后关闭连接
}
fmt.Printf("Worker %d shutting down\n", id)
}
// handleConnection 实际处理连接上的请求 (简化逻辑)
func handleConnection(conn net.Conn) {
reader := bufio.NewReader(conn)
for {
// 设置读取超时,避免worker永久阻塞在一个不活跃的连接上
conn.SetReadDeadline(time.Now().Add(5 * time.Second))
message, err := reader.ReadString('\n')
if err != nil {
if err != io.EOF && !errors.Is(err, net.ErrClosed) && !strings.Contains(err.Error(), "i/o timeout") {
fmt.Printf("Error reading from %s: %v\n", conn.RemoteAddr().String(), err)
}
return // 读取错误或EOF,结束此连接的处理
}
fmt.Printf("Received from %s: %s", conn.RemoteAddr().String(), message)
// 模拟处理
time.Sleep(100 * time.Millisecond)
response := "Processed: " + strings.ToUpper(message)
conn.Write([]byte(response))
}
}
func main() {
listenAddr := "localhost:8080"
listener, err := net.Listen("tcp", listenAddr)
if err != nil {
log.Fatalf("Failed to listen on %s: %v", listenAddr, err)
}
defer listener.Close()
fmt.Printf("TCP Server listening on %s\n", listenAddr)
// 请求队列 (channel of connections)
requestQueue := make(chan net.Conn, RequestQueueSize)
var wg sync.WaitGroup // 用于等待所有 worker goroutine 退出
// 启动固定数量的 worker goroutines
for i := 0; i < MaxWorkers; i++ {
wg.Add(1)
go connHandler(i, requestQueue, &wg)
}
// 主循环,接收新连接并将其放入请求队列
for {
conn, err := listener.Accept()
if err != nil {
// 监听器关闭或其他错误
if errors.Is(err, net.ErrClosed) {
fmt.Println("Listener closed, stopping accept loop.")
break // 退出循环
}
log.Printf("Failed to accept connection: %v", err)
continue
}
// 将新连接发送到请求队列
// 如果队列已满,这里会阻塞,起到一定的背压作用
// 或者使用 select 带 default 来处理队列满的情况(例如,拒绝连接)
select {
case requestQueue <- conn:
// 连接已成功放入队列
default:
fmt.Printf("Request queue full, rejecting connection from %s\n", conn.RemoteAddr().String())
conn.Write([]byte("Server busy, try again later.\n"))
conn.Close()
}
}
// 走到这里通常是 listener 关闭了
fmt.Println("Shutting down server...")
close(requestQueue) // 关闭请求队列,通知所有 worker 不再有新连接
wg.Wait() // 等待所有 worker 处理完当前连接并退出
fmt.Println("All workers finished. Server shut down.")
}
上面这个示例通过固定大小的worker池,有效地控制了并发处理连接的goroutine数量,避免了无限制创建goroutine可能带来的资源耗尽问题。然而,这种固定大小的池模型也并非完美。想象一下,如果客户端连接请求在短时间内激增,数量远超 MaxWorkers,那么 requestQueue 很快就会被填满。后续到达的连接请求,在 requestQueue <- conn 这一步就会阻塞(或者如果使用带 default 的 select,则会被直接拒绝),客户端会感受到明显的延迟甚至连接失败。
虽然我们可以通过增大 RequestQueueSize 来缓解短时突发流量,或者实现更复杂的动态池大小调整逻辑,但这些方法在面对数十万甚至百万级别的超高并发连接时,仍然会面临goroutine调度开销和内存占用的挑战。当我们需要在单个或少量几个线程/goroutine上处理海量并发连接,并追求极致的性能和资源利用率时,就需要考虑更底层的并发模型了。接下来,我们就来看看用户态多路复用这种并发模型。
并发模型三:User-Level Multiplexing
User-Level Multiplexing这种模型通常被称为用户态多路复用,其核心思想是借鉴操作系统的I/O多路复用机制(如Linux的 epoll、BSD的 kqueue、Windows的 IOCP),但在用户层面用更少的goroutine(通常是每个CPU核心一个或固定少数几个)来管理大量的网络连接或其他I/O事件。
在概念上,这种模型依赖于少量核心 goroutine,而不是为每个连接创建一个 goroutine。这些核心 goroutine,通常称为事件循环(Event Loop)或 I/O goroutine,采用非阻塞 I/O,注册感兴趣的事件(例如连接可读、可写)。当操作系统通知某个连接上有事件发生时,相应的核心 goroutine 会被唤醒。此外,针对每个连接,通常会维护一个状态机,以便在事件发生时,核心 goroutine 能够调用对应的处理函数或回调。如果在初步解析数据后需要进一步处理,核心 goroutine 还可以将实际的业务逻辑任务分发给后端的 worker goroutine 池,从而避免阻塞事件循环。
这种模型的优势在于其极低的 goroutine 开销。由于只使用少量核心 goroutine 管理大量连接,这大大减少了goroutine创建、调度和栈内存的开销。同时,这种非阻塞的处理方式非常适合解决 C10K、C100K 甚至 C1M 问题,即在单机上处理数万到数百万的并发连接。此外,开发者还可以更精确地控制内存和 CPU 的使用,提升资源的利用效率。
其适用场景包括需要处理极高并发连接的网络服务器,如高性能网关、消息推送服务、实时通信服务和游戏服务器等,这些场景对延迟和资源消耗有极高的要求。
然而,实现这样一个健壮、高效的用户态多路复用网络库非常复杂,涉及大量底层细节,如非阻塞 I/O、事件轮询、定时器管理和内存管理等。因此,大多数 Go 开发者选择使用成熟的第三方高性能网络库,如:
-
netpoll(CloudWeGo/字节跳动 出品, https://github.com/cloudwego/netpoll)
这些库封装了底层的复杂性,提供了相对易用的 API,使开发者能够更专注于业务逻辑的实现。
由于完整的实现过于复杂,我这里只给出一个概念性的伪代码/结构示意的例子,旨在展示使用这类库时,应用层代码可能的样子。实际API会因库而异。
package main
import (
"fmt"
"log"
// "github.com/some-event-driven-net-library/gnetlike" // 假设这是一个类似gnet的库
)
// AppEventHandler 实现了库定义的事件回调接口
type AppEventHandler struct {
// gnetlike.EventHandler // 嵌入库的基础事件处理器
}
// OnOpen 当新连接建立时被调用
func (ae *AppEventHandler) OnOpen(c /*gnetlike.Conn*/ interface{}) (out []byte, action /*gnetlike.Action*/) {
conn := c.(ActualConnType) // 实际类型转换
fmt.Printf("Connection opened from: %s\n", conn.RemoteAddr().String())
// 可以向客户端发送欢迎消息等
// out = []byte("Welcome!\n")
// action = gnetlike.None
return
}
// OnTraffic 当连接上有数据到达时被调用
func (ae *AppEventHandler) OnTraffic(c /*gnetlike.Conn*/ interface{}, data []byte) (action /*gnetlike.Action*/) {
conn := c.(ActualConnType)
fmt.Printf("Received from %s: %s\n", conn.RemoteAddr().String(), string(data))
// 业务逻辑处理 (可以同步处理,也可以异步分发给worker pool)
response := []byte("Server got: " + strings.ToUpper(string(data)))
conn.AsyncWrite(response) // 假设库提供了异步写回方法
// action = gnetlike.None
return
}
// OnClose 当连接关闭时被调用
func (ae *AppEventHandler) OnClose(c /*gnetlike.Conn*/ interface{}, err error) (action /*gnetlike.Action*/) {
conn := c.(ActualConnType)
fmt.Printf("Connection closed from: %s, error: %v\n", conn.RemoteAddr().String(), err)
// action = gnetlike.None
return
}
// (这里用 ActualConnType 只是为了示意,实际库会有具体的 Conn 类型)
type ActualConnType interface {
RemoteAddr() net.Addr
AsyncWrite([]byte) error
// ... 其他库提供的方法
}
func main() {
eventHandler := &AppEventHandler{}
addr := "tcp://:9090" // 库可能使用自己的地址格式
fmt.Printf("Event-driven server starting on %s\n", addr)
// 启动事件循环,传入我们的事件处理器
err := gnetlike.Serve(eventHandler, addr, gnetlike.WithMulticore(true), gnetlike.WithNumEventLoop(runtime.NumCPU()))
if err != nil {
log.Fatalf("Failed to start server: %v", err)
}
log.Println("Conceptual example: Imagine a gnet-like library running here.")
// 实际使用时,需要替换为真实库的启动代码
// 由于没有实际库,这里让主 goroutine 保持运行
select{}
}
在这个概念示例中,我们不再直接 Accept 连接,而是将连接的生命周期事件(打开、数据到达、关闭)委托给了一个事件处理器( AppEventHandler)。网络库内部会使用用户态多路复用技术高效地管理大量连接,并在事件发生时调用我们提供的回调方法。这种模型将网络I/O处理与业务逻辑处理分离开来。
那么,在这三种入口的并发模型之间,我们该如何做出选择呢?
-
One Goroutine Per Request:理解和开发实现都是最简单的,也是Go的默认方式,适用于绝大多数场景。主要关注可能产生的goroutine数量。
-
Goroutine Pool:当需要严格控制并发度、复用资源或平滑负载,且任务之间相对独立时考虑。增加了实现的复杂度。
-
User-Level Multiplexing:用于需要突破OS线程模型限制、追求极致网络并发性能的特定场景,通常通过使用成熟的第三方库。其编程模型与传统的同步阻塞模型有较大差异,理解、开发和调试起来较为复杂,对开发人员能力的要求较高。
选择哪种模型,取决于你的应用对并发量、性能、资源消耗以及开发复杂度的具体要求和权衡。
面向内部协作:常见的Go并发模式
处理好来自外部世界的并发请求仅仅是第一步。 在一个复杂的Go应用中,请求的处理过程往往不是单一、线性的,它可能需要多个内部组件或处理阶段并发地协作才能完成。 例如,一个数据处理任务可能需要先从数据源读取,然后进行转换,接着做一些计算,最后存储结果。如果这些步骤都串行执行,效率可能会很低,也无法充分利用现代多核CPU的能力。
Go的并发原语(goroutine和channel)为我们组织这种内部协作提供了强大的工具。通过将不同的处理逻辑封装在独立的goroutine中,并通过channel在它们之间安全地传递数据和状态,我们可以构建出高效、清晰且易于推理的并发工作流。为了应对常见的内部协作场景,社区和实践中也沉淀出了一些行之有效的并发模式(Concurrency Patterns)。这些模式就像是搭建复杂并发系统的“乐高积木”,可以帮助我们以标准化的方式解决重复出现的问题。
接下来,我们就来看看几种典型的内部协作的并发模式:Pipeline(流水线)、Fan-out(扇出)和 Fan-in(扇入)。
Pipeline:串联处理,数据流动
Pipeline模式是一种将复杂的处理流程分解为一系列连续的处理阶段(stages)的并发设计。每个阶段通常由一个或多个goroutine负责,它们通过channel连接起来,形成一个数据流。上一个阶段的输出(通过channel发送)成为下一个阶段的输入(通过channel接收),数据就像在流水线上一样依次经过每个阶段的处理。
这种模式的核心优势在于任务分解清晰,每个阶段可以专注于单一的、明确的职责。 同时,如果各个阶段可以独立执行(例如,一个阶段在处理当前数据项时,上一个阶段已经在准备下一个数据项),那么Pipeline就能很好地利用多核CPU实现并行处理,提高整体吞吐量。此外,阶段间channel的缓冲能力还可以起到一定的削峰填谷作用,解耦上下游阶段的处理速度,形成自然的背压(back-pressure)机制。Pipeline模式广泛应用于数据处理、ETL流程、图像/视频处理、编译器等需要分步处理数据的场景。
下面是Go实现Pipeline模式的示意图:

从图中我们看到:数据从源头开始,通过一系列由channel连接的并发处理阶段,最终流向结果。每个箭头代表一个channel,每个处理阶段是一个或多个goroutine。
下面我们再举一个具体的利用pipeline进行数据处理的简单示例,来直观地看一下pipeline模式的威力:
package main
import (
"context"
"fmt"
)
// Stage 1: 生成数字序列
func generateNumbers(ctx context.Context, max int) <-chan int {
out := make(chan int)
go func() {
defer close(out)
for i := 1; i <= max; i++ {
select {
case out <- i:
case <-ctx.Done(): // 响应外部取消
return
}
}
}()
return out
}
// Stage 2: 计算平方
func squareNumbers(ctx context.Context, in <-chan int) <-chan int {
out := make(chan int)
go func() {
defer close(out)
for n := range in { // 从上一个阶段接收数据
select {
case out <- n * n:
case <-ctx.Done():
return
}
}
}()
return out
}
func main() {
ctx, cancel := context.WithCancel(context.Background())
defer cancel() // 确保能取消整个流水线
inputChannel := generateNumbers(ctx, 5) // 第一个阶段
squaredChannel := squareNumbers(ctx, inputChannel) // 第二个阶段
// 消费最终结果
for result := range squaredChannel {
fmt.Println(result)
if result > 10 { // 假设我们基于结果提前停止
fmt.Println("Result exceeded 10, canceling pipeline.")
cancel() // 发出取消信号,所有监听ctx.Done()的阶段都会退出
}
}
fmt.Println("Pipeline finished.")
}
在这个例子中, generateNumbers 和 squareNumbers 分别代表流水线的两个阶段,它们通过channel连接。 context 用于控制整个流水线的取消。generateNumbers输出原始要处理的数值,通过squareNumbers的加工,实现对数值平方的计算。
然而,并非所有的并发协作都是线性的。有时,我们需要将一批任务或数据并行地分发给多个执行单元去处理,以期缩短整体处理时间。这就引出了我们接下来要讨论的 Fan-out(扇出)模式。
Fan-out:并行分发,加速处理
Fan-out模式通常用于将一个数据源或一批任务分发(distribute)给多个并行的worker goroutine进行处理,以提高整体的处理速度。你可以把它想象成一个总管(生产者或分发者)将工作分配给多个工人(消费者或worker)同时进行。
实现Fan-out时,通常有一个输入channel,分发逻辑会从中读取数据或任务,然后通过某种策略(如轮询、随机或基于任务特性)将它们发送到多个worker goroutine各自的输入channel,或者直接让多个worker goroutine从同一个输入channel竞争获取任务。每个worker独立完成其分配到的任务。
下面是Fan-out模式工作原理示意图:
从图中我们看到:一个生产者将任务放入输入channel,多个Worker Goroutine并发地从该channel(或各自的channel)获取并处理任务。
下面我们改造一下前面处理数字平方的示例,看看如何用fan-out模式来实现:
package main
import (
"context"
"fmt"
"sync"
)
func squareWorker(ctx context.Context, id int, in <-chan int, out chan<- int, wg *sync.WaitGroup) {
defer wg.Done()
fmt.Printf("Worker %d started\n", id)
for num := range in {
select {
case out <- num * num:
fmt.Printf("Worker %d processed %d -> %d\n", id, num, num*num)
case <-ctx.Done():
fmt.Printf("Worker %d canceling\n", id)
return
}
}
fmt.Printf("Worker %d finished, input channel closed\n", id)
}
func main() {
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
numbersToProcess := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
inputChan := make(chan int, len(numbersToProcess)) // 带缓冲,避免发送阻塞
resultsChan := make(chan int, len(numbersToProcess)) // 收集结果
var wg sync.WaitGroup
numWorkers := 3 // 启动3个worker
// Fan-out: 启动 workers
wg.Add(numWorkers)
for i := 0; i < numWorkers; i++ {
go squareWorker(ctx, i, inputChan, resultsChan, &wg)
}
// 分发任务到 inputChan
for _, num := range numbersToProcess {
inputChan <- num
}
close(inputChan) // 所有任务发送完毕,关闭 inputChan,worker 会在读完后退出
// 等待所有 worker 完成
go func() { // 启动一个goroutine来等待并关闭resultsChan,避免main阻塞
wg.Wait()
close(resultsChan)
}()
// 收集结果 (Fan-in 的一种简单形式)
for sq := range resultsChan {
fmt.Println("Main received squared value:", sq)
}
fmt.Println("All numbers processed.")
}
在这个例子中,主goroutine将所有待处理数字放入 inputChan,然后启动了 numWorkers 个 squareWorker goroutine,它们并发地从 inputChan 中获取数字并计算平方,再将结果发送到 resultsChan。
与Fan-out将任务“分散”出去相对应,有时我们需要将来自多个并发源头 的数据或结果汇聚到一个统一的地方进行下一步处理或最终消费。这种将多个输入流合并为一个输出流的模式,就是我们接下来要介绍的 Fan-in(扇入)模式。
Fan-in:聚合结果,统一输出
Fan-in模式与Fan-out相对应,它用于 将多个输入channel的数据汇聚(merge/multiplex)到一个输出channel中。
实现Fan-in时,通常会为每个输入channel启动一个goroutine,这个goroutine负责从其对应的输入channel读取数据,并将读取到的数据转发到共同的输出channel。需要注意的是,当所有输入channel都关闭后,负责汇聚的goroutine应该关闭那个共同的输出channel,以通知下游处理结束。
下面是Fan-in模式工作原理示意图:
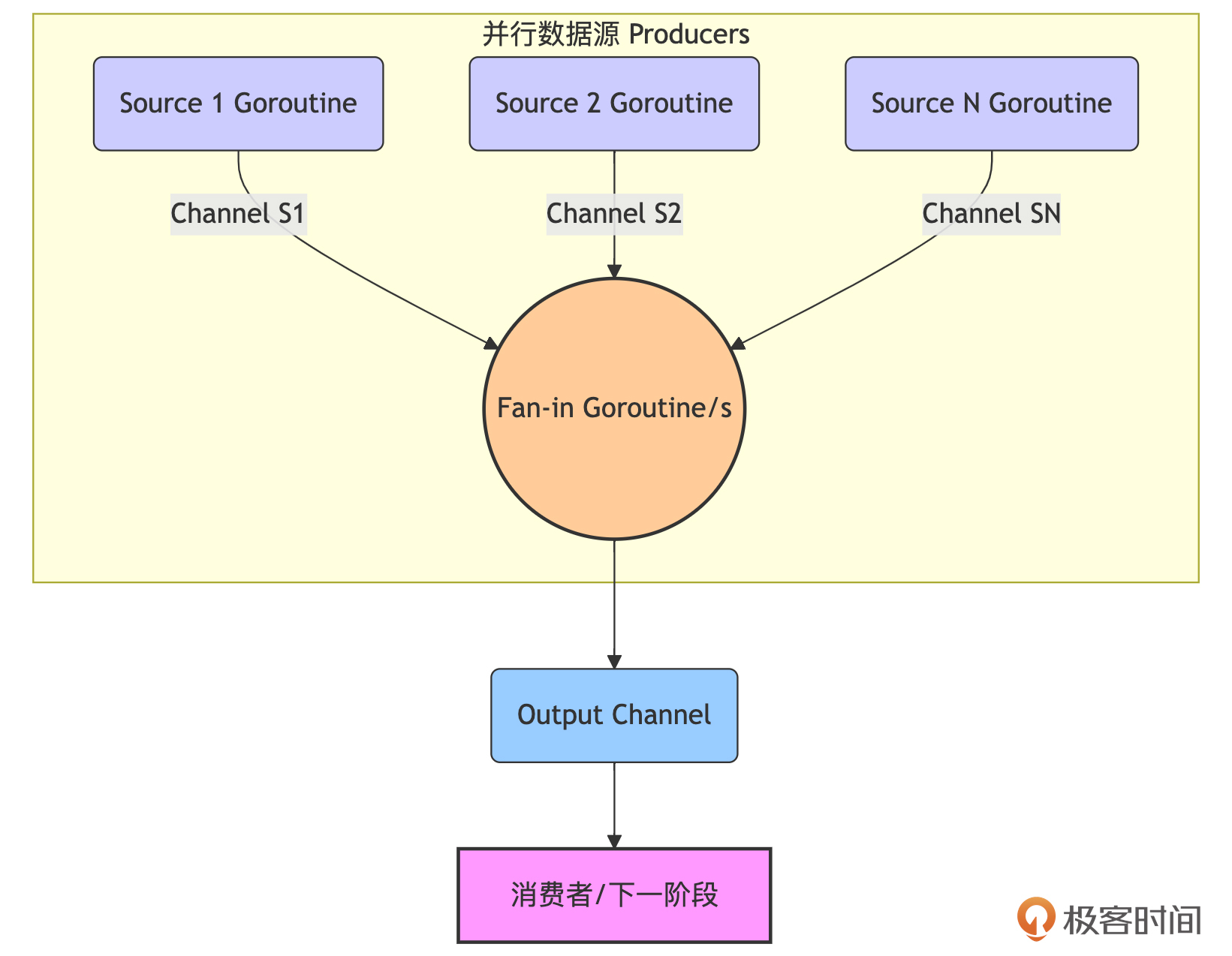
通过上图我们看到:多个数据源(或处理阶段的输出channel)的数据,通过一个或多个汇聚goroutine,被转发到同一个输出channel中。
一个Fan-in模式的经典应用场景是,当我们向多个不同的服务(比如Web搜索、图片搜索、视频搜索)同时发出查询请求后,需要将它们各自返回的结果合并起来,尽快地呈现给用户,而不是等待所有搜索都完成后再一起显示。下面我们就用一个示例来“复现”一下这个经典的Fan-in应用。
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
// search 模拟一个搜索操作,它在一些延迟后返回一个结果。
// kind 参数用于区分不同的搜索源(如 "Web", "Image")。
// query 是搜索查询词。
// 返回一个只读的字符串channel,用于接收搜索结果。
func search(kind string, query string) <-chan string {
ch := make(chan string) // 创建用于返回结果的channel
go func() {
defer close(ch) // 确保goroutine退出时关闭channel
// 模拟不同的搜索延迟
latency := time.Duration(rand.Intn(100)+50) * time.Millisecond
time.Sleep(latency)
// 将格式化的结果发送到channel
ch <- fmt.Sprintf("%s 结果,查询词 '%s' (耗时 %v)", kind, query, latency)
}()
return ch // 返回channel,调用者可以从中接收结果
}
// fanInMerger 接收一个或多个只读的字符串channel(输入channels),
// 并将它们输出的值合并到一个新的只读字符串channel(输出channel)中。
// 当所有的输入channel都关闭并且它们的数据都被读取完毕后,输出channel也会被关闭。
func fanInMerger(inputChannels ...<-chan string) <-chan string {
mergedCh := make(chan string) // 创建用于合并结果的输出channel
var wg sync.WaitGroup // 使用WaitGroup等待所有转发goroutine完成
wg.Add(len(inputChannels)) // 为每个输入channel增加WaitGroup计数
// 为每个输入channel启动一个goroutine,负责将其数据转发到mergedCh
for _, ch := range inputChannels {
go func(c <-chan string) {
defer wg.Done() // 当前goroutine完成时,减少WaitGroup计数
// 从输入channel c 中读取数据,直到它被关闭
for data := range c {
mergedCh <- data // 将读取到的数据发送到合并后的channel
}
}(ch) // 将当前的channel c 作为参数传递给goroutine,避免闭包问题
}
// 启动一个goroutine,用于在所有转发goroutine都完成后关闭mergedCh
go func() {
wg.Wait() // 等待所有转发goroutine执行完毕
close(mergedCh) // 关闭合并后的输出channel,通知消费者没有更多数据
}()
return mergedCh // 返回合并后的channel
}
func main() {
rand.Seed(time.Now().UnixNano()) // 初始化随机数种子
query := "Go并发模式"
// 模拟并行启动多个搜索操作 (这里隐式地形成了Fan-out)
webResults1 := search("Web搜索源1", query)
webResults2 := search("Web搜索源2", query)
imageResults := search("图片搜索源", query)
videoResults := search("视频搜索源", query)
// Fan-in: 将所有搜索源的结果合并到一个channel中
// 我们希望尽快得到结果,不一定需要等待所有搜索完成。
aggregatedResults := fanInMerger(webResults1, webResults2, imageResults, videoResults)
fmt.Printf("正在聚合对 '%s' 的搜索结果:\n", query)
resultCount := 0
maxResultsToDisplay := 3 // 假设我们只关心最先到达的3个结果
// 从合并后的channel中消费结果
for result := range aggregatedResults {
fmt.Println(" -> ", result)
resultCount++
if resultCount >= maxResultsToDisplay {
fmt.Printf("\n已收集 %d 条结果,停止接收。\n", maxResultsToDisplay)
// 在真实的应用程序中,如果在这里提前退出,并且底层的search goroutines
// 还在运行(例如因为它们有更长的超时或没有超时),
// 我们需要一种机制(通常是context)来通知它们也停止工作,以避免资源浪费。
// 这个简化的例子中,我们允许它们自然结束并关闭各自的channel,
// fanInMerger中的goroutine也会随之结束。
break
}
}
// 如果aggregatedResults channel没有被完全读取(例如,如果maxResultsToDisplay小于总结果数),
// fanInMerger中的转发goroutine可能仍在尝试向mergedCh发送数据(如果它们的输入源还没关闭)。
// 一个更健壮的解决方案会使用context来处理取消和超时,确保所有相关goroutine都能及时退出。
// 在这个特定示例中,由于main函数即将退出,所有子goroutine也会被终止。
fmt.Println("主函数消费完毕。")
}
这个例子清晰地展示了Fan-in如何将多个并发数据流合并为一个,让调用者可以统一处理。在实际应用中,结合context进行超时控制和取消传播,可以让这种模式更加健壮。
Pipeline、Fan-out和Fan-in这些模式是Go并发编程中常用的构建块,它们可以相互组合,形成更复杂的并发数据处理流程,帮助我们构建出高效且结构清晰的并发应用。
无论是哪种并发模型或模式,只要我们启动了goroutine,一个无法回避的核心问题就是:这些goroutine何时,以及如何结束?如果对goroutine的生命周期缺乏有效管理,任其自生自灭,或者错误地假设它们会“自动”退出,就极易导致goroutine泄漏,最终耗尽系统资源。因此,深入理解并实践goroutine的生命周期管理,是编写健壮并发程序的重中之重。
Goroutine生命周期管理:避免泄漏,实现优雅退出
启动goroutine很容易 ( go myFunc()),但 正确地管理它们的生命周期,确保它们在不再需要时能够按预期退出,是编写健壮并发程序的关键,也是最容易出问题的地方。 未能正确退出的goroutine会导致goroutine泄漏(goroutine leak),大量僵尸goroutine会增加调度器负担,影响程序性能,同时还会持续占用内存和运行时资源,最终可能拖垮整个应用。
Goroutine的退出策略大致有如下几种:
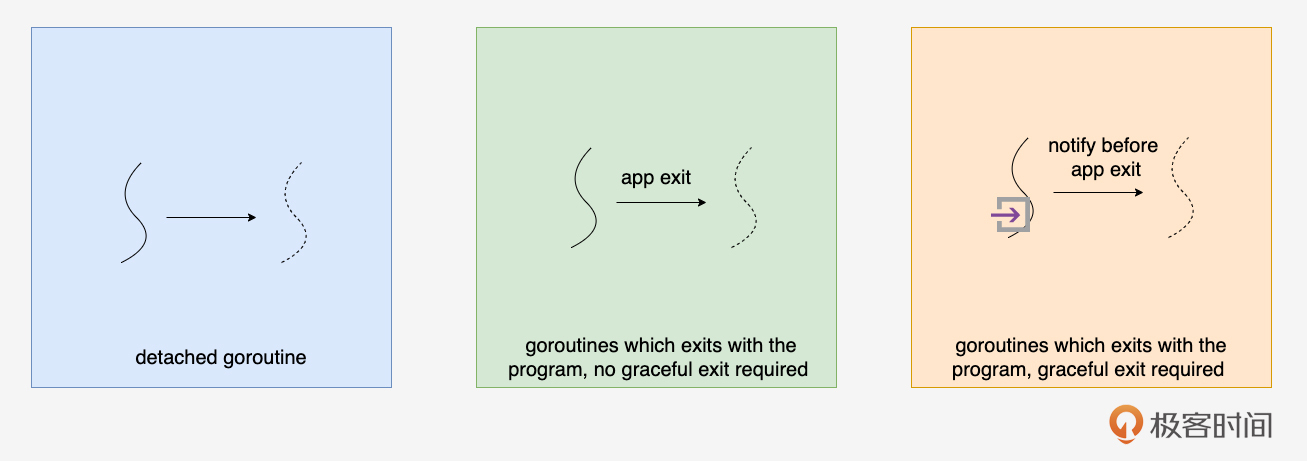
下面我们逐一来看这些退出策略的原理、各自的特点以及适用场景。
退出策略一:自然退出
自然退出(Detached/Fire-and-Forget)是最简单的 goroutine 管理方式。当 goroutine 执行完其函数体内的所有代码后,它会自然结束并退出。在这种情况下,调用方启动这个 goroutine 后,通常不再关心它的完成状态或结果,任其“自生自灭”。
这种模式适合于执行一些非常短暂、一次性的后台任务,例如发送非关键的日志记录或更新一个不影响主流程的缓存项。此外,任务本身应该非常简单,能够保证在所有情况下都会迅速终止,并且不会因为错误或阻塞而导致永久运行。调用方也完全不依赖于该 goroutine 的执行结果或完成信号。
然而,这种方式也存在风险,是最容易被滥用并导致 goroutine 泄漏的方式。如果 goroutine 内部的逻辑存在潜在的永久阻塞点,例如等待一个永远不会有数据的 channel、等待一个永远不会被释放的锁,或者陷入死循环,那么这个 goroutine 可能永远无法退出,成为“僵尸” goroutine。此外,未被捕获的 panic 也可能导致相似的问题。因此,在使用这种方式时需要特别小心,以避免不必要的资源浪费。
但这种退出方式最易实现,下面是一个自然退出策略的示例代码:
package main
import (
"fmt"
"time"
)
// logInBackground 模拟一个在后台记录日志的goroutine
func logInBackground(message string) {
// 这个goroutine非常简单,执行完打印就自然退出了
fmt.Printf("[LOG] %s\n", message)
// 假设这里没有可能导致阻塞的操作
}
// fireAndForgetTask 模拟一个“发射后不管”的任务
func fireAndForgetTask() {
fmt.Println("Starting a fire-and-forget task...")
// 任务逻辑非常简单,保证会结束
time.Sleep(50 * time.Millisecond) // 模拟短暂工作
fmt.Println("Fire-and-forget task completed.")
}
func main() {
go logInBackground("Application started") // 启动日志goroutine
go fireAndForgetTask() // 启动一个不关心结果的任务
fmt.Println("Main function continues its work...")
// 主goroutine继续执行,不等待上面两个goroutine
// 为了演示,让主goroutine稍作等待,以便观察到子goroutine的输出
time.Sleep(100 * time.Millisecond)
fmt.Println("Main function finished.")
// 当main函数退出时,所有仍在运行的goroutine都会被强制终止
}
在这个例子中, logInBackground 和 fireAndForgetTask 都是在执行完自己的简单逻辑后就退出了。这种方式适用于非常特定的、简单的场景。 对于需要长期运行或与外部系统交互的goroutine,通常不应采用这种策略。
退出策略二:与程序/父goroutine共存亡
这种策略下,子goroutine的生命周期在某种程度上依赖于其父goroutine或整个程序的生命周期,并且通常也有两种方式。
-
隐式退出(不推荐):当主goroutine(
main函数)退出时,整个程序会结束,所有仍在运行的其他goroutine也会被强制终止。这是一种隐式的“共存亡”,但它非常粗暴,子goroutine没有机会进行清理工作。 这种方式不应作为主动的goroutine管理策略。 -
显式同步与等待(推荐):更可靠的方式是,父goroutine(或某个协调者)明确地等待其启动的子goroutine完成工作。子goroutine在完成其任务后自然退出。这种同步通常通过
sync.WaitGroup或 channel 来实现。
下面是一个使用 sync.WaitGroup 实现父子goroutine协同退出的示例:
package main
import (
"fmt"
"sync"
"time"
)
// workerWithWaitGroup 模拟一个需要被等待的工作goroutine
func workerWithWaitGroup(id int, wg *sync.WaitGroup) {
defer wg.Done() // 关键:在goroutine退出前调用Done()
fmt.Printf("Worker %d: Starting work\n", id)
time.Sleep(time.Duration(id+1) * 100 * time.Millisecond) // 模拟工作
fmt.Printf("Worker %d: Work finished\n", id)
// Goroutine在此处自然结束
}
func main() {
var wg sync.WaitGroup // 创建一个WaitGroup实例
numWorkers := 3
for i := 0; i < numWorkers; i++ {
wg.Add(1) // 在启动每个goroutine前,增加WaitGroup的计数器
go workerWithWaitGroup(i, &wg)
}
fmt.Println("Main: All workers launched. Waiting for them to complete...")
wg.Wait() // 阻塞,直到WaitGroup的计数器归零(所有worker都调用了Done)
fmt.Println("Main: All workers have completed. Exiting.")
}
在这个例子中, main goroutine 通过 wg.Wait() 等待所有 workerWithWaitGroup goroutine 调用 wg.Done()。当所有worker都完成后, wg.Wait() 返回, main goroutine 继续执行并最终退出。每个worker goroutine在完成其工作后也是自然退出。这种方式确保了父goroutine会等待子goroutine,避免了主程序过早退出的问题。
我们再看一个使用 Channel 进行退出协调的示例:
package main
import (
"fmt"
"time"
)
// workerListeningDone 模拟一个持续工作的goroutine,但会监听done channel
func workerListeningDone(id int, done <-chan struct{}) {
fmt.Printf("Worker %d: Starting\n", id)
for {
select {
case <-done: // 当 done channel 被关闭时,这个case会立即执行
fmt.Printf("Worker %d: Received done signal. Exiting.\n", id)
// 在这里可以执行一些清理工作
return // 退出goroutine
default:
// 模拟正常工作
fmt.Printf("Worker %d: Working...\n", id)
time.Sleep(500 * time.Millisecond)
// 实际应用中,这里的 default 分支可能是处理一个任务,
// 或者从某个工作channel接收任务等。
// 如果是阻塞操作,也需要和 done channel 一起 select。
}
}
}
func main() {
done := make(chan struct{}) // 创建一个用于通知退出的channel
numWorkers := 3
for i := 0; i < numWorkers; i++ {
go workerListeningDone(i, done)
}
// 允许worker运行一段时间
fmt.Println("Main: Workers launched. Simulating work for 2 seconds...")
time.Sleep(2 * time.Second)
// 工作完成或程序需要退出,通知所有worker停止
fmt.Println("Main: Sending done signal to all workers...")
close(done) // 关闭done channel,所有监听它的goroutine都会收到信号
fmt.Println("Main: Waiting for all workers to finish...")
time.Sleep(5 * time.Second) // 设置一个默认的等待时间,等待所有worker退出
fmt.Println("Main: All workers have completed. Exiting.")
}
在这个例子中,父goroutine可以通过关闭一个特定的channel(通常称为 done 或 quit channel)来向所有子goroutine广播一个“停止工作”的信号。子goroutine则通过select 语句监听这个channel。
当然如果你不希望通过设置一个默认等待时间来等待所有Worker退出(存在一定可能,会导致worker无法优雅退出),也可以将WaitGroup与channel结合在一起来实现,这个在下面优雅退出策略的讲解中会有进一步说明。
“与父goroutine共存亡”的关键在于显式的同步机制,确保父级在子级完成前不会退出。这对于许多并发任务是必要的。然而,对于需要更主动控制(如中途取消、超时)的场景,我们就需要更强大的优雅退出策略了。
退出策略三:优雅退出
对于服务器应用或任何需要处理外部信号(如Ctrl+C)、配置变更或部署更新的程序,实现优雅退出(Graceful Shutdown)是至关重要的。这意味着程序在收到退出信号后,不是立即粗暴终止,而是:
-
停止接受新的工作。
-
尝试完成正在进行的任务(或给予一个超时时间)。
-
释放占用的资源(如关闭网络连接、数据库连接、文件句柄)。
-
然后干净地退出。
实现优雅退出的核心在于 有一种机制能够通知所有相关的goroutine应该开始关闭流程。
实现方式1:基于Channel的信号通知
使用一个专门的channel(通常是 chan struct{},因为我们只关心信号,不关心值)来广播退出信号。
package main
import (
"fmt"
"sync"
"time"
)
func gracefulWorker(id int, quit <-chan struct{}, wg *sync.WaitGroup) {
defer wg.Done()
fmt.Printf("Worker %d starting\n", id)
for {
select {
case <-quit: // 监听到退出信号
fmt.Printf("Worker %d received quit signal, shutting down...\n", id)
// ... 执行清理工作 ...
fmt.Printf("Worker %d finished cleanup.\n", id)
return // 退出 goroutine
default:
// ... 正常工作 ...
fmt.Printf("Worker %d working...\n", id)
time.Sleep(500 * time.Millisecond)
}
}
}
func main() {
quit := make(chan struct{})
var wg sync.WaitGroup
for i := 0; i < 3; i++ {
wg.Add(1)
go gracefulWorker(i, quit, &wg)
}
// 模拟一段时间后发送退出信号
time.Sleep(2 * time.Second)
fmt.Println("Main: Sending quit signal...")
close(quit) // 关闭 quit channel,所有监听者都会收到信号
fmt.Println("Main: Waiting for workers to shut down...")
wg.Wait() // 等待所有 worker 优雅退出
fmt.Println("Main: All workers shut down. Exiting.")
}
关闭 quit channel 会让所有 select 中监听 <-quit 的goroutine立即收到一个零值(对于 struct{} 是空结构体),从而触发退出逻辑。
实现方式2:基于 context.Context 的取消传播
这是现代Go并发编程中更推荐的方式,我们在第11节课已经详细学习过 context。 context.WithCancel 创建一个可取消的context,将其传递给goroutine,goroutine监听 ctx.Done()。当外部调用 cancel() 函数时,所有派生出的goroutine都会收到通知。
package main
import (
"context"
"fmt"
"sync"
"time"
)
func contextualWorker(ctx context.Context, id int, wg *sync.WaitGroup) {
defer wg.Done()
fmt.Printf("ContextualWorker %d starting\n", id)
for {
select {
case <-ctx.Done(): // 监听到 context 取消
fmt.Printf("ContextualWorker %d canceled: %v. Shutting down...\n", id, ctx.Err())
// ... 清理工作 ...
fmt.Printf("ContextualWorker %d finished cleanup.\n", id)
return
default:
fmt.Printf("ContextualWorker %d working...\n", id)
time.Sleep(500 * time.Millisecond)
}
}
}
func main() {
// 创建一个可取消的根 context
rootCtx, cancel := context.WithCancel(context.Background())
defer cancel() // 确保在 main 退出时所有派生的 context 都被取消 (兜底)
var wg sync.WaitGroup
for i := 0; i < 3; i++ {
wg.Add(1)
// 将 rootCtx (或其派生ctx) 传递给 worker
go contextualWorker(rootCtx, i, &wg)
}
time.Sleep(2 * time.Second)
fmt.Println("Main: Canceling all workers via context...")
cancel() // 发出取消信号
fmt.Println("Main: Waiting for workers to shut down...")
wg.Wait()
fmt.Println("Main: All workers shut down. Exiting.")
}
context 的优势在于它可以携带截止时间、超时信息,并且取消信号会自动向下传播到所有子孙context,管理更系统化。
实现方式3:结合系统信号(OS Signals)
在生产环境,我们需要响应操作系统信号,包括容器退出时收到的信号(如 SIGINT (Ctrl+C)、 SIGTERM)来优雅退出服务器应用,通常会将信号处理与上述channel或context机制结合。下面就是一个结合系统信号实现优雅退出的伪代码示例流程:
func main() {
// ... (启动你的服务和 worker goroutines,使用 context 或 quit channel) ...
rootCtx, rootCancel := context.WithCancel(context.Background()) // 使用 context 控制
// (启动 workers, 将 rootCtx 传递给它们)
// ...
// 监听系统信号
sigChan := make(chan os.Signal, 1)
signal.Notify(sigChan, syscall.SIGINT, syscall.SIGTERM)
// 阻塞等待信号
receivedSignal := <-sigChan
slog.Warn("Received signal, initiating graceful shutdown...", "signal", receivedSignal.String())
// 触发优雅退出
rootCancel() // 通过 context 取消所有 goroutines
// ... (等待所有 goroutine 结束,例如使用 WaitGroup) ...
// ... (执行其他清理,如关闭数据库连接) ...
slog.Info("Graceful shutdown complete. Exiting.")
}
理论和工具都已齐备,最终我们还是要回到具体的业务场景中。不同的应用特性、性能要求和复杂度,会引导我们做出不同的并发设计选择。没有放之四海而皆准的“最佳模型”,只有最适合当前问题的“合适模型”。
场景驱动:为你的业务选择合适的并发结构与退出策略
在选择合适的并发结构与退出策略时,理解各种并发模型和退出策略至关重要,关键在于如何根据实际业务场景进行选择和组合。 没有银弹,所有设计都是权衡的结果。
-
简单Web服务/API:
net/http的 One Goroutine Per Request 通常是好的起点。在每个handler中,如果需要调用下游服务,务必使用r.Context()传递context,并为下游调用设置合理的超时(context.WithTimeout)。确保所有由请求派生出的goroutine都监听传入的context。 -
后台任务处理器/消息队列消费者:Goroutine Pool 是一个常见的选择,以控制资源消耗和并发度。每个worker从任务队列(通常是channel)获取任务。使用一个可取消的
context(或quitchannel)来通知所有worker优雅退出。 -
数据处理流水线(Pipeline):每个阶段是一个或多个goroutine,通过channel连接。每个阶段的goroutine都应该能够响应上游传入的
context的取消信号,并优雅地关闭其输出channel,以通知下游阶段停止。 -
需要扇出/扇入的并行计算:
sync.WaitGroup结合context是管理大量并行子任务的好方法。父任务创建一个context,分发给所有子任务goroutine。子任务监听context,父任务使用WaitGroup等待所有子任务完成。
在设计并发结构时,核心考量因素包括任务特性(如 CPU 密集型与 I/O 密集型、长任务与短任务、任务之间的独立性)、资源限制(如 CPU 核心数量、内存大小、允许的最大 goroutine 数)、响应性要求(如是否需要低延迟以及对偶发长尾延迟的容忍度)、复杂度(选择的模型和退出机制是否易于理解、实现和维护),以及错误处理与恢复(并发任务失败后的处理方式、是否需要重试,以及如何向上传播错误)。
因此, 在设计并发结构时,务必将goroutine 的生命周期管理和优雅退出放在与核心逻辑同等重要的位置。提前考虑每个 goroutine 在何种条件下启动、如何工作,以及最重要的——如何在不再需要时被确定地、干净地终止。
小结
这一节课,我们从“并发是构造软件的方式”这一理念出发,探讨了如何运用并发思维来设计Go应用的结构骨架,并重点强调了goroutine的生命周期管理:
-
并发的真谛:理解并发不仅仅是为了并行加速,更是为了构建清晰、模块化、高响应性的软件结构。
-
入口并发模型:学习了处理外部请求的三种主要模型:One Goroutine Per Request(
net/http默认,简单直接)、Goroutine Pool(控制资源,平滑负载),以及User-Level Multiplexing(极致性能,通常由库封装),我们在选择时需根据场景权衡。 -
内部协作模式:回顾了 Pipeline(分阶段处理)和 Fan-in/Fan-out(任务分发与结果聚合)等常见并发模式,它们有助于组织复杂的内部并发流程。
-
Goroutine生命周期管理:这是本节课的核心,强调了避免goroutine泄漏的重要性,并详细讨论了自然退出(适用场景极少,需谨慎)、与程序/父goroutine共存亡(通常需显式同步),以及最重要的——优雅退出这三种策略。
-
优雅退出的实现:学习了通过Channel信号、
context.Context取消传播以及结合系统信号来实现goroutine的优雅退出,确保资源释放和任务的妥善处理。
设计并发系统是一项富有挑战但极具价值的工作。通过运用本节课讨论的并发模型、模式和生命周期管理策略,并结合前面学习的 select、 sync 和 context 等工具,你将能更有信心地构建出健壮、高效、可控的Go并发应用。始终记住: 启动的每一个goroutine,都要想好它如何结束。
思考题
假设你正在设计一个批处理系统,它需要从一个输入源(比如一个文件或消息队列)读取大量数据项,对每个数据项进行一个耗时的转换操作,然后将转换后的结果写入一个输出源。
-
你会考虑采用哪种或哪些并发模型/模式来设计这个系统以提高处理吞吐量?(例如,Pipeline? Fan-out/Fan-in? Goroutine Pool?)
-
对于系统中可能启动的多个处理数据的goroutine,你会如何设计它们的优雅退出机制,以确保在收到停止信号时,它们能完成当前正在处理的数据项,并释放相关资源?
欢迎在评论区分享你的设计思路!我是Tony Bai,我们下节课见。
接口设计:发现和定义优雅契约的艺术
你好!我是Tony Bai。
在Go语言的世界里,如果说goroutine和channel赋予了它并发的灵魂,那么接口(interface)无疑是其设计哲学的基石,是构建灵活、可维护、可扩展系统的核心武器。它的重要性正如前Go语言核心团队负责人Russ Cox说过的:“如果只能选择Go语言中的一个特性保留下来,我会选择接口。”
在 《结构体与接口:掌握Go语言组合优于继承的设计哲学》 这节课中,我们已经强化了接口的语法基础,知道了接口定义了一组方法签名(一个行为契约),以及Go最独特的特性之一—— 接口的隐式实现。
但仅仅知道语法还不够。作为进阶开发者,我们更需要掌握接口设计的艺术与时机:
-
接口真的是设计得越多越好吗?我们应该在一开始就为所有东西定义接口吗?
-
Go社区推崇的“小接口”背后,蕴含着怎样的设计智慧?
-
如何在纷繁复杂的业务逻辑中,“发现”那些真正需要抽象成接口的地方?
-
我们如何权衡接口带来的解耦好处与它可能引入的间接性成本?
-
有哪些常见的接口设计“陷阱”需要我们警惕,比如“为了测试而定义接口”?
不理解接口设计的核心原则和演化过程,可能会让我们滥用接口,导致不必要的抽象、代码可读性下降,甚至性能损耗。 相反,恰到好处的接口设计,能让我们的代码如行云流水般优雅和灵活。
这节课,我们就来深入探讨Go接口设计的艺术。
要真正掌握接口设计的艺术,我们首先需要深刻理解接口在Go语言中为何如此重要,它究竟为我们带来了什么核心价值。这不仅关乎语法特性,更关乎一种设计理念。
接口的价值再认识:为何它是Go语言的精髓?
在深入探讨设计原则之前,我们有必要再次强调接口在 Go 语言中的核心价值。
首先, 接口提供了行为抽象。它们只定义了“做什么”(即方法集),而不关心“怎么做”(具体实现)。这种分离使得我们能够将行为契约与具体实现区分开来,从而提高代码的灵活性。
其次,在 第15讲Go包设计 中,我们得出了在代码层面最低的耦合是接口耦合的结论。可见, 接口的解耦能力是其最强大的特性之一。代码可以依赖于抽象的接口,而不是具体的实现类型。当具体实现发生变化时,只要它仍然满足接口契约,依赖于该接口的代码就无需修改。这显著降低了模块间的耦合度,增强了代码的可维护性。
第三,接口支持多态性。 一个接口类型的变量可以持有任何实现了该接口的具体类型的值。 在运行时,调用接口变量的方法会自动派发到实际类型的对应方法上。这种机制是实现运行时灵活性和可扩展性的关键。
最后, Go语言的隐式实现特性使得接口更加轻量和灵活。无需显式声明 implements,只要一个类型拥有接口要求的所有方法,它就会自动实现该接口。这一特性使得我们可以为已有的类型(即使是第三方库的类型,只要能为其定义方法)适配新的接口,而不需要修改其源码。
正是由于这些特性,特别是隐式实现,使得 Go 的接口成为一种极其强大的组合工具,支撑起了 Go 语言“组合优于继承”的设计哲学。这种设计鼓励我们编写小而专注的组件,通过接口将它们灵活地粘合在一起,从而实现更高效的代码组织和重用。
理解了接口的核心价值和Go语言对其独特的“隐式实现”设计后,一个关键问题浮出水面:我们应该在什么时候以及如何去定义接口?是项目一开始就精心规划,还是有更符合Go语言“实用主义”精神的演化路径?Go社区的经验告诉我们,后者往往是更优的选择。
“发现”而非“发明”:接口设计的正确时机与演化过程
一个常见的误区是在项目初期就试图设计出所有“完美”的接口,或者为每一个结构体都配上一个接口。 这种过早、过度的接口抽象往往是项目复杂化的根源,也是需要警惕的反模式。
那么,为什么不应该一开始就设计接口呢?
-
需求不明:项目初期,需求往往不够清晰和稳定。过早定义的接口可能无法准确反映真实需求,导致后续频繁修改,甚至成为设计的累赘。
-
不必要的抽象:接口是为了应对变化、实现解耦或支持多态。如果当前只有一个具体实现,且短期内看不到其他实现的需求,引入接口只会增加代码量和间接性,并无实际收益。
-
过度设计:为每个组件都强加接口,可能会导致接口泛滥,使系统结构变得复杂难懂。
Go社区推崇的实践路径是从具体类型出发,让接口自然涌现。 接下来,我们来介绍些更稳健和实用的做法。
第一,先编写具体实现。 专注于用具体的类型(通常是结构体)来实现当前的核心功能,让代码先跑起来,解决实际问题。
第二,识别抽象需求。 随着项目演进,当以下情况出现时,可能才是考虑抽象成接口的成熟时机:
-
重复的行为模式:你发现多处代码在执行相似的操作,但针对的是不同的具体类型。
-
需要多种实现:某个组件需要支持不同的策略或后端(例如,数据可以存储在内存、文件或数据库中)。
-
需要测试替身(Test Doubles):为了单元测试,你需要替换掉某个真实的依赖(如外部服务、数据库),用一个Mock或Stub对象来控制测试行为。不过这个时机需要仔细甄别,千万不要为了测试而随意添加抽象接口。在后面讲避免过度设计时,我们还会提及这点。
-
需要打破包循环依赖:当包A依赖包B,包B又反过来需要包A的某个功能时,可以在包A或包B中定义一个接口,让另一方实现它,从而打破直接的包依赖。
第三,提取最小化接口:一旦确定需要接口, 只提取调用者真正需要的那部分行为,形成一个最小化的接口。这个接口应该定义在调用者(消费者)的包中,或者一个双方都依赖的公共抽象包中。
第四,重构依赖:修改调用者代码,使其依赖新定义的接口,而不是原来的具体类型。
第五,实现接口:让原有的具体类型(以及未来可能的新类型)实现这个接口。
这种“由具体到抽象”、“按需提取”的方式,能确保我们创建的接口是真正被需要的,其定义也更能反映实际的交互契约。接口是“发现”出来的,而不是凭空“发明”的。接下来,让我们通过一个简单的例子来看看这个“五阶段”的演化过程。
注:示例用做设计展示,因此仅展示代码片段。
阶段一:最初的具体实现
假设我们正在开发一个博客系统,需要一个功能将文章内容保存到磁盘文件。我们可能会先写出这样的具体实现:
// blog/storage.go
package storage
import (
"fmt"
"os"
)
// FileStore 负责将文章保存到文件
type FileStore struct {
BasePath string // 文件存储的基础路径
}
func NewFileStore(basePath string) *FileStore {
return &FileStore{BasePath: basePath}
}
// Save 将文章内容写入到以 title 为名的文件中
func (fs *FileStore) Save(title string, content []byte) error {
filePath := fs.BasePath + "/" + title + ".txt"
fmt.Printf("Saving article '%s' to file: %s\n", title, filePath)
return os.WriteFile(filePath, content, 0644)
}
// ----- main.go (调用方) -----
import "path/to/blog/storage"
func main() {
fileSaver := storage.NewFileStore("/tmp/articles")
fileSaver.Save("MyFirstArticle", []byte("Hello, Go!"))
}
在这个阶段,一切都很直接。 FileStore 和它的 Save 方法工作得很好,我们不需要任何接口。
阶段二:出现新的需求,识别抽象的必要性
现在,产品经理提出新需求:除了保存到本地文件,我们还需要支持将文章保存到数据库(比如 PostgreSQL)。
如果我们直接修改 main 函数或使用 FileStore 的地方,让它根据条件选择用 FileStore 还是 PostgresStore(假设我们也会创建一个 PostgresStore 类型),代码会变得复杂和耦合:
// ----- main.go (糟糕的扩展方式) -----
import (
"path/to/blog/storage"
"path/to/blog/postgresstore" // 引入新的具体依赖
)
func main() {
usePostgres := true // 假设有个配置
content := []byte("Hello, Again!")
if usePostgres {
pgSaver := postgresstore.NewPostgresStore("connection_string")
pgSaver.SaveToDB("MySecondArticle", content) // 方法名可能都不同
} else {
fileSaver := storage.NewFileStore("/tmp/articles")
fileSaver.Save("MySecondArticle", content)
}
}
这里,调用方被迫了解两种不同的存储实现,并且方法签名可能不一致。这是引入接口的好时机,因为我们有了 多种实现同一行为(保存文章)的需求。
阶段三:在消费者端“发现”并定义最小化接口
调用方(比如一个 ArticleService)真正需要的是一个“能够保存文章”的东西,它不关心具体是怎么保存的。我们可以在 ArticleService 所在的包(或者一个公共的接口包)定义这个需求:
// blog/article/service.go (或者 blog/core/interfaces.go)
package article
import "context" // 通常实际接口会包含 context
// ArticleSaver 定义了保存文章行为的契约
// 注意:接口定义在需要它的地方(消费者端)
type ArticleSaver interface {
// SaveArticle 保存文章,接收标题和内容
// 为了与 FileStore.Save 保持一致性,我们这里参数也叫 title, content
// 实际中,接口方法名可以更通用,如 Persist(id string, data Item)
SaveArticle(ctx context.Context, title string, content []byte) error
}
这个 ArticleSaver 接口非常小,只包含了 ArticleService 保存文章所必需的 SaveArticle 方法。
阶段四:修改调用方,依赖接口
现在,我们修改 ArticleService(或之前的 main 函数示例中的逻辑),让它依赖于 ArticleSaver 接口,而不是具体的 FileStore。
// blog/article/service.go
package article
// import "context" // (已在上例中)
// ArticleService 负责文章相关的业务逻辑
type ArticleService struct {
saver ArticleSaver // 依赖 ArticleSaver 接口
}
func NewArticleService(saver ArticleSaver) *ArticleService {
return &ArticleService{saver: saver}
}
func (s *ArticleService) CreateAndSaveArticle(ctx context.Context, title string, content []byte) error {
// ... 可能有一些创建文章的业务逻辑 ...
fmt.Printf("Service: Creating article '%s'\n", title)
// 通过接口保存
return s.saver.SaveArticle(ctx, title, content)
}
阶段五:让具体类型实现接口
这一阶段,让 FileStore 和新的 PostgresStore 实现 article.ArticleSaver 接口。
// blog/storage/filestore.go (原 storage 包)
package storage // 改名为 filestore 可能更清晰,或者放在 storage/file 子包
import (
"context"
"fmt"
"os"
)
type FileStore struct { BasePath string }
func NewFileStore(basePath string) *FileStore { /* ... */ }
// SaveArticle 实现 article.ArticleSaver 接口
func (fs *FileStore) SaveArticle(ctx context.Context, title string, content []byte) error {
filePath := fs.BasePath + "/" + title + ".txt"
fmt.Printf("FileStore: Saving article '%s' to file: %s\n", title, filePath)
return os.WriteFile(filePath, content, 0644)
}
// 确保实现 (可选,但推荐)
// var _ article.ArticleSaver = (*FileStore)(nil)
// blog/storage/postgresstore.go (新的包)
package postgresstore
import (
"context"
"database/sql"
"fmt"
// _ "github.com/lib/pq" // 导入驱动
)
type PostgresStore struct { DB *sql.DB }
func NewPostgresStore(connStr string) (*PostgresStore, error) { /* ... connect DB ... */ return nil, nil }
// SaveArticle 实现 article.ArticleSaver 接口
func (ps *PostgresStore) SaveArticle(ctx context.Context, title string, content []byte) error {
fmt.Printf("PostgresStore: Saving article '%s' to DB\n", title)
// _, err := ps.DB.ExecContext(ctx, "INSERT INTO articles (title, content) VALUES ($1, $2)", title, string(content))
// return err
return nil // 简化
}
// var _ article.ArticleSaver = (*PostgresStore)(nil)
注意, FileStore 的 Save 方法签名可能需要调整为 SaveArticle(ctx context.Context, title string, content []byte) error 以匹配接口。如果不想修改原有 Save 方法,可以再提供一个 SaveArticle 方法,或者使用适配器模式。
最终的组装
我们最后在main函数中通过接口组装调用方与实现方:
// main.go 或其他组装代码
import (
"path/to/blog/article"
"path/to/blog/storage/filestore"
"path/to/blog/storage/postgresstore"
)
func main() {
ctx := context.Background()
content := []byte("Interfaces are powerful!")
// 使用 FileStore
fileSaverImpl := filestore.NewFileStore("/tmp/articles_v2")
articleSvcWithFile := article.NewArticleService(fileSaverImpl)
articleSvcWithFile.CreateAndSaveArticle(ctx, "FileArticle", content)
// 使用 PostgresStore
pgSaverImpl, _ := postgresstore.NewPostgresStore("dummy_conn_str")
articleSvcWithPG := article.NewArticleService(pgSaverImpl)
articleSvcWithPG.CreateAndSaveArticle(ctx, "PostgresArticle", content)
}
在这个逐步演化的过程中, ArticleSaver 接口是根据 ArticleService 的实际需求而“自然涌现”的,而不是一开始凭空设计出来的。这种方式创建的接口通常更贴合实际,也更有价值。
当我们通过实践,在合适的时机“发现”了提取接口的需求后,接下来的问题就是如何设计出一个“好”的接口。仅仅把一组方法签名堆砌在一起远远不够。一个优秀的接口设计应该遵循一些核心原则,这些原则能帮助我们构建出真正解耦、灵活且易于理解的契约。
接口设计核心原则:小、专注、正交与组合
一旦决定需要接口,设计出“好”的接口就成为了关键。Go 的设计哲学和社区实践为我们提供了清晰的指导,主要包括四个核心原则: 小接口原则、单一职责原则、正交性和接口组合。
首先,小接口原则是 Go 接口设计中最核心且广为人知的原则,也符合接口隔离原则(Interface Segregation Principle,ISP)的应用。 这一原则强调接口应该小,方法应该少。理想情况下,很多接口只包含一个方法,例如 io.Reader、 io.Writer、 fmt.Stringer 和 error。小接口的优势在于易于实现,因为方法少,类型实现接口的门槛就低,从而更容易被采纳和复用。此外,小接口能够 更精确地表达调用者对依赖的最小行为期望,并且更灵活地被组合成更大的接口,减少依赖,确保调用者只依赖其真正需要的方法。因此,避免创建“胖接口”(包含大量方法)是非常重要的。如果一个接口的方法过多,就需要思考是否能将其拆分为多个更小、更专注的接口。
其次,单一职责原则(Single Responsibility Principle,SRP的应用) 要求一个接口只关注一类行为或一个单一的职责,其方法集应该共同服务于这个明确的目的。例如, io.Reader 只负责“读”,而 io.Writer 只负责“写”。在设计时,应避免将不相关的行为混合在一个接口中。
接下来是正交性原则,即 接口中定义的方法应尽可能相互独立,功能不重叠。每个方法都应解决一个独特的问题。如果多个方法在功能上有重叠,或者一个方法可以由其他方法组合实现,则需要重新考虑接口的设计。
最后,接口组合(Interface Embedding)是 Go 的一大特色。 当需要一个类型同时具备多种行为时,Go 不鼓励设计一个包含所有方法的大接口,而是推荐通过嵌入多个小接口来组合形成一个新的接口。 例如, io.ReadWriteCloser 就是一个组合接口的例子:
type ReadWriteCloser interface {
Reader // 嵌入了 io.Reader 接口 (Read方法)
Writer // 嵌入了 io.Writer 接口 (Write方法)
Closer // 嵌入了 io.Closer 接口 (Close方法)
}
我们看到io.ReadWriteCloser嵌入了 io.Reader、 io.Writer 和 io.Closer 接口。任何一个类型只要同时实现了 Read、 Write 和 Close 三个方法,就自动实现了 ReadWriteCloser。这种方式比定义一个包含三个方法的大接口更灵活和模块化。
遵循这些原则,我们能够设计出简洁、强大且易于理解和使用的接口。
掌握了设计接口的核心原则,我们就有了“设计什么样”的接口的指导。但更具挑战性的是,在日常纷繁复杂的业务代码中,如何才能敏锐地“识别”出那些值得抽象成接口的“点”,并将其优雅地提取出来呢?这需要一些实践技巧。
实践技巧:如何在业务代码中发现和抽象接口?
理论原则清楚了,那么在日常的业务代码开发中,我们具体如何“发现”和“抽象”出接口呢?下面分享给你一些好用的实践技巧。
识别代码中的“依赖点”
关注你的函数或结构体方法,看看它们直接依赖了哪些其他具体类型的实例,并调用了这些实例的方法,这些直接依赖点是潜在的抽象机会。
// 直接依赖具体类型
type UserService struct {
db *MySQLDatabase // 直接依赖具体的 MySQLDatabase
}
func (s *UserService) GetUser(id int) (*User, error) {
// ... 直接使用 s.db 进行数据库操作 ...
return s.db.QueryUserByID(id)
}
分析“依赖需求”
对于每个依赖点,仔细分析调用者(如 UserService)到底需要被依赖者(如 MySQLDatabase)提供哪些具体行为?它是否关心被依赖者的所有公开方法,还是只关心其中的一小部分?比如, UserService 的 GetUser 方法可能只需要 MySQLDatabase 提供一个类似 QueryUserByID(id int) (*User, error) 的能力,不关心 MySQLDatabase 可能还有的其他方法(如 Backup()、 OptimizeTable() 等)。
定义最小化接口
根据分析出的“依赖需求”,在 调用者(消费者)的包内(或一个共享的接口包内)定义一个只包含这些必要行为的最小化接口。下面是针对上面分析给出的一个接口定义的示例:
package service // UserService 所在的包
// UserStore 定义了 UserService 对用户数据存储的最小需求
type UserStore interface {
QueryUserByID(id int) (*User, error)
// 可能还有 SaveUser(*User) error 等
}
应用依赖倒置
修改调用者,使其依赖新定义的接口,而不是具体类型。在Go中,我们通常通过“构造函数(NewT)”注入接口的实现。比如下面示例:
package service
type UserService struct {
store UserStore // 依赖 UserStore 接口
}
func NewUserService(store UserStore) *UserService {
return &UserService{store: store}
}
func (s *UserService) GetUser(id int) (*User, error) {
// ... 通过 s.store 接口调用 ...
return s.store.QueryUserByID(id)
}
实现接口
接下来,我们让原来的具体类型(如 MySQLDatabase)实现这个新定义的接口。由于Go接口是隐式实现的,如果 MySQLDatabase 已经有了签名匹配的 QueryUserByID 方法,它就自动实现了 UserStore 接口,无需修改 MySQLDatabase 的代码(除非需要调整方法签名或行为)。
package mysqldb // MySQLDatabase 所在的包
import "github.com/user/project/internal/service" // 导入定义接口的包
type MySQLDatabase struct { /* ... */ }
func (db *MySQLDatabase) QueryUserByID(id int) (*service.User, error) { /* ... */ }
// 确保 *MySQLDatabase 实现了 service.UserStore
var _ service.UserStore = (*MySQLDatabase)(nil)
通过这个过程, UserService 从对具体数据库实现的依赖,转变为对抽象 UserStore 接口的依赖,实现了有效的解耦。现在我们可以轻松地替换不同的存储实现(如 PostgresStore、 InMemoryStore),只要它们也实现 UserStore 接口即可。
接口无疑是Go语言中一个极其强大的工具,它能带来解耦、灵活性和可测试性等诸多好处。但正如所有强大的工具一样,如果使用不当或过度使用,也可能反过来增加系统的复杂性。因此,了解接口设计的边界,学会权衡取舍,避免为了抽象而抽象,同样是进阶开发者需要掌握的重要技能。
避免过度设计:接口的边界与取舍
在Go软件设计中,接口虽然非常强大,但其使用必须谨慎,以避免过度设计和滥用接口带来的负面影响。
首先,要 警惕“为测试而接口” 的诱惑。许多开发者为了便于在单元测试中 Mock 某个依赖,往往会为其创建一个接口。然而,如果这个接口在生产代码中没有其他消费者,或者这个具体类型本身在测试中很容易实例化和控制,那么创建这个接口可能就显得过度设计。在 Go 语言中,有多种测试方法可供选择,比如表驱动测试、使用真实的轻量级依赖(通常是fake object,如内存数据库,也可以基于AI快速实现一个轻量级的依赖fake object)和测试辅助函数等,接口并不是唯一的解决方案。引入不必要的接口会增加生产代码的复杂性,因此应仔细评估接口是否真正带来了除测试之外的解耦价值。
其次,设计接口时要权衡抽象成本。接口方法的调用是动态派发的,相较于直接调用具体类型的方法,会有一些额外的运行时开销。虽然这种开销通常很小,但在性能敏感的路径上仍需注意。
此外,过多的接口和间接层可能让代码的实际执行路径变得不够直观,尤其是Go接口是隐式实现的,这会影响代码的可读性和导航。IDE的代码跳转和分析功能也可能受到影响,因此在引入接口时,务必确保其带来的解耦、灵活性和可测试性等收益大于这些潜在的成本。
最后,并非所有情况都需要接口。对于那些非常稳定且不太可能改变的具体类型,尤其是标准库或成熟第三方库提供的类型,通常不需要引入接口。同样,对于项目内部使用的简单工具函数或数据结构,如果没有多态的需求,也无需创建接口。此外,当引入接口并不能带来明显的解耦或灵活性好处,反而增加了代码量和理解难度时,也应避免使用接口。
在此, YAGNI(You Ain’t Gonna Need It)原则 同样适用。设计时不应为了尚未出现的抽象需求而提前创建接口。先让具体实现正常工作,当真正出现抽象需求时,再通过重构来“发现”和提取接口。
小结
这节课,我们深入探讨了Go接口设计的艺术与实践,核心在于理解接口是用来定义和发现行为契约的工具,而非随处安放的语法结构:
-
接口价值再认识:接口通过行为抽象、隐式实现带来了强大的解耦与多态能力,是Go设计哲学的精髓。
-
“发现”而非“发明”接口:接口设计应从具体实现出发,按需演化。当出现重复行为、多种实现需求、测试替身需求或需打破循环依赖时,才是提取接口的成熟时机。避免过早、过度的抽象。
-
核心设计原则:小接口(ISP)、单一职责(SRP)、正交性和通过接口组合构建更复杂契约,是设计优雅、实用接口的关键。
-
实践技巧:通过识别代码中的“依赖点”,分析“依赖需求”,在消费者端定义“最小化接口”,并应用“依赖倒置”,可以有效地在业务代码中发现和抽象出接口。
-
避免过度设计:警惕“为测试而接口”,权衡接口的抽象成本(性能、可读性),遵循“YAGNI”原则,并非所有东西都需要接口。
掌握Go接口设计的艺术,能让你在构建Go应用时,游刃有余地在具体与抽象、耦合与解耦之间做出最佳平衡,编写出真正灵活、可维护、可扩展的高质量代码。
思考题
假设你正在为一个电子商务系统设计订单处理模块。其中有一个核心的 OrderProcessor 类型,它需要完成以下几个步骤:
-
验证订单(
ValidateOrder) -
扣减库存(
DecreaseStock) -
处理支付(
ProcessPayment) -
发送订单确认通知(
SendConfirmation)
这些步骤可能会涉及与库存服务、支付网关、通知服务(邮件、短信等)的交互。
你会如何运用这节课学到的接口设计原则和技巧,来设计 OrderProcessor 及其依赖的接口,以实现良好的解耦和可测试性(可以简述你可能会定义的接口,以及 OrderProcessor 如何依赖它们)?
欢迎在评论区分享你的设计思路!我是Tony Bai,我们下节课见。
错误处理设计:从显式处理到错误链的最佳实践
你好!我是Tony Bai。
在Go语言的设计中,错误处理无疑占据着核心地位,也是与其他许多主流语言区别显著的地方。如果你写过Go代码,一定对随处可见的 if err != nil 印象深刻。这种看似“啰嗦”的方式,恰恰体现了Go对于错误处理的核心哲学。
但是,仅仅知道 if err != nil 是不够的。面对复杂的调用链和多样的错误场景,我们可能会遇到这样的问题:
-
Go为什么坚持使用返回值(
error接口)而不是异常(try-catch)来处理错误?这种设计的优劣何在? -
当错误层层向上传递时,如何避免原始的、有价值的错误上下文信息丢失?
-
errors.Is和errors.As这两个函数有什么区别?我应该在什么时候使用它们来判断错误? -
除了检查特定的错误值或类型,还有没有更灵活的错误处理策略?
-
Go到底有没有“异常”?
panic和recover究竟是做什么用的?我能用panic来传递错误吗? -
Go的错误处理机制是一成不变的吗?社区和官方团队在改进错误处理方面有哪些探索和思考?
不深入理解Go的错误处理哲学、错误链机制、不同的处理策略以及其演进思考,我们可能会写出信息模糊、难以调试、甚至隐藏风险的错误处理代码,也可能无法理解未来Go在错误处理方面可能的变化。 掌握优雅、健壮的错误处理设计,是编写生产级Go应用的关键一环。
这节课,我们就来深入探讨Go错误处理的设计与实践。
要真正理解Go中那些看似“繁琐”的 if err != nil,我们要先深入其设计理念的源头,看看Go为什么选择了这样一条与众不同的错误处理道路,以及这种选择为我们带来了什么。
Go的错误处理哲学:显式处理,错误即值
与其他许多语言(如Java、Python、C#)普遍使用 异常(Exception) 和 try-catch 机制来处理非正常情况不同,Go语言选择了一条不同的道路:将错误作为普通的值(error value)来处理。
Go的核心思想是: 错误是程序正常流程的一部分,应该被显式地检查和处理,而不是通过特殊的控制流(如异常抛出)来绕过。 这种设计基于一个简单的接口:
type error interface {
Error() string // 返回错误的描述信息
}
任何实现了这个接口的类型,都可以作为一个 error 值被返回。函数如果可能失败,通常会将 error 作为其最后一个返回值。调用者则有责任立即检查这个返回的 error 值是否为 nil,比如下面这个典型的示例:
package main
import (
"fmt"
"os"
)
func readFileContent(filename string) ([]byte, error) {
data, err := os.ReadFile(filename) // ReadFile 可能返回错误
if err != nil {
// 错误发生,返回 nil 数据和具体的 error 值
return nil, fmt.Errorf("failed to read file %s: %w", filename, err) // 使用 %w 包装错误 (后面详述)
}
// 成功,返回数据和 nil error
return data, nil
}
func main() {
content, err := readFileContent("my_notes.txt")
if err != nil { // <--- 显式检查错误
fmt.Fprintf(os.Stderr, "Error encountered: %v\n", err)
// ... 进行错误处理,比如记录日志、返回错误码给用户等 ...
os.Exit(1)
}
// 如果 err == nil,则可以安全地使用 content
fmt.Println("File content:", string(content))
}
显式错误处理在编程中有其明显的优缺点。
首先,从优点来看,显式错误处理提供了清晰的错误处理逻辑。由于错误处理代码与正常流程紧密结合,开发者可以轻松识别可能出错的地方以及相应的处理方式。
此外,尽管编译器不强制检查错误,但使用 if err != nil 的惯用法使得忽视错误变得显而易见,这种方式鼓励开发者主动处理错误。同时,将错误视为普通值,使得开发者可以灵活地对待错误进行传递、存储、比较和类型判断等操作,增加了处理的灵活性。
然而,显式错误处理也存在一些缺点。首先,代码冗余是一个常见问题。类似于 if err != nil { return ..., err } 的代码块频繁出现,可能导致代码显得啰嗦。此外,在Go 1.13之前,错误的上下文容易丢失。当错误层层返回时,如果没有特别处理,开发者只能看到最外层的错误描述,而失去了原始错误信息,这可能会影响调试和问题排查的效率。
总的来说,显式错误处理在清晰性和灵活性上有优势,但也面临代码冗余和上下文丢失的挑战。
理解了Go将错误视为普通值并强制显式处理的哲学后,我们自然会遇到一个实践中的挑战:当错误信息经过层层函数调用向上传递时,如何确保底层的、最原始的错误上下文信息不丢失,同时又能让每一层都附加上自己相关的诊断信息呢?这正是Go 1.13版本引入的错误链机制所要解决的核心问题。
错误链的威力:使用 fmt.Errorf %w 包装与 errors 包解构
想象一下这样的调用链: main -> service -> repository -> database driver。如果驱动层返回一个错误,我们希望每一层都能在不丢失原始错误信息的前提下,添加自己这一层的上下文信息,最终形成一个包含完整调用路径信息的“错误链”。
Go 1.13通过错误包装(Error Wrapping)机制实现了这一点。
构建错误链: fmt.Errorf 与 %w
标准库 fmt.Errorf 函数增加了一个新的格式化动词 %w。当使用 %w 来格式化一个 error 类型的值时, fmt.Errorf 会创建一个新的错误值,这个新错误值不仅包含了你提供的格式化字符串,还 “包裹(wrap)” 了原始的那个错误。
// 在 repository 层
dbErr := sql.ErrNoRows // 假设数据库驱动返回这个错误
errRepo := fmt.Errorf("repository layer: user with id %d not found: %w", userID, dbErr)
// 在 service 层
errService := fmt.Errorf("service layer: failed to get user details: %w", errRepo)
// 在 main 或 handler 层收到 errService
fmt.Println(errService)
// 输出可能类似:
// service layer: failed to get user details: repository layer: user with id 123 not found: sql: no rows in result set
我们看到,通过 %w 逐层包装,最终的 errService 包含了从最底层 sql.ErrNoRows 到最外层 service layer 的所有上下文信息。
我们来看一个通用一些的示例:
package main
import (
"errors"
"fmt"
)
func main() {
err1 := errors.New("error1")
err2 := fmt.Errorf("error2: wrap %w", err1)
err3 := fmt.Errorf("error3: wrap %w", err2)
errChain := fmt.Errorf("error chain: wrap %w", err3)
fmt.Println(errChain)
}
运行这个示例,将输出如下结果:
error chain: wrap error3: wrap error2: wrap error1
我们用下面的示意图来更直观地展示这样的结构:

如图所示,从左到右是错误链的包装次序,err1最先被Wrap,接下来是err2,以此类推,直到errN。从右至左是错误链的解包装次序,errN先被解包装处理,接下来是errN-1,以此类推,直到err1。 像这种由错误逐个包裹而形成的链式结构,我们就称之为错误链。
fmt.Printf还支持一次调用使用多个 %w 实现对多个错误的包装,当然你也可以使用 Go 1.20 引入的 errors.Join 函数来实现同样的功能。下面我们看一个示例:
package main
import (
"errors"
"fmt"
)
func main() {
err1 := errors.New("error1")
err2 := errors.New("error2")
err3 := errors.New("error3")
errChain1 := fmt.Errorf("wrap multiple error: %w, %w, %w", err1, err2, err3)
fmt.Println(errChain1)
errChain2 := errors.Join(err1, err2, err3)
fmt.Println(errChain2)
}
运行这个示例,我们可以看到如下输出:
wrap multiple error: error1, error2, error3
error1
error2
error3
两种方式的不同之处在于errors.Join在每个被包装的错误后面加了一个换行符。
解构错误链: Unwrap、 Is 和 As
创建了错误链,我们还需要有方法来检查链中是否包含特定的错误,或者获取链中特定类型的错误信息。标准库 errors 包提供了三个关键函数: errors.Unwrap(err error) error、 errors.Is(err error, target error) bool 和 errors.As(err error, target interface{}) bool。我们分别来看。
首先是 errors.Unwrap(err error) error。 如果 err 是一个包装错误(即它内部有一个通过 %w 或实现了 Unwrap() error 方法包裹的错误), 那 Unwrap 返回被包裹的那个直接内部错误。如果 err 没有包裹其他错误,或者 err 是 nil,则返回 nil。
我们可以通过循环调用 Unwrap 来遍历整个错误链,直到找到根错误(最底层的那个)或者 Unwrap 返回 nil。比如下面的printErrChain函数,利用该函数我们可以清晰地将上面示例中的errChain链上的错误逐一Unwrap出来:
func main() {
err1 := errors.New("error1")
err2 := fmt.Errorf("error2: wrap %w", err1)
err3 := fmt.Errorf("error3: wrap %w", err2)
errChain := fmt.Errorf("error chain: wrap %w", err3)
printErrChain(errChain)
}
func printErrChain(err error) {
fmt.Println("Error Chain:")
for err != nil {
fmt.Printf(" -> %v\n", err)
err = errors.Unwrap(err) // 获取下一个内部错误
}
}
运行该示例,将得到如下输出:
Error Chain:
-> error chain: wrap error3: wrap error2: wrap error1
-> error3: wrap error2: wrap error1
-> error2: wrap error1
-> error1
其次是 errors.Is(err error, target error) bool。errors.Is函数用于判断错误链 err 中是否存在一个错误等于 target 错误值。它会递归地调用 Unwrap 来检查链上的每一个错误是否与 target 相等(使用 == 比较,或者如果错误实现了 Is(error) bool 方法,则调用该方法)。
errors.Is 特别适合用来检查错误链中是否包含某个哨兵错误值(Sentinel Error):
// 检查 errService 是否包含了数据库未找到行的错误ErrNoRows
if errors.Is(errService, sql.ErrNoRows) {
fmt.Println("The root cause was sql.ErrNoRows!")
// 可以进行针对性处理,比如返回 404 Not Found
}
最后是 errors.As(err error, target interface{}) bool。errors.As用于判断错误链 err 中是否存在一个错误的类型匹配 target 指向的类型,并将第一个匹配到的错误值赋给 target。 target 必须是一个指向接口类型或具体错误类型的指针。
errors.As 特别适合用来检查错误链中是否包含某个特定错误类型,并获取该错误的值以访问其包含的额外信息。
下面示例定义了一个自定义网络错误类型NetworkError,并演示了如何使用 errors.As 来检查错误链中是否存在该类型的错误,并提取相关信息:
package main
import (
"errors"
"fmt"
)
// NetworkError 是一个自定义的网络错误类型
type NetworkError struct {
Op string
URL string
Err error // 可能包装了底层错误
}
// Error 方法实现了 error 接口
func (e *NetworkError) Error() string {
return fmt.Sprintf("Network error on %s %s: %v", e.Op, e.URL, e.Err)
}
// Unwrap 方法允许 errors.As 访问被包装的错误
func (e *NetworkError) Unwrap() error {
return e.Err
}
// someOperation 模拟一个可能返回 NetworkError 的操作
func someOperation(url string) error {
// 模拟一个底层错误
originalErr := errors.New("connection refused")
// 创建并返回一个包装后的 NetworkError
return &NetworkError{
Op: "GET",
URL: url,
Err: originalErr,
}
}
func main() {
// 调用 someOperation 获取错误
err := someOperation("https://example.com")
var netErr *NetworkError // 准备一个指针变量来接收
if errors.As(err, &netErr) { // 检查链中是否有 *NetworkError 类型
// 如果找到,netErr 现在指向那个 NetworkError 实例
fmt.Printf("Network error occurred: Op=%s, URL=%s, OriginalErr=%v\n",
netErr.Op, netErr.URL, netErr.Err)
// 可以根据 netErr 中的具体信息做处理
} else {
fmt.Println("No network error found in the error chain.")
fmt.Printf("Original error: %v\n", err)
}
}
运行该示例,将得到如下输出:
Network error occurred: Op=GET, URL=https://example.com, OriginalErr=connection refused
下面再看一个使用接口指针类型作为target的示例:
package main
import (
"errors"
"fmt"
)
// 定义一个通用的错误接口
type CustomError interface {
Error() string
CustomDetails() string // 自定义的错误信息方法
}
// NetworkError 实现了 CustomError 接口
type NetworkError struct {
Op string
URL string
Err error
}
func (e *NetworkError) Error() string {
return fmt.Sprintf("Network error on %s %s: %v", e.Op, e.URL, e.Err)
}
func (e *NetworkError) CustomDetails() string {
return fmt.Sprintf("Op: %s, URL: %s", e.Op, e.URL)
}
func (e *NetworkError) Unwrap() error {
return e.Err
}
// DatabaseError 实现了 CustomError 接口
type DatabaseError struct {
Query string
Err error
}
func (e *DatabaseError) Error() string {
return fmt.Sprintf("Database error with query '%s': %v", e.Query, e.Err)
}
func (e *DatabaseError) CustomDetails() string {
return fmt.Sprintf("Query: %s", e.Query)
}
func (e *DatabaseError) Unwrap() error {
return e.Err
}
// someOperation 模拟返回不同类型错误的操作
func someOperation(errorType string) error {
switch errorType {
case "network":
return &NetworkError{
Op: "GET",
URL: "https://example.com",
Err: errors.New("connection timeout"),
}
case "database":
return &DatabaseError{
Query: "SELECT * FROM users",
Err: errors.New("invalid column name"),
}
default:
return errors.New("unknown error")
}
}
func main() {
// 模拟获取一个错误
err := someOperation("network") // 可以尝试 "database" 或其他值
// 使用接口指针作为 target
var customErr CustomError
if errors.As(err, &customErr) {
fmt.Printf("Custom error detected: %s\n", customErr.Error())
fmt.Printf("Custom details: %s\n", customErr.CustomDetails())
// 进一步判断具体类型 (可选)
switch v := customErr.(type) {
case *NetworkError:
fmt.Println("This is a NetworkError.")
fmt.Printf("URL: %s\n", v.URL)
case *DatabaseError:
fmt.Println("This is a DatabaseError.")
fmt.Printf("Query: %s\n", v.Query)
}
} else {
fmt.Println("No custom error found in the error chain.")
fmt.Printf("Original error: %v\n", err)
}
}
这个例子展示了如何使用接口类型指针作为 errors.As 的 target,从而实现更灵活的错误处理。通过定义一个通用的错误接口,我们可以处理实现了该接口的任何类型的错误,无需事先知道具体的错误类型。类型断言可以用于进一步判断具体类型,并执行特定于该类型的操作。这种方法在处理多种不同类型的错误时非常有用。
Unwrap、 Is、 As 这三个函数是处理错误链的核心工具,让我们能够在保留完整错误上下文的同时,精确地检查和处理我们关心的特定错误情况。
掌握了如何通过错误包装构建信息丰富的错误链,以及如何使用 errors.Unwrap、 Is 和 As 来探查错误链之后,我们面临的下一个问题是:在实际编码中,面对各种不同的错误情况,我们应该采取哪种具体的判断和处理策略呢?Go为我们提供了多种选择,每种策略都有其适用的场景和权衡。
错误处理策略:选择合适的判断与处理方式
知道了如何创建和解构错误链,我们在实际编码中应该采用哪种策略来判断和处理错误呢?主要有4种选择,各有优劣,我们逐一来看一下。
策略一:简单检查 err != nil
这是最基础、最常用的方式。我们只关心操作是否成功,不关心具体的失败原因。
data, err := ioutil.ReadFile("config.json")
if err != nil {
// 只知道出错了,进行通用处理
log.Printf("Failed to read config: %v", err)
return defaultConf, err // 可能直接返回错误
}
// 成功,继续处理 data
这种方式的优点在于其简单直接。通过检查错误是否为 nil,可以快速判断操作是否成功,并进行通用的错误处理。例如,在读取配置文件时,如果发生错误,程序会记录错误信息并返回默认配置和错误。这种处理方式让代码保持了清晰和简洁。
然而,这种方法也有缺点。由于无法根据不同的错误原因采取针对性的错误处理逻辑,开发者在遇到不同的错误情况时可能无法进行适当的响应。这可能导致程序在处理不同类型错误时缺乏灵活性,影响整体的错误处理能力。
策略二:哨兵错误值
预先定义一些导出的错误变量(通常在包级别使用 var ErrXxx = errors.New("...") 定义),这些变量本身就代表了一种特定的错误状态。 调用者通过 errors.Is 来检查返回的错误是否是这个预定义的哨兵值。标准库中的 io.EOF、 sql.ErrNoRows 都是典型的哨兵错误。
package fileutils
import "errors"
var ErrPermission = errors.New("permission denied") // 定义哨兵错误
func WriteData(path string, data []byte) error {
// ... 尝试写入 ...
if permissionIssue {
return ErrPermission // 返回预定义的错误值
}
// ...
return nil
}
// 调用方
err := fileutils.WriteData("/etc/passwd", data)
if errors.Is(err, fileutils.ErrPermission) { // 使用 errors.Is 判断
fmt.Println("Operation failed due to permissions.")
// 采取特定处理
} else if err != nil {
// 处理其他错误
}
这种方法的优点在于其简单易懂,错误的意图非常明确。开发者可以清晰地判断出错误的来源和性质。例如,在写入数据时,如果出现权限问题,可以直接返回预定义的 ErrPermission,调用者随后可以通过 errors.Is 来进行判断并采取相应的处理措施。
然而,哨兵错误值也存在一些缺点。首先,它可能导致包之间的耦合,调用者需要导入定义哨兵错误的包,这增加了依赖性。其次,哨兵错误通常不携带额外的上下文信息,虽然可以通过错误包装来添加这些信息,但这也使得处理变得更加复杂。最后,如果定义的哨兵错误数量过多,管理和记忆这些错误的成本也会随之增加,从而影响开发的效率。
策略三:特定错误类型
定义一个自定义的结构体类型,让它实现 error 接口。这个结构体可以包含丰富的上下文信息(比如哪个字段验证失败、网络操作的目标地址、临时性错误还是永久性错误等)。调用者使用 errors.As 来检查错误链中是否存在这种类型的错误,并获取其值以访问详细信息。
package main
import (
"errors"
"fmt"
)
// FieldError 表示字段验证错误
type FieldError struct {
FieldName string
Issue string
}
// Error 方法实现了 error 接口
func (fe *FieldError) Error() string {
return fmt.Sprintf("validation failed for field '%s': %s", fe.FieldName, fe.Issue)
}
// ValidateInput 验证输入数据
func ValidateInput(input map[string]string) error {
if input["email"] == "" {
// 返回一个具体的 FieldError 类型
return &FieldError{FieldName: "email", Issue: "cannot be empty"}
}
if len(input["password"]) < 8 {
return &FieldError{FieldName: "password", Issue: "must be at least 8 characters"}
}
// ... 其他验证 ...
return nil
}
func main() {
// 模拟输入数据
inputData := map[string]string{
"email": "",
"password": "short",
}
// 调用 ValidateInput 进行验证
err := ValidateInput(inputData)
// 准备接收 FieldError 指针
var fieldErr *FieldError
// 使用 errors.As 判断并获取 FieldError
if errors.As(err, &fieldErr) {
fmt.Printf("Input validation failed on field '%s': %s\n",
fieldErr.FieldName, fieldErr.Issue) // 输出:Input validation failed on field 'email': cannot be empty
// 可以根据 fieldErr.FieldName 给用户更具体的提示
} else if err != nil {
// 处理其他类型的错误
fmt.Printf("An unexpected error occurred: %v\n", err)
} else {
fmt.Println("Input validation successful!")
}
}
这种方法的优点在于其类型安全性。自定义错误类型可以携带详细的上下文信息,使得错误处理更加灵活和具体。例如,在字段验证时,如果某个字段不符合要求,返回的 FieldError 类型可以准确指明出错的字段和问题。这种方式将错误的行为封装在类型内部,使得错误处理更加清晰。
然而,特定错误类型也有其缺点。首先,开发者需要定义额外的类型,增加了代码量。这可能使得代码看起来更加复杂,尤其是在错误种类较多的情况下。此外,定义和管理这些自定义错误类型也需要一定的时间和精力。因此,尽管特定错误类型提供了丰富的上下文信息和灵活性,但在实现上相对较为繁琐。
策略四:行为特征判断
有时我们不关心错误的具体类型或值,而是关心它是否具有某种行为或特征。比如,一个网络错误是否是临时性的(Temporary),可以稍后重试?是否是超时(Timeout)?我们可以定义只包含描述这种行为的方法的接口,然后使用类型断言或 errors.As(如果目标是指向接口的指针)来检查错误是否实现了该接口。
package main
import (
"errors"
"fmt"
"time"
)
// temporary 接口用于描述临时性错误
type temporary interface {
Temporary() bool
}
// OpError 是一个自定义的操作错误类型
type OpError struct {
Op string
Net string
Addr string
Err error
IsTemporary bool // 显式指定是否是临时错误
}
func (e *OpError) Error() string {
return fmt.Sprintf("op error: %s %s %s: %v", e.Op, e.Net, e.Addr, e.Err)
}
func (e *OpError) Temporary() bool {
return e.IsTemporary
}
func (e *OpError) Unwrap() error {
return e.Err
}
// IsTemporary 函数判断错误是否是临时性的
func IsTemporary(err error) bool {
var te temporary
// 可以用 errors.As (更推荐,能处理错误链)
if errors.As(err, &te) {
return te.Temporary()
}
// 或者用类型断言 (只能检查 err 本身)
// if te, ok := err.(temporary); ok {
// return te.Temporary()
// }
return false
}
// 模拟一个可能返回临时性网络错误的函数
func someNetCall() error {
// 模拟一个临时性错误(例如连接超时)
err := &OpError{
Op: "dial",
Net: "tcp",
Addr: "127.0.0.1:8080",
Err: errors.New("connection refused"), // 模拟连接被拒绝
IsTemporary: true, // 显式指定为临时错误
}
return err
}
func main() {
// 调用 someNetCall 获取错误
err := someNetCall()
// 判断错误是否是临时性的
if IsTemporary(err) {
fmt.Println("Network error is temporary, retrying later...")
// 模拟重试逻辑
fmt.Println("Retrying in 5 seconds...")
time.Sleep(5 * time.Second)
fmt.Println("Retry successful (simulated).")
} else if err != nil {
// 处理非临时性错误
fmt.Printf("Non-temporary error: %v\n", err)
} else {
fmt.Println("No error occurred.")
}
}
这个示例展示了如何自定义一个错误类型,并实现 temporary 接口,以及如何使用 errors.As 函数来判断错误链中是否存在实现了该接口的错误。
该策略的优点在于高度解耦,调用者只需关注错误的行为特征,而不依赖于具体的错误类型或值。 这种方式提供了极大的灵活性和可扩展性,使其适用于多种应用场景。然而,缺点是需要预先设计好描述行为的接口,且使用场景相对特定,主要适用于判断错误的可恢复性和类别等情况。
策略选择的考量
在选择错误处理策略时,可以根据具体场景的需求进行判断。对于仅需判断操作是否出错的情况,使用简单的 err != nil 是最合适的方式。若需要区分几种固定且众所周知的错误状态,则可以采用哨兵错误值结合 errors.Is 的方法。在需要传递丰富的错误上下文信息或错误本身具有多种状态的场景中,特定错误类型与 errors.As 的组合会更加有效。
此外,当需要根据错误的某种能力或特征(例如是否可重试)做出决策时,使用行为特征接口配合 errors.As 或类型断言是一个理想的选择。
通常,一个项目中会根据不同需求混合使用这些策略,以实现更灵活和有效的错误处理。
通过上述几种策略,我们可以有效地处理程序中预期的、作为正常流程一部分的“错误”。但Go语言中还有一个与错误处理相关的概念,常常引起混淆,那就是 panic。它与我们一直在讨论的 error 有什么本质区别?我们又该在何种场景下(如果真的需要的话)使用 panic 和 recover 呢?厘清这两者的边界,对于编写健壮的Go程序至关重要。
Panic vs Error:Go 中异常处理的边界与正确场景
Go语言明确区分了错误(error)和异常(panic)。
-
错误(Error): 是预期中可能发生的问题,是程序正常流程的一部分。比如文件未找到、网络连接失败、用户输入无效等。Go强制要求显式地检查和处理错误。
-
异常(Panic): 表示程序遇到了无法恢复的内部错误或严重的程序缺陷,此时程序无法安全地继续执行下去。例如,数组访问越界、空指针解引用、并发写map等。
panic会中断正常的控制流,开始在goroutine的调用栈中向上传递“恐慌”,执行每个defer语句,直到到达顶层或被recover捕获。如果始终未被捕获,那么该panic将会导致整个程序退出。
panic 的正确使用场景非常有限,主要包括几个方面。
首先,在遇到真正不可恢复的错误时,程序如果遭遇内部状态错误,比如关键数据结构的损坏,应该使用 panic,因为继续运行已经没有意义。
其次,在程序的初始化阶段,如 init 函数或全局变量初始化时,如果出现无法继续的错误,使用 panic 可以实现快速失败。
最后,开发者可以在代码中添加断言,尤其是在测试代码中,如果某个本应为真的条件未满足,可以通过 panic 来标明存在编程错误。
另一方面,内置函数 recover() 的作用是在 defer 语句中调用时显现。它能够捕获当前 goroutine 中的 panic,使程序从恐慌状态中恢复,阻断panic的继续向上传递,并返回传递给 panic 的值。如果没有发生 panic, recover 则返回 nil。
recover的主要用途是在程序的边界,即程序中可能会出现异常状态的关键点,通常是与外部交互或执行上下文切换的地方,例如每个 HTTP handler 的顶层或每个 goroutine 的入口函数,捕获意外的panic,记录日志,并返回内部错误给调用者(或 HTTP 500 响应),以防止单个请求或 goroutine 的崩溃导致整个服务进程退出。
需要特别注意的是,绝对不要使用 panic 来传递普通的、可预期的错误。这种做法会破坏 Go 语言明确的错误处理流程,使错误变得难以追踪和处理,进而导致代码脆弱。
在区分 Error 和 Panic,以及选择合适的错误处理策略之外,日常错误处理设计中还有一些重要的实践细节和注意事项,它们虽然零散,却同样影响着代码的质量和可维护性。
错误处理设计的其他注意事项
这里再补充几点重要的错误处理设计的实践建议:
-
日志 vs 返回:在一个函数或方法中,通常应该 要么记录详细错误日志,要么将错误返回给调用者,避免两者都做。通常,底层的函数负责返回错误(可以包装上下文),顶层的调用者(如HTTP handler或main函数)负责根据最终的错误情况记录日志或向用户展示信息。
-
错误信息:
error的Error()方法返回的字符串应该简洁明了,描述错误本身。额外的上下文信息应该通过错误包装添加,或者存储在自定义错误类型的字段中,避免在错误字符串中暴露敏感信息(如文件路径、IP地址等)。 -
错误链深度:过深的错误链(嵌套包装太多层)可能会让错误信息变得冗长难读。在适当的层级,可以考虑处理(比如记录日志后返回一个更通用的错误)或转换错误,而不是一味地向上包装。
通过遵循这些注意事项,我们可以让Go的显式错误处理发挥出其最大的威力,编写出既健壮又易于理解的代码。
到这里,我们已经深入探讨了Go当前错误处理的核心机制、各种策略以及实践中的考量。可以说,Go 1.13版本引入的错误链和 errors.Is/As 极大地完善了Go的错误处理能力,解决了早期版本中上下文信息易丢失、错误判断不便等问题。然而,正如任何广泛使用的语言特性一样,关于Go错误处理的讨论和思考从未停止。社区中关于如何进一步优化错误处理体验、减少样板代码的呼声一直存在,Go核心团队也对此保持着关注和探索。接下来,我们就来简单回顾一下这些年Go在错误处理演进方面的尝试,以及对未来的展望。
Go错误处理的演进与展望
正如我们在本节课开头提到的,错误处理一直是Go社区讨论的热点,在历年的Go官方用户调查中,它也常常位列“最希望改进的功能”榜首。这并非意味着Go现有的错误处理机制( error 接口、显式检查、错误链)不好,恰恰相反,它为构建可靠软件提供了坚实的基础。但社区的期待主要集中在如何能 减少 if err != nil 的样板代码,同时又不牺牲Go错误处理的 显式性、清晰性和错误即值的核心哲学。
多年来,Go核心团队和社区成员为此付出了大量努力,提出了多个备受关注的错误处理改进提案,但遗憾的是,这些提案大多因未能完美平衡简洁性、Go的哲学以及向后兼容性等因素而被搁置或否决。我们不妨简要回顾几个典型的探索方向。
try 内建函数提案(Go 2 Error Handling Trial)
这是Go团队在Go 2草案中最受瞩目的提案之一。它试图引入一个 try 内建函数(或操作符),如果在 try 的表达式中发生错误,当前函数会立即返回该错误。
-
设想语法:
value := try(FailingFunc())。 -
优点:能显著减少
if err != nil { return ..., err }的重复代码。 -
被否决原因:社区对其引入的隐式控制流(类似轻量级异常)存在较大争议,认为它可能破坏Go错误处理的明确性和可读性。错误处理路径不再那么“显眼”,增加了理解代码控制流的难度。同时,如何与
defer交互、如何处理多个返回值的函数等细节也存在复杂性。
错误检查操作符(如 ? 或 check/handle 块 )
借鉴其他语言(如Rust的 ? 操作符),有提案建议引入某种简写操作符或块结构来简化错误检查和返回。
-
设想语法:
value := FailingFunc()?或check err { handle err }。 -
优点:同样旨在减少样板代码。
-
面临挑战:
?操作符的语义与Go现有的多返回值和error接口如何优雅结合是一个难题。check/handle块则引入了新的控制结构,增加了语言复杂性,并可能像try一样被认为引入了不够显式的错误处理路径。
随着泛型的引入,社区开始探索是否能利用泛型来创建更通用的错误处理辅助函数或模式,以减少一些重复代码,例如创建能包装不同类型错误并附加通用上下文的泛型错误类型。实际的现状呢?泛型确实为库作者提供了一些新的工具来封装错误处理逻辑,但它并未从根本上改变Go语言层面的错误处理范式( error 接口和显式检查)。它更多的是在库的层面提供便利,而非语言核心语法的变革。
Go错误处理的核心哲学是错误即值、显式处理。 这意味着错误是普通的返回值,可以像其他值一样被传递、检查、记录。意味着错误处理逻辑是程序正常控制流的一部分,清晰可见。
任何试图“简化”错误处理的提案,如果引入了隐式的控制流(如 try 的提前返回),或者让错误处理路径不够显眼,就很容易与这个核心哲学产生冲突。此外,Go语言对向后兼容性的承诺,以及对保持语言简洁性的追求,都使得对这样一个核心机制的改动需要极其审慎。
我个人认为,当前 Go 的 if err != nil 风格,虽然有时显得重复,但其带来的 代码清晰度、错误处理路径的明确性以及对错误的重视程度 是非常有价值的。它迫使开发者思考每一个可能出错的地方,这对于构建可靠的系统至关重要。错误链机制( %w、 errors.Is、 errors.As)的引入,已经极大地改善了错误上下文传递和错误类型判断的问题,弥补了早期错误处理的一些不足。
当然,如果未来能出现一种新的提案,它能够在 完全保持Go显式、直观的错误处理哲学 的基础上,安全地、优雅地减少一些样板代码,那无疑是值得期待的。
但就目前而言, 拥抱并掌握现有的错误处理机制——理解 error 接口、熟练使用错误包装和 errors 包的辅助函数、根据场景选择合适的错误处理策略——仍然是每个Go开发者提升代码质量的必经之路。
小结
这节课,我们深入系统地探讨了Go语言错误处理的设计哲学、核心机制、实践策略以及未来的演进思考。
-
Go的哲学:我们理解了Go坚持显式处理、错误即值的核心理念。错误作为普通的返回值,强制开发者关注并处理每一个可能出错的地方,这构成了Go程序健壮性的基础。
-
错误链的威力:自Go 1.13以来,通过
fmt.Errorf的%w动词进行错误包装,以及使用errors.Unwrap、errors.Is、errors.As来解构错误链,已经成为现代Go错误处理的标准实践。这使得我们能够在保留完整错误上下文的同时,精确地判断和处理特定错误。 -
核心处理策略:我们学习了根据不同场景选择合适的错误处理策略,包括基础的简单检查(
!= nil)、针对已知错误状态的哨兵错误值(errors.Is)、需要丰富上下文的特定错误类型(errors.As),以及关注错误行为的行为特征判断。 -
Panic vs. Error:我们严格区分了错误(程序正常流程的一部分)和异常(通常是不可恢复的程序缺陷)。明确了
panic仅用于表示严重的内部错误或快速失败,绝不能用来传递普通的、可预期的错误。recover则用于在边界捕获panic,防止程序崩溃。 -
注意事项:我们还强调了一些重要的实践细节,如避免同时记录日志和返回错误、保持错误信息清晰安全、适度管理错误链深度等。
-
演进与展望:我们回顾了Go社区和核心团队在改进错误处理机制方面所做的探索(如
try提案)以及面临的挑战。理解了Go在保持其显式、直观的错误处理哲学与减少样板代码之间的审慎权衡。虽然现有机制已相当成熟,但对更优雅方案的探索仍在继续。
掌握Go的错误处理设计,不仅是编写健壮代码的基础,也是理解Go语言简洁、务实风格的关键。通过显式处理、错误包装、合理的策略选择,并关注其演进,我们可以构建出既可靠又易于调试和维护的Go应用程序。Go的错误处理方式或许不是所有语言中最简洁的,但它无疑是经过深思熟虑的,并且在实践中被证明是行之有效的。
思考题
假设你在编写一个函数 processUserData(userID int),它内部需要依次调用三个函数:
-
getUserProfile(userID)可能返回sql.ErrNoRows或其他数据库错误。 -
calculateScore(profile)可能返回一个自定义的validation.ErrInvalidProfile类型错误。 -
updateAnalytics(userID, score)可能返回一个网络错误,该错误可能实现了temporary接口。
在 processUserData 函数中,你会如何组织错误处理逻辑,以便能够:
-
在
getUserProfile返回sql.ErrNoRows时,返回一个特定的业务错误ErrUserNotFound。 -
在
calculateScore返回validation.ErrInvalidProfile时,能获取到错误的详细信息并记录日志,然后返回一个通用的处理失败错误。 -
在
updateAnalytics返回临时网络错误时,尝试进行1次重试;如果是其他网络错误,则直接返回失败。 -
对于所有其他未预料到的错误,都包装上 “failed to process user data for id X” 的上下文信息再返回。
不需要写完整代码,描述关键的 if err != nil 分支和使用的 errors.Is/As 或类型断言逻辑即可。
欢迎在评论区分享你的错误处理策略!我是Tony Bai,我们下节课见。
API设计:构建用户喜爱、健壮可靠的公共接口
你好!我是Tony Bai。
前面几节课,我们探讨了项目布局、包设计、并发设计、接口设计和错误处理设计,这些都构成了我们构建高质量Go应用的基础。今天,我们要聚焦于这一切努力最终呈现给用户的那个界面——API(Application Programming Interface)。
API无处不在,从我们每天使用的Web服务(RESTful、gRPC)、操作系统调用,到我们代码中导入的各种库和框架。可以说, 现代软件开发很大程度上就是围绕着API进行构建和交互的。
虽然API种类繁多,但本节课将聚焦于如何设计Go包(或模块)对外暴露的公共API。这里的API指的是那些首字母大写、可以被其他包导入和使用的函数、变量、常量、类型(及其可导出字段和方法)。这通常发生在你编写一个库供他人使用,或者在一个大型项目中划分模块,需要定义清晰的模块间交互接口时。
一个设计糟糕的包API,可能会让使用者痛苦不堪:难以理解、容易误用、性能低下、频繁变更导致兼容性噩梦。而一个设计良好、用户喜爱的API,则会像一件趁手的工具,清晰、高效、健壮可靠,能够极大地提升开发效率和库(或模块)的生命力。
那么,如何才能设计出这样的Go包API呢?
-
评判API好坏的标准是什么?仅仅是功能正确吗?
-
Go语言的特性(如简洁性、接口、错误处理)对API设计有哪些具体影响?
-
有哪些核心原则和实践技巧可以指导我们设计出更优秀的API?
这节课,我们就来深入探讨Go包API设计的核心原则与实践。我们将一起:
-
明确Go包API的构成要素。
-
从用户视角出发,建立评价API设计的五大核心标准。
-
结合Go语言特性和示例,逐一解析如何实践这五大标准:易用性、安全性、兼容性、高效性、惯例性。
掌握这些,你将能更有信心地设计出让用户(包括未来的你)用得舒心、值得信赖的Go包API。
Go包API的核心构成:对外暴露的“契约”
在谈论设计原则之前先要明确,当我们说一个Go包的“API”时,具体是指什么。根据Go的导出规则(首字母大写决定可见性),一个包的公共API由以下显性元素构成:
-
导出的函数(Exported Functions):包级别提供的可调用功能。
-
导出的变量(Exported Variables):包级别提供的可访问状态(应谨慎使用,因为它们是全局可变的)。
-
导出的常量(Exported Constants):包级别定义的、不可变的值。
-
导出的类型(Exported Types):
-
类型本身(如
type MyStruct struct {...})。 -
类型的可导出字段(结构体中首字母大写的字段)。
-
类型的可导出方法(首字母大写的方法)。
-
这些导出的标识符共同构成了包与外部世界交互的显性契约。 它们是我们在文档中承诺会保持稳定(或按版本演进)的部分。一旦发布并被用户依赖,对这些API的任何不兼容修改都可能直接破坏用户的代码。
然而,API的“契约”并不仅仅局限于这些明确导出的标识符。这里,我们必须引入一个在API设计和维护领域至关重要的定律——海勒姆定律(Hyrum’s Law),也被称为“隐式接口定律”:
“当你有足够多的API用户时,你在合同(文档)中承诺什么都无关紧要:你系统中所有可观察的行为都会被某些人所依赖。”
这条定律揭示了一个残酷的现实: API的实际契约往往比我们书面承诺的契约更广泛。除了导出的函数签名、类型定义外,API还包含了大量可观察的行为语义,这些也构成了用户可能依赖的隐性契约。这些行为可能包括:
-
特定的错误返回值或错误文本格式:即使用户只检查
err != nil,他们也可能在日志或监控中依赖错误的具体文本。 -
函数执行的副作用:例如,一个函数在完成主要任务的同时,可能还会更新某个全局状态或写入一个日志文件,即使这未在文档中明确说明。
-
性能特征:比如某个函数的平均响应时间,或者它分配内存的模式。
-
特定情况下的panic行为:即使不鼓励,但某些情况下panic也是可观察的。
-
未导出字段的默认值或内部状态的间接影响:通过某些导出方法可以间接观察到。
-
依赖库的版本或行为:如果你的API间接暴露了某个依赖库的特性,用户可能也会依赖它。
海勒姆定律的启示对API设计和维护至关重要:
-
API设计需极其谨慎:在设计API时,不仅要考虑显式的签名,还要思考所有可能被用户观察到的行为和副作用。应尽可能减少不必要的、未承诺的可观察副作用。
-
文档并非万能挡箭牌:即使你在文档中明确说明某个行为是“内部实现细节,请勿依赖”,一旦它被用户观察到并依赖,后续的修改仍然可能“破坏”他们的系统。
-
变更的巨大成本:任何对可观察行为的改动(哪怕是修复一个 “Bug” 或是改变一个未明确承诺的行为),都可能是一个破坏性变更 (Breaking Change)。这也解释了为什么移除那些看似“垃圾”或设计不佳的旧特性会如此困难——总有用户在依赖它们。
-
版本控制和兼容性策略:必须有严格的版本管理策略(如语义版本控制 SemVer)来管理API的演进,并通过清晰的发布说明、废弃策略和迁移指南来帮助用户应对变更。
因此,当谈论Go包API的核心构成时, 我们不仅要关注那些通过首字母大写明确暴露出来的“显性契约”,更要时刻警惕那些可能被用户依赖的“隐性契约”——即API的所有可观察行为。一个真正负责任的API设计者,会努力让显性契约尽可能地覆盖所有预期行为,并最大限度地减少未预期的、可能被依赖的副作用。
理解了API的这种双重契约(显性与隐性),我们才能更好地进入下一环节,讨论如何设计出用户喜爱且长期可靠的API。
用户视角下的API设计“黄金标准”
好的API设计,最终目标是服务好它的用户(可能是其他团队成员、外部开发者,甚至是几个月后的你自己)。用户的核心期望是什么?我们可以将其归纳为五个关键要素,作为我们评判和设计API的“黄金标准”:
-
易用性(Usability): API是否容易理解、学习和正确使用?用户能否快速上手,甚至“用过一次后,下次无需查手册”?
-
安全性(Security & Safety):API是否健壮可靠?是否能防止误用?是否考虑了并发场景下的安全?
-
兼容性(Compatibility):API是否稳定?后续的演进是否能保证向后兼容,不轻易破坏用户的现有代码?
-
高效性(Efficiency):API的性能是否满足需求?是否避免了明显的性能陷阱?资源消耗是否合理?
-
惯例性(Idiomatic):API的设计是否符合Go语言的习惯和风格?是否让有经验的Go开发者感到自然和熟悉?
这些要素本身就是设计任何高质量Go SDK的重要准则。接下来,我们逐一深入探讨如何实践这五大要素。
要素一:易用性——让用户第一次就上手
易用性是API设计中最直观也最影响用户体验的因素。一个易用的API至少应该做到简单和清晰,让用户第一次就上手,并在用过一次后,下次无需查手册,这可以理解为API易用性的充分但不必要的条件。
简单原则(Simplicity)
在追求优秀API设计的道路上,简单性扮演着至关重要的角色。它不仅仅是一个理想状态,更是优秀API的前提条件,尽管简单本身并不足以完全定义优秀。核心在于践行“少即是多”这一关键原则。
“少即是多”强调API的功能应该专注,严格遵循单一职责原则(SRP)。这意味着每一个函数或类型都应当只负责一项明确的任务,并把它做好。我们应极力避免设计那些试图执行过多任务的“万能”函数,或是包含许多不相关方法的复杂类型。一个功能专注、设计简洁的API,其优势是显而易见的:它更容易被开发者理解和学习,更易于进行单元测试和集成测试,同时也具备更高的可组合性,允许开发者像搭积木一样灵活地构建更复杂的功能。
让我们通过一个Go语言的例子,来具体看下如何通过拆分功能提升API的简单性。
首先是反模式:一个函数承载过多职责。
想象一个名为 ProcessUserData 的函数,它试图一次性处理用户数据的多个方面,例如加载用户资料、更新统计信息和发送通知。这种设计往往会导致函数签名复杂(可能需要多个布尔标志来控制不同行为),并且内部逻辑耦合度高。
// 反模式:一个函数做太多事
func ProcessUserData(userID int, loadProfile bool, updateStats bool, sendNotification bool) (*Profile, error) {
var profile *Profile
var err error
if loadProfile {
// 加载用户资料逻辑...
// profile, err = ...
}
if updateStats {
// 更新统计信息逻辑...
}
if sendNotification {
// 发送通知逻辑...
}
return profile, err
}
这样的函数难以理解其确切行为,难以独立测试某一项功能,也难以在其他上下文中复用其部分逻辑。
其次是推荐模式:拆分为专注的函数。
与之相对,推荐的做法是将 ProcessUserData 拆分为多个更小、更专注的函数。每个函数都清晰地定义其单一职责:
// 推荐模式:拆分成更专注的函数/方法
// GetUserProfile 负责获取用户资料
func GetUserProfile(ctx context.Context, userID int) (*Profile, error) { ... }
// UpdateUserStats 负责更新用户统计信息
func UpdateUserStats(ctx context.Context, userID int, stats Stats) error { ... }
// SendNotification 负责发送通知
func SendNotification(ctx context.Context, userID int, message string) error { ... }
通过这样的拆分,每个函数的名称和参数都准确地反映了其功能,并可以独立地为 GetUserProfile、 UpdateUserStats 和 SendNotification 编写测试用例。调用方还可以根据实际需求,按需组合调用这些函数。例如,某个场景可能只需要获取用户资料并发送通知,而不需要更新统计。当需要修改某项功能(如通知逻辑)时,只需要关注 SendNotification 函数,降低了修改带来的风险。
清晰原则(Clarity)
首先是 命名精准与上下文简洁。API的名称(包、类型、函数、方法、变量、常量)应准确、无歧义地描述其功能或代表的实体。避免过于宽泛、模糊或可能产生误解的词语。目标是让用户通过名称就能大致猜到它的用途,让API意图不言自明。
-
在没有歧义的上下文中,简洁通常更受欢迎。例如,标准库
strconv包提供了Atoi(ASCII to Integer)函数,而不是更冗长的ASCIIToInteger,因为在strconv这个包的上下文中Atoi的含义已经足够清晰。 -
避免过于宽泛、模糊或可能产生误解的词语(如
ProcessData、HandleItem),CalculateTotalAmount可以比ProcessData更清晰地表达计算总金额的意图。 -
对于可能产生歧义或功能复杂的API,宁可选择更长但更具描述性的名称。
其次是 参数设计。
-
数量适中:函数或方法的参数不宜过多(通常建议不超过3-4个)。参数过多通常是函数职责不单一的信号。
-
逻辑分组:如果参数较多且逻辑相关,应使用结构体将它们封装起来,提高可读性和可维护性。
-
参数位置符合直觉与惯例:
-
主次分明:将更重要或更“主动”的参数放在前面。例如
http.ListenAndServe(addr string, handler Handler),地址addr是服务的监听目标,handler是处理逻辑,这种顺序符合直觉。如果反过来ListenAndServe(handler Handler, addr string),在调用时http.ListenAndServe(nil, ":8080")就会显得不那么自然(尽管nilhandler 是合法的)。 -
约定俗成:遵循现实世界或领域内的约定。例如,描述几何体时,我们习惯于“长、宽、高”的顺序;计算圆柱体积时,
cylinderVolume(radius, height float64)可能比cylinderVolume(height, radius float64)更符合多数人的认知习惯。 -
标准库惯例:学习并遵循标准库中的参数顺序惯例。例如,
io.Copy(dst Writer, src Reader)和copy(dst, src []T)都是目标参数(dst)在前,源参数(src)在后。这形成了一种强大的模式,用户可以触类旁通。 -
context.Context和error的位置有其特定惯例(将在“惯例性”中详述)。
-
-
可选参数与配置:对于有多个可选参数或复杂配置的函数/方法,优先使用选项模式(Options Pattern),而不是使用大量可变参数或
nil来表示默认值。这使得API调用更清晰,也更易于向后兼容地添加新选项。
下面是选项模式处理可选参数的示例:
package httpclient
type Client struct { timeout time.Duration; retries int }
type Option func(*Client) // 选项是修改 Client 的函数
// WithTimeout 返回一个设置超时的 Option
func WithTimeout(d time.Duration) Option {
return func(c *Client) { c.timeout = d }
}
// WithRetries 返回一个设置重试次数的 Option
func WithRetries(n int) Option {
return func(c *Client) { c.retries = n }
}
// NewClient 接受可变的 Option 参数
func NewClient(opts ...Option) *Client {
// 设置默认值
client := &Client{timeout: 10 * time.Second, retries: 3}
// 应用传入的选项
for _, opt := range opts {
opt(client)
}
return client
}
// 使用
// client1 := httpclient.NewClient() // 使用默认值
// client2 := httpclient.NewClient(httpclient.WithTimeout(5*time.Second), httpclient.WithRetries(1)) // 自定义选项
然后是 返回值明确:返回值的类型和数量应清晰。如果函数可能失败,明确返回 error 类型。如果返回多个值,其含义应易于理解(可考虑具名返回值,但避免裸 return 带来的模糊性)。
最后是 文档与注释:清晰、准确、完整的文档是API易用性的生命线。每个导出的标识符都应有GoDoc注释,解释其用途、行为、参数、返回值、限制和可能的错误。提供可运行的示例代码( Example 函数)能极大地帮助用户理解如何正确使用API。考虑到海勒姆定律,文档也应尽可能明确哪些行为是契约的一部分,哪些是实现细节且可能会改变。
要素二:安全性——构建可信赖的接口
你不能假设API用户都有高尚的品德。一个好的API不仅要易用,更要健壮可靠,能抵御误用甚至是故意攻击,并保证程序的安全。
-
最小权限/暴露原则:只导出(大写)真正需要被外部使用的部分。所有内部实现细节、辅助函数、未最终确定的API都应保持非导出(小写)或放在
internal包中。API表面积越小,越容易维护和保证安全。 -
输入校验:不要信任任何来自外部(甚至是包内部其他部分)的输入。API函数/方法应该对其接收的参数进行必要的校验(如非空检查、范围检查、格式检查等),对于无效输入应明确返回错误,而不是panic或产生未定义行为。
package user
import "errors"
var ErrInvalidEmail = errors.New("invalid email format")
func UpdateEmail(userID int, newEmail string) error {
// 输入校验
if userID <= 0 {
return errors.New("invalid user ID")
}
if !isValidEmailFormat(newEmail) { // 假设有校验函数
return fmt.Errorf("%w: %s", ErrInvalidEmail, newEmail) // 包装错误提供上下文
}
// ... 执行更新逻辑 ...
return nil
}
- 并发安全承诺:
-
明确说明:API(特别是涉及可变状态的类型的方法或操作共享资源的函数)的并发安全性(goroutine-safe)必须在文档中清晰、显著地说明。
-
默认非并发安全:如果没有特别说明,用户通常会假设API不是并发安全的。这是Go社区的一个普遍认知。
-
提供并发安全版本(可选):如果一个核心数据结构或操作在并发场景下需求很高,可以考虑提供两个版本的API:一个基础的、非并发安全的版本(可能性能更高)和一个并发安全的版本。
-
例如
mapvssync.Map:标准库提供了非并发安全的map和并发安全的sync.Map。 -
Safe后缀约定:有时,社区会采用为并发安全版本添加-Safe后缀的命名约定(如MyTypevsMyTypeSafe,或方法DoWork()vsDoWorkSafe()),但这并非官方强制标准,清晰的文档说明更重要。
-
-
内部同步:如果API承诺并发安全,那么它内部必须使用适当的同步原语(如
sync.Mutex、sync.RWMutex、atomic操作)来保护共享状态。
-
- 程序安全承诺:
-
避免不必要的 panic:公共API函数/方法不应该因为可预期的错误情况(如无效输入、资源不可用等)而
panic。这些情况应该通过返回error来处理。panic应保留给真正不可恢复的程序内部错误。 -
禁止
os.Exit:库代码(包API)绝对不能调用os.Exit(),程序的生命周期应由main包或应用程序的顶层逻辑来控制,库中调用os.Exit()会粗暴地终止整个应用程序,这通常是不可接受的。 -
MustXxx模式(谨慎使用):对于某些确实不应该失败的操作(例如,从一个已知合法的常量字符串编译正则表达式),或者开发者明确希望在出错时立即终止程序的场景(通常在初始化阶段或工具类程序中),可以提供一个MustXxx版本的函数。这个函数在内部执行Xxx版本,如果Xxx返回错误,则MustXxx会panic。这是一种将错误检查责任转移给调用者的明确信号。
-
package main
import (
"fmt"
"regexp"
)
// MustCompile 是标准库 regexp 包中的例子
// func Compile(expr string) (*Regexp, error)
// func MustCompile(str string) *Regexp {
// regexp, error := Compile(str)
// if error != nil {
// panic(`regexp: Compile(` + quote(str) + `): ` + error.Error())
// }
// return regexp
// }
func main() {
// 如果正则模式固定且已知合法,使用 MustCompile 很方便
validPattern := `\d+`
re := regexp.MustCompile(validPattern)
fmt.Println(re.MatchString("123")) // true
// 如果模式可能非法,应该使用 Compile 并检查错误
// invalidPattern := `[`
// _, err := regexp.Compile(invalidPattern)
// if err != nil {
// fmt.Println("Compile error:", err)
// }
}
使用 MustXxx 模式时,必须确保其可能 panic 的情况对调用者是清晰和可接受的。
- 资源管理与关闭:如果API创建或管理了需要显式释放的资源(如文件句柄、网络连接、数据库连接池、后台goroutine),必须提供清晰的关闭或清理机制(通常是一个
Close()方法),并在文档中说明何时以及由谁负责调用它。确保资源不会泄漏。
要素三:兼容性——尊重用户的既有代码
API一旦发布并被用户依赖,保持其稳定性就至关重要。频繁的不兼容变更会给用户带来巨大的痛苦。
- 向后兼容承诺: 对于公共API,应尽最大努力保持向后兼容。这意味着,升级到新版本的库后,用户基于旧版本API编写的代码应该仍然能够编译和正确运行。这不仅包括显式的API签名(函数名、参数、返回值、导出类型和字段等),根据海勒姆定律,我们还必须意识到,用户可能依赖了API的任何可观察行为,即“隐性契约”。因此,改变函数的执行副作用、错误返回的特定文本格式,甚至某些性能特征,都可能被视为破坏性变更。
-
可以做(通常安全):添加新的导出函数/类型/方法;给结构体添加新字段(只要用户使用带字段名的字面量初始化);放宽函数参数类型(如从具体类型改为接口)。
-
谨慎或避免做(潜在破坏性变更):
-
删除或重命名导出标识符。
-
改变函数/方法签名(参数或返回值的数量、类型、顺序)。
-
改变导出类型字段的类型或移除字段。
-
改变常量值。
-
改变函数/方法的行为语义或可观察的副作用,即使这些行为未在文档中明确承诺。
-
改变错误返回的具体类型或错误文本格式(如果用户可能依赖它们进行特定处理或解析)。
-
显著改变性能特征(如某个操作突然变慢很多或消耗更多资源)。
-
-
- 语义版本控制(Semantic Versioning - SemVer):遵循 SemVer 2.0.0 规范是管理API兼容性的最佳实践,Go Modules也原生支持SemVer, 为我们保证API兼容性提供了工具链层面的支持。SemVer的版本号格式为
MAJOR.MINOR.PATCH:-
MAJOR版本(如v1.x.x->v2.0.0):包含不兼容的API变更(包括对显性契约和用户可能依赖的隐性契约的破坏)。 -
MINOR版本(如v1.2.x->v1.3.0):包含向后兼容的新功能添加。 -
PATCH版本(如v1.2.3->v1.2.4):包含向后兼容的Bug修复(修复时也要小心,避免改变用户可能已依赖的“buggy”行为)。
-
- 为未来扩展设计:在设计API时,预留一些扩展点,以便未来 在不破坏兼容性的前提下增加功能。
-
接受接口而非具体类型。
-
使用选项模式(Options Pattern)。
-
返回结构体指针而非结构体值(但要注意,即使返回指针,修改结构体内部未导出字段的行为也可能被依赖)。
-
使用函数式参数。
-
明确文档:对于那些你预期可能会改变但又不得不暴露的行为,尽可能在文档中用最强烈的措辞警告用户不要依赖(尽管海勒姆定律告诉我们这可能仍然不够)。
-
要素四:高效性——避免不必要的性能陷阱
虽然API设计的首要目标通常是正确性和易用性,但我们也应关注其性能,避免引入明显的性能陷阱。
首先要 避免不必要的内存分配。
-
避免在API内部创建不必要的临时拷贝。
-
如果函数需要返回切片或map,并且调用者很可能直接修改它们,那么API应该返回副本以保护内部状态,并在文档中说明。
-
如果API返回大量数据(如大的切片或map),考虑是否可以设计成允许调用者提供预先分配好的缓冲区(例如,类似
io.Reader的Read(p []byte))。比如下面这个接收缓冲区的示例:
package data
// ReadDataInto 读取数据到调用者提供的缓冲区 buf
// 返回实际读取的字节数 n 和错误 err
// 这种方式避免了 ReadData 内部为返回数据分配内存
func ReadDataInto(buf []byte) (n int, err error) {
// ... 从某个源读取数据,最多填充 len(buf) 字节 ...
return bytesRead, nil
}
其次要 关注资源消耗。设计API时,要考虑其可能的资源消耗(CPU、内存、网络带宽、文件句柄等)。避免设计出容易导致资源泄漏(如忘记关闭返回的资源)或过度消耗资源的接口。如果某个操作开销特别大,应在文档中明确指出。
最后要 关注性能文档。如果API的性能特征比较特殊(如某个函数是CPU密集型,某个函数有网络延迟),或者有特定的性能调优建议(如建议使用带缓冲的I/O),应该在文档中说明,并最好提供Benchmark代码以方便用户在自己的环境下对API性能做出评估。
要素五:惯例性——写出“Go味道”的API
一个好的Go API应该让有经验的Go开发者感到自然和熟悉,遵循Go社区广泛接受的惯例和风格。这能显著降低用户的学习成本,提高代码的可读性和与其他Go库的互操作性。
- 命名惯例(Naming Conventions):
-
包名(Package Name): 小写、简洁且通常是单数名词,如
http、json、time。包名是调用者使用你API时的前缀(如http.Client),因此它提供了重要的上下文。应避免使用下划线或混合大小写。 -
接口名(Interface Name):如果接口只包含一个方法,通常以
-er结尾,如io.Reader、fmt.Stringer。如果包含多个方法,名称应能概括其行为集合。 -
函数/方法名:
-
使用清晰的驼峰式命名,导出的标识符首字母大写。
-
带有动作语义的函数用动词开头:如
ParseInt、WriteDetail、ConnectToDatabase。 -
创建类函数/构造函数(Constructors):通常命名为
New...或NewXxx...,返回一个类型实例(通常是指针),如errors.New、strings.NewReader、mypkg.NewMyTypeWithConfig(...)。 -
避免不必要的Getter/Setter:Go不鼓励像JavaBeans那样为每个字段都提供
GetXxx和SetXxx方法。如果字段可以安全地直接访问(导出),则直接访问。只有当获取或设置字段需要额外逻辑(如校验、计算、同步、懒加载)时,才需要方法。如果确实需要,简单命名如Value()和SetValue(),比GetValue()更常见。 -
避免与包名重复:函数或类型名不应简单重复包名,因为调用者会写
pkgname.ItemName。例如,在yamlconfig包中,函数名可以是Parse(input string)而不是ParseYAMLConfig(input string)。方法名则可以更简洁,如config.WriteTo(w io.Writer)而不是config.WriteConfigTo(w io.Writer),因为config实例已经提供了上下文。
-
-
- 错误处理(Error Handling):
-
函数或方法如果可能失败,应将
error类型作为其最后一个返回值。 -
调用者负责显式检查返回的
error是否为nil。 -
使用
fmt.Errorf的%w动词来包装错误,保留上下文。 -
使用
errors.Is和errors.As来检查和解构错误链。
-
- Context 的使用:
- 如果函数需要支持取消、超时或传递请求范围的值,应接受
context.Context作为其第一个参数,通常命名为ctx。
- 如果函数需要支持取消、超时或传递请求范围的值,应接受
- 函数 vs. 方法的选择(回顾 第7讲):
-
方法是将接收者作为首参的函数。
-
Go倾向于优先考虑无状态的函数。
-
如果操作与特定类型的状态紧密相关(需要读取或修改类型的字段),应定义为该类型的方法。
-
- 参数与返回值的惯例:
-
参数顺序:
-
context.Context总是在第一个。 -
重要的、必须的参数在前;可选的、配置类的参数在后(可考虑选项模式)。
-
目标(destination)通常在源(source)之前,如
io.Copy(dst Writer, src Reader)。
-
-
参数数量:不宜过多。对于不定数量的同类型参数,如果调用时更倾向于直接列举(如
sum(1, 2, 3)),使用可变参数(nums ...int)比直接使用切片类型参数(nums []int)API更友好。 -
返回值列表:不宜过长。两个返回值(一个有效载荷,一个error)很常见。三个返回值(比如
value, ok, error或quotient, remainder, error)也还可以接受,但再多就是极限了,可能需要考虑返回一个结构体。 -
具名 vs 非具名返回值:如果使用具名返回值能显著提高函数/方法的可读性(例如,当有多个同类型的返回值,或者想在
defer中修改返回值时),那么就使用它。否则,为了简洁,通常使用非具名返回值,避免滥用裸return导致的含义模糊。 -
接受接口返回具体类型(通常是指针):这是一个常见的Go API设计建议。函数参数尽可能使用接口类型,以增加灵活性和可测试性。而返回值,如果是一个你定义的具体类型(尤其是结构体),通常返回其指针
*MyType,除非它是小型且不可变的。 -
切片参数的修改:如果函数对传入的切片做了
append操作(可能导致底层数组重新分配),务必将操作后的新切片作为返回值返回,调用者必须接收这个返回值。
-
func appendToSlice(s []int, elems ...int) []int {
return append(s, elems...)
}
// 调用者: mySlice = appendToSlice(mySlice, 1, 2)
- 零值可用性(Zero Value Usability):
- 设计的类型(尤其是结构体)应尽可能使其零值(即
var t MyType)是有意义且可以直接使用的,或者至少不会导致panic。例如bytes.Buffer的零值就是一个可用的空缓冲区,这简化了类型的初始化。
- 设计的类型(尤其是结构体)应尽可能使其零值(即
编写符合Go惯例的API,最好的学习方式是多阅读和借鉴标准库及社区中广受好评的优秀第三方库的API设计,它们是“活的”最佳实践。
从Go官方设计的MCP SDK看API设计五要素
理论原则和惯例技巧我们已经讨论了不少,但没有什么比分析一个真实世界、经过深思熟虑的API设计更能加深理解了。Go团队最近参与设计了一个针对模型上下文协议(Model Context Protocol,MCP)的官方Go SDK,其 设计草案(Design #364) 为我们提供了一个绝佳的案例,来观察这些API设计要素是如何在实践中应用的。
MCP是一种用于客户端(如IDE、代码编辑器)和服务器(如语言服务器、AI模型服务)之间交换上下文信息、调用工具、获取资源等的协议。 Go团队的目标是为Go语言创建一个高质量的MCP SDK,作为官方modelcontextprotocol/go-sdk。
我们就从这份设计草案中,挑选一些关键点,看看它们是如何体现我们之前讨论的API设计五大核心要素的。
注:在我写这节课的内容时,该SDK的雏形在 https://github.com/golang/tools/tree/master/internal/mcp可以下载。后续该SDK大概率会正式成为MCP官方go-sdk(https://github.com/modelcontextprotocol/go-sdk)。鉴于篇幅,这里不再贴出该SDK的源码, 你 可以自行下载源码,并结合代码一起理解下面的内容。
易用性的体现
-
清晰的命名与职责划分:SDK将核心API组织在单一的
mcp包中(如mcp.Client、mcp.Server、mcp.Stream),这与Go标准库(如net/http、net/rpc)的风格一致,有助于用户快速定位核心功能。同时,将非直接相关的部分(如JSON Schema实现jsonschema)分离到独立的包中,保持了核心包的专注。 核心类型如Client、Server、ClientSession、ServerSession以及方法如Connect、CallTool、ListRoots等,名称都相对直观,能较好地表达其用途。 -
合理的参数设计与选项模式:
-
Context首参数:所有涉及I/O或可能阻塞的操作(如
Connect、CallTool、Read、Write)都接受context.Context作为第一个参数,这是Go并发API的标准实践,便于调用者控制超时和取消。 -
参数结构体:对于复杂的RPC方法(如
ListTools),其参数被封装在XXXParams结构体中(如*ListToolsParams),而不是罗列大量参数,这使得API更整洁,也便于未来扩展参数而保持向后兼容。 -
选项结构体:
NewClient和NewServer函数接受一个可选的*ClientOptions或*ServerOptions结构体参数,用于配置客户端或服务器的行为(如KeepAlive时长、各种处理器)。这里没有使用可变参数函数选项模式,主要是因为客户端与服务端行为参数比较少,大多为必需参数,且参数项多有合理的零值/默认值。
-
-
简化常见操作:提供了如
Server.Run(context.Context, Transport)这样的便捷方法,来处理运行一个会话直到客户端断开的常见场景,简化了用户的代码。 -
迭代器方法:对于List系列的RPC方法,除了返回完整列表的方法外,SDK还提供了返回迭代器的方法(如
(*ClientSession) Tools(...) iter.Seq2[Tool, error]),使用Go 1.23+的iter.Seq2类型。这简化了客户端处理分页逻辑,提供了更符合Go惯例的迭代体验。
安全性的体现
-
错误处理:所有可能失败的操作都返回
error作为最后一个参数,符合Go的错误处理惯例。协议层面的错误(如JSON-RPC错误)被包装成Go的error类型(如JSONRPCError),使得调用者可以统一处理。 -
资源管理:
Stream接口定义了Close() error方法,明确了连接资源需要被关闭。SSEHTTPHandler和StreamableHTTPHandler也提供了Close()方法来停止接受新会话并关闭活动会话。 -
明确的并发模型考量(虽然未详述):文档中提到
Client和Server可以处理多个连接/会话,这暗示了其内部实现需要考虑并发安全。虽然具体同步机制未在API层面暴露,但这是SDK实现者必须考虑的核心安全问题。 -
输入校验(通过JSON Schema):工具(Tool)的输入参数可以通过JSON Schema进行校验,这为API的健壮性提供了一层保障。SDK通过反射从Go类型生成初始Schema,并允许用户自定义,这是一个在灵活性和安全性之间取得平衡的设计。
兼容性的体现
-
最小化API:设计文档多次强调保持API最小化,以允许未来规范演进,并尽可能避免不兼容的SDK API变更。
-
参数使用指针:RPC方法的参数(
XXXParams)和结果(XXXResult)通常使用指针类型。这样做的好处是,如果未来MCP规范在这些结构体中添加了新的可选字段,现有客户端代码传递nil(对于Params)或不处理新字段(对于Result)通常仍能保持向后兼容。
高效性的体现
-
json.RawMessage的使用:对于用户提供的业务数据(如Tool的参数和结果的Content字段),SDK使用json.RawMessage类型。这意味着SDK本身不对这些业务数据进行完全的解析和序列化,而是将其作为原始的JSON字节流传递,将编解码的责任和开销留给客户端和服务器的业务逻辑。这避免了SDK层面不必要的多次编解码,提升了效率。 -
底层Transport抽象:
Transport和Stream接口设计得相对底层,只关注建立连接和读写原始JSON-RPC消息。这使得实现自定义Transport更容易,也为不同Transport的性能优化提供了空间。
惯例性的体现
-
遵循标准库风格:将核心API组织在单一包 (
mcp),使用context.Context作为首参数返回error,这些都与net/http、net/rpc和database/sql等标准库的风格保持一致。 -
接口设计:
Transport和Stream接口的设计(如Connect、Read、Write、Close)体现了Go对小接口和行为抽象的偏好。Stream接口也符合io.Closer惯例。 -
迭代器:使用Go 1.23+ 的
iter.Seq和iter.Seq2作为迭代器方法的返回类型,这是最新的Go惯例。 -
错误处理:使用
ctx.Err()来获取由context取消导致的错误。 -
中间件模式:虽然文档中提到对于认证或context注入等低层请求处理,推荐使用标准的HTTP中间件模式,对于MCP协议层面的中间件,也提供了
Server.AddDispatchers这种类似中间件链的机制。
Go团队设计的这份MCP SDK草案,在很多方面都体现了良好的API设计原则。当然,任何API设计都是权衡的艺术。例如,为了保持API最小化和灵活性,它将JSON-RPC的实现细节隐藏起来,并大量使用 interface{}(通过 any 或 json.RawMessage)来处理动态数据,这可能会在某些时候牺牲一点编译期类型安全或需要用户进行类型断言。但总体而言,这份设计稿为我们提供了一个学习和借鉴如何在Go中设计复杂但清晰、健壮的SDK API的优秀范例。
小结
设计一个用户喜爱且长期可靠的Go包API,是一项极具挑战但也回报丰厚的任务。这节课,我们从Go包API的构成出发,深入探讨了设计优秀API的五大核心要素,并通过分析Go官方设计的MCP SDK案例,将这些原则落到了实处。
-
API的构成与双重契约:我们明确了Go包的API不仅包括显式导出的标识符(函数、类型、常量、变量及其方法和字段),更要警惕海勒姆定律所揭示的隐性契约——即API所有可观察的行为都可能被用户依赖。这要求我们在设计和变更API时必须极其谨慎。
-
易用性:强调简单、清晰、一致的原则。通过精准的命名、合理的参数设计(如选项模式),以及详尽的文档和示例,降低用户的学习和使用成本。MCP SDK通过其清晰的类型和方法命名、参数结构体以及对
context的标准使用体现了这一点。 -
安全性:遵循最小权限,做好输入校验,明确API的并发安全承诺,并提供清晰的资源管理机制,构建可信赖的接口。MCP SDK通过错误处理惯例、资源关闭接口以及对校验(JSON Schema)的考量来保障安全性。
-
兼容性:核心是尊重用户的既有代码。严格遵循向后兼容原则(同时考虑显性和隐性契约),善用语义版本控制 (SemVer),并在设计时预留扩展性。MCP SDK在设计时就考虑了未来规范的演进,并通过最小化API和使用指针参数等方式来提升未来兼容性。
-
高效性:关注API的性能表现,避免不必要的内存分配和资源消耗,并在必要时通过文档指导用户进行性能优化。MCP SDK中使用
json.RawMessage处理业务数据、提供底层Transport抽象等设计都体现了对效率的追求。 -
惯例性:编写具有 “Go味道” 的API,遵循社区的命名、错误处理、参数设计等惯例,使API对Go开发者更加自然和友好。MCP SDK在整体风格、接口设计、错误处理和迭代器使用上都力求与Go标准库和社区最佳实践保持一致。
-
案例的启示:通过分析MCP SDK的设计,我们更具体地看到了这些抽象原则是如何在真实的、由经验丰富的团队设计的API中得到体现和权衡的。它告诉我们,好的API设计需要在规范的完整性、语言的惯用性、系统的健壮性、未来的适应性以及必要的扩展性之间找到精妙的平衡点。
最终,设计API是一场持续的、与用户的“对话”。它要求我们不仅要有扎实的技术功底,更要有同理心,时刻站在用户的角度思考。通过不断实践这些原则,审慎地做出每一个设计决策,并勇于从反馈中学习和迭代,我们才能逐步打造出真正优秀的Go包API,为Go生态的繁荣贡献力量。
思考题
标准库 net/http 包中, http.ListenAndServe(addr string, handler http.Handler) 函数是一个非常常用的API。请你思考以下2个问题:
-
这个API在易用性、安全性和惯例性方面有哪些做得好的地方?
-
它在设计上(特别是参数类型
handler http.Handler)是如何体现Go接口设计和依赖倒置原则的?这带来了什么好处?
欢迎在评论区分享你的分析!我是Tony Bai,我们下节课将开启设计篇的实战串讲。
实战串讲(设计篇):设计高内聚低耦合的“短链接服务” (上)
你好,我是Tony Bai!欢迎来到我们设计先行模块的第一次实战串讲。
在前面的几节课(第14~19节)中,我们系统地学习了Go项目的设计原则,涵盖了项目布局、包设计、并发模型选择、接口设计、错误处理策略以及Go包API设计规范。理论知识我们已经掌握了不少,但设计能力的提升,最终还是要落到实践中去。
很多时候,我们拿到一个需求,最容易产生的冲动就是“撸起袖子就是干”,直接开始编写代码。但没有经过深思熟虑的设计,往往会导致项目后期举步维艰:代码耦合严重、难以测试、不易扩展、维护成本高昂,甚至需要推倒重来。
接下来的两节课,我们将通过一个具体的案例——“短链接服务”,来完整地走一遍设计的流程。目的不是要实现一个功能完备、性能极致的系统,而是要 演示如何将前面学到的设计原则应用到实际问题中,让你看到理论是如何指导实践的,并体会设计决策背后的思考过程。
在这节课中,我们将重点关注:
-
需求解读:明确我们要构建什么。
-
架构草图与分层思想:勾勒系统的核心组件。
-
核心功能模块的识别与初步职责定义:从需求和架构出发,识别出关键的逻辑单元并初步映射到包。
-
项目结构规划(第一版):将逻辑模块映射到初步的物理目录划分。
-
核心包的具体实现与接口的“发现”:实践高内聚、低耦合原则,并演示接口是如何从具体需求中“自然涌现”的,同时展示引入接口后的结构演变。
通过这节课,你将看到一个简单的想法是如何逐步转化为一个结构清晰、职责分明的设计蓝图的。
需求解读与技术选型考量
任何软件设计的起点都是理解并明确需求。只有搞清楚了我们要解决什么问题,为谁解决,才能为后续的架构和技术选型奠定坚实的基础。
我们的目标是设计一个 “短链接服务”(Short Link Service)。它的核心功能很简单,首先是生成短链接(Create Short Link):接收一个原始的长 URL,生成一个唯一的、较短的标识码(比如 aBcDeF),并将长 URL 与短码的映射关系存储起来。返回生成的短码。然后是获取长链接(Get Long URL):接收一个短码,查找对应的原始长 URL并返回。
为了让设计更完整一些,我们再考虑一个常见的扩展需求,也就是点击统计(Analytics - 轻量):记录每个短链接被访问的次数(我们暂时不设计复杂的统计后台,只考虑记录次数)。
非功能性需求(简单考虑):
-
性能:短链接的查找(
GetLongURL)需要非常快。 -
可扩展性:系统未来可能需要支持更多的链接,存储和处理能力需要能水平扩展(设计阶段重点是逻辑结构)。
-
可靠性:服务需要稳定可靠。
技术选型(初步设想,聚焦内部逻辑):
- 短码生成:
-
初步想法:我们可以先尝试一种简单的策略,比如对长URL进行哈希,然后截取一部分作为短码。
-
未来考量:这种简单哈希可能会有冲突,也可能不够“短”或不够“友好”。未来我们可能需要更复杂的策略,如自增ID转特定进制、专门的发号器服务,或者需要处理自定义短码的需求。这种“未来可能变化”的意识是关键。
-
- 数据存储:
-
初步想法:为了快速原型开发和测试,我们可以先考虑将短链接映射关系存储在内存中。
-
未来考量:内存存储在服务重启后会丢失数据,不适用于生产。生产环境通常需要持久化存储,如关系型数据库(MySQL、PostgreSQL)、NoSQL数据库(Redis、Cassandra)或分布式键值存储。我们还需要考虑数据备份、扩展性和查询性能。这里也存在“未来可能替换或有多种实现”的情况。
-
- 对外暴露的核心能力:根据我们定义的核心功能,这个“短链接服务”至少需要对外提供以下几种核心能力,以便用户或其他系统能够与之交互:
-
创建短链接的能力:用户需要一种方式提交一个长URL,并获取到一个对应的短码。
-
通过短码访问长链接的能力:用户或其浏览器需要能通过短码请求服务,并被引导(通常是重定向)到原始的长URL。
-
(可选)获取短链接统计信息的能力:如果我们实现了点击统计,可能还需要一种方式(也许是内部或管理员接口)来查询某个短链接的访问次数。
-
这些能力是服务必须提供的功能性入口点。至于这些入口点最终是以HTTP API的形式(比如 POST /links 和 GET /{short_code})、gRPC服务接口,还是作为一个Go库直接被其他Go程序调用的函数/方法来实现,这是我们后续在详细设计API和传输层时需要具体化的技术决策。 在当前需求分析阶段,我们重点是识别出这些必须对外提供的核心服务能力。
明确了需求和初步的技术方向后,我们需要从一个更高的视角来审视整个系统,勾勒出它的核心组成部分以及它们之间大致的协作关系。这就是架构设计的初步草图,它能帮助我们建立对系统全局的认知。
架构草图与分层思想
根据需求,我们可以初步勾勒出系统的核心逻辑分层和它们之间的交互关系:
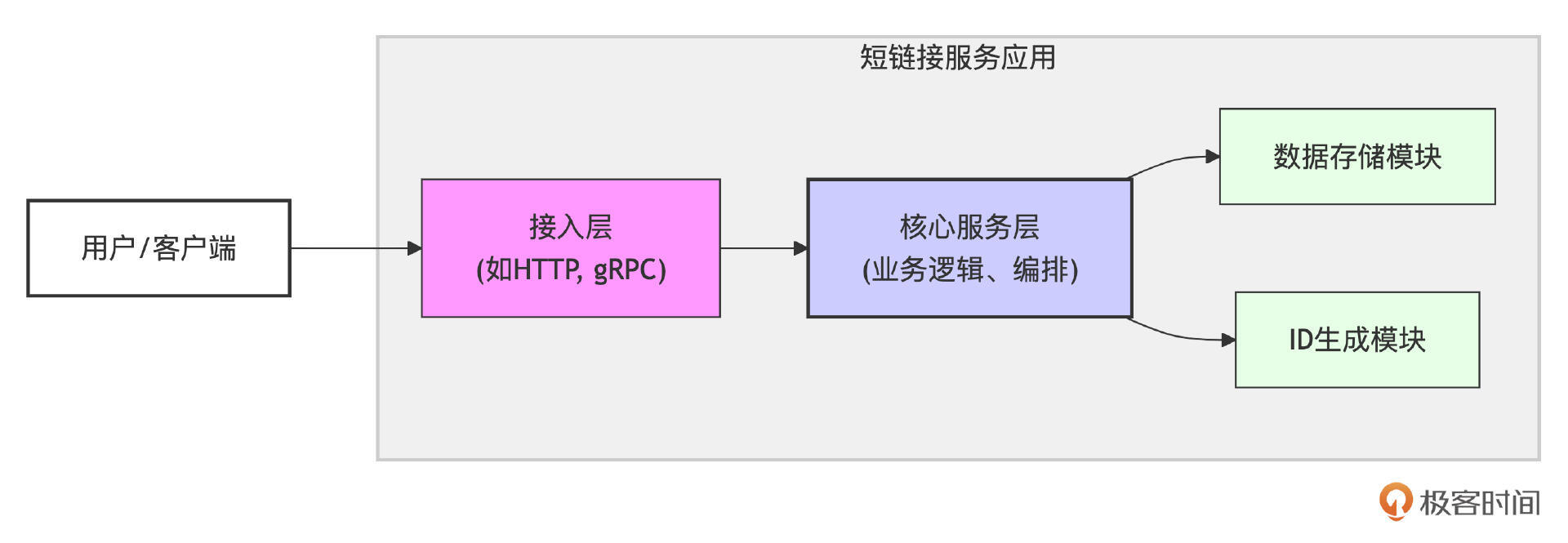
如图所示,整个“短链接服务应用”分为4个核心模块。
-
接入层:负责处理具体的协议(如HTTP)和外部世界的通信。
-
核心服务层(核心业务逻辑):封装了短链接服务的核心业务规则。
-
数据存储模块:负责短链接映射和统计数据的持久化。
-
ID生成模块:负责生成唯一的短码。
这种分层结构使得每一层都可以专注于自己的核心职责。有了高层的架构设想,接下来就需要将这些抽象的“层”和“模块”具体化。首先,我们要识别出构成“短链接服务”应用核心的关键功能单元,并初步为它们划定职责范围,这直接关系到后续代码的组织和包的设计。
核心功能模块识别与初步的包设计考量
在明确了高层架构和分层思想后,我们可以进一步识别出实现“短链接服务”所需的核心功能模块,并为它们初步定义职责。 这个阶段,我们不仅在逻辑层面思考,也开始将这些逻辑单元初步映射到Go的包(package)结构上,思考如何组织这些包以实现高内聚。
-
短码生成模块 ->
idgen包:a. 核心职责:负责根据输入(如长URL),生成一个符合要求的、唯一的短码。所有与短码生成算法、策略、唯一性保证相关的逻辑都应内聚在此。
b. 初步包考量:我们可以创建一个
idgen包来封装所有ID生成相关的逻辑。初期,这个包内将直接包含我们选择的第一种具体实现(例如,基于简单哈希的生成器)。将所有ID生成相关的代码放在一个包内,符合高内聚原则。 -
数据存储模块 ->
storage包:a. 核心职责:持久化短码与长URL的映射关系,以及相关的元数据(如访问计数、创建时间)。提供统一的数据保存、查找和更新接口。所有与数据存取、数据库交互(或内存模拟)相关的逻辑都应内聚在此。
b. 初步包考量:创建一个
storage包来封装所有数据持久化逻辑。初期,这个包内将直接包含我们选择的第一个具体实现(例如,基于内存的存储),将所有存储相关代码放在一起,职责清晰。 -
业务编排服务模块 ->
shortener包:a. 核心职责:作为核心业务逻辑的封装者和协调者。它将使用
idgen包的功能来创建短码,并使用storage包的功能来保存和检索链接信息。它还负责处理核心业务规则,如输入校验、冲突处理逻辑(如果ID生成与存储有冲突)、访问统计的触发等。b. 初步包考量:创建一个
shortener包,它是连接其他底层模块(如idgen、storage)并实现核心业务流程的地方。这个包的内聚性体现在它专注于“短链接服务”本身的核心业务,而不关心ID具体怎么生成、数据具体怎么存储。 -
配置管理模块 ->
config包:a. 核心职责:负责加载和管理应用程序的配置信息(如服务器端口、日志级别、数据库连接字符串等)。
b. 初步包考量:这是一个相对独立且通用的功能,适合放在一个专门的
config包中。 -
外部交互模块 ->
api包:a. 核心职责:处理与外部世界的交互,如接收HTTP请求、解析参数、调用业务编排服务、返回响应。
b. 初步包考量:我们将创建一个
api包,并在其下根据具体协议创建子包,如api/http。它将依赖shortener包。此外,万一未来真的需要支持gRPC或其他某种IPC机制,有一个api目录作为统一的入口点,组织结构会更清晰。例如,可以添加 api/grpc。
通过这样的初步识别和包设计考量,我们已经有了一组逻辑上相对独立且职责明确的候选包。 这些包的划分遵循了高内聚的原则——每个包都聚焦于一个特定的功能领域。
将逻辑模块映射到具体的Go包之后,我们还需要为这些包在文件系统中找到一个合适的“家”。这就是项目结构规划的任务,它要确保我们的代码库既符合Go的组织习惯,又能清晰地反映我们对模块和职责的划分。
项目结构规划(第一版——映射已识别的包)
基于上述识别出的核心功能模块及其对应的包,并结合我们在第14节学习到的项目布局知识,可以规划出项目的第一版项目目录结构如下:
demo1/shortlink/
├── go.mod # Go 模块文件
├── internal/ # 内部代码,项目核心逻辑所在地
│ ├── api/
│ │ └── http/
│ │ ├── handler/
│ │ │ └── handler.go
│ │ └── server/
│ │ └── server.go
│ ├── config/ # 配置管理包
│ │ └── config.go
│ ├── idgen/ # 短码生成包 (初期直接包含简单哈希实现)
│ │ └── simple_hash_generator.go
│ ├── shortener/ # 业务编排服务包
│ │ └── service.go
│ └── storage/ # 数据存储包 (初期直接包含内存实现)
│ └── memory_store.go
└── main.go # 应用主入口
设计决策说明:
-
main.go:放在根目录,作为应用的启动入口,负责初始化依赖并将它们组装起来。此外由于短链接服务就一个可执行程序,我们没有必要建立一个cmd/目录。 -
/internal/:所有核心的功能包都放在这里,因为它们是特定于这个短链接服务的。-
config/: 实现配置加载逻辑。 -
shortener/:这是我们的核心业务逻辑层。service.go将定义Service类型,它会直接依赖于我们接下来要具体实现的idgen/simplehash和storage/memory包中的类型。 -
storage/:这是“数据存储模块”的统一入口包。初期,我们将在storage/memory_store.go文件中直接定义和实现基于内存的存储逻辑,例如memory.Store类型及其方法。此时,storage包本身就提供了第一个具体的存储实现。 -
idgen/:这是“短码生成模块”的统一入口包。初期,我们将在idgen/simple_hash_generator.go文件中直接定义和实现基于简单哈希的ID生成器逻辑,例如idgen.Generator类型及其方法。idgen包本身就提供了第一个具体的生成器实现。 -
api/http/:实现HTTP API的Server和Handler,它将依赖shortener.Service。
-
这个结构将我们识别出的逻辑模块映射到了具体的包路径。 storage 和 idgen 包内部直接包含了它们的第一个具体实现。
项目结构和初步的包划分已经完成,现在是时候深入到每个核心包内部,开始编写具体的实现代码了。正是在这个从抽象到具体,再从具体反思抽象的过程中,接口的真正价值和必要性才会逐渐显现出来。
核心包的具体实现与接口的“发现”
现在,我们开始在规划好的包目录下编写核心功能模块的具体实现。在这个过程中,我们将分析它们之间的依赖关系,并根据可替换性、可测试性和关注点分离等原则,自然地“发现”并提取出接口。
首先是 idgen 包——短码生成机制(具体实现)。
-
职责:负责生成唯一的短码,使用一种简单的哈希策略。
-
内聚性:包内所有代码都围绕“简单哈希生成短码”这一核心功能。
-
对外API(初期):
idgen.NewGenerator()构造函数和(*Generator) GenerateShortCode(...)方法。
// ch20/demo1/shortlink/internal/idgen/simple_hash_generator.go
... ...
const defaultCodeLength = 7
type Generator struct {
}
func NewGenerator() *Generator {
rand.Seed(time.Now().UnixNano())
return &Generator{}
}
func (g *Generator) GenerateShortCode(ctx context.Context, longURL string) (string, error) {
if longURL == "" {
return "", errors.New("idgen: longURL cannot be empty for code generation")
}
hasher := sha256.New()
hasher.Write([]byte(longURL))
hasher.Write([]byte(time.Now().Format(time.RFC3339Nano)))
hasher.Write([]byte(fmt.Sprintf("%d", rand.Int63())))
hashBytes := hasher.Sum(nil)
encoded := base64.URLEncoding.EncodeToString(hashBytes)
if len(encoded) < defaultCodeLength {
return encoded, nil
}
return encoded[:defaultCodeLength], nil
}
然后是 storage 包——数据持久化机制(具体实现)。
-
职责:负责短链接映射和访问计数的持久化。
-
内聚性:所有代码都围绕“内存存储短链接数据”这一功能。
-
对外API(初期):
storage.NewStore()构造函数和(*Store) Save(...)、(*Store) FindByShortCode(...)、(*Store) IncrementVisitCount(...)等方法。Link类型暂时也定义在此包内。
// ch20/demo1/shortlink/internal/storage/memory_store.go
package storage
import (
"context"
"errors"
"sync"
"time"
)
type Link struct {
ShortCode string
LongURL string
VisitCount int64
CreatedAt time.Time
}
var ErrNotFound = errors.New("storage: link not found")
var ErrShortCodeExists = errors.New("storage: short code already exists")
// 初期,这个 Store 就是我们的内存存储具体实现
type Store struct {
mu sync.RWMutex
links map[string]Link
}
func NewStore() *Store { // 构造函数返回具体类型
return &Store{links: make(map[string]Link)}
}
func (s *Store) Save(ctx context.Context, link Link) error { /* ... */ return nil }
func (s *Store) FindByShortCode(ctx context.Context, shortCode string) (*Link, error) { /* ... */ return nil, nil }
func (s *Store) IncrementVisitCount(ctx context.Context, shortCode string) error { /* ... */ return nil }
func (s *Store) Close() error { return nil }
思考点: Link 类型现在是 storage 包的。如果 shortener.Service 要操作 Link,就需要导入 storage 包并使用 storage.Link。这会产生一个从业务核心到具体存储实现的依赖,不太理想。这是后续接口抽象要解决的问题之一。
接着来看 shortener 包——核心业务逻辑(Service层,依赖具体实现)。
-
职责:实现创建短链接、获取长链接等核心业务流程,编排对
idgen.Generator和storage.Store的调用。 -
内聚性:聚焦核心短链接业务逻辑。
-
对外API(初期):
shortener.NewService(...)构造函数和(*Service) CreateShortLink(...)、(*Service) GetAndTrackLongURL(...)方法。 -
SOLID原则初步体现:
-
SRP(单一职责):
shortener包专注于业务编排,将ID生成和存储的具体实现委托给其他包。 -
DIP(依赖倒置原则)——尚未完全体现:目前
shortener.Service直接依赖具体实现类型*idgen.Generator和*storage.Store。这在初期可以接受,但不利于扩展和测试。我们将在下一阶段通过引入接口来改进这一点。
-
// ch20/demo1/shortlink/internal/shortener/service.go
... ...
// Config for Service, allowing dependencies to be passed in.
type Config struct {
Store *storage.Store // Concrete type for demo1
Generator *idgen.Generator // Concrete type for demo1
MaxGenAttempts int
}
type Service struct {
store *storage.Store
generator *idgen.Generator
maxGenAttempts int
}
func NewService(cfg Config) *Service { // Removed error return for simplicity in demo1 main
if cfg.Store == nil || cfg.Generator == nil {
log.Fatalln("Store and Generator must not be nil for Shortener Service")
}
if cfg.MaxGenAttempts <= 0 {
cfg.MaxGenAttempts = 3
}
return &Service{
store: cfg.Store,
generator: cfg.Generator,
maxGenAttempts: cfg.MaxGenAttempts,
}
}
func (s *Service) CreateShortLink(ctx context.Context, longURL string) (string, error) {
if longURL == "" {
return "", fmt.Errorf("%w: longURL cannot be empty", ErrInvalidInput)
}
var shortCode string
for attempt := 0; attempt < s.maxGenAttempts; attempt++ {
log.Printf("DEBUG: Attempting to generate short code, attempt %d, longURL: %s\n", attempt+1, longURL)
code, genErr := s.generator.GenerateShortCode(ctx, longURL)
if genErr != nil {
return "", fmt.Errorf("attempt %d: failed to generate short code: %w", attempt+1, genErr)
}
shortCode = code
linkToSave := storage.Link{
ShortCode: shortCode,
LongURL: longURL,
CreatedAt: time.Now().UTC(),
}
saveErr := s.store.Save(ctx, linkToSave)
if saveErr == nil {
log.Printf("INFO: Successfully created short link. ShortCode: %s, LongURL: %s\n", shortCode, longURL)
return shortCode, nil
}
if errors.Is(saveErr, storage.ErrShortCodeExists) && attempt < s.maxGenAttempts-1 {
log.Printf("WARN: Short code collision, retrying. Code: %s, Attempt: %d\n", shortCode, attempt+1)
continue
}
log.Printf("ERROR: Failed to save link. LongURL: %s, ShortCode: %s, Attempt: %d, Error: %v\n", longURL, shortCode, attempt+1, saveErr)
return "", fmt.Errorf("%w: after %d attempts for input %s: %w", ErrConflict, attempt+1, longURL, saveErr)
}
return "", ErrServiceInternal
}
func (s *Service) GetAndTrackLongURL(ctx context.Context, shortCode string) (string, error) {
if shortCode == "" {
return "", fmt.Errorf("%w: short code cannot be empty", ErrInvalidInput)
}
link, findErr := s.store.FindByShortCode(ctx, shortCode)
if findErr != nil {
if errors.Is(findErr, storage.ErrNotFound) {
log.Printf("WARN: Short code not found. ShortCode: %s\n", shortCode)
return "", fmt.Errorf("short link for code '%s' not found: %w", shortCode, findErr)
}
log.Printf("ERROR: Failed to find link by short code. ShortCode: %s, Error: %v\n", shortCode, findErr)
return "", fmt.Errorf("failed to find link for code '%s': %w", shortCode, findErr)
}
go func(sc string, currentCount int64) {
bgCtx := context.Background()
if err := s.store.IncrementVisitCount(bgCtx, sc); err != nil {
log.Printf("ERROR: Failed to increment visit count (async). ShortCode: %s, Error: %v\n", sc, err)
} else {
log.Printf("DEBUG: Incremented visit count (async). ShortCode: %s, NewCount: %d\n", sc, currentCount+1)
}
}(shortCode, link.VisitCount)
log.Printf("INFO: Redirecting to long URL. ShortCode: %s, LongURL: %s\n", shortCode, link.LongURL)
return link.LongURL, nil
}
internal/api/http下的server和handler则是常规的http server(封装路由)以及请求的处理器,这里就不贴代码了。最后补充一下main.go对各个包和服务的组装环节:
// ch20/demo1/shortlink/main.go
package main
import (
"context"
"errors"
"log"
"net/http"
"os"
"os/signal"
"syscall"
"time"
"github.com/your_org/shortlink/internal/api/http/server"
"github.com/your_org/shortlink/internal/config"
"github.com/your_org/shortlink/internal/idgen"
"github.com/your_org/shortlink/internal/shortener"
"github.com/your_org/shortlink/internal/storage"
)
func main() {
// 1. 简化配置处理 (硬编码)
c, _ := config.LoadConfig()
// 2. 使用标准库 log
log.SetFlags(log.LstdFlags | log.Lshortfile)
log.Println("Starting shortlink service", "version", "shortlink-demo1")
// 3. 初始化依赖 (具体类型)
storeImpl := storage.NewStore()
defer func() {
if err := storeImpl.Close(); err != nil {
log.Printf("Error closing store: %v\n", err)
}
}()
idGenImpl := idgen.NewGenerator()
// 假设 NewService 接受具体类型,并且可能返回错误(如果依赖为nil)
// shortenerService, err := shortener.NewService(storeImpl, idGenImpl) // 如果 NewService 返回 error
shortenerService := shortener.NewService(shortener.Config{
Store: storeImpl,
Generator: idGenImpl,
MaxGenAttempts: 3}) // 使用Config结构
if shortenerService == nil {
log.Fatalln("Failed to create shortener service due to nil dependencies")
}
// 4. 创建并启动 HTTP 服务器 (由 api/http/server.go 负责)
httpServer := server.New(c.Server.Port, shortenerService) // 将 service 注入
go func() {
log.Printf("HTTP server starting on :%s\n", c.Server.Port)
if err := httpServer.Start(); err != nil && !errors.Is(err, http.ErrServerClosed) {
log.Fatalf("HTTP server ListenAndServe error: %v\n", err)
}
}()
// 5. 优雅退出
... ...
}
第一版设计后的包依赖层次图(依赖具体实现):
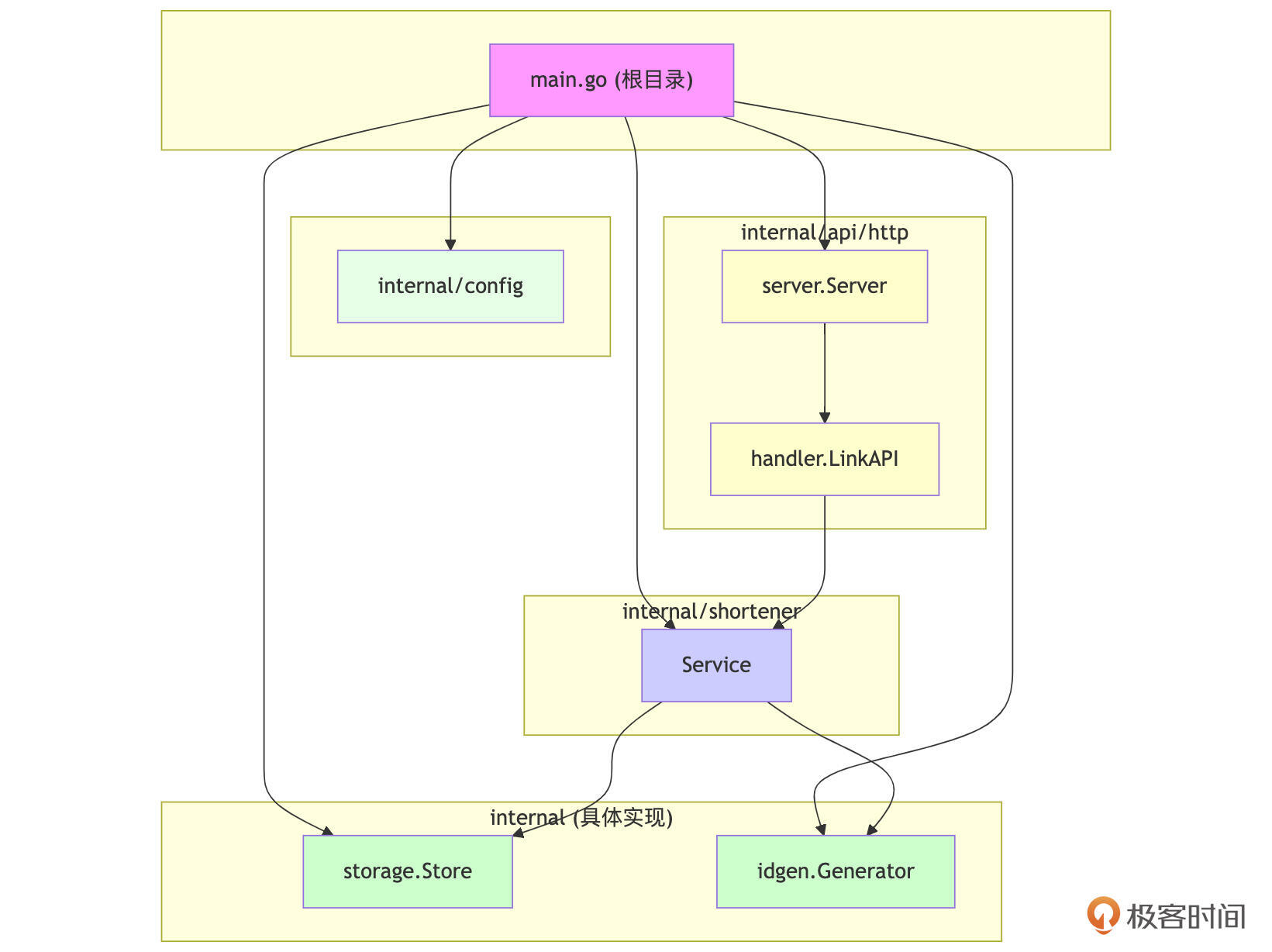
从图中我们看到:
-
main.go:作为应用的入口,负责创建和组装所有核心组件。它直接创建了config、shortener.Service(并将具体的storage.Store和idgen.Generator实例注入其中),以及api/http/server.Server的实例。 -
api/http/server.Server:负责HTTP服务器的启动和路由注册。它会创建一个api/http/handler.LinkAPI的实例。 -
api/http/handler.LinkAPI:包含具体的HTTP请求处理逻辑。它依赖于shortener.Service来执行业务操作。 -
shortener.Service:核心业务逻辑层。在第一版设计中,它直接依赖于internal/storage.Store(此时是内存存储的具体类型)和internal/idgen.Generator(此时是简单哈希生成的具体类型)。 -
internal/storage.Store和internal/idgen.Generator:在此版本中,它们是各自功能域下的具体实现类型。
这个阶段,我们的设计优先考虑了功能的快速实现,包之间的依赖是具体的。 这为我们接下来的“发现”接口过程奠定了基础。更多关于第一版的代码,请访问本专栏代码仓库并下载查看。
至此,我们的 shortener.Service 直接依赖了 storage.Store 和 idgen.Generator 的具体实现。这在项目初期为了快速验证功能是可行的。但随着思考的深入,我们会发现几个关键问题(正如我们第17讲讨论接口设计时提到的),这些问题将自然地引导我们“发现”接口的必要性。
首先是可替换性与扩展性。
我们的“技术选型考量”中已经预见到, simplehash 可能不是最终的ID生成方案, memory.Store 也肯定不是生产环境的存储方案。如果未来我们要引入基于数据库的存储( PostgresStore),或者一种基于雪花算法的ID生成器( SnowflakeGenerator),那么 shortener.Service 将被迫修改其字段类型( store、 generator)和构造函数 NewService 的参数类型。每次增加新的实现或替换旧的实现,都需要改动核心业务逻辑代码,这显然违反了开放-关闭原则。我们希望 shortener.Service 的核心逻辑能够稳定,不随具体依赖的实现变化而变化。
其次是关注点分离与依赖倒置。
shortener.Service 的核心职责是编排业务流程。它不应该强耦合于ID是如何生成的(哈希还是发号器?),或者数据是存在内存里还是数据库里。 它应该只关心它所依赖的组件能提供哪些行为契约。例如,它需要一个“能生成短码的东西”和一个“能保存和查找链接的东西”。这种对“东西”能力的抽象,正是接口的用武之地,也是依赖倒置原则的体现——高层模块(shortener.Service)不应依赖底层模块(具体实现),两者都应依赖抽象(接口)。
最后是可测试性(作为上述好处的自然结果)。
一旦 shortener.Service 依赖于抽象接口,而不是具体实现,那么在对 shortener.Service 进行单元测试时,我们就可以轻松地传入这些接口的测试替身(Test Doubles),如Fake objects或Mocks。这样就能隔离测试 Service 本身的业务逻辑,而不受真实存储或ID生成器的复杂性和不确定性(如网络、磁盘I/O、随机性)的影响。
基于这些更贴近实际设计演进的理由,我们决定引入接口。 shortener.Service 作为消费者,它定义了它对依赖组件的行为期望。
引入接口后的项目结构规划(第二版 - 带接口定义)如下所示。注意,这里只展示结构变化,具体接口定义下一节课会讲。
└── demo2/shortlink/
├── go.mod
├── internal/
│ ├── api/
│ │ └── http/
│ │ ├── handler/
│ │ │ └── handler.go
│ │ └── server/
│ │ └── server.go
│ ├── config/
│ │ └── config.go
│ ├── idgen/
│ │ ├── interface.go # <--- 新增接口定义文件
│ │ └── simplehash/ # 基于简单哈希的具体实现
│ │ └── generator.go
│ ├── shortener/
│ │ └── service.go
│ └── storage/
│ ├── interface.go # <--- 新增接口定义文件
│ └── memory/ # 内存存储的具体实现
│ └── memory.go
└── main.go
我们为 storage 和 idgen 包分别增加了 interface.go 文件,用于定义它们对外暴露的抽象接口。 storage.Link 结构体现在也定义在 storage/interface.go 中,作为接口契约的一部分。具体的实现包(如 memory 和 simplehash)将去实现这些接口,并使用通用的 storage.Link。
引入接口后的包依赖层次图如下(概念性):
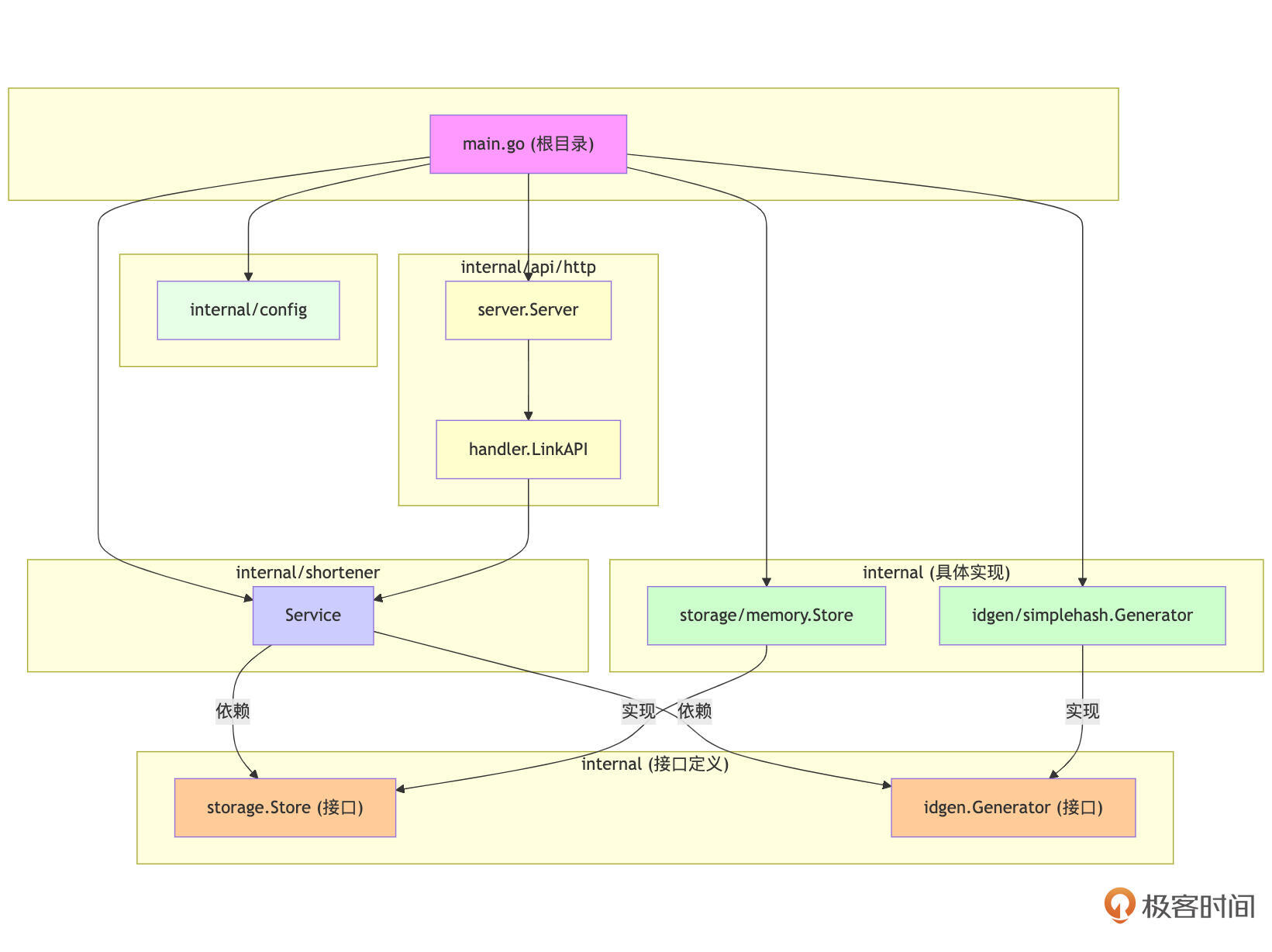
在第二版设计中, main 仍然负责创建具体实现,但现在它将这些实现(它们满足接口)注入到 shortener.Service。 Service 层现在依赖于 storage.Store 和 idgen.Generator 接口(暂定的接口名),实现了与具体实现的解耦。
通过这个演化过程可以知道,我们不是一开始就“发明”接口,而是在编写了具体实现并分析其局限性后,从消费者的需求( shortener.Service 的需求)出发,“发现”并提取出了必要的接口抽象。这种方式创建的接口通常更实用、更聚焦,也更符合Go语言的设计哲学。具体的接口方法签名和更细致的API设计,将是我们下节课的重点。
小结
在这节课中,我们通过“短链接服务”这个具体案例,迈出了从需求到初步设计蓝图的关键一步,重点体验了设计的演进过程。
-
需求解读与技术选型考量:我们明确了服务的核心功能和初步的技术思考方向,并对未来可能的变化点(如短码生成策略、数据存储方式)保持了开放性。
-
架构草图与分层思想:我们勾勒了应用的核心逻辑分层(接入层、核心服务层、数据存储、ID生成),为后续的模块划分和职责定义奠定了基础。
-
核心功能模块识别与包设计考量:我们将逻辑功能映射到初步的Go包(如
shortener、storage、idgen、config、api/http),并强调了在包设计初期就应考虑高内聚原则。 -
项目结构规划(第一版):我们基于识别出的包,规划了第一版的物理目录结构,此时
main.go位于根目录,核心业务逻辑在/internal下,并且shortener.Service直接依赖具体实现的存储和ID生成包。 -
核心包的具体实现与接口的“发现”:我们编写了这些核心包的初步具体实现。然后,通过分析直接依赖具体实现所带来的问题(如可替换性差、可测试性差、违反开放-关闭原则和依赖倒置原则),我们演示了接口是如何从这些实际的设计痛点中“自然涌现”的。最后,我们展示了引入接口定义(在各自功能域的根包下,如
storage/interface.go)后,项目结构和包依赖关系图的演变,实现了核心业务逻辑与具体实现的解耦。
这节课的核心在于理解设计是一个迭代和演进的过程。 我们从具体的需求和初步实现出发,逐步识别出抽象的必要性,让接口成为解决耦合、提升灵活性的自然选择,而不是一开始就进行过度设计。这个过程为我们详细打磨这些Go包API和错误处理策略做了充分的铺垫。
下节课我们将重点详细设计和打磨在本节末尾引入的 storage.Store 和 idgen.Generator 接口,以及 shortener.Service 自身对外暴露的Go API。应用第19讲的Go包API设计五要素,让它们更易用、安全、兼容、高效和符合Go惯例。同时,细化错误处理策略,定义业务错误类型,并规划错误在各层之间的传递与包装,以及简单讨论核心流程中可能涉及的内部并发考量。
这第一部分的实战关键在于体会设计先行的重要性,以及如何将抽象的设计原则应用到具体的项目中,从需求一步步推导出清晰的模块和接口。
思考题
在我们的第一版设计中, shortener.Service 直接依赖了 storage.Store 和 idgen.Generator 的具体类型。在“发现接口的必要性”部分,我们论述了引入接口的好处,如可替换性、可测试性和依赖倒置。
那从团队协作的角度来看,在项目初期(甚至在只有一个具体实现的情况下)就着手定义清晰的接口(比如 storage.Store 和 idgen.Generator 接口),而不是等到多个实现出现时再提取,可能会带来哪些额外的好处或便利?
欢迎在留言区分享你的想法!我是Tony Bai,我们下节课将继续完善“短链接服务”的设计。
实战串讲(设计篇):设计高内聚低耦合的“短链接服务” (下)
你好!我是Tony Bai。
上节课,我们为“短链接服务”这个案例绘制了初步的设计蓝图。我们一起明确了需求,勾勒了分层架构,规划了第一版的项目和包结构(此时依赖具体实现),并通过分析其局限性,“发现”了引入接口抽象的必要性,最终展示了引入接口后的项目结构和依赖关系演变。至此,一个清晰的骨架已经形成。
但仅有骨架和初步的接口定义还不够,我们需要为这个骨架填充更精细的“血肉”,让设计真正能够指导后续的编码实现。一个好的设计不仅要结构清晰,其暴露给调用者的 Go包API 更要精心打磨,确保其易用、安全、健壮。同时,系统内部如何优雅地处理和传递错误,也是决定其可维护性和可靠性的关键。这些正是我们在 第18讲 和 第19讲 中学习的核心内容。
这节课,我们将继续完善“短链接服务”的设计,重点关注:
-
精化核心Go API:应用我们在第19讲学到的Go包API设计五要素(易用性、安全性、兼容性、高效性、惯例性),详细设计和打磨 storage.Store、idgen.Generator 接口,以及 shortener.Service 对外(对模块内其他包,如 api/http)暴露的方法。
-
错误处理设计:根据第18讲的原则,定义业务错误类型,规划错误在 storage -> service -> api/http 层之间的包装与传递策略。
-
并发模型初探:结合 第16讲 的并发设计思想,初步讨论核心流程中可能涉及的入口并发模型、内部协作模式以及goroutine生命周期管理(特别是 context 的使用)。
-
设计蓝图总结:将所有设计决策整合,形成一个更完善、可供后续实现参考的设计方案。
我们的目标是完成整个内部逻辑的详细设计阶段,使其API清晰、错误处理健壮、并发考量周全,为工程实践模块做好充分准备。
精化核心Go API:应用API设计五要素
现在,我们来详细设计和打磨在 第20讲 末尾引入的几个核心Go接口和 shortener.Service 的方法,确保它们符合我们讨论过的API设计“黄金标准”。
storage.Store 接口
这个接口是数据持久化层的契约。
// demo2/shortlink/internal/storage/interface.go
package storage
import (
"context"
"errors"
"time"
)
// Link 是存储在数据库中的短链接信息。
// 它的字段都应可导出,以便 Service 层和可能的其他包使用。
type Link struct {
ShortCode string // 短码,唯一标识
LongURL string // 原始长链接
VisitCount int64 // 访问次数 (注意并发更新问题,Store 实现需处理)
CreatedAt time.Time // 创建时间
// UserID string // (可选扩展) 创建用户ID
// ExpiresAt time.Time // (可选扩展) 过期时间
}
// Store 定义了数据存储层需要提供的核心能力。
// 所有实现都应该是并发安全的。
type Store interface {
// Save 保存一个新的短链接映射。
// 如果 shortCode 已存在,应返回 ErrShortCodeExists。
// 如果 longURL 无效 (例如过长或格式不符),实现可以返回特定错误或依赖上层校验。
Save(ctx context.Context, link Link) error
// FindByShortCode 根据短码查找对应的 Link 信息。
// 如果未找到,必须返回 ErrNotFound。
FindByShortCode(ctx context.Context, shortCode string) (*Link, error)
// IncrementVisitCount 原子地增加指定短码的访问计数。
// 如果 shortCode 不存在,可以返回 ErrNotFound,或者静默失败(取决于业务需求)。
// 此方法必须是并发安全的。
IncrementVisitCount(ctx context.Context, shortCode string) error
// Close 关闭并释放存储层占用的所有资源 (如数据库连接池)。
// 实现应确保幂等性 (多次调用 Close 不会产生副作用)。
Close() error
}
// 包级别导出的哨兵错误,供调用者使用 errors.Is 判断。
var ErrNotFound = errors.New("storage: link not found")
var ErrShortCodeExists = errors.New("storage: short code already exists")
// (可以根据具体存储实现的需求,定义更多特定的导出错误,如 ErrDBQueryFailed 等)
来分析这里关于API设计五要素的考量(storage.Store)。
-
易用性:
-
命名:Store、Save、FindByShortCode、IncrementVisitCount、Link 清晰。
-
参数/返回值:ctx首参数,error尾返回。FindByShortCode 返回 *Link 以便在未找到时返回 nil。
-
错误:使用导出的哨兵错误 ErrNotFound、ErrShortCodeExists,方便调用者精确判断。
-
文档:此处我们省略了相关文档,但实际代码中每个导出项都应有相应的文档,用于清晰说明每个方法的行为、参数、返回值和可能返回的特定错误。
-
-
安全性:
-
并发安全:接口约定实现者必须保证并发安全。
-
资源管理:Close() 方法用于资源释放。
-
-
兼容性/扩展性:
-
Link 结构体作为值传递或返回指针,未来添加新字段(如果可选或有默认值)对现有实现和调用者影响较小。
-
接口方法签名固定,如果未来需要显著不同的存储操作,可能需要定义新的接口或通过组合现有接口进行扩展。
-
-
高效性:返回 *Link 避免拷贝。IncrementVisitCount 被设计为原子操作,其具体实现需要高效。
-
惯例性:完全符合Go的接口设计和错误处理惯例。
idgen.Generator 接口
这个接口抽象了短码的生成逻辑。
// demo2/shortlink/internal/idgen/interface.go
package idgen
import "context"
// Generator 定义了短码生成器的能力。
// 实现应尽可能保证生成的短码在一定概率下是唯一的,并符合业务对长度、字符集的要求。
type Generator interface {
// GenerateShortCode 为给定的输入(通常是长URL)生成一个短码。
// - ctx: 用于传递超时或取消信号,例如ID生成依赖外部服务时。
// - input: 用于生成短码的原始数据,通常是长URL。
// - 返回生成的短码和可能的错误(如生成超时、内部错误等)。
GenerateShortCode(ctx context.Context, input string) (string, error)
}
API设计五要素考量(idgen.Generator):
-
易用性:接口单一方法,职责清晰。
-
安全性:接口本身不涉及太多安全问题,但其实现需要考虑生成ID的随机性、抗碰撞性。
-
兼容性/扩展性:接口简单,易于提供多种不同策略的实现。如果未来需要更复杂的生成选项(如自定义长度、字符集),可能需要一个新的接口或通过配置传递给具体实现。
-
高效性:效率主要取决于具体实现算法。
-
惯例性:符合Go接口设计。
shortener.Service 的API
Service 是核心业务逻辑的封装者,它的公共方法构成了对其他内部包(如 api/http)的主要Go API。
// demo2/shortlink/internal/shortener/service.go
package shortener
import (
"context"
"errors"
"fmt"
"log"
"os"
"strings"
"time"
"github.com/your_org/shortlink/internal/idgen"
"github.com/your_org/shortlink/internal/storage"
)
var ErrInvalidLongURL = errors.New("shortener: long URL is invalid or empty")
var ErrShortCodeTooShort = errors.New("shortener: short code is too short or invalid")
var ErrShortCodeGenerationFailed = errors.New("shortener: failed to generate a unique short code after multiple attempts")
var ErrLinkNotFound = errors.New("shortener: link not found")
var ErrConflict = errors.New("shortener: conflict, possibly short code exists or generation failed after retries")
type Config struct {
Store storage.Store // 依赖接口
Generator idgen.Generator // 依赖接口
Logger *log.Logger // 接收标准库 logger
MaxGenAttempts int
MinShortCodeLen int
}
type Service struct {
store storage.Store
generator idgen.Generator
logger *log.Logger
maxGenAttempts int
minShortCodeLen int
}
func NewService(cfg Config) (*Service, error) {
if cfg.Store == nil {
return nil, errors.New("shortener: store is required for service")
}
if cfg.Generator == nil {
return nil, errors.New("shortener: generator is required for service")
}
if cfg.Logger == nil {
cfg.Logger = log.New(os.Stdout, "[ShortenerService-Default] ", log.LstdFlags|log.Lshortfile)
}
if cfg.MaxGenAttempts <= 0 {
cfg.MaxGenAttempts = 3
}
if cfg.MinShortCodeLen <= 0 {
cfg.MinShortCodeLen = 5
}
return &Service{
store: cfg.Store,
generator: cfg.Generator,
logger: cfg.Logger,
maxGenAttempts: cfg.MaxGenAttempts,
minShortCodeLen: cfg.MinShortCodeLen,
}, nil
}
func (s *Service) CreateShortLink(ctx context.Context, longURL string) (string, error) {
if strings.TrimSpace(longURL) == "" {
return "", ErrInvalidLongURL
}
var shortCode string
for attempt := 0; attempt < s.maxGenAttempts; attempt++ {
s.logger.Printf("DEBUG: Attempting to generate short code, attempt %d, longURL_preview: %s\n", attempt+1, preview(longURL, 50))
code, genErr := s.generator.GenerateShortCode(ctx, longURL)
if genErr != nil {
return "", fmt.Errorf("attempt %d to generate short code failed: %w", attempt+1, genErr)
}
shortCode = code
if len(shortCode) < s.minShortCodeLen {
s.logger.Printf("WARN: Generated short code too short, retrying. Code: %s, Attempt: %d\n", shortCode, attempt+1)
if attempt < s.maxGenAttempts-1 {
continue
} else {
break
}
}
linkToSave := storage.Link{
ShortCode: shortCode,
LongURL: longURL,
CreatedAt: time.Now().UTC(),
}
saveErr := s.store.Save(ctx, linkToSave)
if saveErr == nil {
s.logger.Printf("INFO: Successfully created short link. ShortCode: %s, LongURL_preview: %s\n", shortCode, preview(longURL, 50))
return shortCode, nil
}
if errors.Is(saveErr, storage.ErrShortCodeExists) && attempt < s.maxGenAttempts-1 {
s.logger.Printf("WARN: Short code collision, retrying. Code: %s, Attempt: %d\n", shortCode, attempt+1)
continue
}
s.logger.Printf("ERROR: Failed to save link. LongURL_preview: %s, ShortCode: %s, Attempt: %d, Error: %v\n", preview(longURL, 50), shortCode, attempt+1, saveErr)
return "", fmt.Errorf("%w: after %d attempts for input: %w", ErrShortCodeGenerationFailed, attempt+1, saveErr)
}
return "", ErrShortCodeGenerationFailed
}
func (s *Service) GetAndTrackLongURL(ctx context.Context, shortCode string) (string, error) {
if len(shortCode) < s.minShortCodeLen {
return "", ErrShortCodeTooShort
}
link, findErr := s.store.FindByShortCode(ctx, shortCode)
if findErr != nil {
if errors.Is(findErr, storage.ErrNotFound) {
s.logger.Printf("INFO: Short code not found in store. ShortCode: %s\n", shortCode)
return "", fmt.Errorf("for code '%s': %w", shortCode, ErrLinkNotFound)
}
s.logger.Printf("ERROR: Failed to find link by short code. ShortCode: %s, Error: %v\n", shortCode, findErr)
return "", fmt.Errorf("failed to find link for code '%s': %w", shortCode, findErr)
}
go func(sc string, currentCount int64, parentLogger *log.Logger) {
bgCtx, cancel := context.WithTimeout(context.Background(), 2*time.Second)
defer cancel()
logger := parentLogger // 使用传入的logger实例
if err := s.store.IncrementVisitCount(bgCtx, sc); err != nil {
logger.Printf("ERROR: Failed to increment visit count (async). ShortCode: %s, Error: %v\n", sc, err)
} else {
logger.Printf("DEBUG: Incremented visit count (async). ShortCode: %s, NewCount_approx: %d\n", sc, currentCount+1)
}
}(shortCode, link.VisitCount, s.logger) // 将logger传递进去
s.logger.Printf("INFO: Redirecting to long URL. ShortCode: %s, LongURL_preview: %s\n", shortCode, preview(link.LongURL, 50))
return link.LongURL, nil
}
func preview(s string, maxLen int) string {
if len(s) > maxLen {
return s[:maxLen] + "..."
}
return s
}
接下来再看API设计五要素应用分析(shortener.Service方法)。
- 易用性:
-
方法名 CreateShortLink、GetAndTrackLongURL 清晰表达意图。
-
构造函数 NewService 通过 Config 结构体进行依赖注入和配置,条理清晰,易于未来扩展新配置项(如重试策略、短码字符集等)而无需改变构造函数签名。
-
参数和返回值符合Go惯例(ctx 首位、error 末位)。
-
定义了业务层特定的错误(ErrInvalidLongURL、ErrShortCodeTooShort、ErrShortCodeGenerationFailed、ErrLinkNotFound),方便调用者(如未来的API Handler)进行区分处理。
-
- 安全性:
-
构造函数 NewService 对核心依赖(Store、Generator)进行了nil检查,确保服务能正确初始化。
-
方法对输入参数(longURL、shortCode)进行了基础校验(如非空、最小长度)。
-
并发安全:Service 本身是无状态的(其字段在构造后通常不可变),其并发安全性主要依赖于注入的 Store 和 Generator 实例是否并发安全。我们在 storage.Store 接口的文档中已经约定其实现必须并发安全。idgen.Generator 的实现也应考虑并发。
-
- 兼容性/扩展性:
-
依赖接口(storage.Store、idgen.Generator)使得底层实现可以轻松替换,是保证扩展性的关键。
-
使用 Config 结构体进行配置,未来增加服务层配置(如不同的重试策略、默认短码长度等)时,可以向 Config 中添加字段,而无需修改 NewService 的函数签名,保证了向后兼容。
-
- 高效性:
-
GetAndTrackLongURL 中, 访问计数更新被设计为异步执行,避免了写操作(即使是原子或快速的)阻塞关键的读路径(获取长链接并重定向),优先保证了用户体验。
-
CreateShortLink 中的冲突重试逻辑,虽然简单,但也考虑了ID生成可能碰撞的情况,避免了单次失败即放弃。maxGenAttempts 的引入防止了无限重试。
-
- 惯例性:
-
NewService符合Go“构造函数”模式。
-
错误处理使用错误包装(%w)和 errors.Is。
-
ctx 作为首参数,用于传递超时、取消信号和请求范围值。
-
对关键操作和错误情况使用了结构化日志(slog)。
-
通过这样的打磨,我们的 shortener.Service 对外(对未来的 api/http 包)暴露的Go API变得更加清晰、健壮和易于使用。
错误处理设计:定义错误类型与传递策略
在精化API的过程中,我们已经初步涉及了错误处理,定义了一些业务层的哨兵错误。现在我们系统梳理下整个服务的错误处理策略,确保错误信息能够清晰地在各层之间传递和适当地处理。
错误类型的定义
- storage 包:
-
var ErrNotFound = errors.New("storage: link not found") -
var ErrShortCodeExists = errors.New("storage: short code already exists")这些是存储层可能返回的、需要上层感知的特定错误状态。
-
- idgen 包:
-
var ErrGeneratorUnavailable = errors.New("idgen: generator service unavailable") -
var ErrInputTooLongForGenerator = errors.New("idgen: input too long to generate short code") -
var ErrInputIsEmpty = errors.New("idgen: input is empty")
-
ID生成器也可能返回其特定的错误。
- shortener(Service)包:
-
var ErrInvalidLongURL = errors.New("shortener: long URL is invalid or empty") -
var ErrShortCodeTooShort = errors.New("shortener: short code is too short or invalid") -
var ErrShortCodeGenerationFailed = errors.New("shortener: failed to generate a unique short code after multiple attempts") -
var ErrLinkNotFound = errors.New("shortener: link not found")(这是业务层对“未找到”的统一表示) -
var ErrConflict = errors.New("shortener: conflict, possibly short code exists or generation failed after retries")
-
Service层定义的错误,代表了业务逻辑层面的失败。
错误包装与传递
错误应该在系统中清晰地传递,并在每一层适当地包装以添加上下文信息,同时保留原始错误信息以便根源分析。
-
idgen 具体实现(如 simplehash.Generator):如果内部发生错误,应返回具体的错误。
-
storage 具体实现(如 memory.Store):
-
操作成功返回 nil。
-
已知错误情况(如未找到、已存在)返回包内定义的哨兵错误(storage.ErrNotFound、storage.ErrShortCodeExists)。
-
如果依赖的底层系统(如数据库驱动)返回错误,应使用
fmt.Errorf("...: %w", underlyingErr)包装该错误,添加存储层上下文。
-
-
shortener.Service:
-
输入校验失败:直接返回业务层定义的错误,如 ErrInvalidLongURL。
-
调用 idgen.Generator 失败:接收 generator 返回的错误,用 fmt.Errorf 包装,添加业务上下文。
go code, genErr := s.generator.GenerateShortCode(ctx, longURL) if genErr != nil { return "", fmt.Errorf("failed to generate short code from generator: %w", genErr) } -
调用 storage.Store 失败:
-
对于 store.Save,如果返回 storage.ErrShortCodeExists,Service层需要根据重试逻辑处理,如果最终失败,应包装成 ErrShortCodeGenerationFailed 或 ErrConflict 并附加上下文。
-
对于 store.FindByShortCode,如果返回 storage.ErrNotFound,Service层应将其转换为业务层自己的 ErrLinkNotFound(通过包装或直接返回新错误并包装原始错误),以对上层隐藏存储细节。
go link, findErr := s.store.FindByShortCode(ctx, shortCode) if findErr != nil { if errors.Is(findErr, storage.ErrNotFound) { return "", fmt.Errorf("for code '%s': %w", shortCode, ErrLinkNotFound) // 转换为业务层错误 } return "", fmt.Errorf("store failed to find link for code '%s': %w", shortCode, findErr) } -
对于其他来自 store 的错误,同样用 fmt.Errorf 包装。
-
-
api/http/handler 层的错误处理
HTTP Handler层是错误处理的最终边界之一(面向外部用户),它负责将从Service层接收到的各种 error 映射为对用户友好的、安全的HTTP响应。
-
使用 errors.Is来判断是否是特定的业务错误值(如 shortener.ErrInvalidLongURL、shortener.ErrLinkNotFound)。
-
使用 errors.As 来判断是否是特定的错误类型(如果我们定义了携带额外数据的自定义错误类型)。
-
根据不同的错误,返回不同的HTTP状态码和错误信息体。
-
shortener.ErrInvalidLongURL、shortener.ErrShortCodeTooShort -> HTTP 400 Bad Request
-
shortener.ErrLinkNotFound -> HTTP 404 Not Found
-
shortener.ErrConflict(或包装了 storage.ErrShortCodeExists 的错误)-> HTTP 409 Conflict
-
其他所有未明确处理的错误(通常是包装了底层错误的 ErrServiceInternal 或 ErrShortCodeGenerationFailed 等) -> HTTP 500 Internal Server Error。此时,应记录 完整的错误链信息 到服务器日志中(包含shortCode、longURL 等上下文),但 只向客户端返回通用的错误提示,避免泄露内部实现细节。
-
通过这样的分层错误定义、包装和判断策略,我们能确保:
-
上下文不丢失:底层错误信息通过 %w 保存在错误链中。
-
精确判断:在合适的层级使用 errors.Is 和 errors.As 进行针对性处理。
-
关注点分离:每层只关心和处理与自己职责相关的错误。
-
API清晰:Service层向其调用者(如HTTP Handler)暴露定义清晰的业务错误。
并发模型初探:构建短链接服务的并发结构与生命周期
清晰的API和健壮的错误处理是构建可靠服务的基础。但对于像“短链接服务”这样可能面临大量并发请求的应用,并发设计同样是其架构的灵魂。我们在第16讲中已经系统地学习了如何从入口并发模型、内部协作模式和goroutine生命周期管理等维度去思考并发。现在,我们就将这些理论原则初步应用到“短链接服务”这个具体案例中,看看在设计阶段,应该如何为其并发行为勾勒出清晰的蓝图。虽然详细的并发代码实现、性能调优和更复杂的同步原语使用属于后续工程实践的范畴,但在当前的设计阶段,对并发模型的初步选择和对goroutine生命周期的考量是至关重要的。
面向外部请求:入口并发模型选择
对于我们的“短链接服务”,其主要外部交互是通过HTTP API(未来可能还有gRPC等)。
One Goroutine Per Request(继承自 net/http)我们将使用Go标准库的 net/http 来构建HTTP服务。net/http 服务器的默认行为就是为每一个接收到的HTTP请求启动一个新的goroutine来处理。这意味着我们的服务入口天然就采用了 “一个请求一个goroutine” 的并发模型。
这种模型简单直接,能很好地利用多核CPU并行处理多个请求,且单个请求的I/O阻塞不会影响其他请求。
虽然单个goroutine开销小,但如果面临极高的并发请求(如DDoS攻击或非常大量的合法突发流量),无限制地创建goroutine仍可能耗尽系统资源。在工程实践阶段,我们可能需要考虑引入一些限流或熔断机制,或者在更极端情况下考虑更底层的网络模型(如用户态多路复用,但对于短链接服务,这通常是过度设计)。目前,我们先依赖 net/http 的健壮性。
面向内部协作:并发模式的应用
在处理每个请求的goroutine内部,以及服务可能存在的后台任务中,我们也需要考虑并发模式的应用。
-
shortener.Service 方法的并发调用:由于入口采用了“一个请求一个goroutine”,shortener.Service 的方法(如 CreateShortLink、GetAndTrackLongURL)将会被并发调用。因此,Service 自身及其依赖的 storage.Store 和 idgen.Generator 的具体实现 必须设计为并发安全的。我们在 storage.Store 接口的文档中已约定了这一点,其内存实现 memory.Store 也使用了 sync.RWMutex 来保证。idgen.Generator 的实现也应遵循此原则。
-
异步访问计数更新(GetAndTrackLongURL 中):在 GetAndTrackLongURL 方法中,获取长链接是主路径,而更新访问计数可以被视为一个次要的、可容忍一定延迟的操作。为了不阻塞主路径的响应,我们初步设计将其异步化:主goroutine(处理请求的goroutine)在获取到长链接后,可以启动一个新的“任务goroutine”去执行 store.IncrementVisitCount。
-
模式:这可以看作一种简单的Fire-and-Forget(如果错误不关键)或者需要进一步管理的后台任务。
-
实现:简单实现是
go s.store.IncrementVisitCount(...)。更健壮的实现可能需要一个专门的、有界缓冲的channel和一组worker goroutine来处理这些计数更新任务,形成一个简单的 Goroutine Pool或后台任务队列,以控制并发更新的压力并处理可能的错误。 -
生命周期:这些异步任务goroutine也需要被管理,确保在服务关闭时能优雅退出。
-
-
未来可能的内部并发模式:
-
批量操作:如果未来有批量创建短链接或批量查询的需求,可以考虑使用 Fan-out/Fan-in 模式来并行处理批次中的每个条目,然后聚合结果。
-
后台清理/分析:如果需要定期清理过期的短链接或进行数据分析,可以启动一个或多个后台goroutine,使用类似定时任务或Pipeline的模式。
-
Goroutine生命周期管理:确保优雅退出
这是并发设计中至关重要的一环,目的是 避免goroutine泄漏并确保服务在关闭时能够优雅地释放资源。
-
main.go 中对HTTP服务器的优雅退出:我们在 main.go 中已经初步实现了监听 SIGINT 和 SIGTERM 信号,并在收到信号后调用 httpServer.Shutdown(ctx)。这会使得HTTP服务器停止接受新连接,等待现有请求在超时期限内处理完毕,然后关闭。
-
context.Context 的核心作用:
-
请求范围的取消与超时:net/http 服务器为每个请求创建的goroutine会自动关联一个 r.Context()。这个 context 应该被透传到所有下游的调用链中(如 shortener.Service 的方法,以及它们调用的 storage.Store 和 idgen.Generator 的方法)。
-
下游goroutine的响应:所有可能长时间运行或阻塞的下游操作(数据库查询、ID生成、内部channel等待等)都应该在其 select 语句中监听 ctx.Done(),以便在请求被客户端取消或处理超时时,能够及时中止操作并返回。
-
示例
shortener.Service.GetAndTrackLongURL中异步计数更新goroutine的生命周期:我们提到将计数更新异步化。这个异步goroutine的生命周期也需要管理。虽然它可能在主请求处理goroutine返回后仍在运行,但它也应该能响应整个应用关闭的信号。
-
// 在 Service 的 GetAndTrackLongURL 方法中
go func(sc string, parentCtx context.Context) { // 传递父 context
// 为这个后台任务创建一个新的、可能带超时的context
// 但确保它能响应整个应用的关闭信号 (通过 rootCtx in main)
// 或者,如果这个任务生命周期应该与请求严格绑定,则直接用请求的 ctx
// 这里我们假设它是一个可以略微超出请求生命周期的后台更新
// 考虑从main传递一个全局的appCtx用于控制所有后台任务
// select {
// case <-appCtx.Done(): // 应用关闭信号
// s.logger.Info("Application shutting down, stopping async increment", "short_code", sc)
// return
// default:
// // 正常执行
// }
// 更简单的做法是,如果这个异步goroutine不持有外部资源,
// 并且其执行时间可控,可以不显式传递父ctx,它会在程序退出时被终止。
// 但如果它可能长时间运行或持有资源,则必须能被优雅关闭。
// 此处简化:假设其是短暂的,或依赖程序整体退出
bgCtx, cancel := context.WithTimeout(context.Background(), 2*time.Second) // 给它自己的超时
defer cancel()
if err := s.store.IncrementVisitCount(bgCtx, sc); err != nil {
s.logger.ErrorContext(bgCtx, "Failed to increment visit count (async)", "short_code", sc, "error", err)
} else {
// ...
}
}(shortCode, r.Context()) // 将请求的context或其派生context传递给goroutine的参数
// 避免闭包直接捕获可能已结束的请求的context (r.Context())
这里要强调一下,示例代码采用了上面代码片段中的简单做法,但对于上面异步计数更新的goroutine,更安全的做法是:如果其工作必须在应用关闭前完成,则应从 main 函数传递一个全局的、可取消的 appCtx 给 Service,并在启动这类后台goroutine时,基于 appCtx 或请求 ctx(如果需要请求级超时/取消)来派生新的 context。并在服务关闭时 cancel 这个 appCtx。这确保了所有后台任务都能被通知到。
如果服务包含其他独立的后台goroutine(如定时任务、消息队列消费者),它们也必须通过类似的方式(监听 done channel 或 context)来管理其生命周期,并能在服务关闭时优雅退出。
最后,我们再对设计阶段的并发考量做个总结。
-
入口模型:初步选择 net/http 的“一个请求一个goroutine”模型,并意识到其潜在的goroutine数量问题(为工程阶段的限流等优化埋下伏笔)。
-
内部协作:核心服务方法需要并发安全。识别出可异步化的内部操作(如访问计数),并初步考虑其并发模式和生命周期管理。
-
生命周期:强调 context.Context 在整个调用链中的透传和使用,作为控制超时、取消和优雅退出的核心机制。所有启动的goroutine都应有明确的退出路径并能响应取消信号。
这些初步的并发设计思考,将指导我们在后续的工程实践中,选择合适的同步原语,实现健壮的并发逻辑和优雅的服务生命周期管理。
小结
在这节课中,我们继续完善了“短链接服务”的设计蓝图,将前面几节学习的设计原则应用到了更具体的API设计、错误处理和并发考量中。
-
精化核心Go API:我们重点打磨了项目内部的核心Go接口(如storage.Store、idgen.Generator)和 shortener.Service 的方法。在设计过程中,我们结合了第19讲讨论的API设计五要素——易用性(清晰命名、合理参数、选项模式)、安全性(输入校验、并发安全承诺)、兼容性(接口依赖、Config结构)、高效性(异步更新计数)、以及Go的惯例性(ctx 与 error、构造函数、错误处理模式),力求使这些内部API也达到高质量标准。
-
错误处理设计:我们规划了分层的错误处理策略。在 storage 和 shortener 包中定义了明确的哨兵错误(如 storage.ErrNotFound、shortener.ErrLinkNotFound、shortener.ErrInvalidLongURL),并演示了如何在Service层通过错误包装(%w)保留上下文,以及在未来的API Handler层如何使用 errors.Is 来精确判断和映射业务错误到外部响应。
-
并发模型初探:我们从应用整体结构的角度思考了“短链接服务”的并发设计。
a. 入口并发模型:明确了将依赖 net/http 的 “一个请求一个goroutine” 模型作为起点。
b. 内部协作:强调了核心服务(shortener.Service)及其依赖(Store、Generator 实现)必须是并发安全的。并以“访问计数异步更新”为例,初步探讨了引入简单后台goroutine或未来可能使用worker pool等模式进行内部并发协作的可能性。
c. Goroutine生命周期管理:强调了 context.Context 在整个调用链中的透传对于控制超时、取消和实现优雅退出的核心作用,所有长时间运行或阻塞的API都接受了 ctx。
-
设计蓝图完善:通过这些细化设计,我们的“短链接服务”内部模块划分、核心Go接口定义、错误处理机制和初步的并发策略都更加清晰和完善,形成了一个更具可实施性的设计方案。
这节课的核心在于将抽象的设计原则具体化到代码接口和交互流程的设计中。我们看到了一个良好的API(即使是内部API)是如何通过细致的考量(五要素)逐步形成的,以及健壮的错误处理和前瞻性的并发思考是如何在设计阶段就融入系统的。这个经过精化的设计蓝图,为我们下一模块的工程实践打下了坚实的基础。
思考题
在我们的 shortener.Service 设计中,它依赖于 storage.Store 和 idgen.Generator 这两个接口。我们通过构造函数 NewService(cfg shortener.Config) 将这两个接口的具体实现注入进去。现在请你思考两个问题:
-
这种依赖注入(Dependency Injection)的方式,相比于在 Service 内部直接创建 memory.Store 或 simplehash.Generator 的实例,主要带来了哪些设计上的好处?(可以从可测试性、可替换性、模块耦合度等方面考虑)
-
如果未来我们的 shortener.Service 还需要依赖一个新的服务,比如一个 Notifier 接口(用于发送通知),你会如何修改 Service 的设计(特别是其构造和依赖管理方式)来优雅地集成这个新的依赖,同时保持其良好的设计特性?
欢迎在评论区分享你的设计思考!我是Tony Bai,我们工程实践篇再见!
应用骨架:从初始化、组件编排到优雅退出的最佳实践(上)
你好,我是Tony Bai。
在模块二中,我们一起深入探讨了Go语言在项目布局、包设计、并发设计、接口设计、错误处理以及API设计等多个层面的核心原则与最佳实践。通过这些内容的学习,相信你已经掌握了如何从“设计”的视角出发,去构思和编写出结构更清晰、耦合更低、更易于维护和扩展的Go代码。我们甚至通过一个“短链接服务”的实战串讲,将这些设计理念融会贯通,体验了从需求到初步API设计的过程。
然而,优秀的设计和高质量的代码片段,最终还需要被有效地组织和运行起来,才能真正交付价值,变成一个稳定可靠的线上服务。 如何将我们精心设计的模块和代码,组装成一个能够应对生产环境复杂挑战的完整应用? 这正是我们模块三——工程实践,锻造生产级Go服务,所要聚焦的核心命题。
本模块将带你从代码走向服务,重点关注那些将Go代码转化为可靠线上服务的关键环节:
-
如何构建规范的应用骨架(初始化、依赖注入、优雅退出)?
-
如何实现可复用、高内聚的核心组件(配置、日志、插件化)?
-
如何为你的服务装上“眼睛”和“耳朵”,实现全面的可观测性(Metrics、Logging、Tracing)?
-
如何进行高效的故障排查、组织有效的测试、实施性能调优、拥抱云原生部署,乃至与AI大模型集成,让你的Go应用真正具备生产级的战斗力,助你打通Go工程化的“最后一公里”。
作为模块三的开篇,我们将从构建一个Go应用的“龙骨”——应用骨架(Application Skeleton)展开。
想象一下,你的Go项目还在“裸奔”吗?是从一个简单的 main 函数开始,然后随着需求的迭代,代码像藤蔓一样随意生长?当项目逐渐庞大,你是否发现:
-
新的功能模块难以优雅地融入现有体系?
-
配置、日志、数据库连接等基础组件的初始化散落在各处,难以统一管理?
-
每次服务升级或重启,都心惊胆战,生怕丢失数据或影响用户?
-
团队新人面对一团“意大利面条”式的代码,无从下手,维护成本居高不下?
如果这些场景让你感同身受,那么你可能忽略了一个至关重要的环节—— 构建一个坚实的应用骨架(Application Skeleton)。
很多开发者,尤其是那些未曾深度参与过大型项目从0到1构建的同学,对于如何搭建一个结构清晰、生命周期可控、组件协同高效的Go应用骨架,往往感到迷茫。他们可能知道如何写单个功能,但如何将这些功能有机地组织起来,形成一个强大而可靠的整体,却是一个巨大的挑战。
一个健壮的应用骨架,是项目成功的基石。它不仅仅是一个 main 函数,更是项目的“龙骨”,定义了项目的结构规范、组件的初始化与交互方式、以及程序的启动与退出行为,直接影响着代码的可维护性、可测试性、可扩展性以及线上服务的稳定性。 掌握应用骨架的设计与实践,是Go工程师从“能写代码”到“能构建可靠系统”的关键一步。
接下来的两节课,我们就深入Go工程实践的核心地带,探讨“应用骨架”的设计与实现。这两节课也可以看作是工程实践模块的总纲,为后续更具体的工程化主题(如配置、日志、可观测性等)奠定基础。
这节课,我先带你深刻理解为何应用骨架如此重要,它如何解决简单 main 函数无法应对的挑战。接着,我们将借鉴业界主流Go项目的实践,分析几种常见的应用骨架构建模式,看看“他山之石”如何攻玉。
准备好了吗?让我们一起揭开Go应用骨架的神秘面纱,为你的项目构建坚不可摧的“龙骨”!
为何应用骨架如此重要?
我们先来思考一个根本问题:一个简单的 main 函数,真的能撑起一个复杂的生产级应用吗?
想象一下,最初你的应用可能只有一个简单的功能, main 函数里顺序执行几行代码就搞定了。但随着业务发展:
-
你需要加载配置文件。
-
你需要初始化数据库连接、缓存客户端。
-
你需要启动一个HTTP服务来接收外部请求。
-
你需要在程序的各个位置输出不同级别的log。
-
你可能还需要一些后台任务(goroutine)周期性执行。
-
你需要处理操作系统的信号,以便在服务关闭时做一些清理工作。
如果这些逻辑都堆砌在 main 函数中,或者随意散落在几个辅助函数里,很快你就会发现代码变得难以阅读和管理。这就是简单 main 函数的局限性。
那么,如果缺乏一个设计良好的应用骨架,具体会带来哪些“切肤之痛”呢?
-
代码结构混乱,职责不清:初始化逻辑、业务逻辑、中间件逻辑混杂在一起,新人接手项目时,往往需要花费大量时间去理解代码的组织方式和执行流程。
-
组件初始化顺序失控:比如,作为基础构件的日志系统还没准备好,基础服务客户端(如数据库连接池)就开始尝试记录其初始化日志,导致启动失败或关键信息丢失。又或者,业务组件在它依赖的基础服务客户端尚未就绪时就被调用,引发nil指针恐慌。这种依赖关系复杂的组件之间,初始化顺序一旦失控,问题排查将非常棘手。
-
配置管理分散,难以统一:无论是基础构件(如日志级别、输出目标)、基础服务客户端(如数据库地址、连接池大小),还是业务组件(如业务规则阈值),如果它们的配置管理方式五花八门,甚至硬编码,那将导致配置难以集中管理和动态更新。
-
缺乏统一的启动和退出流程:服务启动时,可能遗漏了某个关键基础构件或基础服务客户端的初始化,导致后续依赖它的业务组件无法正常工作。服务关闭时,如果没有一个统一的、考虑了组件依赖顺序的退出流程,就可能导致基础服务客户端的连接未正确关闭、正在执行的业务组件任务被粗暴中断,最终造成数据丢失、资源泄漏,甚至服务无法正常停止。
-
难以进行有效的单元测试和集成测试:组件间紧密耦合,难以独立测试。想mock某个依赖,却发现它被深层嵌套在初始化代码中。
-
扩展新功能或替换组件时“牵一发而动全身”:由于缺乏清晰的边界和抽象,修改一处代码可能引发意想不到的连锁反应。
这些痛点,相信经历过项目失控的同学都深有体会。而一个精心设计的应用骨架,正是解决这些问题的良药。它如同建筑的“龙骨”,为整个应用提供了坚实的支撑和清晰的结构。
应用骨架的核心价值,可以总结为以下几点:
-
规范性(Standardization):提供一致的项目结构和开发范式,降低团队成员的沟通成本和学习曲线。
-
可控性(Controllability):精确管理应用的整个生命周期,包括清晰的初始化顺序、组件的运行状态监控以及可预测的关闭流程。
-
协作性(Collaboration):清晰定义组件间的依赖关系和通信方式,使得不同组件可以独立开发和测试,然后顺畅地集成。
-
健壮性(Robustness):内置统一的错误处理机制、优雅退出策略、以及对外部信号的响应能力,提升服务的整体可靠性。
-
可维护性与可扩展性(Maintainability & Scalability):模块化的设计使得代码更易于理解、修改和调试。当需要添加新功能或替换现有组件时,对现有系统的影响也更小。
对于任何希望构建和维护中大型Go项目,或者希望提升自身Go工程能力的开发者来说,理解和掌握应用骨架的设计与实现,都是一项基础且极端重要的技能。它能帮助你从“写功能”的层面,上升到“构建系统”的层面。
业界主流Go应用骨架模式
理解了应用骨架的重要性之后,我们自然会问:那些成熟的、大型的Go开源项目是如何组织其应用骨架的?它们有哪些值得我们学习和借鉴的模式呢?
直接深入这些项目的源码去逐行分析可能非常耗时,且容易迷失在细节中。更有效的方法是,选取一些有代表性的项目,提炼其骨架设计的核心思想和模式。
调研方法与核心分析维度
当我们去审视一个项目的应用骨架时,可以重点关注以下几个方面:
-
启动入口与命令行处理:程序的
main函数在哪里?如何进行命令行参数的解析?这部分属于基础构件的范畴。 -
配置加载与管理:应用配置从何而来(文件、环境变量、远端)?如何被解析并传递给需要的模块?这也是基础构件的核心。
-
核心组件的组织与初始化:
-
基础构件的初始化:除了命令行和配置,还包括日志系统、可观测性组件(如Metrics、Tracing)等是如何被初始化的?
-
基础服务客户端的初始化:如数据库连接池、缓存客户端、消息队列客户端等是如何基于配置被创建和准备就绪的?
-
业务组件的初始化与组装:核心业务逻辑是如何被组织成组件,并依赖前两者进行初始化的?
-
-
组件间的依赖关系解决:不同类型的组件(基础构件、基础服务客户端、业务组件)之间的依赖是如何被注入和管理的(例如,业务组件如何获取到数据库客户端实例)?
-
应用生命周期管理与优雅退出:应用如何统一启动所有组件?如何响应外部信号(如
SIGINT、SIGTERM)并协调所有组件(特别是那些有状态或需要清理资源的组件)实现有序、平滑的关闭?
通过对这些维度的观察,我们可以总结出几种常见的Go应用骨架模式。
模式一:轻量级/脚本式骨架(Lightweight/Script-like Skeleton)
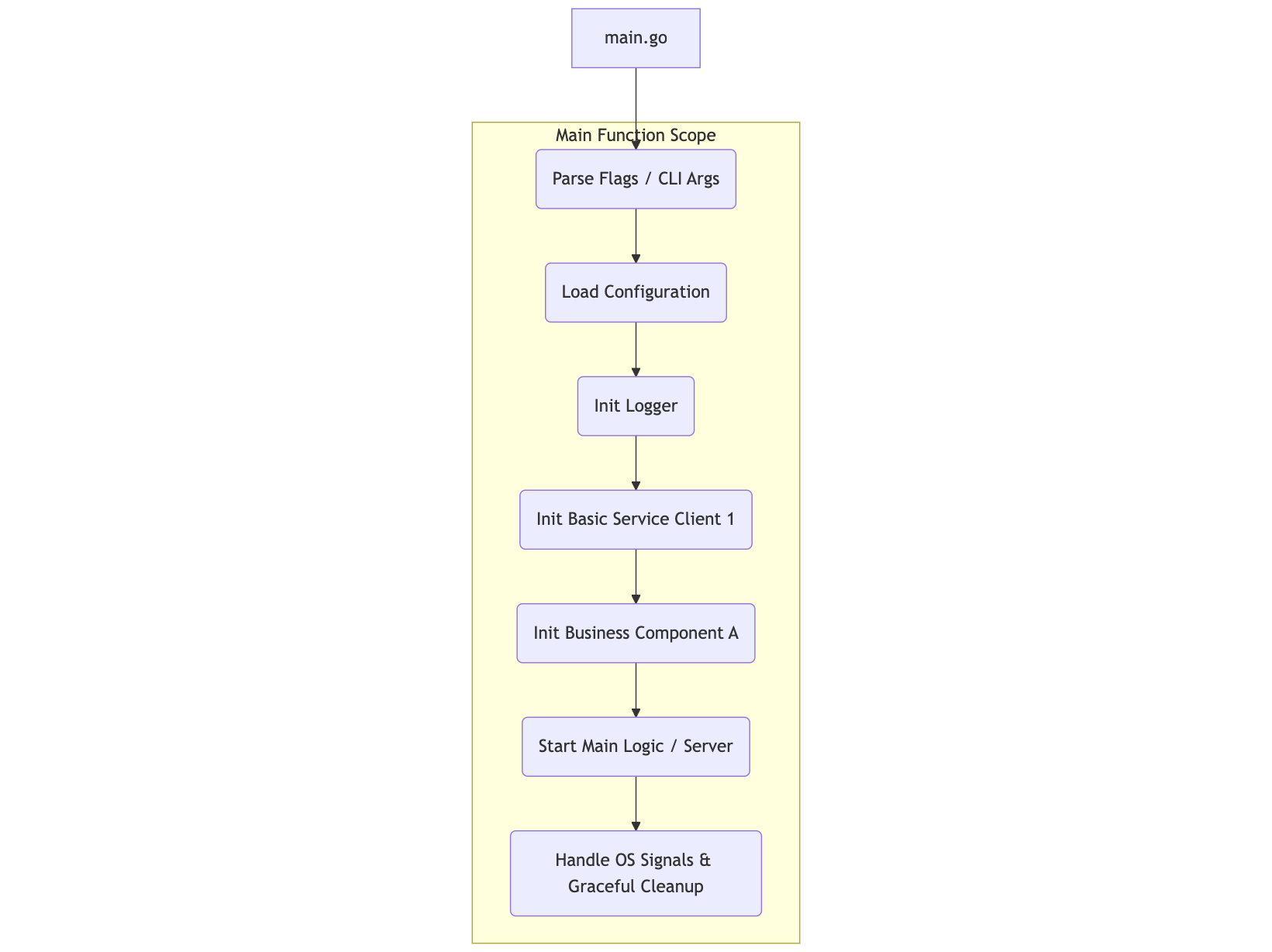
这是一种以核心 main 函数为中心构建的结构。如上图所示, main.go 作为入口,其内部(或通过少量直接调用的辅助函数)顺序执行了包括基础构件(命令行解析、配置加载、日志初始化)、基础服务客户端(示例中的Basic Service Client 1)和业务组件(示例中的Business Component A)的初始化,以及主逻辑的启动和信号处理。整个流程由 main 函数直接驱动和控制。
该模式的特点在于组件初始化逻辑简单直接,依赖关系通常不复杂,通过参数传递或包级变量即可解决。生命周期管理也较为简单,通常仅处理基本的信号退出。
这种结构在许多命令行工具(CLI)、小型后台服务以及早期版本的简单应用中得到广泛应用。它的主要优点在于简单直观,易于理解和快速上手,对于小型项目而言,效率也相对较高。然而,随着项目规模和复杂度的增加, main 函数可能会迅速膨胀,导致维护困难。同时,组件间的耦合度较高,使得测试和扩展变得更加复杂。
因此,轻量级/脚本式骨架适用于功能单一的小工具、原型验证以及团队内部使用的简单服务,特别是那些短期内不会大规模扩展的项目。
模式二:模块化/组件化驱动骨架(Modular/Component-driven Skeleton)
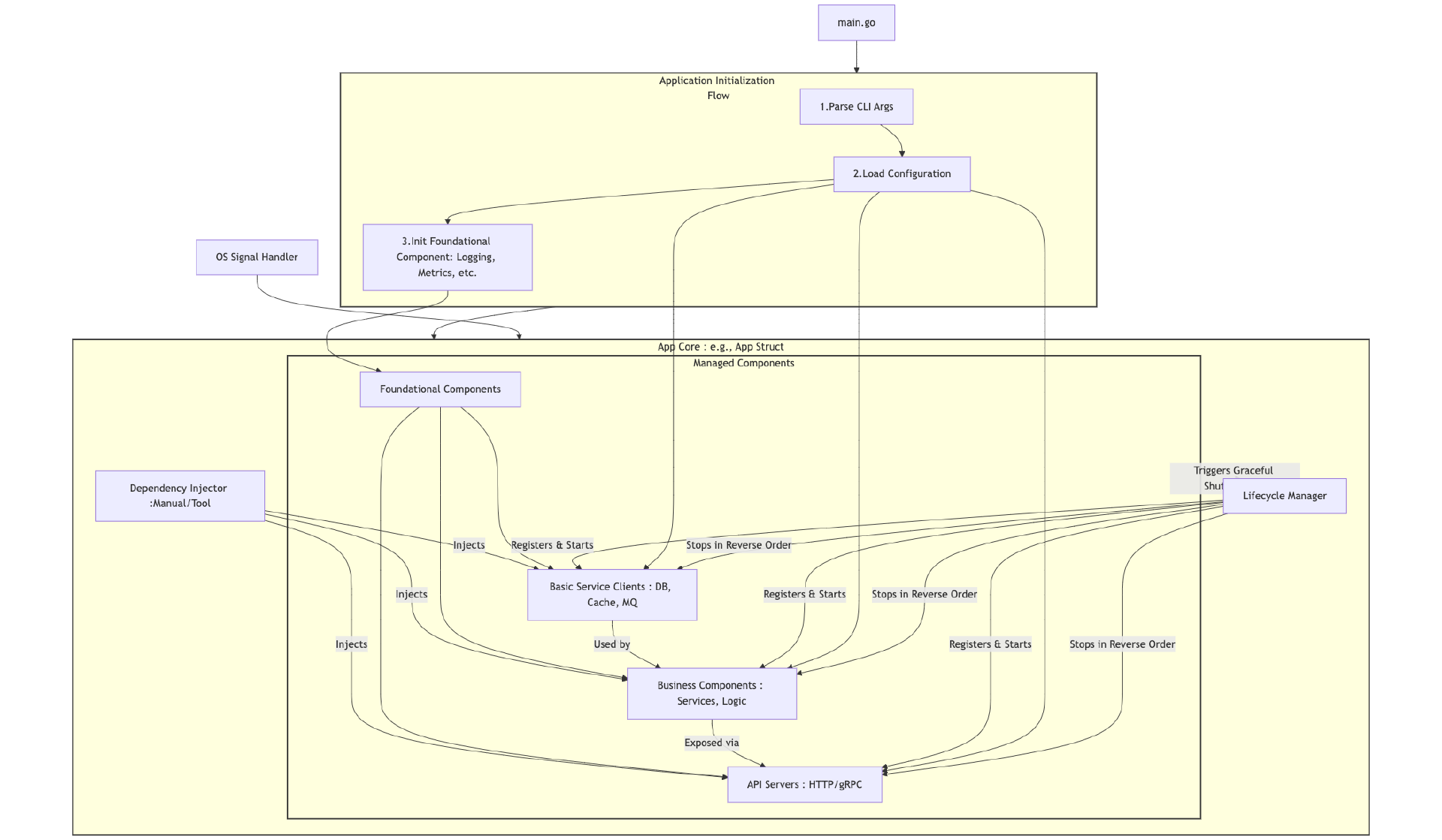
模块化/组件化驱动骨架,如上图所示,强调将应用拆分为定义清晰的基础构件(如配置、日志、可观测性)、基础服务客户端(如数据库、缓存)和业务组件。
每个需要独立管理生命周期的组件(尤其是基础服务客户端和某些业务组件,以及承载它们的服务器如HTTP/gRPC Server)通常会实现统一的生命周期接口(如 Start(ctx)、 Stop(ctx))。
应用骨架的核心(通常是一个中心化的 App 或 Server 结构体,即图中的 App Core Instance)负责:
-
按依赖顺序初始化所有基础构件(如
AppInit流程所示)。 -
基于配置和已初始化的基础构件,创建并初始化所有基础服务客户端。
-
将基础构件和基础服务客户端注入到业务组件中,完成业务组件的初始化和组装(通过
DependencyInjector)。 -
注册所有需要管理生命周期的组件,并通过
LifecycleManager编排它们的有序启动。 -
响应
SignalHandler捕获的信号,通过LifecycleManager实现所有注册组件的有序、基于信号的优雅关闭。
这种设计在许多中大型Go应用中得到了广泛应用,包括一些微服务框架的早期或核心版本,以及像Prometheus和etcd等大型基础设施软件的核心启动逻辑。例如,在Prometheus的 main 函数中,会构建一个 reloadable.NewTransaction 来管理各个组件的生命周期,这体现了对组件化和生命周期管理的重视。
模块化骨架的主要优点在于其结构清晰、职责分明,使得组件能够独立开发和测试,易于扩展和替换。同时,应用的生命周期管理也更具可控性。然而,相较于轻量级骨架,这种设计在初期投入上可能稍大,且如果依赖关系非常复杂,手动的依赖管理可能会变得繁琐(此时可以考虑依赖注入DI工具)。
因此,模块化/组件化驱动骨架特别适用于那些需要长期维护和演进的生产级Go应用,尤其是包含多个独立功能单元(如API服务、后台处理器和数据存储交互等)的系统。这也是我们后续“庖丁解牛”部分重点分析和推荐的模式。
模式三:基于框架的约定式骨架(Framework-based Convention Skeleton)
基于框架的约定式骨架,依赖于特定的Go Web框架(如Gin、Echo、Beego)或微服务框架(如 go-kratos、 go-zero)。
这些框架通常提供了一整套的应用骨架结构、组件生命周期管理机制(通过 LifecycleManager)、依赖注入容器(可选的 DIContainer),以及丰富的内置基础设施,包括路由( Router)、中间件( MiddlewareStack)、配置和日志等功能(通常封装在 Framework Core Engine 中)。
开发者主要通过遵循框架的“约定”(Convention over Configuration)来填充业务逻辑代码,例如在 AppSetup 中进行应用配置和组件注册,定义 Handlers、 BusinessLogic Services、 DataRepositories 等。框架的 LifecycleManager 也会调用用户定义的启动和停止钩子。
例如,使用 go-kratos 构建的应用会有一个 App 结构体来管理 HTTPServer 和 GRPCServer 等,并通过 app.Run() 启动,框架负责底层的生命周期协调。 go-zero 则通过 .api 或 .proto 文件定义服务,并自动生成项目骨架和部分业务代码的脚手架。
这种模式的优点在于开发效率高,框架通常集成了大量最佳实践和开箱即用的功能,从而降低了开发者构建完整应用的门槛。此外,成熟框架的社区生态相对完善,遇到问题时也更容易找到解决方案。
然而,基于框架的设计也存在一些缺点。开发者对框架的依赖较强,可能会面临一定的学习曲线和“黑盒”效应,理解框架内部机制可能需要额外成本。此外,框架的灵活性和可定制性可能受到限制,如果框架本身设计不佳或不再维护,项目的迁移成本也会较高。
因此,这种模式特别适用于需要快速开发标准化的Web应用或微服务的场景,尤其是在团队对特定框架有深入理解和使用经验的情况下,以及当项目需求与框架提供的能力高度匹配时。
通过借鉴上述这些模式,我们可以看到,并没有一个“放之四海而皆准”的完美应用骨架。选择或设计适合自己团队和业务需求的骨架模式才是关键。对于大多数从头开始构建的中大型项目,模块化/组件化驱动的骨架(模式二)往往是一个不错的起点,它在规范性和灵活性之间取得了较好的平衡。而当你需要快速迭代或团队成员对某个框架非常熟悉时,基于框架的骨架(模式三)也能显著提升开发效率。
理解这些模式,能帮助我们更有方向性地去设计自己的应用骨架,或者在评估第三方框架时,看清其背后的组织哲学。
小结
这节课,我们首先深刻理解了一个设计良好的应用骨架对于构建高质量、可维护、可扩展的Go应用来说极端重要,它远超一个简单 main 函数所能承载的职责。我们分析了缺乏骨架所带来的种种“切肤之痛”,并明确了骨架的核心价值:规范性、可控性、协作性、健壮性以及可维护性与可扩展性。
接着,我们借鉴了业界的成熟实践,“他山之石,可以攻玉”,探讨了轻量级/脚本式、模块化/组件化驱动、以及基于框架的约定式等几种常见的应用骨架构建模式,并分析了它们各自的特点、优缺点及适用场景,帮助你拓宽视野,为自己的项目选择或设计合适的骨架打下基础。
下节课,我们会庖丁解牛,深入拆解一个典型应用骨架的核心组成部分。欢迎在留言区分享你的思考和设计!我是Tony Bai,我们下节课见。
应用骨架:从初始化、组件编排到优雅退出的最佳实践(下)
你好,我是Tony Bai。
在了解了不同的骨架模式后,我们会庖丁解牛,深入拆解一个典型应用骨架的核心组成部分:从应用的启动与初始化(包括基础构件如命令行解析、配置加载、日志等的初始化),到各类组件的编排与依赖管理(包括基础服务客户端和业务组件的组装),再到程序如何实现优雅退出(信号处理、资源清理、平滑关停)。
最后,我们会基于典型应用骨架的讲解,给出一个可运行的、概念性的Demo项目代码示例,让你直观地看到这些理论是如何在实践中落地的,并提供一个可以参考和扩展的起点。
我们以模块化/组件化驱动骨架(即模式二),作为接下来详细拆解的蓝本。
一个健壮的模块化应用骨架,其核心在于一个中心化的应用核心实例( App Core Instance),它负责编排应用的整个生命周期。这个过程可以分解为三大关键环节:应用的启动与初始化、核心组件的编排与依赖管理,以及最终的优雅退出。
应用启动:初始化、命令行与配置
应用的启动是整个骨架运作的开端,对应下图中的 Application Initialization Flow。这个阶段的核心任务是准备好应用运行所需的基础环境和数据,确保后续的组件能够被正确创建和配置。我们首先来看初始化流程的整体控制。
初始化流程与顺序控制
一个清晰、可控的初始化序列是应用稳定启动的基石。这涉及如何组织代码,以及如何决定各个部分的初始化时机。
首先是 init() 函数的审慎使用。 在我的《 Go语言第一课》中就已经多次强调,Go语言的 init() 函数在包导入时自动执行。这使得它非常适合执行那些绝对必要、无外部依赖(如配置文件、命令行参数)、且必须在包加载时完成的纯粹初始化操作。例如,数据库驱动的注册(如 _ "github.com/go-sql-driver/mysql")、编解码器的注册,或者设置一些包级别的常量和内部状态。然而,要极力避免在 init() 函数中执行复杂的逻辑,进行I/O操作(如读文件、网络请求),或者依赖其他包 init() 函数的执行顺序。因为 init() 函数的执行顺序由包的导入关系决定,这可能导致隐蔽的初始化依赖问题,使得代码难以理解、测试和调试。滥用 init() 函数会降低代码的可预测性和可维护性。
其次是显式的应用级初始化。 更为推荐和健壮的做法是,在应用的入口(通常是 main.go 中的 main 函数)引导一个显式的、可控的初始化序列。这通常意味着我们会定义一个或多个应用级别的初始化函数(例如 setupApplication()、 initializeApp()),或者将初始化逻辑封装在 App Core Instance 的构造函数中。在 main 函数中,我们按照清晰的逻辑顺序调用这些函数。
这样做的好处显而易见:
-
顺序可控:初始化步骤和它们的执行顺序完全由开发者掌控,一目了然,易于理解和调整。
-
依赖明确:可以将配置对象、其他已初始化的组件实例等作为参数显式传递给后续的初始化函数,使得依赖关系清晰可见。
-
错误处理更佳:显式的函数调用允许我们直接处理初始化过程中可能发生的错误,并据此决定是继续执行、优雅退出还是直接panic。
-
可测试性更高:独立的初始化函数更容易进行单元测试,可以通过传入mock的配置或依赖来验证其行为。
最后是关键组件的初始化顺序考量。 一个典型的、合理的初始化顺序通常遵循依赖关系,先初始化被依赖的,再初始化依赖者。
-
命令行参数解析(
CmdParser):这是应用获取外部输入的第一个环节,解析结果可能影响后续步骤,例如指定配置文件的加载路径或覆盖某些默认参数。 -
配置加载(
ConfigLoader):基于命令行参数或约定的默认路径,从文件、环境变量或远程配置中心加载应用的全部配置信息,并将其解析到一个强类型的Go结构体中。这个配置结构体是后续所有组件初始化的“燃料”。 -
基础构件初始化(
FoundationalComponentsInit):在配置加载完毕后,应立即初始化核心的基础构件。这包括:-
日志系统:这是重中之重,应尽早初始化。一旦日志系统就绪,后续的初始化步骤、组件运行以及错误处理都能依赖它来输出结构化、可管理的日志信息。
-
可观测性组件:如 Metrics 收集器(例如Prometheus的registry和collectors)、Tracing Provider(例如OpenTelemetry的SDK配置和导出器)。这些组件能帮助我们监控应用状态和追踪请求链路,对生产环境至关重要。
-
其他任何不直接依赖于具体业务逻辑或外部服务客户端的平台级工具或共享服务。
-
这些在应用启动初期完成的初始化步骤,它们的产物(如最终的配置实例、全局的日志器实例、指标注册表等)将被传递给后续的 App Core Instance(我们下节课会讲),用于进一步构建和编排更上层的基础服务客户端和业务组件。一个精心设计的初始化流程,能为整个应用的稳定运行打下坚实的基础。接下来,我们具体看看命令行参数是如何解析的。
命令行参数解析
命令行参数是用户或部署脚本与应用交互、进行启动时配置的一种重要方式。Go标准库为此提供了基础支持。
-
标准库
flag包:对于大多数应用来说,如果命令行参数需求比较简单(例如,只需要接收-config <path>、-port <number>、-debug这样的标志),标准库的flag包完全够用。它简单易学,是Go语言内置的标准功能,无需引入额外依赖。通过flag.String()、flag.Int()、flag.Bool()等函数定义参数,然后调用flag.Parse()即可解析。 -
为何以及何时选择第三方库? 当你的应用需要更复杂的命令行接口(CLI)时,
flag包就可能显得力不从心。例如:-
子命令(Subcommands):像
docker ps、git commit -m "message"这样,应用有多个功能模块,每个模块有自己的一套参数。 -
更丰富的参数类型和校验:需要非基本类型的参数、参数别名、参数分组、自动生成更美观和详细的帮助信息等。
-
更佳的用户体验:包括命令自动补全、更友好的错误提示等。在这种情况下,社区流行的第三方库如
spf13/cobra(被Kubernetes、Docker、Hugo等大量知名项目采用)或urfave/cli会是更好的选择。它们提供了构建功能强大且用户友好的CLI应用的完整框架。本节课我们不深入这些库的具体API,而是重点理解它们能解决什么问题,以及何时使用它们。
-
-
命令行参数与配置文件的优先级:一个常见的实践是,允许命令行参数覆盖配置文件中定义的同名配置项。这为用户在启动时临时调整某些参数提供了便利,而无需修改配置文件。例如,你可以通过
-log-level debug来临时开启调试日志,即使配置文件中设置的是info级别。这种优先级的设定通常在配置加载逻辑中实现。
命令行参数解析完成后,我们就获得了应用启动所需的一些关键信息,其中最重要的往往是配置文件的路径。接下来,就轮到配置加载与管理登场了。
配置加载与管理
配置是应用的“大脑”,它指导着应用中几乎所有组件的行为。一个健壮且灵活的配置管理机制对于应用骨架至关重要。
- 配置源的多样性:生产环境中的应用通常需要从多种来源获取配置信息,以适应不同的部署环境和运维需求:
-
配置文件:这是最常见的方式,如JSON、YAML、TOML、INI等格式的文件。它们结构清晰,易于人工编辑和版本控制。
-
环境变量:在容器化(如Docker)和云原生环境(如Kubernetes)中非常流行。环境变量便于在不同部署阶段(开发、测试、生产)注入不同的配置,实现配置与代码的分离。
-
命令行参数:如前所述,用于在启动时临时覆盖或指定少量关键配置。
-
远程配置中心:对于分布式系统或需要动态更新配置的场景,使用配置中心(如etcd、Consul、Apollo、Nacos)是常见的选择。应用启动时从配置中心拉取配置,并可能监听后续的配置变更。
-
- 加载策略:
-
启动时加载:大部分配置项在应用启动时一次性加载完成。
-
多源合并与优先级覆盖:一个好的配置系统应该支持从多个源(如默认值、配置文件、环境变量、命令行参数)加载配置,并能定义清晰的优先级规则进行合并和覆盖。例如,常见的优先级顺序是:命令行参数 > 环境变量 > 指定的配置文件 > 默认配置文件 > 内置默认值。
-
- 推荐实践:
-
使用结构体映射配置:定义一个或多个Go结构体,其字段与配置文件的结构(或环境变量的命名规范)相对应。然后,将从各种源解析出来的配置数据填充(unmarshal/decode)到这些结构体实例中。这样做的好处是类型安全(编译期检查),并且在代码中通过结构体字段访问配置项非常方便直观。
-
利用库简化加载:手动处理多源加载、格式解析、优先级合并等逻辑可能非常繁琐且容易出错。社区有许多优秀的配置管理库,如
spf13/viper,它能很好地处理这些复杂需求,支持多种配置文件格式、环境变量读取、远程配置源、配置热加载(watch),以及将配置自动映射到结构体等功能。理解这类库的核心设计思想(如统一的Get接口、多源优先级管理、与结构体解耦等)比死记硬背其API更为重要。
-
配置系统是驱动整个应用骨架运转的“燃料”,它决定了各个基础构件、基础服务客户端和业务组件的行为。一个健壮的配置系统本身也是一个重要的基础构件。在后续的《核心组件:构建健壮Go服务的配置、日志与插件化方案》中,我们将结合示例,深入探讨配置管理的最佳实践,包括多源加载、结构化配置、动态更新(热加载)等。这节课我们重点关注配置如何在骨架的启动阶段被加载并传递给需要它的组件。
当应用的启动和基础配置准备就绪后,应用骨架的核心职责就转向了如何将各个功能模块有机地组织起来,这就是我们接下来要讨论的“组件的编排”。
组件的编排:组装与依赖管理
一旦完成了初步的初始化(对应图1中的 Application Initialization Flow),控制权就交给了图中的 App Core Instance。它像一位乐队指挥,负责创建、组装并启动应用中的各个核心组件,让它们协同工作,共同完成应用的使命。这个过程我们称之为“组件的编排”。
识别与定义核心组件
首先,我们需要识别出应用中承担不同职责的核心组件。参照图1中 Managed Components 的分类,这些组件通常包括:
-
基础构件(
FC - Foundational Components):这些是在初始化阶段就已经准备好的实例,例如我们之前讨论的Logger(日志记录器)、可能的Metrics Collector(指标收集器)、Tracer Provider(分布式追踪提供者)等。它们通常不直接依赖其他自定义的业务组件,而是作为基础服务被其他所有类型的组件依赖和使用。 -
基础服务客户端(
BSC - Basic Service Clients):这些是应用与外部基础设施(如数据库、缓存服务、消息队列、第三方API等)进行交互的客户端或连接池。例如,*sql.DB实例、*redis.Client实例、Kafka或RabbitMQ的生产者/消费者客户端等。它们的创建和配置高度依赖于从AppConfig中加载到的相关配置信息,并且通常会使用基础构件中的Logger来记录其操作日志。 -
业务组件(
BC - Business Components):这是应用的核心所在,封装了具体的业务逻辑。例如,在一个电商应用中,可能会有UserService、OrderService、ProductService等。这些业务组件通常会依赖一个或多个基础服务客户端来完成数据的持久化和检索,同时也可能需要基础构件(如Logger)来辅助。 -
API服务器/Lifecycle组件(
Servers):这些是应用对外提供服务或执行后台任务的入口和执行体。最常见的是HTTP服务器(如基于net/http或 Gin、Echo 等框架构建)和gRPC服务器。此外,消息队列的消费者进程、定时的批处理任务执行器等,如果它们有独立的运行和关闭生命周期,也属于此类。这些组件通常会组合一个或多个业务组件(通过依赖注入的方式),将业务能力暴露给外部调用者或触发内部处理流程。由于它们通常需要管理网络监听、后台goroutine等资源,因此会实现我们稍后讨论的统一生命周期管理接口。
一个至关重要的设计原则是:面向接口设计组件。 尽可能为你定义的组件(尤其是基础服务客户端和业务组件)抽象出清晰的接口,而不是让其他组件直接依赖它们的具体实现类型。这样做的好处是:
-
解耦:依赖方只关心接口定义的能力,不关心具体如何实现。
-
可测试性:在单元测试中,可以轻松地为接口创建模拟(mock)实现,从而隔离被测试组件的行为。
-
可替换性:如果未来需要更换某个组件的具体实现(例如,将数据库从MySQL迁移到PostgreSQL,或者将缓存从本地内存缓存切换到Redis),只要新的实现满足相同的接口,对依赖方代码的改动就会非常小。
这是实现“高内聚、低耦合”设计目标的关键实践,也是构建一个灵活、可维护应用骨架的基础。
当组件被清晰定义后,接下来的问题就是如何在 App Core Instance 中创建并把它们“编排”起来。
组件的初始化与编排
在 App Core Instance 内部(通常在其构造函数或一个专门的初始化方法中),我们需要根据加载的配置和已经准备好的基础构件,来实例化和组装其他各类组件。
-
实例化:每个组件通常都有一个自己的构造函数(例如,
NewDatabaseClient(cfg config.DBConfig, logger *logger.Logger) (*DatabaseClient, error),NewUserService(dbClient data.UserRepo, logger *logger.Logger) *UserService)。App Core Instance负责调用这些构造函数,并传入必要的配置和依赖项,从而创建出各个组件的实例。这个过程就是图1中DependencyInjector概念上所做的事情。 -
生命周期管理接口(
LifecycleManager的作用体现):对于那些需要显式启动和停止的组件(特别是API服务器/Lifecycle组件,以及某些可能管理着连接池或后台goroutine的基础服务客户端或业务组件),我们通常会定义一个统一的生命周期管理接口。这有助于App Core Instance以一致的方式管理它们。一个常见的模式如下:
package lifecycle // 通常放在项目的 pkg/lifecycle 或 internal/platform/lifecycle 目录下
import "context"
// Component defines the interface for a manageable application component
// that has a distinct start and stop lifecycle.
type Component interface {
Start(ctx context.Context) error // Starts the component.
// This method can be blocking (e.g., http.ListenAndServe)
// or non-blocking (launching goroutines and returning).
// The provided context can be used for cancellation during startup.
Stop(ctx context.Context) error // Stops the component gracefully.
// The provided context typically carries a deadline for shutdown.
Name() string // Optional: Returns a human-readable name for the component, useful for logging.
}
App Core Instance 会持有一个 []lifecycle.Component 的切片,将所有需要管理的组件注册到这个列表中。在应用启动时,它会遍历这个列表并调用每个组件的 Start 方法;在应用关闭时,则会按相反的顺序遍历并调用 Stop 方法。
启动与停止顺序,这个顺序至关重要,必须由 App Core Instance 内的 LifecycleManager(逻辑概念,实际可能是 App 结构体中的一段代码)精确控制。
-
启动顺序:通常遵循依赖关系。被依赖的组件(如基础服务客户端)应先于依赖它们的组件(如业务组件,再如API服务器)启动。例如,数据库连接池必须先成功启动并准备好接受连接,然后依赖它的业务服务才能正常初始化和运行,最后API服务器才能开始接收并处理依赖这些业务服务的请求。
-
停止顺序:通常是启动顺序的逆序。例如,API服务器应首先停止接受新的外部请求,并等待已在处理的请求完成;然后,业务组件可能需要完成其正在进行的任务;最后,基础服务客户端(如数据库连接池、消息队列连接)才关闭它们的连接和释放资源。
通过这种方式, App Core Instance 就如同一位经验丰富的指挥家,确保乐队中的每个乐器(组件)都能在正确的时间以正确的方式开始演奏,并在演出结束时和谐地谢幕。
接下来,我们更深入地探讨一下如何优雅地处理这些组件之间的依赖关系。
依赖管理模式
依赖注入(DI)是构建模块化、可测试和可维护软件的核心技术之一。其基本思想是:一个对象(或组件)不应该自己创建它所依赖的其他对象(依赖项),而应该由外部环境(如 App Core Instance 或DI容器)在创建时将这些依赖项“注入”给它。
为何需要DI?原因主要有三个:
-
解耦(Decoupling):组件只声明它需要什么类型的依赖(通常是接口),而不关心这个依赖的具体实现是如何创建的。这降低了组件之间的耦合度。
-
可测试性(Testability):在单元测试中,可以非常方便地为组件注入模拟(mock)的依赖对象,从而隔离被测试组件的行为,使其测试不依赖于真实的数据库、网络服务等外部环境。
-
灵活性和可配置性(Flexibility & Configurability):可以在不修改组件自身代码的情况下,通过改变注入的依赖项(例如,在测试时注入内存数据库,在生产时注入真实数据库客户端)来改变组件的行为或适应不同的环境。
Go语言简洁的设计哲学使得手动DI非常自然且常用,通常不需要重量级的DI框架。
构造函数注入(Constructor Injection)是Go中最常见也最为推荐的DI方式。在创建组件实例时,通过其构造函数的参数将所有必需的依赖项传入。
// foundational/logger/logger.go
// func New(cfg config.LoggerConfig) *Logger { ... }
// client/database/client.go
// func New(cfg config.DBConfig, logger *logger.Logger) (*Client, error) { ... }
// biz/user/service.go
// type DBInterface interface { Query(...) (...) } // 定义接口
// func NewService(db DBInterface, logger *logger.Logger) *Service { ... }
// transport/http/server.go
// type UserServiceProvider interface { GetUser(...) (...) } // 定义接口
// func New(cfg config.HTTPServerConfig, userService UserServiceProvider, logger *logger.Logger) lifecycle.Component { ... }
// 在 appcore/app.go 的 New() 方法中:
// appLogger := logger.New(cfg.Logger)
// dbClient, _ := database.New(cfg.DB, appLogger)
// userService := user.NewService(dbClient, appLogger) // dbClient 实现了 UserServiceProvider 所需的DBInterface
// httpServer := http.New(cfg.HTTPServer, userService, appLogger)
如图1所示, App Core Instance(通过其内部的 DependencyInjector 逻辑) 正是利用构造函数注入,将基础构件( FC)注入到基础服务客户端( BSC),再将 FC 和 BSC 注入到业务组件( BC),最后将 FC 和 BC 注入到API服务器( Servers)。这种依赖链条在应用初始化时被清晰、显式地建立起来,具有编译期类型安全、易于理解和追踪的优点。
此外,还可以通过组件暴露的公有Setter方法来注入依赖。这种方式适用于可选依赖,或者需要在对象生命周期中动态改变依赖的场景。不过,在Go中相对少用,因为它可能导致对象在所有依赖被设置前处于不完整或不可用状态,且依赖关系不如构造函数注入那样一目了然。
最后是接口注入,也就是定义一个特定的接口,要求依赖注入者实现该接口的方法来接收依赖项。这种方式在Go中更为罕见,因为构造函数注入通常更简单、更直接。
当应用规模变得非常大,组件数量众多,依赖关系图错综复杂时,纯粹手动的构造函数注入(尤其是在单一的 App Core 构造函数中完成所有组装)可能会导致这个构造函数变得异常冗长、难以维护,并且容易因参数顺序或类型匹配错误而出错。这个时候,我们会借助一些依赖注入的容器/工具。
常见的依赖注入工具包括 Google wire、 uber Fx、 facebook inject 等。这些工具大致可分为两类,一类是利用代码生成技术的编译期依赖注入,比如Wire,另一类则是利用反射技术的运行时依赖注入,比如fx。
google/wire 是Go社区一个广受欢迎的编译时依赖注入工具。它的核心思想是:你只需为你应用中的每个组件编写其独立的构造函数(在Wire中称为Provider),并在构造函数签名中明确声明其依赖项。然后,你定义一个或多个Injector函数,在这些函数中通过 wire.Build(...) 列出你希望Wire帮你构建的目标组件以及所有相关的Provider。Wire会在编译期间分析这些Provider之间的依赖关系图,并自动为你生成一个包含所有必要实例化和注入逻辑的Go源文件( wire_gen.go)。
静态注入框架的优点主要体现在几个方面。首先,它提供了编译时安全,这意味着如果依赖关系无法满足,例如某个依赖缺失、类型不匹配或存在循环依赖, wire 会在编译时报错,而不必等到运行时才出现panic。这种机制有效地减少了运行时错误的可能性,提高了代码的可靠性。其次,静态注入框架避免了运行时反射开销。生成的代码是纯粹的Go代码,因此没有运行时反射带来的性能损耗。这使得应用在执行时更加高效。此外,生成的代码通常是可读的,开发者可以轻松地检查这些代码,以理解依赖是如何被组装的。这种透明性增强了代码的可维护性和可理解性。最后,静态注入框架实现了关注点分离,将组件的创建逻辑(Provider)与其组装逻辑(Injector)分离。这种设计使得各个部分的职责更加清晰,有助于提升代码的模块化和可重用性。
google/wire 这类依赖注入工具可以极大地简化复杂依赖关系的组装过程,确保所有基础构件、基础服务客户端和业务组件都能正确地获取到它们的依赖项,并最终构建出功能完整的API服务器/Lifecycle组件,这些最终都由 App Core Instance 来统一管理。是否使用DI工具,需要根据项目规模、团队熟悉度和对编译时安全的追求来权衡。
日志系统作为重要的基础构件,是排查问题、监控应用状态的基础。结构化日志、日志级别控制、异步写入等是构建一个优秀日志系统的关键,我们会在后面的课程中详细展开,并重点介绍Go 1.21引入的 slog 标准库。在骨架层面,我们需要尽早初始化日志组件,并通过依赖注入的方式,将其注入到其他所有需要日志输出的组件中(如基础服务客户端、业务组件、API服务器等)。
同样,一个生产级的应用骨架还应为可观测性(Observability)的其他方面——Metrics(指标监控)和 Tracing(分布式链路追踪)——预留接口或集成点。这意味着在应用初始化阶段,我们会创建并配置相应的基础构件(如Prometheus的指标注册表、OpenTelemetry的Tracer Provider)。然后,通过依赖注入,将这些构件传递给需要暴露指标或参与链路追踪的组件(特别是API服务器和业务组件)。这些都属于应用骨架需要考虑的‘基础构件’,我们会在后面的课程中深入探讨如何将它们的设计与实现融入Go应用。”
至此,我们已经探讨了如何识别、定义、初始化和组装应用中的各类核心组件,以及如何管理它们之间的依赖关系。这些共同构成了应用骨架在运行期间的“交响乐”。
接下来,我们还需要关注这首交响乐如何优雅地结束。
应用结束:信号处理与优雅退出
一个专业的、生产级的应用,不仅要能稳定地启动和高效地运行,更要在需要停止时体面地“谢幕”,而不是粗暴地中断,留下未完成的任务和混乱的资源状态。这对应图1中由 SignalHandler 捕获操作系统信号,并由 App Core Instance 通过其 LifecycleManager 协调的关闭流程。
为何需要优雅退出?
优雅退出(Graceful Shutdown)对于现代应用,尤其是长时间运行的服务来说,至关重要。其核心价值在于:
-
避免数据丢失或损坏:确保所有正在进行的、未完成的写操作(例如,数据库事务提交、消息队列中的消息确认、文件写入刷新到磁盘)能够安全完成或得到妥善回滚。
-
释放已占用的资源:主动关闭网络连接(如HTTP、gRPC连接,数据库连接池中的连接)、文件句柄,以及其他系统资源,避免资源泄漏,为下一次启动或系统其他进程腾出空间。
-
确保正在处理的请求得到妥善完成:对于API服务器,优雅退出意味着它会停止接受新的入站请求,但会给当前正在处理的请求一定的时间窗口来完成它们的处理和响应,而不是直接切断连接,从而极大地提升用户体验和系统间调用的可靠性。
-
符合云原生环境对应用生命周期管理的要求:在容器编排平台(如Kubernetes)中,当需要更新、缩容或删除一个Pod时,Kubelet会先向Pod内的容器发送
SIGTERM信号,并给予一个宽限期(grace period)。应用如果能响应该信号并在此期限内完成优雅退出,就能实现平滑的滚动更新和资源回收。如果超时仍未退出,平台可能会发送SIGKILL强制终止。
未能实现优雅退出的应用,在停止时可能会导致数据不一致、用户请求失败、资源无法及时释放等问题,严重影响服务的质量和稳定性。
一个完整的优雅退出流程,通常遵循以下步骤:
-
监听退出信号:应用需要主动监听操作系统发送的终止信号(如
SIGINT、SIGTERM)。 -
触发关闭流程:一旦收到信号,应用应记录日志,并启动内部的关闭程序。这通常涉及创建一个带有超时机制的
context(我们称之为shutdownCtx),用于控制整个关闭过程的时长。 -
有序停止组件:按照预定的顺序(通常是启动顺序的逆序,或者是基于组件间依赖关系的更复杂顺序),调用各个核心组件的
Stop(shutdownCtx)方法。每个组件的Stop方法负责执行其自身的清理逻辑,并应尊重shutdownCtx的超时限制。 -
等待组件停止:主关闭流程需要等待所有组件都已停止,或者
shutdownCtx超时。 -
等待其他后台任务:如果应用中存在不直接由组件生命周期管理的后台goroutine(例如,一些辅助性的、由
main或AppCore直接启动的任务),需要使用如sync.WaitGroup等机制来确保它们在程序退出前也能完成。 -
执行最终清理:执行任何剩余的、全局性的清理工作(例如,刷新最后的日志缓冲区)。
-
记录退出日志并终止:明确记录应用已成功(或因超时而部分成功)退出的信息,然后程序终止。
接下来,我们将详细探讨这个流程中的关键环节。
捕获操作系统信号
Go语言通过标准库 os/signal 包提供了捕获和处理操作系统信号的能力。对于优雅退出,我们最常关注以下两个信号:
-
syscall.SIGINT:中断信号。通常由用户在终端按下Ctrl+C时发送给前台进程。 -
syscall.SIGTERM:终止信号。这是标准的、通用的程序终止请求信号,不指定信号类型的kill命令默认发送此信号。Kubernetes、systemd等现代服务管理系统在停止服务时,通常也会先发送SIGTERM。
在 App Core Instance(如图1中的 SignalHandler 逻辑部分,通常实现在 App 结构体内部或一个辅助模块中),我们会创建一个channel来接收这些信号的通知,并在一个专门的goroutine中阻塞等待:
// (在 appcore/app.go 或 foundational/signal/handler.go 中)
// quitSignals := []os.Signal{syscall.SIGINT, syscall.SIGTERM}
// sigChan := make(chan os.Signal, 1)
// signal.Notify(sigChan, quitSignals...)
// // 在App的Run方法或一个专门的goroutine中:
// go func() {
// sig := <-sigChan
// app.logger.Infof("AppCore: Received OS signal: %v. Initiating graceful shutdown...", sig)
// app.initiateShutdown() // 这是一个触发AppCore关闭流程的方法
// }()
// 更现代且推荐的方式是使用 Go 1.16+ 引入的 `signal.NotifyContext`:
// appCtx, stopSignalListening := signal.NotifyContext(context.Background(), syscall.SIGINT, syscall.SIGTERM)
// defer stopSignalListening() // 确保释放资源
// // ... 应用主逻辑 ...
// <-appCtx.Done() // 阻塞直到信号发生,appCtx被取消
// app.logger.Infof("AppCore: OS signal received or context cancelled. Initiating graceful shutdown...")
// app.performGracefulShutdown(context.Background()) // 传入一个新的根上下文用于关闭流程
使用 signal.NotifyContext 的好处是,它能将信号处理与Go的 context 机制无缝集成,当信号发生时,它会取消返回的 context,这可以非常方便地用来通知应用的主运行循环停止。
一旦捕获到退出信号, App Core Instance 就需要开始协调所有组件的关闭过程。
运用 context 实现超时与取消传播
在执行优雅退出流程时,我们不能无限期地等待所有组件完成关闭,因为某些组件的关闭过程可能会因外部依赖问题而卡住。因此,为整个关闭流程设定一个总的超时时间是非常必要的。Go的 context 包是实现这一目标的理想工具。
当 App Core Instance 收到退出信号并准备开始关闭组件时,它应该:
- 创建一个新的
context,并为其设置一个合理的超时时间(例如,15秒、30秒,这个时间应该略小于Kubernetes等平台的grace period)。
// (在 AppCore 的关闭逻辑中)
// overallShutdownTimeout := 30 * time.Second // 可配置
// shutdownCtx, cancelShutdown := context.WithTimeout(context.Background(), overallShutdownTimeout)
// defer cancelShutdown() // 确保即使提前完成,超时相关的资源也能释放
- 将这个带有超时的
shutdownCtx逐层传递给所有需要关闭的lifecycle.Component的Stop(ctx)方法。
每个组件的 Stop 方法在执行其清理逻辑时,应该:
-
尊重传入的
shutdownCtx的截止时间。如果清理操作是耗时的(例如,等待所有数据库连接归还连接池),它应该使用select语句同时监听其自身操作的完成和shutdownCtx.Done()。 -
如果
shutdownCtx在其操作完成前被取消(超时),组件应尽力快速停止当前操作,释放关键资源,并返回ctx.Err()。
通过这种方式, context 机制确保了整个优雅退出流程既有秩序,又有时间限制,避免了无限期阻塞。
核心组件的优雅关闭实践
App Core Instance(通过其 LifecycleManager 逻辑)需要按照与启动时相反的顺序(或基于更复杂的依赖关系图)来停止各个组件。
-
API服务器/Lifecycle组件(
Servers):这是最先需要关闭的,目的是停止接受新的外部请求或处理新的消息/任务。-
HTTP Server(
net/http):调用http.Server.Shutdown(shutdownCtx)方法。它会平滑地关闭服务器。首先关闭所有监听器,停止接受新连接;然后处理所有已建立连接上的活动请求,直到它们完成或shutdownCtx超时/取消;最后关闭所有空闲连接。 -
gRPC Server(
google.golang.org/grpc):调用grpc.Server.GracefulStop()方法。它会停止接受新的RPC请求,并等待所有当前正在处理的RPC完成。注意,GracefulStop()本身是一个阻塞调用,直到所有RPC完成或服务器被强制停止(通过调用Server.Stop())。因此,通常会将其放在一个goroutine中,并使用shutdownCtx来控制其超时或被外部取消。 -
消息队列消费者:应该停止从队列中拉取新的消息,并等待当前正在处理的一批消息完成其业务逻辑和确认(ack/nack)操作。其
Stop方法应确保在shutdownCtx的约束下完成这些。
-
-
业务组件:如果业务组件本身启动了后台goroutine(例如,进行一些周期性计算或维护任务),或者持有一些需要显式清理的内部状态,并且它实现了
lifecycle.Component接口,那么它的Stop(shutdownCtx)方法会被调用。业务组件应确保其后台任务能够响应shutdownCtx的取消并安全退出。 -
基础服务客户端:在上层业务逻辑和API服务都已停止或正在停止后,可以安全地关闭与外部基础设施的连接。
-
数据库连接池:调用连接池库提供的
Close()方法。一个设计良好的连接池Close()方法通常会等待所有已借出的连接被归还,然后关闭所有底层的物理连接。 -
Redis客户端、其他RPC客户端等,调用它们各自库提供的
Close()方法。 -
如果这些客户端也实现了
lifecycle.Component接口(例如,通过包装其原生Close方法),则它们的Stop(shutdownCtx)会被统一调用。
-
-
基础构件:某些基础构件在应用退出前也可能需要执行清理操作。
-
日志系统:如果使用了带缓冲的异步日志写入,其
Stop方法(或一个专门的Sync/Flush方法)应确保将所有缓冲区中的日志条目刷新到最终的输出目标(如文件或远端日志服务)。 -
Metrics/Tracing导出器:可能需要将缓存的指标或追踪数据导出到后端。
-
等待后台任务完成
如果应用中存在一些不直接由 LifecycleManager 管理的,但仍需在应用主逻辑退出前等待其完成的后台goroutine(例如,一些由 main 或 AppCore 直接启动的辅助性、非组件化的goroutine), App Core Instance 需要使用 sync.WaitGroup 等同步原语来追踪这些goroutine的完成。在所有 lifecycle.Component 都已停止后,主程序真正退出前,应调用 wg.Wait()。
清理与日志
在整个优雅退出的每一个关键步骤中, App Core Instance 都应通过其 Logger 记录清晰的日志信息,包括:开始关闭、正在停止哪个组件、组件停止成功与否、遇到的任何错误、以及最终应用成功退出的信息。这些日志对于事后排查关闭过程中可能发生的问题非常有价值。
此外,确保所有必要的最终清理操作(例如,删除临时文件、释放特定的系统级句柄等,如果这些不由各组件的 Stop 方法处理的话)在程序终止前被执行。
优雅退出是确保应用数据一致性和服务稳定性的最后一道防线,它要求应用核心实例能够精确协调所有API服务器/Lifecycle组件、业务组件(如果它们管理自身生命周期)乃至基础服务客户端(如果它们持有需要释放的资源,或者其库本身支持优雅关闭)的关闭顺序和行为。
通过以上三个方面的精心设计与实现——应用的启动、组件的编排、优雅的退出——我们就能构建出一个真正健壮、可维护、可扩展的Go应用骨架。这个骨架不仅能支撑起当前复杂的业务需求,更能从容应对未来的变化与挑战。
模块化应用骨架Demo项目示例
为了更直观地理解上述核心组成如何协同工作,我们构建了一个简化的Go项目。这个Demo将演示一个基于图1理念的模块化应用骨架。通过这个示例,你可以看到配置如何驱动初始化,各个不同类型的组件(基础构件、基础服务客户端、业务组件、API服务器)如何被组织和依赖注入,以及应用如何通过统一的生命周期管理实现启动和优雅退出。
项目布局( app-skeleton-demo/)
这个典型的模块化应用骨架项目,其目录结构可能如下所示,它清晰地划分了不同职责的代码:
app-skeleton-demo/
├── cmd/
│ └── myapp/
│ └── main.go // 应用入口, 初始化并运行App Core
├── configs/
│ └── config.yaml // 示例配置文件
├── internal/
│ ├── appcore/ // App Core 实现 (图1中的App Core Instance)
│ │ └── app.go // App结构体, Run, Stop, 依赖注入和生命周期管理逻辑
│ ├── foundational/ // 基础构件
│ │ ├── config/
│ │ │ └── config.go // 配置结构体定义与加载
│ │ └── logger/
│ │ └── logger.go // 日志组件封装
│ ├── client/ // 基础服务客户端
│ │ └── database/
│ │ └── client.go // 数据库客户端 (模拟, 实现Lifecycle)
│ ├── biz/ // 业务组件 (Business Components)
│ │ └── user/
│ │ └── service.go // 用户服务
│ └── transport/ // API服务器/Lifecycle组件
│ └── http/
│ └── server.go // HTTP服务器 (实现Lifecycle)
└── pkg/
└── lifecycle/
└── lifecycle.go // 定义Lifecycle接口
核心入口: cmd/myapp/main.go
main.go 是整个应用的启动入口,它负责最顶层的引导工作:解析命令行参数、加载配置,然后创建并运行我们的核心应用实例( appcore.App)。
package main
import (
"app-skeleton-demo/internal/appcore"
"app-skeleton-demo/internal/foundational/config"
"flag"
"fmt"
"os"
"strings"
)
var (
configPath string
)
func init() {
// 定义 -config 标志,用于指定配置文件的路径
// 默认指向 "configs/config.yaml",这个路径是相对于可执行文件运行的位置
// 在开发时,如果从项目根目录运行 `go run ./cmd/myapp/main.go`,请确保configs目录在根目录下
flag.StringVar(&configPath, "config", "configs/config.yaml", "path to config file (e.g., ./configs/config.yaml)")
}
func main() {
flag.Parse() // 解析命令行传入的标志
// 1. 加载配置 (基础构件的职责)
// 这是应用启动的第一步关键操作,后续所有组件的初始化都依赖于此配置
cfg, err := config.Load(configPath)
if err != nil {
// 在日志系统完全初始化之前,关键的启动错误直接输出到标准错误
fmt.Fprintf(os.Stderr, "FATAL: Failed to load configuration from '%s': %v\n", configPath, err)
os.Exit(1) // 非正常退出
}
// 2. 创建应用核心实例 (appcore.App)
// appcore.New() 内部会完成所有组件的初始化和依赖注入
app, err := appcore.New(cfg)
if err != nil {
// 如果应用核心创建失败,同样记录致命错误并退出
// 此时,如果app为nil或者app.Logger()为nil,我们仍然需要一种方式输出错误
errorMsg := fmt.Sprintf("FATAL: Failed to create application: %v\n", err)
if app != nil && app.Logger() != nil { // 尝试使用应用日志器
app.Logger().Fatalf(strings.TrimSuffix(errorMsg, "\n"))
} else {
fmt.Fprint(os.Stderr, errorMsg)
}
os.Exit(1)
}
// 3. 运行应用
// app.Run() 是一个阻塞调用,它会启动所有生命周期组件,
// 并等待操作系统的退出信号(如 SIGINT, SIGTERM)或内部组件发生致命错误。
// 当接收到退出指令后,它会执行优雅关闭流程。
if err := app.Run(); err != nil {
// 如果 app.Run() 返回错误,表明应用在运行或关闭过程中遇到了问题。
// 此时应用级的日志系统应该已经可用。
app.Logger().Errorf("FATAL: Application terminated with error: %v", err)
os.Exit(1) // 非正常退出
}
// 如果 app.Run() 正常返回(err == nil),说明应用已成功完成优雅关闭。
// 相关的成功日志应在 app.Run() 内部或组件的Stop方法中打印。
// main函数在此处正常结束,隐式返回 os.Exit(0)。
}
代码示例说明与运行步骤
这个Demo项目虽然为省略了大部分内部实现细节,但其核心结构和 main.go 的引导流程清晰地展示了以下内容:
-
配置驱动:应用的启动和行为由外部
configs/config.yaml文件决定。 -
分层与组件化:代码按照职责被组织在
foundational(基础构件,如配置加载、日志)、client(基础服务客户端,如数据库模拟)、biz(业务组件,如用户服务)、transport(API服务器,如HTTP服务)以及核心的appcore中。 -
依赖注入的起点:
appcore.New()函数是所有依赖关系被手动(或通过DI工具)组装的中心。 -
统一的生命周期管理:通过
pkg/lifecycle.Component接口和appcore.App的编排,实现了对需要显式启动和停止的组件(如HTTP服务器、模拟的数据库客户端)的统一管理。 -
信号处理与优雅退出:
appcore.App内部封装了对操作系统信号的监听和响应逻辑,确保应用在收到退出指令时能够有序地关闭各个组件。
示例项目运行步骤:
-
获取完整代码:从专栏提供的代码库中获取
app-skeleton-demo项目的完整源代码。 -
创建配置文件:在项目根目录下创建
configs/config.yaml文件,内容如下(或参考代码库中的示例):yaml appName: "MyModularDemoApp" logger: level: "info" httpServer: addr: ":8080" db: dsn: "simulated_user:simulated_pass@tcp(127.0.0.1:3306)/simulated_db"。 -
初始化Go模块并获取依赖:在
app-skeleton-demo根目录下运行
go mod init app-skeleton-demo # 如果代码库中没有go.mod,或者你想重新开始
go mod tidy # 获取必要的依赖,如 gopkg.in/yaml.v3
-
运行应用:在
app-skeleton-demo根目录下运行bash go run ./cmd/myapp/main.go -config ./configs/config.yaml。或者,如果你的配置文件路径与main.go中flag定义的默认值一致,可以直接运行bash go run ./cmd/myapp/main.go -
观察日志:控制台将输出各个组件的初始化、启动日志。HTTP服务器将在
http://localhost:8080上监听。 -
测试API(可选):如果你查看了代码库中
transport/http/server.go的实现,可以尝试访问其定义的API端点(例如,http://localhost:8080/api/user?id=123)。 -
优雅退出:在运行应用的终端中按下
Ctrl+C。观察应用如何捕获信号,并按顺序优雅地关闭各个组件,最后打印“Application MyModularDemoApp stopped gracefully.”(或类似的日志)。
最后,我们强烈建议你结合这一节的内容,仔细阅读并运行专栏配套GitHub代码库中的完整 app-skeleton-demo 示例。在代码库中,你可以看到:
-
internal/appcore/app.go如何实现App结构体,并在其New()方法中完成所有组件的手动依赖注入,以及如何在Run()方法中编排组件的启动、信号监听和优雅关闭逻辑。 -
各个模拟组件(如
internal/foundational/logger/logger.go、internal/client/database/client.go、internal/biz/user/service.go、internal/transport/http/server.go)是如何定义的,它们如何接收依赖,以及那些需要生命周期管理的组件是如何实现pkg/lifecycle.Component接口的Start()和Stop()方法的。 -
配置文件
configs/config.yaml如何驱动不同组件的配置。
小结
好了,关于Go应用骨架的设计与实践,我们就探讨到这里。我们以模块化/组件化驱动的骨架为蓝本(参考图1),详细“庖丁解牛”般地拆解了一个典型应用骨架的三大核心组成部分:
-
应用的启动:涵盖了初始化流程与顺序控制的考量、命令行参数的解析方法,以及配置加载与管理的最佳实践。
-
组件的编排:深入探讨了如何识别与定义核心组件(基础构件、基础服务客户端、业务组件、API服务器/Lifecycle组件),如何进行组件的初始化与编排,特别是通过依赖注入(尤其是构造函数注入和
google/wire的思想)来组装它们。 -
优雅的退出:详细阐述了为何需要优雅退出,以及如何通过捕获操作系统信号、运用
context进行超时与取消传播,来实现核心组件的有序关闭和资源清理。
最后,我们通过一个概念性的模块化应用骨架Demo项目的布局和核心入口代码,展示了这些理论是如何在实践中结合起来的,并引导你通过配套代码库进行更深入的学习和实践。
结合示意图和理论阐述,以及动手实践配套的完整代码示例,你将能够对一个典型的、模块化的Go应用骨架是如何从概念走向实践,如何将各个部分有机地组织起来,从而构建一个健壮、可维护的系统,有一个非常具体和深入的理解。这为你将来构建自己的Go应用或参与大型Go项目打下坚实的基础。
构建一个优秀的应用骨架,是一项既考验技术深度也考验架构能力的综合性工作。希望这节课的内容能为你点亮一盏明灯,让你在Go工程化的道路上走得更加稳健和自信。
思考题
假设你现在要从头开始设计一个中等规模的Go微服务,它需要对外提供HTTP API,对内可能需要与数据库、缓存以及另一个gRPC服务交互,并且需要处理一些异步消息。
-
你会选择或设计一种什么样的应用骨架模式(参考本讲讨论的模式,或提出自己的融合思路)?为什么?
-
请按照本讲讨论的基础构件、基础服务客户端、业务组件、API服务器/Lifecycle组件的分类,简要描述一下这个微服务的核心组件会有哪些?它们之间的依赖关系大致是怎样的?你会如何设计它们的初始化顺序,并通过怎样的依赖注入方式(手动或工具思路)将它们组装在应用核心实例(App Core Instance)中?
-
在优雅退出方面,你会特别关注哪些组件的关闭顺序和细节?
欢迎在留言区分享你的思考和设计!我是Tony Bai,我们下节课见。
核心组件:构建健壮Go服务的配置、日志与插件化方案(上)
你好,我是Tony Bai。
在上一节课,我们构建了Go应用的“龙骨”——应用骨架。它为程序提供了清晰的结构和可控的生命周期。然而,仅有骨架不足以支撑一个功能完备、稳定可靠的生产级服务。我们需要一系列核心组件来填充这个骨架,赋予其处理实际业务的能力。
接下来的两节课,我们将深入探讨Go应用中三个至关重要的核心组件:配置管理、日志系统,以及在特定场景下提升应用灵活性的插件化架构。
-
配置管理的优劣直接影响应用的部署灵活性、环境适应性以及运维效率。不当的配置管理会使项目难以维护,问题排查效率低下。
-
规范有效的日志系统是保障线上服务稳定运行、快速定位和解决问题的关键。缺乏结构化、信息全面的日志,会让我们在故障面前束手无策。
-
而当应用发展到一定阶段,需要支持更灵活的功能扩展或允许第三方集成时,一个设计良好的插件化架构能提供强大的支持。需要强调的是,插件化并非所有应用的必选项,它通常适用于那些对动态性、可扩展性有较高要求的复杂系统。
掌握这些核心组件(尤其是配置和日志这两个基础组件)的设计原则和最佳实践,对于提升Go应用的健壮性、可维护性和整体质量至关重要。
这节课,我们先深入配置管理的实践。从基础的配置方式出发,探讨如何整合命令行、环境变量、配置文件乃至远程配置中心(如Nacos)等多种来源,实现优先级管理、类型安全访问,并展望配置热加载机制。
我讲到的每一个核心组件,都会结合清晰的演进思路和关键的代码示例进行讲解,力求让你不仅掌握理论,更能将其有效应用于实际项目中。准备好了吗?让我们开始构建Go应用的强大核心组件吧!
配置,作为控制应用程序行为的关键数据集合,其重要性不言而喻。它涵盖了从数据库连接信息、服务监听端口,到特性开关、业务阈值等方方面面。一个设计良好、易于管理的配置系统,是确保应用在不同环境中稳定运行、灵活部署和高效运维的基石。
我们先来思考一个简单的问题:如果我的应用只有几个配置项,使用硬编码或简单全局变量可以吗?
在项目初期,或当配置项极少且固定不变时,直接在代码中硬编码配置值,或使用几个全局变量来存储,看似是最快捷的方式。
// ch23/config/initial/main.go
const defaultPort = ":8080"
var databaseDSN = "user:password@tcp(localhost:3306)/mydb" // 全局变量
func main() {
// ...
// http.ListenAndServe(defaultPort, nil)
// db, _ := sql.Open("mysql", databaseDSN)
// ...
}
然而,这种简单化的处理方式,随着应用规模的增长和部署环境的复杂化,其弊端会迅速暴露:
-
不灵活性:任何配置变更(如环境迁移、参数调整)都需要修改代码、重新编译和部署,效率低下且易引入错误。
-
安全风险:敏感信息(如密钥、密码)硬编码在源码中,存在安全隐患。
-
维护困难:配置分散,难以集中查找、理解和管理。
-
测试不便:难以模拟不同的配置场景进行测试。
显然,我们需要更系统、更健壮的配置管理方案。那么,一个“系统且健壮的配置管理方案”究竟应该具备哪些特性呢?它应该能够灵活地从多种来源获取配置,清晰地处理不同来源的优先级,提供类型安全的访问方式,并且在需要时能够动态更新。我们先从配置的来源谈起。
配置的来源与优先级:从命令行到多源融合
一个成熟的Go应用通常需要从多个来源获取配置信息,以适应不同的部署环境和运维需求,并且需要一套清晰的规则来决定当同一个配置项在不同来源中都有定义时,以哪个为准。
一个Go应用的配置来源通常有如下几个:
-
命令行参数:命令行参数由用户在启动应用时通过命令行直接传入,如
./myapp -port=8081,通常用于指定少量关键参数或临时覆盖某些参数。Go标准库的flag包可满足基本的命令行参数解析需求。对于复杂的命令行参数,可考虑使用spf13/cobra等库。 -
环境变量:从应用运行的操作系统环境中读取,如
MYAPP_PORT=8080 ./myapp。该配置来源在容器化(Docker、Kubernetes)和云原生部署中非常流行,便于环境隔离和动态注入。Go应用可通过os.Getenv()读取。 -
配置文件:将配置存储于外部文件(如JSON、YAML、TOML、INI等)是广泛使用的一种配置源方式,这种方式适合管理大量、结构化的配置项,易于编辑和版本控制。
-
远程配置中心:在一些分布式系统和需要配置统一管理的场景中,配置数据可以集中存储在远端服务,应用启动时拉取,并可支持动态更新。常用的远程配置中心有Nacos、etcd、Consul、Apollo等。
-
默认值:在代码中为配置项预设的合理默认值,作为所有其他来源都未提供时的兜底。
当配置项可能来自多个源时,必须有明确的优先级规则。常见的顺序(从高到低)是:
-
命令行参数
-
环境变量
-
远程配置中心
-
指定的配置文件
-
默认位置的配置文件
-
应用内置的默认值
实现这样的多源加载和优先级合并,手动处理会很复杂。幸运的是,成熟的配置库(如 spf13/viper)通常已内置了这些能力。
了解了配置的多种来源和它们之间的优先级关系后,我们接下来看看实际的配置加载与访问机制本身是如何从简单到复杂,逐步演进以满足更高要求的。
配置加载与访问的演进之路
配置系统的设计,往往会经历一个从简单到逐步完善的过程,以平衡易用性、灵活性、类型安全和性能。我们将通过几个阶段的示例来展示这个演进。
阶段一:全局变量法 + 结构体映射
这是很多项目起步时可能采用的方式,核心在于将配置文件内容直接映射到一个Go结构体上,并通过一个(通常是导出的)全局变量来持有这个配置实例。接下来,我们看看实现这个阶段配置加载与访问方法的示例步骤。
第一步定义 Config 结构体。 使用Go结构体对应配置文件结构,通过字段标签(如 yaml:"port")进行映射。
// ch23/config/stage1/config/config.go
type ServerConfig struct {
Port int `yaml:"port"`
Timeout string `yaml:"timeout"`
}
type DatabaseConfig struct {
DSN string `yaml:"dsn"`
}
type AppConfig struct {
AppName string `yaml:"appName"`
Server ServerConfig `yaml:"server"`
Database DatabaseConfig `yaml:"database"`
}
第二步加载并映射。 应用启动时读取配置文件,使用如 gopkg.in/yaml.v3 等库反序列化到 AppConfig 实例。
// ch23/config/stage1/config/config.go
var GlobalAppConfig *AppConfig
// LoadGlobalConfig loads configuration from the given file path into GlobalAppConfig.
func LoadGlobalConfig(filePath string) error {
data, err := os.ReadFile(filePath)
if err != nil {
return fmt.Errorf("stage1: failed to read config file %s: %w", filePath, err)
}
var cfg AppConfig
if err := yaml.Unmarshal(data, &cfg); err != nil {
return fmt.Errorf("stage1: failed to unmarshal config data: %w", err)
}
GlobalAppConfig = &cfg
fmt.Printf("[Stage1 Config] Loaded: AppName=%s, Port=%d\n", GlobalAppConfig.AppName, GlobalAppConfig.Server.Port)
return nil
}
第三步访问配置。 通过访问该(全局或注入的) AppConfig 实例的字段获取配置。
// ch23/config/stage1/main.go
func main() {
// 为了能直接运行,你可能需要调整配置文件路径,并确保文件存在
// 在实际项目中,这个路径通常来自命令行参数或固定位置
err := config.LoadGlobalConfig("app.yaml")
if err != nil {
log.Fatalf("Failed to load config: %v", err)
}
if config.GlobalAppConfig != nil {
fmt.Printf("Accessing config: AppName is '%s', Server Port is %d\n",
config.GlobalAppConfig.AppName, config.GlobalAppConfig.Server.Port)
fmt.Printf("Database DSN: %s\n", config.GlobalAppConfig.Database.DSN)
} else {
fmt.Println("Config was not loaded.")
}
}
这种方法有其明显的优缺点。 优点在于类型安全和访问的便利性。 配置项以强类型字段存在,确保了数据的准确性。同时,开发者可以通过结构体字段进行访问,这种方式在IDE中非常友好,能够提高编码效率。
然而,这种方法也带来了一些问题,就是 使用全局变量可能导致隐式依赖,测试变得困难,并且难以管理配置的生命周期。此外,强耦合的问题也不容忽视,消费方直接依赖于 config.GlobalAppConfig 的具体类型,这限制了系统的灵活性。
尽管这种方法简单,但在大型项目中,很快就会成为瓶颈。因此,我们不禁思考,是否可以将配置的实现细节隐藏起来,只暴露必要的API,从而提高系统的可维护性和灵活性呢?
阶段二:封装配置读取API
为了解耦配置的消费者与配置的具体存储结构,并提供更灵活的访问方式(例如,通过类似 "server.port" 这样的字符串路径),我们可以封装一层配置读取API(基于反射的section.key访问)。早期的一种尝试可能是通过反射来遍历结构体字段及其标签,实现根据 section.key 字符串查找配置值。
首先,我们在阶段一的 config.go 中增加 GetByPath 和类型化Getter。
// ch23/config/stage2/config/config.go
package config
import (
"fmt"
"os"
"reflect"
"strconv"
"strings"
"gopkg.in/yaml.v3"
)
// AppConfig, ServerConfig, DatabaseConfig 结构体定义同stage1
var currentAppConfig *AppConfig // 包级私有变量
// Load loads configuration from the given file path.
func Load(filePath string) error {
data, err := os.ReadFile(filePath)
if err != nil {
return fmt.Errorf("stage2: failed to read config file %s: %w", filePath, err)
}
var cfg AppConfig
if err := yaml.Unmarshal(data, &cfg); err != nil {
return fmt.Errorf("stage2: failed to unmarshal config data: %w", err)
}
currentAppConfig = &cfg
fmt.Printf("[Stage2 Config] Loaded: AppName=%s, Port=%d\n", currentAppConfig.AppName, currentAppConfig.Server.Port)
return nil
}
// GetByPath retrieves a configuration value by a dot-separated path.
// This is a simplified example using reflection and has performance implications.
func GetByPath(path string) (interface{}, bool) {
if currentAppConfig == nil {
return nil, false
}
parts := strings.Split(path, ".")
v := reflect.ValueOf(*currentAppConfig) // Dereference pointer
for _, part := range parts {
if v.Kind() == reflect.Ptr { // Should not happen with currentAppConfig being value
v = v.Elem()
}
if v.Kind() != reflect.Struct {
return nil, false
}
found := false
// Case-insensitive field matching for flexibility, or use tags
var matchedField reflect.Value
for i := 0; i < v.NumField(); i++ {
fieldName := v.Type().Field(i).Name
yamlTag := v.Type().Field(i).Tag.Get("yaml")
if strings.EqualFold(fieldName, part) || yamlTag == part {
matchedField = v.Field(i)
found = true
break
}
}
if !found {
return nil, false
}
v = matchedField
}
if v.IsValid() && v.CanInterface() {
return v.Interface(), true
}
return nil, false
}
// GetString provides a typed getter for string values.
func GetString(path string) (string, bool) {
val, ok := GetByPath(path)
if !ok {
return "", false
}
s, ok := val.(string)
return s, ok
}
// GetInt provides a typed getter for int values.
func GetInt(path string) (int, bool) {
val, ok := GetByPath(path)
if !ok {
return 0, false
}
// Handle if it's already int or can be parsed from string
switch v := val.(type) {
case int:
return v, true
case int64: // YAML might unmarshal numbers as int64
return int(v), true
case float64: // YAML might unmarshal numbers as float64
return int(v), true
case string:
i, err := strconv.Atoi(v)
if err == nil {
return i, true
}
}
return 0, false
}
之后,我们可以在 main.go 中按如下方式使用:
// ch23/config/stage2/main.go
package main
import (
"ch23/config/stage2/config"
"fmt"
"log"
)
func main() {
err := config.Load("./app.yaml")
if err != nil {
log.Fatalf("Failed to load config: %v", err)
}
appName, ok := config.GetString("appName")
if ok {
fmt.Printf("appName from GetString: %s\n", appName)
} else {
fmt.Println("appName not found or not a string.")
}
port, ok := config.GetInt("server.port")
if ok {
fmt.Printf("server.port from GetInt: %d\n", port)
} else {
fmt.Println("server.port not found or not an int.")
}
-, ok := config.GetString("server.host")
if !ok {
fmt.Println("server.host (non-existent) correctly not found.")
}
}
这种基于反射的动态路径访问方法具有其独特的优缺点。优点在于调用方的解耦, 调用者只需了解配置项的路径字符串,无需关注具体实现,从而提高了灵活性。
然而,这种灵活性是以性能为代价的。反射的使用会带来性能开销,对于对性能敏感的路径访问来说并不友好。此外,尽管可以通过类型化的Getter部分缓解类型断言的问题,但实现过程仍然较为繁琐。因此,虽然这种方法在启动时一次性读取配置时表现良好,但如果配置项在运行时被频繁访问,就需要进一步的优化,以确保系统的高效性。
阶段三:基于索引的快速 section.key 访问
为了解决反射带来的性能问题,可以在配置加载完成后,预先将所有配置项“打平”并存入一个 map[string]interface{} 作为索引。后续的配置访问就变成了高效的map查找。
我们在 config.go 中增加索引构建和基于索引的Getter。
// ch23/config/stage3/config/config.go
... ...
// AppConfig, ServerConfig, DatabaseConfig 结构体定义同stage1
var (
currentAppConfig *AppConfig
configIndex = make(map[string]interface{})
)
// Load loads configuration and builds an index for fast access.
func Load(filePath string) error {
data, err := os.ReadFile(filePath)
if err != nil {
return fmt.Errorf("stage3: failed to read config file %s: %w", filePath, err)
}
var cfg AppConfig
if err := yaml.Unmarshal(data, &cfg); err != nil {
return fmt.Errorf("stage3: failed to unmarshal config data: %w", err)
}
currentAppConfig = &cfg
buildIndex("", reflect.ValueOf(*currentAppConfig)) // Build index after loading
fmt.Printf("[Stage3 Config] Loaded and indexed: AppName=%s, Port=%d\n", currentAppConfig.AppName, currentAppConfig.Server.Port)
return nil
}
func buildIndex(prefix string, rv reflect.Value) {
if rv.Kind() == reflect.Ptr {
rv = rv.Elem()
}
if rv.Kind() != reflect.Struct {
return
}
typ := rv.Type()
for i := 0; i < rv.NumField(); i++ {
fieldStruct := typ.Field(i)
fieldVal := rv.Field(i)
// Use YAML tag as key part, fallback to lowercase field name
keyPart := fieldStruct.Tag.Get("yaml")
if keyPart == "" {
keyPart = strings.ToLower(fieldStruct.Name)
}
if keyPart == "-" { // Skip fields Wärme `yaml:"-"`
continue
}
currentPath := keyPart
if prefix != "" {
currentPath = prefix + "." + keyPart
}
if fieldVal.Kind() == reflect.Struct {
buildIndex(currentPath, fieldVal)
} else if fieldVal.CanInterface() {
configIndex[currentPath] = fieldVal.Interface()
}
}
}
// GetByPathFromIndex retrieves a value from the pre-built index.
func GetByPathFromIndex(path string) (interface{}, bool) {
if currentAppConfig == nil { // Ensure config was loaded
return nil, false
}
val, ok := configIndex[strings.ToLower(path)] // Normalize path to lowercase for lookup
return val, ok
}
// GetString, GetInt methods now use GetByPathFromIndex
func GetString(path string) (string, bool) {
val, ok := GetByPathFromIndex(path)
if !ok { return "", false }
s, ok := val.(string)
return s, ok
}
func GetInt(path string) (int, bool) {
val, ok := GetByPathFromIndex(path)
if !ok { return 0, false }
switch v := val.(type) {
case int: return v, true
case int64: return int(v), true // Common for YAML numbers
case float64: return int(v), true // Common for YAML numbers
case string:
i, err := strconv.Atoi(v)
if err == nil { return i, true }
}
return 0, false
}
main.go 中的使用方式与Stage2相同,但内部实现已优化。
这种方法在访问性能上显著提升,通过高效的map查找实现快速访问,这是其主要优点。然而,值得注意的是, 初始化时需要构建索引,这会带来一定的开销,尽管通常这个开销是可以接受的。此外,对于非常复杂的嵌套结构,如数组内嵌结构体,打平逻辑可能需要更精细的处理。
通过这三个阶段的演进,我们逐步解决了一些核心问题(如类型安全、灵活访问、访问性能),但同时也引入了实现的复杂度(如手动构建索引、处理各种类型转换)。这引出了一个自然的问题:为何不直接使用社区已经打磨好的成熟方案呢?这种选择可能会减少开发成本,并提高系统的稳定性和可维护性。
之所以我们花时间从阶段一(简单结构体映射)逐步演进到阶段三(基于索引的快速访问),是为了帮助你理解那些成熟的第三方配置库(如我们接下来要讨论的Viper)是如何一步步解决这些核心问题的。这些成熟方案的设计思路和演进过程,在很大程度上也遵循了类似的思考路径: 从满足基本需求,到优化性能,再到提供更灵活和健壮的API。 通过理解这个演进过程,你能更深刻地体会到这些库为何如此设计,以及它们为你解决了哪些潜在的“坑”。
接下来,我们就来看看这类成熟方案的代表。
阶段四:拥抱成熟第三方库
上述演进过程实际上揭示了构建一个强大配置库所需要考虑的许多方面(多源、优先级、类型安全访问、嵌套路径、性能等)。幸运的是,Go社区已经有了非常成熟和流行的第三方配置管理库,其中最著名的之一就是 spf13/viper。 spf13/viper 核心能力有如下几点:
-
多配置源与格式:支持JSON、YAML、TOML、INI、HCL等文件格式,以及环境变量、命令行参数(通过
pflag集成)、远程配置源(需配合对应Provider)、代码内设置的默认值。 -
优先级管理:内置对不同来源配置的优先级合并。
-
类型安全的访问:提供如
viper.GetString("database.dsn"),viper.GetInt("server.port")等类型化Getter。 -
Unmarshal到结构体:方便地将配置反序列化到Go结构体。
-
嵌套路径访问:支持点分隔路径(如
server.http.port)。 -
配置热加载(Watch):监控配置文件变化并自动重新加载。
下面,我们就用viper来改造一下配置的加载与访问,首当其冲的是config.go中的配置项定义与配置加载实现,代码如下:
// ch23/config/stage4/config/config.go
package config
import (
"fmt"
"strings"
"github.com/spf13/pflag"
"github.com/spf13/viper"
)
// AppConfig, ServerConfig, DatabaseConfig 结构体定义同stage1
// 但需要使用 `mapstructure` 标签以供 Viper Unmarshal
type ServerConfig struct {
Port int `mapstructure:"port"`
Timeout string `mapstructure:"timeout"`
}
type DatabaseConfig struct {
DSN string `mapstructure:"dsn"`
}
type AppConfig struct {
AppName string `mapstructure:"appName"`
Server ServerConfig `mapstructure:"server"`
Database DatabaseConfig `mapstructure:"database"`
}
// ViperInstance 是一个导出的 viper 实例,方便在应用中其他地方按需获取配置
// 或者,你也可以将 Load 返回的 AppConfig 实例通过 DI 传递
var ViperInstance *viper.Viper
func init() {
ViperInstance = viper.New()
}
// LoadConfigWithViper initializes and loads configuration using Viper.
func LoadConfigWithViper(configPath string, configName string, configType string) (*AppConfig, error) {
v := ViperInstance // Use the global instance or a new one
// 1. 设置默认值
v.SetDefault("server.port", 8080)
v.SetDefault("appName", "DefaultViperAppFromCode")
// 2. 绑定命令行参数 (使用 pflag)
// pflag 的定义通常在 main 包的 init 中,或者一个集中的 flag 定义文件
// 这里为了示例完整性,假设已定义并 Parse
if pflag.Parsed() { // Ensure flags are parsed before binding
err := v.BindPFlags(pflag.CommandLine)
if err != nil {
return nil, fmt.Errorf("stage4: failed to bind pflags: %w", err)
}
} else {
fmt.Println("[Stage4 Config] pflag not parsed, skipping BindPFlags. Ensure pflag.Parse() is called in main.")
}
// 3. 绑定环境变量
v.SetEnvPrefix("MYAPP") // e.g., MYAPP_SERVER_PORT, MYAPP_DATABASE_DSN
v.AutomaticEnv() // Automatically read matching env variables
v.SetEnvKeyReplacer(strings.NewReplacer(".", "_")) // server.port -> SERVER_PORT
// 4. 设置配置文件路径和类型
if configPath != "" {
v.AddConfigPath(configPath) // 如 "./configs"
}
v.AddConfigPath("$HOME/.myapp") // HOME目录
v.AddConfigPath(".") // 当前工作目录
v.SetConfigName(configName) // "app" (不带扩展名)
v.SetConfigType(configType) // "yaml"
// 5. 读取配置文件
if err := v.ReadInConfig(); err != nil {
if _, ok := err.(viper.ConfigFileNotFoundError); ok {
// 配置文件未找到是可接受的,可能依赖环境变量或默认值
fmt.Printf("[Stage4 Config] Config file '%s.%s' not found in search paths; relying on other sources.\n", configName, configType)
} else {
// 其他读取配置文件的错误
return nil, fmt.Errorf("stage4: failed to read config file: %w", err)
}
} else {
fmt.Printf("[Stage4 Config] Using config file: %s\n", v.ConfigFileUsed())
}
// 6. Unmarshal到结构体
var cfg AppConfig
if err := v.Unmarshal(&cfg); err != nil {
return nil, fmt.Errorf("stage4: failed to unmarshal config to struct: %w", err)
}
fmt.Printf("[Stage4 Config] Successfully loaded and unmarshalled. AppName: %s, ServerPort: %d, DBDsn: %s\n",
cfg.AppName, cfg.Server.Port, cfg.Database.DSN)
return &cfg, nil
}
main.go 文件的变更如下:
// ch23/config/stage4/main.go
package main
import (
"ch23/config/stage4/config"
"fmt"
"log"
"os" // For setting environment variables for testing
"github.com/spf13/pflag"
)
var (
// Define flags using pflag for Viper integration
port = pflag.IntP("port", "p", 0, "HTTP server port (from pflag)")
appName = pflag.String("appname", "", "Application name (from pflag)")
// It's better to use a config file path flag if viper needs to load a specific file
// rather than individual config item flags, but this shows direct flag binding.
)
func main() {
pflag.Parse() // Must be called before Viper binds flags
// Simulate setting environment variables for testing
os.Setenv("MYAPP_SERVER_TIMEOUT", "60s") // This will be mapped to server.timeout if struct has it
os.Setenv("MYAPP_DATABASE_DSN", "env_user:env_pass@tcp(env_host:3306)/env_db")
cfg, err := config.LoadConfigWithViper("./", "app", "yaml")
if err != nil {
log.Fatalf("Failed to load config with Viper: %v", err)
}
fmt.Println("\n--- Final Configuration ---")
fmt.Printf("AppName: %s\n", cfg.AppName)
fmt.Printf("Server Port: %d\n", cfg.Server.Port)
fmt.Printf("Server Timeout: %s\n", cfg.Server.Timeout)
fmt.Printf("Database DSN: %s\n", cfg.Database.DSN)
fmt.Println("\n--- Accessing directly from Viper instance ---")
// Note: Viper keys are case-insensitive by default for Get, but exact for Unmarshal via mapstructure tags
fmt.Printf("Viper AppName: %s\n", config.ViperInstance.GetString("appName"))
fmt.Printf("Viper Server Port: %d\n", config.ViperInstance.GetInt("server.port"))
fmt.Printf("Viper DB DSN: %s\n", config.ViperInstance.GetString("database.dsn"))
fmt.Printf("Viper Server Timeout (from env): %s\n", config.ViperInstance.GetString("server.timeout"))
// Example of how pflag overrides if a value was set
if *port > 0 { // pflag gives 0 if not set for IntP
fmt.Printf("Pflag --port was set, it has high priority: %d (reflected in cfg.Server.Port if names match or bound)\n", *port)
}
}
之后,你可以试着带命令行参数或环境变量运行,查看配置源优先级对最终配置加载结果的影响:
$ go run main.go -p 9999 --appname="CmdLineApp"
$ MYAPP_SERVER_PORT=7777 MYAPP_APPNAME="EnvApp" go run main.go
Viper这类库集成了社区在配置管理上的大量最佳实践,使我们能高效管理来自命令行、环境变量、本地配置文件等各种来源的配置项,并处理好它们之间的优先级。
通过这几个阶段的演进,我们从最基础的配置方式逐步走向了一个功能强大、来源多样、访问便捷的配置解决方案。理解这个演进过程,有助于我们根据项目的实际需求选择或设计合适的配置管理策略。
然而,仅仅在应用启动时加载一次配置,在很多现代应用场景下可能还不够。当应用需要长时间运行,并且其行为可能需要根据外部变化(例如,特性开关的调整、依赖服务地址的变更)进行动态调整时,我们就需要一种机制,让应用能够在不重启的情况下感知并应用这些配置的变更。这就是我们接下来要探讨的——配置热加载。
配置热加载:让应用动态适应变化
配置热加载允许应用在运行时动态地感知并应用配置的变更,而无需停止和重启服务。这对于提升运维灵活性、实现A/B测试、快速响应线上调整等场景至关重要。
实现可靠的配置热加载,主要需要解决以下问题:如何及时检测配置变更?如何安全地更新应用内部的配置状态(尤其要考虑并发)?如何通知并让依赖配置的组件平滑过渡到新配置等?下面我们给出两种常见的场景的热加载实现思路与示例。
基于本地文件监控实现热加载
第一个就是基于配置文件的热加载场景。 spf13/viper 提供了 WatchConfig() 方法,它底层通常使用像 fsnotify 这样的库来监控本地配置文件的文件系统事件。当检测到配置文件被修改时,Viper 会自动重新读取并解析该文件,并可以通过 viper.OnConfigChange(func(e fsnotify.Event) { ... }) 注册一个回调函数来处理配置变更。
下面是一个完整的示例,演示了如何使用Viper监控本地YAML文件的变化,并在变化时热加载配置。示例的配置结构体定义如下:
// ch23/config/hotload/viper/config/config.go
package config
// FeatureFlags holds boolean flags for features.
type FeatureFlags struct {
NewAuth bool `mapstructure:"newAuth"`
ExperimentalAPI bool `mapstructure:"experimentalApi"`
}
// ServerConfig holds server specific configurations.
type ServerConfig struct {
Port int `mapstructure:"port"`
TimeoutSeconds int `mapstructure:"timeoutSeconds"`
}
// AppConfig is the root configuration structure.
type AppConfig struct {
AppName string `mapstructure:"appName"`
LogLevel string `mapstructure:"logLevel"`
FeatureFlags FeatureFlags `mapstructure:"featureFlags"`
Server ServerConfig `mapstructure:"server"`
}
热加载的核心逻辑在ch23/config/hotload/viper/hotloader/loader.go文件中实现:
// ch23/config/hotload/viper/hotloader/loader.go
package hotloader
import (
"ch23/hotload/viper/config" // Adjust import path if your module name is different
"fmt"
"log"
"sync"
"time"
"github.com/fsnotify/fsnotify"
"github.com/spf13/viper"
)
// SharedConfig holds the current application configuration.
// It's protected by a RWMutex for concurrent access.
type SharedConfig struct {
mu sync.RWMutex
cfg *config.AppConfig
}
// Get returns a copy of the current config to avoid race conditions on the caller's side
// if they hold onto it while it's being updated. Or, caller can use its methods.
func (sc *SharedConfig) Get() config.AppConfig {
sc.mu.RLock()
defer sc.mu.RUnlock()
if sc.cfg == nil { // Should not happen if initialized properly
return config.AppConfig{}
}
return *sc.cfg // Return a copy
}
// Update atomically updates the shared configuration.
func (sc *SharedConfig) Update(newCfg *config.AppConfig) {
sc.mu.Lock()
defer sc.mu.Unlock()
sc.cfg = newCfg
log.Printf("[HotLoader] Configuration updated: %+v\n", *sc.cfg)
}
// GetLogLevel is an example of a type-safe getter.
func (sc *SharedConfig) GetLogLevel() string {
sc.mu.RLock()
defer sc.mu.RUnlock()
if sc.cfg == nil {
return "info" // Default
}
return sc.cfg.LogLevel
}
// IsFeatureEnabled is another example.
func (sc *SharedConfig) IsFeatureEnabled(featureKey string) bool {
sc.mu.RLock()
defer sc.mu.RUnlock()
if sc.cfg == nil {
return false
}
// This is a simplified check; a real app might have more robust feature flag access
switch featureKey {
case "newAuth":
return sc.cfg.FeatureFlags.NewAuth
case "experimentalApi":
return sc.cfg.FeatureFlags.ExperimentalAPI
default:
return false
}
}
// InitAndWatchConfig initializes Viper, loads initial config, and starts watching for changes.
// It returns a SharedConfig instance that can be safely accessed by the application.
func InitAndWatchConfig(configDir string, configName string, configType string) (*SharedConfig, *viper.Viper, error) {
v := viper.New()
v.AddConfigPath(configDir)
v.SetConfigName(configName)
v.SetConfigType(configType)
// Initial read of the config file
if err := v.ReadInConfig(); err != nil {
if _, ok := err.(viper.ConfigFileNotFoundError); ok {
return nil, nil, fmt.Errorf("config file not found: %w", err)
}
return nil, nil, fmt.Errorf("failed to read config: %w", err)
}
var initialCfg config.AppConfig
if err := v.Unmarshal(&initialCfg); err != nil {
return nil, nil, fmt.Errorf("failed to unmarshal initial config: %w", err)
}
log.Printf("[HotLoader] Initial configuration loaded: %+v\n", initialCfg)
sharedCfg := &SharedConfig{
cfg: &initialCfg,
}
// Start watching for config changes in a separate goroutine
go func() {
v.WatchConfig() // This blocks internally or uses a goroutine, check Viper docs
log.Println("[HotLoader] Viper WatchConfig started.")
v.OnConfigChange(func(e fsnotify.Event) {
log.Printf("[HotLoader] Config file changed: %s (Op: %s)\n", e.Name, e.Op)
// It's crucial to re-read and re-unmarshal the config
// as v.ReadInConfig() is needed to refresh Viper's internal state from the file.
if err := v.ReadInConfig(); err != nil {
log.Printf("[HotLoader] Error re-reading config after change: %v", err)
// Decide on error handling: revert, keep old, or panic?
// For simplicity, we keep the old config.
return
}
var newCfgInstance config.AppConfig
if err := v.Unmarshal(&newCfgInstance); err != nil {
log.Printf("[HotLoader] Error unmarshaling new config: %v", err)
// Keep the old config if unmarshaling fails
return
}
sharedCfg.Update(&newCfgInstance)
})
}()
return sharedCfg, v, nil
}
主程序你可以在 ch23/config/hotload/viper/main.go 中找到,这里就不贴出其代码了。
我们可以按下面操作步骤来验证基于viper的配置文件动态加载效果,先运行main.go:
$go run main.go
然后在应用运行时,尝试修改 configs/app.yaml 文件中的内容(例如,改变 logLevel 或 featureFlags.newAuth 的值)并保存。
观察控制台输出,你会看到Viper检测到文件变更,并重新加载配置, SharedConfig 中的值也会相应更新,从而在下一次Ticker触发时打印出新的配置值。
这种基于文件监控的热加载机制,在Kubernetes等云原生环境中依然有其用武之地。当配置文件通过ConfigMap挂载到Pod的文件系统中时,如果ConfigMap发生变更,Kubernetes会更新Pod内对应的挂载文件(这可能有一个延迟)。这个文件更新事件同样可以被 fsnotify(Viper底层使用)捕获,从而触发应用内的配置热加载。这是一种实现运行时配置更新的常见方式,而无需重启Pod。
另外一个常见的场景则是基于远程配置中心实现热加载,我们来简要看看。
基于远程配置中心实现热加载
当配置存储在远程配置中心(如etcd、Consul、Nacos、Apollo)时,我们通常有两种热加载的实现方式,一种是利用viper这样的配置框架实现。
以 spf13/viper 为例,它通过其 remote 包和可插拔的远程Provider机制,支持某些配置中心的配置变更监听。具体的实现方式和能力取决于所使用的远程Provider。某些Provider可能支持 viper.WatchRemoteConfig() 或 viper.WatchRemoteConfigOnChannel() 方法,当远程配置发生变化时,Viper会尝试重新拉取配置,并像本地文件变更一样,触发 OnConfigChange 回调(如果已注册)。例如,使用一个支持Watch的Viper etcd Provider 时,当etcd中对应的配置键值发生变化,Provider会通知Viper,从而触发热加载流程。确保引入正确的etcd Provider,并按照相关文档配置Viper。
另外一种,则是通过主流的配置中心(如Nacos、etcd、Apollo、Consul)自己提供的Go SDK。
这些SDK直接支持监听配置变更并执行回调函数。例如,Nacos的Go SDK( github.com/nacos-group/nacos-sdk-go/v2)提供了 ListenConfig API,应用客户端可以通过该API订阅特定配置的变更。当Nacos服务器上的配置被修改并发布后,SDK会通知应用,并执行开发者提供的 OnChange 回调函数。在此回调中,开发者可以获取最新的配置字符串,解析并更新内存中的配置实例,最终通知相关组件。
类似地,etcd的Go客户端库( go.etcd.io/etcd/client/v3)提供了 Watch API,允许应用对存储配置的特定key或前缀设置Watch。当这些key的值发生变化时,etcd服务器会通过Watch通道将变更事件推送给客户端,应用在收到事件后解析并应用新配置。
使用配置中心自身的SDK进行热加载通常能提供更细致的控制和更及时的变更通知,但开发者可能需要自行处理更多与配置解析、应用和组件通知相关的逻辑。在国内,Nacos因其功能丰富且与Java生态结合紧密,在Go项目中作为配置中心和实现配置热加载也相当流行。
不过无论是上述哪种场景,在实现热加载时,有几个核心挑战和注意事项需要特别强调。
首先,确保线程安全是至关重要的。在更新内存中的配置实例时,必须保证操作的线程安全性,以避免潜在的并发问题。其次,组件的状态更新也非常关键。组件需要能够响应配置的变更,并安全地更新其内部状态或行为,这样才能确保系统的稳定性和可靠性。
此外,在应用新配置之前,最好有一个验证机制,以确保新配置的有效性。如果出现问题,还需考虑如何回滚到上一个已知良好的配置,以减少对系统的影响。最后,明确哪些配置项支持动态更新,哪些变更仍然需要服务重启也是非常重要的。这种部分热加载的策略可以帮助优化系统的运行效率,并降低服务中断的风险。
小结
我们首先深入探讨了配置管理。从最初简单的硬编码和全局变量的局限性出发,我们沿着一条演进的路径,学习了如何整合命令行参数、环境变量、配置文件乃至远程配置中心(如etcd、Nacos)等多种配置源,理解了优先级策略的重要性。我们借鉴了从手动解析到利用结构体映射,再到封装API(如 section.key 访问及其优化),最终引出了像 spf13/viper 这样成熟第三方库的核心设计思想,并探讨了它们如何支持远程配置源。特别地,我们还详细讨论了配置热加载的需求、核心挑战以及基于本地文件监控(以Viper为例)和远程配置中心(如etcd、Nacos)的实现思路。
思考题
-
配置与日志的综合应用:假设你正在设计一个需要对接多种第三方服务(如不同的支付渠道、不同的短信服务商)的Go应用。你会如何设计其配置结构来管理这些第三方服务的不同参数(如API Key、URL、超时等)?在日志方面,当调用这些第三方服务时,你会重点记录哪些结构化信息(考虑使用
slog.Attr),以便于问题排查和SLA监控?你会选择log/slog还是其他方案,为什么? -
插件化选型思考:如果你的应用(例如一个内容管理系统CMS)需要允许网站管理员通过安装不同的“功能模块”(例如,SEO优化工具、评论系统、电商购物车模块)来扩展网站功能,你会倾向于选择哪种插件化架构模式来实现这个需求?请阐述你选择的主要理由,并简要说明主应用与这些“功能模块”插件之间可能的交互方式。
欢迎在留言区分享你的思考和见解!我是Tony Bai,我们下节课见。
核心组件:构建健壮Go服务的配置、日志与插件化方案(下)
你好,我是Tony Bai。
上节课,我们深入配置管理的实践,学习了如何整合命令行参数、环境变量、配置文件乃至远程配置中心等多种配置源,理解了优先级策略的重要性。
这节课,我们接着聚焦日志最佳实践。分析传统日志记录的不足,明确现代日志系统的核心要素(结构化、级别、上下文、输出目标等),并重点讲解Go 1.21+ 官方推出的结构化日志库 log/slog。我们还会结合“标准库优先,按需拓展”的理念进行讨论。
最后,我们将探讨插件化架构。从Go原生 plugin 包的能力与局限出发,借鉴社区经验,总结几种在Go应用中更实用、更常见的插件化设计模式,并分析其适用场景,帮助你判断何时以及如何为应用引入插件化能力。
日志最佳实践与 log/slog 详解
如果说配置是应用行为的指南,那么日志系统就是应用运行状态的忠实记录者。 它记录下应用运行过程中的关键事件、状态变化、错误信息以及调试线索。没有高质量的日志,线上服务一旦出现问题,开发者就难以快速有效地定位和解决。
那么,如果让 fmt.Println 和标准库 log 包打天下,会有什么问题?
在学习Go的初期,或者编写一些简单的脚本时,我们可能习惯于使用 fmt.Println() 或标准库的 log.Println() 来输出信息。
// ch23/logging/simple/main.go
package main
import (
"fmt"
"log"
"os"
)
func doSomething() error {
// ... 模拟操作 ...
return fmt.Errorf("simulated error: something went wrong")
}
func main() {
fmt.Println("Application starting...") // 直接输出到 Stdout
// 配置标准库 log
log.SetOutput(os.Stdout) // 通常默认是 Stderr,这里改为 Stdout 方便观察
log.SetFlags(log.LstdFlags | log.Lmicroseconds | log.Lshortfile)
log.Println("Standard logger configured.")
err := doSomething()
if err != nil {
// 不同的输出方式
fmt.Printf("Output with fmt.Printf: Error occurred: %v\n", err)
log.Printf("Output with log.Printf: Error occurred: %v\n", err)
}
fmt.Println("Application finished.")
}
运行后,这个示例的输出可能如下:
$go run main.go
Application starting...
2025/05/24 19:56:11.449705 main.go:20: Standard logger configured.
Output with fmt.Printf: Error occurred: simulated error: something went wrong
2025/05/24 19:56:11.449854 main.go:26: Output with log.Printf: Error occurred: simulated error: something went wrong
Application finished.
这种方式对于临时调试或非常简单的应用可能够用,但对于生产级服务,其弊端显而易见:
-
非结构化:
fmt.Println和标准库log默认输出的是纯文本字符串。**当日志量巨大时,从中筛选、聚合、分析特定信息变得极其困难。机器难以解析,人工阅读效率也低。 -
没有日志级别:所有的输出信息“待遇”相同。我们无法区分哪些是调试信息(Debug),哪些是常规流程信息(Info),哪些是警告(Warn),哪些是错误(Error)。在生产环境,我们通常不希望看到大量的调试信息,但在排查问题时又需要它们。
-
缺乏上下文信息:日志条目通常是孤立的。我们很难将一条日志与特定的用户请求、业务事务或分布式调用链关联起来。这使得追踪一个完整流程的执行路径和状态变化变得困难。
-
功能单一,难以扩展:标准库
log功能非常基础,不支持自定义格式化、多种输出目标、日志轮转等高级特性。
因此,要构建一个健壮、可观测的Go服务,我们需要一个更现代、更强大的日志解决方案。那么,一个现代化的日志系统应该具备哪些关键特征呢?下面我们就来全面系统了解一下。
现代日志系统的核心要素
一个设计良好的现代日志系统,通常应具备以下核心要素:
- 结构化日志(Structured Logging)是最核心的一点。结构化日志意味着每条日志记录不再是简单的文本字符串,而是具有明确 schéma 的数据结构,通常是JSON格式或key-value对格式。
// 示例:一条结构化的JSON日志
{
"timestamp": "2023-10-27T10:30:15.123Z",
"level": "ERROR",
"message": "Failed to process payment",
"service": "payment-service",
"trace_id": "abc-123-xyz-789",
"user_id": "user-456",
// ... 更多业务相关字段 ...
}
它极易被机器解析、索引和查询,便于开发者利用日志管理工具(如ELK Stack、Grafana Loki、VictoriaLogs等)进行高效的日志聚合、搜索、过滤、可视化和告警。
-
日志级别(Log Levels):通过为日志消息设置不同的严重级别(如DEBUG、INFO、WARN、ERROR、FATAL/CRITICAL),可以控制在不同环境下实际输出的日志量,便于信息过滤。
-
上下文信息(Contextual Information):在日志中包含丰富的上下文,如时间戳、服务名、主机名、请求ID、Trace ID、用户ID、业务ID等,能将分散的日志条目串联起来,还原完整的业务流程或问题场景。
-
可配置的输出目标(Outputs/Sinks):日志系统应支持将日志输出到不同的目标。
-
控制台(Stdout/Stderr):便于开发调试和容器日志收集。
-
本地文件(Local Files):持久化日志,常用于传统部署。
-
集中式日志收集系统/消息队列:如ELK Stack的Logstash/Fluentd、Kafka、NATS等。这是构建可观测性的重要一环,将日志集中后,可以方便地与Metrics、Tracing联动分析,提供对系统行为更全面的洞察。如果日志中包含了关键的业务指标或错误计数,它们甚至可以被日志分析系统提取出来,间接贡献给Metrics系统。
-
-
性能考量(Performance):日志记录不应成为应用瓶颈(例如,通过异步写入、避免不必要的反射和内存分配来优化)。
-
日志轮转与归档(Log Rotation & Archiving):当日志输出到本地文件时,必须有机制来防止日志文件无限增长,通常通过专门的库或外部工具实现。
具备了这些核心要素,我们的日志系统才能真正成为应用稳定运行的得力助手。了解了理想状态后,我们来看看在Go语言中,日志方案是如何一步步发展,并最终催生出官方的log/slog库的。
日志方案的演进:从第三方库的启示到拥抱 log/slog
在Go官方推出log/slog之前,Go社区在日志库方面已经有了非常丰富的实践和探索,其中不乏一些设计优秀、广受欢迎的第三方库。它们不仅解决了标准库log的诸多不足,也为slog的最终设计提供了宝贵的经验和启示。下面我们就先来简要回顾一下这些第三方库的贡献。
sirupsen/logrus
logrus可能是早期最流行的Go结构化日志库之一。它API设计与标准库log包高度兼容,使得迁移成本较低。提供了日志级别、JSON/Text格式化,以及通过Hook机制扩展输出目标(如发送到Sentry、Syslog等)的能力。
下面是logrus的使用示例代码片段,完整示例参见ch23/logging/logrus_example/main.go。
// import "github.com/sirupsen/logrus"
// logrus.SetFormatter(&logrus.JSONFormatter{})
// logrus.WithFields(logrus.Fields{
// "animal": "walrus",
// "size": 10,
// }).Info("A group of walrus emerges from the ocean")
运行示例,可以得到类似下面输出结果:
{"level":"info","msg":"A group of walrus emerges from the ocean","time":"2025-05-24T20:13:54.068+08:00"}
{"level":"warning","msg":"The group is larger than expected","time":"2025-05-24T20:13:54.068+08:00"}
{"action":"swim","animal":"walrus","level":"error","msg":"Failed to count all walruses","size":10,"time":"2025-05-24T20:13:54.068+08:00"}
Logrus推广了结构化日志和可扩展性的理念,但其基于 interface{} 的 Fields 和反射的使用,在高性能场景下存在一些开销。
uber-go/zap
zap库由Uber开源,专为高性能和低(零)分配而设计。它通过避免使用 interface{}(而是采用强类型的 zap.Field 构造函数如 zap.String()、 zap.Int())、几乎不使用反射,以及大量使用 sync.Pool 等技巧,实现了极致的日志记录性能。它提供了Logger(高性能,但API略繁琐)和SugaredLogger(性能稍逊,但API更接近fmt.Printf和logrus,更易用)两种API。
下面是zap的使用示例代码片段,完整示例代码见ch23/logging/zap_example/main.go。
// import "go.uber.org/zap"
// import "time"
// logger, _ := zap.NewProduction() // JSON格式, INFO级别以上
// defer logger.Sync() // Flushes any buffered log entries
// logger.Info("failed to fetch URL",
// zap.String("url", "http://example.com"),
// zap.Int("attempt", 3),
// zap.Duration("backoff", time.Second),
// )
运行示例,可以得到类似下面输出结果:
{"level":"debug","ts":"2025-05-24T20:19:41.244+0800","caller":"zap_example/main.go:40","msg":"This is a zap debug message.","component":"auth","user_id_count":1005}
{"level":"info","ts":"2025-05-24T20:19:41.245+0800","caller":"zap_example/main.go:44","msg":"Zap logger initialized.","url":"http://example.com","attempt":3,"backoff":1}
{"level":"warn","ts":"2025-05-24T20:19:41.245+0800","caller":"zap_example/main.go:49","msg":"Potential issue detected.","warning_code":"W001"}
{"level":"error","ts":"2025-05-24T20:19:41.245+0800","caller":"zap_example/main.go:50","msg":"Operation failed.","error":"network connection refused","stacktrace":"main.main\n\t/Users/tonybai/go/src/github/go-advanced/part3/source/ch23/logging/zap_example/main.go:50\nruntime.main\n\t/Users/tonybai/.bin/go1.24.3/src/runtime/proc.go:283"}
zap 证明了Go日志库可以达到极高的性能,并强调了在设计API时为性能所做的权衡(例如,要求用户显式提供字段类型)。它对Go社区在高性能组件设计方面产生了深远影响。
这些优秀的第三方库,极大地推动了Go社区对结构化日志、高性能日志以及日志系统可扩展性的认知和实践。它们在各自的领域都做得非常出色,并为后续标准库的演进提供了宝贵的参考。
log/slog:Go官方的结构化日志解决方案(Go 1.21+)
在选择日志库时,标准库 log 的局限性使其难以胜任生产级应用的需求。而引入第三方库则需要权衡其功能、性能、学习成本、社区支持和依赖管理等因素。正是由于这种背景,Go官方推出了 log/slog。
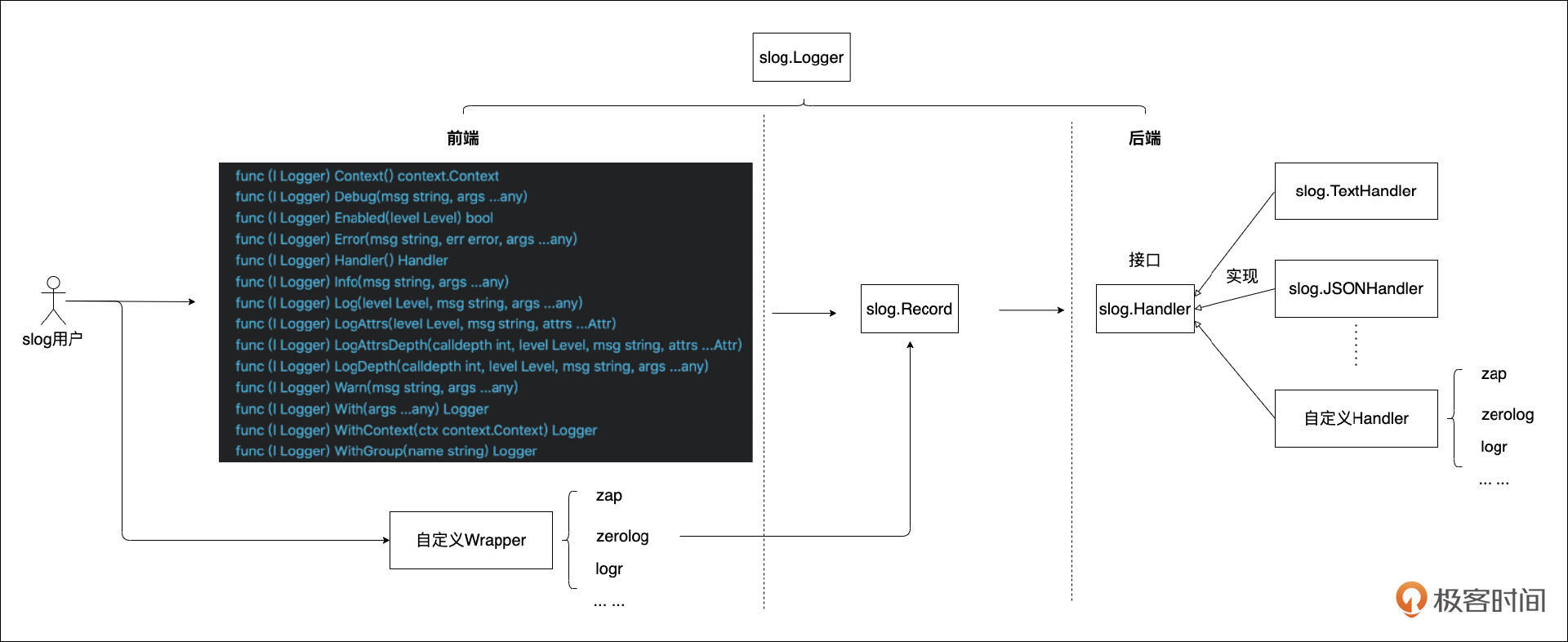
log/slog 旨在提供一个易用、高性能、可扩展的结构化日志基础,并期望能逐步统一Go生态的日志记录方式。其设计目标与核心特性包括:
-
开箱即用的结构化日志:默认支持JSON和类似logfmt的文本格式。
-
日志级别:内置了
LevelDebug、LevelInfo、LevelWarn、LevelError。 -
高性能:设计上充分考虑了性能,避免了标准库
log和早期一些第三方库的性能瓶颈(如过度反射、大量分配)。官方宣称其性能接近zap。 -
可插拔的
Handler:这是slog设计的核心亮点。slog.Logger通过一个slog.Handler接口来处理日志记录的实际格式化和输出。这意味着开发者可以轻松替换或自定义Handler,以支持不同的输出格式、目标,或添加额外的处理逻辑(如采样、过滤、对接第三方服务等)。 -
与标准库
log兼容:可以将标准库log的输出重定向到slog。
slog的核心API包括如下类型与方法:
-
slog.Logger:日志记录器实例,通过slog.New(Handler)创建。 -
slog.Handler:这是一个接口类型,定义了处理日志记录的核心逻辑。标准库提供了slog.TextHandler和slog.JSONHandler两个内建实现。
type Handler interface {
Enabled(context.Context, Level) bool
Handle(context.Context, Record) error
WithAttrs(attrs []Attr) Handler
WithGroup(name string) Handler
}
-
slog.Record:代表一条日志记录的结构体,包含时间、级别、消息、属性等。 -
slog.Attr:代表一个key-value属性对,用于向日志记录添加结构化数据。通过slog.String(key, value)、slog.Int(key, value)、slog.Duration(key, value)、slog.Any(key, value)等函数创建。
下面是slog的一个基本用法与上下文集成的示例:
// ch23/logging/slog_example/main.go
package main
import (
"context"
"fmt"
"log/slog"
"os"
"time"
)
type User struct {
ID string
Name string
}
// UserLogValue implements slog.LogValuer to customize logging for User type
func (u User) LogValue() slog.Value {
return slog.GroupValue(
slog.String("id", u.ID),
slog.String("name", u.Name),
)
}
func main() {
// --- TextHandler Example ---
txtOpts := &slog.HandlerOptions{
Level: slog.LevelDebug,
AddSource: true, // 添加源码位置 (文件名:行号)
ReplaceAttr: func(groups []string, a slog.Attr) slog.Attr {
// 将所有 Info 级别的 level 字段的键名改为 "severity"
if a.Key == slog.LevelKey && a.Value.Any().(slog.Level) == slog.LevelInfo {
a.Key = "severity"
}
return a
},
}
txtHandler := slog.NewTextHandler(os.Stdout, txtOpts)
txtLogger := slog.New(txtHandler)
txtLogger.Info("TextHandler: Server started.", slog.String("port", ":8080"))
// --- JSONHandler Example ---
jsonOpts := &slog.HandlerOptions{
Level: slog.LevelInfo, // JSON logger只输出Info及以上
ReplaceAttr: func(groups []string, a slog.Attr) slog.Attr {
if a.Key == slog.TimeKey { // 自定义时间戳字段名和格式
a.Key = "event_time"
a.Value = slog.StringValue(a.Value.Time().Format(time.RFC3339Nano))
}
return a
},
}
jsonHandler := slog.NewJSONHandler(os.Stderr, jsonOpts)
jsonLogger := slog.New(jsonHandler)
jsonLogger.Error("JSONHandler: Payment failed.",
slog.String("order_id", "ord-123"),
slog.Any("error_details", map[string]string{"code": "P401", "message": "Insufficient funds"}),
)
// --- Using With for contextual logging ---
requestID := "req-abc-789"
userLogger := jsonLogger.With(
slog.String("request_id", requestID),
slog.Group("user_info",
slog.String("id", "user-xyz"),
slog.Bool("authenticated", true),
),
)
userLogger.Info("User action performed.", slog.String("action", "view_profile"))
userLogger.Debug("This debug from userLogger will not be printed by jsonLogger (LevelInfo).")
// --- Implementing LogValuer for custom type logging ---
currentUser := User{ID: "u-555", Name: "Alice Wonderland"}
userLogger.Info("Processing user data.", slog.Any("user_object", currentUser))
// --- Setting a default logger ---
slog.SetDefault(txtLogger.WithGroup("global")) // All subsequent slog.Info etc. will use this
slog.Info("This is a global log message via default logger (TextHandler).", slog.Int("count", 42))
// for components requiring specific contexts or outputs, explicit logger injection is preferred.
doWorkWithGlobalLogger()
}
func doWorkWithGlobalLogger() {
slog.Warn("Warning from a function using the global default logger.", slog.String("module", "worker"))
}
运行示例,可以得到类似下面输出结果:
time=2025-05-24T20:54:15.787+08:00 severity=INFO source=/Users/tonybai/go/src/github/go-advanced/part3/source/ch23/logging/slog_example/main.go:37 msg="TextHandler: Server started." port=:8080
{"event_time":"2025-05-24T20:54:15.787392+08:00","level":"ERROR","msg":"JSONHandler: Payment failed.","order_id":"ord-123","error_details":{"code":"P401","message":"Insufficient funds"}}
{"event_time":"2025-05-24T20:54:15.787457+08:00","level":"INFO","msg":"User action performed.","request_id":"req-abc-789","user_info":{"id":"user-xyz","authenticated":true},"action":"view_profile"}
{"event_time":"2025-05-24T20:54:15.787465+08:00","level":"INFO","msg":"Processing user data.","request_id":"req-abc-789","user_info":{"id":"user-xyz","authenticated":true},"user_object":{"id":"u-555","name":"Alice Wonderland"}}
time=2025-05-24T20:54:15.787+08:00 severity=INFO source=/Users/tonybai/go/src/github/go-advanced/part3/source/ch23/logging/slog_example/main.go:75 msg="This is a global log message via default logger (TextHandler)." global.count=42
time=2025-05-24T20:54:15.787+08:00 level=WARN source=/Users/tonybai/go/src/github/go-advanced/part3/source/ch23/logging/slog_example/main.go:86 msg="Warning from a function using the global default logger." global.module=worker
从示例中我们也看到:一旦通过 slog.SetDefault(logger) 设置了全局默认的 slog.Logger,应用中的任何包都可以直接调用包级别的 slog.Info()、 slog.Error() 等函数进行日志记录,而无需显式传递 slog.Logger 实例。全局默认logger更适合作为一种普适性的、便捷的基础日志记录手段。
而对于那些需要携带特定上下文信息(如请求ID、用户ID)或者需要输出到特定目标(通过不同的Handler)的组件或逻辑单元(例如HTTP请求处理器、gRPC服务实现、业务服务方法),仍然推荐显式地创建和注入(或通过 logger.With() 派生)特定的 slog.Logger 实例。这样做能使日志的上下文更丰富,也更容易管理不同模块的日志行为。
此外, slog 本身不强制要求将 Logger 实例通过 context.Context 传递,但你可以这样做,或者创建一个包装了 context.Context 的 Logger。更常见的做法是,当你需要为特定请求或流程添加上下文属性时,可以使用 logger.With(attrs ...slog.Attr) 来创建一个新的 Logger 实例,它会携带这些额外的属性。这种做法也被称为上下文集成(Contextual Logging):
func handleRequest(ctx context.Context, baseLogger *slog.Logger, requestID string) {
reqLogger := baseLogger.With(slog.String("request_id", requestID))
reqLogger.Info("Processing request")
// ...
if err := doWork(ctx, reqLogger); err != nil {
reqLogger.Error("Work failed", slog.Any("error", err))
}
}
许多Web框架和库也开始提供与 slog 集成的中间件,可以自动从请求上下文中提取或注入 Logger。
如果你需要将日志发送到 slog 标准库未直接支持的目标(如Kafka、特定的云日志服务),或者需要实现非常定制化的格式化、过滤、采样逻辑,你可以通过实现 slog.Handler 接口来创建自己的Handler。这是 slog 强大扩展性的体现。
type MyCustomHandler struct {
// ...你的依赖和配置...
next slog.Handler // 可以包装另一个Handler,形成处理链
}
func (h *MyCustomHandler) Enabled(ctx context.Context, level slog.Level) bool {
return h.next.Enabled(ctx, level) // 或自定义逻辑
}
func (h *MyCustomHandler) Handle(ctx context.Context, r slog.Record) error {
// ...你的自定义处理逻辑,例如修改Record,或将其发送到特定目标...
// r.AddAttrs(slog.String("custom_field", "my_value"))
return h.next.Handle(ctx, r) // 调用下一个Handler
}
// ...实现 WithAttrs 和 WithGroup ...
那么,何时选择 slog?何时仍可能考虑第三方库呢?
slog 作为标准库是未来的趋势。对于新项目,或希望减少外部依赖、追求与Go生态更好集成的项目, slog 无疑是首选。
如果项目已深度使用某个第三方日志库(如 zap 或 logrus),并强依赖其特定高级功能或庞大的Hook生态,立即迁移可能成本较高,可以考虑使用桥接Handler或在新模块中逐步采用 slog。
但如果对日志性能有极端严苛要求,且基准测试表明 slog 在特定场景下仍有差距时,专门优化的库(如 zap)可能仍是备选。
总的来说, “标准库优先”原则在此依然适用。 slog 为Go的结构化日志提供了坚实的基础和统一的API。
熟悉了现代日志系统的核心要素和Go中日志方案的演进,我们还需要解决一个实际问题:当日志输出到本地文件时,如何有效地管理这些文件?
日志轮转与归档
当日志输出到本地文件时,管理这些文件的大小和生命周期至关重要,以防止它们无限增长并耗尽磁盘空间。slog本身作为日志记录API和格式化库,不直接处理文件轮转的物理操作。这项工作通常交给专门的库来完成。
下面是结合 slog 与 natefinch/lumberjack 实现日志轮转的一个示例, natefinch/lumberjack 是一个在Go社区广泛使用的,用于实现日志文件轮转的库。它实现了 io.Writer 接口,可以非常方便地与 slog(或其他任何接受 io.Writer 的日志库)集成。
// ch23/logging/slog_lumberjack/main.go
package main
import (
"io" // Required for io.MultiWriter
"log/slog"
"os"
"time"
"github.com/natefinch/lumberjack"
)
func main() {
// 1. 配置 lumberjack.Logger 作为 io.Writer
logFilePath := "./logs/myapp_rotated.log" // 日志文件路径
os.MkdirAll("./logs", os.ModePerm) // 确保logs目录存在
logFileWriter := &lumberjack.Logger{
Filename: logFilePath,
MaxSize: 1, // 每个日志文件的最大大小 (MB)
MaxBackups: 3, // 保留的旧日志文件的最大数量
MaxAge: 7, // 保留的旧日志文件的最大天数 (天)
Compress: true, // 是否压缩旧的日志文件 (使用gzip)
LocalTime: true, // 使用本地时间命名备份文件
}
// 2. 创建一个slog Handler
// 使用 io.MultiWriter 可以同时将日志输出到文件和控制台(方便开发调试)
handlerOptions := &slog.HandlerOptions{
Level: slog.LevelDebug,
AddSource: true, // 添加源码位置
ReplaceAttr: func(groups []string, a slog.Attr) slog.Attr {
if a.Key == slog.TimeKey {
a.Value = slog.StringValue(a.Value.Time().Format("2006-01-02 15:04:05.000"))
}
return a
},
}
// 可以选择输出格式,例如JSON或Text
// logger := slog.New(slog.NewJSONHandler(io.MultiWriter(os.Stdout, logFileWriter), handlerOptions))
logger := slog.New(slog.NewTextHandler(io.MultiWriter(os.Stdout, logFileWriter), handlerOptions))
slog.SetDefault(logger) // 可选:设置为默认logger
slog.Info("Application starting with file rotation enabled via lumberjack.")
slog.Debug("This is a debug message that should appear in both console and file.")
// 模拟大量日志输出以触发轮转 (1MB大约需要较多条目)
// 调整循环次数和日志内容大小以实际触发轮转
// 一条典型slog日志(带时间、级别、源、消息、几个属性)可能在100-300字节左右
// 1MB = 1024 * 1024 bytes. 大约需要 3500 - 10000条日志.
for i := 0; i < 5000; i++ {
slog.Info("This is a test log entry to demonstrate rotation.",
slog.Int("entry_number", i),
slog.String("data_payload", fmt.Sprintf("some_long_data_string_padding_%d_%s", i, time.Now().String())),
)
if i%1000 == 0 && i != 0 {
slog.Warn("Milestone log entry reached.", slog.Int("progress_mark", i/1000))
time.Sleep(100 * time.Millisecond) // 稍微暂停,让日志有机会写入
}
}
slog.Info("Application finished logging. Check the './logs' directory for rotated files.")
}
运行这个示例后,检查项目下的 ./logs/ 目录,你会看到 myapp_rotated.log 文件,以及当它达到1MB后被轮转、压缩(如果开启Compress)的备份文件。
logs git:(main) ✗ $ls
myapp_rotated-2025-05-24T21-17-18.008.log.gz myapp_rotated.log
通过这种方式,我们利用 slog 的结构化日志能力和 lumberjack 的文件管理能力,构建了一个既强大又易于维护的本地文件日志系统。
至此,我们已经深入探讨了应用骨架中两个至关重要的基础组件:配置管理和日志系统。它们为应用的稳定运行、灵活部署和问题排查提供了坚实的基础。然而,当应用发展到一定阶段,面临更复杂的需求,例如需要动态扩展功能、允许第三方集成或实现特定业务逻辑的灵活替换时,我们就可能需要引入更高级的架构模式——插件化架构。
插件化架构设计模式
随着应用功能的日益丰富和业务场景的不断演变,我们有时会遇到这样的需求:希望应用的核心保持稳定,但又能灵活地增减或替换某些特定功能模块,甚至允许第三方开发者为我们的平台贡献扩展。这时,插件化架构(Plugin Architecture)就显得尤为重要。
当我的应用需要支持第三方扩展,或者在不重新编译主程序的情况下动态增减功能时,该怎么办?
如果你的应用只是简单地将所有功能都硬编码在主程序中,那么每次添加一个小特性、修复一个小模块的 Bug,或者集成一个新的第三方服务,都可能意味着要修改核心代码、重新编译整个应用并重新部署。这不仅效率低下,而且容易引入新的风险。
插件化架构顾名思义就是将应用的核心功能与可插拔的扩展功能(插件)分离开来。 主应用定义好与插件交互的接口和规范,插件则按照这些规范实现具体的功能。这样,就可以在不修改主应用核心代码的前提下,通过添加、移除或替换插件来改变或扩展应用的行为。
插件化的核心价值在于其带来的灵活性和可扩展性,它使得应用能够更好地适应变化、解耦模块、促进社区贡献并支持功能定制。然而,实现一个优秀的插件化系统也面临诸多挑战,包括:
-
如何定义稳定且易用的插件接口?
-
如何管理插件的版本兼容性?
-
如何保障插件的安全性与资源隔离?
-
如何处理插件的发现与加载机制?
-
如何应对可能增加的性能开销和调试复杂度?
因此,选择是否引入插件化以及采用何种插件化方案,需要仔细权衡这些价值与挑战。并非所有应用都需要复杂的插件系统,但理解其设计模式对于构建大型、可演进的系统非常有益。
接下来,我们先看看Go语言原生提供的插件支持,然后再探讨社区中更为主流和实用的插件化架构模式。
Go原生 plugin 包:美好的初衷与残酷的现实
Go语言在1.8版本中引入了官方的 plugin 包,旨在提供一种原生的方式来构建和加载插件。其核心思想是将Go包编译为共享对象文件(在Linux上是 .so 文件,macOS上是 .dylib 文件),主程序可以在运行时动态加载这些文件,并查找和使用其中导出的符号(变量和函数)。
下面是一个演示plugin基本用法的示例。我们首先看看插件包 ch23/plugins/native/myplugin/plugin.go,注意:插件包的包名必须是 main:
// ch23/plugins/native/myplugin/plugin.go
package main
import "fmt"
// PluginName 是一个导出的变量
var PluginName = "MyNativeGoPlugin"
// Greet 是一个导出的函数
func Greet(name string) string {
return fmt.Sprintf("Hello, %s, from %s!", name, PluginName)
}
// Version 是另一个导出变量示例
var Version = "1.0.0"
// 为了能被编译为plugin,必须有一个main函数,即使它是空的
func main() {
// 通常插件的main函数不执行任何操作,因为其代码是被主程序加载和调用的
}
在 ch23/plugins/native/myplugin/ 目录下运行下面命令可以编译该插件:
$go build -buildmode=plugin -o myplugin.so plugin.go
这会生成 myplugin.so 文件,我们将该文件拷贝一份到其上层目录ch23/plugins/native下。
接下来,我们再来看加载和使用插件的主程序( ch23/plugins/native/main.go):
package main
import (
"fmt"
"log"
"os"
"path/filepath"
"plugin"
)
func main() {
exePath, err := os.Executable()
if err != nil {
log.Fatalf("Failed to get executable path: %v", err)
}
pluginDir := filepath.Dir(exePath)
pluginPath := pluginDir+"./myplugin.so" // 假设.so文件在当前工作目录下,或相对于main.go
// 最简单的运行方式:
// 1. cd ch23/plugins/native/myplugin
// 2. go build -buildmode=plugin -o ../myplugin.so plugin.go (将.so输出到上一级目录)
// 3. cd .. (进入 ch23/plugins/native 目录)
// 4. go run main.go
log.Printf("Attempting to load plugin from: %s\n", pluginPath)
p, err := plugin.Open(pluginPath)
if err != nil {
log.Fatalf("Failed to open plugin '%s': %v\nIf running with 'go run', ensure '%s' is in the current directory or adjust path.", pluginPath, err, filepath.Base(pluginPath))
}
log.Println("Plugin loaded successfully.")
// 查找导出的变量 PluginName
pluginNameSymbol, err := p.Lookup("PluginName")
if err != nil {
log.Fatalf("Failed to lookup PluginName: %v", err)
}
pluginName, ok := pluginNameSymbol.(*string) // 需要类型断言,因为Lookup返回plugin.Symbol (interface{})
if !ok {
log.Fatalf("PluginName is not a *string, actual type: %T", pluginNameSymbol)
}
fmt.Printf("Plugin's registered name: %s\n", *pluginName)
// 查找导出的变量 Version
versionSymbol, err := p.Lookup("Version")
if err != nil {
log.Fatalf("Failed to lookup Version: %v", err)
}
version, ok := versionSymbol.(*string)
if !ok {
log.Fatalf("Version is not a *string, actual type: %T", versionSymbol)
}
fmt.Printf("Plugin's version: %s\n", *version)
// 查找导出的函数 Greet
greetSymbol, err := p.Lookup("Greet")
if err != nil {
log.Fatalf("Failed to lookup Greet: %v", err)
}
greetFunc, ok := greetSymbol.(func(string) string) // 类型断言为函数类型
if !ok {
log.Fatalf("Greet is not a func(string) string, actual type: %T", greetSymbol)
}
// 调用插件中的函数
message := greetFunc("Go Developer")
fmt.Println(message)
// 尝试修改插件中的可导出变量 (如果插件设计允许)
log.Printf("Original PluginName in plugin: %s\n", *pluginName)
*pluginName = "MyUpdatedNativePlugin" // 修改的是主程序持有的指针指向的值
// 再次调用函数,看看插件内部是否感知到变化(取决于插件如何使用该变量)
// 如果Greet函数直接使用全局的PluginName,它会看到变化
// 但如果Greet函数在调用时捕获了PluginName的副本,则可能看不到
// 在我们的简单示例中,Greet函数每次都会读取全局的PluginName
messageAfterChange := greetFunc("Gopher")
fmt.Println(messageAfterChange)
}
在ch23/plugins/native下编译主程序并运行:
$go build -o main
$./main
2025/05/24 21:48:31 Attempting to load plugin from: /Users/tonybai/go/src/github/go-advanced/part3/source/ch23/plugins/native/myplugin.so
2025/05/24 21:48:31 Plugin loaded successfully.
Plugin's registered name: MyNativeGoPlugin
Plugin's version: 1.0.0
Hello, Go Developer, from MyNativeGoPlugin!
2025/05/24 21:48:31 Original PluginName in plugin: MyNativeGoPlugin
Hello, Gopher, from MyUpdatedNativePlugin!
我们看到go plugin的机制是可以工作的。但这仅是一个demo,因此不要乐观过早!因为Go原生的 plugin 包虽然提供了一种动态加载代码的机制,但在实际应用中面临诸多严格的约束,这极大地限制了它的普及和易用性。这些约束主要包括:
-
平台限制:官方明确支持Linux、macOS、FreeBSD,但尚不支持Windows等其他平台。
-
构建环境高度一致性要求:这是最主要的痛点。主程序和所有插件必须使用完全相同版本(包括补丁版本)的Go编译器进行编译。此外,它们的GOPATH/GOROOT设置(尤其在非Module模式下)以及所依赖的所有共享包(包括直接和间接依赖)的源代码和版本也必须完全一致。任何细微的差异都可能导致插件加载失败,并伴随难以调试的错误,如
plugin was built with a different version of package X。 -
动态链接与Go的静态编译优势相悖:Go语言的一大优势是能够编译成单个静态链接的可执行文件,便于分发和部署。然而,使用
plugin包意味着主程序必须进行动态链接,这在一定程度上削弱了Go的这一核心优势。 -
无法热卸载(No Hot Unloading):一旦插件通过
plugin.Open()被加载到主进程的地址空间中,Go的plugin包目前没有提供任何安全地卸载(unload)或替换它的机制。这对于需要真正动态更新插件版本的场景是一个重大限制。 -
版本管理复杂:由于上述对构建环境和依赖版本的严格一致性要求,管理插件及其依赖的版本变得非常具有挑战性,尤其是在大型项目或有多个独立开发的插件时。
-
符号查找的类型安全:
Lookup()方法返回的是plugin.Symbol(其底层类型是interface{}),这意味着主程序在获取到插件的符号后,必须进行类型断言才能将其转换为期望的变量指针或函数类型。如果类型不匹配,会在运行时发生panic。
这样来看,尽管Go原生 plugin 包提供了一种底层的动态代码加载能力,但其严苛的约束使得它在许多实际的生产场景中并非一个便捷或理想的选择。开发者在考虑使用它时,必须仔细评估是否能满足并长期维持这些一致性要求。
鉴于此,社区和业界在实践中更多地探索和采用了其他不依赖于原生 plugin 包的插件化架构模式。
社区主流的Go应用插件化架构模式
由于Go原生 plugin 包的实际应用限制,社区和业界探索出了多种更为实用和灵活的插件化架构模式。这些模式通常不依赖于操作系统级别的共享对象动态加载,而是通过Go语言自身的特性(如接口、包管理)或进程间通信机制来实现主应用与插件的解耦和集成。
模式一:基于接口与注册机制的“内部插件”
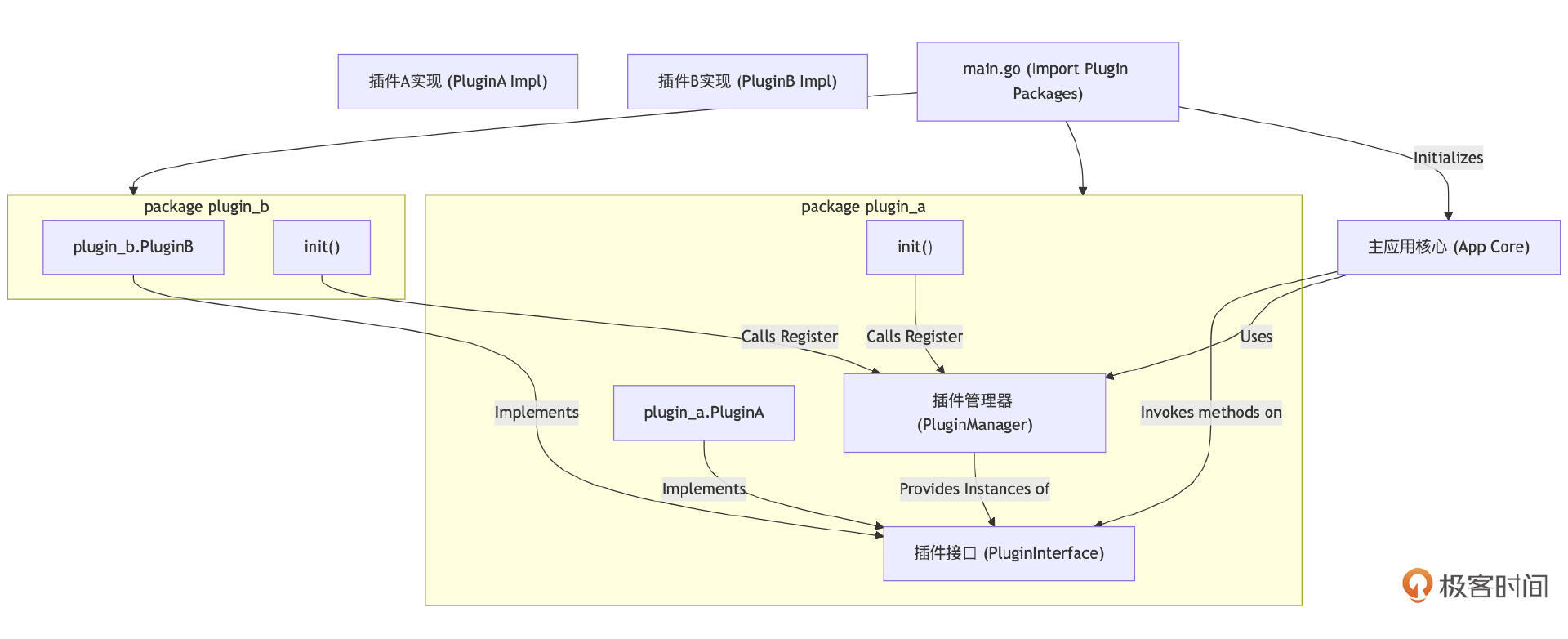
这种模式下,插件作为普通的Go包存在,它们实现主应用预先定义好的接口。主应用通过某种机制(通常是插件包在 init() 函数中调用主应用提供的注册函数)来发现和管理这些插件的实现。最终,插件代码会和主应用代码一起被编译到同一个可执行文件中。
这种模式的核心思想是利用Go的接口实现多态,并通过包导入时的 init 副作用或显式注册来收集插件。 其优点在于类型安全(编译期检查)、高性能(直接方法调用)和统一的依赖管理。然而,它并不提供运行时热插拔的能力,添加或更新插件都需要重新编译主应用。由于插件与主应用在同一进程空间,也没有资源隔离和强安全性保障。
这种模式非常适合那些需要高度模块化,且允许不同团队开发可组合功能,但所有功能模块可以一起编译和部署的场景。许多开源项目,如Caddy Web服务器的模块系统,就广泛采用了类似的思想。
模式二:基于IPC/RPC的“外部插件”
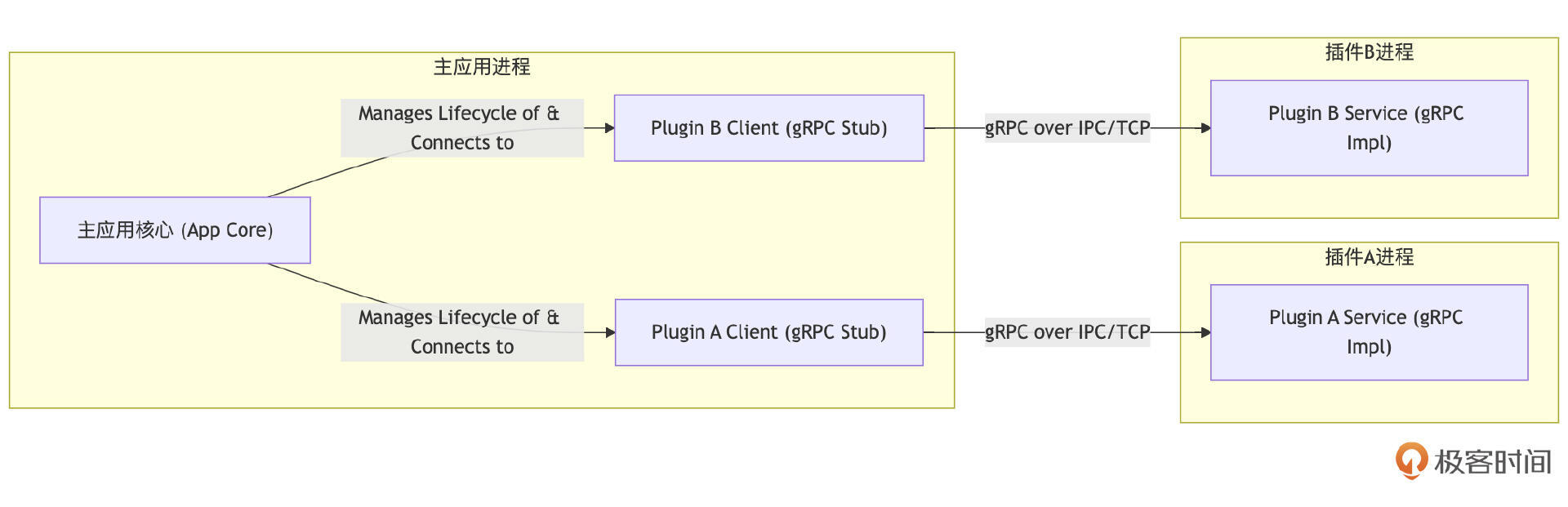
在这种模式中,插件作为完全独立的进程运行与主应用进程分离。主应用和插件进程之间通过某种标准的进程间通信(IPC)机制,如Unix Domain Socket、Named Pipes,或者更常用的远程过程调用(RPC)框架(如gRPC、HTTP)进行交互。主应用通常负责启动、监控插件子进程,并管理与它们的通信。
HashiCorp开源的 go-plugin 库( https://github.com/hashicorp/go-plugin)是这种模式的一个非常优秀且成熟的实现。它默认使用gRPC作为通信协议,并封装了插件发现、版本协商、双向流式RPC、插件进程管理等诸多复杂细节,大大简化了构建外部插件系统的难度。
这种模式的核心优势在于它实现了真正的运行时热插拔、热更新甚至热卸载(通过管理子进程的启停)。 由于进程隔离,它还带来了语言无关性(插件可以用任何支持gRPC的语言编写)、更好的资源隔离和稳定性(一个插件进程的崩溃通常不会直接影响主应用),以及增强的安全性(可以对插件进程施加更严格的权限控制)。
当然,这种模式的代价是引入了IPC/RPC带来的通信开销(数据序列化/反序列化、上下文切换等),增加了部署和管理的复杂度(需要管理多个进程),并且主应用与插件之间共享复杂状态或大量数据可能不如进程内那样高效。
这种模式非常适合对运行时动态性要求极高(如需要不停机更新功能模块)、需要支持异构语言插件,或者对安全性和稳定性有较高要求的场景。许多基础设施工具,如Terraform(其Provider插件系统)、Vault、Consul等,都广泛采用了基于 go-plugin 的外部插件架构。由于基于 hashicorp/go-plugin 的示例代码量较大,涉及定义protobuf服务、实现gRPC服务端和客户端等,此处不展示完整代码,你可以参考 hashicorp/go-plugin 的官方文档和示例。
模式三:基于脚本语言嵌入的插件
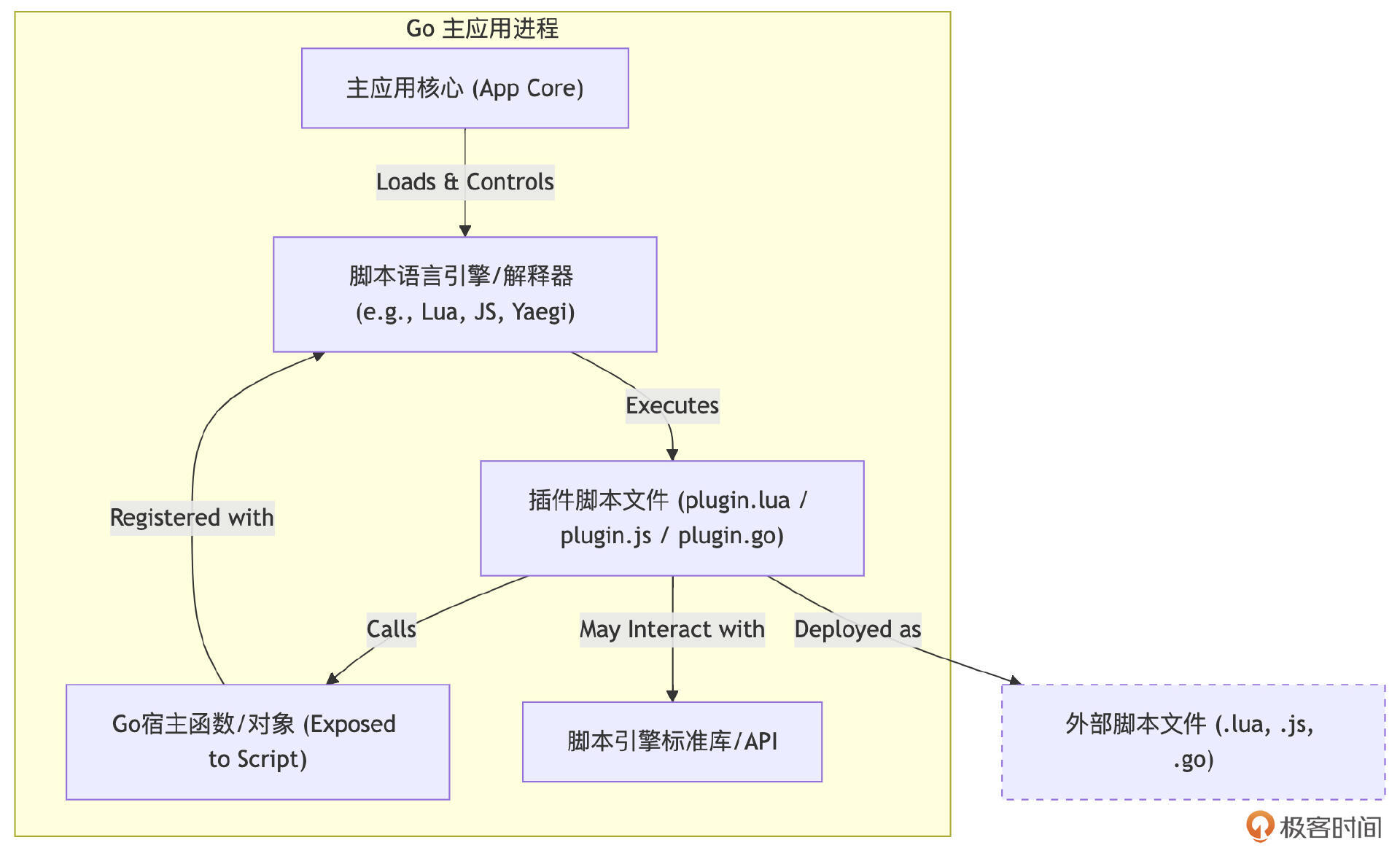
这种模式的核心是在Go主应用中嵌入一个脚本语言的解释器或运行时,例如使用 robertkrimen/otto 嵌入JavaScript(ES5)解释器,或使用 yuin/gopher-lua 嵌入Lua解释器,或使用 traefik/yaegi 嵌入一个Go语言自身的解释器。插件则以该脚本语言的脚本文件形式存在,由主应用在运行时加载并执行这些脚本。主应用需要向脚本的执行环境暴露一些Go函数或对象作为API,供脚本调用以与主应用交互。
这种模式的主要优点是高度的动态性,脚本插件通常可以非常方便地在运行时被加载、更新甚至移除,无需重启主应用,并且插件开发可能更为快速(对熟悉脚本语言的开发者而言)。脚本解释器也往往能提供一定程度的沙箱环境以增强安全性。
然而,这种模式的缺点也十分明显:脚本执行的性能通常远低于原生Go代码;在Go与脚本语言之间传递数据和调用函数可能涉及复杂的类型转换和绑定逻辑,不如原生Go接口那样直接和类型安全;调试脚本插件也可能比调试Go代码更困难。此外,它还引入了对脚本解释器库的依赖。
此模式适用于那些需要高度动态化、允许用户自定义复杂逻辑,但对性能要求不是极端苛刻的场景,例如某些Web服务器的请求/响应修改规则、游戏中的行为脚本、数据处理管道中的自定义转换规则,或者规则引擎的条件判断等。
在为你的Go应用选择或设计插件化架构时,没有一刀切的答案。你需要仔细权衡动态性需求、性能要求、安全性与隔离性、开发复杂度与团队技能、插件的语言要求以及部署与运维复杂度等多种因素。
对于大多数Go应用,如果需要插件化:
-
当模块间信任度高,对性能敏感,且不需要运行时动态加载时,基于接口的内部插件(模式一)因其简单、高效和类型安全,通常是首选。
-
当对运行时动态性、语言异构性或强隔离性有更高要求时,基于IPC/RPC的外部插件(模式二,特别是使用
hashicorp/go-plugin)则是一个非常成熟和强大的选择。 -
脚本嵌入(模式三)则适用于更特定的且对动态性有极端需求,但对性能要求却不苛刻的场景。
小结
好了,关于Go应用中核心组件——配置管理、日志系统以及插件化架构的设计与实践,我们就探讨到这里。这节课,我们深入了应用骨架之下的关键“器官”,理解了它们如何支撑一个健壮、可维护、可扩展的Go服务。
我们聚焦于日志最佳实践,分析了 fmt.Println 和标准库 log 在生产环境中的不足,明确了现代日志系统应具备的核心要素:结构化、级别、上下文信息、可配置的输出目标(及其对接可观测性的意义)、性能考量和日志轮转。我们回顾了 logrus 和 zap 等优秀第三方库对Go社区的贡献,并本着“标准库优先,按需拓展”的原则,重点学习了Go 1.21+ 官方推出的结构化日志库 log/slog 的核心API、用法、上下文集成(特别是通过 slog.SetDefault 实现便捷的全局日志记录),以及通过自定义Handler进行扩展的能力。同时,我们也探讨了何时选择 slog,以及何时可能仍需考虑其他方案,并结合 natefinch/lumberjack 演示了日志轮转的实现。
我们探讨了应用的插件化架构,了解了插件化的核心价值与挑战,分析了Go原生 plugin 包美好的初衷及其在实践中的诸多约束。更重要的是,我们借鉴社区和业界的成熟经验,总结了几种更为实用的Go应用插件化设计模式:基于接口的内部插件(编译时)、基于IPC/RPC的外部插件(运行时、跨语言,如 hashicorp/go-plugin),以及基于脚本语言嵌入的插件,并讨论了它们各自的优缺点和适用场景。
至此,你不仅掌握了配置、日志这两个每个Go应用都不可或缺的核心组件的设计要点和最佳实践,也对插件化这一重要(但非必须)的架构模式有了更深入的理解。这些知识将直接提升你构建和维护高质量Go服务的能力。在后续的课程中,我们将继续深入探讨与工程实践相关的其他重要主题,例如更全面的可观测性体系构建。
思考题
-
配置与日志的综合应用:假设你正在设计一个需要对接多种第三方服务(如不同的支付渠道、不同的短信服务商)的Go应用。你会如何设计其配置结构来管理这些第三方服务的不同参数(如API Key、URL、超时等)?在日志方面,当调用这些第三方服务时,你会重点记录哪些结构化信息(考虑使用
slog.Attr),以便于问题排查和SLA监控?你会选择log/slog还是其他方案,为什么? -
插件化选型思考:如果你的应用(例如一个内容管理系统CMS)需要允许网站管理员通过安装不同的“功能模块”(例如,SEO优化工具、评论系统、电商购物车模块)来扩展网站功能,你会倾向于选择哪种插件化架构模式来实现这个需求?请阐述你选择的主要理由,并简要说明主应用与这些“功能模块”插件之间可能的交互方式。
欢迎在留言区分享你的思考和见解!我是Tony Bai,我们下节课见。
可观测性:Metrics、Logging、Tracing,让你的Go服务不再是黑盒(上)
你好,我是Tony Bai。
在前面的几节课中,我们已经为Go应用打下了坚实的“地基”和“主体结构”。我们学习了如何构建一个健壮的应用骨架,使其具备清晰的初始化流程、合理的组件编排和优雅的退出机制。我们还深入探讨了支撑应用运行的核心组件,包括如何进行灵活的配置管理、如何实现结构化的日志记录,以及在需要时如何设计可扩展的插件化架构。
可以说,我们的Go应用现在已经能够按照预期逻辑正确地“运转”起来了。但是,一个仅仅能“正确运转”的应用,距离能让我们在生产环境中安心运维、快速响应问题的服务,还缺少了非常关键的一环。想象一下,应用上线后:
-
我们如何知道它当前的健康状况如何?处理请求的速率是多少?响应延迟是否在可接受范围内?CPU和内存等资源消耗是否正常?
-
当用户报告问题,或者某个功能表现异常时,我们如何才能快速定位到问题的具体环节或错误信息?
-
如果应用由多个微服务组成(或者即使是单体应用,其内部调用链路也可能很复杂),一个请求在系统中流转的完整路径是怎样的?性能瓶颈又潜藏在哪一步?
传统的、仅靠查看零散的应用日志或依赖基本的系统监控(如top命令看CPU),在面对现代应用的复杂性和对高可用、高性能的要求时,已经显得捉襟见肘。我们需要一套更系统、更深入的方法来“观测”我们的应用——这就是可观测性(Observability)。
可观测性,简单来说就是我们能够从系统外部产生的信号,如日志、指标、追踪数据(tracing)中,推断和理解其内部状态、行为和性能的能力。 它不仅仅是“监控”(Monitoring)的简单升级,更是一种主动的、探索式的系统理解能力,是保障现代应用(尤其是云原生和分布式应用)稳定、高效运行的基石。一个具有良好可观测性的系统,能帮助我们自信地回答关于系统“正在发生什么”以及“为什么会这样发生”的任意问题。
接下来的三节课,我们会一起为我们的Go服务构建起强大的“感知系统”。具体来说,我们将:
-
探讨云原生时代为何可观测性如此重要,以及它是如何从传统监控演进而来,其核心支柱又是什么。
-
深入Metrics、Logging和Tracing这三大支柱在Go生态中的主流技术栈和实践。
-
三大支柱如何整合,以及可观测性数据采集中常见的Push与Pull模型,以及展望eBPF技术为Go应用可观测性带来的革命性影响。
在深入具体的技术栈之前,我们首先需要理解为何在当今的云原生时代,可观测性变得如此不可或缺,以及它与传统的“监控”有何不同。
为何云原生应用更需要可观测性?
云原生架构以其微服务、容器化、不可变基础设施、声明式API和动态调度等特性,为我们带来了前所未有的敏捷性、弹性和可扩展性。但与此同时,这些特性也显著增加了系统的复杂性,比如说:
-
组件数量激增:一个单体应用可能被拆分为数十甚至数百个微服务,每个服务可能有多个实例运行在不同的容器中。
-
交互路径复杂:用户的一个请求可能需要跨越多个微服务才能完成,服务间的依赖关系错综复杂。
-
动态性与短暂性:容器和Pod的生命周期可能很短,它们会被动态地创建、销毁和迁移。IP地址和实例标识不再固定。
-
故障模式多样化:问题的根源可能在任何一个服务、任何一个实例、网络层面,甚至是编排平台自身。
在这样的背景下,像预先定义好要监控的关键指标,搭建固定的仪表盘,当指标超过阈值时发出告警这样的传统的监控方法虽然仍然有用,但往往不足以应对。因为我们很难预知所有可能发生的故障模式,也很难通过有限的仪表盘快速定位未知问题的根源。
云原生应用需要的是一种更深层次的、能够主动探索和理解系统内部状态的能力,这就是可观测性。要理解可观测性的真正含义及其与我们熟知的“监控”之间的关系,我们需要先明确它们各自的侧重点。
可观测性的演进与核心支柱
可观测性并非一个全新的概念,它源于控制理论,指的是系统可以由其外部输出推断其内部状态的程度。在软件领域,我们可以将其通俗地理解为:我们能够多好地理解和解释我们系统的行为,仅仅通过观察其外部产生的信号(如日志、指标、追踪数据)。
从“监控”到“可观测性”的视角转变
长久以来,“监控”是我们保障系统稳定运行的主要手段。但随着系统复杂性的指数级增长,仅仅“监控”已知问题已显不足,我们需要一种更主动、更深入的洞察能力,这便是“可观测性”所倡导的。
监控的核心理念更侧重于“我们知道要注意什么,并据此进行观察”。 它通常是基于我们对系统已有认知和历史经验,预先定义好一系列关键性能指标(KPIs)、健康检查项和告警规则。当系统运行时,我们通过仪表盘跟踪这些已知指标,当指标偏离正常范围或触发告警阈值时,我们就知道系统可能出现了已知类型的问题。监控告诉我们系统是否在按照我们预期的方式工作,以及何时偏离了这个预期。
与监控相比,可观测性更强调的是“我们具备探索和理解任何可能发生的情况的能力,即使是我们之前未曾预料到的未知问题”。 它不仅仅是收集数据,更在于这些数据是否足够丰富、是否能够被灵活地查询和关联,从而允许我们提出任意的“为什么”和“怎么样”的问题,并能从中找到答案。可观测性使我们能够深入调试、诊断和理解那些复杂的、新兴的,甚至从未见过的系统行为。可以说,可观测性是构建和运维高度动态、大规模分布式系统的坚实基础,而监控则是建立在可观测性数据之上的一种具体应用。
理解了这种视角上的转变,我们接下来需要明确构成一个可观测系统的“外部信号”,即我们赖以推断内部状态的遥测数据主要包含哪些核心部分。
可观测性的三大支柱
业界普遍认为,一个完善的可观测性体系主要由以下三种不同类型但又相互关联的遥测数据(Telemetry Data)构成,它们从不同维度为我们描绘了系统的运行画像:
首先来看Metrics(度量/指标)。 Metrics是可聚合的、数值型的时间序列数据,它们通常在固定的时间间隔内被收集,主要作用是反映系统在一段时间内的宏观状态、性能表现和变化趋势。 例如,一个Web服务的每秒请求数(QPS)、API请求的平均延迟和P99延迟、错误请求的百分比、CPU和内存的平均使用率、消息队列的当前长度、数据库的活跃连接数等。
指标数据通常是数字,这使得它们非常易于进行数学运算(如求和、平均、百分位计算、速率计算)和长期存储。它们是构建监控仪表盘,进行趋势分析、设置告警阈值及容量规划的理想数据源。通过指标,我们可以快速了解系统的整体健康状况和性能基线。
再来看Logging(日志)。 日志是离散并带有精确时间戳的事件记录。每一条日志通常记录了在特定时间点发生的某个特定事件的详细上下文信息。 例如,一次用户登录成功的记录(包含用户ID、登录时间、IP地址)、一次订单创建失败的记录(包含订单ID、失败原因、相关的错误堆栈)、服务启动时的配置信息、一个函数执行过程中的关键调试信息、一次数据库慢查询的完整SQL语句和参数。
日志通常是文本形式(在现代系统中,强烈推荐使用结构化格式如JSON),它们包含了关于单个事件的丰富细节。日志非常适合用于事后审计、具体错误的深度排查、理解某个特定请求或业务流程的完整执行步骤和遇到的问题。虽然日志量通常较大,但其提供的上下文深度是Metrics和Tracing难以替代的。
最后看Tracing(追踪/链路)。 分布式追踪记录的是,单个请求(或一个完整的业务事务)在现代分布式系统中,从最初的入口开始到最终的响应(或错误)结束,其间跨越多个服务、组件和基础设施的完整调用路径和在每个环节的耗时及相关的元数据。
比如说,一个用户在电商App上提交订单的请求可能先经过移动App的API网关,然后调用订单服务,订单服务接着可能会调用用户认证服务、商品库存服务、优惠券服务和支付服务,最后才返回结果。分布式追踪会将这个请求在所有这些服务中的每一次调用(这些调用被称为一个Span)都记录下来,并将它们按照父子关系串联起来,形成一个完整的Trace(调用链)。
追踪提供了对请求的端到端视图,以及在复杂系统中各个组件之间交互的清晰画像。它对于理解服务依赖关系、定位分布式环境下的性能瓶颈(哪个服务、哪个环节最慢)、分析错误在服务间的传播路径,以及优化整体系统架构都至关重要。
你可能还会听过这样一种说法:Events(事件)是可观测性的第四大支柱。事件可以看作是比日志更结构化、更富含特定业务或系统语义的离散记录,它们通常用于表示系统中发生的有意义的、原子性的状态变更或活动。但在目前的实践中,高质量的结构化日志往往已经能够承载许多事件所要表达的信息,两者的界限有时会比较模糊。
Metrics、Logging、Tracing这三大支柱并非各自为战的孤岛,恰恰相反,它们相互补充、相互印证。一个真正强大的可观测性平台,应该能够让我们在这三种数据之间轻松地进行跳转和联动分析。例如,当你从Metrics图表上发现某个服务的错误率飙升时,你应该能快速跳转到该时间段内该服务的错误日志,并从错误日志中提取出TraceID,进而查看到导致错误的完整分布式调用链。这种整合能力是实现高效故障排查和深度系统理解的关键。
理解了可观测性的核心理念和三大支柱之后,我们自然会关心构建这样一个体系期望达到的目标。
可观测性体系的目标
构建一个完善的可观测性体系,其最终目标是为了:
-
快速故障检测与定位:当问题发生时,能够迅速发现(通过告警),并通过关联的日志、指标和追踪数据快速定位到问题的根源。
-
性能瓶颈分析与优化:深入理解应用的性能表现,识别出CPU、内存、I/O或网络瓶颈,为性能优化提供数据支持。
-
系统容量规划与资源管理:通过对历史指标数据的分析,预测未来的资源需求,进行合理的容量规划,避免资源浪费或不足。
-
理解用户行为与业务趋势:从指标和日志中提取业务相关数据,分析用户行为模式、业务流程的转化率等,为产品决策提供支持。
-
提升系统可靠性和开发者信心:当你对系统的内部状态有清晰的洞察时,你就能更有信心地进行变更、发布新版本,并更快地从故障中恢复。
小结
这节课,我们理解了在云原生时代,为何可观测性(而不仅仅是传统监控)如此重要,以及它的核心目标是提供对系统内部状态和行为的深刻洞察。
云原生架构在带来前所未有的敏捷性、弹性和可扩展性的同时,也显著增加了系统的复杂性。可观测性是能够让我们从系统外部产生的信号中,推断和理解其内部状态、行为和性能的能力。与监控相比,可观测性更强调的是“我们具备探索和理解任何可能发生的情况的能力,即使是我们之前未曾预料到的未知问题”。
最后,我们再来回忆一下可观测性的三大核心支柱,这是我们这三节课的核心内容:
-
Metrics 是可聚合的、数值型的时间序列数据,它们通常在固定的时间间隔内被收集。它们的主要作用是反映系统在一段时间内的宏观状态、性能表现和变化趋势。
-
Logging 是离散并带有精确时间戳的事件记录。每一条日志通常记录了在特定时间点发生的某个特定事件的详细上下文信息。
-
Tracing 记录的是,单个请求(或一个完整的业务事务)在现代分布式系统中,从最初的入口开始到最终的响应(或错误)结束,其间跨越多个服务、组件和基础设施的完整调用路径和在每个环节的耗时及相关的元数据。
下一节课,我们将深入这三大核心支柱的主流技术栈和实践。欢迎在留言区分享你的思考和方案!我是Tony Bai,我们下节课见。
可观测性:Metrics、Logging、Tracing,让你的Go服务不再是黑盒(中)
你好,我是Tony Bai。
上节课,我们一起探讨了云原生时代为何可观测性如此重要,以及它是如何从传统监控演进而来,其核心支柱又是什么。这节课,我们将深入了解Metrics、Logging和Tracing三大支柱在Go生态中的主流技术栈和实践:
-
Metrics(度量/指标):如何使用Prometheus或新兴的VictoriaMetrics来量化Go应用的状态与趋势。
-
Logging(日志):如何构建有效的结构化日志系统,并利用Loki或VictoriaLogs等方案进行集中管理和分析。
-
Tracing(追踪/链路):如何借助OpenTelemetry和Grafana Tempo等工具,洞察分布式请求的完整路径和性能瓶颈。因为内容比较多,这一部分我们放到下节课讲。
首先,我们来看Metrics。
Go应用的Metrics:量化系统状态与趋势
Metrics(度量或指标)是可观测性的基石之一。它们通过可聚合的数值型时间序列数据,为我们描绘出系统在一段时间内的运行画像,告诉我们系统“有多快”、“有多忙”、“消耗了多少资源”、“产生了多少错误”等等。对于Go应用而言,我们不仅关心其底层的资源消耗(如CPU、内存),也关心其业务层面的表现(如请求速率、处理延迟、错误数量等)。接下来,我们将学习Metrics的核心概念,了解主流的Go Metrics方案(特别是Prometheus及其兼容生态如VictoriaMetrics),并掌握如何在Go应用中实际暴露和收集指标。
Metrics的核心概念
在深入具体工具之前,我们先了解一下Metrics领域的一些通用核心概念。
首先是指标类型,最常见的指标类型包括:
-
Counter(计数器):一个单调递增的累积值,用于记录某个事件发生的总次数。例如,HTTP请求的总数、发生的错误总数。它只能增加或在应用重启时重置为零。我们通常关心其在一段时间内的变化率(rate)。
-
Gauge(仪表盘/瞬时值):一个可以任意上升或下降的数值,表示某个指标在特定时间点的瞬时值。例如,当前的CPU使用率、内存占用大小、队列中的任务数量、活跃的goroutine数量。
-
Histogram(直方图):对观察到的值(通常是请求延迟或响应大小)进行采样,并将其分布到一组可配置的桶(buckets)中进行计数,同时也会记录观察值的总和(sum)和总次数(count)。通过直方图,我们可以计算分位数(quantiles,如P95、P99延迟),从而更好地理解数据的分布情况,而不仅仅是平均值。
-
Summary(摘要/概要):与Histogram类似,也用于观察值的分布,但它直接在客户端(应用侧)计算和暴露预定义的分位数(例如,φ=0.5、φ=0.9、φ=0.99),以及总和(sum)和总次数(count)。计算分位数可能对客户端有一定性能开销,且聚合多个Summary实例的分位数比较困难。
标签(Labels / Tags)是实现Metrics多维度分析的关键。一个指标可以关联一组键值对标签,用于区分该指标的不同实例或方面。例如,一个名为 http_requests_total 的Counter可以有 method="GET"、 path="/api/users"、 status_code="200" 这样的标签,从而允许我们按HTTP方法(method)、路径(path)、状态码(status_code)等维度对请求总数进行聚合和查询。
时序数据库(TSDB - Time Series Database):专门用于存储和查询带有时间戳的指标数据(即时间序列)的数据库。Prometheus、VictoriaMetrics以及InfluxDB等都是常见的TSDB。
掌握了这些基本概念,我们还需要一个方法论来指导我们应该监控哪些指标。对于服务类应用,Grafana Labs的VP Product,同时也是Prometheus和OpenMetrics早期贡献者Tom Wilkie,于2018年提出的 RED方法论 是一个非常好的起点, 它能帮助我们快速搭建起一套核心的服务质量指标体系:
-
Rate(R - 速率):服务每秒处理的请求数量。这通常对应QPS或RPS。
-
Errors(E - 错误数/率):服务处理请求时发生的错误数量或错误率。
-
Duration(D - 耗时/延迟):服务处理每个请求所需的时间,通常关注其分布(如平均值、P90、P95、P99)。
监控这三个核心指标,能让我们对服务的健康状况和性能表现有一个基本的把握。对于不是Metrics专家的开发人员来说,遵循RED方法论至少能确保关键的服务质量指标被覆盖。除此之外, 对于更通用的应用或系统,Google的SRE经验总结出的“四个黄金信号”(Four Golden Signals)也是一个重要的参考:延迟(Latency)、流量(Traffic)、错误(Errors)、饱和度(Saturation)。 饱和度衡量的是服务有多“满”,强调了对系统中最受约束资源的监控。
有了这些核心概念和指导方法论,我们就可以来看Go生态中主流的Metrics方案了。
主流Metrics方案演进与Go实践
在Go生态中,Prometheus因其与云原生理念的天然契合,长期以来都是Metrics监控的事实标准。但随着技术的发展和对大规模、高性能监控需求的增加,也涌现出了一些优秀的替代或增强方案,如VictoriaMetrics。
Prometheus:云原生监控的事实标准
Prometheus是一个开源的监控和告警工具包,最初由SoundCloud开发,现已成为CNCF(Cloud Native Computing Foundation)的毕业项目。基于Prometheus的监控方案的核心架构包括多个关键组件:
-
Prometheus Server负责拉取、存储、查询和告警。
-
Exporters用于将非Prometheus格式的指标转换为可被Prometheus识别的格式。
-
Alertmanager处理告警信息。
-
Grafana则用于数据的可视化。
Prometheus方案通常采用Pull模型,定期通过HTTP从目标的 /metrics 端点拉取数据。这种方式确保了监控数据的实时性和准确性。在Go应用中,开发者可以通过使用官方的 prometheus/client_golang 库来暴露Prometheus格式的Metrics。具体步骤包括定义和注册自定义指标,例如使用 prometheus.NewCounterVec、 NewGaugeVec 和 NewHistogramVec 等函数,并通过 promhttp.Handler() 暴露 /metrics 端点,以便Prometheus Server能够访问这些指标数据。
// ch24/metrics/prometheus_example/main.go
package main
import (
"fmt"
"log"
"math/rand"
"net/http" // For prometheus.NewGoCollector example
"time"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promauto"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
var (
httpRequestsTotal = promauto.NewCounterVec(
prometheus.CounterOpts{
Name: "myapp_http_requests_total",
Help: "Total number of HTTP requests processed by the application.",
},
[]string{"method", "path", "status_code"},
)
httpRequestDurationSeconds = promauto.NewHistogramVec(
prometheus.HistogramOpts{
Name: "myapp_http_request_duration_seconds",
Help: "Histogram of HTTP request latencies.",
Buckets: prometheus.DefBuckets,
},
[]string{"method", "path"},
)
)
func handleHello(w http.ResponseWriter, r *http.Request) {
startTime := time.Now()
time.Sleep(time.Duration(rand.Intn(500)+50) * time.Millisecond)
statusCode := http.StatusOK
if rand.Intn(10) == 0 {
statusCode = http.StatusInternalServerError
w.WriteHeader(statusCode)
fmt.Fprintf(w, "Oops! Something went wrong.")
} else {
w.WriteHeader(statusCode)
fmt.Fprintf(w, "Hello from Go Metrics App!")
}
duration := time.Since(startTime).Seconds()
httpRequestsTotal.With(prometheus.Labels{
"method": r.Method,
"path": r.URL.Path,
"status_code": fmt.Sprintf("%d", statusCode),
}).Inc()
httpRequestDurationSeconds.With(prometheus.Labels{
"method": r.Method,
"path": r.URL.Path,
}).Observe(duration)
log.Printf("%s %s - %d, duration: %.3fs", r.Method, r.URL.Path, statusCode, duration)
}
func main() {
http.HandleFunc("/hello", handleHello)
metricsMux := http.NewServeMux()
metricsMux.Handle("/metrics", promhttp.Handler())
go func() {
log.Println("Metrics server listening on :9091")
if err := http.ListenAndServe(":9091", metricsMux); err != nil {
log.Fatalf("Failed to start metrics server: %v", err)
}
}()
log.Println("Application server listening on :8080")
if err := http.ListenAndServe(":8080", nil); err != nil {
log.Fatalf("Failed to start application server: %v", err)
}
}
在这个示例中,我们暴露了两个自定义指标,一个是Counter类型的myapp_http_requests_total,另外一个则是直方图类型的httpRequestDurationSeconds。
编译运行上述示例:
$cd ch24/metrics/prometheus_example
$go build
$./demo
2025/06/09 06:03:05 Application server listening on :8080
2025/06/09 06:03:05 Metrics server listening on :9091
接下来,我们在浏览器或用curl访问几次 http://localhost:8080/hello 来产生一些指标数据。然后访问 http://localhost:9091/metrics,你会看到Prometheus格式的文本指标输出,包括我们自定义的 myapp_http_requests_total、 myapp_http_request_duration_seconds,以及Go运行时指标(如 go_goroutines):
$ curl http://localhost:9091/metrics
# HELP go_gc_duration_seconds A summary of the wall-time pause (stop-the-world) duration in garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 0
go_gc_duration_seconds{quantile="0.25"} 0
go_gc_duration_seconds{quantile="0.5"} 0
go_gc_duration_seconds{quantile="0.75"} 0
go_gc_duration_seconds{quantile="1"} 0
go_gc_duration_seconds_sum 0
go_gc_duration_seconds_count 0
... ...
# HELP myapp_http_request_duration_seconds Histogram of HTTP request latencies.
# TYPE myapp_http_request_duration_seconds histogram
myapp_http_request_duration_seconds_bucket{method="GET",path="/hello",le="0.005"} 0
myapp_http_request_duration_seconds_bucket{method="GET",path="/hello",le="0.01"} 0
myapp_http_request_duration_seconds_bucket{method="GET",path="/hello",le="0.025"} 0
myapp_http_request_duration_seconds_bucket{method="GET",path="/hello",le="0.05"} 0
myapp_http_request_duration_seconds_bucket{method="GET",path="/hello",le="0.1"} 0
myapp_http_request_duration_seconds_bucket{method="GET",path="/hello",le="0.25"} 3
myapp_http_request_duration_seconds_bucket{method="GET",path="/hello",le="0.5"} 4
myapp_http_request_duration_seconds_bucket{method="GET",path="/hello",le="1"} 6
myapp_http_request_duration_seconds_bucket{method="GET",path="/hello",le="2.5"} 6
myapp_http_request_duration_seconds_bucket{method="GET",path="/hello",le="5"} 6
myapp_http_request_duration_seconds_bucket{method="GET",path="/hello",le="10"} 6
myapp_http_request_duration_seconds_bucket{method="GET",path="/hello",le="+Inf"} 6
myapp_http_request_duration_seconds_sum{method="GET",path="/hello"} 1.782521357
myapp_http_request_duration_seconds_count{method="GET",path="/hello"} 6
# HELP myapp_http_requests_total Total number of HTTP requests processed by the application.
# TYPE myapp_http_requests_total counter
myapp_http_requests_total{method="GET",path="/hello",status_code="200"} 5
myapp_http_requests_total{method="GET",path="/hello",status_code="500"} 1
... ...
promhttp_metric_handler_requests_total{code="200"} 0
promhttp_metric_handler_requests_total{code="500"} 0
promhttp_metric_handler_requests_total{code="503"} 0
直接查看这些文本指标对于调试来说可能有用,但要真正发挥Metrics的威力,我们需要让Prometheus来抓取和查询它们。
为了快速体验,我们可以使用Docker在本地启动一个单点的Prometheus实例。
我们先来创建Prometheus配置文件(prometheus.yml)。在你的项目目录(例如ch24/metrics/prometheus_example/下,或一个专门的monitoring目录)创建一个名为prometheus.yml的文件,内容如下:
# prometheus.yml
global:
scrape_interval: 15s # 每15秒抓取一次指标,默认为1分钟
evaluation_interval: 15s # 每15秒评估一次告警规则
# alerting: # 告警管理配置,本示例中暂时不配置Alertmanager
# alertmanagers:
# - static_configs:
# - targets:
# # - alertmanager:9093
scrape_configs:
# 第一个抓取作业:抓取Prometheus自身的指标 (可选,但有助于了解Prometheus健康状况)
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090'] # Prometheus默认监听9090端口
# 第二个抓取作业:抓取我们的Go应用暴露的指标
- job_name: 'my-go-app'
# 这里我们假设Go应用运行在宿主机,Prometheus在Docker中。
static_configs:
- targets: ['localhost:9091'] # 目标是宿主机的9091端口
labels:
instance: my-go-app-instance-1 # (可选) 为这个target添加标签
在这个配置文件中,scrape_interval定义了Prometheus抓取指标的频率,这里是15s抓取一次指标。在scrape_configs下,我们为my-go-app作业定义了一个static_configs。target列表中的 'localhost:9091' 告诉prometheus抓取指标的具体地址。
接下来,我们在包含prometheus.yml的目录下,打开终端并运行以下命令:
docker run \
-d \
--network host \
-v $(pwd)/prometheus.yml:/etc/prometheus/prometheus.yml \
--name prometheus-server \
prom/prometheus:latest
通过curl访问http://localhost:8080/hello来产生一些指标数据。然后等待片刻(例如,等待一两个scrape_interval的时间,即15-30秒),打开浏览器,访问Prometheus的Web UI: http://localhost:9090。点击顶部导航栏的 “Status” -> “Target health”。你应该能看到名为 my-go-app 的作业,其State应该是 “UP”,并且Last Scrape时间是最近的,如下图所示:
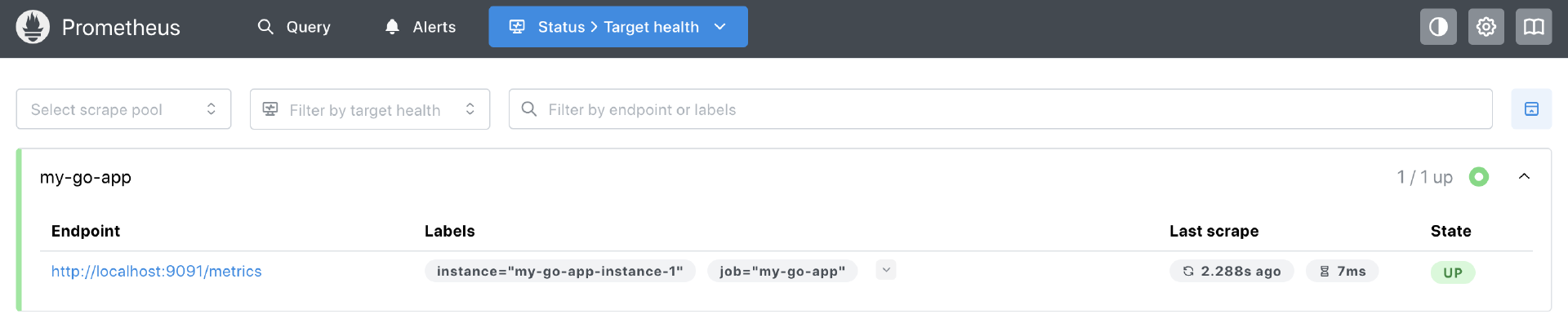
如果State是 “DOWN”,你需要检查网络连接(Docker容器是否能访问到宿主机的9091端口)和Go应用是否仍在运行且 /metrics 端点可访问。
在Prometheus Web UI的 “Query” 页面,你可以在表达式输入框中输入PromQL查询语句来查询和可视化你的Go应用指标。例如:
-
查询HTTP请求总数:myapp_http_requests_total,你应该能看到不同method、path、status_code组合的时间序列。
-
计算每秒请求速率(QPS):
rate(myapp_http_requests_total{path="/hello"}[1m]),这会显示过去1分钟内,/hello路径的平均每秒请求速率。 -
查询P95请求延迟:
histogram_quantile(0.95, sum(rate(myapp_http_request_duration_seconds_bucket{path="/hello"}[1m])) by (le))。 -
查询/hello的总请求次数:
myapp_http_request_duration_seconds_count{path="/hello"}(请求总次数)。 -
查询/hello的请求总耗时:
myapp_http_request_duration_seconds_sum{path="/hello"}(总耗时)。 -
查看Go运行时goroutine数量:
go_goroutines。
Prometheus的Web UI会以图表或表格的形式展示查询结果,如下图这样:
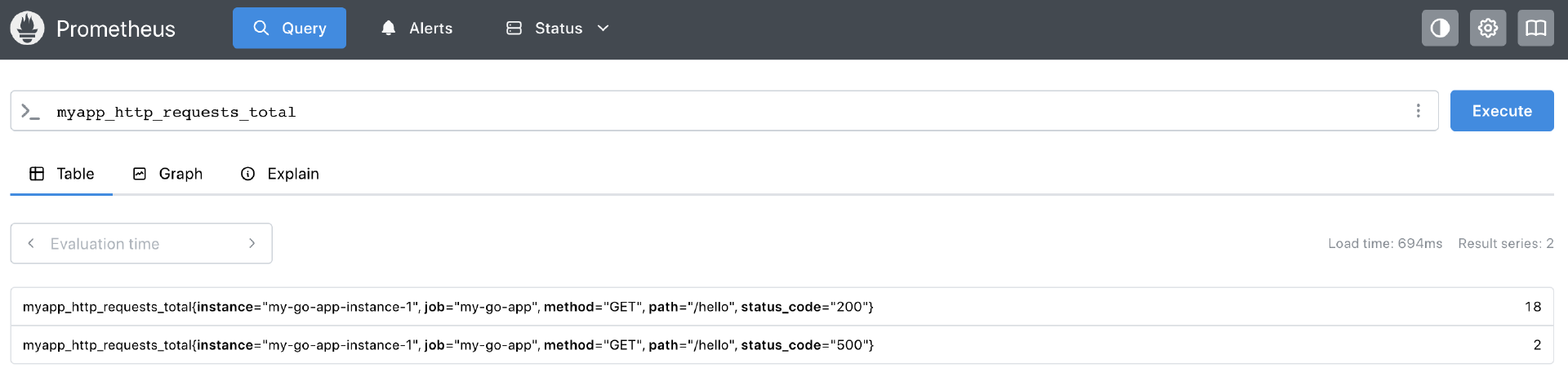
通过这个简单的单机Docker Prometheus部署,我们就成功地将Go应用暴露的Metrics数据收集起来,并能够使用强大的PromQL进行查询和分析了。这为我们后续使用Grafana进行更丰富的可视化和告警打下了基础。
Prometheus凭借其强大的数据模型、Pull机制的简洁性,以及与Kubernetes的深度集成(服务发现),奠定了其在云原生监控领域的领导地位。然而,正如任何系统一样,当面临大规模部署和对高可用性、长期存储的极致追求时,最初的Prometheus单点架构也暴露出了一些局限性。
Prometheus单点部署的挑战与演进方案
一个独立的Prometheus Server实例,虽然功能强大且易于上手,但在生产环境中,特别是当监控的Targets数量巨大、产生的指标时间序列非常多,或者对监控数据的持久性和可用性要求极高时,可能会遇到以下挑战:
-
单点故障:如果该Prometheus Server宕机,整个监控和告警系统就会失效。
-
存储容量与性能瓶颈:Prometheus Server内置的TSDB是为单机优化的,其存储容量受限于本地磁盘,当数据量过大或保留时间过长时,磁盘I/O和查询性能都可能成为瓶颈。
-
全局视图与数据聚合困难:如果你有多个独立的Prometheus Server(例如,每个Kubernetes集群或每个数据中心部署一个),要获得一个跨所有实例的全局指标视图,或者对来自不同Prometheus的数据进行统一聚合查询会比较困难。
-
长期数据存储:Prometheus本地TSDB通常不适合做非常长时间(例如,数年)的指标数据存储和高效查询。
为了解决这些问题,Prometheus社区和相关生态发展出了一系列优秀的解决方案, 它们通常围绕着如何实现Prometheus的高可用、可扩展和长期存储能力展开。
先来看方案一:Prometheus联邦(Federation)。
-
原理:允许一个Prometheus Server(上层Prometheus)从其他Prometheus Server(下层Prometheus)抓取(scrape)它们已经聚合或筛选过的指标数据。
-
用途:主要用于构建层次化的监控体系,例如,一个全局的Prometheus Server从多个数据中心或集群的Prometheus Server中收集关键的、聚合后的指标,以获得一个概览视图。
-
局限:联邦通常只抓取少量聚合数据,不适合传输原始的高基数指标;对于大规模的全局查询和长期存储,能力仍然有限。
方案二:Thanos。Thanos是一个非常流行的开源项目, 它旨在为Prometheus提供高可用、可扩展的全局查询视图和无限的长期存储能力,同时保持与Prometheus生态的兼容性。
-
核心组件与思想:
-
Sidecar:它与每个Prometheus Server实例一起部署,负责将Prometheus本地TSDB中的数据块(通常是最近2小时的数据)上传到对象存储(如S3、GCS、Azure Blob Storage、MinIO等)进行长期存储,并暴露一个Store API供查询。
-
Query(Thanos Querier):一个无状态的组件,它实现了Prometheus的查询API。当收到查询请求时,它会同时查询所有Prometheus Sidecar(获取近期数据)和Store Gateway(获取长期历史数据),并将结果合并后返回给用户或Grafana。这提供了全局的、跨所有Prometheus实例的查询视图。
-
Store Gateway:部署在对象存储之前,它实现了Store API,使得Thanos Querier能够查询存储在对象存储中的历史数据块。
-
Compact(Thanos Compactor):负责对对象存储中的数据块进行压缩(compaction)和降采样(downsampling),以优化存储效率和长期查询性能。
-
Ruler(Thanos Ruler):用于在全局数据视图上执行记录规则和告警规则(可选)。
-
Receive(Thanos Receiver):允许通过Prometheus的Remote Write协议直接将数据写入Thanos的长期存储(绕过Sidecar和本地Prometheus存储),适用于某些场景(可选)。
-
-
优点:提供了真正的全局查询视图和基于对象存储的、经济高效的长期存储方案;与Prometheus紧密集成;高可用性(Querier、Store Gateway等组件可以水平扩展)。
-
部署与运维:Thanos本身是一个分布式系统,其部署和运维相比单点Prometheus要复杂许多。
方案三:Cortex Cortex。Cortex Cortex是另一个CNCF孵化项目,它提供了一个水平可扩展、高可用、多租户的、兼容Prometheus的监控系统。Cortex通常接收来自Prometheus Server(通过Remote Write)或兼容Agent推送的指标数据。其内部架构也比较复杂,包含了Ingester、Distributor、Querier、Ruler、Compactor、Store Gateway等多个微服务组件,并依赖NoSQL数据库(如Cassandra、Bigtable)或对象存储作为后端。 Cortex更侧重于构建大规模、多租户的监控即服务(Monitoring-as-a-Service)平台。
这些方案(特别是Thanos和Cortex)极大地扩展了Prometheus的能力,使其能够胜任非常大规模的监控场景。然而,它们自身也引入了新的运维复杂性。
正是在这样的背景下,一些力求在性能、可扩展性和运维简洁性之间取得更好平衡的新兴解决方案开始受到关注,VictoriaMetrics便是其中的佼佼者。
VictoriaMetrics:高性能、可扩展的Prometheus兼容监控方案
VictoriaMetrics是一款开源的高性能、高性价比的时间序列数据库和监控解决方案,与Prometheus生态系统高度兼容。它的崛起背景与大规模Prometheus集群(结合Thanos或Cortex)运维的复杂性以及其他时间序列数据库(如InfluxDB 3.0核心转向Rust)的变化密切相关。这些因素为VictoriaMetrics这样的新兴方案提供了发展空间,许多用户发现它在提供强大功能的同时,部署和运维相对更为简单。
VictoriaMetrics具备几个核心优势。首先,它在数据摄入和查询性能方面表现优异,自定义的时间序列数据库存储引擎实现了 高压缩比,有效降低了存储成本。其次,相较于其他分布式时间序列数据库方案,VictoriaMetrics的单点和集群版本通常 对CPU和内存的占用更低,表现出较低的资源消耗。
在部署和水平扩展方面,VictoriaMetrics提供了 易于使用的单节点版本(victoria-metrics-single),适合中小型监控场景或作为评估入门。该版本将所有功能集成在一个二进制文件中,方便启动和使用。而集群版本则通过清晰分离的组件(vmstorage用于存储,vminsert作为数据写入代理,vmselect作为数据查询代理)实现水平扩展,架构相对简洁。
此外,VictoriaMetrics与Prometheus生态系统 高度兼容,支持Prometheus的抓取协议,可以直接抓取Go应用暴露的 /metrics 端点,或通过其Agent vmagent进行抓取。它还全面支持PromQL查询语言,并可以作为Prometheus的远程写后端(Remote Write target),同时支持Grafana作为可视化前端。
最后,VictoriaMetrics支持Push和Pull模型,除了通过vmagent进行Pull外,它还原生支持通过HTTP API接收多种协议(如InfluxDB Line Protocol、Graphite、OpenTSDB、DataDog和Prometheus Remote Write)推送的指标数据。这些特性使得VictoriaMetrics成为一个灵活且高效的监控解决方案。国内很多互联网大厂都将其可观测平台升级到了以VictoriaMetrics为中心的新一代方案。
下面我们就来介绍一下这个方案的参考架构,以及一个简单的演示示例。
Go应用集成与参考架构
一个常见的、推荐的集成架构是,让本地的Prometheus Server(或vmagent)负责指标的抓取,然后通过Prometheus的remote_write功能,将所有(或筛选后的)指标数据实时写入到中心的VictoriaMetrics(单点或集群)进行长期存储和统一查询。
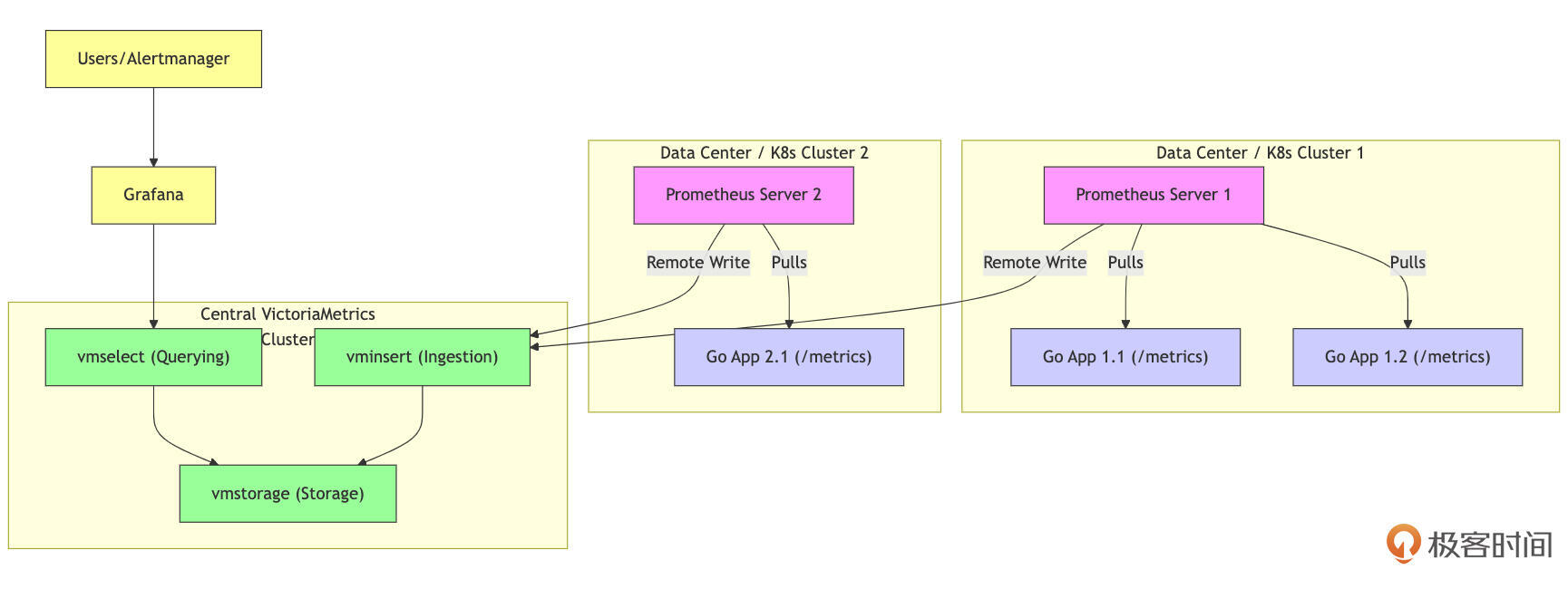
如上图所示:在应用环境中,部署一个或多个抓取代理(Scraper)是监控系统的第一步。这些抓取代理可以是标准的Prometheus Server,也可以是更轻量的vmagent。它们的主要职责是通过HTTP Pull的方式,从你的Go应用及其他需要监控的目标的 /metrics 端点收集指标数据。
一旦抓取代理收集到这些指标数据,它们会使用Prometheus的remote_write协议,将数据实时地通过HTTP Post的方式发送给VictoriaMetrics的数据摄入组件(VMInsert)。对于VictoriaMetrics的单节点版本,通常会监听一个端口,处理写入和查询请求。
接下来,VMInsert负责接收这些数据,并进行初步处理,然后将数据分发到存储节点(VMStorage)进行高效的压缩和持久化。这一过程确保了数据的高效存储和管理。
最后,当用户或Grafana需要查询数据时,它们会向VictoriaMetrics的查询组件(VMSelect)发送PromQL查询请求。VMSelect会从VMStorage中检索相关数据,执行查询,并将结果返回给请求者。这一整套流程确保了数据的实时获取、处理和查询,为监控系统提供了高效的解决方案。
这种架构的优势在于:
-
解耦:抓取层(Prometheus/vmagent)与存储/查询层(VictoriaMetrics)分离,各自可以独立扩展和管理。
-
兼容性:Go应用无需任何改动,继续暴露Prometheus格式的metrics。
-
性能与效率:充分利用了Prometheus成熟的服务发现和抓取能力,以及VictoriaMetrics在存储、查询性能和资源效率上的优势。
-
长期存储:VictoriaMetrics非常适合作为Metrics的长期存储解决方案。
下面我们就使用Docker部署单机版VictoriaMetrics并通过Prometheus Remote Write写入数据来演示一下上述架构过程。由于VictoriaMetrics与Prometheus的抓取协议和远程写协议兼容,我们之前为Prometheus编写的Go应用无需任何修改。我们将分别使用 docker run 命令启动一个Prometheus实例(配置为将数据Remote Write到VictoriaMetrics)和一个单节点的VictoriaMetrics实例。
假设你在项目根目录下创建一个名为 monitoring_vm 的子目录,用于存放相关的配置文件。
// ch24/metrics/prometheus_example下面
# tree -F -L 1 monitoring_vm
monitoring_vm/
├── prometheus.yml # Prometheus配置文件(增加remote write配置)
└── vm_data/ # VictoriaMetrics数据持久化目录
这个配置文件与之前`docker-compose`示例中的类似
这里的prometheus.yml与前面的不同之处在于新增的remote_write部分需要指向VictoriaMetrics容器的地址:
// ch24/metrics/prometheus_example/monitoring_vm/prometheus.yml
global:
scrape_interval: 15s # 每15秒抓取一次指标,默认为1分钟
evaluation_interval: 15s # 每15秒评估一次告警规则
remote_write: # 本次新增
- url: "http://localhost:8428/api/v1/write"
# queue_config: # (可选)
# capacity: 50000
# max_samples_per_send: 5000
scrape_configs:
# 第一个抓取作业:抓取Prometheus自身的指标 (可选,但有助于了解Prometheus健康状况)
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090'] # Prometheus默认监听9090端口
# 第二个抓取作业:抓取我们的Go应用暴露的指标
- job_name: 'my-go-app'
# 这里我们假设Go应用运行在宿主机,Prometheus在Docker中。
static_configs:
- targets: ['localhost:9091'] # 目标是宿主机的9091端口
labels:
instance: my-go-app-instance-1 # (可选) 为这个target添加标签
接下来,使用 docker run 分别启动VictoriaMetrics和Prometheus的单节点实例,其中Prometheus的启动命令与前面的一致,VictoriaMetrics的启动命令如下:
// 在ch24/metrics/prometheus_example/monitoring_vm下执行
$ docker run -d \
--name victoriametrics-server \
--network host \
-v $(pwd)/vm_data:/victoria-metrics-data \
victoriametrics/victoria-metrics:latest \
-retentionPeriod=1y \
-storageDataPath=/victoria-metrics-data
这里有几个启动参数需要注意。首先,使用 -v $(pwd)/vm_data:/victoria-metrics-data 参数可以将本地的vm_data目录挂载到容器内。这一设置用于持久化VictoriaMetrics的数据,因此确保该目录存在或Docker具有创建权限是非常重要的。需要特别注意的是, $(pwd) 在Linux和macOS下指的是当前目录,确保路径的正确性至关重要。
其次, -retentionPeriod=1y 参数用于设置数据的保留期限为一年。这意味着在这一时间段内,数据将被保留,超出期限的数据将会被清理。
最后, -storageDataPath=/victoria-metrics-data 参数用于指定容器内的数据存储路径,这一路径与挂载的卷相对应。这一设置确保了VictoriaMetrics能够在正确的位置存储和管理数据,从而实现高效的数据持久化。通过这些参数的配置,可以有效地管理VictoriaMetrics的数据存储和保留策略。
接下来,我们就可以验证数据是否写入VictoriaMetrics了。我们等待一段时间(例如,几个抓取周期,几十秒到一分钟),让Prometheus抓取Go应用指标并通过remote_write发送给VictoriaMetrics。打开浏览器访问VictoriaMetrics自带的Web页面 http://localhost:8428/vmui/。在VMUI的查询框中,输入PromQL查询语句来查询已写入的指标,例如: myapp_http_requests_total。
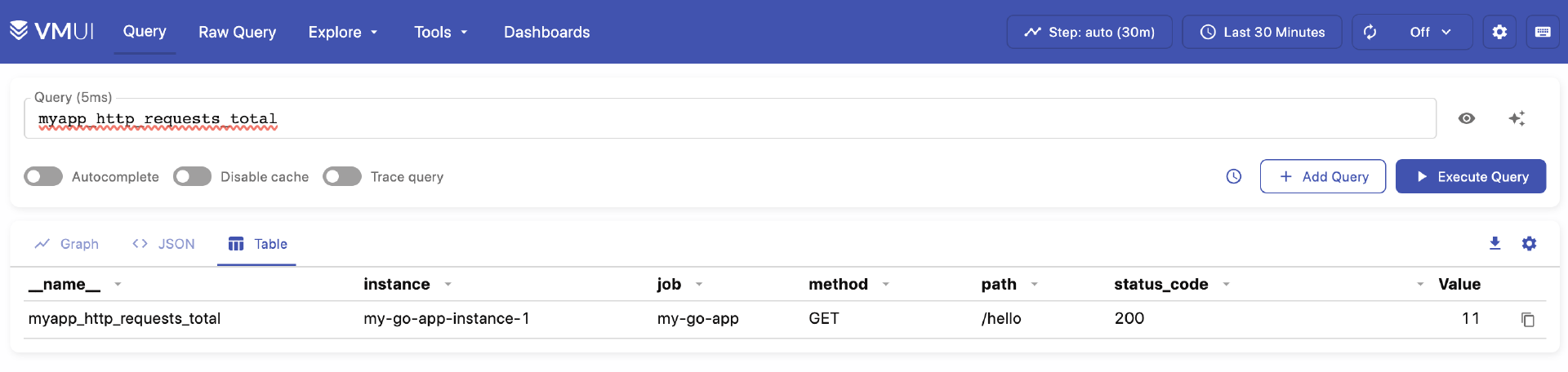
如果你能像上图那样查询到来自my-go-app作业的指标,并且数据在持续更新,说明从Go应用 -> Prometheus -> VictoriaMetrics的整个数据流已经成功建立。
这个示例演示了如何将Prometheus作为抓取代理,并将数据长期存储在VictoriaMetrics中。在实际生产中,你也可以直接使用vmagent来代替Prometheus Server进行抓取和远程写入,以获得更轻量级的抓取端。
VictoriaMetrics凭借其出色的性能、资源效率、易用性和Prometheus兼容性,正迅速成为Go社区乃至整个云原生监控领域一个非常受欢迎的选择,尤其适合那些对性能和成本敏感的大规模监控场景,或者希望从传统Prometheus部署简化运维的团队。
了解了如何收集和存储指标后,我们还需要一个强大的工具来将这些冰冷的数字转化为直观的图表和可行动的洞察。
指标数据可视化与告警
Grafana 是目前最流行的开源监控数据可视化和分析平台。它以其强大的图表能力、灵活的仪表盘定制、丰富的数据源支持以及美观的界面而著称。它可以连接包括Prometheus、VictoriaMetrics、InfluxDB、Elasticsearch、Loki、Tempo在内的众多数据源。Grafana的入门使用方法非常简单,我这里就以Grafana + VictoriaMetrics展示 my-go-app 的RED指标为例,简单介绍一下Grafana的入门使用方法,当然更高阶的玩法你可以自行阅读Grafana文档学习。
下面,我们将演示如何使用Docker运行一个Grafana实例、如何在Grafana中添加VictoriaMetrics作为数据源,以及如何创建一个简单的仪表盘(dashboard),展示我们之前Go应用(my-go-app)暴露的并已存入VictoriaMetrics的RED指标,包括:
-
Rate(R):
/hello路径的每秒请求数。 -
Errors(E):
/hello路径的HTTP 5xx错误率。 -
Duration(D):
/hello路径的P95请求延迟。
首先,我们使用Docker启动一个Grafana实例:
$ docker run -d \
--name grafana-server \
-p 3000:3000 \
--network host \
-e "GF_SECURITY_ADMIN_USER=admin" \
-e "GF_SECURITY_ADMIN_PASSWORD=admin" \
grafana/grafana-oss:latest
实例启动成功后,我们在浏览器中打开http://localhost:3000,并使用用户名admin和密码admin登录。
进入Grafana主页面后,我们下一步就是添加VictoriaMetrics这个数据源。在Grafana主界面的左侧导航栏,找到图标(Connections)并点开后,选择 Data sources。然后在 Data sources 页面点击Add new data source按钮。在数据源类型列表中,搜索并选择Prometheus。是的,你没有看错,因为VictoriaMetrics与Prometheus的查询API兼容,所以我们选择Prometheus类型的数据源来连接VictoriaMetrics。
在配置数据源时,我们给这个数据源取个名字 VictoriaMetrics-Local,并输入VictoriaMetrics的查询API地址: http://localhost:8428。之后点击页面底部的 “Save & test” 按钮。如果一切配置正确,你应该会看到 “Data source is working” 的绿色提示。
现在我们创建一个新的仪表盘(dashboard)来展示my-go-app的指标。
在左侧导航栏点击加号图标(+),选择Dashboard。在新仪表盘中,点击Add new panel(或Add visualization)。我们会像这样添加三个面板(panel),它们的名字和query语句分别如下:
- 面板1:Rate(QPS for
/hello)。PromQL查询语句(计算/hello的每秒请求速率):
sum(rate(myapp_http_requests_total{job="my-go-app", path="/hello"}[1m])) by (path)
- 面板2:Errors(HTTP 5xx Error Rate for
/hello)。PromQL查询语句(计算5xx错误率):
sum(rate(myapp_http_requests_total{job="my-go-app", path="/hello", status_code=~"5.."}[1m]))
/
sum(rate(myapp_http_requests_total{job="my-go-app", path="/hello"}[1m]))
* 100
- 面板3:Duration(P95 Latency for
/hello)。PromQL查询语句(计算P95延迟):
histogram_quantile(0.95, sum(rate(myapp_http_request_duration_seconds_bucket{job="my-go-app", path="/hello"}[5m])) by (le, path))
配置完的Dashboard整体展示如下图所示:
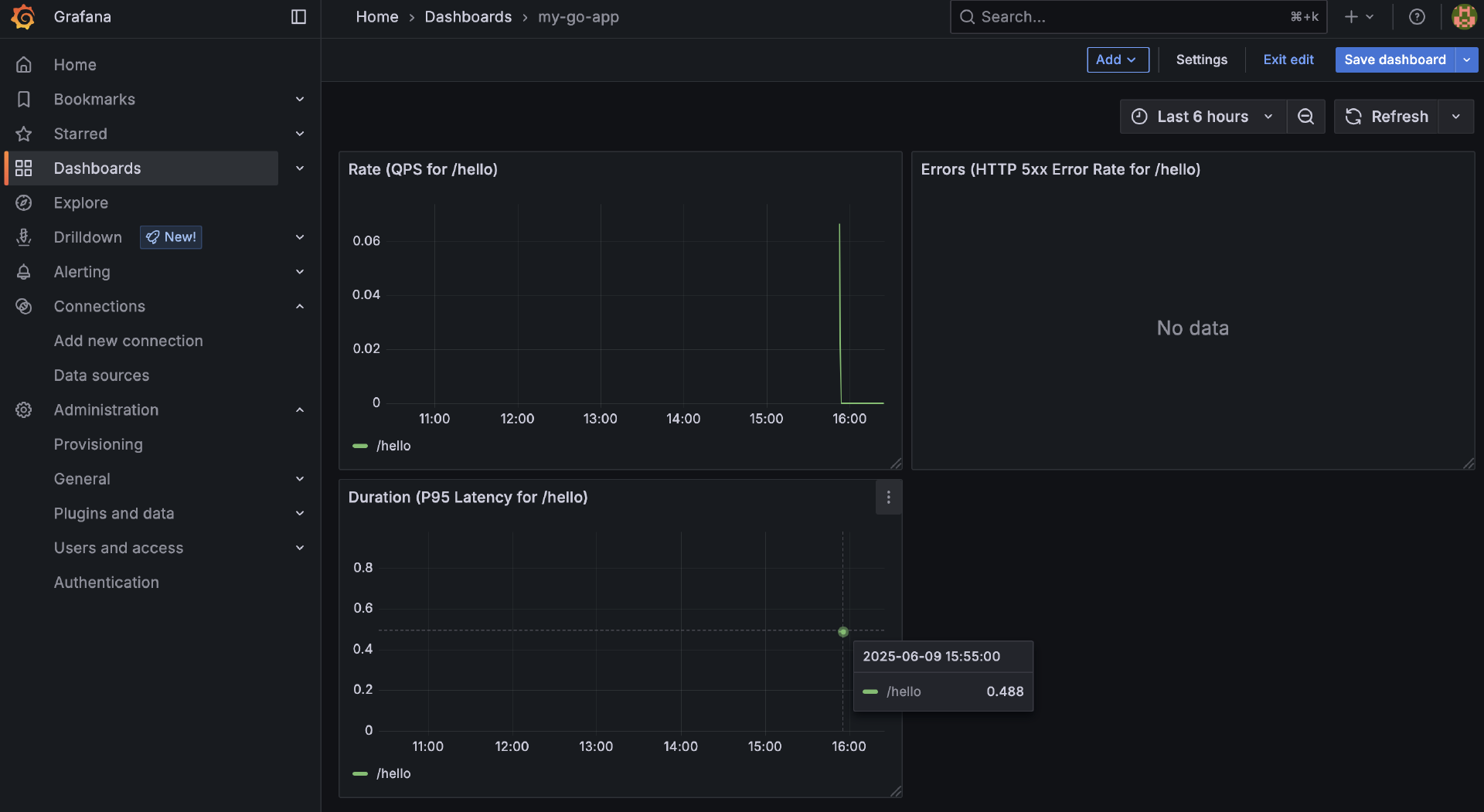
现在,你应该有了一个简单的Grafana仪表盘,它从VictoriaMetrics中读取由你的Go应用产生、经Prometheus收集并写入的RED指标,并以图表的形式实时展示出来。你可以继续访问Go应用的 /hello 端点来产生更多数据,观察仪表盘上的变化。
Grafana不仅能可视化,还能基于这些查询设置告警,但内容较多,我们就不展开了。Grafana与Prometheus/VictoriaMetrics的结合,为我们提供了一个功能强大且用户友好的监控数据可视化和告警平台。这使得我们能够将从Go应用收集到的Metrics数据转化为易于理解的、实时的运行状态视图,并基于这些视图设置有效的告警,从而实现对应用健康状况的持续监控和主动响应。
在掌握了如何通过Metrics来量化系统状态之后,我们还需要一种方法来记录系统中发生的具体事件和它们的详细上下文,这就是日志系统要解决的问题。
Go应用的Logging:记录关键事件与上下文
日志是可观测性的三大支柱中,信息密度最高、最接近原始事件细节的一环。与Metrics提供的聚合性、数值型概览不同,日志记录的是离散的、带有时间戳的事件,它们为我们提供了关于特定操作、错误或状态变化的详细上下文。高质量的日志是故障排查、行为审计和深入理解系统行为不可或缺的“证据”。
在深入具体的日志收集和分析方案之前,我们首先需要明确,一个现代化的、服务于可观测性目标的日志系统,应该具备哪些核心要素。
日志的核心要素回顾
前面,我们已经初步探讨了日志系统,这里我们再次强调并从可观测性的角度深化几个关键要素。
首先来看结构化日志。再次强调, 结构化日志是现代日志系统的绝对核心和标配。 告别无格式的纯文本日志,拥抱JSON或logfmt(key=value pairs)等结构化格式。
结构化日志使得每一条记录都成为一个富含元数据的小型“数据库条目”。这使得后续的日志收集代理(如Fluentd、Promtail)能够轻松解析,并在集中的日志存储和分析系统(如Loki、Elasticsearch、VictoriaLogs)中进行高效的字段级索引、搜索、过滤、聚合和可视化。比如,你可以轻易地查询“过去1小时内,order-service服务所有level为ERROR且与特定trace_id相关的日志”。
再来看 日志级别。DEBUG、INFO、WARN、ERROR、FATAL/CRITICAL等多种日志级别允许根据环境(开发、测试、生产)和当前需求(常规监控 vs 深度排障)动态调整日志的详细程度,从而在信息量和日志存储/处理成本之间取得平衡。
接着来看丰富的上下文信息,它 是提升日志诊断价值的关键。除了标准的时间戳、级别、消息、服务名、实例ID之外,应尽一切可能在日志中包含与当前事件相关的、有助于理解和关联的上下文信息。
首先,可观测性关联ID是实现日志与追踪数据关联的核心。通过集成分布式追踪,可以自动或手动将 trace_id 和 span_id 添加到所有相关日志条目中,以便于跟踪请求或操作。此外,对于每个外部请求(如HTTP请求),应生成一个唯一的 request_id 并在所有相关日志中携带,以便于后续分析。
其次,记录业务与用户上下文也非常重要。这包括 user_id、 session_id、 tenant_id,以及与当前业务操作相关的核心实体ID,如 order_id、 product_id 和 payment_id 等,这些信息有助于理解事件的背景。
另外,技术栈上下文同样不可忽视。对于HTTP服务日志,应记录 http_method、 http_path、 http_status_code 等信息;对于gRPC服务,则需记录 grpc_method 和 grpc_status_code。此外,脱敏后的 db_query、 queue_name 和 message_id(对于消息队列)也应记录,以提供更全面的技术背景。
最后,在记录错误详情时,除了错误消息外,还应包含错误类型、关键错误码以及简化的错误堆栈(特别是在未预期的错误情况下)。这些信息将有助于快速定位和解决问题。
我们来看 可配置的输出目标与收集策略。日志系统应具备可配置的输出目标与收集策略,以确保高效的日志管理。在云原生和容器化环境中,最佳实践是让Go应用将所有结构化日志直接输出到标准输出(stdout)和标准错误(stderr),这样应用无需处理日志文件的写入和管理,这些任务由基础设施层负责。同时,日志收集代理(如Filebeat、Fluent Bit、Promtail等)应部署在节点或Sidecar中,负责从应用容器的输出中收集日志,并进行初步解析和过滤,随后转发至集中式日志存储后端。集中式日志存储与分析是可观测性的核心部分,而日志的输出与收集策略应服务于整体可观测性目标。
最后来看 性能考量。日志记录操作不应成为应用的性能瓶颈。对于高吞吐量的应用,可考虑使用异步日志记录,比如应用线程将日志消息放入内存队列,由专门的后台goroutine负责实际I/O。但需注意队列满或应用崩溃时可能丢失少量日志的风险。
具备了这些核心要素,我们的日志系统才能真正成为诊断问题、理解系统行为的有力工具。现在,我们来看看当Go应用将这些高质量的日志输出后,它们是如何被收集、存储和分析的。
日志输出策略与收集方案的演进
Go应用如何输出日志,以及这些日志如何被高效地收集、存储并最终用于分析,是构建有效日志体系的关键。
遵循云原生最佳实践,Go 应用应将所有日志(包括业务日志、访问日志和错误日志)直接输出到标准输出(stdout)和标准错误(stderr)。这种策略的主要优势在于解耦和标准化。应用无需关心日志文件的存储位置、格式或轮转策略,这些工作由基础设施层(如容器运行时和日志收集代理)处理。此外,Kubernetes 等编排平台提供了内置机制来收集这些日志流,使运维团队能够独立于应用部署选择和更换日志收集代理和后端存储系统。
在 Go 中,可通过标准库 log 设置输出为 os.Stdout 或 os.Stderr。如果使用 log/slog,可以在创建 TextHandler 或 JSONHandler 时指定输出目标。第三方日志库如 zap 和 logrus 也支持配置输出到 io.Writer。
一旦日志通过标准流输出,就需要集中系统聚合来自众多容器实例的日志,并提供存储、索引和查询分析能力。
传统的 ELK/EFK Stack(Elasticsearch/OpenSearch、Logstash/Fluentd、Kibana)是一个重量级的解决方案,该方案通过部署日志收集代理(如 Filebeat 或 Fluentd)来收集日志,再通过 Logstash 处理与转换,最终存储在 Elasticsearch 中供查询和可视化使用。尽管功能强大,但这个方案的资源消耗也极高。
相比之下,Grafana Loki 提供了一个轻量级的日志聚合系统,只索引日志的元数据(标签),而不对完整内容进行全文索引。这使得 Loki 在存储和内存成本上具有优势,且易于与 Grafana 和 Prometheus 生态系统集成。然而,Loki 在处理广泛查询时性能较差,尤其是在没有有效标签进行预过滤的情况下。
新兴的 VictoriaLogs 采用列式存储和布隆过滤器的设计,旨在提供更高的性能和资源效率。它结合了标签索引和高压缩比的优势,支持对高基数字段的高效查询。VictoriaLogs 提供了类 SQL 的查询语言(LogsQL),使得复杂的日志分析变得更加便捷。此外,VictoriaLogs为单一二进制文件,易于部署和配置,且最新版本还支持集群模式,可以灵活地水平扩展。
选择哪种日志收集、存储和分析方案,是一个需要根据团队规模、数据量、查询需求、运维能力、成本预算以及与现有监控体系的集成偏好等多种因素综合权衡的决策。但无论你选择哪种强大的后端日志系统(如ELK、Loki或我们接下来重点演示的VictoriaLogs), Go应用本身如何产生高质量的、结构化的、富含上下文的日志,是决定整个日志体系能否发挥最大价值的源头。 这正是我们接下来要结合实战详细探讨的。
在可观测性的“黄金三角”中,日志扮演着记录离散事件、提供详细上下文的关键角色。为了让Go应用的日志能够被高效地收集、存储、索引,并能与其他遥测数据(如TraceID)轻松关联,我们需要在应用层面遵循一系列最佳实践。
具体来说,我们将:
-
在Go应用中使用log/slog输出结构化、富含上下文的JSON日志到标准输出。
-
使用Filebeat作为日志收集代理,从Go应用容器的stdout收集这些日志。
-
配置Filebeat将日志直接发送到VictoriaLogs的Elasticsearch兼容API。
-
最后,在Grafana中配置VictoriaLogs数据源并查询这些日志。
Go应用侧:使用slog输出高质量的JSON日志
回顾我们之前学习的log/slog,以及本节课前面讨论的日志核心要素,我们的Go应用在输出日志时应遵循:
-
配置slog.JSONHandler并输出到os.Stdout。
-
在创建Logger时或通过.With()添加全局/组件级上下文:service_name、service_version、instance_id(或让收集代理添加)、environment等。
-
在处理请求或特定业务逻辑时,创建携带请求级/任务级上下文的Logger:
-
trace_id 和 span_id(如果集成了OpenTelemetry):这是实现日志与追踪深度关联的核心!
-
request_id、user_id、session_id等。
-
其他关键业务ID(如order_id)。
-
-
日志消息简洁明了,可变信息作为slog.Attr:避免将变量直接拼接到消息字符串中。
-
结构化地记录错误:使用slog.Any(“error”, err),并考虑是否需要记录更详细的错误类型或码。
-
不记录敏感信息,或确保已脱敏。
下面我们来看一个示例Go应用:
// ch24/logging/slog_example/main.go
package main
import (
"context" // 引入context,虽然本例中未深度使用OTel的context,但为最佳实践预留
"fmt"
"log/slog"
"math/rand"
"net/http"
"os"
"strings"
"time"
// "go.opentelemetry.io/otel/trace" // 假设如果用了OTel,会这样获取traceID
)
const (
serviceName = "my-go-filebeat-app"
serviceVersion = "1.0.0"
)
// 模拟从context获取TraceID (在实际OTel集成中,这会由OTel库提供)
func getMockTraceID(ctx context.Context) string {
// In a real app with OTel:
// span := trace.SpanFromContext(ctx)
// if span.SpanContext().HasTraceID() {
// return span.SpanContext().TraceID().String()
// }
// For demo, generate a random-like one
return fmt.Sprintf("trace-%x", rand.Int63n(time.Now().UnixNano()))
}
func main() {
// --- 初始化slog Logger (输出JSON到stdout) ---
logLevel := new(slog.LevelVar) // Default to Info
logLevel.Set(slog.LevelInfo) // 可以从配置读取和设置
if os.Getenv("LOG_LEVEL") == "debug" {
logLevel.Set(slog.LevelDebug)
}
jsonHandler := slog.NewJSONHandler(os.Stdout, &slog.HandlerOptions{
AddSource: true, // 添加源码位置
Level: logLevel,
ReplaceAttr: func(groups []string, a slog.Attr) slog.Attr {
if a.Key == slog.TimeKey { // 标准化时间格式
a.Value = slog.StringValue(a.Value.Time().Format(time.RFC3339Nano))
}
if a.Key == slog.LevelKey { // 将级别转为大写字符串
level := a.Value.Any().(slog.Level)
a.Value = slog.StringValue(strings.ToUpper(level.String()))
}
return a
},
})
// 创建基础Logger,并添加全局属性
baseLogger := slog.New(jsonHandler).With(
slog.String("service_name", serviceName),
slog.String("service_version", serviceVersion),
)
slog.SetDefault(baseLogger) // 设置为全局默认logger,方便各处使用
slog.Info("Application starting...", slog.String("log_level_set", logLevel.Level().String()))
// --- HTTP服务器逻辑 ---
http.HandleFunc("/hello", func(w http.ResponseWriter, r *http.Request) {
// 为每个请求创建上下文相关的logger
// 在实际应用中,trace_id和request_id会由中间件或上游服务注入到context或请求头
ctx := r.Context() // 假设context中已包含追踪信息
traceID := getMockTraceID(ctx) // 模拟获取TraceID
requestID := r.Header.Get("X-Request-ID")
if requestID == "" {
requestID = fmt.Sprintf("req-%x", rand.Int63n(time.Now().UnixNano()))
}
reqLogger := slog.Default().With( // 使用默认logger并添加属性
slog.String("trace_id", traceID),
slog.String("request_id", requestID),
slog.String("http_method", r.Method),
slog.String("http_path", r.URL.Path),
)
reqLogger.Info("Received request for /hello.")
// 模拟业务处理
processingTime := time.Duration(rand.Intn(100)+20) * time.Millisecond
time.Sleep(processingTime)
if rand.Intn(10) < 2 { // 20%概率出错
err := fmt.Errorf("simulated internal error processing hello request")
reqLogger.Error("Failed to process /hello request.",
slog.Any("error", err.Error()), // 直接记录err.Error()字符串
slog.Duration("processing_time_ms", processingTime),
)
http.Error(w, "Internal Server Error", http.StatusInternalServerError)
return
}
reqLogger.Info("Successfully processed /hello request.",
slog.Duration("processing_time_ms", processingTime),
slog.String("response_payload", "Hello Gopher!"),
)
fmt.Fprintln(w, "Hello Gopher!")
})
port := "8088" // Go应用监听的端口
slog.Info("HTTP server listening on port.", slog.String("port", port))
if err := http.ListenAndServe(":"+port, nil); err != nil {
slog.Error("Failed to start HTTP server.", slog.Any("error", err))
os.Exit(1)
}
}
这个Go应用会输出类似这样的JSON日志到stdout:
{"time":"2025-06-10T02:06:25.591684388Z","level":"INFO","source":{"function":"main.main.func2","file":"/app/main.go","line":81},"msg":"Received request for /hello.","service_name":"my-go-filebeat-app","service_version":"1.0.0","trace_id":"trace-33da44cd87bb672","request_id":"req-133a11250538e0c7","http_method":"GET","http_path":"/hello"}
{"time":"2025-06-10T02:06:25.626013097Z","level":"INFO","source":{"function":"main.main.func2","file":"/app/main.go","line":97},"msg":"Successfully processed /hello request.","service_name":"my-go-filebeat-app","service_version":"1.0.0","trace_id":"trace-33da44cd87bb672","request_id":"req-133a11250538e0c7","http_method":"GET","http_path":"/hello","processing_time_ms":34000000,"response_payload":"Hello Gopher!"}
接下来,我们使用Docker运行VictoriaLogs单节点实例,并确保其Elasticsearch兼容的批量插入API(默认在主HTTP端口9428的 /insert/elasticsearch/ 路径)可被Filebeat访问:
# 在ch24/logging/slog_example下面执行,确保vlogs_data目录已经存在
ker run -d \
--name victorialogs-server \
-p 9428:9428 \
-v $(pwd)/vlogs_data:/victoria-metrics-data \
--network host \
victoriametrics/victoria-logs:latest \
-storageDataPath=/victoria-metrics-data \
-retentionPeriod=30d
然后,我们配置并运行Filebeat将Go应用日志发送到VictoriaLogs。Filebeat是elastic开源的、Go实现的日志collector。当然VictoriaLogs还支持其他的主流collector,比如logstash、fluentd、vector等。我们将配置Filebeat的container input来收集Docker日志,并使用output.elasticsearch将其直接发送到VictoriaLogs:
# ch24/logging/slog_example/filebeat.yml
filebeat.inputs:
- type: filestream
id: my-go-app-logs # 唯一的 ID
paths:
- /var/lib/docker/containers/*/*.log
parsers:
- container:
stream: all
processors:
# 第二步解析:对 'message' 字段中包含的应用日志字符串进行解码
- decode_json_fields:
fields: ["message"] # 告诉处理器去解析 'message' 字段的内容
target: "" # 将解析出的键值对(如 'msg', 'level', 'time')放到事件的根级别
overwrite_keys: true # 如果有同名字段,用解析出来的值覆盖(比如用应用的'time'覆盖)
add_error_key: true
- timestamp:
field: time # 使用刚刚从内层JSON解析出来的 'time' 字段
layouts:
- '2006-01-02T15:04:05.999999999Z'
# 如果解析失败,不要恐慌,但要记录下来
on_failure:
- append_to_array:
field: error.message
value: "Failed to parse application timestamp."
- drop_fields:
fields: [message] # 'message' 字段已经被解析,可以丢弃了
ignore_missing: true
output.elasticsearch:
hosts: ["http://localhost:9428/insert/elasticsearch/"]
parameters:
_msg_field: "msg"
_time_field: "@timestamp"
_stream_fields: "service_name,level,http_method"
allow_older_versions: true
使用Docker运行Filebeat:
# 在ch24/logging/slog_example下面执行,确保filebeat.yml文件已经存在
docker run -d \
--user root \
--name filebeat-to-victorialogs \
-v /var/lib/docker/containers:/var/lib/docker/containers:ro \
-v /var/run/docker.sock:/var/run/docker.sock:ro \
-v $(pwd)/filebeat.yml:/usr/share/filebeat/filebeat.yml:ro \
--network host \
docker.elastic.co/beats/filebeat:9.0.0
构建Go应用的Docker镜像,并启动容器:
$ cd ch24/logging/slog_example
$ docker build -t my-go-slog-app:latest .
$ docker run -d \
--name my_go_app_for_filebeat_vl \
--network host \
-e LOG_LEVEL="debug" \ # 通过环境变量设置日志级别
my-go-slog-app:latest # 使用你构建的Go应用镜像名
现在,Go应用会将JSON日志输出到stdout,Docker会捕获它们,Filebeat会从Docker容器日志文件中读取这些JSON行,并根据配置将它们推送到VictoriaLogs。
最后,我们在之前启动的Grafana中添加VictoriaLogs数据源并查询日志,在connections -> Data sources中,我们需要通过位于页面最下方的 “Find more data source plugins” 来添加 VictoriaLogs数据源类型:
一旦有了VictoriaLogs数据源,我们就可以基于该数据源创建Dashboard了。不过,我们也无需从头开始创建,可以在Grafana官方dashboard搜索一款你中意的VictoriaLogs Dashboard,通过其id直接导入到Grafana中使用即可。这里我们使用的就是id为22759的 VictoriaLogs Explorer。下面就是通过该Dashboard查看的log信息:
你也可以点击某一条log,查看它的字段详情:
VictoriaLogs支持强大的 logsql 查询语言,通过在Dashboard的query中输出logsql语句即可完成各种功能的查询。
通过这个端到端的示例,我们完整地演示了从Go应用(使用slog输出高质量JSON日志)-> Filebeat(收集并转发)-> VictoriaLogs(存储与索引)-> Grafana(查询与可视化)的整个日志链路。 这个流程为你构建一个现代化的、基于Filebeat和VictoriaMetrics生态的日志系统提供了清晰的、可操作的指引。
日志为我们提供了关于离散事件的详细记录和上下文,Metrics则量化了系统的宏观状态和趋势。然而,当我们的Go应用作为复杂分布式系统的一部分,一个用户请求可能需要跨越多个服务边界才能完成时,仅仅依靠这两个支柱往往难以快速定位性能瓶颈或理解端到端的故障。这时,我们就需要可观测性的第三大支柱——分布式追踪(Distributed Tracing),它能为我们描绘出请求在系统中流转的完整“足迹地图”。
小结
在Metrics方面,我们学习了其核心概念(类型、标签、RED方法论),并重点实践了Prometheus作为云原生监控的事实标准,包括如何在Go应用中使用prometheus/client_golang暴露/metrics端点,以及如何通过单机Docker部署的Prometheus进行指标的拉取和初步查询。我们还介绍了新兴的高性能、Prometheus兼容方案VictoriaMetrics,并探讨了其优势以及通过Prometheus remote_write与其集成的参考架构。最后,提及了使用Grafana进行指标可视化与告警。
对于Logging,我们强调了结构化日志(如JSON)输出到标准输出/错误流是云原生最佳实践。我们对比分析了传统的ELK/EFK方案、轻量级的Grafana Loki,以及VictoriaMetrics生态下的高性能日志解决方案VictoriaLogs。我们通过一个端到端示例,展示了如何在Go应用中使用log/slog输出高质量的JSON日志,然后通过Filebeat(配置为与VictoriaLogs的Elasticsearch兼容API交互)进行收集,并最终在Grafana中进行查询。
下节课,我们再深入Tracing领域。欢迎在留言区分享你的思考和方案!我是Tony Bai,我们下节课见。
可观测性:Metrics、Logging、Tracing,让你的Go服务不再是黑盒(下)
你好,我是Tony Bai。
上节课,我们深入了解了Metrics、Logging在Go生态中的主流技术栈和实践。这节课,我们先继续探讨Tracing,再来聊聊这三者是如何整合的,可观测性数据采集中常见的Push与Pull模型,以及展望eBPF技术为Go应用可观测性带来的革命性影响。
Go应用的Tracing:洞察分布式链路与瓶颈
在微服务架构下,一个用户的请求可能需要依次或并行地调用多个Go服务(甚至混合其他语言的服务)才能完成。当这个请求变慢或出错时,如何快速定位是哪个环节、哪个服务出了问题?如何理解整个请求的端到端耗时和内部瓶颈?这就是分布式追踪(Distributed Tracing)要解决的核心问题。它允许我们像侦探一样,追踪一个请求从起点到终点,在复杂的分布式系统中穿梭的完整路径,并记录下每一段路程(即每次服务调用或重要操作)的耗时、元数据和可能发生的错误。
接下来,我们就深入探讨如何为Go应用引入分布式追踪能力。我们将首先理解其核心概念,然后重点学习业界标准OpenTelemetry(OTel)在Go中的应用,包括如何进行代码插桩、上下文传播。最后,我们将通过一个包含两个Go HTTP服务相互调用的实战示例,演示如何将追踪数据发送到OpenTelemetry Collector并最终在Grafana Tempo中进行可视化和分析,让你直观感受分布式追踪的威力。
要有效地利用分布式追踪,我们首先需要掌握它的一些基本术语和核心理念。
分布式追踪的核心概念
理解以下几个核心概念是掌握分布式追踪的基础:
-
Trace(追踪/链路):代表一个请求(或一个完整的业务事务)在分布式系统中的完整生命周期或执行路径。一个Trace由一个或多个Span组成,所有属于同一个Trace的Span共享同一个全局唯一的
TraceID。你可以把它想象成一次旅行的完整行程单。 -
Span(跨度/区间):Trace中的基本工作单元,代表一个命名的、有明确开始和结束时间的操作。例如,一次HTTP请求的接收和处理、一次数据库查询、一个函数的执行、一次消息的发布或消费等,都可以被表示为一个Span。每个Span都有一个在当前Trace内唯一的
SpanID,并且(除了整个Trace的第一个Span,即根Span Root Span之外)通常会有一个ParentSpanID来指向上游调用它的那个Span。通过这种父子关系,所有的Span就串联成了一个树状结构的调用链。我们可以用下图来更直观地理解Trace和Span的关系:
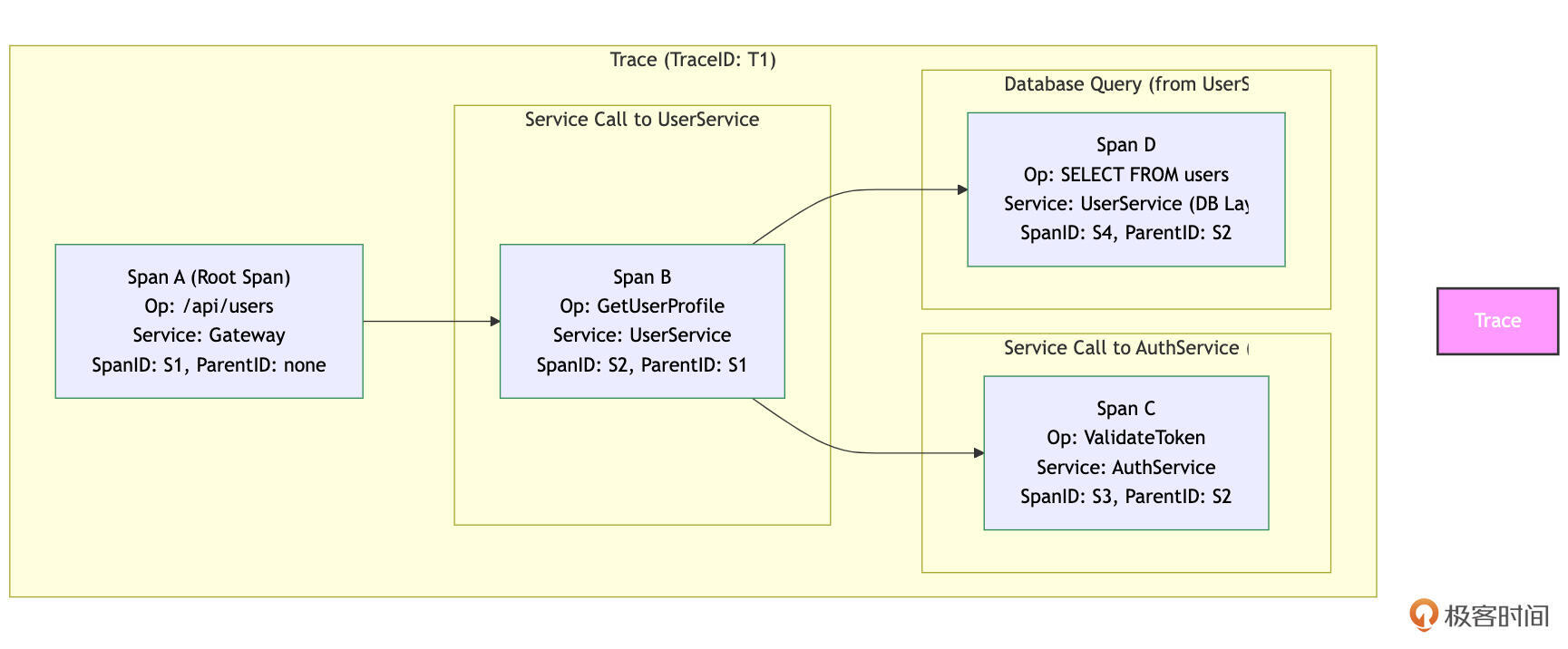
如图所示,整个矩形框代表一个Trace(T1)。Span A是这个Trace的根Span,代表网关服务收到的初始请求。它没有父Span。网关服务调用了用户服务,产生了子Span Span B( ParentID: S1)。用户服务内部又调用了认证服务(产生子Span Span C, ParentID: S2)和数据库(产生子Span Span D, ParentID: S2)。这样,通过 TraceID 和 ParentSpanID,这些Span被组织成了一个清晰的调用树,反映了请求的处理流程。
-
SpanContext(跨度上下文):包含了在一个Trace中全局唯一标识一个Span所需的所有信息,主要包括
TraceID和SpanID。它还可能携带其他需要在进程边界(例如,通过HTTP Header或gRPC Metadata)传播的追踪相关信息,如采样决策(Sampling Decision)和Baggage Items(用户定义的、随调用链传播的键值对,例如customer_tier=premium)。上下文传播是实现分布式追踪的关键机制。 -
Attributes / Tags(属性/标签):附加到Span上的键值对元数据,用于描述Span操作的更多上下文细节。例如,HTTP请求的URL、方法、状态码;数据库查询的SQL语句(可能需要脱敏)、影响行数;或者业务相关的ID(如
order_id)等。这些属性对于后续筛选、聚合和分析Trace数据非常重要。 -
Events / Logs(事件/日志):在一个Span的时间范围内发生的、带有精确时间戳的具名事件或简短日志消息。例如,标记一个缓存命中/未命中、记录一个特定的错误信息(但不是替代结构化日志),或者标记一个复杂操作的某个关键子步骤完成。
-
Instrumentation(代码插桩):为了能够生成上述的Trace和Span数据,需要在应用代码的关键位置(例如,收到外部请求时、发起对其他服务的RPC调用前、访问数据库前后、执行重要业务逻辑的函数入口和出口等)插入额外的代码逻辑来创建Span、设置其属性、记录事件,并在跨服务调用时正确地传播SpanContext。这个过程就叫做“插桩”。插桩可以是手动的,也可以在一定程度上通过库或Agent提供的自动插桩功能来实现。
理解了这些核心概念,我们就能更好地去选择和使用具体的分布式追踪解决方案。在当前的云原生生态中,OpenTelemetry已经成为了这个领域的事实标准。
OpenTelemetry:可观测性的未来与Go实践
在分布式追踪领域,曾经存在多种不同的标准和实现,如OpenTracing和OpenCensus。为了统一和简化,社区最终融合这些标准,诞生了OpenTelemetry(简称为 OTel)。
OpenTelemetry是一个由CNCF(Cloud Native Computing Foundation)托管的开源项目,旨在提供一套统一的、厂商中立的API、SDK(软件开发工具包)和工具,以生成、收集和导出遥测数据。这些数据包括Traces、Metrics和 Logs。尽管Logs的支持仍在发展中,Traces和Metrics是OTel当前最成熟的部分。OTel的目标是成为可观测性数据采集的事实标准,使开发者能够方便地在应用中集成可观测性能力,同时灵活选择和切换后端分析平台,如Jaeger、Zipkin、Tempo、Datadog和New Relic等。
OpenTelemetry Go SDK核心组件
对于Go语言,OpenTelemetry提供了官方的API和Go SDK,主要包括几个核心组件。
首先是 TracerProvider,它是创建 Tracer 的工厂,通常在应用启动时配置为全局的TracerProvider。
其次是 Tracer,用于从代码中创建新的Span,可以通过 tracerProvider.Tracer("instrumentation-library-name") 获取。
每个Span代表一个操作单元,通过 tracer.Start(ctx, "span-name", opts...) 创建。
此外, SpanProcessor 定义了Span在完成时如何被处理,例如同步导出或批量异步导出。最后, Exporter 负责将处理过的Span数据发送到具体的追踪后端,OTel提供了多种Exporter实现,包括OTLP Exporter、Jaeger Exporter和Zipkin Exporter等。其中,OTLP(OpenTelemetry Protocol)是OTel定义的一种通用遥测数据传输协议,推荐使用该格式进行数据导出。
Tracer、Span和Exporter的协作工作流程可以用下面这个流程示意图表示:
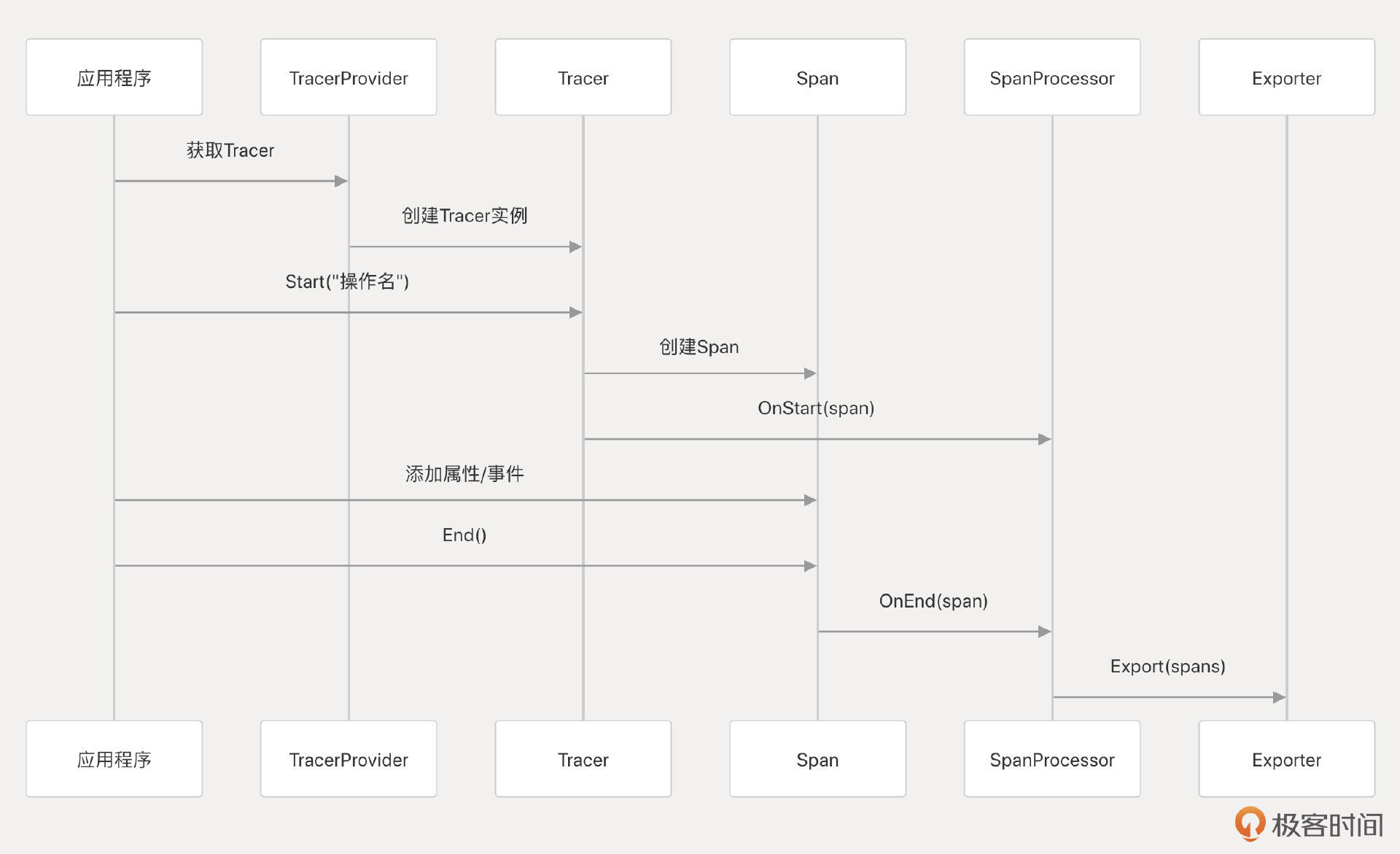
那么Go代码如何集成OTel Tracing呢?我们继续往下看。
在Go代码中集成OTel Tracing的两种方式
在Go代码中集成OTel Tracing的主要方式有两种,一种是手动插桩,另外一种是自动插桩。
手动插桩是指在应用程序的源代码中直接添加OpenTelemetry API和SDK的代码,以明确地创建和管理Trace、Span等追踪元素。这种方式提供了对追踪数据收集的精细控制,允许开发者捕获特定于业务逻辑的自定义指标和事件。
自动插桩是指利用预构建的库、agent或工具,在不修改应用程序源代码的情况下自动捕获和发送遥测数据。对于Go语言,由于其编译型特性,传统的自动插桩(如Java的字节码注入)较为困难。OTel提供了两种自动插桩的方案, 一种是 基于eBPF自动插桩,用户无需通过SDK手动修改业务代码。eBPF可以自动检测Go应用,收集HTTP、数据库和RPC调用相关的数据,同时自动传递用户上下文,确保整个trace的完整性。另外一种则是 通过类似 InstrGen 的工具在编译时实现自动插桩。InstrGen可以在编译期间解析整个项目的语法树,并在指定方法中插入代码以启用应用程序监控。这个编译时插桩方案可以避免eBPF自动插桩方案的诸多限制,如内核版本约束、性能开销大、eBPF指令长度限制等。
虽说手动插桩是“侵入式”的,需要修改现有代码,但对于规模较小的项目来说确实很方便,也提供了最大的灵活性和定制能力。并且,手动插桩对于开发者来说,也是理解代码Tracing机制的最好方式,因此这一节课中的示例也将选择手动插桩的方式。
在Go代码中集成OTel Tracing的示例
为了更具体地理解如何在Go应用中实践分布式追踪,我们将通过一个包含两个简单HTTP服务( service-a 和 service-b)相互调用的示例来演示。 service-a 会接收外部请求,然后调用 service-b,最终将结果返回。我们将使用OpenTelemetry Go SDK对这两个服务进行手工插桩,并通过OTLP gRPC Exporter将追踪数据发送到一个本地运行的OpenTelemetry Collector,Collector再将数据转发给Grafana Tempo进行存储和可视化。下面是这个示例的拓扑与数据流示例图:

如上图所示:
-
用户通过
curl或浏览器向Service A的:8080端口发起请求。 -
Service A处理请求,其中一部分逻辑会调用Service B的:8081端口。 -
Service A和Service B都集成了OpenTelemetry Go SDK。它们产生的Trace Span数据会通过OTLP gRPC协议发送到OTel Collector的:4317端口。 -
OTel Collector进行简单的处理(如批量化)后,再将Trace数据通过OTLP gRPC协议转发给Grafana Tempo进行存储。 -
开发者或运维人员可以通过
Grafana(配置了Tempo数据源)的UI来查询和可视化存储在Tempo中的Trace数据。
下面,我们就来一步步使用单机版Docker实现示意图中的流程。
我们首先启动流程图中tracing backend,这里以 Grafana的Tempo 为例:
// 在ch24/tracing/otel_tempo_example下执行(确保tempo_data目录存在)
docker run -d \
--name tempo-server \
--user root \
--network host \
-p 3200:3200 \
-p 4317:4317 \
-v $(pwd)/tempo_data:/tmp/tempo \
grafana/tempo:latest \
-storage.trace.backend=local \
-storage.trace.local.path=/tmp/tempo/traces
其中3200端口是供Grafana查询数据的http端口,4317端口则是 OpenTelemetry Collector(下面简称为OTel Collector)向Tempo发送Trace数据的服务端口。
注意:生产环境Tempo通常使用对象存储作为后端存储,这里使用的本地路径(temp_data)存储数据仅限于demo。
接下来,我们再来启动OTel Collector。OTel Collector负责接收来自Go应用的跟踪信息、指标以及日志等遥测数据、处理遥测数据,并使用其组件将其导出到各种可观测性后端(这里是Tempo),这里我们仅使用OTel Collector接收跟踪数据。
下面是OTel Collector使用的配置文件ch24/tracing/otel_tempo_example/otel-collector-config.yaml,这个配置文件告诉Collector如何接收、处理和导出数据:
# ch24/tracing/otel_tempo_example/otel-collector-config.yaml
receivers:
otlp: # 接收OTLP协议的数据
protocols:
grpc:
endpoint: 0.0.0.0:14317 # OTLP gRPC receiver on port 14317
http:
endpoint: 0.0.0.0:14318 # OTLP HTTP receiver on port 14318
processors:
batch: # 批量处理数据以提高效率,减少对后端的请求次数
exporters:
otlp: # 将数据通过OTLP gRPC发送给Tempo
endpoint: "localhost:4317" # Tempo容器的服务名和OTLP gRPC端口
tls:
insecure: true # 仅用于本地演示,生产环境应使用TLS
service:
pipelines:
traces: # 定义traces数据的处理管道
receivers: [otlp]
processors: [batch]
exporters: [otlp] # 指向上面定义的otlp exporter (即发送给Tempo)
使用下面docker命令可以在本地启动一个基于上述配置文件的OTel Collector:
$docker run -d --name otel-collector-server \
-p 14317:14317 `# OTLP gRPC (for services to send to Collector)` \
-p 14318:14318 `# OTLP HTTP (optional)` \
-v $(pwd)/otel-collector-config.yaml:/etc/otel-collector-config.yaml \
--network host \
otel/opentelemetry-collector-contrib:latest \
--config=/etc/otel-collector-config.yaml
有了Tempo和OTel Collector后,就差向它们发送Trace数据的应用了。我们逐个看一下拓扑示意图中的Service A和Service B的代码。
我们将创建一个通用的包和相关函数来初始化TracerProvider,供 service-a 和 service-b 共同使用:
// ch24/tracing/otel_tempo_example/tracing/tracer.go
package tracing
import (
"context"
"fmt"
"log"
"time"
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc"
"go.opentelemetry.io/otel/propagation"
"go.opentelemetry.io/otel/sdk/resource"
sdktrace "go.opentelemetry.io/otel/sdk/trace"
semconv "go.opentelemetry.io/otel/semconv/v1.26.0"
"google.golang.org/grpc"
"google.golang.org/grpc/credentials/insecure"
)
// InitTracerProvider initializes and registers an OTLP gRPC TracerProvider.
// It returns a shutdown function that should be called by the application on exit.
func InitTracerProvider(ctx context.Context, serviceName, serviceVersion, otlpEndpoint string) (func(context.Context) error, error) {
log.Printf("Initializing TracerProvider for service '%s' (v%s), OTLP endpoint: '%s'\n", serviceName, serviceVersion, otlpEndpoint)
res, err := resource.Merge(
resource.Default(),
resource.NewWithAttributes(
semconv.SchemaURL,
semconv.ServiceName(serviceName),
semconv.ServiceVersion(serviceVersion),
// attribute.String("environment", "demo"), // 可选的其他全局属性
),
)
if err != nil {
return nil, fmt.Errorf("failed to create OTel resource: %w", err)
}
// 创建到OTLP Collector的gRPC连接
// 在生产中,应该使用安全的凭证 (e.g., grpc.WithTransportCredentials(credentials.NewClientTLSFromCert(nil, "")))
// 并处理连接错误和重试
connCtx, cancelConn := context.WithTimeout(ctx, 5*time.Second) // 连接超时
defer cancelConn()
conn, err := grpc.DialContext(connCtx, otlpEndpoint,
grpc.WithTransportCredentials(insecure.NewCredentials()), // 仅用于演示
grpc.WithBlock(), // 阻塞直到连接成功或超时
)
if err != nil {
return nil, fmt.Errorf("failed to create gRPC connection to OTLP collector at '%s': %w", otlpEndpoint, err)
}
log.Printf("Successfully connected to OTLP collector at %s\n", otlpEndpoint)
// 创建OTLP Trace Exporter
traceExporter, err := otlptracegrpc.New(ctx, otlptracegrpc.WithGRPCConn(conn))
if err != nil {
// 尝试关闭连接,如果创建exporter失败
if cerr := conn.Close(); cerr != nil {
log.Printf("Warning: failed to close gRPC connection after exporter creation failed: %v", cerr)
}
return nil, fmt.Errorf("failed to create OTLP trace exporter: %w", err)
}
log.Println("OTLP trace exporter initialized.")
// 创建BatchSpanProcessor,这是生产推荐的
bsp := sdktrace.NewBatchSpanProcessor(traceExporter)
// 创建TracerProvider
tp := sdktrace.NewTracerProvider(
sdktrace.WithSampler(sdktrace.AlwaysSample()), // 为了演示,采样所有trace
sdktrace.WithResource(res),
sdktrace.WithSpanProcessor(bsp),
)
// 设置为全局TracerProvider和Propagator
otel.SetTracerProvider(tp)
otel.SetTextMapPropagator(propagation.NewCompositeTextMapPropagator(
propagation.TraceContext{}, // W3C Trace Context (标准)
propagation.Baggage{}, // W3C Baggage
))
log.Printf("Global TracerProvider and Propagator set for service '%s'.\n", serviceName)
// 返回一个关闭函数,它会关闭TracerProvider和gRPC连接
shutdownFunc := func(shutdownCtx context.Context) error {
log.Printf("Attempting to shutdown TracerProvider for service '%s'...\n", serviceName)
var errs []error
if err := tp.Shutdown(shutdownCtx); err != nil {
errs = append(errs, fmt.Errorf("TracerProvider shutdown error: %w", err))
log.Printf("Error shutting down TracerProvider for %s: %v\n", serviceName, err)
} else {
log.Printf("TracerProvider for %s shut down successfully.\n", serviceName)
}
if err := conn.Close(); err != nil {
errs = append(errs, fmt.Errorf("gRPC connection close error: %w", err))
log.Printf("Error closing gRPC connection for %s: %v\n", serviceName, err)
} else {
log.Printf("gRPC connection for %s closed successfully.\n", serviceName)
}
if len(errs) > 0 {
// 可以将多个错误合并返回,这里简单返回第一个
return fmt.Errorf("shutdown for service %s encountered errors: %v", serviceName, errs)
}
return nil
}
return shutdownFunc, nil
}
接下来,我们先来创建示意图中的service-a,该服务暴露/call-b端点,凡是请求该端点的请求,service-a会通过HTTP客户端调用service-b:
// ch24/tracing/otel_tempo_example/service-a/main.go
package main
import (
"context"
"demo/tracing" // 导入通用的tracing初始化包
"fmt"
"io"
"log"
"net/http"
"os"
"os/signal"
"syscall"
"time"
"go.opentelemetry.io/contrib/instrumentation/net/http/otelhttp" // HTTP client/server auto-instrumentation
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/attribute"
"go.opentelemetry.io/otel/codes"
oteltrace "go.opentelemetry.io/otel/trace" // 不直接用trace.Tracer,而是通过otel.Tracer获取
)
func main() {
ctx, stop := signal.NotifyContext(context.Background(), syscall.SIGINT, syscall.SIGTERM)
defer stop()
serviceName := "service-a"
serviceVersion := "1.0.0"
otlpEndpoint := os.Getenv("OTEL_EXPORTER_OTLP_ENDPOINT")
if otlpEndpoint == "" {
otlpEndpoint = "localhost:14317" // OTel Collector服务地址
log.Printf("[%s] OTEL_EXPORTER_OTLP_ENDPOINT not set, using default: %s\n", serviceName, otlpEndpoint)
}
// 初始化TracerProvider
shutdownTracer, err := tracing.InitTracerProvider(ctx, serviceName, serviceVersion, otlpEndpoint)
if err != nil {
log.Fatalf("[%s] Failed to initialize TracerProvider: %v. Is OTel Collector running at %s?", serviceName, err, otlpEndpoint)
}
defer func() { // 确保在应用退出时关闭TracerProvider
shutdownCtx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
if err := shutdownTracer(shutdownCtx); err != nil {
log.Printf("[%s] Error during TracerProvider shutdown: %v", serviceName, err)
}
}()
// 获取一个Tracer实例
tracer := otel.Tracer(serviceName + "-tracer") // Tracer命名
// 创建一个带有OTel自动插桩的HTTP客户端
// otelhttp.NewTransport 会自动为出站请求创建Span并注入Trace Context
otelClient := http.Client{
Transport: otelhttp.NewTransport(http.DefaultTransport),
}
// 定义HTTP Handler
callBHandler := func(w http.ResponseWriter, r *http.Request) {
// 从请求的context中启动一个新的Span,它会成为otelhttp.NewHandler创建的父Span的子Span
// 或者如果这个handler是顶层入口,它会成为新的根Span(如果otelhttp.NewHandler没用)
// 在本例中,我们将使用otelhttp.NewHandler包装整个Mux,所以这里tracer.Start会创建子Span
requestCtx, parentSpan := tracer.Start(r.Context(), "service-a.handler.callServiceB")
defer parentSpan.End()
parentSpan.SetAttributes(attribute.String("http.target", r.URL.Path))
log.Printf("[%s] Received request for %s\n", serviceName, r.URL.Path)
// 获取service-b的URL (应来自配置或服务发现)
serviceB_URL := os.Getenv("SERVICE_B_URL")
if serviceB_URL == "" {
serviceB_URL = "http://localhost:8081/data" // service-b服务地址
log.Printf("[%s] SERVICE_B_URL not set, using default: %s\n", serviceName, serviceB_URL)
}
// 创建到service-b的请求,并使用带有当前Span的context
// otelClient.Transport (otelhttp.NewTransport) 会自动从requestCtx中提取Trace Context并注入到出站请求头
outboundReq, err := http.NewRequestWithContext(requestCtx, "GET", serviceB_URL, nil)
if err != nil {
parentSpan.RecordError(err)
parentSpan.SetStatus(codes.Error, "failed to create request to service-b")
http.Error(w, "Internal server error", http.StatusInternalServerError)
return
}
log.Printf("[%s] Calling Service B at %s...\n", serviceName, serviceB_URL)
resp, err := otelClient.Do(outboundReq) // 使用带OTel插桩的HTTP客户端发送请求
if err != nil {
parentSpan.RecordError(err)
parentSpan.SetStatus(codes.Error, "failed to call service-b")
http.Error(w, fmt.Sprintf("Failed to call service-b: %v", err), http.StatusServiceUnavailable)
return
}
defer resp.Body.Close()
bodyBytes, err := io.ReadAll(resp.Body)
if err != nil {
parentSpan.RecordError(err)
parentSpan.SetStatus(codes.Error, "failed to read response from service-b")
http.Error(w, "Internal server error reading response", http.StatusInternalServerError)
return
}
responseMessage := fmt.Sprintf("Service A got response from Service B: [%s]", string(bodyBytes))
parentSpan.AddEvent("Received response from Service B", oteltrace.WithAttributes(attribute.Int("response.size", len(bodyBytes))))
parentSpan.SetStatus(codes.Ok, "Successfully called service-b")
w.WriteHeader(resp.StatusCode)
fmt.Fprint(w, responseMessage)
log.Printf("[%s] Successfully handled /call-b request.\n", serviceName)
}
// 使用otelhttp.NewHandler包装我们的业务handler,使其自动处理入站请求的Trace上下文和根Span创建
// "service-a-http-server" 将作为这个HTTP服务器instrumentation的名称,影响根Span的命名
tracedCallBHandler := otelhttp.NewHandler(http.HandlerFunc(callBHandler), "service-a.http.inbound")
mux := http.NewServeMux()
mux.Handle("/call-b", tracedCallBHandler)
server := &http.Server{
Addr: ":8080",
Handler: mux, // 使用已包装的handler
}
go func() {
log.Printf("[%s] HTTP server listening on :8080\n", serviceName)
if err := server.ListenAndServe(); err != nil && err != http.ErrServerClosed {
log.Fatalf("[%s] Service A failed to start: %v", serviceName, err)
}
}()
<-ctx.Done() // 等待退出信号
log.Printf("[%s] Shutdown signal received, stopping server...\n", serviceName)
shutdownServerCtx, cancelShutdownServer := context.WithTimeout(context.Background(), 5*time.Second)
defer cancelShutdownServer()
if err := server.Shutdown(shutdownServerCtx); err != nil {
log.Printf("[%s] Error during server shutdown: %v", serviceName, err)
}
log.Printf("[%s] Server stopped.\n", serviceName)
}
service-b的代码与service-a类似:
// ch24/tracing/otel_tempo_example/service-b/main.go
... ...
func simulateWork(ctx context.Context, duration time.Duration, operationName string) {
// 获取当前context中的tracer,创建一个子span
tracer := otel.Tracer("service-b-worker-tracer") // 可以用更具体的tracer name
_, span := tracer.Start(ctx, operationName)
defer span.End()
span.SetAttributes(attribute.Int64("work.duration.ns", duration.Nanoseconds()))
log.Printf("[Service B] Worker: Starting %s (will take %v)\n", operationName, duration)
time.Sleep(duration)
log.Printf("[Service B] Worker: Finished %s\n", operationName)
span.AddEvent("Work simulation completed")
}
func dataHandler(w http.ResponseWriter, r *http.Request) {
// otelhttp.NewHandler 已经为这个请求创建了一个服务器端Span,并将其放入r.Context()
// 我们可以从r.Context()中获取当前的Span,或者直接用它来创建子Span
ctx := r.Context()
tracer := otel.Tracer("service-b-handler-tracer") // 获取tracer
// 手动创建一个子span来表示这个handler内部的特定业务逻辑
var handlerSpan oteltrace.Span // Using oteltrace alias from global import
ctx, handlerSpan = tracer.Start(ctx, "service-b.handler.processData")
defer handlerSpan.End()
handlerSpan.SetAttributes(attribute.String("handler.message", "Service B processing /data request"))
log.Printf("[Service B] Received request at /data. TraceID: %s\n", oteltrace.SpanFromContext(ctx).SpanContext().TraceID())
// 模拟一些工作
simulateWork(ctx, 50*time.Millisecond, "databaseQuery")
simulateWork(ctx, 30*time.Millisecond, "externalAPICall")
fmt.Fprintln(w, "Data from Service B (processed)")
handlerSpan.AddEvent("Successfully returned data from Service B")
handlerSpan.SetStatus(codes.Ok, "Data processed and returned")
}
func main() {
ctx, stop := signal.NotifyContext(context.Background(), syscall.SIGINT, syscall.SIGTERM)
defer stop()
serviceName := "service-b"
serviceVersion := "1.0.0"
otlpEndpoint := os.Getenv("OTEL_EXPORTER_OTLP_ENDPOINT")
if otlpEndpoint == "" {
otlpEndpoint = "localhost:14317" // Otel Collector服务名
log.Printf("[%s] OTEL_EXPORTER_OTLP_ENDPOINT not set, using default: %s\n", serviceName, otlpEndpoint)
}
shutdownTracer, err := tracing.InitTracerProvider(ctx, serviceName, serviceVersion, otlpEndpoint)
if err != nil {
log.Fatalf("[%s] Failed to initialize TracerProvider: %v", serviceName, err)
}
defer func() {
shutdownCtx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
if err := shutdownTracer(shutdownCtx); err != nil {
log.Printf("[%s] Error during TracerProvider shutdown: %v", serviceName, err)
}
}()
// 使用otelhttp.NewHandler来自动为HTTP请求创建span并处理上下文传播
// "service-b.http.inbound" 将作为这个HTTP服务器instrumentation的名称
handlerWithTracing := otelhttp.NewHandler(http.HandlerFunc(dataHandler), "service-b.http.inbound")
mux := http.NewServeMux()
mux.Handle("/data", handlerWithTracing) // 注册带追踪的handler
server := &http.Server{
Addr: ":8081",
Handler: mux,
}
go func() {
log.Printf("[%s] HTTP server listening on :8081\n", serviceName)
if err := server.ListenAndServe(); err != nil && err != http.ErrServerClosed {
log.Fatalf("[%s] Service B failed to start: %v", serviceName, err)
}
}()
<-ctx.Done()
log.Printf("[%s] Shutdown signal received, stopping server...\n", serviceName)
shutdownServerCtx, cancelShutdownServer := context.WithTimeout(context.Background(), 5*time.Second)
defer cancelShutdownServer()
if err := server.Shutdown(shutdownServerCtx); err != nil {
log.Printf("[%s] Error during server shutdown: %v", serviceName, err)
}
log.Printf("[%s] Server stopped.\n", serviceName)
}
上面两段代码演示了如何使用OpenTelemetry(OTel)对两个 service-a 和 service-b 两个服务代码进行手动插桩,以实现分布式追踪。我们大致解释一下代码的核心要点:
-
OTel 初始化: 两个服务都依赖一个共享的
tracing包(demo/tracing)来初始化TracerProvider。初始化时会配置服务名称(serviceName)、服务版本(serviceVersion)和 OTLP导出器端点(OTEL_EXPORTER_OTLP_ENDPOINT,默认为localhost:14317),用于将追踪数据发送到我们已经启动的Otel Collector。程序优雅退出时会调用shutdownTracer来确保追踪数据被完整发送。 -
Service A(调用方):
-
HTTP 服务器端插桩:使用
otelhttp.NewHandler包装其HTTP处理器(callBHandler)。这会自动为进入/call-b的请求创建一个服务器端 Span,并将追踪上下文(Trace Context)放入请求的context.Context中。 -
手动创建子 Span:在
callBHandler内部,通过tracer.Start()手动创建一个子 Span(service-a.handler.callServiceB),用于包裹调用 Service B 的业务逻辑。 -
HTTP 客户端插桩:创建一个
http.Client,其Transport被otelhttp.NewTransport包装。当 Service A 调用 Service B 时,这个 Transport 会自动从当前context.Context中提取追踪信息,并创建一个客户端 Span(作为service-a.handler.callServiceB的子 Span),然后将追踪上下文(如 Trace ID、Span ID)注入到发往 Service B 的 HTTP 请求头中(实现上下文传播)。 -
Span 操作:在 Span 上设置属性(
SetAttributes)、添加事件(AddEvent)、记录错误(RecordError)和设置状态(SetStatus)。
-
-
Service B(被调用方):
-
HTTP 服务器端插桩:同样使用
otelhttp.NewHandler包装其HTTP处理器(dataHandler)。当收到来自 Service A 的请求时,它会自动从请求头中提取追踪上下文,并创建一个新的服务器端 Span,该 Span 会成为 Service A 中客户端 Span 的子 Span,从而将两个服务的追踪串联起来。 -
手动创建子 Span:在
dataHandler内部,手动创建子 Span(service-b.handler.processData)来包裹其核心处理逻辑。 -
模拟工作单元的 Span:
simulateWork函数进一步创建更细粒度的子 Span(如databaseQuery、externalAPICall),展示如何追踪内部操作。 -
Span 操作:同样在 Span 上进行属性、事件和状态的设置。
-
-
上下文传播(Context Propagation):
-
核心机制是通过
context.Context在函数调用链中传递追踪信息。 -
跨服务边界时,
otelhttp库负责在 HTTP 请求头中序列化和反序列化追踪上下文(通常使用 W3C Trace Context 标准)。
-
这两段代码通过结合 OTel 提供的 HTTP 自动插桩库和手动创建 Span 的方式,为两个微服务构建了一个完整的分布式追踪链路。通过这些插桩,当一个请求从 Service A 发起,流经 Service B,再到 Service B 内部的模拟工作单元时,整个调用链上的所有操作都会被记录为一系列关联的 Span。这些 Span 数据发送到 OTel Collector 并最终存储在追踪后端后,可以可视化整个分布式请求的路径、延迟和依赖关系,便于问题排查和性能分析。
下面,我们来构建并运行service-a和service-b:
// 在ch24/tracing/otel_tempo_example下
$go build -o svc-a service-a/main.go
$go build -o svc-b service-a/main.go
// 在新窗口启动service-a
$./svc-a
2025/06/11 06:56:56 [service-a] OTEL_EXPORTER_OTLP_ENDPOINT not set, using default: localhost:14317
2025/06/11 06:56:56 Initializing TracerProvider for service 'service-a' (v1.0.0), OTLP endpoint: 'localhost:14317'
2025/06/11 06:56:56 Successfully connected to OTLP collector at localhost:14317
2025/06/11 06:56:56 OTLP trace exporter initialized.
2025/06/11 06:56:56 Global TracerProvider and Propagator set for service 'service-a'.
2025/06/11 06:56:56 [service-a] HTTP server listening on :8080
// 在新窗口启动service-b
$./svc-b
2025/06/11 06:57:45 [service-b] OTEL_EXPORTER_OTLP_ENDPOINT not set, using default: localhost:14317
2025/06/11 06:57:45 Initializing TracerProvider for service 'service-b' (v1.0.0), OTLP endpoint: 'localhost:14317'
2025/06/11 06:57:45 Successfully connected to OTLP collector at localhost:14317
2025/06/11 06:57:45 OTLP trace exporter initialized.
2025/06/11 06:57:45 Global TracerProvider and Propagator set for service 'service-b'.
2025/06/11 06:57:45 [service-b] HTTP server listening on :8081
然后通过curl访问service-a的/call-b端点,以产生流量和trace数据:
// 在新窗口多次访问service-a的call-b端点
$ curl localhost:8080/call-b
Service A got response from Service B: [Data from Service B (processed)
$ curl localhost:8080/call-b
Service A got response from Service B: [Data from Service B (processed)
... ...
接下来就是通过Grafana查看Trace数据了。在Grafana中,你可以添加Tempo类型数据源,具体操作和前面添加prometheus、victorialogs数据源大同小异,这里不赘述了。有了Tempo数据源后,我们就可以通过Explore > tempo查看来自tempo数据源的数据了(如下图所示):
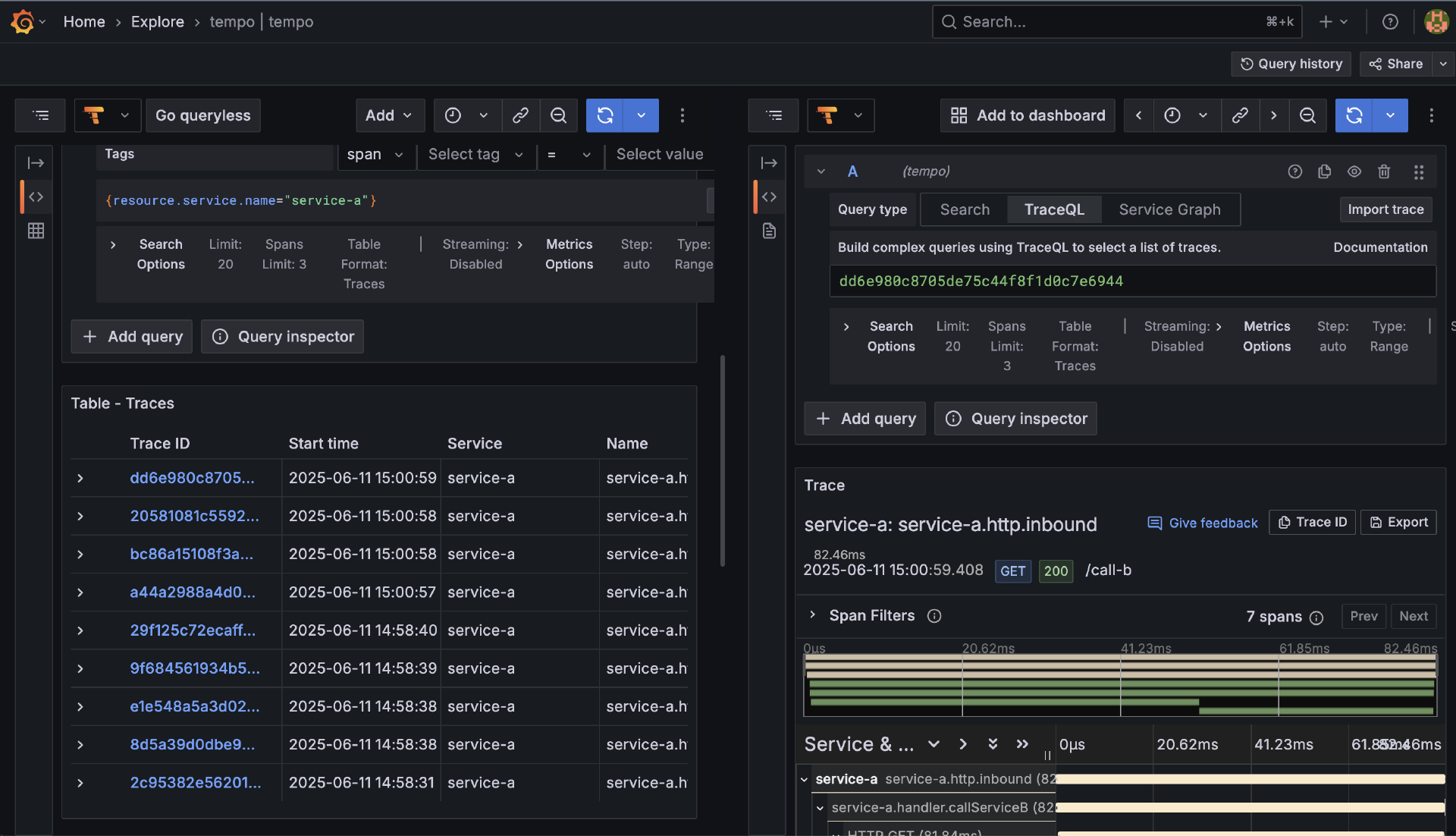
你应该能看到名为 service-a 和 service-b 的服务,并且可以搜索到包含多个Span(一个来自service-a的 service-a.handleCallB,一个由 otelhttp.NewTransport 自动创建的HTTP客户端Span,一个由service-b的 otelhttp.NewHandler 自动创建的HTTP服务端Span service-b-http-server,以及service-b内部手动创建的 service-b.dataHandler.Process 和 service-b.internalProcessing)的完整Trace。点击Trace可以看到详细的调用链、每个Span的耗时、属性和事件。
通过这个更完整的示例,我们演示了如何使用OpenTelemetry Go SDK为多个相互调用的Go服务进行插桩,并通过OTel Collector将追踪数据发送到Grafana Tempo进行可视化。这清晰地展现了分布式追踪在理解微服务交互和定位跨服务瓶颈方面的强大能力。
至此,我们的Go应用产生的标准化Trace数据,已经通过OpenTelemetry Collector的桥梁,顺利抵达了Grafana Tempo后端。Tempo凭借其针对TraceID优化的存储和与Grafana的无缝集成,为我们提供了一种高效的追踪数据解决方案。
然而,正如技术世界常态,解决方案往往不止一种。在Tempo之外,业界还有哪些久经考验或独具特色的主流Tracing后端?例如,经典的Jaeger和Zipkin是如何应对大规模追踪数据的?而像VictoriaMetrics这样的新兴力量,在尝试将Trace数据融入其统一可观测性版图时,又展现了哪些不同的设计思路和性能表现?深入了解这些不同的“玩家”如何进行Trace数据的存储、查询、分析和可视化,对我们构建真正适合自身业务场景的追踪体系至关重要。
主流Tracing后端与可视化
一旦Go应用通过OTel SDK生成并导出了Trace数据(通常通过OTLP协议发送给OpenTelemetry Collector),我们就需要一个强大的追踪后端(Tracing Backend)来接收、持久化存储这些海量的Trace数据,并提供高效的查询接口和丰富的可视化能力。
在开源领域,有几个广为人知且经过生产环境检验的追踪后端,我们一一来看。
Jaeger( https://www.jaegertracing.io/)由Uber开源,是CNCF的毕业项目,功能非常全面,生态也相对成熟。Jaeger通常包含 jaeger-agent(可选,用于在应用节点收集和转发数据)、 jaeger-collector(接收数据并写入存储)、存储后端(支持Cassandra、Elasticsearch、Kafka、BadgerDB等多种,甚至可以直接将数据写入ClickHouse – ClickHouse因其LSM-Tree和列式存储特性,被证明非常适合存储Trace Span数据)以及 jaeger-query(提供查询API和Web UI)。
Jaeger提供丰富的查询功能(按服务、操作、标签、耗时、错误等搜索Trace),直观的Trace火焰图和甘特图可视化服务依赖拓扑图以及Trace数据对比等。Jaeger可以直接接收OTLP数据(较新版本),或者通过OTel Collector将其配置为Jaeger的Exporter。Grafana也内置了对Jaeger数据源的支持。
另一个历史悠久且流行的开源追踪系统 Zipkin( https://zipkin.io/),源于Twitter。与Jaeger类似,Zipkin也有Collector、Storage(支持多种后端如Cassandra、Elasticsearch、MySQL)、Query Service和Web UI。其数据模型(特别是B3传播头)对后续的追踪标准(如W3C Trace Context)有一定影响。最后,Zipkin同样可以接收OTLP数据(通过OTel Collector转换或直接支持)。
然而,随着监控数据量的持续爆炸式增长,社区对存储成本效益、查询性能以及与现有监控生态(特别是Metrics和Logs)的无缝集成提出了更高的要求。正是在这种背景下,一些新的、设计理念更现代的追踪后端应运而生,其中Grafana Tempo是一个突出的代表。
Grafana Tempo( https://grafana.com/oss/tempo/)为海量Trace设计,与Grafana生态深度融合。Grafana Tempo是Grafana Labs推出的一个高可扩展、高性价比的分布式追踪后端。它的设计哲学与Grafana Loki(用于日志)有诸多相似之处,都强调通过简化的索引策略和与对象存储的集成来降低大规模遥测数据存储的成本。
-
核心设计理念:
-
专注于通过TraceID进行高效查找,对TraceID本身建立索引。 它不试图对Span的每一个属性(tag)都建立复杂的二级索引(这正是传统追踪系统如Elasticsearch后端可能导致存储和查询成本高昂的原因之一)。
-
与对象存储深度集成。 Tempo将原始的Trace Span数据主要存储在廉价的对象存储服务中(如Amazon S3、Google Cloud Storage、Azure Blob Storage、MinIO等)。
-
依赖于从Metrics或Logs中“发现”TraceID。 Tempo的设计鼓励一种“先从Metrics或Logs中发现问题,再用TraceID深入追踪”的工作流。例如,当你从Grafana的Metrics仪表盘上看到一个服务的P99延迟飙升,或者从Loki的日志中找到一条错误日志,你应该能够从这些Metrics或Logs的元数据中提取出相关的TraceID,然后再到Tempo中用这个TraceID精确查找完整的调用链进行深度分析。
-
-
架构组件:Tempo通常包含Distributor(接收数据)、Ingester(构建内存中的Trace并写入后端)、Compactor(合并和压缩数据块)、Querier/Query Frontend(处理查询)等组件。它可以单节点运行,也可以集群部署。
-
与Grafana、Loki、Prometheus/VictoriaMetrics的无缝集成:这被认为是Tempo的核心优势和最大卖点。在Grafana的统一界面中,你可以:
-
观察来自Prometheus或VictoriaMetrics的Metrics图表,发现异常。
-
从Metrics图表(例如,通过Exemplars或者时间范围和标签)一键跳转到相关的Logs(存储在Loki或VictoriaLogs中)。
-
从Logs中提取出关键的TraceID。
-
用这个TraceID直接在Grafana中查询Tempo数据源,查看该请求的完整Trace视图。 这种Metrics-Logs-Traces之间的无缝跳转和上下文关联,极大地提升了故障排查和性能分析的效率和体验。
-
Tempo以其低存储成本、高可扩展性、以及与Grafana可观测性生态的深度融合,正迅速成为云原生环境下分布式追踪后端的一个非常受欢迎的选择,尤其适合那些已经在使用Grafana、Prometheus和Loki的团队。
最后,VictoriaMetrics团队也一直在积极探索和研究分布式追踪的存储与查询问题。Trace Span数据与结构化日志在本质上非常相似:都是由键值对(字段/属性)构成,都有高写入速率的需求,且通常只有一小部分数据会被频繁查询。因此,该团队基于VictoriaLogs之上实现了一个高效的Trace存储和检索原型:VictoriaTraces。在特定条件下,该原型在CPU使用率、内存消耗和数据大小方面,相比基于ClickHouse或Tempo(本地磁盘模式)的Jaeger具有较大的性能优势。这意味着,对于那些已经在使用或考虑使用VictoriaMetrics和VictoriaLogs的Go开发者来说,未来很可能可以直接将Trace数据也存入VictoriaLogs(或其演进版本),从而在VictoriaMetrics生态内实现Metrics、Logs、Traces的统一存储和查询,这无疑是非常有吸引力的前景。
选择哪种追踪后端,取决于团队的技术栈、已有的监控基础设施、对存储成本和查询性能的特定需求、以及与Metrics/Logs系统的集成偏好。但无论选择哪种后端,Go应用侧坚持使用OpenTelemetry SDK进行插桩并导出OTLP格式的数据,是确保未来灵活性和可移植性的最佳实践。
通过Metrics量化状态,通过Logging记录事件,通过Tracing洞察链路,我们就能为Go应用构建起一个强大的可观测性体系。但这三者如果各自为政,其威力会大打折扣。要真正释放可观测性的力量,实现对复杂系统行为的深度理解和快速的问题定位,就必须将这些不同来源的遥测数据有效地整合与关联起来。
整合、模型与未来:构建统一可观测性视图
理解了如何分别构建Metrics、Logging和Tracing系统之后,我们首先要解决的问题是,如何让这“三驾马车”协同作战,而不是各行其是。
Metrics、Logging、Tracing的整合与关联
为何需要整合? 想象一下这样的典型线上排障场景:
-
你收到一个告警,提示某个服务的P99延迟(来自Metrics系统)突然飙升。
-
你自然希望查看该时间段内这个服务的错误日志(来自Logging系统),看看是否有相关的异常信息或错误堆栈。
-
如果日志指向了某个特定的请求或用户,你可能还想找到这个(或类似)慢请求的完整分布式调用链(来自Tracing系统),以分析具体的性能瓶颈在哪里。
如果这三者是孤立的,你可能需要在不同的监控系统、不同的查询界面之间手动切换、复制ID、调整时间范围进行搜索,这个过程不仅效率低下,而且容易遗漏关键信息。而如果它们能够被有效地整合关联起来,你就可以从一个Metrics告警或图表,平滑地钻取(drill down)到相关的日志条目,再从日志中提取出TraceID,一键跳转到该Trace的详细视图,整个排障流程将变得行云流水。
那么,实现这种数据间关联的关键是什么呢? 答案主要在于一致的元数据/标签和有效的上下文传播。
首先,一致的元数据和标签是实现数据关联的“粘合剂”。我们必须确保在Metrics的标签、结构化日志的字段以及Trace Span的属性中,使用相同含义、相同命名(或可映射)的键来记录那些能够将不同遥测数据串联起来的关键上下文信息。例如, service_name、 instance_id(或 pod_name、 host)、 environment(如 prod、 staging)、 version(应用版本)等,这些都应该是所有遥测数据共有的。
而对于实现Logs和Traces之间的精确关联, trace_id 和 span_id 是最核心的关联ID,必须努力将它们包含在每一条与特定追踪活动相关的日志中。此外,诸如 user_id、 request_id、 session_id 和 order_id 等与具体业务或请求相关的ID,如果也能在Metrics、Logs和Traces中一致地出现(作为标签或属性),将极大地增强我们按业务维度进行故障排查和数据分析的能力。
其次,上下文传播是确保这些关联ID(特别是TraceID和SpanID)能够在分布式系统中正确传递的关键机制。正如我们在讨论Tracing时提到的,当一个请求跨越多个服务边界时,TraceID和SpanID必须通过网络调用(例如,作为HTTP Headers或gRPC Metadata)在服务之间正确地传播下去。同时,在单个服务内部的函数调用链中,这些ID也应该被有效地传递(通常是利用Go的 context.Context),以便在任何需要记录日志或Metrics的地方都能够获取到它们。
最终,数据间的这种关联能力还需要一个强大的、具有整合能力的可视化平台来呈现。现代的可观测性平台(如Grafana)通常都致力于提供这种统一的视图。例如,在Grafana中,你可以通过精心设计的仪表盘和数据源配置,实现:
-
从Prometheus的Metrics图表(例如,一个显示高错误率的面板)直接跳转到VictoriaLogs的日志查询界面,并自动使用图表中的时间范围和相关标签(如
service_name、instance_id)作为日志的初始过滤条件。 -
从VictoriaLogs的日志条目中,如果该日志包含了
trace_id字段,可以配置一个“衍生链接(derived link)”,使得用户点击该TraceID后,能直接在Tempo(或Jaeger/Zipkin)数据源中打开这个Trace的详细视图(如Span列表等)。
通过这种方式,我们就打破了Metrics、Logging和Tracing之间的数据孤岛,构建了一个真正统一和高效的可观测性分析流程,使得从发现问题到定位根因的路径大大缩短。
在讨论完数据整合之后,我们还需要了解一下可观测性领域遥测数据的采集模型。
Push vs. Pull 模型在可观测性中的应用
在收集遥测数据时,主要有两种基本的数据流模型:Push(推送)模型和Pull(拉取)模型。理解它们的原理和差异,有助于我们选择合适的工具和设计合理的架构。
在Pull模型中,中央收集系统(例如Prometheus Server)扮演主动角色,它会定期地向被监控的目标(例如我们Go应用暴露的 /metrics 端点)发起请求,以“拉取”最新的数据。这种模型的优点如下:
-
集中控制,监控系统可以统一管理所有目标的发现、抓取配置和频率。
-
易于服务发现,尤其是在像Kubernetes这样的动态环境中,Prometheus的服务发现机制非常强大。
-
对目标应用的压力相对可控,应用只需被动地暴露一个端点。
-
能够通过拉取成功与否间接 检测目标的存活状态。
然而,Pull模型也存在一些不适用的场景,例如对于生命周期非常短暂的任务(如Serverless函数、短时间运行的批处理作业),Prometheus可能在它们结束之前还未来得及拉取数据。此外,如果目标应用位于复杂的网络环境(如NAT之后或有严格防火墙限制),中央系统可能难以直接访问其端点。Prometheus的Metrics收集是Pull模型的典型代表。
与此相对,在Push模型中,被监控的目标(通常是应用自身,或者部署在应用旁边的Agent)扮演主动角色,它会将产生的遥测数据主动“推送”到中央收集系统。这种模型的优点在于:
-
非常适合短暂任务和Serverless函数,因为它们可以在结束前主动推送自己的数据。
-
对网络环境要求更低(NAT/防火墙友好),只要目标能访问到中央收集系统的接收端点即可。
-
数据的实时性可能更高。 因为数据可以一产生就立即推送,无需等待中央系统的固定拉取周期。
但是,Push模型也面临一些挑战:中央系统对数据源的控制力相对较弱,难以统一管理所有源的配置和发送行为。如果大量数据源同时向中央系统推送数据,可能会造成“推送风暴”,导致收集系统过载(因此需要有效的限流、鉴权和背压机制)。并且,如果一个数据源停止推送数据,中央系统可能无法立即判断它是正常停止还是发生了故障(通常需要心跳或其他带外机制来辅助判断存活状态)。Logging(如Filebeats将日志Push到VictorilLogs)和Tracing(如OTel Exporter将Trace数据Push到Collector或后端)通常采用Push模型。 某些Metrics系统(如VictoriaMetrics)也原生支持多种协议的Push数据摄入,或者像Prometheus通过Pushgateway间接支持短暂任务的Push。
在现代可观测性系统中,我们往往会看到 这两种模型的混合使用。例如,一个常见的组合可能是:使用Prometheus(Pull模型)收集Metrics,使用Filebeat将日志Push到VictoriaLogs(Push模型),并使用OpenTelemetry Collector接收应用Push过来的Trace数据(Push模型)。选择哪种模型或组合,需要根据具体的数据类型、应用场景、网络环境以及对控制和实时性的要求来综合考虑。
除了数据整合和采集模型,可观测性领域的技术本身也在不断演进。其中,eBPF技术的兴起,为我们观测Go应用(乃至整个系统)带来了革命性的新视角。
eBPF对Go可观测性的革命性影响(展望)
在可观测性领域,一个正在快速发展并展现出巨大潜力的技术是eBPF(extended Berkeley Packet Filter)。虽然深入eBPF的细节超出了本节课要讲的范围,但了解其基本概念及其对Go可观测性的潜在影响,对于我们把握未来的技术趋势非常重要。
简单来说,eBPF是一种允许开发者在Linux内核中安全、高效地执行自定义代码(eBPF程序)的技术,而无需修改内核源代码或加载传统的内核模块。这些eBPF程序可以被附加到内核的各种“钩子点”(如系统调用入口/出口、网络数据包处理路径、内核函数调用等)。当内核执行到这些钩子点时,对应的eBPF程序就会被触发执行,从而能够以极低的开销收集到非常详细的系统和应用行为数据。
eBPF对可观测性的革命性影响主要体现在:
-
零侵入/自动插桩:这是eBPF最引人注目的特性之一。对于许多类型的可观测数据收集(特别是与网络流量、系统调用、内核事件相关的Metrics和部分Traces),eBPF可以做到对被观测的应用代码完全透明。也就是说,我们无需在Go应用层面进行任何代码修改、引入SDK或重新编译部署,eBPF程序就能直接在内核层面“观察”到应用的外部行为(如它发起了哪些网络连接、读写了哪些文件、执行了哪些系统调用)并收集相关数据。
-
获取更底层的、更全面的遥测数据:eBPF可以直接访问内核数据结构和事件,从而能够收集到许多传统用户态监控工具难以获取或开销较大的信息,例如精确到每个进程/容器的网络流量统计、TCP连接的生命周期事件、DNS解析延迟、系统调用的频率和耗时、磁盘I/O的细节等。
-
对Go应用的价值:
-
弥补Go运行时可观测性的盲点:虽然Go的
pprof和trace工具能提供丰富的运行时内部信息,但对于某些更底层的、与操作系统内核交互密切的行为(如精确的网络包收发细节、文件I/O的实际耗时、特定系统调用的瓶颈),eBPF能提供更直接、更全面的观测视角。 -
实现更低开销的持续剖析:一些基于eBPF的剖析工具(如Parca、Pyroscope的eBPF模式)正在探索如何通过在内核层面采样CPU执行、内存分配(通过hook malloc/free 等)甚至off-CPU时间,来实现比传统用户态采样更低开销、干扰更小的持续性能剖析。
-
自动化的服务依赖拓扑发现和部分分布式追踪能力:通过监控所有进程的网络连接和请求(特别是对HTTP/1.x、HTTP/2、gRPC等常见协议的解析),基于eBPF的工具可以在一定程度上自动发现服务之间的调用关系,构建服务拓扑图,并为这些协议的请求自动生成Trace Span,而无需应用层进行手动插桩(尽管其包含的业务上下文信息可能不如SDK插桩丰富)。
-
当前,已经有不少优秀的开源项目(如CNCF的Pixie、Cilium、Falco和Grafana Labs的Pyroscope、Deepflow等)和商业产品正在积极利用eBPF来构建新一代的、更自动化的、零侵入或低侵入的可观测性解决方案。
eBPF无疑正在为云原生可观测性带来一场深刻的变革。它使得我们能够以一种前所未有的方式和粒度去理解和诊断我们的Go服务(以及运行它们的基础设施),并且很多时候是以对应用代码零侵入的方式。对于Go开发者来说,关注并理解eBPF技术及其在可观测性领域的应用,将是未来提升系统洞察能力、简化可观测性集成的一个非常重要的方向。
小结
这节课,我们继续深入Tracing领域,认识到OpenTelemetry(OTel)作为统一的、厂商中立的遥测数据标准的重要性。我们学习了OTel Tracing的核心概念(Trace、Span、SpanContext),以及如何在Go应用中使用OTel Go SDK进行手动插桩来生成和传播Trace数据,并通过OTLP Exporter将其发送到OpenTelemetry Collector,最终在追踪后端(如Grafana Tempo)进行可视化和分析。我们通过一个包含两个Go HTTP服务相互调用的示例,完整演示了这个过程。
此外,我们还讨论了如何整合Metrics、Logging和Tracing(通过一致的元数据和上下文传播,特别强调了TraceID在日志中的重要性),分析了可观测性数据采集中常见的Push与Pull模型的特点与应用,并展望了eBPF技术为Go应用可观测性带来的革命性影响和未来的巨大潜力,它有望实现零侵入或极低侵入的自动化可观测数据收集。
通过连续三节课的学习,相信你已经掌握了为Go服务构建强大可观测性体系的核心知识和技能。这将使你能够更自信地将Go应用部署到复杂的生产环境,并在出现问题时,拥有快速洞察和解决问题的能力,真正让你的服务不再是一个难以捉摸的“黑盒”,为后续的故障诊断、性能调优打下坚实的数据基础。
思考题
- 技术选型与集成策略:假设你正在为一个新的Go微服务(例如,一个处理用户画像分析的核心服务,它会接收数据、进行一些计算,并可能调用其他内部服务)设计其完整的可观测性方案。
-
Metrics:你会选择Prometheus作为基础,还是直接考虑VictoriaMetrics?为什么?你的Go应用会暴露哪些关键的自定义指标(遵循RED或黄金四信号的思路)?
-
Logging:你会选择Loki还是VictoriaLogs作为日志后端(假设不考虑ELK)?理由是什么?你的Go应用会使用
log/slog输出哪些关键的结构化字段来帮助你分析用户画像处理的流程和可能遇到的问题? -
Tracing:你会如何使用OpenTelemetry Go SDK对这个画像分析服务进行插桩,以追踪一个画像生成请求的完整生命周期(包括可能的内部函数调用和对其他服务的调用)?
-
- 数据关联与eBPF的思考:
-
为了将Metrics、Logging和Tracing数据有效地关联起来,你认为在你的Go应用代码(例如,
slog日志的属性、OTel Span的属性)以及在日志收集代理(如Filebeat、Promtail、Vector)的配置中,最关键的需要保持一致或能够相互映射的上下文ID或标签是什么? -
如果让你畅想一下,eBPF技术未来可能会如何改变或简化你为这个Go用户画像服务构建可观测性的方式(例如,在自动插桩、网络监控、底层性能剖析等方面)?
-
欢迎在留言区分享你的思考和方案!我是Tony Bai,我们下节课见。
测试进阶:组织、覆盖、Mock与Fuzzing的最佳实践(上)
你好,我是Tony Bai。
在Go工程实践中,编写测试是保障代码质量、提升系统稳定性的基石。你可能已经熟悉了如何用Go编写基本的单元测试,但随着项目复杂度的提升,仅仅“会写测试”远远不够。我们还需要掌握更高级的测试组织方法、处理复杂依赖的策略、应对并发场景的技巧,以及利用自动化工具探索代码边界的能力。
回忆一下,你是否遇到过下面这些进阶测试中的挑战?
-
一个函数的测试用例写了几百行,包含了各种场景,难以阅读和维护?
-
面对依赖数据库或外部API的模块,开发者编写单元测试时举步维艰,不知道如何下手?
-
为并发代码编写的测试时灵时不灵,数据竞争和死锁像幽灵一样难以捉摸?
-
测试覆盖率报告显示一片绿色,但上线后依然Bug频出?
-
感觉自己的测试用例总是覆盖不到那些“刁钻”的边界条件?
接下来的两节课,我们将超越基础的单元测试,直面上述挑战中的问题,深入探讨Go测试的进阶技巧与最佳实践。我们将一起:
-
快速回顾Go测试的基础类型(单元、基准、示例),确保我们在同一起跑线。
-
深入探讨 测试组织 的核心技巧:子测试(t.Run)和表驱动测试(Table-Driven Tests),学习如何编写清晰、可维护的测试用例集,以及如何利用子测试规划包内测试的层次布局。
-
重点攻克 并发测试 的难点,讨论如何在Go中安全有效地测试并发代码,包括使用 t.Parallel、sync 包、数据竞争检测,并展望Go 1.25即将正式引入的 testing/synctest。
-
详解 测试策略中的Fake、Stub与Mock,以及如何利用 testdata 管理测试数据,有效隔离外部依赖。
-
讨论如何正确 理解和运用测试覆盖率,避免将其作为唯一的衡量标准。
-
介绍Go 1.18引入的强大特性—— Fuzzing(模糊测试),学习如何利用它自动发现代码中的边界条件和潜在缺陷。
这节课,我们先来看Go测试基础和测试组织的核心技巧。
Go测试基础回顾
在深入探讨Go测试的进阶技巧之前,让我们快速回顾一下构成Go测试体系的几个核心基石。这能确保我们对接下来的讨论有共同的语境。Go语言的测试能力主要由标准库中的 testing 包和强大的 go test 命令行工具提供。
测试文件的约定与测试函数的签名
Go的测试遵循一套简单而明确的约定,这使得测试的发现和执行自动化成为可能。
首先是测试文件命名。 所有测试代码都必须放置在以 _test.go 为后缀的文件中。这些测试文件需要与它们所测试的源文件位于同一个包内。例如,如果你的包中有一个 calculator.go 文件,那么它的测试代码通常会放在 calculator_test.go 文件里。
其次是单元测试函数(Unit Tests)。 这是最常见的测试类型,用于验证包中某个独立函数或方法的行为。函数签名必须是 func TestXxx(t *testing.T),其中函数名必须以 Test 开头,其后的 Xxx 是你为测试命名的部分,通常会包含被测试的函数或方法名。 t *testing.T 是测试框架提供的上下文对象,用于报告测试结果和状态。示例如下:
// ch25/basics/calc.go
package basics
func Add(a, b int) int { return a + b }
// ch25/basics/calc_test.go
package basics
import "testing"
func TestAdd(t *testing.T) {
if Add(1, 2) != 3 {
t.Error("1 + 2 should be 3") // 报告错误
}
}
然后是示例测试函数(Example Tests)。 主要用于展示包中函数或方法如何使用,它们既是测试(如果包含 // Output: 注释则会验证输出),也是实时更新的文档。函数签名通常是 func ExampleXxx()。函数名必须以 Example 开头。示例如下:
// ch25/basics/calc_test.go
import "fmt"
func ExampleAdd() {
sum := Add(5, 10)
fmt.Println(sum)
// Output: 15
}
这些命名和签名约定是Go测试框架能够自动发现并执行测试的基础。
testing.T 的核心交互
*testing.T(用于单元测试和示例测试)对象是测试函数与测试框架交互的桥梁。它们提供了一系列方法来报告测试状态、记录信息和控制测试流程。我们不必在此罗列所有方法,但理解其核心交互方式很重要。
-
报告失败:
-
t.Error(args...)/t.Errorf(format, args...)报告测试失败,但允许测试继续执行。 -
t.Fatal(args...)/t.Fatalf(format, args...)报告测试失败,并立即停止当前测试函数(或子测试)的执行。
-
-
记录信息:
t.Log(args...)/t.Logf(format, args...)输出日志信息,通常在go test -v时显示。 -
跳过测试:
t.Skip(args...)/t.Skipf(format, args...)将当前测试标记为跳过。 -
辅助函数标记:
t.Helper()。在自定义的测试辅助函数中调用,使错误报告的行号更准确。 -
资源清理:
t.Cleanup(f func())。注册一个函数,在当前测试(或子测试)结束后执行,非常适合资源释放。
熟悉这些核心方法,能帮助我们编写出表意清晰、结果明确的测试。
go test 命令的核心功能
go test 是执行所有类型测试的统一入口。它是一个功能非常强大的工具,这里我们仅回顾几个最核心的常用参数,更详细的用法可以通过 go help test 查看。
- 运行测试:
-
go test:运行当前包下的所有测试。 -
go test ./...:运行当前目录及所有子目录下的测试。 -
-run TestNameRegex:只运行名称匹配正则表达式的测试(例如,-run TestMyFeature)。 -
-bench BenchmarkNameRegex:运行匹配的基准测试(例如,-bench .运行所有基准测试)。关于性能基准测试的内容,我们将在后面的课程中进行全面系统的进阶讲解。
-
- 控制输出与行为:
-
-v:详细输出,包括每个测试的名称、状态和日志。 -
-count n:将每个测试运行n次。 -
-failfast:在第一个测试失败后立即停止。 -
-short:运行一个“简短”模式的测试,测试代码中可以用testing.Short()来判断是否跳过耗时测试。
-
- 覆盖率分析:
-
-cover:计算并显示测试覆盖率。 -
-coverprofile=coverage.out:将覆盖率数据保存到文件。 -
go tool cover -html=coverage.out:生成HTML格式的覆盖率报告。
-
- 并发与性能:
-
-race:启用数据竞争检测器。 -
-benchmem:在基准测试中报告内存分配。 -
-fuzz FuzzTargetName(Go 1.18+):运行模糊测试。
-
以上这些基础构成了我们进阶讨论的起点。理解这些约定、API和命令,是有效运用Go测试框架的前提。现在,让我们深入第一个进阶主题:如何更好地组织我们的测试代码。
测试组织:构建清晰、可维护的测试用例集
随着被测试代码复杂度的增加,一个简单的 TestXxx 函数可能会迅速膨胀,尤其是当一个函数有多种输入组合和边界条件时,如何避免测试函数冗长且难以阅读?当一个包内有多个相关的函数或类型方法需要测试时,如何组织测试文件和函数,使其逻辑清晰?测试用例集如果没有清晰的组织结构,会给理解和管理测试带来困难。Go测试框架提供了子测试和表驱动测试这两种强大的机制来协助解决这些问题,同时 “让添加新测试用例变得容易”,是我们组织测试时应遵循的核心原则。
子测试(t.Run):化整为零,提升测试粒度与可读性
Go 1.7 引入的 t.Run 方法允许我们在一个顶层测试函数(TestXxx)内部创建和运行独立的、命名的子测试。每个子测试都有自己的 *testing.T 实例,可以独立地报告成功、失败或跳过。
那么,为何需要子测试?原因如下:
-
隔离失败:一个子测试的失败不会影响其他子测试的执行。
-
更清晰的测试报告:
go test -v的输出会清晰显示层级和名称(如TestMyFunction/SubTestA/Case1),便于定位。 清晰的子测试命名对于使测试失败易读至关重要。 -
共享Setup/Teardown逻辑:可以在父测试中执行通用设置和清理。
-
逻辑分组:将相关测试组织在同一个父测试下。
子测试的通常使用形式如下:
func TestXxx(t *testing.T) {
t.Run(name string, f func(t *testing.T) {
// 子测试f的函数体,实现子测试测试逻辑
})
)
其中,name 参数是子测试的描述性名称,f 是子测试的执行函数。下面是一个典型的 使用子测试进行测试管理 的示例:
// ch25/subtests/parser_test.go
package subtests
import (
"fmt"
"testing"
)
// ParseInput is a function we want to test with subtests.
func ParseInput(input string, strictMode bool) (string, error) {
if input == "" {
return "", fmt.Errorf("input cannot be empty")
}
if strictMode && len(input) > 10 {
return "", fmt.Errorf("input too long in strict mode (max 10 chars)")
}
return "parsed: " + input, nil
}
func TestParseInput_WithSubtests(t *testing.T) {
t.Log("Setting up for ParseInput tests...")
// defer t.Log("Tearing down after ParseInput tests...") // Example of shared teardown
t.Run("EmptyInput", func(t *testing.T) {
// t.Parallel() // This subtest could run in parallel if independent
_, err := ParseInput("", false)
if err == nil {
t.Error("Expected error for empty input, got nil")
} else {
t.Logf("Got expected error for empty input: %v", err)
}
})
t.Run("ValidInputNonStrict", func(t *testing.T) {
// t.Parallel()
input := "hello world" // More than 10 chars, but non-strict
expected := "parsed: " + input
result, err := ParseInput(input, false)
if err != nil {
t.Errorf("Expected no error for valid input in non-strict mode, got %v", err)
}
if result != expected {
t.Errorf("Expected result '%s', got '%s'", expected, result)
}
})
t.Run("StrictChecks", func(t *testing.T) { // A group for strict mode tests
// t.Parallel() // This group itself can be parallel with other top-level t.Run
t.Run("InputTooLongInStrictMode", func(t *testing.T) {
// t.Parallel()
input := "thisisareallylonginput" // More than 10 chars
_, err := ParseInput(input, true) // strictMode = true
if err == nil {
t.Error("Expected error for too long input in strict mode, got nil")
} else {
expectedErrorMsg := "input too long in strict mode (max 10 chars)"
if err.Error() != expectedErrorMsg {
t.Errorf("Expected error message '%s', got '%s'", expectedErrorMsg, err.Error())
}
t.Logf("Got expected error for long input in strict mode: %v", err)
}
})
t.Run("ValidShortInputInStrictMode", func(t *testing.T) {
// t.Parallel()
input := "short"
expected := "parsed: " + input
result, err := ParseInput(input, true) // strictMode = true
if err != nil {
t.Errorf("Expected no error for short input in strict mode, got %v", err)
}
if result != expected {
t.Errorf("Expected result '%s', got '%s'", expected, result)
}
})
})
}
以-v标志运行该测试,go测试框架会输出类似如下结果:
$go test -v
=== RUN TestParseInput_WithSubtests
parser_test.go:20: Setting up for ParseInput tests...
=== RUN TestParseInput_WithSubtests/EmptyInput
parser_test.go:29: Got expected error for empty input: input cannot be empty
=== RUN TestParseInput_WithSubtests/ValidInputNonStrict
=== PAUSE TestParseInput_WithSubtests/ValidInputNonStrict
=== RUN TestParseInput_WithSubtests/StrictChecks
=== PAUSE TestParseInput_WithSubtests/StrictChecks
=== NAME TestParseInput_WithSubtests
parser_test.go:77: Tearing down after ParseInput tests...
=== CONT TestParseInput_WithSubtests/ValidInputNonStrict
=== CONT TestParseInput_WithSubtests/StrictChecks
=== RUN TestParseInput_WithSubtests/StrictChecks/InputTooLongInStrictMode
=== PAUSE TestParseInput_WithSubtests/StrictChecks/InputTooLongInStrictMode
=== RUN TestParseInput_WithSubtests/StrictChecks/ValidShortInputInStrictMode
=== PAUSE TestParseInput_WithSubtests/StrictChecks/ValidShortInputInStrictMode
=== CONT TestParseInput_WithSubtests/StrictChecks/InputTooLongInStrictMode
=== CONT TestParseInput_WithSubtests/StrictChecks/ValidShortInputInStrictMode
=== NAME TestParseInput_WithSubtests/StrictChecks/InputTooLongInStrictMode
parser_test.go:60: Got expected error for long input in strict mode: input too long in strict mode (max 10 chars)
--- PASS: TestParseInput_WithSubtests (0.00s)
--- PASS: TestParseInput_WithSubtests/EmptyInput (0.00s)
--- PASS: TestParseInput_WithSubtests/ValidInputNonStrict (0.00s)
--- PASS: TestParseInput_WithSubtests/StrictChecks (0.00s)
--- PASS: TestParseInput_WithSubtests/StrictChecks/InputTooLongInStrictMode (0.00s)
--- PASS: TestParseInput_WithSubtests/StrictChecks/ValidShortInputInStrictMode (0.00s)
PASS
ok ch25/subtests 0.007s
从上面TestParseInput_WithSubtests的测试输出中我们可以清晰地看到,子测试支持嵌套定义。例如,我们在StrictChecks这个子测试内部,又定义了InputTooLongInStrictMode和ValidShortInputInStrictMode这两个更下一层的子测试。这种 嵌套能力使得我们可以构建出非常精细和有层次的测试结构,这对于组织针对复杂功能(其本身可能包含多个子功能或多种状态组合)的测试场景非常有用。测试报告会忠实地反映这种层级关系,使得定位问题更加精准。
如果子测试之间是相互独立的(不共享可变状态,或者共享状态已得到妥善同步),可以在每个子测试的f func(t *testing.T)函数体开头调用t.Parallel()。这会告诉测试框架,这个子测试可以与其他标记为Parallel的(同层级的)子测试或顶层测试并发执行。重要的是,父测试函数(如TestParseInput_WithSubtests)在所有其Parallel子测试完成之前不会返回。
子测试为我们提供了组织复杂测试场景的强大武器,它使得我们可以将一个庞大的测试需求分解为一系列更小、更专注、更易于管理的测试单元。而当这些测试单元共享相似的测试逻辑,仅在输入数据和期望输出上有所不同时,表驱动测试便是子测试的最佳拍档,能进一步提升测试代码的简洁性和可维护性。
表驱动测试(Table-Driven Tests):数据与逻辑分离的最佳实践
表驱动测试是Go社区广为推崇的一种测试模式,它完美体现了 “将测试用例与测试逻辑分开” 的测试惯例。其核心思想是将一系列测试用例的输入数据和期望输出组织在一个“表”(通常是结构体切片)中,然后编写一段通用的测试逻辑来遍历这个表,对每一行(即每一个测试用例)执行测试。
表驱动测试的核心思想与结构是这样的:
-
定义测试用例结构体:通常包含 name(string,用于子测试命名和描述)、输入参数字段、期望输出字段、期望错误类型等。
-
创建测试用例表:一个该结构体的切片实例。
-
循环执行:遍历切片,对每个测试用例:
-
使用
t.Run(testCase.name, func(t *testing.T) { ... })创建子测试。清晰的testCase.name是保证测试失败信息易读的关键。 -
在子测试内部执行被测逻辑,并进行断言。
-
下面是一个表测试驱动的典型示例:
// ch25/tabledriven/calculator_test.go
package tabledriven
import (
"fmt"
"math"
"testing"
// "github.com/google/go-cmp/cmp"
)
// Function to be tested
func Divide(a, b float64) (float64, error) {
if b == 0 {
return 0, fmt.Errorf("division by zero")
}
return a / b, nil
}
func TestDivide_TableDriven(t *testing.T) {
testCases := []struct {
name string // Test case name
a, b float64 // Inputs
expectedVal float64 // Expected result value
expectedErr string // Expected error message substring (empty if no error)
}{
{
name: "ValidDivision_PositiveNumbers",
a: 10, b: 2,
expectedVal: 5,
expectedErr: "",
},
{
name: "ValidDivision_NegativeResult",
a: -10, b: 2,
expectedVal: -5,
expectedErr: "",
},
{
name: "DivisionByZero",
a: 10, b: 0,
expectedVal: 0,
expectedErr: "division by zero",
},
{
name: "ZeroDividedByNumber",
a: 0, b: 5,
expectedVal: 0,
expectedErr: "",
},
{
name: "FloatingPointPrecision",
a: 1.0, b: 3.0,
expectedVal: 0.3333333333333333,
expectedErr: "",
},
}
for _, tc := range testCases {
currentTestCase := tc
t.Run(currentTestCase.name, func(t *testing.T) {
val, err := Divide(currentTestCase.a, currentTestCase.b)
if currentTestCase.expectedErr != "" {
if err == nil {
t.Errorf("Divide(%f, %f): expected error containing '%s', got nil",
currentTestCase.a, currentTestCase.b, currentTestCase.expectedErr)
} else if err.Error() != currentTestCase.expectedErr {
t.Errorf("Divide(%f, %f): unexpected error message: got '%v', want substring '%s'",
currentTestCase.a, currentTestCase.b, err, currentTestCase.expectedErr)
}
} else {
if err != nil {
t.Errorf("Divide(%f, %f): unexpected error: %v", currentTestCase.a, currentTestCase.b, err)
}
}
if currentTestCase.expectedErr == "" {
const epsilon = 1e-9
if math.Abs(val-currentTestCase.expectedVal) > epsilon {
t.Errorf("Divide(%f, %f) = %f; want %f (within epsilon %e)",
currentTestCase.a, currentTestCase.b, val, currentTestCase.expectedVal, epsilon)
}
}
})
}
}
运行该测试用例,你会看到类似下面的测试输出结果:
$go test -v
=== RUN TestDivide_TableDriven
=== RUN TestDivide_TableDriven/ValidDivision_PositiveNumbers
=== RUN TestDivide_TableDriven/ValidDivision_NegativeResult
=== RUN TestDivide_TableDriven/DivisionByZero
=== RUN TestDivide_TableDriven/ZeroDividedByNumber
=== RUN TestDivide_TableDriven/FloatingPointPrecision
--- PASS: TestDivide_TableDriven (0.00s)
--- PASS: TestDivide_TableDriven/ValidDivision_PositiveNumbers (0.00s)
--- PASS: TestDivide_TableDriven/ValidDivision_NegativeResult (0.00s)
--- PASS: TestDivide_TableDriven/DivisionByZero (0.00s)
--- PASS: TestDivide_TableDriven/ZeroDividedByNumber (0.00s)
--- PASS: TestDivide_TableDriven/FloatingPointPrecision (0.00s)
PASS
ok ch25/tabledriven
表驱动测试是Go中编写单元测试的事实标准,它极大地提高了测试代码的组织性、可读性和可维护性,并简化了新测试用例的添加过程——通常只需要在表中增加一行数据。这完美契合了“让添加新测试用例变得容易”的原则。
掌握了子测试和表驱动测试后,我们就可以更有条理地组织一个包内的测试代码了。
利用子测试规划包内测试的层次布局
当一个包内有多个相关的函数,或者一个类型有多个方法需要测试时,如何组织这些测试,使其在 go test -v 的输出中逻辑清晰、易于定位,是一个值得思考的问题。子测试在这里能发挥巨大作用,帮助我们构建清晰的测试层次。
利用子测试规划包内测试的层次布局的策略如下:
-
按被测单元组织顶层测试函数:为主要类型或功能模块创建顶层
TestXxx函数。例如,对于一个UserService类型,我们可以创建一个TestUserService(t *testing.T)作为其所有方法测试的入口。 -
在顶层测试函数中使用 t.Run 为每个方法或主要功能点创建子测试分组:在
TestUserService内部,为CreateUser、GetUser、UpdateUser等每个公开方法创建一个子测试。这形成了测试报告的第一层逻辑分组,使得报告更易读,例如TestUserService/CreateUser。 -
在方法/子功能级别的子测试内,再使用表驱动测试或进一步的子测试来覆盖不同场景:对于每个方法的测试(如
CreateUser的子测试),内部再使用表驱动测试来覆盖该方法的各种输入场景和边界条件。表驱动的每一行又可以通过 t.Run 变成更下一级的子测试,例如TestUserService/CreateUser/ValidInput。
为了更直观地展示这一策略,我们来看一个具体的示例(为了展示测试层次布局,示例代码做了简化):
// ch25/testhierarchy/user_service.go
package user_service
import "fmt"
type User struct {
ID string
Name string
}
type UserService struct {
users map[string]User
}
func NewUserService() *UserService {
return &UserService{users: make(map[string]User)}
}
func (s *UserService) CreateUser(id, name string) (User, error) {
if id == "" {
return User{}, fmt.Errorf("user ID cannot be empty")
}
if _, exists := s.users[id]; exists {
return User{}, fmt.Errorf("user %s already exists", id)
}
nu := User{ID: id, Name: name}
s.users[id] = nu
fmt.Printf("[UserService] User created: %+v\n", nu)
return nu, nil
}
func (s *UserService) GetUser(id string) (User, error) {
user, ok := s.users[id]
if !ok {
return User{}, fmt.Errorf("user %s not found", id)
}
fmt.Printf("[UserService] User retrieved: %+v\n", user)
return user, nil
}
func (s *UserService) UpdateUser(id, newName string) error {
if id == "" || newName == "" {
return fmt.Errorf("id and newName cannot be empty for UpdateUser")
}
user, ok := s.users[id]
if !ok {
return fmt.Errorf("user %s not found", id)
}
user.Name = newName
s.users[id] = user
fmt.Printf("[UserService] UpdateUser called for ID: %s, NewName: %s\n", id, newName)
return nil
}
// ch25/testhierarchy/user_service_test.go
package user_service
import (
"testing"
)
// TestUserService acts as the main entry point for testing all UserService functionalities.
// It demonstrates how to group tests for different methods using t.Run.
func TestUserService(t *testing.T) {
// Optional: Common setup for all UserService tests can go here.
t.Log("Starting tests for UserService...")
// --- Group for CreateUser method tests ---
t.Run("CreateUser", func(t *testing.T) {
t.Log(" Running CreateUser tests...")
// Sub-case 1 for CreateUser: Valid input
t.Run("ValidInput", func(t *testing.T) {
// t.Parallel() // This specific case could run in parallel with other CreateUser cases.
userService := NewUserService() // Fresh instance for isolation
_, err := userService.CreateUser("user123", "Alice")
if err != nil {
t.Errorf("CreateUser with valid input failed: %v", err)
}
// Add more specific assertions if needed, but focus here is on structure.
t.Log(" CreateUser/ValidInput: PASSED (simulated)")
})
// Sub-case 2 for CreateUser: Invalid input (e.g., empty ID)
t.Run("EmptyID", func(t *testing.T) {
userService := NewUserService()
_, err := userService.CreateUser("", "Bob")
if err == nil {
t.Error("CreateUser with empty ID should have failed, but got nil error")
}
t.Log(" CreateUser/EmptyID: PASSED (simulated error check)")
})
// Add more t.Run calls for other CreateUser scenarios (e.g., duplicate ID)
})
// --- Group for GetUser method tests ---
t.Run("GetUser", func(t *testing.T) {
t.Log(" Running GetUser tests...")
userService := NewUserService()
userService.CreateUser("userExists", "Charlie")
// Sub-case 1 for GetUser: Existing user
t.Run("ExistingUser", func(t *testing.T) {
// t.Parallel()
_, err := userService.GetUser("userExists")
if err != nil {
t.Errorf("GetUser for existing user failed: %v", err)
}
t.Log(" GetUser/ExistingUser: PASSED (simulated)")
})
// Sub-case 2 for GetUser: Non-existing user
t.Run("NonExistingUser", func(t *testing.T) {
// t.Parallel()
_, err := userService.GetUser("userDoesNotExist")
if err == nil {
t.Error("GetUser for non-existing user should have failed, but got nil error")
}
t.Log(" GetUser/NonExistingUser: PASSED (simulated error check)")
})
})
// --- Group for UpdateUser method tests (Illustrative) ---
t.Run("UpdateUser", func(t *testing.T) {
t.Log(" Running UpdateUser tests (structure demonstration)...")
t.Run("ValidUpdate", func(t *testing.T) {
userService := NewUserService()
userService.CreateUser("userToUpdate", "OldName")
err := userService.UpdateUser("userToUpdate", "NewName")
if err != nil {
t.Errorf("UpdateUser failed: %v", err)
}
t.Log(" UpdateUser/ValidUpdate: PASSED (simulated)")
})
})
t.Log("Finished tests for UserService.")
}
运行测试后,我们可以看到结构层次清晰的测试报告输出:
$go test -v
=== RUN TestUserService
user_service_test.go:11: Starting tests for UserService...
=== RUN TestUserService/CreateUser
user_service_test.go:15: Running CreateUser tests...
=== RUN TestUserService/CreateUser/ValidInput
[UserService] User created: {ID:user123 Name:Alice}
user_service_test.go:26: CreateUser/ValidInput: PASSED (simulated)
=== RUN TestUserService/CreateUser/EmptyID
user_service_test.go:36: CreateUser/EmptyID: PASSED (simulated error check)
=== RUN TestUserService/GetUser
user_service_test.go:44: Running GetUser tests...
[UserService] User created: {ID:userExists Name:Charlie}
=== RUN TestUserService/GetUser/ExistingUser
[UserService] User retrieved: {ID:userExists Name:Charlie}
user_service_test.go:55: GetUser/ExistingUser: PASSED (simulated)
=== RUN TestUserService/GetUser/NonExistingUser
user_service_test.go:65: GetUser/NonExistingUser: PASSED (simulated error check)
=== RUN TestUserService/UpdateUser
user_service_test.go:71: Running UpdateUser tests (structure demonstration)...
=== RUN TestUserService/UpdateUser/ValidUpdate
[UserService] User created: {ID:userToUpdate Name:OldName}
[UserService] UpdateUser called for ID: userToUpdate, NewName: NewName
user_service_test.go:79: UpdateUser/ValidUpdate: PASSED (simulated)
=== NAME TestUserService
user_service_test.go:83: Finished tests for UserService.
--- PASS: TestUserService (0.00s)
--- PASS: TestUserService/CreateUser (0.00s)
--- PASS: TestUserService/CreateUser/ValidInput (0.00s)
--- PASS: TestUserService/CreateUser/EmptyID (0.00s)
--- PASS: TestUserService/GetUser (0.00s)
--- PASS: TestUserService/GetUser/ExistingUser (0.00s)
--- PASS: TestUserService/GetUser/NonExistingUser (0.00s)
--- PASS: TestUserService/UpdateUser (0.00s)
--- PASS: TestUserService/UpdateUser/ValidUpdate (0.00s)
PASS
ok ch25/testhierarchy 0.006s
通过示例我们看到这种测试分层组织方式的优点如下:
-
测试报告结构清晰:输出结果按
TestType/Method/CaseName的层次组织,非常易于定位具体哪个场景的测试失败。 -
逻辑聚合:将与同一类型或功能相关的所有测试都聚合在一个顶层测试函数下,方便管理和理解。
-
可共享Setup/Teardown:可以在顶层
TestUserService函数级别执行一次性的设置(如创建UserService实例、初始化依赖等),并通过t.Cleanup注册清理逻辑。这些设置对所有子测试可见(上述示例里没有显式提供setup/teardown)。
这种分层组织方式,使得即便是包含大量测试用例的包,其测试结构也能保持清晰和易于导航。
为了更直观地理解这种基于子测试的层次化测试组织,我们可以用下图来表示一个典型的布局,其中包含了Setup和Teardown的执行时机:
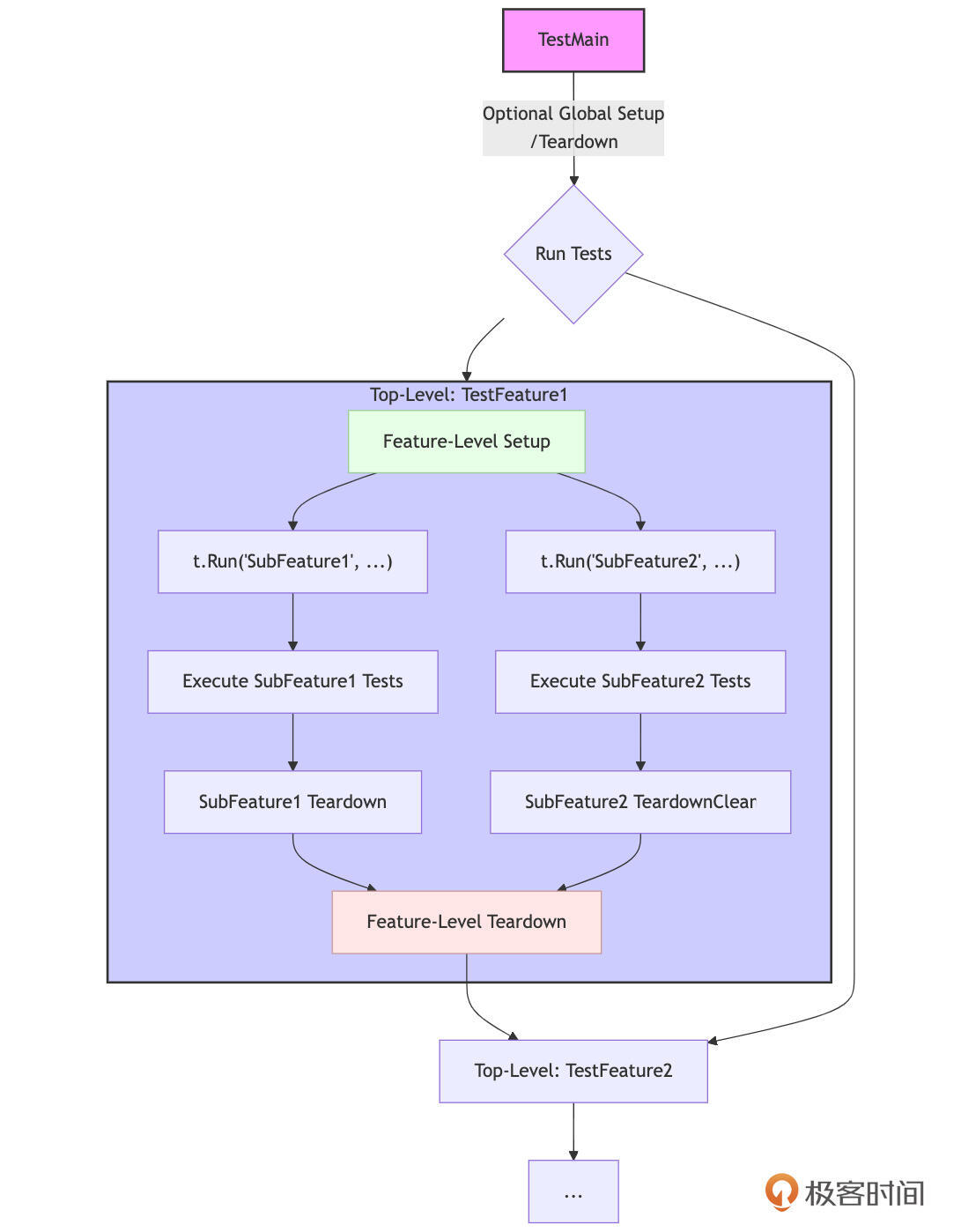
我们来详细解释下图中的重要内容。
-
(可选)
TestMain(m *testing.M):位于包级别,可以执行一次性的全局Setup(在m.Run()之前)和全局Teardown(在m.Run()之后)。这通常用于设置/清理整个包测试所需的外部依赖或环境。 -
顶层测试函数(如
TestFeature1):这是针对一个主要功能、类型或模块的测试入口。-
Feature-Level Setup:在顶层测试函数体的开始部分,可以直接编写该特性所有子测试共享的Setup代码。
-
t.Run("SubFeatureX", ...):通过 t.Run 创建子测试,用于测试该特性下的不同子功能或场景。 -
Sub-Feature Tests:在每个子测试的函数体内,执行具体的测试逻辑。这里可以进一步嵌套 t.Run 或使用表驱动测试。
-
Sub-Feature Teardown:在每个子测试内部,可以使用 t.Cleanup() 来注册该子测试完成后的清理逻辑。这些清理函数会在其对应的子测试返回后立即执行。
-
Feature-Level Teardown:在顶层测试函数中,可以使用 t.Cleanup() 或 defer 语句来注册在该函数所有子测试(包括并行的子测试)都执行完毕后的清理逻辑。
-
-
其他顶层测试函数(如 TestFeature1):包内可以有多个并列的顶层测试函数,它们之间通常是独立的。
通过这种层次化的组织,结合 t.Run 和 t.Cleanup,我们可以构建出结构清晰、Setup/Teardown逻辑明确、易于维护和扩展的测试套件。这不仅使得单个测试用例更易于理解和编写,也极大地提升了整个测试集的可管理性。
然而,当我们的测试场景变得更为复杂,例如测试用例本身包含大量数据,或者需要模拟文件系统交互,甚至需要一种领域特定的语言来描述测试时,我们还可以探索一些更高级的测试组织与数据管理方式。
更高级的测试组织与数据管理(扩展思路)
虽然子测试和表驱动测试是Go测试的基石,能解决大部分组织问题,但对于某些特定和复杂的场景,以下进阶思路能进一步提升测试的表达力和可维护性。
当表驱动不适用时:明确独立的子测试
并非所有东西都适合放在表中。对于某些测试用例,如果它们各自需要非常独特的、大量的Setup/Teardown逻辑,或者其核心测试逻辑本身差异巨大,那么强行将它们塞进一个复杂的、包含许多条件分支的表驱动测试中,反而可能降低可读性。
在这种情况下,直接为这些特殊场景编写独立的、描述性命名的子测试(t.Run),或者甚至将它们拆分成多个独立的顶层 TestXxx 函数,可能是更清晰的选择。
例如,测试一个复杂算法的多种极端边界条件,每个边界条件可能都需要一套完全不同的输入构造和验证逻辑,此时独立的子测试能更好地隔离和表达这些特定场景。如下面的概念示例:
// 概念示例
func TestComplexAlgorithm(t *testing.T) {
t.Run("HandlesEmptyInputGracefully", func(t *testing.T) {
// Specific setup for empty input
// Specific assertions for empty input
// Specific cleanup if needed
})
t.Run("HandlesVeryLargeInputWithinLimits", func(t *testing.T) {
// Specific setup for large input
// Specific assertions for large input
})
t.Run("HandlesInputWithSpecialCharactersCorrectly", func(t *testing.T) {
// ...
})
// ...
}
使用 testdata 与黄金文件进行输入输出测试(及Update模式)
当测试用例的输入数据或期望输出结果比较复杂,不适合直接硬编码在测试函数中时(例如,多行文本、JSON/XML片段、或者格式化的输出),Go语言提供了一种优雅的解决方案,即通过 testdata 目录约定结合“黄金文件”(Golden Files)测试模式。当测试用例的输入数据或期望输出结果不适合直接硬编码到测试函数中时(例如,多行文本、JSON/XML片段或格式化输出),testdata 目录便显得尤为重要。
testdata 目录的约定允许开发者在包目录下创建一个名为 testdata 的子目录,并将所有外部测试数据文件放置其中。这些文件在运行 go test 时可以通过相对路径被测试代码访问,但它们不会被编译到最终的包或可执行文件中,仅用于测试目的。
在此基础上, 黄金文件模式 提供了一种管理复杂期望输出的有效方法。在这种模式下,对于一个给定的输入(该输入本身也可能来源于 testdata 中的文件),被测函数会产生一个输出。我们将这个“正确的”、“期望的”输出预先保存到一个文件中,这个文件就是所谓的“黄金文件”,通常也存放在 testdata 目录下,并遵循特定的命名约定(例如, testcase1_input.txt 对应 testcase1_output.golden)。测试逻辑的核心在于运行被测函数,获取其实际输出,然后将其与黄金文件中的内容进行精确比较,从而验证函数行为的正确性。
为了提升维护效率,特别是当被测函数逻辑更新导致大量黄金文件需要修改时,可以引入 Update模式。通过在运行 go test 时传递一个自定义的命令行标志(例如 -update),测试逻辑会改变其行为:它不再进行比较,而是将函数的实际输出直接覆盖(更新)到对应的黄金文件中。然而, 更新黄金文件后,必须使用版本控制工具(如 git diff)仔细审查这些变更,以确保新的黄金内容确实是正确的、符合预期的,而不是因为引入了新的Bug才产生的。只有在审查通过后,才能将更新后的黄金文件提交到版本库。
这种测试模式的优点显而易见:它使得 \_test.go 文件保持简洁,将测试逻辑与大量测试数据分离;复杂数据变得易于管理,可以方便地编辑、审查和版本控制 testdata 中的文件;通过查看黄金文件,测试的可读性大大增强,可以直观地了解期望的输出格式和内容;同时,Update模式显著提升了测试的维护效率。
下面我们用一个示例来直观地感受一下这种测试管理方式。假设我们有一个函数 TransformText,它对输入的文本进行某种转换(例如,本例中的转换为大写并添加前缀)。下面是该示例的目录结构:
ch25/
└── goldenfiles/
├── transformer.go
├── transformer_test.go
└── testdata/
├── case1_input.txt
├── case1_output.golden
├── case2_input.txt
└── case2_output.golden
被测函数代码如下:
// ch25/goldenfiles/transformer.go
package goldenfiles
import (
"fmt"
"strings"
)
// TransformText applies a simple transformation to the input string.
func TransformText(input string) string {
// Example transformation: Convert to uppercase and add a prefix.
// In a real scenario, this could be much more complex.
transformed := strings.ToUpper(input)
return fmt.Sprintf("TRANSFORMED: %s", transformed)
}
testdata目录下的初始文件内容:
ch25/goldenfiles/testdata/case1_input.txt:
Hello World
ch25/goldenfiles/testdata/case2_input.txt:
Go Testing is Fun!
测试代码如下:
package goldenfiles
import (
"flag" // To define the -update flag
"os"
"path/filepath"
"strings"
"testing"
"github.com/google/go-cmp/cmp" // For better diffs
)
var update = flag.Bool("update", false, "Update golden files with actual output.")
// TestMain can be used to parse flags.
func TestMain(m *testing.M) {
flag.Parse()
code := m.Run()
os.Exit(code)
}
func TestTransformText_Golden(t *testing.T) {
testCases := []struct {
name string
inputFile string // Relative to testdata/
// Golden file will be inputFile with .golden suffix
}{
{name: "Case1_HelloWorld", inputFile: "case1_input.txt"},
{name: "Case2_GoTesting", inputFile: "case2_input.txt"},
{name: "Case3_EmptyInput", inputFile: "case3_empty_input.txt"}, // Expects an empty input file
{name: "Case4_SpecialChars", inputFile: "case4_special_input.txt"},
}
// Create dummy input files for Case3 and Case4 if they don't exist
// This is just for the example to be self-contained for generation.
// In a real scenario, these files would already exist with meaningful content.
os.MkdirAll(filepath.Join("testdata"), 0755)
os.WriteFile(filepath.Join("testdata", "case3_empty_input.txt"), []byte(""), 0644)
os.WriteFile(filepath.Join("testdata", "case4_special_input.txt"), []byte("你好, 世界 & < > \" '"), 0644)
for _, tc := range testCases {
currentTC := tc // Capture range variable
t.Run(currentTC.name, func(t *testing.T) {
// t.Parallel() // Golden file tests often modify files, so parallelism needs care
inputPath := filepath.Join("testdata", currentTC.inputFile)
// Golden file path is derived from input file name
goldenPath := strings.TrimSuffix(inputPath, filepath.Ext(inputPath)) + "_output.golden"
inputBytes, err := os.ReadFile(inputPath)
if err != nil {
t.Fatalf("Failed to read input file %s: %v", inputPath, err)
}
inputContent := string(inputBytes)
actualOutput := TransformText(inputContent)
if *update { // Check if the -update flag is set
// Write the actual output to the golden file
err := os.WriteFile(goldenPath, []byte(actualOutput), 0644)
if err != nil {
t.Fatalf("Failed to update golden file %s: %v", goldenPath, err)
}
t.Logf("Golden file %s updated.", goldenPath)
// After updating, we might want to skip the comparison for this run,
// or we can let it compare to ensure what we wrote is what we get if read back.
// For this example, we'll just log and continue (which means it might PASS if written correctly).
}
// Read the golden file for comparison
expectedOutputBytes, err := os.ReadFile(goldenPath)
if err != nil {
// If golden file doesn't exist and we are not in -update mode, it's an error.
// Or, it could mean this is the first run for a new test case,
// and you might want to automatically create it (similar to -update).
// For strictness, we'll consider it an error here if not in -update mode.
t.Fatalf("Failed to read golden file %s: %v. Run with -args -update to create it.", goldenPath, err)
}
expectedOutput := string(expectedOutputBytes)
// Compare actual output with golden file content
// Using github.com/google/go-cmp/cmp for better diffs
if diff := cmp.Diff(expectedOutput, actualOutput); diff != "" {
t.Errorf("TransformText() output does not match golden file %s. Diff (-golden +actual):\n%s",
goldenPath, diff)
}
})
}
}
要运行上述测试,先要确保 ch25/goldenfiles/testdata/ 目录存在,并已创建 case1_input.txt 和 case2_input.txt(内容如前述)。 case3_empty_input.txt 和 case4_special_input.txt 会由测试代码创建(仅为演示)。
然后,我们在 ch25/goldenfiles/ 目录下,先不带 -update 标志运行测试。如果黄金文件 _output.golden 不存在或内容不匹配,测试会失败:
$go test -v .
=== RUN TestTransformText_Golden
=== RUN TestTransformText_Golden/Case1_HelloWorld
transformer_test.go:77: Failed to read golden file testdata/case1_input_output.golden: open testdata/case1_input_output.golden: no such file or directory. Run with -args -update to create it.
=== RUN TestTransformText_Golden/Case2_GoTesting
transformer_test.go:77: Failed to read golden file testdata/case2_input_output.golden: open testdata/case2_input_output.golden: no such file or directory. Run with -args -update to create it.
=== RUN TestTransformText_Golden/Case3_EmptyInput
transformer_test.go:77: Failed to read golden file testdata/case3_empty_input_output.golden: open testdata/case3_empty_input_output.golden: no such file or directory. Run with -args -update to create it.
=== RUN TestTransformText_Golden/Case4_SpecialChars
transformer_test.go:77: Failed to read golden file testdata/case4_special_input_output.golden: open testdata/case4_special_input_output.golden: no such file or directory. Run with -args -update to create it.
--- FAIL: TestTransformText_Golden (0.00s)
--- FAIL: TestTransformText_Golden/Case1_HelloWorld (0.00s)
--- FAIL: TestTransformText_Golden/Case2_GoTesting (0.00s)
--- FAIL: TestTransformText_Golden/Case3_EmptyInput (0.00s)
--- FAIL: TestTransformText_Golden/Case4_SpecialChars (0.00s)
FAIL
FAIL ch25/goldenfiles 0.022s
FAIL
接下来,我们使用Update模式生成或更新黄金文件:
$go test -v -update
运行后,检查 testdata 目录,你会发现 case1_input_output.golden、 case2_input_output.golden 等文件已被创建或更新。此时,用 git diff testdata/ 来审查这些变更。
再次正常运行测试:
$go test -v
=== RUN TestTransformText_Golden
=== RUN TestTransformText_Golden/Case1_HelloWorld
=== RUN TestTransformText_Golden/Case2_GoTesting
=== RUN TestTransformText_Golden/Case3_EmptyInput
=== RUN TestTransformText_Golden/Case4_SpecialChars
--- PASS: TestTransformText_Golden (0.00s)
--- PASS: TestTransformText_Golden/Case1_HelloWorld (0.00s)
--- PASS: TestTransformText_Golden/Case2_GoTesting (0.00s)
--- PASS: TestTransformText_Golden/Case3_EmptyInput (0.00s)
--- PASS: TestTransformText_Golden/Case4_SpecialChars (0.00s)
PASS
ok ch25/goldenfiles 0.011s
如果黄金文件已正确更新,所有测试现在应该通过。
高级测试数据组织和测试方法
上面这些方法主要关注单个或成对的输入/输出文件。但有时,我们的测试场景可能更为复杂,需要模拟一个包含多个文件和目录的结构,或者用一种更领域特定的语言来描述测试逻辑。
首先来看使用 txtar 组织多文件测试用例。 当你的测试需要模拟一个小型文件系统环境,或者涉及一组相互关联的输入文件和期望的输出文件时(例如,测试一个处理Go模块、编译过程或代码生成任务的工具), golang.org/x/tools/txtar 包提供了一种非常有用的解决方案。
txtar 定义了一种简单的文本归档格式,允许你在一个单一的文本文件中清晰地表示一个包含多个文件的“虚拟”文件树。每个“文件”在 txtar 存档中都有一个文件名标记(如 -- go.mod --)和其对应的内容。这种格式易于人工阅读和编辑,并且在版本控制系统(如Git)中进行差异比较也非常友好。
你的测试代码可以使用 txtar.ParseFile() 或 txtar.Parse() 来解析这些存档文件,然后在内存中访问这些虚拟文件,或者将它们提取到临时的真实文件系统中,以便被测代码能够像处理普通文件一样处理它们。Go命令本身的许多复杂测试就是用 txtar 格式来组织的。对于需要处理文件集合或目录结构的测试场景,txtar 是一种值得考虑的高级数据组织方式。
接着来看测试专用的迷你语言(DSL)/ 脚本化测试。 对于某些特定领域的测试,尤其是当测试用例的描述具有高度的重复模式,或者可以用一套领域特定的指令序列来更自然地表达时,可以考虑设计一种测试专用的迷你语言(DSL)或测试脚本。这些DSL脚本通常存储在普通的文本文件中(例如,放在 testdata 目录下)。
你的测试代码则需要包含一个解析器来读取和理解这些脚本,一个执行引擎来逐条执行脚本中的指令,并验证结果。例如,一个测试CLI工具的脚本可能会包含设置环境变量、执行命令、检查标准输出/标准错误内容、以及验证退出码等指令。
这种方法的核心优势在于,它可以使得测试用例的编写非常简洁、高度可读,并且更贴近业务或被测系统的自然语言描述,从而真正实现“让添加新测试用例变得容易”。对于非程序员(如QA或领域专家)来说,理解甚至编写这种DSL脚本也可能更容易。
go命令本身的测试和go.dev网站的端到端测试有一部分就是通过这种脚本化方式高效组织的。虽然设计和实现一个DSL及其解释器需要一定的初期投入,但对于大型、复杂的测试套件,或者需要大量相似但略有不同的测试场景时,这种投入往往是值得的。社区也有如 rsc.io/script 这样的库可以作为实现此类脚本化测试的起点。
这些更高级的组织和数据管理方式,为我们应对极端复杂的测试场景提供了额外的工具。当然,它们也带来了更高的实现成本,需要根据项目的具体需求和收益进行权衡。
通过灵活运用子测试、表驱动测试,并结合 testdata 目录以及这些扩展的高级测试思路,我们可以构建出结构清晰、层次分明、易于维护和扩展的测试套件。然而,Go的一大特色是并发。如何为我们的并发代码编写可靠的测试,是下一个必须攻克的难关。
小结
这一节课,我们首先快速回顾了Go测试的基础:单元测试、基准测试、示例测试的函数签名约定和 go test 命令的核心用法,为后续的进阶讨论奠定了共同的理解基础。
在测试组织方面,我们重点学习了如何使用子测试(t.Run)来提升测试的粒度、隔离失败并使测试报告更清晰,以及如何结合表驱动测试来实现数据与测试逻辑的有效分离,让添加新测试用例变得简单。我们还探讨了如何利用子测试来规划包内测试的层次布局,并通过 testdata 目录、黄金文件(含Update模式)、txtar 以及领域特定语言(DSL)等高级数据管理和组织技巧来应对复杂测试场景。
下一节课,我们继续讨论并发测试、测试策略,理解测试覆盖率,以及自动化探索。欢迎在留言区分享你的思考和实践经验!我是Tony Bai,我们下节课见。
测试进阶:组织、覆盖、Mock与Fuzzing的最佳实践(下)
你好,我是Tony Bai。
上一节课,我们快速回顾了Go测试的基础,并学习了如何构建清晰、可维护的测试用例集。这一节课,我们继续深入Go测试的进阶技巧与最佳实践。首先,我们来聊聊并发测试。
并发测试:驾驭Go并发代码的质量保障
Go语言以其内建的并发原语(goroutine和channel)著称,这使得编写并发程序相对简单。然而,并发编程本身充满了挑战,并发缺陷(Bugs)往往难以发现、难以复现,并且可能导致如数据竞争、死锁、活锁、资源泄漏等严重后果。如何确保我们的并发代码是正确的呢?为并发代码编写全面、可靠的测试至关重要,这也是Go测试工作中最具挑战性的部分之一。
并发缺陷的主要挑战在于其 非确定性——goroutine的调度顺序和执行时机具有不确定性,同一个测试在不同运行中可能产生不同的交错执行序列,导致并发Bug时而出现、时而消失,这使得它们 难以复现 和 难以观察。
传统的并发测试方法往往依赖于运气(希望随机调度能暴露问题)、大量的重复执行(如go test -count=1000),或者通过time.Sleep来尝试控制时序(这通常是不可靠的)。虽然Go工具链提供了一些有力的帮助,但社区一直在探索更有效的并发测试手段。
下面我们先来回顾一下传统并发测试手段以及它们的局限。
传统并发测试手段及其局限
在深入探讨Go最新的并发测试特性之前,我们先回顾一下已有的、开发者常用的几种方法及其局限性。
方法一:利用t.Parallel()尝试暴露问题。
我们知道t.Parallel()用于并行化独立的测试用例以加速整体测试执行。虽然它不是专门为测试并发代码的正确性而设计的,但通过同时运行多个测试(如果这些测试间接或直接地调用了共享的并发代码),有时确实能增加并发冲突发生的概率,从而帮助暴露一些潜在的并发问题,尤其是与-race标志结合使用时。
但必须明确,t.Parallel()本身并不能保证发现并发Bug,它只是改变了测试用例的执行方式。 如果测试用例本身没有精心设计来触发特定的并发场景,或者被测的并发逻辑的缺陷不依赖于这种测试用例级别的并行,那么t.Parallel()可能收效甚微。
方法二:数据竞争检测(go test -race)。
这是Go并发测试的“守护神”。通过在go test命令后添加-race标志,可以启用Go内置的数据竞争检测器。Go编译器会在代码中插入额外的检测指令,在运行时监控对共享内存的访问。如果检测到两个或多个goroutine在没有适当同步(如互斥锁)的情况下同时访问(且至少一个是写操作)同一内存位置,它会报告一个数据竞争。竞争检测器的报告会详细指出发生竞争的goroutine、代码位置及相关的内存访问信息,为定位问题提供了直接线索。下面是一个利用数据竞争检测找到代码并发问题的示例:
// ch25/concurrency/race/race_condition_test.go
package concurrency
import (
"sync"
"testing"
)
var counter int // Shared variable that will cause a data race
// incrementCounter increments the global counter. This is not safe for concurrent use.
func incrementCounter(wg *sync.WaitGroup) {
defer wg.Done()
// This line is the source of the data race when called concurrently:
counter++
}
// TestDataRace demonstrates a data race condition.
// Run with go test -race -run TestDataRace to detect it.
func TestDataRace(t *testing.T) {
var wg sync.WaitGroup
numGoroutines := 100
counter = 0 // Reset counter for each test run
wg.Add(numGoroutines)
for i := 0; i < numGoroutines; i++ {
go incrementCounter(&wg)
}
wg.Wait() // Wait for all goroutines to complete
t.Logf("Counter value after concurrent increments (non-deterministic due to race): %d", counter)
if numGoroutines > 0 && counter < 1 { // This condition is arbitrary for demo
// t.Errorf("Counter should be greater than 0 if goroutines ran, but this is not a reliable check without -race.")
}
}
// --- Corrected version with a Mutex to prevent data race ---
var safeCounter int
var mu sync.Mutex // Mutex to protect safeCounter
// incrementSafeCounter increments the global safeCounter using a mutex.
func incrementSafeCounter(wg *sync.WaitGroup) {
defer wg.Done()
mu.Lock() // Acquire lock
safeCounter++
mu.Unlock() // Release lock
}
// TestNoDataRace demonstrates the correct way to handle shared state concurrently.
// Run with go test -race -run TestNoDataRace to verify no race is detected.
func TestNoDataRace(t *testing.T) {
var wg sync.WaitGroup
numGoroutines := 100
safeCounter = 0 // Reset safeCounter
wg.Add(numGoroutines)
for i := 0; i < numGoroutines; i++ {
go incrementSafeCounter(&wg)
}
wg.Wait()
// With the mutex, the final value of safeCounter should be deterministic.
if safeCounter != numGoroutines {
t.Errorf("Expected safeCounter to be %d, got %d", numGoroutines, safeCounter)
} else {
t.Logf("SafeCounter correctly incremented to: %d", safeCounter)
}
}
针对上述代码,运行 go test -v -race -run TestDataRace 会清晰地报告counter++处的数据竞争:
$go test -v -race -run TestDataRace
=== RUN TestDataRace
==================
WARNING: DATA RACE
Read at 0x00000b12def0 by goroutine 15:
ch25/concurrency/race.incrementCounter()
ch25/concurrency/race/race_condition_test.go:14 +0x78
ch25/concurrency/race.TestDataRace.gowrap1()
ch25/concurrency/race/race_condition_test.go:26 +0x33
Previous write at 0x00000b12def0 by goroutine 59:
ch25/concurrency/race.incrementCounter()
ch25/concurrency/race/race_condition_test.go:14 +0x90
ch25/concurrency/race.TestDataRace.gowrap1()
ch25/concurrency/race/race_condition_test.go:26 +0x33
... ...
==================
race_condition_test.go:34: Counter value after concurrent increments (non-deterministic due to race): 100
testing.go:1490: race detected during execution of test
--- FAIL: TestDataRace (0.02s)
FAIL
exit status 1
FAIL ch25/concurrency/race 0.036s
强烈建议在测试所有并发Go代码时始终启用-race标志,它可以发现许多难以察觉的并发问题,虽然会使测试运行得慢一些并增加内存消耗,但其价值远超这点开销。
不过,虽然-race非常擅长发现数据竞争,但它 不能保证发现所有类型的并发Bug,例如某些逻辑死锁、活锁、或者因不正确的执行顺序导致的逻辑错误(即使这些错误不直接涉及数据竞争)。
由于传统并发测试方法的这些局限性(尤其是对特定goroutine交错顺序的依赖和难以复现问题),Go团队一直在探索更强大、更具确定性的并发测试工具。
testing/synctest:Go并发测试的重量级方案
为了解决传统并发测试的痛点,Go团队在 Go 1.24版本中以实验性特性引入了testing/synctest包(包名和API在正式版中可能微调),并计划在Go 1.25版本中正式发布。这个新包旨在提供一种更系统、更可控的方式来测试并发代码,以实现确定性的并发测试。
synctest包通过创建一个被称为“气泡(bubble)”的隔离执行环境,在这个环境中,goroutine的调度和时间的流逝受到测试框架的控制。这使得测试能够系统地探索并发代码在不同goroutine交错执行(interleavings)下的行为,从而更容易发现和复现那些依赖特定执行顺序的并发Bug。
synctest包的核心功能围绕着两个关键API:synctest.Test和synctest.Wait。
package synctest
import "testing"
func Test(t *testing.T, f func(*testing.T))
func Wait()
首先,synctest.Test(t *testing.T, f func(*testing.T))是启动synctest环境的主要入口。在Go 1.24实验版中此函数曾名为Run,Go 1.25更名为Test,并且函数签名也发生了变化,从func Run(f func())变为func Test(t *testing.T, f func(*testing.T))。
Test函数会在一个新的goroutine中执行传入的函数f。这个新的goroutine以及由它直接或间接启动的所有其他goroutine,都将运行在这个特殊的“气泡”内。这个“气泡”提供了一个隔离的执行环境:它使用合成时间(Synthetic Time),这意味着气泡内的time.Now()返回的是一个受控的假时钟时间,而time.Sleep()则会使当前goroutine阻塞,但只有当整个气泡中的所有goroutine都进入“持久阻塞(durably blocked)”状态时,假时钟才会向前推进,从而使time.Sleep(duration)几乎立即返回并拨快假时钟。尽管synctest不能完全控制每一个指令的执行,但通过Wait()和时间推进机制,它对goroutine的调度顺序施加了显著影响。
值得注意的是,传递给f的*testing.T参数在气泡内有特殊行为:t.Cleanup注册的函数会在气泡内执行,t.Context()返回的上下文的Done通道与气泡关联,但在气泡内调用t.Run创建子测试会导致panic。synctest.Test会一直等待,直到气泡内的所有goroutine都退出后才返回。
其次,synctest.Wait()也是synctest中的一个关键同步原语。当气泡内的一个goroutine调用synctest.Wait()时,它会阻塞,直到气泡内除了它自己之外的所有其他goroutine都进入“持久阻塞”状态。这里,“持久阻塞”特指那些只能被气泡内部的其他事件(如channel操作、sync.Cond.Signal、定时器触发)唤醒的阻塞,例如阻塞在气泡内创建的channel的发送/接收操作、select所有case都是气泡内channel、sync.Cond.Wait以及time.Sleep。与此相对,阻塞在sync.Mutex.Lock()、系统调用、网络I/O或气泡外创建的channel上,则不被视为持久阻塞,因为这些阻塞可能由气泡外部的事件解除。
synctest.Wait()的作用在于,它允许测试代码在启动一些并发操作后暂停执行,等待这些并发操作达到一个“稳定”或“静止”的状态(即所有其他goroutine都阻塞了,等待下一个事件或时间推进),然后再进行断言或执行下一步操作。这有效地消除了对不可靠的time.Sleep的依赖,使得并发测试更加确定和可靠。
下面我们就来看两个使用synctest进行典型并发测试的示例,注意下面示例需要gotip或Go 1.25+版本才能正确运行。
第一个示例展示了如何用synctest测试context.AfterFunc:
// ch25/concurrency/synctest/afterfunc_test.go
package concurrency
import (
"context"
"testing"
"testing/synctest"
)
func TestAfterFuncWithSyncTest(t *testing.T) {
// The testing.T passed to synctest.Test's callback is special.
// We use the outer 't' to call synctest.Test itself.
synctest.Test(t, func(st *testing.T) { // st is the synctest-aware *testing.T
ctx, cancel := context.WithCancel(context.Background())
called := false
context.AfterFunc(ctx, func() {
called = true
})
// Assertion 1: AfterFunc should not have been called yet.
synctest.Wait() // Wait for all goroutines in the bubble to settle.
// The AfterFunc's goroutine is likely blocked waiting for ctx.Done().
if called {
st.Fatal("AfterFunc was called before context was canceled")
}
cancel() // Cancel the context, this should trigger AfterFunc.
// Assertion 2: AfterFunc should now have been called.
synctest.Wait() // Wait again for AfterFunc's goroutine to run and set 'called'.
if !called {
st.Fatal("AfterFunc was not called after context was canceled")
}
st.Log("Test with synctest completed successfully.")
})
}
在这个例子中,测试逻辑被封装在 synctest.Test 的回调中。通过使用 synctest.Wait(),我们避免了容易出错的 time.Sleep() 方法。第一个 Wait() 调用确保在执行 cancel() 之前,AfterFunc 的回调没有机会被执行,因为它在等待 ctx.Done()。这样可以有效避免潜在的竞态条件。
在调用 cancel() 之后,第二个 Wait() 确保 AfterFunc 的回调能够执行。此时,它会因 ctx.Done() 的信号而被唤醒,随后在回调中设置 called=true,使其对应的 goroutine 退出或再次进入阻塞状态。这种设计使得测试既快速又可靠,并且逻辑十分清晰。synctest 内部的假时钟和受控调度机制为这一切提供了必要的保障,从而提高了测试的准确性和稳定性。
我们再来看另外一个测试context.WithTimeout的示例:
// ch25/concurrency/synctest/timeout_test.go
package concurrency
import (
"context"
"testing/synctest"
"testing"
"time"
)
func TestWithTimeoutWithSyncTest(t *testing.T) {
synctest.Test(t , func(st *testing.T) {
// Create a context.Context which is canceled after a timeout.
const timeout = 5 * time.Second
ctx, cancel := context.WithTimeout(context.Background(), timeout)
defer cancel()
// Wait just less than the timeout.
time.Sleep(timeout - time.Nanosecond)
synctest.Wait()
st.Logf("before timeout: ctx.Err() = %v\n", ctx.Err())
// Wait the rest of the way until the timeout.
time.Sleep(time.Nanosecond)
synctest.Wait()
st.Logf("after timeout: ctx.Err() = %v\n", ctx.Err())
})
}
这段Go代码演示了如何使用testing/synctest包来对context.WithTimeout的行为进行确定性的并发测试。传统上,测试context.WithTimeout往往需要依赖真实的 time.Sleep,这会导致测试运行缓慢且可能不稳定(即“flaky test”,因为真实的 time.Sleep 无法保证在并发环境下的精确时序)。synctest通过提供一个受控的“气泡”执行环境,解决了这个问题。
在这个例子中,time.Sleep()在synctest环境中并不会真的暂停那么长时间。相反,它会注册一个定时器,并使当前goroutine持久阻塞。当调用synctest.Wait()并且所有其他goroutine也都持久阻塞时,synctest的调度器会查看是否有待处理的定时器。如果有, 它会将假时钟直接拨到下一个最近的定时器到期时间,并唤醒相应的goroutine(s)。这使得依赖时间的测试可以快速且确定地执行。这个例子中,在Wait函数调用的作用下,第一个time.Sleep将合成时间推进timeout - time.Nanosecond的时长,在这一气泡内的时间点上,上下文的超时时间还差一个纳秒才到,所以ctx应该还没有被取消。
synctest.Wait的第二次调用与第一次调用类似,它再次等待所有其他 goroutine 进入持久阻塞状态。第二个time.Sleep(time.Nanosecond)再次使用synctest的合成时间,这次只推进time.Nanosecond。这使得合成时间恰好达到或超过了timeout的5秒。但这次不同的是,由于前一个 time.Sleep 使得合成时间超过了 5 秒,context.WithTimeout 内部的定时器 goroutine 应该已经从阻塞中被唤醒,并执行了取消 ctx 的操作。这个 synctest.Wait() 确保了 ctx 的取消操作已经完成并传播,使得 ctx.Err() 可以被准确地检查。此时 ctx 已经超时,所以 ctx.Err() 应该返回 context.DeadlineExceeded。
运行上述测试,我们将得到下面的结果:
$gotip test -v
=== RUN TestAfterFuncWithSyncTest
afterfunc_test.go:36: Test with synctest completed successfully.
--- PASS: TestAfterFuncWithSyncTest (0.00s)
=== RUN TestWithTimeoutWithSyncTest
timeout_test.go:20: before timeout: ctx.Err() = <nil>
timeout_test.go:25: after timeout: ctx.Err() = context deadline exceeded
--- PASS: TestWithTimeoutWithSyncTest (0.00s)
PASS
ok demo 0.004s
testing/synctest的核心优势在于其能够提升并发Bug的发现率和复现率,并通过简化并发测试的编写(减少对time.Sleep和复杂手动同步的依赖)增强对并发代码正确性的信心。该包已经确定将在Go 1.25版本(2025年8月份)中正式发布。届时,Go开发者将拥有一个更强大的原生工具来编写更可靠、更易于维护的并发测试。
掌握这些并发测试的工具、技术和策略,是保障Go并发应用质量的关键。接下来,我们将转向另一个常见的测试挑战:如何处理被测代码对外部依赖(如数据库、网络服务)的调用。
测试策略:Fake、Stub、Mock与Testdata的妙用
单元测试的核心在于隔离。我们希望独立地测试一个小的代码单元,而不受其外部依赖的复杂性、不稳定性或副作用的影响。当被测试代码需要与数据库、文件系统、网络服务等交互时,直接在单元测试中使用这些真实依赖通常是不可取的,因为这会使测试变慢、不稳定、难以设置和清理,并可能产生副作用。
为了解决这个问题,我们引入了 测试替身(Test Doubles)。它们是轻量级的、行为受控的对象,在测试中取代真实的依赖组件。
“测试替身”是一个通用术语,泛指所有在测试中用来替代真实依赖对象的对象。常见的类型包括Stubs、Fakes、Mocks、Spies、Dummies等。在本Go进阶课的讲解中,我们主要关注Stubs、Fakes和Mocks,它们能帮助我们有效地隔离被测单元。
Stubs vs. Fakes:提供预设数据与简化实现
Stubs和Fakes这两者都用于替换真实依赖,但它们侧重点有所不同。
Stubs(桩对象)
Stub是一种非常简单的测试替身。它为其所替代的接口方法提供预设的、通常是硬编码的响应。Stub本身通常不包含复杂的逻辑或状态变化,其主要目的是满足被测代码对依赖接口的调用,并返回受控的数据(或错误),以便测试被测代码在接收到这些特定输入时的不同行为路径。
下面是一个典型的使用Stubs对象作为测试替身的示例:
// ch25/doubles/stubs/weather.go (被测系统和依赖接口)
package doubles
import "fmt"
type WeatherProvider interface {
GetTemperature(city string) (int, error)
}
func GetWeatherAdvice(provider WeatherProvider, city string) string {
temp, err := provider.GetTemperature(city)
if err != nil {
return fmt.Sprintf("Sorry, could not get weather for %s: %v", city, err)
}
if temp > 25 {
return fmt.Sprintf("It's hot in %s (%d°C)! Stay hydrated.", city, temp)
} else if temp < 10 {
return fmt.Sprintf("It's cold in %s (%d°C)! Dress warmly.", city, temp)
}
return fmt.Sprintf("The weather in %s is pleasant (%d°C).", city, temp)
}
// ch25/doubles/stubs/weather_test.go
package doubles
import (
"fmt"
"testing"
)
// --- Stub Implementation ---
type WeatherProviderStub struct {
FixedTemperature int
FixedError error
CityCalled string // Optional: to verify if the correct city was passed
}
func (s *WeatherProviderStub) GetTemperature(city string) (int, error) {
s.CityCalled = city // Record the city that was called
return s.FixedTemperature, s.FixedError
}
func TestGetWeatherAdvice_WithStub(t *testing.T) {
t.Run("HotWeather", func(t *testing.T) {
stub := &WeatherProviderStub{FixedTemperature: 30, FixedError: nil}
advice := GetWeatherAdvice(stub, "Dubai")
expected := "It's hot in Dubai (30°C)! Stay hydrated."
if advice != expected {
t.Errorf("Expected '%s', got '%s'", expected, advice)
}
if stub.CityCalled != "Dubai" {
t.Errorf("Expected GetTemperature to be called with 'Dubai', got '%s'", stub.CityCalled)
}
})
t.Run("ProviderError", func(t *testing.T) {
stub := &WeatherProviderStub{FixedError: fmt.Errorf("API quota exceeded")}
advice := GetWeatherAdvice(stub, "London")
expected := "Sorry, could not get weather for London: API quota exceeded"
if advice != expected {
t.Errorf("Expected '%s', got '%s'", expected, advice)
}
})
}
从示例中可以看到, 桩使得GetWeatherAdvice函数的测试完全独立于真实的WeatherProvider实现(例如,不需要网络连接、不需要真实的 API 密钥等)。 通过设置FixedTemperature和FixedError,测试可以精确地控制GetTemperature方法的返回值,从而覆盖GetWeatherAdvice函数在不同输入下的所有逻辑分支(例如,温度过高、温度过低、正常温度、获取失败等)。 并且,桩的实现非常简单,没有外部依赖,因此测试运行速度非常快。
Fakes(伪对象)
Fake对象是测试替身的一种,它提供了一个具有与真实对象相同接口的、 可工作的实现,但这个实现通常比真实对象更简单、更轻量。Fake对象有自己的状态和逻辑,能够模拟真实对象的某些行为,但不适合用于生产环境(例如,它可能使用内存存储代替真实数据库,或者不处理并发、持久化等复杂问题)。
当你的测试需要一个能实际工作的依赖,并且这个依赖的行为(包括状态变化)对被测对象的逻辑有重要影响,但你又不希望引入真实依赖的复杂性、速度慢或不稳定性时,Fake是一个很好的选择。
下面我们也来看一个使用Fakes对象作为替身的示例。假设我们有一个UserNotifier接口,用于发送通知,还有一个UserCreationService依赖它。
// ch25/doubles/fakes/notifier.go
package doubles
import "fmt"
type User struct {
ID string
Email string
Name string
}
type UserNotifier interface {
NotifyUserCreated(user User) error
}
type UserCreationService struct {
notifier UserNotifier
// ... other dependencies like a UserRepository
}
func NewUserCreationService(notifier UserNotifier) *UserCreationService {
return &UserCreationService{notifier: notifier}
}
func (s *UserCreationService) CreateUserAndNotify(id, email, name string) (User, error) {
if email == "" {
return User{}, fmt.Errorf("email cannot be empty")
}
user := User{ID: id, Email: email, Name: name}
// ... logic to save user to a repository ...
fmt.Printf("Service: User %s created.\n", user.ID)
err := s.notifier.NotifyUserCreated(user)
if err != nil {
// Log the notification error but don't fail user creation for this demo
fmt.Printf("Service: Failed to notify user %s creation (non-fatal): %v\n", user.ID, err)
}
return user, nil
}
// ch25/doubles/fakes/notifier_test.go
package doubles
import (
"fmt"
"testing"
)
// --- Fake Notifier Implementation ---
type FakeUserNotifier struct {
NotificationsSent []User // Stores users for whom notifications were "sent"
ShouldFail bool // Control whether NotifyUserCreated should return an error
FailureError error // The error to return if ShouldFail is true
}
func NewFakeUserNotifier() *FakeUserNotifier {
return &FakeUserNotifier{NotificationsSent: []User{}}
}
func (f *FakeUserNotifier) NotifyUserCreated(user User) error {
if f.ShouldFail {
fmt.Printf("[FakeNotifier] Simulating failure for user: %s\n", user.ID)
return f.FailureError
}
fmt.Printf("[FakeNotifier] 'Sent' notification for user: %+v\n", user)
f.NotificationsSent = append(f.NotificationsSent, user)
return nil
}
// Helper to check if a notification was sent for a specific user ID
func (f *FakeUserNotifier) WasNotificationSentFor(userID string) bool {
for _, u := range f.NotificationsSent {
if u.ID == userID {
return true
}
}
return false
}
func TestUserCreationService_WithFakeNotifier(t *testing.T) {
t.Run("SuccessfulNotification", func(t *testing.T) {
fakeNotifier := NewFakeUserNotifier()
service := NewUserCreationService(fakeNotifier)
user, err := service.CreateUserAndNotify("u123", "alice@example.com", "Alice")
if err != nil {
t.Fatalf("CreateUserAndNotify failed: %v", err)
}
if !fakeNotifier.WasNotificationSentFor(user.ID) {
t.Errorf("Expected notification to be sent for user %s, but it wasn't.", user.ID)
}
if len(fakeNotifier.NotificationsSent) != 1 {
t.Errorf("Expected 1 notification to be sent, got %d", len(fakeNotifier.NotificationsSent))
}
})
t.Run("FailedNotification", func(t *testing.T) {
fakeNotifier := NewFakeUserNotifier()
fakeNotifier.ShouldFail = true
fakeNotifier.FailureError = fmt.Errorf("simulated network error")
service := NewUserCreationService(fakeNotifier)
user, err := service.CreateUserAndNotify("u456", "bob@example.com", "Bob")
if err != nil {
// Assuming CreateUserAndNotify itself doesn't fail on notification error for this demo
t.Fatalf("CreateUserAndNotify unexpectedly failed itself: %v", err)
}
// Check that notification was attempted but no successful notification recorded
if fakeNotifier.WasNotificationSentFor(user.ID) {
t.Errorf("Notification for user %s should have failed, but fake shows it as sent.", user.ID)
}
if len(fakeNotifier.NotificationsSent) != 0 {
t.Errorf("Expected 0 successful notifications, got %d", len(fakeNotifier.NotificationsSent))
}
// In a real test, you might also check logs or other side effects of a failed notification attempt.
})
}
从上面示例中我们看到,伪对象比桩更“智能”一些。与桩通常只返回预设值不同,伪对象提供了更接近真实依赖项的功能性实现,尽管这个实现是简化的。例如,FakeUserNotifier 不仅返回错误或成功,它还会“记录”成功发送的通知。
伪对象可以模拟依赖项的更复杂行为和状态变化,例如本例中记录发送历史,或者模拟一些内部逻辑。 由于伪对象具有一些内部状态(如 NotificationsSent 列表),测试可以检查这些状态来验证被测单元与依赖项交互后产生的副作用。
与桩类似,伪对象也实现了测试隔离,避免了对外部资源的真实依赖。
伪对象在内存中运行速度快,并且其行为完全由测试代码控制,因此也具有高度的可预测性。
Mocks:关注交互,验证行为
Mock对象是一种特殊的测试替身,它不仅能像Stub一样提供对方法调用的响应,更重要的是,它能 验证被测试代码是否以预期的方式与其依赖进行了交互。你可以为Mock对象的方法预设期望的调用(包括期望被调用的次数、期望接收的参数等),并在测试结束后断言这些期望是否都已满足。
当你的测试重点在于验证被测试代码与依赖之间的交互协议是否正确时,Mock非常有用。例如:
-
验证某个重要的外部方法(如支付、发送邮件)是否被调用了恰好一次,并且参数正确。
-
验证在特定条件下,某个依赖的方法是否根本不应该被调用。
-
验证一系列依赖调用的顺序是否符合预期。
在Go中,Mock对象的实现方式主要有两种,一种是 手动编写Mock,你可以手动为一个接口编写Mock实现。这个Mock结构体通常会包含字段来记录方法被调用的次数、接收到的参数,以及预设的返回值和错误。当然最常用的还是第二种,即 使用Mock生成工具,手动编写Mock比较繁琐且容易出错。Go社区提供了优秀的Mock生成工具,下面是使用较多的两个:
-
golang/mock/gomock:由Go团队维护的官方Mock框架。你需要先定义接口,然后使用mockgen工具根据接口生成Mock代码。测试时使用gomock.Controller和EXPECT()方法来设置期望。
-
stretchr/testify/mock:testify测试工具套件中的一部分。它允许你通过内嵌mock.Mock结构体并为接口方法编写Mock实现(通常只需调用m.Called(args…)并处理其返回值)来创建Mock对象。测试时使用mockObj.On(“MethodName”, args…).Return(retArgs…)来设置期望。
下面我们来看一个使用 stretchr/testify/mock实现基于Mock对象作为测试替身的示例。假设我们有一个AuditService接口,用于记录重要操作。一些重要的操作服务依赖该接口,我们要对这些服务进行测试。
// ch25/doubles/mocks/audit.go
package doubles
import "fmt"
type AuditEvent struct {
Action string
UserID string
Details map[string]interface{}
}
type AuditService interface {
RecordEvent(event AuditEvent) error
}
type ImportantOperationService struct {
audit AuditService
}
func NewImportantOperationService(audit AuditService) *ImportantOperationService {
return &ImportantOperationService{audit: audit}
}
func (s *ImportantOperationService) PerformImportantAction(userID string, data string) error {
fmt.Printf("[ImportantOperationService] Performing action for user %s with data: %s\n", userID, data)
// ... perform the actual important operation ...
event := AuditEvent{
Action: "IMPORTANT_ACTION_PERFORMED",
UserID: userID,
Details: map[string]interface{}{"input_data": data, "status": "success"},
}
// We expect this audit event to be recorded.
if err := s.audit.RecordEvent(event); err != nil {
// Log failure to audit but operation itself might still be considered successful
fmt.Printf("[ImportantOperationService] WARN: Failed to record audit event: %v\n", err)
// Depending on requirements, this might or might not be a fatal error for the operation.
// For this demo, we assume it's not fatal for PerformImportantAction itself.
}
return nil
}
// ch25/doubles/mocks/audit_test.go
package doubles
import (
"fmt"
"testing"
"github.com/stretchr/testify/assert" // For assertions
"github.com/stretchr/testify/mock" // For mocking
)
// --- Mock AuditService Implementation ---
type MockAuditService struct {
mock.Mock // Embed mock.Mock
}
// RecordEvent is the mock implementation of the AuditService interface method.
func (m *MockAuditService) RecordEvent(event AuditEvent) error {
// This method records that a call was made and with what arguments.
// It will also return an error if one was specified with .Return().
args := m.Called(event)
return args.Error(0) // Return the first (and only, in this case) error argument
}
func TestImportantOperationService_WithMockAudit(t *testing.T) {
t.Run("SuccessfulOperationAndAudit", func(t *testing.T) {
// 1. Create an instance of the mock object.
mockAudit := new(MockAuditService)
// 2. Setup expectations on the mock.
// We expect RecordEvent to be called once with a specific AuditEvent structure.
// We use mock.MatchedBy to perform a custom match on the AuditEvent argument.
expectedUserID := "user789"
expectedData := "sensitive_data_processed"
mockAudit.On("RecordEvent", mock.MatchedBy(func(event AuditEvent) bool {
return event.Action == "IMPORTANT_ACTION_PERFORMED" &&
event.UserID == expectedUserID &&
event.Details["input_data"] == expectedData &&
event.Details["status"] == "success"
})).Return(nil).Once() // Expect it to be called once and return no error.
// 3. Create the service instance, injecting the mock.
service := NewImportantOperationService(mockAudit)
// 4. Call the method on the service that should trigger the mock's method.
err := service.PerformImportantAction(expectedUserID, expectedData)
assert.NoError(t, err, "PerformImportantAction should not return an error")
// 5. Assert that all expectations on the mock were met.
mockAudit.AssertExpectations(t)
})
t.Run("OperationSucceedsButAuditFails", func(t *testing.T) {
mockAudit := new(MockAuditService)
simulatedAuditError := fmt.Errorf("audit system unavailable")
// Expect RecordEvent to be called, but this time it will return an error.
mockAudit.On("RecordEvent", mock.AnythingOfType("AuditEvent")).Return(simulatedAuditError).Once()
service := NewImportantOperationService(mockAudit)
err := service.PerformImportantAction("userFail", "dataFail")
// In our SUT, PerformImportantAction logs the audit error but doesn't propagate it.
assert.NoError(t, err, "PerformImportantAction should still succeed even if auditing fails (per demo SUT logic)")
mockAudit.AssertExpectations(t)
})
}
这段示例展示了如何使用模拟对象辅助进行单元测试。模拟对象是测试替身的一种,它不仅像桩和伪对象那样提供预设行为或功能性实现,更重要的是,它允许测试代码验证被测单元是否以预期的方式与依赖项进行了交互。
这个示例使用了stretchr/testify/mock库来生成mock对象,通过mock对象的On().Return()等方法,可以精确地定义依赖项在特定调用下的行为,包括调用了哪些方法、调用了多少次、传入了哪些参数、返回值和可能抛出的错误。
何时选择Stub/Fake?何时选择Mock?
选择使用Stub、Fake还是Mock,取决于你的测试目标和被替代依赖的特性:
- 状态验证 vs. 行为验证:
-
如果你主要关心的是 被测试代码在与依赖交互后,其自身的状态或返回值是否正确,那么Stub或Fake通常更合适。它们帮助你控制依赖的输出,从而验证被测代码的逻辑分支。
-
如果你主要关心的是 被测试代码是否以预期的方式调用了其依赖的方法(例如,调用了正确的次数、传入了正确的参数、或者在特定条件下根本没有调用),那么Mock是更好的选择,它侧重于验证交互的“契约”。
-
- 依赖的复杂度与可替代性:
-
如果依赖的接口非常简单,并且很容易就能编写一个轻量级的、能返回所需数据的Stub,或者一个能模拟基本行为的Fake,那么这通常是首选。Fake让测试更接近真实的集成场景(尽管是简化的),测试代码也往往更易读,因为它关注的是结果而非调用细节。人工智能辅助编码这些年的发展,也让实现一个Fake对象变得十分容易。
-
如果依赖的接口非常复杂,或者其真实行为难以模拟(例如,一个复杂的第三方API客户端),而你只关心被测代码是否正确地调用了该接口的某几个关键方法,那么使用Mock可以让你精确地指定和验证这些交互点,而无需实现整个复杂依赖的Fake。
-
- 避免过度使用Mock:
-
过度依赖Mock,尤其是对几乎所有外部依赖都使用Mock,并且在Mock中详细指定了所有交互细节,可能导致测试与被测代码的 实现细节过度耦合。这意味着,如果将来你重构了被测代码的内部实现(即使其外部行为和API保持不变),很多Mock基础的测试也可能失败,增加了维护成本。
-
经验法则:优先测试组件的公开API和可见行为,而不是其内部实现细节。 尽量使用Fake或真实的(如果可行且轻量)依赖来驱动被测对象的行为,并断言其最终状态或输出。只有当你确实需要验证与某个难以控制或观察的依赖之间的特定交互时,才考虑使用Mock。
-
测试应该关注“做什么”(what),而不是“怎么做”(how)。Fakes和Stubs帮助我们验证“做什么”的结果,而Mocks则更偏向于验证“怎么做”的过程。
-
通过明智地选择和使用测试替身(Stubs、Fakes、Mocks)以及有效地管理测试数据(如使用testdata目录),我们可以编写出既隔离、快速,又能有效验证代码单元逻辑正确性的单元测试。这些策略极大地提升了我们处理外部依赖的能力,使得单元测试的覆盖范围和深度得以扩展。
然而,当我们编写了大量的测试用例,覆盖了各种功能点和边界条件后,一个自然而然的问题就浮现出来:我们如何衡量我们的测试到底做得怎么样?我们的测试是否已经足够充分? 这就引出了一个在软件测试领域广泛讨论和使用的指标——测试覆盖率。
衡量效果:理解测试覆盖率的意义与局限
代码覆盖率(Code Coverage)是衡量测试充分性的一个常用指标。它表示在运行测试套件时,被测源代码中有多大比例的代码行(或语句、分支、函数等)至少被执行过一次。Go语言内置了强大的覆盖率分析工具。不过,测试覆盖率达到100%就意味着代码完美无缺吗?在这一节中,我们就来探讨一下Go测试覆盖率工具的使用方法、覆盖率的局限以及如何正确看待和使用覆盖率这个指标。
如何生成和查看覆盖率报告
go test内置对覆盖率报告生成和查看的支持有以下几种。
首先是生成覆盖率数据。
$go test -cover # 在测试结果末尾打印当前包的覆盖率百分比
$go test -coverprofile=coverage.out # 将覆盖率数据输出到 coverage.out 文件
我们可以对单个包或整个项目(如 go test ./… -coverprofile=coverage.out)生成覆盖率。
其次是查看覆盖率报告。 我们通过go tool cover命令可以查看go test命令生成的覆盖率报告。如果要查询函数级别覆盖率,可以使用下面命令:
$go tool cover -func=coverage.out
其输出示例如下:
ch25/basics/calc.go:4: Add 100.0%
ch25/doubles/stubs/weather.go:9: GetWeatherAdvice 83.3%
total: (statements) 90.5%
测试覆盖率报告也支持HTML的可视化格式:
$go tool cover -html=coverage.out -o coverage.html
这会生成一个 coverage.html 文件,用浏览器打开后,可以清晰地看到源代码中哪些行被覆盖(通常绿色),哪些未被覆盖(通常红色),哪些部分覆盖。
测试覆盖率的真正意义
它衡量的是“执行过”,而非“验证过”:覆盖率工具只能告诉你哪些代码行在测试过程中被执行了,并不能判断这些代码行的逻辑是否被充分、正确地验证了。一行代码可能被执行了,但相关的断言可能是缺失的或错误的。
高覆盖率是必要条件,但不是充分条件:
-
必要性:低覆盖率(例如,低于70-80%)通常明确地指示测试不充分,有大量代码未经任何测试执行,存在潜在的Bug风险。追求一个合理的高覆盖率(例如,80-90%以上,具体目标因项目和团队而异)是应该的,它可以驱动我们思考如何测试到那些被遗漏的分支和逻辑。
-
非充分性:即使达到100%的语句覆盖率,也 绝不意味着代码是无懈可击的。
覆盖率的局限性与误区
首先,100%覆盖率的陷阱:
-
逻辑错误:覆盖率无法发现代码中的逻辑错误。如果代码的逻辑本身就是错的,即使100%覆盖,错误依然存在。
-
边界条件遗漏:测试可能覆盖了主要路径,但遗漏了关键的边界值、nil输入、空集合、超大数据等可能引发问题的场景。
-
并发问题:语句覆盖率通常无法揭示数据竞争、死锁等并发缺陷。这些需要专门的并发测试策略和 -race 检测器。
-
性能问题、安全漏洞、可用性问题等 也无法通过简单的代码覆盖率来衡量。
-
依赖外部系统的交互:如果对外部依赖使用了Mock,Mock本身的代码会被覆盖,但与真实外部系统交互的潜在问题(如API变更、网络问题)则无法通过单元测试覆盖率反映。
其次,只追求数字的危险。 如果团队将覆盖率百分比作为唯一的、强制性的KPI,可能会导致开发者为了“刷数据”而编写大量低质量、无实际验证意义的测试(例如,只调用函数,不检查返回值或副作用)。这种测试不仅浪费时间,还会给人一种虚假的安全感。
最后,无法覆盖或难以覆盖的场景:
-
某些极端的错误处理路径(例如,模拟磁盘满、网络完全断开、硬件故障等)在单元测试中可能非常难以或不值得去模拟和覆盖。
-
直接调用 os.Exit() 或 panic 且未被恢复(recover)的代码路径。
-
某些与特定操作系统或环境强相关的代码。
如何科学地看待和使用覆盖率
那么,我们如何科学地看待和使用覆盖率呢?
-
将其作为发现测试盲点的工具,而非最终目标:当覆盖率报告显示某些代码块是红色(未覆盖)时,这应该促使你去分析:为什么这部分代码没有被测试到?是测试用例设计不全,还是这部分代码确实难以通过单元测试覆盖(可能需要集成测试)?或者,这部分代码甚至是“死代码”(dead code)?
-
结合代码审查、逻辑分析和业务场景理解:在评估测试充分性时,不能只看覆盖率数字。需要结合对代码逻辑的理解、对业务需求的掌握,以及通过代码审查来判断测试用例是否覆盖了所有重要的场景、边界条件和潜在的错误路径。
-
关注覆盖率的变化趋势,并设定合理的目标:对于新代码,要求有较高的初始覆盖率。对于遗留代码,逐步提升覆盖率。设定一个团队共同认可的、合理的覆盖率目标(例如,85%),并将其作为质量门禁之一,但不要唯数字论。
-
区分不同类型的覆盖率:除了语句覆盖率,还有分支覆盖率、路径覆盖率等更细致的指标(Go标准工具主要关注语句覆盖率,一些第三方工具可能提供更丰富的分析)。理解这些差异有助于更全面地评估测试。
-
不要为了100%而100%:追求最后几个百分点的覆盖率,其投入产出比可能会非常低。将精力投入到测试那些业务关键、逻辑复杂、易出错的模块上,可能比死磕一些无关紧要的边缘代码覆盖率更有价值。
总之,测试覆盖率是一个有用的工具,但绝不是衡量测试质量的唯一标准,更不是代码质量的等价物。它需要与其他测试实践、代码质量保障手段(如静态分析、代码审查、手动测试等)结合使用,才能发挥其最大价值。
我们已经讨论了如何通过精心设计的单元测试、基准测试、示例测试,以及利用子测试、表驱动、测试替身等技巧来主动验证我们已知的代码路径和逻辑。但是,对于那些我们可能没有预料到的、由复杂输入组合或极端边界条件引发的潜在缺陷,我们还能做些什么呢?能否有一种方法,让程序自动去探索这些未知的“雷区”?
幸运的是,Go语言为我们提供了一种强大的自动化探索技术——Fuzzing(模糊测试)。
自动化探索:利用Fuzzing发现边界缺陷
传统的单元测试依赖于开发者预先设计好的测试用例,这些用例通常覆盖了已知的正常路径、错误路径和一些常见的边界条件。但是,对于复杂的输入空间,开发者很难穷尽所有可能的“刁钻”组合,那些未被预料到的输入往往是隐藏Bug和安全漏洞的温床。
Fuzzing(模糊测试)正是一种旨在解决这个问题的自动化测试技术。
什么是Fuzzing(模糊测试)?
Fuzzing是一种软件测试技术,它通过向被测试程序(通常是某个函数或API)提供大量自动生成的、通常是无效的、非预期的或随机的数据作为输入,然后监控程序的行为,观察是否会发生崩溃(panic)、断言失败、错误、未定义行为(如无限循环、内存损坏)或安全漏洞(如缓冲区溢出)。
Fuzzing测试与普通测试在下面几方面存在显著差异:
-
输入生成:普通测试的输入由开发者预先定义;Fuzzing的输入由Fuzzing引擎自动生成和变异。
-
探索性:普通测试验证已知行为;Fuzzing旨在探索未知行为和发现隐藏缺陷。
-
目标:普通测试通常关注功能正确性;Fuzzing更侧重于健壮性、安全性和发现边缘案例。
可以看到,Fuzzing测试是常规测试的重要补充,Go团队在语言演进过程中十分重视Fuzzing测试技术,早在2015年,Go goroutine调度器的设计者、现Google工程师的 Dmitry Vyukov,就实现了Go语言的首个fuzzing工具 go-fuzz。Go 1.18版本开始,Go更是内置了对Fuzzing的支持。接下来,我们就来看看如何在Go 1.18+中实现对代码的Fuzzing test。
Go 1.18+ 内置Fuzzing支持
从Go 1.18版本开始,Go语言在标准工具链中内置了对Fuzzing的原生支持,这使得在Go项目中应用Fuzzing变得非常方便。
- Fuzz测试函数的签名:一个Fuzz测试目标(Fuzz Target)是一个名为 FuzzXxx 的函数,它接受一个 *testing.F 类型的参数。
go func FuzzMyFunction(f *testing.F) { // ... Fuzzing logic ... }
-
f.Add(args…)添加种子语料(Seed Corpus):种子语料是一些由开发者提供的、合法的、有代表性的输入示例。Fuzzing引擎会以这些种子为基础,通过各种变异策略(如位翻转、删除、插入、拼接等)来生成新的测试输入。提供高质量的种子语料可以显著提高Fuzzing发现Bug的效率。
-
Fuzzing执行体:这是Fuzz测试的核心。fuzzFn是一个回调函数,它会被Fuzzing引擎用不同的输入(包括初始的种子语料和引擎生成的变异输入)反复调用。
-
第一个参数 t *testing.T:与单元测试中的t类似,用于报告失败(如t.Fatal、t.Error)。如果fuzzFn中发生panic,或者调用了t.Fatal,Fuzzing引擎会认为发现了一个“有趣”的输入(crashing input),并将其保存下来。
-
后续参数:这些参数的类型由开发者定义,Fuzzing引擎会尝试为这些类型的参数生成和变异数据。f.Add()提供的种子语料的类型必须与这些参数匹配。
-
f.Fuzz(fuzzFn func(t *testing.T, originalCorpusArgs..., generatedArgs...))
- go test -fuzz=FuzzTargetName 命令的使用:使用此命令来启动对特定Fuzz目标(如FuzzMyFunction)的Fuzzing过程。Fuzzing会持续运行,直到被手动停止(Ctrl+C)、发生崩溃、或者达到某个预设的时间/迭代限制。 当Fuzzing发现导致问题的输入时,它会将这个输入保存到一个名为 testdata/fuzz/FuzzTargetName/<hex_string> 的文件中,并报告失败。开发者随后可以用这个crashing input来编写一个普通的单元测试,以便稳定复现和调试该Bug。
让我们来看一个非常基础的例子,假设我们有一个简单的函数,它尝试解析一个表示年龄的字符串,并期望年龄在合理范围内。
// ch25/fuzzing/simpleparser/parser.go
package simpleparser
import (
"fmt"
"strconv"
)
// ParseAge parses a string into an age (integer).
// It expects the age to be between 0 and 150.
func ParseAge(ageStr string) (int, error) {
if ageStr == "" {
return 0, fmt.Errorf("age string cannot be empty")
}
age, err := strconv.Atoi(ageStr)
if err != nil {
return 0, fmt.Errorf("not a valid integer: %w", err)
}
if age < 0 || age > 150 { // Let's introduce a potential bug for "> 150" for fuzzing to find
// if age < 0 || age >= 150 { // Corrected logic for ">="
return 0, fmt.Errorf("age %d out of reasonable range (0-149)", age)
}
return age, nil
}
注意:上面的代码中,我们故意在年龄上限的判断上留了一个小问题(age > 150 而不是 age >= 150 或者 age > 149),看看Fuzzing能否帮助我们发现相关的边界问题。
下面是针对ParseAge的Fuzz测试代码:
// ch25/fuzzing/simpleparser/parser_fuzz_test.go
package simpleparser
import (
"testing"
"unicode/utf8" // We might check for valid strings if ParseAge expects it
)
func FuzzParseAge(f *testing.F) {
// Add seed corpus: valid ages, edge cases, invalid inputs
f.Add("0")
f.Add("1")
f.Add("149") // Edge case for upper bound (based on "> 150" bug, this is valid)
f.Add("150") // This input should ideally be valid, but might fail due to the bug
f.Add("-1")
f.Add("abc") // Not an integer
f.Add("") // Empty string
f.Add("1000") // Out of range
f.Add(" 77 ") // String with spaces (Atoi handles this)
f.Add("\x80test") // Invalid UTF-8 prefix - strconv.Atoi might handle or error early
// The Fuzzing execution function
f.Fuzz(func(t *testing.T, ageStr string) {
// Call the function being fuzzed
age, err := ParseAge(ageStr)
// Define our expectations / invariants
if err != nil {
t.Logf("ParseAge(%q) returned error: %v (this might be expected for fuzzed inputs)", ageStr, err)
return
}
if age < -1000 || age > 1000 { // Arbitrary broad check for successfully parsed ages
t.Errorf("ParseAge(%q) resulted in an unexpected age %d without error", ageStr, age)
}
if utf8.ValidString(ageStr) {
if age < 0 || age >= 150 {
t.Errorf("Successfully parsed age %d for input %q is out of the *absolute* expected range 0-150", age, ageStr)
}
}
})
}
通过下面命令运行Fuzz测试:
# 确保 Go 版本 >= 1.18,运行5秒,或直到发现问题。可以去掉 -fuzztime 让它持续运行
$go test -fuzz=FuzzParseAge -fuzztime=5s
fuzz: elapsed: 0s, gathering baseline coverage: 0/140 completed
failure while testing seed corpus entry: FuzzParseAge/seed#3
fuzz: elapsed: 0s, gathering baseline coverage: 1/140 completed
--- FAIL: FuzzParseAge (0.03s)
--- FAIL: FuzzParseAge (0.00s)
parser_fuzz_test.go:38: Successfully parsed age 150 for input "150" is out of the *absolute* expected range 0-150
FAIL
exit status 1
FAIL ch25/fuzzing/simpleparser 0.036s
... ...
Fuzzing如何帮助发现问题:
-
Panic发现:如果某个生成的ageStr(例如,一个超长的数字字符串导致strconv.Atoi内部问题,尽管不太可能)导致ParseAge或Atoi发生panic,Fuzzing会捕获它。
-
边界条件与逻辑错误:
-
我们的种子 f.Add(“150”)。ParseAge的逻辑是 if age < 0 || age > 150 { return err }。这意味着输入"150"会被ParseAge认为是合法的(150 > 150 为 false)。
-
在f.Fuzz的逻辑中,如果我们写一个断言,例如,我们期望ParseAge能成功解析0到150(包含150)之间的所有数字字符串。如果ParseAge内部的检查是 age > 150 才会报错,那么当Fuzzing引擎用种子"150"调用时,ParseAge会成功返回150。但如果ParseAge的检查是 age >= 150 就会报错,那么Fuzzing用种子"150"调用时,err会非nil,我们的f.Fuzz逻辑会提前返回。
-
关键在于f.Fuzz内部的断言如何定义“正确性”。如果Fuzzing引擎生成了一个字符串(或我们提供了种子)如 “150”,ParseAge由于Bug age > 150(应该 age >= 150 如果150是上限的话,或者 age > 149 如果149是上限)可能会错误地接受或拒绝它。
-
修正ParseAge的Bug:假设我们希望年龄范围是 0 <= age <= 149。那么ParseAge应为 if age < 0 || age > 149 { err }。
-
此时,种子f.Add(“149”)应该成功。
-
种子f.Add(“150”)应该导致ParseAge返回错误。
-
如果Fuzzing引擎生成的输入(或种子)"150"被ParseAge错误地解析成功了(例如,如果ParseAge的检查是age > 150),而我们的f.Fuzz中的断言是 if age < 0 || age > 149 { t.Error(…) },那么当age是150时,这个断言就会触发,Fuzzing就会报告这个不一致。
-
-
这个简单的例子展示了Fuzzing如何通过自动生成输入并检查不变性(或预期行为)来帮助发现代码中的逻辑缺陷和边界问题。那么如何编写更为有效的Fuzz测试,能帮助开发人员更快找到一些边界条件相关的问题呢?我们接下来继续看。
编写有效的Fuzz测试
首先是选择合适的Fuzz目标函数。 Fuzzing最适合用于测试那些处理外部的、不可信的或复杂格式输入的函数。例如:
-
解析函数(如解析JSON、XML、Protobuf、自定义二进制格式等)。
-
编解码函数。
-
处理用户输入的API端点逻辑(如果能将核心处理逻辑提取出来)。
-
任何接受字节切片、字符串或复杂结构体作为输入的且内部逻辑复杂的函数。而依赖大量外部状态(如数据库)、执行非常慢、或者输入空间过于简单(如简单的算术运算)的函数,可能不是Fuzzing的最佳目标。
其次是提供有意义的种子语料(f.Add)。 种子语料应覆盖一些已知的、合法的,以及可能触发边界条件的输入。例如,对于一个解析器,种子可以包括一些简单的有效输入、空的输入、以及一些结构上略有不同的有效输入。Fuzzing引擎会基于这些种子进行变异。
接着是在Fuzzing执行体(f.Fuzz)中编写清晰的检查逻辑。
-
核心任务:在fuzzFn中,你需要调用被测试的函数,并对其行为进行检查。
-
检查内容:
-
不应Panic:这是Fuzzing最容易发现的问题。如果被测函数因某个输入而panic,Fuzzing引擎会自动捕获并报告。
-
错误处理:如果函数对于无效输入应该返回错误,验证是否返回了错误,并且错误类型或内容是否符合预期。
-
不变性检查(Invariants):检查某些在函数执行前后应该保持不变的属性。例如,如果一个函数对数据进行编码后再解码,结果应该与原始数据相同。
-
行为一致性:例如,用两种不同的方法处理同一个输入,结果应该一致。
-
避免副作用:如果被测函数不应有副作用(如修改全局状态),可以检查这些状态。
-
-
使用t *testing.T的方法(如t.Errorf、t.Fatalf)来报告任何不符合预期的行为。
最后是理解Fuzzing引擎的工作方式。 Go的内置Fuzzing引擎是覆盖率引导(Coverage-guided)的。这意味着它会优先选择那些能够触发新代码路径的输入进行变异和保留,从而更有效地探索代码。
Fuzzing是现代软件测试工具箱中一个越来越重要的组成部分,Go将其集成到标准工具链中,极大地降低了开发者使用这一强大技术的门槛。
小结
这节课,针对Go语言的并发特性,我们深入讨论了并发测试的策略:如何安全地使用t.Parallel()并行化独立测试用例,回顾了在测试中运用sync包和channel进行同步的方法,并再次强调了数据竞争检测器(go test -race)在发现内存访问竞争方面的关键作用。尤为重要的是,我们展望了Go 1.25中计划正式引入的testing/synctest(在Go 1.24中作为实验特性),它旨在通过受控的goroutine调度和合成时间来实现确定性的并发测试,有望彻底改变我们测试复杂并发逻辑的方式。
在处理外部依赖方面,我们详解了测试替身中的Stubs、Fakes与Mocks:理解了Stub主要用于提供预设响应,Fake提供简化的工作实现,而Mock则侧重于验证被测代码与依赖之间的交互行为。我们学习了如何根据测试目标选择合适的测试替身,并结合代码示例(如使用stretchr/testify/mock)进行了演示。
我们还辨证地讨论了测试覆盖率的真正意义及其局限性,强调它是一个发现测试盲点、驱动测试改进的有用工具,但不应被视为衡量测试质量的唯一黄金标准,更不能为了追求100%的数字而牺牲测试的实际价值和可维护性。
最后,我们介绍了Go 1.18版本起内置的强大自动化探索技术——Fuzzing(模糊测试)。我们学习了如何编写Fuzz目标函数(FuzzXxx)、提供种子语料(f.Add),以及Fuzzing引擎如何通过覆盖率引导自动生成和变异输入,来帮助我们发现代码中的边界条件、非预期行为和潜在的安全缺陷。
这两节课,我们从基础回顾到前沿的自动化探索技术,帮助你掌握一系列Go测试的进阶“兵器谱”。将它们熟练运用于你的日常开发中,不仅能帮助你更早、更有效地发现和修复软件缺陷,更能让你对所构建的Go应用的质量和稳定性充满信心。
思考题
-
并发与Mock的结合:假设你有一个需要并发调用某个外部HTTP API(该API有速率限制)的函数。你将如何设计测试来验证你的函数在并发调用时能正确处理API的成功响应、错误响应以及潜在的速率限制(例如,通过模拟API返回HTTP 429 Too Many Requests状态码)?你会用到本讲讨论的哪些测试组织技巧、并发测试原语和Mocking策略?
-
Fuzzing目标选择:在你当前参与的项目中,有哪些函数或模块你认为最适合应用Fuzzing测试?为什么(考虑它们的输入特性和潜在风险)?你会如何为它们设计有代表性的种子语料,以及在Fuzzing执行体中重点检查哪些不变性或属性?
欢迎在留言区分享你的思考和实践经验!我是Tony Bai,我们下节课见。
静态代码分析:在编码阶段发现并修复Go潜在问题
你好,我是Tony Bai。
在前面的课程中,我们已经一起学习了Go语言的项目布局、各种设计原则与模式、并发编程、Web框架应用,以及像配置、日志这样的核心组件构建。通过这些内容的学习,我们已经能够编写出结构清晰、功能完善、易于扩展和维护的Go程序。这些无疑都是构建高质量Go服务的重要基石。
但是,仅仅依靠开发者自身的经验、代码审查和单元测试,就足以保证代码的完美无瑕吗?答案往往是否定的。在复杂的软件项目中,一些潜在的问题,特别是代码风格、编码规范、潜在的安全风险、性能隐患,以及某些微妙的逻辑错误等非功能性问题,可能很难通过这些传统手段完全发现。
为了进一步提升代码质量,防患于未然,我们需要引入自动化的“代码哨兵”——静态代码分析。
静态代码分析(Static Code Analysis)是一种在不实际执行代码的情况下,对源代码进行分析和检查的技术。 它就像一位经验丰富的代码审查员,能够自动扫描你的Go代码,并根据一系列预设的规则和模式,指出其中可能存在的各种问题。这些问题可能小到编码风格的不一致,大到潜在的安全漏洞或严重的逻辑缺陷。
这节课,我们就深入Go工程实践中这一重要环节:
-
理解为何静态分析如此重要,它如何帮助我们在编码阶段“防患于未然”。
-
学习和实践Go生态中主流的静态分析工具,包括Go官方自带的go vet和功能强大的staticcheck,以及集大成的Linter聚合器 golangci-lint,还会简要介绍一些专项检查工具如errcheck和unused。
-
简要展望如何定制自己的代码检查器,以满足团队特定的规范和需求。
通过本节课的学习,你将掌握如何利用这些强大的静态分析工具,将许多潜在问题扼杀在摇篮中,显著提升你的Go代码质量、可读性、可维护性和整体的健壮性。
为何需要静态分析?防患于未然的“代码体检”
在开始使用各种静态分析工具之前,我们首先需要理解它们是什么,能带来什么价值,以及大致是如何工作的。
什么是静态代码分析?
静态代码分析,顾名思义就是在 不实际运行程序 的前提下,对程序的源代码(或者有时是编译后的中间代码)进行自动化的分析和检查。它的目标是通过对代码的词法、语法、语义、控制流、数据流等多个层面进行扫描和推断,来识别其中可能存在的各种缺陷和改进点。
这些潜在问题可以非常广泛,包括但不限于:
-
语法错误和类型错误:虽然Go编译器本身会捕捉这些,但某些静态分析工具可能提供更早或更友好的提示。
-
潜在的逻辑错误:例如,未初始化的变量、空指针解引用风险、不可能的条件判断、资源未释放等。
-
违反编码规范和最佳实践:例如,不一致的命名、过长的函数、过高的复杂度、API的误用等。
-
代码风格问题:例如,不正确的缩进、多余的空格、不规范的注释等(gofmt 主要解决格式化,但静态分析可以检查更广义的风格)。
-
安全漏洞:例如,潜在的SQL注入、跨站脚本(XSS)风险、不安全的并发访问模式等。
-
性能瓶颈:例如,低效的循环、不必要的内存分配、可以优化的算法等。
静态分析工具就像给我们的代码做了一次全面的“体检”,在问题真正引发故障之前就发出预警。
那么,静态分析的核心价值是什么呢?将静态分析融入到我们的开发流程中,可以带来诸多显著的益处:
-
早期发现问题,降低修复成本:这是静态分析最核心的价值。在代码编写阶段或代码提交前就能发现问题,远比在测试阶段、集成阶段甚至生产环境才发现问题要容易修复,成本也低得多。正所谓“防患于未然”。
-
自动化检查,提升效率:静态分析工具可以自动、快速地扫描大量代码,执行许多原本需要人工代码审查才能发现的检查项,从而将宝贵的审查精力解放出来,聚焦于更复杂的业务逻辑和架构设计。
-
提升代码质量的多个维度:
-
规范性与一致性:帮助团队遵循统一的编码规范和最佳实践,使得代码库风格一致,降低新成员的理解成本。
-
可读性与可维护性:通过指出复杂的代码结构、不清晰的命名、冗余的代码等,促进编写更易读、更易维护的代码。
-
健壮性与可靠性:发现潜在的错误、资源泄漏、并发问题等,减少运行时Bug,提升应用的稳定性。
-
安全性:一些专注于安全的静态分析工具(SAST - Static Application Security Testing)能帮助发现常见的安全漏洞。
-
-
促进学习与知识传递:静态分析工具的报告和建议,往往也包含了对某些语言特性或编程模式的正确用法的解释,这对于开发者(尤其是初学者)来说,也是一个很好的学习和提升机会。
尽管静态分析非常强大,但它并非万能的,也存在其固有的局限性:
-
误报(False Positives):有时,静态分析工具可能会报告一些实际上并不是问题的“警告”或“错误”。这可能是因为工具的规则过于通用,或者未能完全理解代码的特定上下文。过多的误报会降低开发者对工具的信任度,甚至导致他们忽略真正的告警。
-
漏报(False Negatives):由于静态分析不执行代码,它无法完全模拟程序在所有可能的运行时环境和输入下的行为。因此,它可能会漏掉一些只有在特定运行时条件下才会暴露的缺陷(尤其是复杂的逻辑错误或并发问题)。
-
不能完全替代动态测试和人工审查:静态分析是代码质量保障体系中的重要一环,但它应该与单元测试、集成测试、人工代码审查等其他手段相辅相成,而不是取代它们。
静态分析是如何工作的?
理解静态分析工具大致是如何工作的,有助于我们更好地使用它们和解读其报告。虽然不同工具的具体实现各异,但其核心原理通常涉及以下几个阶段:
-
词法分析(Lexical Analysis):将源代码文本分解成一系列的“词法单元”(Tokens),例如关键字(
func、if)、标识符(变量名、函数名)、运算符(+、=)、字面量(123、"hello")、标点符号({、})等。 -
语法分析(Syntax Analysis):根据Go语言的语法规则,将词法单元序列转换成一种结构化的表示,最常见的就是抽象语法树(Abstract Syntax Tree,AST)。AST清晰地表达了代码的结构和层次关系。
-
语义分析(Semantic Analysis):在AST的基础上,进行更深层次的检查和信息提取。这可能包括:
-
类型检查:验证类型是否匹配、操作是否合法。
-
作用域分析:确定标识符的定义和引用范围。
-
控制流分析(Control Flow Analysis):构建代码的控制流图(CFG),分析代码块的执行路径和可达性。
-
数据流分析(Data Flow Analysis):分析数据在程序中的传播路径,例如变量的定义-使用链、指针的别名分析、污点数据的追踪(用于安全分析)等。
-
-
模式匹配与规则检查(Pattern Matching & Rule Checking):这是静态分析工具发现问题的核心。工具会根据预定义的规则集(Linter Rules)或启发式模式,在AST、CFG、数据流信息或其他中间表示上进行匹配。如果代码的某个部分匹配了某个“坏味道”模式或违反了某个规则,工具就会报告一个问题。
例如,go vet 在检查printf格式化字符串时,会解析printf调用的AST节点,提取格式化字符串和实际参数,然后比较它们的数量和类型是否匹配。staticcheck 在进行更复杂的分析时,可能会构建更详细的程序表示,并在其上执行数据流分析来发现更微妙的问题。
了解这些基本原理,能帮助我们理解为何静态分析工具有时会产生误报(可能因为其模式匹配不够精确或上下文理解不足),以及为何它们通常对代码风格和常见错误模式非常敏感。
现在,我们已经对静态分析有了初步的认识,接下来将重点介绍Go生态中那些主流的、能帮助我们提升代码质量的静态分析工具。
Go语言主流静态分析工具实践
Go语言生态系统拥有丰富的静态分析工具,从官方内置到社区驱动,它们覆盖了代码质量的方方面面。掌握这些工具的使用,是将静态分析融入日常开发流程的关键。接下来,我就挑选出Go项目中最常用的几个静态分析工具,逐一为你介绍它们的使用和实践方法。
go vet:来自官方的“代码医生”
go vet 是Go语言工具链中内置的一个简单但非常实用的静态分析工具。它的设计目标是检查Go源代码中那些编译器可能不会报错,但却是常见错误或可疑构造的代码。
- 核心检查项举例:go vet 包含了一系列分析器(analyzers),用于检查特定类型的问题。以下是一些常见的检查类别(
go tool vet help可以查看所有支持的分析器及其简要说明)。-
printf格式化:检查
fmt.Printf及其类似函数的格式化字符串与其参数的数量和类型是否匹配。这是go vet最广为人知的功能之一。 -
未使用结果(unusedresult):检查那些返回了
error或其他重要结果但其返回值未被使用的函数调用(例如,调用了fmt.Errorf但未使用其结果)。 -
结构体标签(structtag):检查结构体字段标签的格式是否规范(如
json:"name,omitempty")。 -
循环闭包变量捕获(loopclosure):检查在
for循环中创建的goroutine或defer语句是否正确捕获了循环变量(这是Go中一个常见的坑)。Go 1.23版本修改了for循环变量语义后,这个检查仅对Go 1.23版本之前的代码有效了。 -
context.Context丢失取消(lostcancel):检查当一个函数返回context.Context和context.CancelFunc后,CancelFunc是否被调用。 -
不正确的
errors.As或errors.Is用法(errorsas):检查errors.As的第二个参数是否是指向错误接口或具体错误类型的指针。 -
不安全的
atomic操作(atomic):检查sync/atomic包中函数的参数是否符合对齐要求。 -
HTTP响应体未关闭(
httpresponse):检查http.Get等函数返回的resp.Body是否被正确关闭。 -
还有许多其他检查,例如:
asmdecl(汇编声明)、assign(无用赋值)、bools(布尔表达式简化)、buildtags、cgocall、composites、copylocks、directive、ifaceassert(不可能的接口断言)、nilfunc(nil函数比较)、shift(非法位移)、slog(Go 1.21+log/slog用法检查)、stdmethods(标准方法签名)、testinggoroutine(测试中goroutine误用t)、timeformat(time.Format布局串)、unmarshal(Unmarshal目标类型)、unreachable(不可达代码)、unsafeptr。
-
go vet的用法十分简单,可以直接在你的包路径或文件上运行 go vet:
$go vet ./... # 检查当前目录及其所有子包
$go vet mypkg/main.go mypkg/utils.go # 检查指定文件
go vet 会将发现的问题输出到标准错误。
Go vet的输出通常格式为 filepath:line:column: message。例如:
mypkg/utils.go:42:10: Sprintf call has arguments but no formatting directives
这表示在 mypkg/utils.go 文件的第42行第10列,一个 Sprintf 调用可能存在问题。
我们看一个真实的示例,下面是被go vet进行静态检查的目标Go代码示例( ch25/staticanalysis/vetexamples/main.go 和 vet_test.go):
// ch26/vetexamples/vet_examples.go
package vetexamples
import (
"context"
"fmt"
"sync"
"time"
)
// Example 1: Printf format error
func PrintfError(name string, age int) {
fmt.Printf("Name: %s, Age: %d years, Height: %.2f\n", name, age) // Missing argument for %.2f
}
// Example 2: Loop closure
func LoopClosureProblem() {
var wg sync.WaitGroup
s := []string{"a", "b", "c"}
for _, v := range s { // v is reused in each iteration
wg.Add(1)
go func() { // This goroutine captures the loop variable v by reference
defer wg.Done()
// All goroutines will likely print 'c' because v will be 'c' when they run
fmt.Printf("Loop var (problem): %s\n", v)
}()
}
wg.Wait()
}
func LoopClosureFixed() {
var wg sync.WaitGroup
s := []string{"a", "b", "c"}
for _, v := range s {
v := v // Create a new variable v shadowing the loop variable
wg.Add(1)
go func() {
defer wg.Done()
fmt.Printf("Loop var (fixed): %s\n", v)
}()
}
wg.Wait()
}
// Example 3: Lost cancel
func ProcessWithContext(parentCtx context.Context) context.Context {
newCtx, _ := context.WithTimeout(parentCtx, 5*time.Second)
go func() { // Simulate work that respects cancellation
<-newCtx.Done()
fmt.Println("ProcessWithContext: context done (e.g. timeout or manual cancel)")
}()
// For this example, let's make a clear lost cancel case for go vet to find:
if time.Now().Year() > 2000 { // Dummy condition
_, cancelFuncThatWillBeLost := context.WithCancel(parentCtx)
_ = cancelFuncThatWillBeLost // Suppress unused variable, but vet checks if called.
}
return newCtx // Returning the context, but what about cancel from line 60?
}
// Dummy main for package to be vet-able
func main() {
PrintfError("Alice", 30)
LoopClosureProblem()
LoopClosureFixed()
ctx := context.Background()
derivedCtx := ProcessWithContext(ctx)
_ = derivedCtx
}
运行 go vet,我们将得到下面的输出:
$go vet .
# ch26/vetexamples
./vet_examples.go:24:43: loop variable v captured by func literal
./vet_examples.go:45:10: the cancel function returned by context.WithTimeout should be called, not discarded, to avoid a context leak
./vet_examples.go:12:2: fmt.Printf format %.2f reads arg #3, but call has 2 args
go vet 是一个很好的起点,它轻量、快速,并且能捕捉到许多常见的低级错误。但对于更全面、更深入的静态分析,我们通常需要更强大的工具。
staticcheck:更全面、更深入的静态检查
staticcheck(由Dominik Honnef开发和维护)是一个广受欢迎的、功能极其强大的Go静态分析工具集。它不仅仅是go vet的简单增强,而是包含了一系列独立的检查器,覆盖了代码的正确性、性能、风格简化以及一些可疑模式等多个方面。
相比于 go vet,staticcheck具有如下特点:
-
检查范围更广:staticcheck 包含了 数百个检查规则(分为SA系列-Static Analysis、S系列-Simple、ST系列-Style、QF系列-QuickFix等),远超 go vet。
-
检查更深入:许多检查基于更复杂的程序分析技术(如SSA - Static Single Assignment form),能发现更微妙的问题。
-
错误分类清晰:每个检查都有一个唯一的ID(如
SA5009),方便查阅文档和配置。 -
活跃维护与更新:staticcheck 社区非常活跃,工具和检查规则会随Go语言的发展而持续更新。
staticcheck的安装和使用都非常简单:
$go install honnef.co/go/tools/cmd/staticcheck@latest # 安装最新版
go: downloading honnef.co/go/tools v0.6.1
然后,通过下面命令就可以检查当前目录以及所有子包:
$staticcheck ./...
staticcheck输出格式通常是 filepath:line:column: message (CHECK_ID)。这里我们用staticcheck对上面的go vet示例做一次检查:
// 在ch26/vetexamples目录下
$staticcheck .
vet_examples.go:12:13: Printf format %.2f reads arg #3, but call has only 2 args (SA5009)
vet_examples.go:60:6: func main is unused (U1000)
我们看到staticcheck检出了两个问题,但这比go vet还要少,似乎static check没有其介绍的那么强大。其实,这是因为staticcheck默认检查范围导致的。我们不妨开启更多检查再试一下:
// 在ch26/vetexamples目录下
$staticcheck -checks "all" .
vet_examples.go:1:1: at least one file in a package should have a package comment (ST1000)
vet_examples.go:10:1: comment on exported function PrintfError should be of the form "PrintfError ..." (ST1020)
vet_examples.go:12:13: Printf format %.2f reads arg #3, but call has only 2 args (SA5009)
vet_examples.go:15:1: comment on exported function LoopClosureProblem should be of the form "LoopClosureProblem ..." (ST1020)
vet_examples.go:43:1: comment on exported function ProcessWithContext should be of the form "ProcessWithContext ..." (ST1020)
vet_examples.go:60:6: func main is unused (U1000)
这里,我们用 -checks 标志开启了"all"模式,即运行所有检查,结果即迥然不同了。如果你要排除某个检查,也可以在命令行中体现:
// 在ch26/vetexamples目录下
$staticcheck -checks "all,-U1000,-ST1020" .
vet_examples.go:1:1: at least one file in a package should have a package comment (ST1000)
vet_examples.go:12:13: Printf format %.2f reads arg #3, but call has only 2 args (SA5009)
在这次执行中,我们忽略掉了U1000和ST1020这两项检查。当然你也可以运行特定的检查,就像下面这样:
// 在ch26/vetexamples目录下
$staticcheck -checks "U1000,ST1020" .
vet_examples.go:10:1: comment on exported function PrintfError should be of the form "PrintfError ..." (ST1020)
vet_examples.go:15:1: comment on exported function LoopClosureProblem should be of the form "LoopClosureProblem ..." (ST1020)
vet_examples.go:43:1: comment on exported function ProcessWithContext should be of the form "ProcessWithContext ..." (ST1020)
vet_examples.go:60:6: func main is unused (U1000)
在这次执行中,我们仅让staticcheck进行U1000和ST1020这两项检查。
如果你想开启所有检查,但又想在某些特定代码行或特定文件中忽略特定的检查,可以使用linter directive,staticcheck的linter directive支持行级和文件级:
- 在问题代码行的上一行添加
//lint:ignore CHECK_ID reason来忽略特定检查:
//lint:ignore ST1003 My custom error type doesn't need Error suffix
type MyCustomError struct { msg string }
- 在源文件中添加
//lint:file-ignore CHECK_ID reason来忽略特定检查:
//lint:file-ignore U1000 Ignore all unused code, it's generated
到这里,我们看到staticcheck以其检查的深度和广度以及极强的定制性,成为Go项目中事实上的标准静态分析工具之一。
然而,当我们需要组合多种Linter,并对它们进行统一配置和管理时,golangci-lint就登场了。
golangci-lint:集大成的Linter聚合器
golangci-lint是一个非常流行的Go Linter聚合器。它本身不是一个Linter,而是 集成了大量社区优秀的静态分析工具和Linter(包括go vet、staticcheck、errcheck、unused、gofmt、goimports、misspell等等,总数超过几十个),并提供了统一的命令行接口、配置文件、输出格式以及与CI/CD集成的便利性。
golangci-lint能成为非常流行的Go Linter聚合器与其鲜明的特点不无关系:
-
一站式运行多种检查:无需单独安装和运行每个Linter。
-
高性能:通过并发执行和缓存机制优化了运行速度。
-
高度可配置:可以通过YAML配置文件(通常是
.golangci.yml或.golangci.yaml)精确控制启用哪些Linters、禁用哪些检查、为特定Linter设置参数、排除特定文件或目录等。 -
与CI/CD集成友好:输出格式多样(文本、JSON、Checkstyle等),易于集成到GitHub Actions、GitLab CI、Jenkins等流水线中。
-
支持自动修复(
--fix):对于某些Linter(如格式化、imports、一些简单的代码简化),可以尝试自动修复发现的问题。
这里推荐采用官方的安装方式安装golangci-lint:
# binary will be $(go env GOPATH)/bin/golangci-lint
$curl -sSfL https://raw.githubusercontent.com/golangci/golangci-lint/HEAD/install.sh | sh -s -- -b $(go env GOPATH)/bin v2.1.6
golangci/golangci-lint info checking GitHub for tag 'v2.1.6'
golangci/golangci-lint info found version: 2.1.6 for v2.1.6/darwin/amd64
golangci/golangci-lint info installed /Users/tonybai/Go/bin/golangci-lint
$golangci-lint --version
golangci-lint has version 2.1.6 built with go1.24.2 from eabc2638 on 2025-05-04T15:41:19Z
和govet、staticcheck一样,golangci-lint使用也非常简单,我们还以vet_example.go那个示例为例,使用golangci-lint对其进行一次检查:
$golangci-lint run ./...
vet_examples.go:12:2: printf: fmt.Printf format %.2f reads arg #3, but call has 2 args (govet)
fmt.Printf("Name: %s, Age: %d years, Height: %.2f\n", name, age) // Missing argument for %.2f
^
vet_examples.go:45:10: lostcancel: the cancel function returned by context.WithTimeout should be called, not discarded, to avoid a context leak (govet)
newCtx, _ := context.WithTimeout(parentCtx, 5*time.Second)
^
vet_examples.go:60:6: func main is unused (unused)
func main() {
^
3 issues:
* govet: 2
* unused: 1
我们看到golangci-lint的输出更为详细,不仅输出了问题行代码,还用^符号指出了问题的具体位置。
当然命令行形态的golangci-lint还支持问题修复和指定输出信息到特定格式的文件:
$golangci-lint run --fix ./... # 尝试自动修复
$golangci-lint run --out-format=json ./... > report.json # 输出JSON格式报告
在实际项目中,我们通常会为项目创建一个 .golangci.yml 配置文件,而不是依赖默认设置或纯命令行参数。这使得linting行为可复现、可版本控制,并且易于团队共享。下面是一个 .golangci.yml 配置文件的内容片段:
# .golangci.yml
run:
timeout: 5m
skip-dirs:
- vendor/
- internal/generated/ # Example: skip generated code
skip-files:
- ".*_test.go" # Example: skip linting test files for some linters
# - "zz_generated.*.go"
linters-settings:
govet:
check-shadowing: true # Enable shadowing check
errcheck:
# Report about not checking errors in type assertions: `a, ok := I.(MyType)`
check-type-assertions: true
# Report about not checking errors in blank assignments: `_ = fn()`
check-blank: true
staticcheck:
# Define specific checks or check groups for staticcheck
# For example, enable all 'SA' checks:
checks: ["SA*"]
# Or disable a specific check:
# checks: ["all", "-SA5008"]
gofmt:
simplify: true # Apply `gofmt -s`
goimports:
local-prefixes: github.com/yourorg/yourproject # Your project's local prefixes
misspell:
locale: US
unused: # Settings for 'unused' (which is part of staticcheck suite but can be configured here too)
# Check for unused arguments in functions.
check-exported: false # Set to true to check exported symbols (can be noisy)
linters:
# Disable all linters by default and explicitly enable specific ones
disable-all: true
enable:
- govet
- errcheck
- staticcheck
- unused
- gosimple # Suggests simplifications (part of staticcheck suite)
- structcheck # Finds unused struct fields (part of staticcheck suite)
- varcheck # Finds unused global variables and constants (part of staticcheck suite)
- ineffassign # Detects when assignments to variables are not used
- typecheck # Runs `go type-check` (fast type checking)
- goimports # Sorts imports and adds missing/removes unreferenced ones
- misspell # Corrects commonly misspelled English words in comments and strings
- revive # Fast, configurable, opinionated, extensible linter (replaces golint)
# Add more linters as needed, e.g.:
# - bodyclose # Checks for unclosed HTTP response bodies
# - noctx # Finds functions that should probably take a context.Context
# - gocritic # Opinionated linter with many checks
# - gosec # Go security checker
# - makezero # Finds slice declarations with non-zero length and zero capacity
# - tparallel # Checks for t.Parallel calls in wrong places
# - wastedassign # Finds wasted assignments
# - whitespace # Linter for whitespace
# - unparam # Reports unused function parameters
issues:
exclude-rules:
# Example: exclude a specific error message from a specific linter in a specific path
- path: _test\.go # Regex for file path
linters:
- errcheck # Specific linter
text: "Error return value of .(.*) is not checked" # Regex for error message
# Example: ignore all SA1019 (deprecated) warnings from staticcheck
# - linters: [staticcheck]
# text: "SA1019:"
# output:
# format: colored-line-number # Default and usually good for local use
# print-issued-lines: true
# print-linter-name: true
这个配置文件:
-
设置了运行超时和跳过的目录/文件。
-
为
govet、errcheck、staticcheck、goimports、misspell、unused等Linter进行了具体设置。 -
通过
disable-all: true然后enable列表的方式,明确启用了我们想要的Linters,这通常比默认启用所有然后禁用一部分要更可控。 -
提供了
issues.exclude-rules示例,用于精确忽略某些不想处理的告警。
对于golangci-lint生成的代码静态分析报告,我们需要逐个分析报告的问题,判断是需要修复代码,还是调整配置(例如,忽略特定规则或路径),或者在代码中添加 //nolint:lintername 注释(应谨慎使用,并说明理由)。对于 --fix 选项,建议先在本地试运行并仔细审查其修改,确认无误后再提交。
golangci-lint以其强大的整合能力和高度的可配置性,已成为Go项目静态分析的事实标准工具。
其他专项检查工具
虽然golangci-lint集成了很多Linter,但有时我们可能只需要针对性地运行某个专项检查,或者某些工具可能尚未被golangci-lint完全集成或提供相同的配置粒度。
-
errcheck(github.com/kisielk/errcheck):Go语言通过显式返回error来进行错误处理,但开发者有时可能会忘记检查或处理这些错误,这可能导致程序行为异常或隐藏bug。errcheck就是专门用来发现这类问题的。 -
unused(github.com/dominikh/go-tools/cmd/unused):未使用的变量、常量、函数、类型或结构体字段会增加代码的认知负担和维护成本,还可能掩盖逻辑错误(例如,一个本应被使用的计算结果被意外地赋给了未使用的变量)。unused是专门用来发现此类问题的。 -
gosec(github.com/securego/gosec):专注于Go代码的安全扫描,能发现常见的安全漏洞,如硬编码凭证、不安全的随机数使用、SQL注入风险、路径遍历等。 -
nakedret(github.com/alexkohler/nakedret):检查函数是否使用了裸返回(named return values without explicit return values),这在某些情况下会降低代码可读性。 -
unparam(mvdan.cc/unparam):查找函数中那些总是以相同常量值传递或从未被实际使用的参数。
如何在项目中有效集成静态分析
仅仅知道有哪些工具是不够的,更重要的是将它们有效地融入到日常的开发和协作流程中。这里介绍一下在项目中有效集成静态分析工具的一般步骤。
第一步:从配置开始。 对于像golangci-lint这样的聚合工具,首先要为项目创建一个共享的配置文件(如 .golangci.yml)。在这个文件中,团队共同决定启用哪些Linter、禁用哪些检查、设置哪些参数。这个配置文件应纳入版本控制。
第二步:本地开发环境集成。
-
IDE/编辑器插件:大多数主流的Go IDE(如GoLand)和编辑器(如VS Code配合Go插件)都支持集成golangci-lint或其他Linter,可以在你编写代码时实时或保存时自动进行检查,并直接在编辑器中提示问题。这是最快反馈、最早发现问题的方式。
-
Git Pre-commit Hook:设置一个Git pre-commit钩子,在每次
git commit之前自动运行选定的静态分析检查(通常是快速检查的一部分)。如果检查不通过,则阻止提交。这能确保进入代码库的代码至少满足基本的静态分析要求。
第三步:CI/CD流水线集成,这是最重要的集成点。 在持续集成(CI)服务器上(如GitHub Actions、GitLab CI、Jenkins、Travis CI等),将静态分析(通常是运行golangci-lint)作为构建和测试流程中的一个强制步骤。
-
如果静态分析发现任何问题(例如,
golangci-lint run以非零状态码退出),CI构建应标记为失败,阻止有问题的代码被合并到主分支或部署到生产环境。 -
CI环境中的静态分析报告可以被存档,或输出为特定格式(如JUnit XML、Checkstyle)供其他质量管理工具消费。
第四步:逐步引入,处理存量问题。
-
对于已有大量代码的遗留项目,一次性启用所有严格的Linter规则可能会产生海量的告警,令人望而却步。
-
策略:
-
从小处着手:先启用最核心、误报率最低的Linter和规则(例如,go vet的基本检查,errcheck,unused等)。
-
逐步增加:待团队适应并修复了初期问题后,再逐步启用更严格或更细致的检查(如staticcheck的更多规则,代码复杂度检查等)。
-
关注新代码:golangci-lint支持
--new或--new-from-rev选项,可以只对本次提交或某个Git修订版本之后新增/修改的代码进行检查。这使得在遗留项目中引入静态分析的阻力更小,团队可以先确保新代码符合规范,再逐步清理旧代码的问题。 -
设定基线:对于实在难以立即修复的存量问题,可以在配置文件中通过
issues.exclude-rules或代码内//nolint注释进行临时忽略(务必注明理由和计划),但要避免滥用。
-
第五步:定期审查和调整规则。 静态分析的配置不是一成不变的。随着项目的发展、Go版本的升级、团队规范的演变,应定期回顾和调整启用的Linter和规则,确保它们仍然适用且有效。
通过这些集成方式,静态分析才能真正成为提升代码质量的持续动力,而不是一次性的“运动式”检查。
定制规则:构建自己的代码检查器
通过将这些主流的静态分析工具集成到我们的开发流程中,我们可以极大地提升代码质量,减少潜在的Bug。然而,即便拥有了go vet、staticcheck及golangci-lint这样强大的工具集,它们提供的通用规则有时也可能无法完全覆盖我们团队特定的编码规范、独特的业务约束,或者那些在代码审查中反复出现的、可以通过模式识别的特定问题。
例如,你可能会遇到以下场景:
-
团队约定禁止在项目中使用某个标准库包的特定函数,因为它在你们的上下文中容易被误用。
-
业务逻辑要求某个核心实体在创建后,必须显式调用其
Initialize()方法。 -
代码审查时,经常发现某些类型的错误没有被正确地包装上下文信息。
对于这些高度定制化的需求,依赖通用工具可能力不从心。这时,Go语言为我们提供了更深层次的控制力——允许我们 构建自己的自定义静态代码检查器。
定制检查器的核心价值在于其 针对性 和 自动化:
-
针对性:它能够精确地捕捉到那些通用工具无法识别的、与你的项目特性或团队规范紧密相关的特定问题模式。
-
自动化:将原本需要依赖资深开发者经验、通过人工代码审查反复指出的问题,转化为可自动执行的检查规则。这不仅节省了宝贵的审查时间,更能保证规则在整个代码库中的一致执行。
-
知识沉淀:通过将团队在长期开发中总结出的最佳实践、常见陷阱和特定业务约束固化为可执行的检查规则,这些宝贵的经验得以沉淀和共享,有助于新成员快速融入团队规范,并减少重复犯错的概率。
那么,Go语言为我们提供了哪些基础构件来支持这种自定义静态分析器的开发呢?这就要提到go/analysis包了。
Go分析工具的构建块:go/analysis 包
Go官方提供了一个强大的框架,用于编写模块化的静态代码分析器,它位于 golang.org/x/tools/go/analysis 包(通常简称为 analysis 包)。这个框架使得编写自定义检查器变得相对规范和容易。
analysis 包的核心概念如下:
-
analysis.Analyzer:这是定义一个分析器的核心结构体。它包含了分析器的名称、文档、以及最重要的Run函数(分析逻辑的入口)。它还可以声明对其他分析器结果的依赖。 -
analysis.Pass:当分析器的Run函数被调用时,它会接收一个*analysis.Pass对象作为参数。这个对象封装了当前分析阶段所需的所有信息,例如:-
被分析包的类型信息(
pass.TypesInfo) -
被分析包的抽象语法树(AST)文件列表(
pass.Files) -
报告问题的能力(
pass.Reportf) -
与其他分析器共享数据(
Fact)的能力
-
-
AST(Abstract Syntax Tree):静态分析的核心通常是遍历和检查代码的AST。Go标准库的
go/parser可以将源代码解析成AST,go/ast包定义了AST节点的类型,go/ast/inspect则提供了方便遍历AST节点的工具。 -
类型信息(
go/types):analysis框架会利用go/types包对代码进行完整的类型检查,并将类型信息提供给分析器,这使得分析器可以进行更深入的语义分析。 -
Fact:一种在不同分析器之间或同一分析器对不同包的分析遍之间共享信息的机制。 -
go/analysis框架鼓励编写小而专注的分析器,这些分析器可以组合在一起形成更强大的检查工具(例如,go vet和staticcheck本身就是由许多这样的
Analyzer组成的)。
编写简单分析器的步骤概览与示例
让我们通过一个简单的例子来演示如何编写一个自定义的静态分析器。假设我们想创建一个分析器 checkpubfuncname,用于检查非 main 包中的顶层函数名是否都以大写字母开头(即是否为导出函数)。如果不是,则报告一个问题(这只是一个教学示例,实际中go vet可能已有类似或更复杂的检查)。
1. 定义Analyzer结构体:我们需要创建一个 analysis.Analyzer 实例,并填充其字段。
2. 实现run函数:这是分析器的核心逻辑。它接收一个 *analysis.Pass 对象,我们可以通过它访问AST和类型信息。
3. 遍历AST节点:使用 ast.Inspect 或直接遍历 pass.Files 中的AST节点,找到我们关心的代码模式(这里是函数声明)。
4. 执行检查逻辑:对找到的函数声明,检查其名称。
5. 报告问题:如果发现不符合规则的函数名,使用 pass.Reportf 报告。
下面是该示例的分析器逻辑的代码片段:
// ch26/customanalyzer/checkpubfuncname/analyzer.go
package checkpubfuncname
import (
"go/ast"
"strings"
"unicode"
"golang.org/x/tools/go/analysis"
"golang.org/x/tools/go/analysis/passes/inspect"
"golang.org/x/tools/go/ast/inspector"
)
const Doc = `check for top-level function names that do not start with an uppercase letter (not exported) in non-main packages.
This analyzer helps enforce a convention that all top-level functions in library packages
should be exported if they are intended for external use, or kept unexported (lowercase)
if they are internal helpers. This specific check flags functions that might have been
intended to be package-private but were accidentally named with a non-uppercase first letter,
or vice-versa if the policy was to export all top-level funcs.`
// Analyzer is the instance of our custom analyzer.
var Analyzer = &analysis.Analyzer{
Name: "checkpubfuncname",
Doc: Doc,
Run: run,
Requires: []*analysis.Analyzer{inspect.Analyzer}, // We need the inspector pass
// ResultType: // Not producing any facts or results for other analyzers
// FactTypes: // Not using facts
}
func run(pass *analysis.Pass) (interface{}, error) {
// Skip "main" package, as main.main is an exception, and other funcs might be internal.
// This is a simplistic check; real linters have more sophisticated ways to handle package types.
if pass.Pkg.Name() == "main" {
return nil, nil
}
// Get the inspector. This is provided by the inspect.Analyzer requirement.
inspectResult := pass.ResultOf[inspect.Analyzer].(*inspector.Inspector)
// We are interested in function declarations (ast.FuncDecl)
nodeFilter := []ast.Node{
(*ast.FuncDecl)(nil),
}
inspectResult.Preorder(nodeFilter, func(n ast.Node) {
funcDecl, ok := n.(*ast.FuncDecl)
if !ok {
return
}
// We are interested in top-level functions in the package.
if funcDecl.Recv == nil { // It's a function, not a method
funcName := funcDecl.Name.Name
// Skip special function "init"
if funcName == "init" {
return
}
// Skip test functions (TestXxx, BenchmarkXxx, ExampleXxx)
if strings.HasPrefix(funcName, "Test") ||
strings.HasPrefix(funcName, "Benchmark") ||
strings.HasPrefix(funcName, "Example") {
return
}
if len(funcName) > 0 {
firstChar := rune(funcName[0])
if !unicode.IsUpper(firstChar) {
// This is a top-level function in a non-main package,
// and its name starts with a lowercase letter.
pass.Reportf(funcDecl.Pos(), "top-level function '%s' in package '%s' is not exported (name starts with lowercase)", funcName, pass.Pkg.Name())
}
}
}
})
return nil, nil // No result for other analyzers, no error
}
待检查代码片段:
// ch26/customanalyzer/testpkg/testpkg.go
package testpkg // A library package (not main)
import "fmt"
// This function is correctly exported.
func ExportedFunction() {
fmt.Println("This is an exported function.")
}
// thisFunctionIsUnexported violates our hypothetical rule if we want all top-level funcs exported.
// Or, it's just a note if we only want to list unexported top-level functions.
// For this analyzer, we assume the rule is "top-level functions should be exported".
func thisFunctionIsUnexported() { // Analyzer should flag this
fmt.Println("This function is not exported.")
}
type MyStruct struct{}
// This is a method, should be ignored by our simple check (Recv != nil)
func (s *MyStruct) ExportedMethod() {
fmt.Println("This is an exported method.")
}
func (s *MyStruct) unexportedMethod() {
fmt.Println("This is an unexported method.")
}
// TestHelperFunction is a test helper, should be ignored by our check
func TestHelperFunction() {}
func init() {
fmt.Println("testpkg init")
}
接下来是驱动该独立分析器运行的命令行工具的代码片段:
// ch26/customanalyzer/cmd/checkpubfunc/main.go
package main
import (
"customanalyzer/checkpubfuncname" // Adjust import path to your module
"golang.org/x/tools/go/analysis/singlechecker"
)
func main() {
singlechecker.Main(checkpubfuncname.Analyzer)
}
analysis的 singlechecker 可以方便地将单个Analyzer包装成一个命令行工具。 multichecker 则可以将多个Analyzer组合起来。构建和运行这个命令行工具:
//在ch26/customanalyzer下
$go build customanalyzer/cmd/checkpubfunc
$./checkpubfunc ./testpkg
ch26/customanalyzer/testpkg/testpkg.go:13:1: top-level function 'thisFunctionIsUnexported' in package 'testpkg' is not exported (name starts with lowercase)
我们看到。自定义分析器成功捕捉到被检查代码(testpkg/testpkg.go)中的非导出顶层函数。
我们还可以将自定义分析器集成到golangci-lint中去。golangci-lint支持通过Go插件( .so 文件,有原生plugin包的限制)或作为“私有 Linter”的方式集成自定义分析器。这通常需要更复杂的配置和构建步骤,具体可以参考golangci-lint的文档关于如何添加自定义Linter的部分。
这部分的主要目的是为你打开一扇门,了解Go强大的静态分析框架,并了解构建一个简单自定义检查器的基本流程。虽然深入AST操作和类型系统需要更多的学习,但go/analysis包为我们定制团队或项目特有的代码规范检查提供了可能。对于更复杂的需求,你可以进一步研究该框架的文档和社区中已有的自定义分析器实现。
小结
这节课,我们深入探讨了Go语言中的静态代码分析,这个在编码阶段就能帮助我们“防患于未然”的强大工具。通过学习,我们了解了静态分析如何成为提升代码质量、保障项目健壮性的重要一环。
我们首先理解了静态代码分析的基本概念及其核心价值:它能在不执行代码的前提下,自动发现潜在的错误、不规范的写法、安全隐患和性能问题,从而在开发早期就介入,降低修复成本,提升整体代码质量和团队协作效率。我们也简要了解了其工作原理和局限性。
接着,也是本节课的重点,我们详细学习和实践了Go生态中主流的静态分析工具:
-
官方自带的go vet,它能帮助我们捕捉许多常见的Go编程错误和可疑构造。
-
功能更全面、检查更深入的staticcheck工具集,它覆盖了从代码正确性到性能优化的多个方面。
-
集大成的Linter聚合器golangci-lint,它允许我们方便地一次性运行大量社区优秀的Linter,并通过配置文件进行统一管理,是现代Go项目持续集成的利器。
此外,我们还简要介绍了一些专项检查工具,如专注于错误处理检查的errcheck和发现未使用代码的unused。最重要的是,我们讨论了如何将这些工具有效地集成到日常开发流程中,例如通过IDE插件、Git pre-commit hook以及CI/CD流水线。
最后,我们展望了如何构建自定义的代码检查器。我们理解了当通用工具无法满足团队特定需求时定制规则的必要性,并简要介绍了Go官方提供的go/analysis包作为构建自定义分析器的框架,通过一个简单的示例了解了其基本步骤。
通过有效地运用静态代码分析,我们可以编写出更健壮、更可维护、更符合Go语言最佳实践的代码,为构建高质量的软件系统打下坚实的基础。
思考题
-
工具选择与集成策略:假设你加入了一个新的Go项目,发现该项目之前没有系统地使用任何静态代码分析工具。你会建议团队从哪个(或哪些)工具开始引入?你的引入策略是怎样的(例如,是一次性启用所有推荐规则,还是逐步启用?如何处理初次扫描可能产生的大量历史问题)?你将如何说服团队成员接受并在日常开发中使用这些工具?
-
团队规范的自动化思考:在你当前的团队或你参与过的项目中,是否存在一些反复在代码审查中被指出的、与团队特定编码约定或常见错误模式相关的问题(这些问题可能不被通用Linter覆盖)?请举一个例子。如果让你考虑为此设计一个非常简单的自定义静态检查规则(不要求写代码,只描述思路),你会关注代码的哪些特征或模式?
欢迎你在留言区留下你的思考和答案,也欢迎你把这节课分享给更多对Go语言静态代码分析感兴趣的朋友。我是Tony Bai,我们下节课见。
部署与升级:拥抱云原生,实现Go应用持续交付(上)
你好,我是Tony Bai。
在前面的课程中,我们已经走过了Go项目的设计、编码、测试以及核心组件构建的完整旅程。我们学习了如何编写出结构清晰、功能健壮、质量有保障的Go代码。但仅仅拥有高质量的代码还不够, 如何将我们精心打造的Go应用高效、可靠地部署到生产环境,并在后续快速迭代和需求变更中实现平滑、无缝的升级,是衡量一个项目工程化成熟度的关键标准,也是我们Go工程师在工程实践中必须面对的重要课题。
传统的部署方式,例如手动拷贝二进制文件、逐台服务器配置环境、编写复杂的启停脚本,往往充满了痛点:
-
环境不一致:开发、测试、生产环境的差异可能导致“在我这里明明是好的”这类经典问题。
-
手动操作易错:部署和升级过程涉及大量手动步骤,容易因人为疏忽引入故障。
-
升级过程复杂且风险高:发布新版本时,如何保证服务不中断?如何快速回滚?这些都是棘手的难题。
幸运的是,以容器化(特别是Docker)和容器编排(特别是Kubernetes)为代表的云原生技术栈,为现代应用的部署和升级带来了革命性的变化。它们使得我们可以将Go应用及其依赖打包成轻量、可移植的“集装箱”,并在强大的编排平台上实现自动化部署、弹性伸缩和复杂的发布策略,从而真正拥抱持续交付(Continuous Delivery)。
Go是天然适合云原生的,因为很多云原生基础设施,比如Docker、Kubernetes都是由Go语言打造的。
接下来的两节课,我们将一起探索Go应用在云原生时代的部署与升级之道。这节课,我们先学习如何将Go应用容器化,掌握编写高效、安全的Dockerfile的最佳实践,以及优化Go镜像体积的技巧。接着,我们再了解一个开发阶段的利器——Docker Compose,学习如何用它快速搭建和管理包含多个服务的本地Go应用环境。下节课,我们再入门Kubernetes的核心概念,并深入剖析主流的平滑发布策略。
Go应用的容器化:构建轻量、高效、可移植的“集装箱”
在现代软件开发中,容器化几乎已成为应用交付的标准方式。对于Go应用而言,容器化同样能带来诸多益处:
-
环境一致性:容器将应用及其所有运行时依赖(库、配置文件、环境变量等)打包在一起,形成一个自包含的单元。无论是在开发者的本地机器、测试服务器还是生产集群,这个容器都能以完全相同的方式运行,彻底解决了“环境不一致”的痛点。
-
可移植性:容器镜像可以在任何支持容器运行时的环境(如Docker Desktop、Kubernetes、AWS ECS、Google Cloud Run等)中运行,实现了“一次构建,到处运行”。
-
轻量与高效:相比于虚拟机,容器共享宿主机的操作系统内核,启动更快,资源占用更少。Go语言编译出的静态链接二进制文件本身就很小巧,与容器技术结合更能发挥其轻量高效的优势。
-
易于部署和扩展:容器化的应用更容易通过编排工具(如Kubernetes)进行自动化部署、水平扩展和版本管理。
-
隔离性:容器之间提供了一定程度的隔离(尽管不如虚拟机彻底),有助于应用间的资源管理和安全性。
接下来,我们以目前最流行的容器化技术Docker为例,探讨如何为Go应用构建优秀的容器镜像。
容器化技术概览(以Docker为例)
要理解什么是容器,首先要了解容器与虚拟机(VM)的区别。
虚拟机通过Hypervisor在物理硬件之上虚拟化出一整套独立的操作系统内核和硬件资源,每个虚拟机都运行一个完整的操作系统。这使得虚拟机之间具有良好的隔离性,但同时也带来了较大的资源开销和较慢的启动速度。相比之下,容器则在宿主机操作系统之上,利用操作系统层面的虚拟化技术(例如 Linux 的 Namespaces 和 Cgroups)来创建隔离的运行时环境。容器共享宿主机的内核,只打包应用本身及其所需的依赖库和二进制文件。因此,容器更为轻量级,启动速度更快,并且能够实现更高的资源密度。
Docker 作为容器化技术的代表,其核心概念包括镜像(Image)、容器(Container)和仓库(Repository)。
镜像是一个只读的模板,它包含了运行应用所需的所有文件系统内容,如代码、运行时环境、库、环境变量和配置文件,以及启动应用的指令。镜像采用分层结构,每一层都对应着 Dockerfile 中的一条指令。
容器则是镜像的一个可运行实例。 当一个镜像被启动时,会在其顶层添加一个可写层,从而形成一个容器。可以将镜像理解为面向对象编程中的“类”,而容器则是“对象”,即类的具体实例。也可以将镜像理解为可执行文件,而容器则是基于该可执行文件启动的一个进程。
最后, 仓库是用于存储和分发 Docker 镜像的平台。这些仓库可以是公共的,例如 Docker Hub,也可以是私有的,例如 Harbor、AWS ECR 或 Google GCR,它们方便用户共享和管理自己的镜像。
那么如何将Go应用构建为一个包含了所有运行环境的容器镜像呢?这就需要Dockerfile。下面我们就来看看Go应用的Dockerfile最佳实践。
Go应用的Dockerfile最佳实践
Dockerfile是一个文本文件,它包含了一系列指令,用于指导Docker如何从一个基础镜像开始,一步步构建出我们应用的目标镜像。编写一个优秀的Dockerfile对于构建出体积小、构建速度快、安全性高的Go应用镜像至关重要。下面是一些有关Dockerfile的最佳实践,我们逐一来看一下。
选择合适的基础镜像
基础镜像是我们构建应用镜像的起点。对于Go应用,常见的选择有:
-
scratch:这是一个完全空的镜像,不包含任何文件系统和用户空间工具。如果你的Go应用是静态链接编译的(即不依赖任何外部动态链接库,包括C库如glibc/musl),那么使用scratch作为最终运行阶段的基础镜像,可以构建出体积极致精简(可能只有几MB)的镜像。 -
alpine:一个基于Alpine Linux的非常小巧的Linux发行版镜像(通常只有5MB左右)。它包含了musl libc和一个基本的包管理器(apk),如果你的应用需要一些基础的shell工具或者依赖某些C库但又希望镜像尽可能小,Alpine是一个不错的选择。但要注意musl libc与glibc在某些行为上可能存在的细微差异。 -
distroless(Google’s Distroless Images):这类镜像仅包含应用运行所需的最小依赖(例如,仅包含语言运行时和必要的库,没有shell、包管理器或其他不必要的工具),旨在减小攻击面,提升安全性。Google提供了针对Go的gcr.io/distroless/static(用于静态链接二进制文件)和gcr.io/distroless/base(包含glibc等基础库)等镜像。 -
官方Go语言镜像(如
golang:1.xx-alpine):通常用于构建阶段,它包含了完整的Go SDK和编译环境。不推荐直接将其作为最终的生产镜像,因为它体积较大,包含许多运行时不需要的工具。
有了适合的基础镜像后,接下来,我们就要考虑如何构建一个体积小、启动快的Go应用镜像了。
长期以来,构建轻量级的Go应用镜像一直是一个挑战,开发者们常常需要在镜像体积和启动速度之间进行权衡。传统方法通常需要将整个Go编译环境打包进镜像,导致镜像体积庞大且不够灵活。直到Docker多阶段构建功能的出现,使得这一过程得以简化。
多阶段构建(Multi-stage Builds)
多阶段构建就是我们可以在一个阶段中编译Go应用,然后在下一个阶段中将最终的可执行文件复制到一个更小的基础镜像中,从而显著减小镜像的体积并提升启动速度。 这种方法不仅优化了资源使用,还提高了部署效率,是优化Go镜像体积的核心最佳实践。
多阶段构建允许我们在一个Dockerfile中定义多个构建阶段,每个阶段都可以使用不同的基础镜像。通常,我们会有一个“构建阶段”(builder stage)和一个“运行阶段”(final stage):
-
构建阶段:使用一个包含完整Go编译环境的基础镜像(如
golang:1.21-alpine),在这个阶段复制源代码、下载依赖、编译Go应用生成静态链接的二进制文件。 -
运行阶段:从一个非常轻量级的基础镜像开始(如
scratch或distroless/static),然后只从构建阶段COPY --from=builder编译好的二进制文件以及任何必要的运行时文件(如配置文件模板、TLS证书等,如果有的话)。
这种方式可以确保最终的生产镜像只包含运行应用所必需的最小内容,而不会包含庞大的编译工具链和中间产物,从而大幅减小镜像体积。
除了选择基础镜像以及多阶段构建的实践外,还有一些实践也是非常重要的。我们继续来看几个。
优化镜像层缓存
Docker镜像是分层的,每一条Dockerfile指令都会创建一个新的镜像层。Docker在构建镜像时会尝试复用已有的层来加速构建。为了最大限度地利用层缓存:
-
将不经常变动的指令(如安装基础依赖、设置环境变量)放在Dockerfile的前面。
-
将经常变动的指令(如
COPY . .复制整个项目源代码)放在后面。 -
例如,先
COPY go.mod go.sum ./并运行go mod download,利用Go模块的缓存。然后再COPY . .复制剩余代码并编译。这样,如果只有业务代码变动而依赖未变,go mod download这一层就可以被缓存复用。
非root用户运行
默认情况下,容器内的进程以root用户身份运行,这存在一定的安全风险。最佳实践是创建一个非root用户,并在运行阶段使用 USER 指令切换到该用户来运行应用。
处理静态资源和配置文件
-
如果应用包含静态资源(如HTML模板、JS/CSS文件),可以将它们与编译好的二进制文件一起
COPY到最终镜像中。 -
对于配置文件,一种常见的做法是在镜像中包含一个默认的配置文件或配置文件模板,然后在运行时通过ConfigMap或Secret挂载实际的配置文件来覆盖或填充它。
设置工作目录、暴露端口、定义启动命令
-
WORKDIR /app:设置容器内的工作目录。 -
EXPOSE 8080:声明容器运行时会监听的端口(这只是一个元数据声明,实际端口映射在docker run -p或Kubernetes Service中定义)。 -
CMD ["/app/myapp"]或ENTRYPOINT ["/app/myapp"]:定义容器启动时执行的默认命令。ENTRYPOINT通常用于定义容器的主命令,而CMD可以为其提供默认参数(可以被docker run时覆盖)。对于Go应用,通常直接使用CMD ["/path/to/your/binary", "arg1", "arg2"]或ENTRYPOINT ["/path/to/your/binary"]配合CMD ["arg1", "arg2"]。
示例:一个优化的Go应用Dockerfile
下面我们展示一个包含上述主要最佳实践的Dockerfile样板。假设我们有一个简单的Go Web应用,它是静态链接的,其Dockerfile如下(代码中包含了详尽的注释,这里就不再一一解释了):
# ---- Build Stage ----
# Use an official Go image as a builder.
# Specify the Go version. Alpine versions are smaller.
FROM golang:1.21-alpine AS builder
# Set the Current Working Directory inside the container
WORKDIR /app
# Copy go mod and sum files to leverage Docker cache
COPY go.mod go.sum ./
# Download all dependencies. Dependencies will be cached if the go.mod and go.sum files are not changed.
RUN go mod download && go mod verify
# Copy the source code into the container
COPY . .
# Build the Go app for a static release.
# CGO_ENABLED=0 disables Cgo, producing a static binary (no external C libraries).
# -ldflags="-w -s" strips debugging information, reducing binary size.
# -o /app/myapp specifies the output path for the binary.
RUN CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build -ldflags="-w -s" -o /app/myapp .
# ---- Run Stage ----
# Start from a scratch image for the smallest possible footprint.
FROM scratch
# (Optional) If your app needs CA certificates for HTTPS calls, or timezone data
# COPY --from=builder /etc/ssl/certs/ca-certificates.crt /etc/ssl/certs/
# COPY --from=builder /usr/share/zoneinfo /usr/share/zoneinfo
# Set the Current Working Directory for the runtime container
WORKDIR /app
# Copy the Pre-built binary file from the previous stage.
COPY --from=builder /app/myapp /app/myapp
# (Optional) If you created a non-root user in the builder stage or have a base image with one
# USER nonroot:nonroot
# Expose port 8080 to the outside world
EXPOSE 8080
# Command to run the executable
ENTRYPOINT ["/app/myapp"]
# CMD ["--config=/etc/app/config.yaml"] # Optional default arguments for ENTRYPOINT
Go镜像优化技巧
除了Dockerfile的最佳实践,还有一些额外的技巧可以帮助进一步优化Go应用的容器镜像。
首先是静态链接编译(上面Dockerfile示例中已做)。 通过设置 CGO_ENABLED=0 和合适的GOOS/GOARCH,可以编译出不依赖外部C库的纯静态Go二进制文件。这使得我们可以使用极小的基础镜像(如scratch)。 ldflags "-w -s" 可以去除调试信息和符号表,进一步减小二进制文件体积。
CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build -a -ldflags="-w -s" -o myapp .
# -a 标志强制重新构建所有依赖的包(通常与静态链接一起使用,确保所有部分都是静态的)
其次是使用 .dockerignore 文件。 在项目根目录下创建一个 .dockerignore 文件,列出那些不需要(也不应该)被 COPY 到Docker构建上下文中的文件和目录。这类似于 .gitignore。例如,可以忽略 .git 目录、本地开发环境的配置文件、 *.md 文件、测试文件、临时的构建产物等。这能减小构建上下文的大小,加快 COPY 指令的速度,并避免将敏感或不必要的文件打包到镜像中。
# .dockerignore example
.git
.vscode
*.md
*.test.go
tmp/
bin/
# Any other local dev files or build artifacts not needed in the image
然后是压缩镜像(工具辅助)。 虽然Docker本身会对镜像层进行压缩存储和传输,但有一些工具(如 slim 或 dive)可以帮助你分析镜像内容、找出不必要的膨胀,并通过各种技术(如静态/动态分析、移除不必要的文件、甚至重新构建应用>)来进一步“瘦身”镜像,有时能取得显著的效果。但使用这类工具需要谨慎,并充分测试瘦身后的镜像以确保其功能完好。
最后是扫描镜像安全漏洞。
在构建出镜像后,使用镜像扫描工具(如开源的 Trivy、 Clair 或商业SaaS服务)对其进行安全漏洞扫描,是非常重要的安全实践。这些工具会检查镜像中包含的操作系统包和应用依赖是否存在已知的CVE(Common Vulnerabilities and Exposures)。
通过上述实践和技巧,我们可以为Go应用构建出理想的容器镜像,为后续部署奠定基础。但在进入生产级的Kubernetes编排之前,对于本地开发和测试,我们有一个更轻便的工具——Docker Compose。
开发阶段的利器:Docker Compose简化多服务环境搭建
我们已经学会了如何为Go应用构建优化的Docker镜像,这解决了单个应用的环境一致性和可移植性问题。但是,现代应用往往不是孤立存在的,它们通常需要与数据库(如PostgreSQL、MySQL)、缓存服务(如Redis)、消息队列(如Kafka)等多个后端服务协同工作。
在本地开发或进行集成测试时,如果需要手动逐个启动和配置这些依赖服务,将会非常耗时且容易出错,尤其对于新加入团队的成员来说,搭建一套完整的开发环境可能就需要半天甚至更长时间。
Docker Compose 应运而生,它正是为了解决在 开发和测试阶段 轻松管理多容器应用的痛点而设计的。
Docker Compose是什么?它解决了什么核心问题?
Docker Compose 是一个用于 定义和运行多容器Docker应用 的工具。它的核心价值和解决的主要问题可以归纳为如下几点:
-
一键式环境编排:它允许你通过一个单一的YAML配置文件(通常是
docker-compose.yml或compose.yaml)来描述构成你整个应用所需的所有服务(包括你的Go应用容器、数据库容器、缓存容器等)、它们之间的网络连接、数据卷、端口映射以及启动依赖等。然后,只需一条命令(如docker-compose up),Compose就能为你自动完成所有这些服务的构建(如果需要)、启动和连接。 -
简化本地开发环境搭建:这是Docker Compose最主要的应用场景。开发者不再需要在本地机器上分别安装和配置PostgreSQL、Redis等,只需一个
docker-compose.yml文件和Docker环境,就能快速拉起一套包含所有依赖的、隔离的开发环境。 -
保障开发/测试环境一致性:Compose文件本身可以纳入版本控制,确保团队所有成员以及CI/CD流程中的测试环境所使用的依赖服务版本和基础配置是一致的,大大减少了“在我机器上是好的”这类问题。
-
快速迭代与调试:结合源码卷挂载和热重载工具,可以实现Go应用代码修改后在容器内自动重新编译和运行,提升开发效率。
简单来说,如果Dockerfile是用来定义如何“制造”一个“集装箱”(镜像)的说明书,那么Docker Compose就是用来指挥多个不同的“集装箱”如何在一起协同工作的“港口调度系统”(但主要用于开发和测试的小型“港口”)。它大大降低了在本地处理微服务架构或依赖复杂应用的门槛。
Docker Compose典型用法与关键实践
让我们通过一个典型的场景——一个Go Web应用依赖PostgreSQL数据库——来看看Docker Compose是如何工作的。
首先我们看看Go应用的代码片段:
// ch27/composeapp/app/main.go
package main
import (
"database/sql"
"fmt"
"log"
"net/http"
"os"
"time"
_ "github.com/lib/pq" // PostgreSQL driver
)
func main() {
dbHost := os.Getenv("DB_HOST_APP") // 从环境变量读取
dbPort := os.Getenv("DB_PORT_APP")
dbUser := os.Getenv("DB_USER_APP")
dbPassword := os.Getenv("DB_PASSWORD_APP")
dbName := os.Getenv("DB_NAME_APP")
appPort := os.Getenv("APP_PORT")
if appPort == "" {
appPort = "8080"
}
psqlInfo := fmt.Sprintf("host=%s port=%s user=%s password=%s dbname=%s sslmode=disable",
dbHost, dbPort, dbUser, dbPassword, dbName)
var db *sql.DB
var err error
// Retry logic for DB connection
for i := 0; i < 5; i++ {
db, err = sql.Open("postgres", psqlInfo)
if err == nil {
err = db.Ping()
if err == nil {
log.Println("Successfully connected to PostgreSQL via Docker Compose!")
break
}
}
log.Printf("DB conn attempt %d failed: %v. Retrying in 2s...", i+1, err)
time.Sleep(2 * time.Second)
}
if err != nil {
log.Fatalf("Could not connect to DB: %v", err)
}
defer db.Close()
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hello from Go App! DB Host from env: %s\n", dbHost)
// ... (可以加一个简单的DB查询)
})
log.Printf("Go app listening on port %s...", appPort)
http.ListenAndServe(":"+appPort, nil)
}
下面是基于多阶段构建的Dockerfile的内容:
# ch27/composeapp/app/Dockerfile
FROM golang:1.21-alpine AS builder
WORKDIR /app
COPY go.mod go.sum ./
RUN go mod download
COPY . .
RUN go build -o /app/main .
FROM alpine:latest
WORKDIR /app
COPY --from=builder /app/main /app/main
RUN chmod +x /app/main
# COPY config.yaml /app/config.yaml # 如果有配置文件也可以拷贝
EXPOSE 8080
CMD ["/app/main"]
最后则是用于启动应用调试环境的docker-compose.yml文件:
# ch27/composeapp/docker-compose.yml
version: '3.8' # Or a newer compatible version
services:
# Go Application Service
go-app:
build:
context: ./app # 指向Go应用代码和Dockerfile的目录
dockerfile: Dockerfile
container_name: my_go_app_dev
ports:
- "8080:8080" # 将主机的8080端口映射到容器的8080端口
# volumes:
# - ./app:/app # 关键:将本地Go源码目录挂载到容器的/app目录
# 这样本地代码修改后,如果配合热重载工具(如air),容器内应用能自动重启
environment: # 通过环境变量传递配置给Go应用
- APP_PORT=8080
- DB_HOST_APP=postgres-db # 使用postgres-db服务名作为主机名
- DB_PORT_APP=5432
- DB_USER_APP=devuser
- DB_PASSWORD_APP=devpass
- DB_NAME_APP=devdb
depends_on: # 确保postgres-db服务先于go-app启动
postgres-db:
condition: service_healthy # 更可靠的依赖:等待DB健康检查通过
networks:
- app-net
# PostgreSQL Database Service
postgres-db:
image: postgres:15-alpine
container_name: my_postgres_dev
environment:
- POSTGRES_USER=devuser
- POSTGRES_PASSWORD=devpass
- POSTGRES_DB=devdb
volumes:
- postgres_dev_data:/var/lib/postgresql/data # 使用命名卷持久化数据
ports: # 可选:如果需要从主机直接访问DB调试
- "5433:5432" # 主机5433映射到容器5432
networks:
- app-net
healthcheck: # 确保数据库真正可用
test: ["CMD-SHELL", "pg_isready -U devuser -d devdb"]
interval: 5s
timeout: 3s
retries: 5
# 定义网络
networks:
app-net:
driver: bridge
# 定义命名卷
volumes:
postgres_dev_data:
我们重点看一下这份docker-compose.yml文件:
-
服务定义(
services):go-app和postgres-db是我们定义的两个服务。 -
服务镜像构建:go-app服务的build下面提供了该服务的源码路径(
./app)与镜像构建文件名(Dockerfile),docker-compose启动服务前会先使用该路径下的Dockerfile构建go-app的镜像。 -
环境变量配置(environment):Go应用所需的数据库连接信息等配置,通过环境变量从Compose文件注入。Go应用内部使用
os.Getenv()读取。 -
服务名解析与网络(
networks、DB_HOST_APP=postgres-db):Compose会自动为在同一个自定义网络(这里是app-net)中的服务创建DNS记录,使得go-app容器可以通过服务名postgres-db直接访问PostgreSQL容器,而无需关心其动态分配的IP地址。 -
启动依赖与健康检查(
depends_on、healthcheck):go-app的depends_on确保postgres-db先启动。更进一步,condition: service_healthy会等待postgres-db的healthcheck通过后,go-app才启动,这比简单等待容器启动更可靠,避免了Go应用启动时DB尚未就绪的问题。 -
数据持久化(
volumes顶层和service内):postgres_dev_data是一个命名卷,用于持久化PostgreSQL的数据。即使postgres-db容器被删除和重新创建,数据也能保留。
docker-compose的使用也非常简单。
然后,在包含 docker-compose.yml 文件的目录( ch27/composeapp/)下,我们可以通过docker-compose完成下面操作:
-
启动所有服务:
docker-compose up(前台运行,看日志)或docker-compose up -d(后台运行) -
查看服务状态:
docker-compose ps -
查看日志:
docker-compose logs go-app(或-f实时跟踪) -
停止并移除所有服务:
docker-compose down(加-v移除命名卷) -
进入容器执行命令:
docker-compose exec go-app sh
Docker Compose通过一个简单的YAML文件,极大地简化了包含多个相互依赖服务的本地开发环境的搭建和管理。它让开发者能够快速启动一个与生产环境服务架构相似(但更轻量)的本地副本,专注于代码编写和调试,而无需深陷复杂的环境配置泥潭。它是从单个Dockerfile到生产级Kubernetes编排之间一个非常实用和高效的过渡工具,尤其适合Go这类编译型语言的快速迭代开发。
到这里,我们的Go应用已经容器化,并且在Docker Compose环境中测试完毕了,能够与依赖服务协同工作了。但是,如何在生产环境中大规模地管理、伸缩、容错并自动化这些容器化应用呢?Docker Compose主要面向单机开发和测试,其能力在生产级编排上是不足的。这时,Kubernetes(K8s)就该登场了。它已经成为云原生时代容器编排的事实标准,为我们提供了在生产环境中运行和管理分布式应用的强大平台。
小结
这节课,我们首先学习了如何将Go应用容器化。通过掌握Dockerfile的最佳实践(如选择合适的基础镜像、利用多阶段构建、优化层缓存、非root用户运行)和镜像优化技巧(如静态链接编译、使用 .dockerignore),我们可以为Go应用构建出轻量、高效、安全且可移植的“集装箱”。
在进入生产级编排之前,我们特别介绍了开发阶段的利器——Docker Compose。我们学习了如何通过 docker-compose.yml 文件定义和运行多容器Go应用及其依赖(如数据库、缓存),如何利用卷挂载实现代码热重载,以及Compose在简化本地开发、保障环境一致性和加速迭代方面的核心价值。
欢迎在留言区分享你的思考和方案!我是Tony Bai,我们下节课见。
部署与升级:拥抱云原生,实现Go应用持续交付(下)
你好,我是Tony Bai。
这节课,我们将一起入门Kubernetes的核心概念,并重点讨论在K8s中部署Go服务的典型模式,包括配置管理、健康检查和资源管理。最后,我们将深入剖析 主流的平滑发布策略——滚动更新、蓝绿部署与金丝雀发布,理解它们的原理、优缺点,以及Go应用如何配合这些策略实现无缝升级。
这两节课学完,你将能够为你的Go应用插上云原生的翅膀,使其部署更简单、升级更平滑、运行更稳健。
Kubernetes部署:Go服务在云原生时代的“标准舞台”
我们的Go应用已经容器化,并且在Docker Compose环境中能够与依赖服务协同工作了。但是,如何在生产环境中大规模地管理、伸缩、容错并自动化这些容器化应用呢? 答案在当前的云原生时代几乎是唯一的,那就是 Kubernetes(K8s)。Kubernetes已经成为容器编排领域的事实标准,它提供了一个健壮、可扩展、声明式的框架,用于自动化容器化应用的部署、扩展和管理。对于我们精心构建的Go服务来说,Kubernetes正是那个能让它们在生产环境中大放异彩的“标准舞台”。
理解Kubernetes的核心概念,并掌握如何在其中部署和管理我们的Go服务,是Go工程师迈向云原生运维的关键一步。 更重要的是,Kubernetes提供的环境和能力,也为我们后续要讨论的平滑发布策略(如滚动更新、蓝绿部署、金丝雀发布)奠定了基础。没有Kubernetes这样的编排平台,许多高级的发布和运维技术将难以实现。
Kubernetes核心概念入门
要理解Kubernetes,就要从其核心概念开始。下面是Kubernetes这个平台的一些核心概念,我们逐一来看一下。
-
Pod:K8s中可以创建和管理的 最小部署单元。一个Pod代表集群中一个运行的进程。它可以包含一个或多个紧密协作的容器,这些容器共享同一个网络命名空间、存储卷,并且可以在同一节点上被共同调度。
-
Service(服务):K8s Service为一组逻辑上相关的Pod提供一个 稳定的网络入口点。它会给这组Pod分配一个唯一的、虚拟的IP地址(ClusterIP)和一个DNS名称,集群内的其他应用可以通过这个ClusterIP或DNS名称来访问这些Pod,Service会自动进行负载均衡。
-
Deployment(部署):Deployment是K8s中用于 声明式地管理应用副本和更新 的一种控制器。你可以在Deployment中定义期望的应用状态,Deployment控制器会持续工作以确保集群的实际状态与期望状态一致。它支持滚动更新和回滚等发布策略。
-
ReplicaSet(副本集):ReplicaSet确保在任何给定时间都有指定数量的Pod副本在运行。它通常不直接使用,而是由Deployment在内部创建和管理。
-
Namespace(命名空间):Namespace用于在同一个物理集群内创建多个 虚拟的、逻辑隔离的集群环境,可以用来隔离不同团队、项目或环境的资源。
-
ConfigMap(配置映射)与 Secret(保密字典):
-
ConfigMap:用于存储应用的非敏感配置数据,并将其以环境变量、命令行参数或挂载卷的形式注入到Pod的容器中。
-
Secret:专门用于存储敏感数据,如密码、API密钥、TLS证书等。
-
-
Ingress(入口):(可选)定义了从集群外部访问集群内部Service的规则,通常是HTTP和HTTPS路由,需要Ingress Controller配合。
理解这些核心概念,是我们后续讨论如何在K8s中部署Go服务的基础。它们就像Kubernetes这座复杂城市的“街道”、“建筑”和“基础设施”,为我们的Go应用容器提供了运行的场所和交互的规则。
熟悉了这些基本构件之后,我们自然会问:如何将这些概念组合起来,形成一套行之有效的方案,真正把我们的Go服务部署到Kubernetes集群中,并让它稳定、高效地运行起来呢?这就引出了我们在K8s中部署Go服务的典型模式。
在Kubernetes中部署Go服务的典型模式
在Kubernetes中部署一个Go服务(或其他任何类型的服务),通常不是简单地运行一个Pod那么简单。为了实现高可用、可伸缩、易于管理和配置的目标,我们需要将前面介绍的多个核心概念(如Deployment、Service、ConfigMap、Secret、Health Probes等)有机地组合起来,形成一套标准的、可重复的部署模式。
掌握这种典型模式至关重要,因为它不仅是生产环境中部署Go服务的最佳实践,也是后续实现自动化运维、持续集成/持续交付(CI/CD)以及高级发布策略(如滚动更新、蓝绿部署)的基础。 一个精心设计的部署模式,能够让你的Go服务在Kubernetes这个强大的平台上充分发挥其潜力,同时显著降低运维的复杂度和风险。
接下来,我们将通过编写YAML声明式配置文件的方式,来具体展示这个典型模式是如何构成的,以及Go应用自身需要如何配合。一个最小但能体现核心思想的生产级Go服务部署,通常至少会涉及Deployment和Service这两个关键的Kubernetes资源对象。
编写Deployment YAML
Deployment是Kubernetes中用于声明式地管理应用副本(Pod)和更新策略的核心对象。它确保了我们期望数量的Go应用实例始终在运行,并能在版本更新时进行平滑的滚动升级。
下面是一个部署简单Go Web服务的 myapp-deployment.yaml 文件示例:
# myapp-deployment.yaml
apiVersion: apps/v1 # 1. 指定API版本,apps/v1是当前稳定版本
kind: Deployment # 2. 声明资源类型为Deployment
metadata: # 3. 元数据,用于标识和组织资源
name: my-go-app-deployment # Deployment的名称,在Namespace内唯一
labels: # 标签,用于选择和组织资源
app: my-go-app # 例如,app=my-go-app 可以被Service用来选择此Deployment管理的Pod
version: v1.0.0 # 可以加上版本标签,便于管理
spec: # 4. 规格,定义Deployment的期望状态
replicas: 3 # 期望运行3个Pod副本,K8s会努力维持这个数量
selector: # 5. 选择器,定义此Deployment管理哪些Pod
matchLabels:
app: my-go-app # 它必须与下面template.metadata.labels中的标签匹配
# (注意:通常版本标签不放在selector中,以便Service可以同时选择新旧版本Pod进行滚动更新)
template: # 6. Pod模板,描述如何创建每个Pod实例
metadata:
labels: # Pod自身的标签,必须包含selector中定义的标签
app: my-go-app
version: v1.0.0 # Pod也带上版本标签
spec: # Pod的规格
containers: # 定义Pod中运行的容器列表(通常Go服务只有一个主容器)
- name: my-go-app-container # 容器名称,在Pod内唯一
image: your-registry/my-go-app:v1.0.0 # 7. 指定Go应用的Docker镜像及其版本标签
imagePullPolicy: IfNotPresent # (可选) 镜像拉取策略,IfNotPresent表示如果本地已有则不拉取
ports:
- name: http # (可选) 为端口命名,便于引用
containerPort: 8080 # 8. 应用在容器内部监听的端口号
protocol: TCP # (可选) 默认为TCP
# --- 9. 通过环境变量传递配置 ---
env:
- name: APP_DATABASE_URL # 环境变量名
valueFrom: # 值从其他地方获取
secretKeyRef: # 从一个Secret对象中获取
name: db-credentials-secret # Secret对象的名称
key: database_url # Secret中对应的键 (key)
- name: LOG_LEVEL
valueFrom:
configMapKeyRef: # 从一个ConfigMap对象中获取
name: app-configmap # ConfigMap对象的名称
key: log.level # ConfigMap中对应的键
# 也可以直接设置固定值的环境变量:
# - name: GIN_MODE
# value: "release"
# --- 10. 健康检查 (Health Probes) ---
livenessProbe: # 存活探针:判断容器是否仍在运行且健康
httpGet: # 通过HTTP GET请求检查
path: /healthz # Go应用需要提供这个HTTP端点
port: 8080 # 对应containerPort
scheme: HTTP # (可选) 默认为HTTP
initialDelaySeconds: 15 # 容器启动后15秒开始第一次探测
periodSeconds: 20 # 每20秒探测一次
timeoutSeconds: 5 # 探测超时时间 (默认1s)
successThreshold: 1 # (可选) 连续1次成功即认为健康 (默认1)
failureThreshold: 3 # 连续3次失败后认为不健康 (K8s会重启容器)
readinessProbe: # 就绪探针:判断容器是否准备好接收流量
httpGet:
path: /readyz # Go应用需要提供这个HTTP端点
port: 8080
initialDelaySeconds: 5 # 容器启动后5秒开始探测
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3 # 连续3次失败后认为未就绪 (Service会将其从负载均衡中移除)
# startupProbe: (K8s 1.18+) # 启动探针,用于启动时间较长的应用 (可选)
# httpGet:
# path: /startupz
# port: 8080
# failureThreshold: 30 # 允许较多次失败,给足启动时间
# periodSeconds: 10 # 探测间隔
# --- 11. 资源请求与限制 (Resource Requests and Limits) ---
resources:
requests: # Pod调度时,节点必须能满足这些最小资源请求
memory: "64Mi" # 请求64兆字节内存
cpu: "100m" # 请求0.1 CPU核心 (100 millicores)
limits: # 容器使用的资源不能超过这些硬性限制
memory: "128Mi" # 内存上限128Mi
cpu: "500m" # CPU上限0.5核心
# (可选) terminationGracePeriodSeconds: 30 # Pod停止时,给容器优雅退出的宽限时间 (默认30s)
# (可选) imagePullSecrets: # 如果镜像是私有的,需要指定拉取凭证
# - name: my-registry-secret
下面,我们针对这份Deployment文件的几个关键点简单说明一下:
-
apiVersion和kind:标准K8s对象头,指明API版本和资源类型。 -
metadata:包含name(Deployment的唯一标识)和labels(用于组织和选择)。labels非常重要,Service会用它来找到这个Deployment管理的Pod。 -
spec:定义了Deployment的期望状态。 -
replicas:期望运行的Pod副本数量。K8s会自动维护这个数量,如果某个Pod挂了,会自动创建一个新的。 -
selector:告诉Deployment它应该管理哪些Pod。matchLabels必须与下面template.metadata.labels中的标签一致。 -
template:这是Pod的模板,Deployment会根据这个模板来创建新的Pod。 -
image:指定你的Go应用打包好的Docker镜像地址和版本标签。 -
containerPort:声明容器内部应用监听的端口。这本身不暴露端口到外部,但Service会用到它。 -
env:通过环境变量向Go应用注入配置。这里演示了从Secret(用于敏感数据如DB URL)和ConfigMap(用于非敏感数据如日志级别)中获取值。Go应用需要能从环境变量中读取这些配置(例如,使用os.Getenv()或Viper等库的AutomaticEnv()功能)。 -
Health Probes(健康检查):这是让Kubernetes能够感知你的Go应用健康状况的关键机制。Deployment中可以配置三种探针:
-
livenessProbe(存活探针):用于判断容器是否“活着”。如果探测失败,Kubernetes会重启容器。 -
readinessProbe(就绪探针):用于判断容器是否“准备好”接收流量。如果探测失败,Pod的IP地址会从所有匹配的Service的端点列表中移除。 -
startupProbe(启动探针, K8s 1.18+):(可选)用于那些启动过程可能比较耗时的应用。在启动探针成功之前,存活探针和就绪探针不会开始。这可以防止应用因启动慢而被存活探针过早杀死。
-
这些探针可以通过HTTP GET、TCP Socket连接或在容器内执行命令等方式进行。对于Go Web服务,HTTP GET是最常用的方式。 Go应用自身需要如何实现这些探针端点,我们稍后会详细讨论。
resources(资源请求与限制):-
requests:Pod在被调度到某个Node上时,Node必须拥有足够的可用资源来满足这些请求。它也影响Pod的服务质量等级(QoS)。 -
limits:容器可以使用的资源硬上限。如果内存使用超过limit,容器可能会被OOMKilled;如果CPU使用时长超过limit,可能会被节流。为Go应用设置合理的资源请求和限制非常重要,以保证集群的稳定性和资源的有效利用。
-
Go应用如何配合Deployment的定义
为了让我们的Go应用能够良好地在上述Deployment的管理下运行,应用本身需要做一些适配。
首先是读取配置。 Go应用需要能够从环境变量中读取配置(如使用标准库的 os.Getenv(),或者像 spf13/viper 这样的库可以通过 AutomaticEnv() 功能自动绑定环境变量)。如果Deployment中配置是通过文件卷(Volume Mounts from ConfigMap/Secret)挂载的,那么Go应用就需要从指定的挂载路径读取这些配置文件。
其次是实现健康检查端点。 这是至关重要的一环,直接关系到应用在Kubernetes中的稳定性和可用性。Go应用(通常是Web服务)需要实现Deployment中 livenessProbe、 readinessProbe(以及可能的 startupProbe)通过 httpGet 指定的HTTP路径和端口。
/healthz(Liveness Probe 端点实现): 这个端点的实现逻辑应该非常简单和轻量。 它的核心目标是确认应用进程本身是否还在运行,并且其内部核心循环(例如HTTP服务器的监听循环)没有僵死。存活探针不应该检查外部依赖(如数据库连接状态、下游服务是否可达等)的健康状况。如果仅仅因为一个外部依赖暂时抖动或不可用,就导致Kubernetes重启你的应用容器,这往往是不必要的,甚至可能加剧问题(例如,所有实例同时重启去冲击一个本已不堪重负的数据库)。一个好的存活探针可能仅仅是简单地返回http.StatusOK(状态码200)。如果应用内部有可以快速检测到的致命的、不可恢复的内部错误状态,也可以在此反映。
// 示例:Go应用中简单的Liveness Probe Handler
// http.HandleFunc("/healthz", func(w http.ResponseWriter, r *http.Request) {
// w.WriteHeader(http.StatusOK)
// fmt.Fprintln(w, "ok")
// })
/readyz(Readiness Probe 端点实现): 就绪探针的逻辑应该比存活探针更全面和严格。它的目标是告诉Kubernetes,当前这个Pod实例是否真正准备好处理生产流量。应用在完成所有关键的初始化工作之前,不应该让/readyz返回成功。这些初始化工作可能包括:- 成功连接到所有必需的数据库和缓存服务。
- 加载完必要的配置和数据到内存中。
- 所有内部的核心模块和goroutine已正常启动并准备就绪。
- 依赖的关键下游服务(如果这些服务的不可用会导致本服务也无法正常提供核心功能)初步可达。一旦
/readyz返回成功(通常是http.StatusOK),Kubernetes就会认为这个Pod实例已经就绪,并会将其加入到对应Service的负载均衡池中,开始接收流量。在应用运行期间,如果检测到自身某个 关键的、使其无法正常提供核心服务 的状态(例如,与主数据库的连接断开且无法恢复,或者某个核心内部组件故障),/readyz应该开始返回失败状态码(如http.StatusServiceUnavailable(503))。这样,Kubernetes就能将其从负载均衡中暂时移除,避免将新的用户请求导入到这个有问题的实例,直到它恢复正常。
// 示例:Go应用中稍复杂的Readiness Probe Handler (概念性)
// var isAppReady bool // 由应用初始化逻辑和状态监控更新
// var readinessMux sync.RWMutex // 保护isAppReady的并发访问
//
// func setReadyStatus(ready bool) {
// readinessMux.Lock()
// isAppReady = ready
// readinessMux.Unlock()
// }
//
// func readinessHandler(w http.ResponseWriter, r *http.Request) {
// readinessMux.RLock()
// currentReadyStatus := isAppReady
// readinessMux.RUnlock()
//
// if currentReadyStatus /* && checkCriticalDependencies() */ {
// w.WriteHeader(http.StatusOK)
// fmt.Fprintln(w, "ready")
// } else {
// w.WriteHeader(http.StatusServiceUnavailable)
// fmt.Fprintln(w, "not ready")
// }
// }
// http.HandleFunc("/readyz", readinessHandler)
/startupz(Startup Probe 端点实现, K8s 1.18+):(可选)如果应用启动过程确实非常耗时(例如,需要几分钟来预热大量缓存数据或建立复杂的外部连接),可以使用启动探针。其实现逻辑可以与就绪探针类似,或者是一个更简单的、仅表示“主要启动流程已完成”的信号。一旦启动探针成功,其职责就完全移交给了后续的存活探针和就绪探针。
通过精心设计和实现这些健康检查端点,Go应用就能与Kubernetes的生命周期管理机制良好协作,从而实现更高的可用性和稳定性。
编写Service YAML
Service为一组具有相同标签的Pod(由Deployment管理)提供一个统一的、稳定的访问入口(ClusterIP和DNS名称),并在这组Pod之间进行负载均衡。下面是一个将上述Deployment暴露为集群内部服务的 myapp-service.yaml 示例:
# myapp-service.yaml
apiVersion: v1 # Service属于核心API组 (core/v1)
kind: Service
metadata:
name: my-go-app-service # Service的名称
labels:
app: my-go-app # (可选) Service也可以有自己的标签
spec:
selector: # 1. 选择器,关键!它必须匹配你希望此Service代理的Pod的标签
app: my-go-app # 这里选择了所有带有 app=my-go-app 标签的Pod
ports:
- name: http # (可选) 端口名称
protocol: TCP # (可选) 默认为TCP
port: 80 # 2. Service自身暴露给集群内部其他Pod访问的端口号
targetPort: 8080 # 3. 流量将被转发到后端Pod容器的哪个端口 (必须与Pod模板中定义的containerPort匹配)
type: ClusterIP # 4. Service类型 (默认为ClusterIP)
# ClusterIP: 只在集群内部可见,通过一个内部IP地址访问。
# NodePort: 在每个集群节点的某个静态端口上暴露服务 (通常用于测试或特定场景)。
# LoadBalancer: (通常在云环境中如AWS, GCP, Azure) 会自动创建一个外部负载均衡器,
# 将外部流量导入到此Service。
# ExternalName: 将Service映射到一个外部的DNS名称 (通过CNAME记录)。
我们针对这份Service文件的几个关键点简单说明一下:
-
selector:这是Service与Pod关联的核心。Service会持续监控集群中所有带有匹配标签(这里是app: my-go-app)的Pod,并将它们作为自己的后端端点(Endpoints)。 -
port:Service监听的端口。集群内的其他应用如果想访问my-go-app服务,就会连接到这个Service的ClusterIP和这个port(例如,http://my-go-app-service:80)。 -
targetPort:Service接收到流量后,会将流量转发到后端某个Pod的这个端口上。这个值必须与Deployment中Pod模板里定义的containerPort一致。它可以是一个数字端口,也可以是Pod端口的命名引用(如果Deployment的ports中定义了name)。 -
type:决定了Service如何被访问。ClusterIP是最常见的类型,用于集群内部服务间的通信。
应用YAML到集群
当你编写好这些YAML文件后,可以使用 kubectl apply -f <filename.yaml> 命令将它们提交给Kubernetes集群的API Server。
kubectl apply -f myapp-configmap.yaml # 假设你还有ConfigMap和Secret的YAML文件
kubectl apply -f myapp-secret.yaml
kubectl apply -f myapp-deployment.yaml
kubectl apply -f myapp-service.yaml
以下是上述命令的执行效果:
-
Kubernetes会根据
myapp-deployment.yaml的定义,创建Deployment对象。 -
Deployment控制器会根据
replicas: 3和Pod模板,创建3个Pod的ReplicaSet,并确保3个Pod实例被调度到集群节点上运行。每个Pod会拉取your-registry/my-go-app:v1.0.0镜像,并根据定义的env、ports、probes、resources来启动容器。 -
同时,根据
myapp-service.yaml,Kubernetes会创建Service对象。Service会分配一个集群内部的IP地址(ClusterIP),并开始监控所有带有app: my-go-app标签的Pod。当这些Pod的Readiness Probe成功后,Service会将它们加入到自己的负载均衡池中。 -
此后,集群内的其他应用就可以通过
my-go-app-service的DNS名称(或ClusterIP)和Service定义的port(如80)来访问你的Go应用了,Service会自动将请求轮询(或其他负载均衡策略)到后端健康的3个Pod实例的targetPort(如8080)上。 -
你可以通过
kubectl get deployments、kubectl get pods、kubectl get services、kubectl describe pod <pod-name>、kubectl logs <pod-name> -c <container-name>等命令来查看部署状态和应用日志。
通过这种方式,我们就将Go应用以一种声明式的、可重复的、可扩展的方式部署到了Kubernetes中。
Go应用在Kubernetes环境下的日志与可观测性集成
虽然我们已经详细探讨过Go应用自身如何设计和实现可观测性,但在这里,我们还是要再从Kubernetes部署的角度简要说明一下集成方式。
- 日志(Logging):
-
Go应用侧:关键在于将所有日志(结构化的,如使用
log/slog) 输出到标准输出(stdout)和标准错误(stderr)。这是云原生应用日志处理的最佳实践。 -
Kubernetes侧:Kubernetes集群通常会配置一个日志收集方案(例如,节点上运行Fluentd或Fluent Bit作为日志代理)。这些代理会自动收集所有容器的标准输出流,并将它们转发到集中的日志存储和分析系统(如Elasticsearch + Kibana、Grafana Loki、VictoriaLogs或云服务商提供的日志服务)。
-
开发者应避免让Go应用直接写入本地日志文件并自行管理轮转,因为这会与K8s的日志架构冲突,并使日志管理复杂化。
-
- 监控(Metrics & Tracing):
- Go应用侧:
-
Metrics:Go应用应通过HTTP端点(通常是
/metrics)以Prometheus格式暴露其内部的关键性能指标和业务指标。 -
Tracing:Go应用应集成分布式追踪库(如OpenTelemetry),生成和传播Trace信息。
-
- Kubernetes侧:
-
Metrics:Prometheus(通常通过Prometheus Operator部署在K8s中)可以配置为自动发现并抓取(scrape)集群内带有特定注解(如
prometheus.io/scrape: 'true')的Pod或Service暴露的/metrics端点。 -
Tracing:追踪数据通常由应用直接或通过Agent(如OpenTelemetry Collector部署为DaemonSet或Sidecar)发送到集中的追踪后端(如Jaeger、Zipkin、Grafana Tempo)。
-
- Go应用侧:
通过这种方式,Go应用自身的日志和可观测性数据能够无缝地融入到Kubernetes集群的整体监控和日志管理体系中,为后续的故障排查、性能分析和告警打下基础。
我们已经成功地将Go应用容器化,并通过Kubernetes的Deployment和Service将其稳定地部署到了集群中,实现了配置管理、健康检查和基本的日志监控集成。这为我们的应用提供了一个健壮的运行环境。但是,软件开发是一个持续迭代的过程,新功能、Bug修复、性能优化层出不穷。当我们的Go应用需要发布新版本时,又将面临新的挑战: 如何才能在升级过程中最大限度地减少甚至避免服务中断,保证用户体验的平滑过渡,并有效控制发布带来的风险呢?
平滑发布:实现Go应用的无缝升级与迭代
在快速迭代的现代软件开发中,频繁地发布新版本是常态。然而,每一次发布都如同一次“心脏搭桥手术”,操作不当就可能对“病人”(我们的线上服务)造成冲击:新版本可能引入未被发现的Bug,升级过程可能导致服务短暂中断或性能抖动,用户体验可能因此受到影响。因此,仅仅能够“部署”是不够的,我们还需要掌握“如何优雅地升级”,这就是平滑发布(也常被称为渐进式交付或零停机部署)所要解决的核心问题。
平滑发布的核心目标非常明确:
-
最大限度减少或避免服务中断(Zero Downtime Deployment / Near Zero Downtime):在从旧版本切换到新版本的过程中,用户应尽可能感受不到服务的停顿或不可用。
-
降低发布风险:通过逐步引入新版本并持续、密切地监控其在真实生产环境(或部分生产流量)下的表现,我们可以在问题影响范围扩大之前及时发现并处理。
-
具备快速回滚能力:如果新版本在线上暴露出严重问题,我们必须能够迅速、安全地将服务状态回退到上一个已知的稳定版本,将损失降到最低。
-
验证新版本在真实环境下的表现:在受控的、小范围的真实流量下观察新版本的功能、性能和稳定性,这比任何模拟环境的测试都更具说服力。
幸运的是,Kubernetes作为强大的容器编排平台,其Deployment对象本身就内置了对滚动更新(Rolling Update)这种基础平滑发布策略的支持。而对于更复杂、更精细的发布需求,Kubernetes生态(例如通过Service、Ingress以及Service Mesh工具如Istio、Linkerd,或渐进式交付工具如Argo Rollouts、Flagger)也为我们实现更高级的发布策略(如蓝绿部署、金丝雀发布)提供了强大的基础设施。
主流平滑发布策略详解
在理解了平滑发布的必要性和核心目标之后,现在让我们具体来看一看在Kubernetes生态中,有哪些主流的发布策略可以帮助我们实现这一目标(以Kubernetes Deployment或相关机制为例)。每种策略都有其独特的运作方式、优势和适用场景。我们将重点关注滚动更新、蓝绿部署和金丝雀发布这三种最常用且具有代表性的方法。
滚动更新(Rolling Update)
这是Kubernetes Deployment默认的更新策略( strategy: type: RollingUpdate)。它通过逐步地、分批次地用新版本的Pod替换旧版本的Pod来实现更新。在整个更新过程中,新旧版本的Pod会同时存在并共同处理流量。
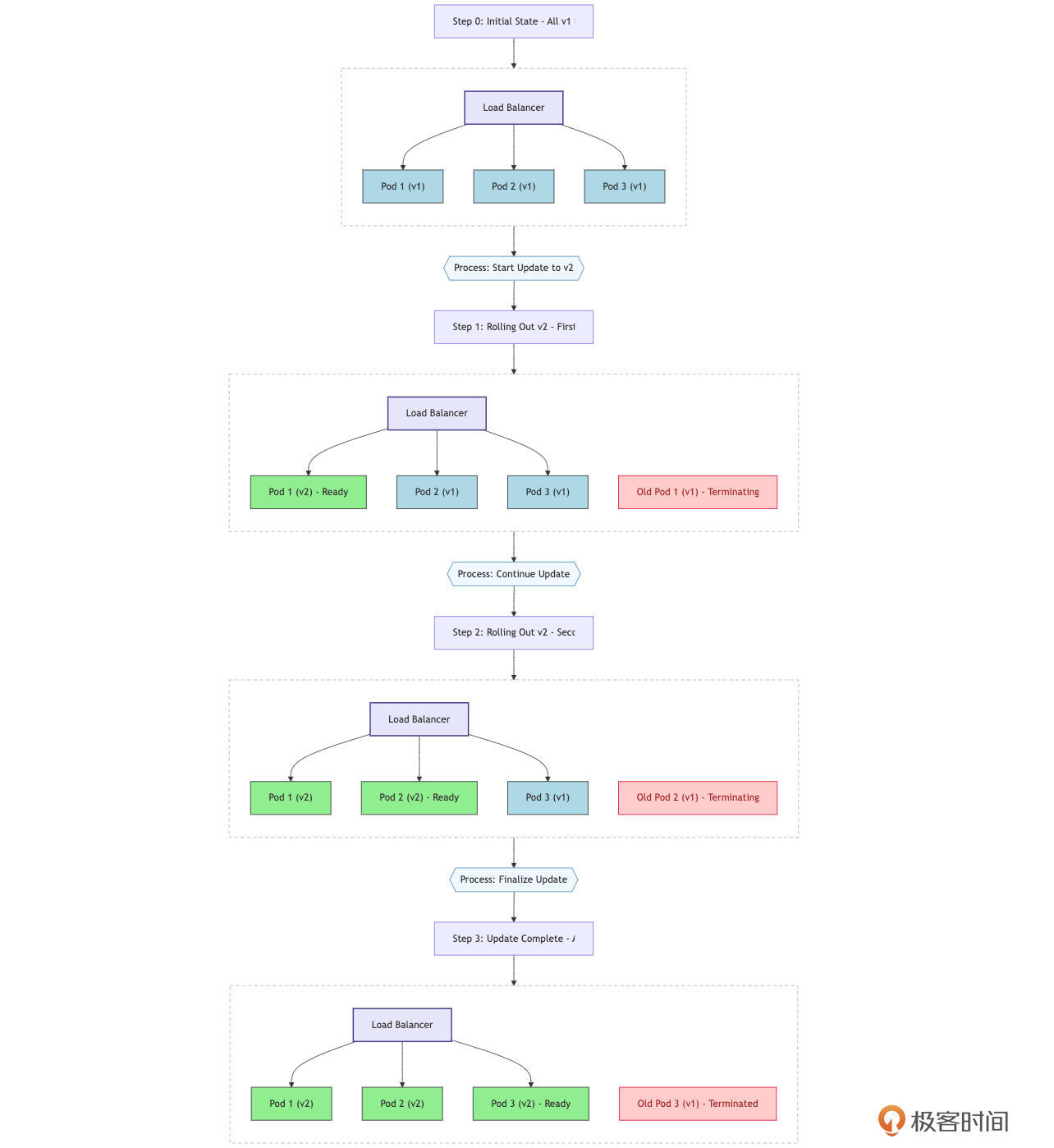
Kubernetes Deployment通过 spec.strategy.rollingUpdate 字段下的 maxSurge 和 maxUnavailable 参数来精细控制更新过程:
-
maxSurge:在更新过程中,允许创建的超出期望副本数的Pod数量(或百分比)。例如,如果replicas: 3,maxSurge: 1,则在更新时最多可以有4个Pod运行。 -
maxUnavailable:在更新过程中,允许的最大不可用Pod数量(或百分比)。例如,如果replicas: 3,maxUnavailable: 1,则在更新时至少要有2个Pod是可用的。
Kubernetes 在更新 Pod 时,采用了一种先启动新版本 Pod、等待其就绪(通过 Readiness Probe),再停止旧版本 Pod 的策略。这种方法具有多个优点。
首先,它是 Kubernetes 的默认行为,实现相对简单且自动化程度高。在更新过程中,只要合理控制 maxUnavailable,服务基本可以保持不中断。
此外,该策略的资源利用率较高,因为不需要额外的完整环境。同时,它还支持版本回滚,用户可以通过命令 kubectl rollout undo deployment/... 轻松回退到之前的版本。
然而,这种更新方式也存在一些缺点。由于新旧版本的实例会在更新过程中同时存在并处理请求,如果新旧版本之间存在不兼容的 API 或数据格式变更,可能会引发问题。此外,尽管回滚操作相对直接,但回滚过程本身也可能对已经使用新版本的用户造成影响,尤其是在新版本涉及数据变更的情况下。因此,在进行版本更新时,需要综合考虑这些因素,以确保服务的稳定性和用户体验。
在这种模式下, Go应用与Kubernetes配合实现优雅退出(Graceful Shutdown)就显得至关重要了。
当 Kubernetes 停止旧版本的 Pod 时,会首先发送 SIGTERM 信号。为了确保应用能够妥善处理这一信号,Go 应用必须能够捕获它,停止接受新请求,并在 terminationGracePeriodSeconds 的时间内处理完所有已有请求,释放资源后再正常退出。这种机制能够有效避免正在处理的请求被粗暴中断,从而提升用户体验。
此外,在新旧版本同时服务的情况下,API 版本的兼容性也是一个重要考量。为了确保平稳过渡,新旧版本所提供的外部 API 及其内部交互接口必须向后兼容,或者可以通过 API 网关等机制进行适配,从而避免因接口不兼容而导致的问题。
最后,如果新版本涉及数据库 Schema 的变更,开发团队需要仔细规划迁移策略,以确保在过渡期间新旧版本的代码都能正确处理数据状态。这种周密的设计与实现,可以有效降低版本更新过程中可能出现的风险,确保服务的稳定性和可靠性。
蓝绿部署(Blue/Green Deployment)
蓝绿部署的前提是需要同时准备两套完全相同(硬件资源、网络配置等)但独立的生产环境:“蓝色”环境(Blue Environment)运行当前稳定的生产版本(v1),“绿色”环境(Green Environment)部署新版本(v2)。
开始时,所有生产流量都指向蓝色环境。当绿色环境部署完成并通过所有测试(包括在真实流量的子集下进行测试,如果可能)后,通过负载均衡器或DNS切换,将所有流量瞬间从蓝色环境切换到绿色环境。绿色环境成为新的生产环境,蓝色环境则作为热备份,如果绿色环境出现问题,可以快速将流量切回蓝色环境。
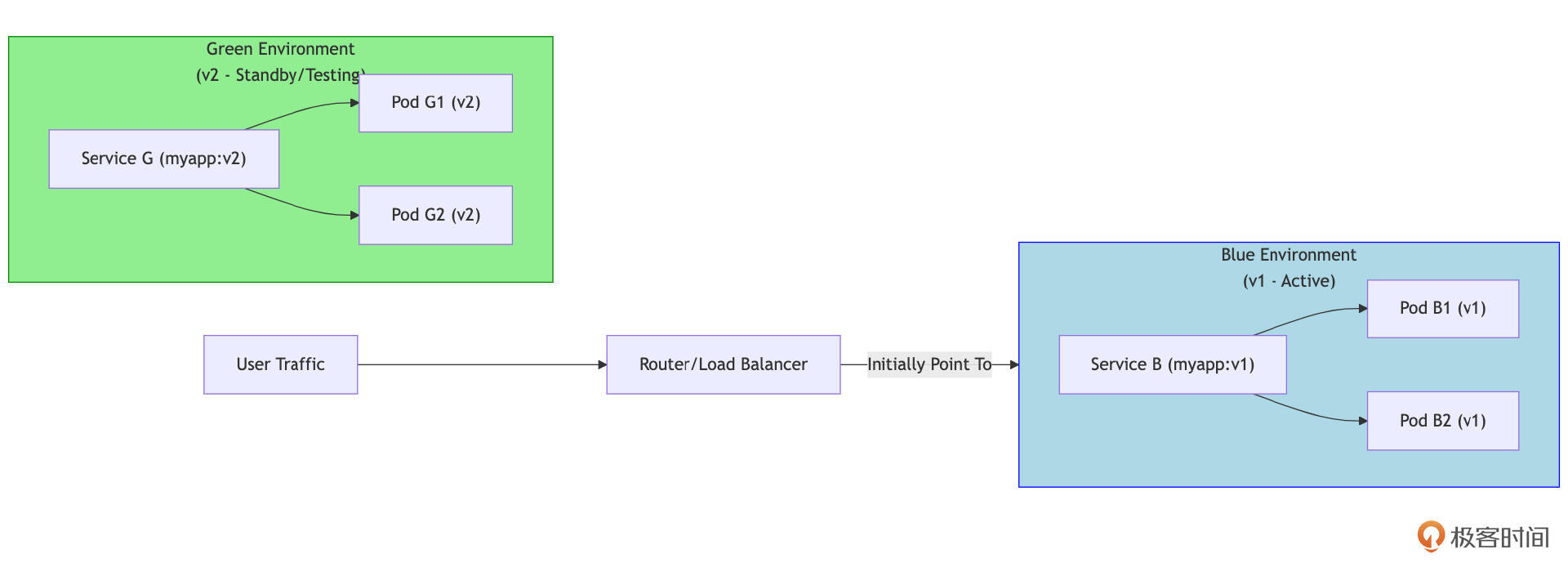
Kubernetes 本身并没有一个名为“蓝绿部署”的直接控制器,但可以通过手动操作或借助工具来实现这一策略。
通常的做法是为蓝色版本和绿色版本分别创建独立的 Deployment(例如, myapp-blue-deployment 和 myapp-green-deployment) 以及相应的 Service(例如, myapp-blue-service 和 myapp-green-service)。
此外,一个“主” Service(或 Ingress 规则)负责接收外部流量,它通过修改其 selector 来指向蓝色或绿色 Service,从而实现流量的切换。例如,主 Service myapp-production-service 的 selector 最初可能是 version: blue,切换时则修改为 version: green,同时确保 Pod 的 labels 也相应更新。借助 Service Mesh 工具(如 Istio、Linkerd)或更高级的交付工具(如 Argo Rollouts、Flagger),可以更方便地管理蓝绿部署流程及流量切换。
蓝绿部署的优点在于其发布和回滚的速度非常快且风险低,几乎实现零停机时间,因为流量的切换是瞬间完成的。新版本可以在隔离的环境中进行充分测试,包括压力测试和集成测试,而不会影响到现有的生产流量。一旦需要回滚,只需将流量指向旧环境,这一过程非常可靠。
然而,蓝绿部署也存在一些缺点。首先,资源成本较高,因为在切换期间需要维护两套完整的生产环境,导致资源需求翻倍。对于有状态服务,特别是涉及数据库的 Schema 变更和数据同步,情况会变得相当复杂。必须确保两个环境能够操作同一个(或同步的)数据存储,或者在切换时妥善处理数据迁移。
在 Go 应用的设计中,最好采用无状态的架构,或者将状态管理交给外部存储(如 Redis 或数据库),这样在切换环境时就不会丢失会话信息。此外,如果新旧版本共用同一数据库,则需要确保新版本的代码及其 Schema 变更(如果有)对旧版本是向后兼容的,或者在切换前后制定明确的数据迁移和同步步骤,以确保数据的一致性和完整性。
金丝雀发布 (Canary Release)
这是一种更渐进、更谨慎的发布策略。首先,将新版本(v2)部署到一小部分服务器或用户(这些被称为“金丝雀”实例或“金丝雀”群体)。然后,让这部分用户开始使用新版本,同时密切监控新版本的表现(例如,错误率、响应时间、CPU/内存使用、业务指标、用户反馈等)。如果金丝雀版本表现稳定且符合预期,就逐步扩大其部署范围(例如,从1%用户到5%,再到20%,以此类推),直到最终所有流量都切换到新版本,旧版本被完全替换。如果在任何阶段金丝雀版本出现问题,可以立即将其流量切回旧版本,并将影响控制在最小范围。
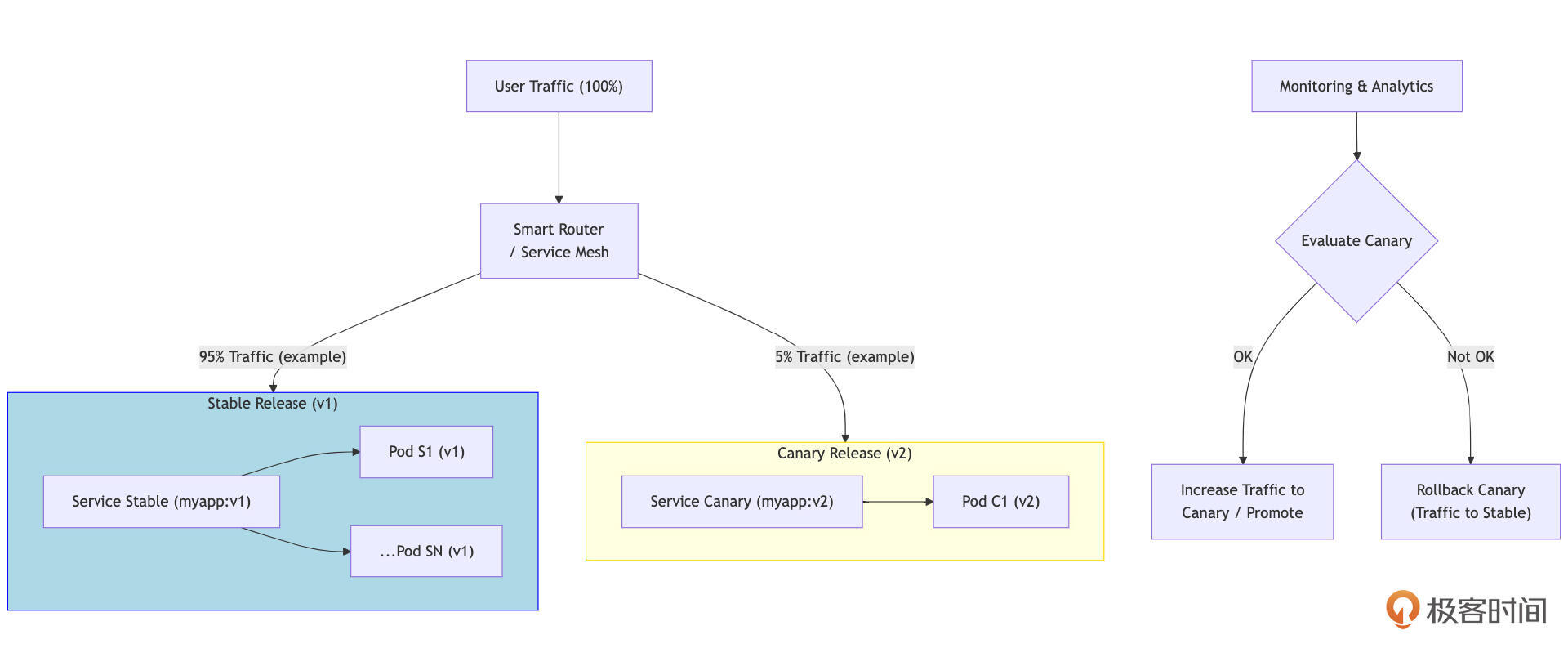
在 Kubernetes 中实现金丝雀发布通常比滚动更新和蓝绿部署更复杂,但也提供了更大的灵活性。
金丝雀发布的基本策略是手动管理多个 Deployment,维护一个主版本的 Deployment(例如, myapp-stable-deployment)和一个金丝雀版本的 Deployment( myapp-canary-deployment)。通过调整它们的 replicas 数量,并让同一个 Service 通过标签选择器同时选中这两个 Deployment 的 Pod,可以粗略控制流量比例,例如分配 90% 的流量给稳定版本,10% 给金丝雀版本。然而,这种方法的精确度有限。
为了实现更精确的流量切分,可以使用 Ingress Controller,支持基于权重或 HTTP Header 的流量切分(例如 Nginx Ingress 的金丝雀注解)。此外,使用 Service Mesh 工具(如 Istio 或 Linkerd)是实现复杂金丝雀发布和 A/B 测试的推荐方式。Service Mesh 提供了细粒度的流量路由控制能力,能够基于权重、HTTP 头部(如 User-Agent、特定 cookie、地理位置)以及 gRPC 方法等,将特定比例或特定用户的流量精确导向金丝雀版本。这些工具通常还集成了遥测数据收集,便于监控金丝雀版本的表现。
渐进式交付工具(如 Argo Rollouts 和 Flagger)专门用于自动化和管理金丝雀发布及蓝绿部署等高级发布策略。这些工具构建在 Kubernetes 之上,并通常与 Service Mesh 和监控系统(如 Prometheus)集成,根据预设的分析规则(例如,错误率不超过 X%,延迟不高于 Y 毫秒)自动判断是否逐步推进发布或进行回滚。
金丝雀发布的主要优点是风险最低,因为新版本仅暴露给一小部分用户,这使得在真实生产流量下对其功能、性能和稳定性进行小范围验证成为可能。此外,这种方式能够收集真实用户对新版本的反馈,一旦出现问题,影响范围极小,且可以快速回滚。
然而,金丝雀发布的缺点在于实现和管理相对复杂,特别是在流量切分和金丝雀版本监控方面。整个发布周期可能较长,因为需要逐步增加流量并观察效果。此外,对强大的监控、日志和告警能力的要求也很高,以便及时、准确地评估金丝雀版本的表现。
在 Go 应用的设计中,强大的可观测性至关重要。应用必须暴露详细的 Metrics(使用 Prometheus 等工具)、结构化日志(如使用 slog 输出到集中式日志系统),以及分布式追踪信息,这些都是评估金丝雀版本健康状况的重要依据。同时,可以通过特性开关(Feature Flags)与金丝雀发布配合使用,即使代码已经部署,也可以在运行时控制新功能的开启范围,从而进一步细化风险。此外,由于新旧版本会长时间共存,确保 API 和数据格式的兼容性设计尤为重要,以避免在切换过程中出现问题。
选择合适的发布策略
没有一种发布策略是万能的。选择哪种策略,通常需要根据以下因素进行权衡:
-
业务风险承受能力:应用的核心程度如何?一次发布失败可能造成的业务损失有多大?风险承受能力低的应用更适合金丝雀发布或蓝绿部署。
-
应用复杂度和特性:应用是有状态还是无状态?新版本是否涉及破坏性的数据或API变更?这些都会影响策略的选择。
-
团队的运维能力和工具支持:团队是否熟悉Kubernetes的高级特性?是否有Service Mesh或渐进式交付工具的支持?运维能力强的团队更能驾驭复杂的发布策略。
-
资源成本:蓝绿部署需要双倍资源,这是否在预算之内?
-
发布频率和速度要求:如果需要非常频繁和快速地发布,滚动更新可能更敏捷,而金丝雀发布周期较长。
在实践中,团队也可能 组合使用这些策略。例如,先进行小范围的金丝雀发布,验证核心功能后,再通过滚动更新或蓝绿部署全面铺开。
Go语言本身编译出的高效、轻量的二进制文件,以及其强大的并发处理能力和完善的生态(如Prometheus监控、优雅退出支持),使其非常适合在Kubernetes这样的云原生环境中采用这些先进的平滑发布策略,从而实现真正意义上的持续交付和快速迭代。
小结
这节课,我们入门了Kubernetes的核心概念(如Pod、Service、Deployment、ConfigMap、Secret),并重点讨论了在K8s中部署Go服务的典型模式。这包括如何编写Deployment和Service的YAML文件,如何通过环境变量或挂载卷管理配置,如何为Go应用实现有效的健康检查(Liveness、Readiness、Startup Probes),以及如何设置资源请求与限制。我们还简要提及了日志和监控的集成思路。
最后,也是非常关键的一环,我们详细剖析了主流的平滑发布策略:滚动更新、蓝绿部署与金丝雀发布。我们分析了每种策略的原理、优缺点、在Kubernetes中的实现思路,以及Go应用如何配合这些策略来实现无缝升级。
这两节课,我们深入探讨了Go应用从代码完成到生产环境部署和持续升级的关键环节,重点拥抱了云原生的理念和实践。你不仅掌握了将Go应用部署到生产环境并实现平滑升级的核心技术和策略,更对Go在云原生时代如何大放异彩有了更深的理解。这将是你构建和运维大规模、高可用Go服务的重要一步。
思考题
-
你的团队目前正在为一个包含Go后端、PostgreSQL数据库和Redis缓存的Web应用进行开发。请简要描述你会如何使用
docker-compose.yml来搭建本地开发环境,特别是如何处理Go应用的代码热重载和与数据库/缓存的连接(例如,服务名如何解析,配置如何传递)。 -
当这个应用准备上生产时,从你设计的Docker Compose环境迁移到Kubernetes部署,你会主要关注哪些配置和管理上的关键差异点需要适配和调整(例如,在服务发现、配置管理方式、持久化存储方案、健康检查实现、以及资源管理等方面,K8s与Compose有何不同,你的Go应用需要如何适应这些变化)?
欢迎在留言区分享你的思考和方案!我是Tony Bai,我们下节课见。
故障诊断:线上问题排查的利器与策略(上)
你好,我是Tony Bai。
在前面的课程中,我们已经学习了如何为Go应用构建健壮的应用骨架、核心组件,如何进行容器化部署和实现平滑的线上升级。特别是 《可观测性:Metrics、Logging、Tracing,让你的Go服务不再是黑盒》 这节课,为我们构建了一套强大的“雷达系统”,通过日志、指标和追踪,辅以告警机制,能够帮助我们及时发现线上服务出现的异常。
然而, 当告警的铃声响起,或者用户反馈的问题如雪片般飞来,日志信息有时却像一本密码本,指标曲线也只是描绘了症状而非病因,Trace链条可能在中途断裂或指向一个模糊的区域。这时,真正的挑战才刚刚开始:如何从纷繁复杂的现象中剥茧抽丝,快速、准确地定位到问题的根源? 不同的问题类型——是潜藏的程序逻辑错误,还是难以捉摸的并发异常,抑或是缓慢蚕食资源的性能瓶颈——它们是否需要我们亮出不同的诊断“兵器”和应对策略?
这正是接下来两节课我们要聚焦的核心: 在可观测性系统发出预警之后,我们将深入探讨深度诊断的阶段。我们将学习如何对线上Go应用出现的问题进行有效分类,并针对不同类型的问题,掌握Go生态中一系列强大的诊断工具和高级定位技巧。目标是让你能够像一位经验丰富的“应用医生”一样,高效地找到问题的根因,为后续的修复和优化工作打下坚实的基础,最终保障线上服务的稳定与高效。
线上问题诊断的通用策略与问题分类
在正式介绍各种诊断工具之前,我们首先需要建立一个结构化的诊断思维框架。面对线上问题,慌乱和盲目尝试往往会浪费宝贵的时间,甚至可能使问题恶化。一个清晰的诊断流程和对问题类型的准确判断,是高效排查的前提。
诊断流程概览:从现象到根因
线上问题的诊断就像医生看病,需要遵循一定的章法,从表面的“症状”入手,通过一系列的“检查”和“分析”,最终找到“病根”。虽然每个问题都有其独特性,但一个通用的诊断流程可以帮助我们系统性地思考和行动。
我们可以用下图来概括这个诊断流程的主要阶段:
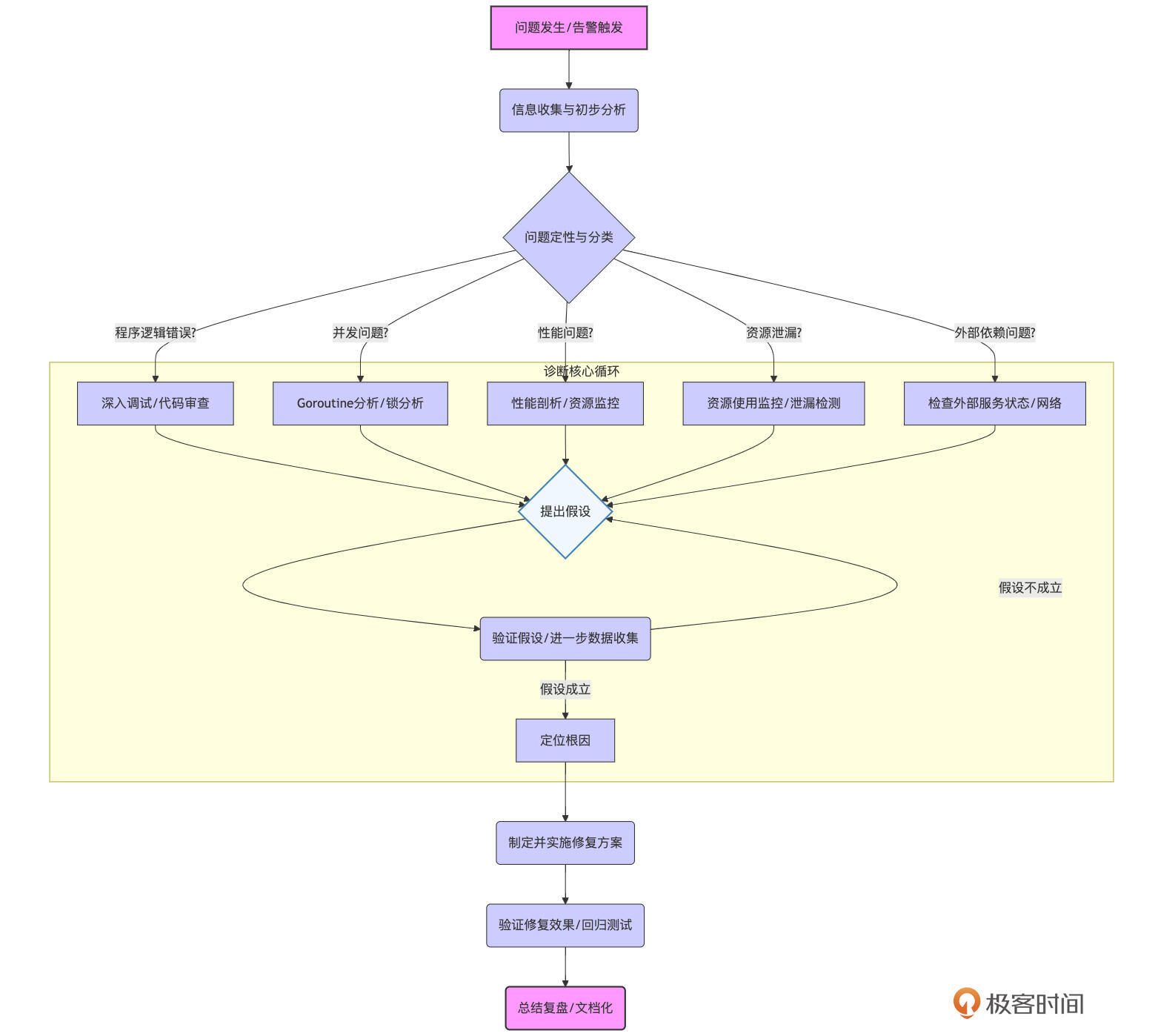
上图展示了这个迭代的诊断过程,具体来说,它通常包含以下关键步骤:
-
信息收集与初步分析:当问题发生或告警被触发时,首先要做的是全面收集与问题相关的所有信息。这包括:
-
告警信息:详细阅读告警内容,了解是哪个指标触发了告警、具体的阈值、发生的时间点以及持续时长。
-
日志分析:仔细查阅问题发生时间点前后相关的服务日志,特别是ERROR和WARN级别的日志。关注是否有异常堆栈、特定的错误码或者不寻常的日志模式。结构化日志中的上下文信息(如TraceID、UserID、RequestID)对于关联事件非常有价值。
-
指标监控数据:查看监控系统(如Prometheus、Grafana)中与问题服务相关的核心指标曲线,例如:QPS(每秒请求数)、请求延迟(平均值、P95、P99)、错误率、CPU使用率、内存使用率、goroutine数量、GC活动频率和暂停时间等。通过指标可以快速判断问题的影响范围和严重程度。
-
分布式追踪数据:如果系统集成了分布式追踪(如Jaeger、Tempo、OpenTelemetry),根据TraceID查找有问题的请求链路,可以帮助定位瓶颈或错误发生的具体服务和操作环节。
-
用户反馈/业务现象:详细了解用户报告的问题现象、他们正在执行的操作、问题发生的时间、影响范围等。这些一手信息往往能提供重要线索。
-
复现步骤(如果可能):尝试在测试环境或一个隔离的、影响可控的生产环境(如果条件允许)中复现问题。能够稳定复现问题,对于后续的深入分析和调试至关重要。
-
-
问题初步定性与分类:在收集到足够的信息后,需要对问题的性质进行初步判断和分类。这是为了帮助我们选择正确的诊断方向和工具。例如,这个问题看起来更像是一个功能性的Bug,还是性能瓶颈?是系统资源耗尽,还是并发逻辑引入的死锁或竞争?问题是持续性的,还是偶发性的?影响是全局的,还是只针对特定用户或特定场景?
-
假设与验证:基于初步的定性和分类,我们会对问题的可能根因提出一个或多个假设。例如:“我怀疑是最近上线的一个新功能引入了内存泄漏”,或者“我认为是数据库连接池配置不当导致了请求超时”。然后,针对每个假设,我们需要设计具体的验证方案,这可能包括:
-
查阅特定模块的代码。
-
进一步收集更细粒度的日志或指标。
-
使用性能剖析工具。
-
在测试环境中构造特定场景进行复现。
-
进行A/B测试或回滚特定变更。
-
-
缩小范围,定位根因:通过不断地提出假设、进行验证、排除不相关的因素,我们逐步缩小问题的可能范围,最终定位到导致问题的具体代码片段、配置项、环境因素或外部依赖。这个过程可能需要反复迭代。
-
修复与验证:(虽然修复本身超出了本节课“诊断”的范畴,但它是诊断的最终目的)一旦找到根因,就需要制定并实施修复方案。修复后,必须通过严格的测试(单元测试、集成测试、回归测试)和持续的监控来验证问题是否已彻底解决,并且没有引入新的问题。
-
总结与复盘:问题解决后,进行全面的复盘是非常重要的。记录问题的现象、诊断过程、根因分析、解决方案以及可以采取的预防措施。将这些经验教训文档化,分享给团队,有助于避免类似问题再次发生,并提升整个团队的故障处理能力。
这个诊断流程并非一成不变的线性过程,很多时候需要在不同步骤之间来回跳转,例如,在验证假设时发现新的信息,可能需要重新回到信息收集或问题分类阶段。但拥有这样一个结构化的框架,能帮助我们在面对复杂问题时保持清晰的思路。
对问题进行准确的分类,是选择后续诊断工具和策略的第一步。接下来,我们就来看看Go线上服务中一些常见的问题类型。
Go线上常见问题分类
为了更有针对性地选择诊断“武器库”,我们可以将Go线上服务中遇到的问题大致归为以下几类。理解这些分类有助于我们在诊断初期快速形成判断,并采取合适的排查路径。
首先是程序逻辑错误,也就是我们常说的Bugs。
这类问题通常表现为应用的功能行为不符合预期。例如,一个计算函数返回了错误的结果;一个API接口在处理特定输入时崩溃(panic),可能源于nil指针解引用、数组越界或不正确的类型断言;或者错误处理流程不当,导致重要错误被忽略,或者错误信息丢失了关键的上下文,使得后续排查困难。这类问题的特点是,它们通常与代码的特定执行路径和输入数据紧密相关,一旦触发条件满足,问题往往能够稳定复现。
其次,并发问题是Go应用中一类独特且具有挑战性的问题。
Go语言强大的并发能力是一把双刃剑,如果使用不当,很容易引入难以察觉的并发缺陷。常见的并发问题包括:
-
死锁(Deadlocks):多个goroutine因相互等待对方持有的资源(如互斥锁、channel)而形成循环等待,导致所有相关的goroutine都永久阻塞,无法继续执行。
-
活锁(Livelocks):goroutine们虽然在活动(CPU可能还在消耗),但它们在徒劳地重复某些操作以响应其他goroutine的行为,却无法取得任何实质进展,就像两个人同时给对方让路结果谁也过不去一样。
-
Goroutine泄漏(Goroutine Leaks):goroutine在完成其任务后(或者因为某些条件永远无法满足而无法完成任务)没有正常退出,导致其占用的资源(主要是栈内存)无法被回收。如果泄漏的goroutine数量持续增长,最终会耗尽系统内存,导致应用OOM(Out Of Memory)被杀死。
-
数据竞争(Data Races):两个或多个goroutine在没有适当同步机制(如互斥锁)保护的情况下,同时访问(且至少一个是写操作)同一块共享内存区域。这会导致程序的行为变得不可预测,结果可能因goroutine的执行时序而异。虽然
go test -race能在测试阶段发现大部分数据竞争,但仍有少数情况可能在线上因特定并发模式或配置问题而触发,或者在测试覆盖不到的边缘代码中出现。
并发问题的特点是它们往往具有非确定性,难以稳定复现,其行为与goroutine的调度和执行时序密切相关。
再次,性能问题是线上服务质量的直接体现。
即便功能完全正确,如果应用响应缓慢或资源消耗过高,用户体验也会大打折扣。常见的性能问题表现为:
-
CPU飙高/过度消耗:应用进程长时间占用过高的CPU资源,可能是由于低效的算法、密集的计算或者失控的循环等。
-
内存泄漏/OOM:应用的内存使用量持续不合理地增长,并且无法被垃圾回收器(GC)有效回收,最终可能导致内存耗尽,触发OOM被操作系统杀死。
-
响应延迟过大/抖动:API请求的处理时间或后台任务的执行时间远超预期,或者响应时间非常不稳定,时快时慢。
-
吞吐量下降:应用在单位时间内能够成功处理的请求数或完成的任务数显著低于正常水平。性能问题可能由多种原因引起,包括但不限于低效的算法实现、不恰当的数据结构选择、过度的锁竞争、GC压力过大、以及外部I/O(网络、磁盘)瓶颈等。
然后,还有一类是资源问题,特指除了CPU和内存之外的其他系统资源的耗尽或管理不当。 例如:
-
文件句柄泄漏(File Descriptor Leaks):应用在打开文件、网络连接(socket)等需要文件句柄的资源后,未能正确关闭它们,导致系统中可用的文件句柄数量逐渐耗尽。当达到上限时,应用将无法再打开新的文件或建立新的网络连接。
-
网络连接耗尽:对于需要与大量下游服务交互的应用,如果连接池管理不当(例如,连接池太小导致请求排队,或者连接未及时归还和复用),或者创建了过多无法及时释放的临时连接,都可能导致端口耗尽或连接数达到系统上限。
-
其他系统资源耗尽:例如,信号量、共享内存段、线程数(如果应用大量使用了cgo或依赖于创建OS线程的库)等。
这类问题通常表现为应用在运行一段时间后,开始出现无法创建新连接、打开新文件等相关的错误。
最后,外部依赖问题也需要我们在诊断时加以区分。
很多时候,我们的应用功能异常或性能下降,其根源并不在应用自身,而是由于其依赖的下游服务(如数据库、缓存、消息队列、第三方API等)出现了故障、性能瓶颈,返回了错误数据,或者网络连接不稳定。在这种情况下,我们的应用可能只是一个“受害者”。诊断时,我们需要有能力通过日志、指标和追踪数据来判断问题是否源于外部,以便将问题正确地上报或转交给相关的团队处理。
对线上问题进行这样的初步分类,能帮助我们更有针对性地选择后续的诊断工具和分析策略,从而更快地逼近问题的真相。
在所有这些问题类型中,程序逻辑错误(Bugs)和运行时Panic可能是开发者最常直接面对的。当应用的日志和指标指向了某个功能异常,或者一个未被捕获的panic导致服务中断时,我们就需要深入到代码的执行层面,去理解那一刻究竟发生了什么。
诊断程序逻辑错误与运行时Panic
程序逻辑错误,即我们常说的Bug,是软件开发过程中难以完全避免的“副产品”。它们可能源于对需求的细微误解、算法设计上的缺陷、对边界条件的考虑不周,或者是对Go语言特性及标准库函数的不当使用。当这些错误潜藏在复杂的业务逻辑中,仅通过日志难以直接定位,或者当它们以一个运行时panic的形式突然爆发,导致服务中断时,我们就需要有更直接、更深入的手段来剖析代码的实际执行情况。
在探讨高级调试工具之前,我们先回顾一下最原始但也最直接的调试方法。
Printf调试法的局限与适用场景
在许多开发者(尤其是初学者)的工具箱中, fmt.Println 或 log.Printf 等打印语句往往是遇到问题时的第一反应。通过在代码的关键路径上插入这些“探针”,输出变量的当前值、函数的调用顺序,或者某个条件分支是否被执行,确实能够在一定程度上帮助我们理解程序的行为,尤其是在一些简单场景下。例如,当一个计算结果不符合预期时,在计算过程的几个关键步骤打印中间变量的值,往往能快速发现是哪一步出了问题。
printf调试法尤其适合以下场景:
-
快速验证简单逻辑:对于一些小段代码或独立函数的行为验证,Printf调试非常便捷。
-
无法使用或不便使用调试器的环境:在某些严格受限的生产环境(如果策略允许临时修改和部署)、嵌入式系统,或者难以附加调试器的复杂并发场景(尽管打印本身可能干扰并发行为)中,打印日志可能是获取内部状态的少数可行手段之一。
-
复现困难的偶发问题:对于那些难以稳定复现、无法通过断点稳定捕获的问题,预先在可疑代码路径上埋点打印详细的上下文日志,有助于在问题下一次偶然发生时,捕获到足够的信息来分析根源。
然而,Printf调试法的缺点也非常突出,使其在面对复杂问题时显得力不从心:
-
侵入性强且流程繁琐:需要直接修改源代码,添加打印语句,然后重新编译、部署、运行。调试结束后,还需要记得移除或注释掉这些临时代码,否则会污染生产日志或影响性能。这个过程本身就容易引入新的错误或遗漏。
-
信息片面且静态:只能打印出你在编码时预先决定要看的信息。一旦运行起来,如果发现需要看其他变量的状态,或者想深入某个函数调用,就必须重复“修改-编译-运行”的循环。
-
效率低下:对于复杂的逻辑链条或大量的迭代,可能需要添加非常多的打印点,导致输出信息泛滥,难以从中筛选有效内容。
-
难以处理复杂数据:对于大型结构体、嵌套对象或长切片/映射,简单打印其内容可能非常不直观,甚至因输出过长而无法有效阅读。
-
对并发程序行为的潜在干扰:大量的I/O操作(打印到控制台或文件)本身会消耗时间,这可能会改变goroutine的调度时序和执行顺序,有时甚至会“巧合地”掩盖或改变并发问题的表现。同时,来自不同goroutine的打印输出交织在一起,也可能难以解读。
因此,虽然Printf调试法因其简单易上手而有其用武之地,但当我们需要更系统、更深入、更交互式地探查程序状态时,专业的调试工具就成为了必然的选择。
对于Go语言而言, Delve 无疑是这个领域的事实标准。
交互式调试利器:Delve深度应用技巧
Delve是专为Go语言从头设计的、功能强大的源码级调试器。它深刻理解Go的运行时、goroutine调度以及语言特性,为我们提供了在运行时暂停程序、检查状态、单步执行代码、分析调用栈等一系列强大的交互式调试能力。
Delve核心交互流程
Delve与开发者之间有一套结构化的核心调试交互流程。我们可以通过下图来理解其核心的交互步骤:
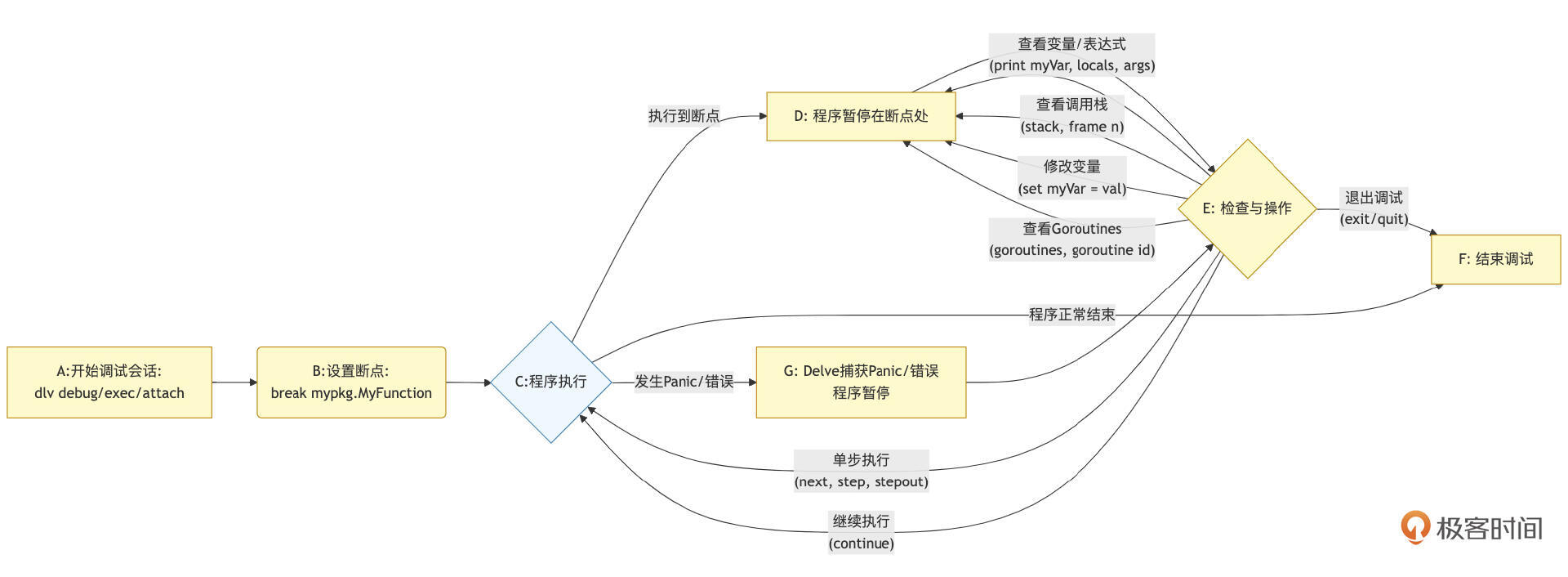
下面我们就结合这幅示意图,对Delve的核心交互流程做个简单说明。
-
开始调试会话(A):通过
dlv debug(编译并启动)、dlv exec(调试已编译程序)或dlv attach(附加到已运行进程)来启动Delve。 -
设置断点(B):使用
break命令在代码的关键位置(如函数入口、特定行号)设置一个或多个断点。 -
程序执行(C):使用
continue命令(或Delve启动后自动开始执行,取决于启动方式)让程序运行。-
如果程序执行到断点,会进入 程序暂停状态(D)。
-
如果程序正常执行结束,会进入 结束调试状态(F)。
-
如果程序发生未捕获的Panic或错误,Delve会捕获它并使程序暂停在 Panic/错误点(G)。
-
-
程序暂停在断点处(D)/ Panic点(G):此时,控制权交还给Delve命令行。
-
检查与操作(E):在程序暂停时,开发者可以执行一系列Delve命令来检查程序状态或控制后续执行:
-
查看变量/表达式:使用
print、locals、args等命令查看当前上下文的变量值和表达式结果。 -
查看调用栈:使用
stack、frame等命令分析函数调用路径。 -
单步执行:使用
next(逐行,不进入函数)、step(逐行,进入函数)、stepout(执行完当前函数并返回)来细致地跟踪代码执行。单步执行后,程序会再次暂停,流程回到(C) ->(D)。 -
继续执行:使用
continue让程序继续运行到下一个断点、结束或发生错误。流程回到(C)。 -
修改变量:(慎用,可能会改变程序行为)使用
set命令在运行时修改变量的值。 -
查看Goroutines:(对于并发程序)使用
goroutines、goroutine <id>等命令检查和切换goroutine上下文。 -
退出调试:使用
exit或quit命令结束调试会话,流程进入(F)。
-
-
结束调试(F):Delve会话结束,程序(如果仍在运行)可能会被终止。
可以说,这个流程图清晰地展示了Delve的交互式特性:开发者通过命令在“执行”和“检查/控制”状态之间切换,逐步深入理解程序的行为并定位问题。
虽然在高度敏感的生产环境中直接附加调试器进行长时间的交互式调试通常是不推荐的(因为它会暂停服务或影响性能),但在某些受控的线上诊断场景下,或者在与生产环境高度一致的预发/灰度环境中, Delve的远程调试和Core Dump分析能力能发挥巨大作用。前提是,团队制定了严格的线上调试规范和权限控制,并且操作人员经验丰富。
我们先来看看远程调试是如何工作的。
Delve远程调试的步骤
当你的Go应用运行在一个远程服务器、容器(如Docker、Kubernetes Pod)或者你无法直接登录操作的环境中时,Delve的远程调试功能允许你在本地开发机上通过网络连接到远端的Delve服务,并像调试本地程序一样进行交互。
其核心关系、流程及操作步骤可以结合下图来理解:
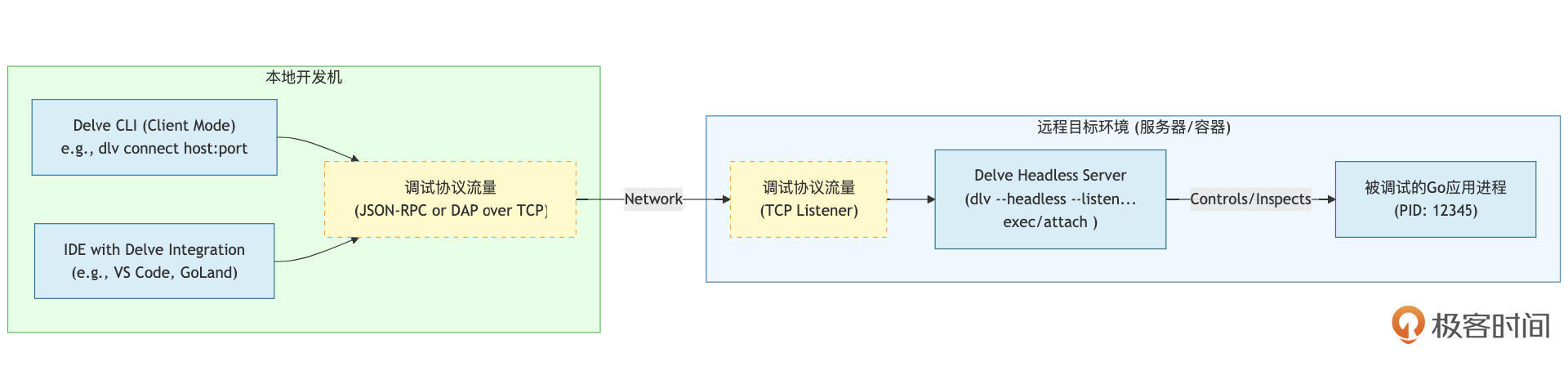
结合示意图,我们再对 远程调试的工作流程与关键组件 做一些简单地说明。
在进行远程调试时,第一步是在远程目标环境中启动Delve Headless服务器( DelveServer)。确保目标机器上已安装 dlv,然后以无头模式启动Delve。这种模式下,Delve不会启动交互式命令行界面,而是作为服务器运行,等待调试客户端的连接。此时,Delve服务器可以附加到已经在运行的Go应用进程( TargetGoApp),或直接执行你的Go应用的可执行文件。为了确保Delve能够正常工作,建议在编译Go应用时加入调试信息并禁用优化。
你可以使用以下命令启动Delve服务器:
dlv --headless --listen=:2345 --api-version=2 --accept-multiclient exec ./myapp_for_debug -- <your_app_arguments_if_any>
或者,如果你的Go应用已经在运行(例如,PID为12345),则可以附加到该进程:
dlv --headless --listen=:2345 --api-version=2 --accept-multiclient attach 12345
在此命令中, --listen=:2345 指定了Delve服务器的监听地址和端口, --api-version=2 使用推荐的调试协议版本,而 --accept-multiclient 则允许多个调试客户端同时连接到同一Delve服务器。启动后, DelveServer 将控制 TargetGoApp 的执行,并准备通过网络接收调试指令。
接下来,在本地开发机上需要启动Delve客户端( LocalCLI 或IDE)并连接到远程服务器。确保你的本地开发机器上也安装了 dlv。你可以使用 dlv connect 命令或通过IDE(如VS Code或GoLand)连接到远程的Delve Headless Server。例如,命令如下:
dlv connect <remote_target_host_ip_or_dns>:2345
在IDE中,你只需配置远程调试目标,输入远程主机的IP或DNS名称及Delve服务器监听的端口(2345)。此时,本地的Delve实例或IDE充当调试客户端的角色。
一旦连接成功,本地Delve客户端(或IDE的调试界面)便可以向远程的 DelveServer 发送调试命令,例如设置断点、继续执行、单步执行、查看变量、查看调用栈等。 DelveServer 接收到这些命令后,会在 TargetGoApp 上执行相应操作,并将结果通过网络回传给本地的调试客户端显示。整个过程对于本地开发者来说,体验与调试本地程序非常相似,只是指令和数据在网络间传递。
Delve远程调试示例
为了更具体地感受Delve的交互式调试过程,让我们通过一个更贴近线上场景的例子,来演示如何使用Delve的远程调试功能来诊断一个正在运行的服务中发生的panic。
假设我们有一个简单的HTTP服务,它有一个正常的 /ping 接口和一个会导致panic的 /oops 接口。当 /oops 被访问时,服务会panic。我们将模拟在线上(或一个独立的测试环境)运行这个服务,当它panic后(或者为了调试方便,我们让它在panic前等待),我们从本地通过Delve远程连接上去进行诊断。
下面是被调试的Go HTTP服务的代码片段:
// ch28/remote_panic_service/main.go
package main
import (
"fmt"
"log"
"net/http"
"os"
"runtime/debug" // 用于在panic时打印堆栈并保持进程
"time"
)
var shouldPanicImmediately = false // 控制是否在panic后立即退出,还是等待调试
func criticalOperation(input string) {
if input == "trigger_panic" {
log.Println("CRITICAL: About to perform an operation that will panic!")
var data []int
// 故意制造一个越界panic
fmt.Println("Accessing out of bounds:", data[5]) // PANIC!
}
log.Printf("CRITICAL: Operation with input '%s' completed successfully (simulated).\n", input)
}
func oopsHandler(w http.ResponseWriter, r *http.Request) {
log.Println("OOPS_HANDLER: Received request for /oops, preparing to panic...")
// 在实际生产panic场景,程序会直接退出或被重启策略拉起。
// 为了演示调试,我们可以在这里加入一个延迟或特定条件,
// 使得在panic发生后,进程不会立即消失,给我们附加调试器的时间。
// 或者,如果 'shouldPanicImmediately' 为 false,我们捕获panic,打印堆栈,然后死循环等待调试。
if !shouldPanicImmediately {
defer func() {
if r := recover(); r != nil {
log.Printf("PANIC RECOVERED (for debugging): %v\n", r)
log.Println("Stacktrace from recover:")
debug.PrintStack() // 打印当前goroutine的堆栈
// 为了让Delve有机会附加,这里让goroutine进入一个可控的等待状态
// 在真实的线上panic(未recover或recover后os.Exit),进程会终止。
// 如果是K8s等环境,Pod会被重启。
// Core Dump是分析这种已终止进程panic的常用手段。
// 这里我们模拟的是一个“卡住”而非立即退出的panic场景。
log.Println("Process will now hang, waiting for debugger to attach to its PID...")
for { // 无限循环,让进程保持存活
time.Sleep(1 * time.Minute)
}
}
}()
}
// 触发panic
criticalOperation("trigger_panic") // 这个调用会panic
// 这行不会被执行
fmt.Fprintln(w, "If you see this, something went wrong with the panic trigger!")
}
func pingHandler(w http.ResponseWriter, r *http.Request) {
log.Println("PING_HANDLER: Received request for /ping")
fmt.Fprintln(w, "PONG!")
}
func main() {
// 从环境变量读取是否立即panic退出的配置
if os.Getenv("PANIC_IMMEDIATELY") == "true" {
shouldPanicImmediately = true
}
pid := os.Getpid()
log.Printf("Starting HTTP server on :8080 (PID: %d)...", pid)
log.Printf(" Normal endpoint: http://localhost:8080/ping")
log.Printf(" Panic endpoint: http://localhost:8080/oops")
if !shouldPanicImmediately {
log.Println(" NOTE: On /oops panic, this demo server will recover, print stack, and hang for debugging.")
log.Println(" In a real production scenario without such a recover, the process would terminate.")
}
http.HandleFunc("/ping", pingHandler)
http.HandleFunc("/oops", oopsHandler)
if err := http.ListenAndServe(":8080", nil); err != nil {
log.Fatalf("Failed to start server: %v", err)
}
}
下面我们来讲一下构建执行该服务、触发panic及远程调试的步骤。
阶段一:在“远程”环境启动服务和Delve Headless Server。
- 编译Go服务(推荐带调试信息):
# 进入 ch28/remote_panic_service目录
$go build -gcflags="all=-N -l" -o remote_panic_server main.go
- 运行Go服务。 在服务器终端中启动该服务:
# 在服务器终端中运行
$./remote_panic_server
2025/06/02 12:09:30 Starting HTTP server on :8080 (PID: 1286962)...
2025/06/02 12:09:30 Normal endpoint: http://localhost:8080/ping
2025/06/02 12:09:30 Panic endpoint: http://localhost:8080/oops
2025/06/02 12:09:30 NOTE: On /oops panic, this demo server will recover, print stack, and hang for debugging.
2025/06/02 12:09:30 In a real production scenario without such a recover, the process would terminate.
我们看到该服务启动后会打印出其PID:1286962,记下这个PID。
3. 触发Panic。
为了让Delve能附加到一个已发生panic(并被我们代码中的 recover 捕获并“卡住”)的状态,我们需要先触发它。打开浏览器或使用curl访问 http://localhost:8080/oops。服务器终端应该会打印出panic被recover的信息和堆栈,然后开始“hang”住。
// 触发panic后,remote_panic_server的日志输出
2025/06/02 12:09:40 OOPS_HANDLER: Received request for /oops, preparing to panic...
2025/06/02 12:09:40 CRITICAL: About to perform an operation that will panic!
2025/06/02 12:09:40 PANIC RECOVERED (for debugging): runtime error: index out of range [5] with length 0
2025/06/02 12:09:40 Stacktrace from recover:
goroutine 7 [running]:
runtime/debug.Stack()
/root/.bin/go1.24.1/src/runtime/debug/stack.go:26 +0x6b
runtime/debug.PrintStack()
/root/.bin/go1.24.1/src/runtime/debug/stack.go:18 +0x13
main.oopsHandler.func1()
/root/test/goadv/ch28/remote_panic_service/main.go:36 +0x13a
panic({0x89d200?, 0xc00001a1b0?})
/root/.bin/go1.24.1/src/runtime/panic.go:792 +0x136
main.criticalOperation({0x8bb8f6, 0xd})
/root/test/goadv/ch28/remote_panic_service/main.go:19 +0x3ae
main.oopsHandler({0x8f6a20, 0xc0000000e0}, 0xc000160000)
/root/test/goadv/ch28/remote_panic_service/main.go:52 +0xf0
net/http.HandlerFunc.ServeHTTP(0x8d5ca8, {0x8f6a20, 0xc0000000e0}, 0xc000160000)
/root/.bin/go1.24.1/src/net/http/server.go:2294 +0x33
net/http.(*ServeMux).ServeHTTP(0xae9d40, {0x8f6a20, 0xc0000000e0}, 0xc000160000)
/root/.bin/go1.24.1/src/net/http/server.go:2822 +0x3c2
net/http.serverHandler.ServeHTTP({0xc00013a200}, {0x8f6a20, 0xc0000000e0}, 0xc000160000)
/root/.bin/go1.24.1/src/net/http/server.go:3301 +0x257
net/http.(*conn).serve(0xc000134240, {0x8f6e28, 0xc000138190})
/root/.bin/go1.24.1/src/net/http/server.go:2102 +0x1b75
created by net/http.(*Server).Serve in goroutine 1
/root/.bin/go1.24.1/src/net/http/server.go:3454 +0xa9a
2025/06/02 12:09:40 Process will now hang, waiting for debugger to attach to its PID...
- 在“远程”环境启动Delve Headless Server并attach到Go服务进程。 在另一个服务器终端中,使用之前记下的PID启动Delve Headless Server。
$ dlv --headless --listen=:2345 --api-version=2 --accept-multiclient attach 1286962
API server listening at: [::]:2345
2025-06-02T12:10:37Z warn layer=rpc Listening for remote connections (connections are not authenticated nor encrypted)
attach成功后,目标Go服务进程的执行实际上是被Delve暂停了(或者如果它之前在无限循环中,也会被Delve接管)。
注:如果没有安装delve调试器,可以使用go install github.com/go-delve/delve/cmd/dlv@latest安装dlv 。
阶段二:在本地开发机通过Delve客户端进行远程调试。
- 连接到远程Delve服务器。
在你的本地开发机(或另一个终端,如果都在本地模拟)上,运行 dlv connect:
# 假设远程服务器IP是 <remote_server_ip>,如果都在本地,可以是 localhost 或 127.0.0.1
dlv connect localhost:2345
如果连接成功,你会看到Delve的 (dlv) 提示符。
2. 诊断Panic。
由于我们是在 /oops 接口触发panic后(并被recover和hang住)附加的,我们期望能看到与该panic相关的goroutine和调用栈。我们先查看所有goroutine:
(dlv) goroutines
Goroutine 1 - User: /root/.bin/go1.24.1/src/net/fd_unix.go:172 net.(*netFD).accept (0x5caaa9) [IO wait]
Goroutine 2 - User: /root/.bin/go1.24.1/src/runtime/proc.go:436 runtime.gopark (0x479e71) [force gc (idle)]
Goroutine 3 - User: /root/.bin/go1.24.1/src/runtime/proc.go:436 runtime.gopark (0x479e71) [GC sweep wait]
Goroutine 4 - User: /root/.bin/go1.24.1/src/runtime/proc.go:436 runtime.gopark (0x479e71) [GC scavenge wait]
Goroutine 5 - User: /root/.bin/go1.24.1/src/runtime/proc.go:436 runtime.gopark (0x479e71) [finalizer wait]
Goroutine 6 - User: /root/.bin/go1.24.1/src/runtime/proc.go:436 runtime.gopark (0x479e71) [chan receive]
Goroutine 7 - User: /root/.bin/go1.24.1/src/runtime/time.go:338 time.Sleep (0x47d51c) [sleep]
Goroutine 8 - User: /root/.bin/go1.24.1/src/net/fd_posix.go:55 net.(*netFD).Read (0x5c9093) [IO wait]
[8 goroutines]
我们看到了多个goroutine。其中一个(通常是处理HTTP请求的那个)的堆栈顶部停在我们 recover 后的无限循环 time.Sleep 处。找到这个goroutine的ID,这里是goroutine 7。
切换到goroutine 7:
(dlv) goroutine 7
Switched from 0 to 7 (thread 1286962)
查看goroutine 7的完整调用栈信息:
(dlv) stack -full
0 0x0000000000479e71 in runtime.gopark
at /root/.bin/go1.24.1/src/runtime/proc.go:436
unlockf = runtime.resetForSleep
lock = unsafe.Pointer(0x0)
reason = waitReasonSleep (19)
traceReason = traceBlockSleep (14)
traceskip = 1
mp = (*runtime.m)(0xaeac80)
gp = (*runtime.g)(0xc0001361c0)
status = (unreadable could not find loclist entry at 0xb1929 for address 0x479e71)
1 0x000000000047d51c in time.Sleep
at /root/.bin/go1.24.1/src/runtime/time.go:338
ns = 60000000000
gp = (*runtime.g)(0xc0001361c0)
t = (unreadable could not find loclist entry at 0xb4c56 for address 0x47d51c)
now = (unreadable could not find loclist entry at 0xb4cea for address 0x47d51c)
when = (unreadable could not find loclist entry at 0xb4d43 for address 0x47d51c)
2 0x000000000073bfe6 in main.oopsHandler.func1
at /root/test/goadv/ch28/remote_panic_service/main.go:45
r = interface {}(runtime.boundsError) {x: 5, y: 0, signed: true,...+1 more}
3 0x0000000000479936 in runtime.gopanic
at /root/.bin/go1.24.1/src/runtime/panic.go:792
e = (unreadable error loading module data: read out of bounds)
gp = (unreadable could not find loclist entry at 0xb1461 for address 0x479936)
p = runtime._panic {argp: unsafe.Pointer(0xc000169250), arg: interface {}(runtime.boundsError) *(*interface {})(0xc000169280), link: *runtime._panic nil,...+11 more}
ok = (unreadable could not find loclist entry at 0xb14c9 for address 0x479936)
fn = (unreadable could not find loclist entry at 0xb14fc for address 0x479936)
4 0x00000000004416f4 in runtime.goPanicIndex
at /root/.bin/go1.24.1/src/runtime/panic.go:115
x = 5
y = 0
5 0x000000000073b54e in main.criticalOperation
at /root/test/goadv/ch28/remote_panic_service/main.go:19
input = "trigger_panic"
data = []int len: 0, cap: 0, nil
6 0x000000000073b710 in main.oopsHandler
at /root/test/goadv/ch28/remote_panic_service/main.go:52
w = net/http.ResponseWriter(*net/http.response) 0xc000169520
r = ("*net/http.Request")(0xc000160000)
7 0x000000000071d633 in net/http.HandlerFunc.ServeHTTP
at /root/.bin/go1.24.1/src/net/http/server.go:2294
f = main.oopsHandler
w = net/http.ResponseWriter(*net/http.response) 0xc000169550
r = ("*net/http.Request")(0xc000160000)
8 0x0000000000720762 in net/http.(*ServeMux).ServeHTTP
at /root/.bin/go1.24.1/src/net/http/server.go:2822
mux = ("*net/http.ServeMux")(0xae9d40)
w = net/http.ResponseWriter(*net/http.response) 0xc000169650
r = ("*net/http.Request")(0xc000160000)
h = net/http.Handler(net/http.HandlerFunc) main.oopsHandler
... ...
现在你应该能看到导致panic的完整调用栈,从栈顶往下查找,你会找到 main.criticalOperation 中的 data[5],以及调用它的 main.oopsHandler。这时我们可以跳到对应的Frame,检查相关变量状态:
(dlv) bt
0 0x0000000000479e71 in runtime.gopark
at /root/.bin/go1.24.1/src/runtime/proc.go:436
1 0x000000000047d51c in time.Sleep
at /root/.bin/go1.24.1/src/runtime/time.go:338
2 0x000000000073bfe6 in main.oopsHandler.func1
at /root/test/goadv/ch28/remote_panic_service/main.go:45
3 0x0000000000479936 in runtime.gopanic
at /root/.bin/go1.24.1/src/runtime/panic.go:792
4 0x00000000004416f4 in runtime.goPanicIndex
at /root/.bin/go1.24.1/src/runtime/panic.go:115
5 0x000000000073b54e in main.criticalOperation
at /root/test/goadv/ch28/remote_panic_service/main.go:19
6 0x000000000073b710 in main.oopsHandler
at /root/test/goadv/ch28/remote_panic_service/main.go:52
7 0x000000000071d633 in net/http.HandlerFunc.ServeHTTP
at /root/.bin/go1.24.1/src/net/http/server.go:2294
8 0x0000000000720762 in net/http.(*ServeMux).ServeHTTP
at /root/.bin/go1.24.1/src/net/http/server.go:2822
9 0x000000000072bdd7 in net/http.serverHandler.ServeHTTP
at /root/.bin/go1.24.1/src/net/http/server.go:3301
10 0x000000000071c215 in net/http.(*conn).serve
at /root/.bin/go1.24.1/src/net/http/server.go:2102
11 0x000000000072289c in net/http.(*Server).Serve.gowrap3
at /root/.bin/go1.24.1/src/net/http/server.go:3454
12 0x0000000000481021 in runtime.goexit
at /root/.bin/go1.24.1/src/runtime/asm_amd64.s:1700
(dlv) frame 5
> runtime.gopark() /root/.bin/go1.24.1/src/runtime/proc.go:436 (PC: 0x479e71)
Warning: debugging optimized function
Frame 5: /root/test/goadv/ch28/remote_panic_service/main.go:19 (PC: 73b54e)
(dlv) locals
data = []int len: 0, cap: 0, nil
到这里,结合remote_panic_service的源码,基本可以定位是访问nil切片导致的panic。
3. 结束调试。 使用 exit 断开与远程Delve服务器的连接。
(dlv) exit
Would you like to kill the headless instance? [Y/n] y
Would you like to kill the process? [Y/n] y
在退出之前,我们可以选择是否让远程的Delve服务器也随之退出,以及是否杀掉被调试的Go服务进程。
这个示例的核心在于演示了远程 attach 的流程,以及如何在panic被 recover(并使进程保持存活以便调试)的场景下,通过Delve探查goroutine状态和调用栈来辅助定位问题。
远程调试的几个注意事项
远程调试为开发者提供了强大的能力,可以深入到远端或隔离环境中的Go程序。这在诊断复杂问题时尤为有效,特别是偶发的、仅在特定条件下出现的逻辑错误。通过快速附加Delve进行远程调试,开发者往往能更直接地捕获问题的瞬间状态,而无需分析大量日志。然而,进行远程调试时有几点需要我们注意。
首先,确保远程调试端口(如2345)受到严格的网络访问控制,以防未经授权的访问。可以通过限制特定IP、使用VPN或堡垒机来增强安全性。
其次,远程调试会暂停被调试的goroutine甚至整个目标进程的执行,因此在生产环境中进行此操作必须极其谨慎。应确保目标明确、操作迅速,并尽可能在流量低谷期进行,以避免对整体服务造成不可接受的影响。
最后,为了获得最佳的远程调试体验,目标Go应用最好用包含调试信息的方式编译。然而,在生产环境中,通常会为了性能和体积而去除调试信息。这需要在部署策略中进行权衡。如果计划进行远程调试,可能需要为特定诊断场景准备带调试信息的版本。
到这里,你应该能清晰地理解远程调试的整体架构和操作流程了。
调试已崩溃程序的核心转储
在真实的线上场景,如果一个未被recover的panic导致进程直接崩溃并生成了core dump,那么我们会使用 dlv core <executable> <core_dump_file> 来进行事后分析,其分析过程(查看堆栈、变量等)与交互式调试类似。
当Go应用因未恢复的panic或更底层的错误(如段错误)而异常终止时,如果操作系统配置允许(通常通过 ulimit -c unlimited 或修改 /etc/security/limits.conf 来启用,并配置 kernel.core_pattern),系统会生成一个核心转储文件(core dump)。这个文件是程序崩溃瞬间的内存快照。Delve可以加载这个core dump文件进行离线的事后分析。
$dlv core <path_to_your_go_executable> <path_to_core_dump_file>
加载成功后,虽然程序没有在运行,但Delve会恢复到程序崩溃时的状态。你可以:
-
使用
stack查看导致panic的goroutine的完整调用栈。 -
使用
goroutines查看所有goroutine在崩溃时的状态和位置。 -
使用
print <variable>查看(在可访问范围内的)变量值。
这对于分析那些难以在线上直接调试的、偶发的、导致服务崩溃的致命错误非常有价值。例如,一个由特定输入序列触发的nil指针解引用panic,如果在线上发生,core dump就能帮你还原现场。
Delve通过其丰富的交互式命令,为我们深入探查Go程序的运行时状态提供了无与伦比的能力,是诊断复杂逻辑错误和panic不可或缺的工具。
当然,除了交互式调试,Go运行时本身也提供了一些机制来帮助我们理解程序的行为,尤其是当panic发生时。接下来再看看Go运行时为我们留下的“现场”,以及该如何理解这个“现场”。
理解Panic堆栈与 runtime/debug 包
当Go程序遭遇一个未被 recover 捕获的panic时,它会异常终止,并在终止前打印出导致panic的错误信息以及一个详细的调用堆栈(Call Stack / Stack Trace)。这个堆栈信息是定位panic来源的“第一现场”。
那如何解读Go的panic堆栈信息呢?一个典型的panic堆栈(如此前Delve示例中因数组越界产生的panic)通常包含:
-
panic:关键字,后跟panic的类型(如runtime error)和具体的错误信息(如index out of range [5] with length 0)。 -
触发panic的goroutine的ID和状态(如
goroutine 7 [running]:)。 -
调用栈序列:这是最重要的部分,它自顶向下(从panic直接发生点到goroutine的启动点)列出了函数调用链。每一行通常包含:
-
包名和函数名(如
main.process)。 -
源文件名和行号(如
/path/to/delvepanic/main.go:8)。 -
相对于函数入口的指令偏移量(如
+0xYY)。
-
通过仔细阅读这个调用栈,我们可以从panic发生的直接位置开始,逐层向上回溯,理解函数是如何被调用的,以及在哪个调用路径上触发了问题。
有时,我们可能不希望程序在遇到某些可预见的“严重”错误时直接panic退出,而是希望捕获到类似panic的详细上下文信息(特别是调用栈)用于日志记录或错误报告,然后再决定如何处理(例如,优雅关闭或返回特定错误)。标准库的 runtime/debug 包为此提供了工具:
-
debug.Stack():调用此函数会返回当前goroutine的调用堆栈的格式化字节切片。你可以将其转换为字符串,记录到日志中,或附加到错误信息里。 -
debug.PrintStack():直接将当前goroutine的调用堆栈打印到标准错误(stderr)。
我们来看一个示例:
// ch28/debugstack/main.go
package main
import (
"fmt"
"os"
"runtime/debug"
)
func Bar() {
fmt.Println("In Bar, about to print stack to stderr via debug.PrintStack():")
debug.PrintStack()
}
func Foo() {
fmt.Println("In Foo, calling Bar.")
Bar()
}
func main() {
fmt.Println("Starting main.")
Foo()
if err := someOperationThatMightError(); err != nil {
// 将堆栈信息作为错误上下文的一部分
detailedError := fmt.Errorf("operation failed: %w\nCall stack:\n%s", err, debug.Stack())
fmt.Fprintf(os.Stderr, "%v\n", detailedError)
}
fmt.Println("Finished main.")
}
func someOperationThatMightError() error {
// 模拟一个操作,该操作内部可能还调用了其他函数
return performComplexStep()
}
func performComplexStep() error {
return fmt.Errorf("a simulated error occurred deep in call stack")
}
运行此程序, debug.PrintStack() 会直接将调用 Bar 时的堆栈打印到stderr。而在 main 函数中处理 someOperationThatMightError 返回的错误时,我们通过 debug.Stack() 获取了当时的堆栈,并将其格式化到错误信息中,这对于记录错误上下文非常有用。下面就是该程序在我的本地环境输出的堆栈信息:
// 在ch28/debugstack下执行
$go run main.go
Starting main.
In Foo, calling Bar.
In Bar, about to print stack to stderr via debug.PrintStack():
goroutine 1 [running]:
runtime/debug.Stack()
/Users/tonybai/.bin/go1.24.3/src/runtime/debug/stack.go:26 +0x5e
runtime/debug.PrintStack()
/Users/tonybai/.bin/go1.24.3/src/runtime/debug/stack.go:18 +0x13
main.Bar()
ch28/debugstack/main.go:11 +0x4b
main.Foo()
ch28/debugstack/main.go:16 +0x4b
main.main()
ch28/debugstack/main.go:21 +0x57
operation failed: a simulated error occurred deep in call stack
Call stack:
goroutine 1 [running]:
runtime/debug.Stack()
/Users/tonybai/.bin/go1.24.3/src/runtime/debug/stack.go:26 +0x5e
main.main()
ch28/debugstack/main.go:25 +0x88
Finished main.
在某些类Unix操作系统上,一些底层的运行时错误(如通常导致SIGSEGV信号的nil指针解引用,或非法内存访问)默认可能不会立即以Go panic的形式出现,而是可能先被操作系统信号处理。调用 debug.SetPanicOnFault(true) 可以改变这种行为,使得这些“faults”(故障)总是以Go panic的形式被抛出,从而能打印出Go风格的、包含goroutine信息的调用堆栈,这有时比分析底层的core dump或操作系统信号对Go开发者来说更直接。但要注意,这会改变程序在某些极端错误下的行为模式,应谨慎使用并了解其影响。
通过结合Delve的交互式调试能力和对panic堆栈的细致解读,以及 runtime/debug 包提供的工具,我们可以有效地诊断和定位Go程序中的逻辑错误和运行时panic,为快速修复问题提供坚实的基础。
在诊断完逻辑错误后,并发问题是Go开发者经常需要面对的另一类挑战。我们下一节课会讲到。
小结
这节课,我们一起开始探索Go应用线上故障诊断的复杂世界。
我们首先建立了线上问题诊断的通用流程(信息收集、问题分类、假设验证、定位根因、修复验证、总结复盘),并对Go服务中常见的问题类型(程序逻辑错误、并发问题、性能问题、资源问题)进行了梳理,强调了针对不同问题采用不同诊断工具的重要性。
对于程序逻辑错误与运行时Panic,我们回顾了Printf调试的适用场景与局限,并重点学习了交互式调试器Delve的核心功能与进阶技巧,包括断点、单步执行、变量查看、调用栈分析,以及在线上(或类线上)环境中非常有价值的远程调试和Core Dump分析。同时,我们也理解了如何解读Go的Panic堆栈,并了解了 runtime/debug 包在主动获取堆栈信息方面的应用。
欢迎在留言区分享你的思考和方案!我是Tony Bai,我们下节课见。
故障诊断:线上问题排查的利器与策略(下)
你好,我是Tony Bai。
上节课,我们一起建立了线上问题诊断的通用流程,梳理了Go服务中常见的问题类型,同时对于程序逻辑错误与运行时Panic,我们还回顾了Printf调试的适用场景与局限,并重点学习了交互式调试器Delve的核心功能与进阶技巧。
这节课,我们继续深入Go应用线上故障诊断的复杂世界,来学习如何诊断具体的并发问题和性能问题。
通过这两节课的学习,你在面对线上服务的“疑难杂症”时,就能够胸有成竹,运用恰当的策略和工具。
诊断并发问题:解密Goroutine的行为
Go语言的并发模型虽然强大,但也引入了新的问题类型,如死锁、活锁、goroutine泄漏等。当这些问题发生时,应用可能表现为失去响应、性能急剧下降或资源耗尽。诊断这类问题的关键在于,能够洞察大量goroutine的当前状态和它们之间的交互。
下面,我们就来探讨几种诊断Go并发问题的有效方法和工具。首先介绍一个轻量级的进程诊断工具 gops,它可以快速获取运行中Go进程的goroutine堆栈和运行时统计信息。
gops:轻量级Go进程诊断工具
gops(由Google开发,项目地址是 github.com/google/gops)是一个非常实用的命令行工具,用于列出当前系统上正在运行的Go进程,并对它们进行一些基本的诊断操作。它的一个巨大优势是 通常无需修改目标Go程序或重启它 就能获取信息。不过,这需要你的目标Go程序内像下面代码一样嵌入了gops的Agent:
package main
import (
"log"
"time"
"github.com/google/gops/agent"
)
func main() {
if err := agent.Listen(agent.Options{}); err != nil {
log.Fatal(err)
}
// ... ...
}
gops 的Agent(在目标Go程序启动时会自动运行一小段代码)会在一个特定的位置(例如,Unix Domain Socket或特定TCP端口,取决于操作系统和配置)监听来自 gops 命令行工具的连接和指令。当 gops 命令行工具执行如 gops stack <pid> 时,它会连接到目标Go进程的Agent,Agent随后会调用Go运行时内部的函数(例如,与 runtime.Stack 或 runtime/pprof 包中获取profile数据相关的函数)来收集所需的信息,并将结果返回给 gops 命令行工具显示。
这种机制与 net/http/pprof 包的工作方式有相似之处,后者也是通过HTTP服务暴露运行时profile数据的接口。实际上, gops 提供的某些功能(如获取CPU/Heap profile、trace数据)底层就是触发了与 net/http/pprof 端点类似的运行时数据收集逻辑。相比于 net/http/pprof 端点, gops 提供了一种体验更好的替代途径来获取类似的诊断信息,特别是goroutine堆栈、运行时统计和基本的profile数据。对于更深入的、可交互的profile分析(如生成火焰图), net/http/pprof 的Web界面或 go tool pprof 仍然是首选。
gops也支持连接到远程的Go应用上,前提是Go应用在调用agent.Listen时将参数agent.Options中的Addr(host:port)设置为对外部开放的ip和port,不过出于安全考虑,是否这么做需要根据实际情况做出权衡。
在目标机器上,通过下面命令安装gops命令行工具后便可以对目标Go程序进行调试诊断了:
$go install github.com/google/gops@latest
下面我们结合一个示例程序来展示一下gops的主要用法以及如何基于gops对目标程序的并发问题进行调查和诊断。示例的源码如下:
// ch28/gops_deadlock/main.go
package main
import (
"fmt"
"os"
"sync"
"time"
"github.com/google/gops/agent"
)
func main() {
if err := agent.Listen(agent.Options{}); err != nil {
panic(err)
}
fmt.Printf("My PID is: %d. Waiting for deadlock...\n", os.Getpid())
var mu1, mu2 sync.Mutex
var wg sync.WaitGroup
wg.Add(2)
go func() { // Goroutine 1
defer wg.Done()
mu1.Lock()
fmt.Println("G1: mu1 locked")
time.Sleep(100 * time.Millisecond) // Give G2 time to acquire mu2
fmt.Println("G1: Attempting to lock mu2...")
mu2.Lock() // Will block here waiting for G2
fmt.Println("G1: mu2 locked (should not happen in deadlock)")
mu2.Unlock()
mu1.Unlock()
}()
go func() { // Goroutine 2
defer wg.Done()
mu2.Lock()
fmt.Println("G2: mu2 locked")
time.Sleep(100 * time.Millisecond) // Give G1 time to acquire mu1
fmt.Println("G2: Attempting to lock mu1...")
mu1.Lock() // Will block here waiting for G1
fmt.Println("G2: mu1 locked (should not happen in deadlock)")
mu1.Unlock()
mu2.Unlock()
}()
fmt.Println("Setup complete. Run 'gops stack <PID>' from another terminal, then send SIGINT (Ctrl+C) to stop.")
var done = make(chan struct{})
go func() {
wg.Wait()
close(done)
}()
for {
select {
case <-done:
fmt.Println("Program close normally")
return
default:
time.Sleep(5 * time.Second)
}
}
}
这是一个用两个goroutine展示经典的AB-BA死锁模式的示例。我们先把它运行起来:
// 在ch28/gops_deadlock目录下
$go build
$./gops_deadlock
My PID is: 17707. Waiting for deadlock...
Setup complete. Run 'gops stack <PID>' from another terminal, then send SIGINT (Ctrl+C) to stop.
G1: mu1 locked
G2: mu2 locked
G1: Attempting to lock mu2...
G2: Attempting to lock mu1...
由于死锁,导致程序hang住,并未退出,这正是gops一展身手进行并发诊断的最佳时机。
诊断第一步就是查找当前目标主机上运行的Go程序。
gops 可以列出所有可连接的Go进程及其PID和程序路径:
$gops
68 1 aTrustXtunnel go1.20.5 /Library/sangfor/SDP/aTrust.app/Contents/Resources/bin/aTrustXtunnel
81 1 aTrustXtunnel go1.20.5 /Library/sangfor/SDP/aTrust.app/Contents/Resources/bin/aTrustXtunnel
17707 10635 gops_deadlock* go1.24.3 /Users/tonybai/github/geekbang/column/go-advanced/part3/source/ch28/gops_deadlock/gops_deadlock
18680 15382 gops go1.18.3 /Users/tonybai/Go/bin/gops
85163 85131 present go1.24.3 /private/var/folders/cz/sbj5kg2d3m3c6j650z0qfm800000gn/T/go-build1258102410/b001/exe/present
85131 68928 go go1.24.3 /Users/tonybai/.bin/go1.24.3/bin/go
当然,我们也可以用gops tree命令以树状形式展示可连接的Go进程:
$gops tree
...
├── 1
│ ├── 81 (aTrustXtunnel) {go1.20.5}
│ └── 68 (aTrustXtunnel) {go1.20.5}
├── 598
│ └── 62393 (net-core) {go1.23.0}
├── 10635
│ └── [*] 17707 (gops_deadlock) {go1.24.3}
├── 15382
│ └── 18706 (gops) {go1.18.3}
└── 68928
└── 85131 (go) {go1.24.3}
└── 85163 (present) {go1.24.3}
我们设计的目标程序在输出日志中打印了pid(17707),gops也可以直接基于该pid进行后续诊断操作。
gops <pid> 显示目标进程的概要信息,包括父进程pid、线程数量、CPU使用、运行时间以及gops agent的连接方式等。这让我们可以对目标进程有一个大致的了解:
$gops 17707
parent PID: 10635
threads: 5
memory usage: 0.013%
cpu usage: 0.004%
username: tonybai
cmd+args: ./gops_deadlock
elapsed time: 01:14:44
local/remote: 127.0.0.1:53669 <-> :0 (LISTEN)
gops stats <pid> 显示指定进程的运行时统计信息,包括当前goroutine数量、GOMAXPROCS、内存分配、GC暂停时间等。这对于监控goroutine泄漏或GC压力非常有用。
$gops stats 17707
goroutines: 5
OS threads: 5
GOMAXPROCS: 8
num CPU: 8
gops version <pid>:查看目标Go应用所使用的Go版本。
$gops version 17707
go1.24.3
gops memstats <pid>:打印目标进程的更详细的内存分配统计( runtime.MemStats)。
$gops memstats 17707
alloc: 1.14MB (1193752 bytes)
total-alloc: 1.14MB (1193752 bytes)
sys: 7.96MB (8344840 bytes)
lookups: 0
mallocs: 386
frees: 13
heap-alloc: 1.14MB (1193752 bytes)
heap-sys: 3.75MB (3932160 bytes)
heap-idle: 2.02MB (2121728 bytes)
heap-in-use: 1.73MB (1810432 bytes)
heap-released: 1.99MB (2088960 bytes)
heap-objects: 373
stack-in-use: 256.00KB (262144 bytes)
stack-sys: 256.00KB (262144 bytes)
stack-mspan-inuse: 33.59KB (34400 bytes)
stack-mspan-sys: 47.81KB (48960 bytes)
stack-mcache-inuse: 9.44KB (9664 bytes)
stack-mcache-sys: 15.34KB (15704 bytes)
other-sys: 980.17KB (1003689 bytes)
gc-sys: 1.56MB (1638752 bytes)
next-gc: when heap-alloc >= 4.00MB (4194304 bytes)
last-gc: -
gc-pause-total: 0s
gc-pause: 0
gc-pause-end: 0
num-gc: 0
num-forced-gc: 0
gc-cpu-fraction: 0
enable-gc: true
debug-gc: false
回到重点问题上,如何用gops分析死锁,这就涉及gops的重要子命令gops stack了。通过 gops stack <pid>,我们可以打印指定PID的Go进程中所有goroutine的堆栈信息。这也是诊断死锁或goroutine卡在何处的极其有用的命令,其输出格式与panic时的堆栈类似,我们对gops_deadlock使用gops stack命令后的输出内容如下:
$gops stack 17707
goroutine 19 [running]:
runtime/pprof.writeGoroutineStacks({0x118ad880, 0xc000106060})
/Users/tonybai/.bin/go1.24.3/src/runtime/pprof/pprof.go:764 +0x6a
runtime/pprof.writeGoroutine({0x118ad880?, 0xc000106060?}, 0x0?)
/Users/tonybai/.bin/go1.24.3/src/runtime/pprof/pprof.go:753 +0x25
runtime/pprof.(*Profile).WriteTo(0xabfbcc0?, {0x118ad880?, 0xc000106060?}, 0x0?)
/Users/tonybai/.bin/go1.24.3/src/runtime/pprof/pprof.go:377 +0x14b
github.com/google/gops/agent.handle({0x118ad858, 0xc000106060}, {0xc00008e000?, 0x1?, 0x1?})
/Users/tonybai/Go/pkg/mod/github.com/google/gops@v0.3.28/agent/agent.go:200 +0x2992
github.com/google/gops/agent.listen({0xab239b8, 0xc000124040})
/Users/tonybai/Go/pkg/mod/github.com/google/gops@v0.3.28/agent/agent.go:144 +0x1b4
created by github.com/google/gops/agent.Listen in goroutine 1
/Users/tonybai/Go/pkg/mod/github.com/google/gops@v0.3.28/agent/agent.go:122 +0x35c
goroutine 1 [sleep]:
time.Sleep(0x12a05f200)
/Users/tonybai/.bin/go1.24.3/src/runtime/time.go:338 +0x165
main.main()
/Users/tonybai/github/geekbang/column/go-advanced/part3/source/ch28/gops_deadlock/main.go:60 +0x23d
goroutine 20 [sync.Mutex.Lock, 34 minutes]:
internal/sync.runtime_SemacquireMutex(0xc000106028?, 0xc0?, 0x1e?)
/Users/tonybai/.bin/go1.24.3/src/runtime/sema.go:95 +0x25
internal/sync.(*Mutex).lockSlow(0xc0001040e8)
/Users/tonybai/.bin/go1.24.3/src/internal/sync/mutex.go:149 +0x15d
internal/sync.(*Mutex).Lock(...)
/Users/tonybai/.bin/go1.24.3/src/internal/sync/mutex.go:70
sync.(*Mutex).Lock(...)
/Users/tonybai/.bin/go1.24.3/src/sync/mutex.go:46
main.main.func1()
/Users/tonybai/github/geekbang/column/go-advanced/part3/source/ch28/gops_deadlock/main.go:29 +0x125
created by main.main in goroutine 1
/Users/tonybai/github/geekbang/column/go-advanced/part3/source/ch28/gops_deadlock/main.go:23 +0x12b
goroutine 21 [sync.Mutex.Lock, 34 minutes]:
internal/sync.runtime_SemacquireMutex(0xc000106028?, 0x0?, 0x1e?)
/Users/tonybai/.bin/go1.24.3/src/runtime/sema.go:95 +0x25
internal/sync.(*Mutex).lockSlow(0xc0001040e0)
/Users/tonybai/.bin/go1.24.3/src/internal/sync/mutex.go:149 +0x15d
internal/sync.(*Mutex).Lock(...)
/Users/tonybai/.bin/go1.24.3/src/internal/sync/mutex.go:70
sync.(*Mutex).Lock(...)
/Users/tonybai/.bin/go1.24.3/src/sync/mutex.go:46
main.main.func2()
/Users/tonybai/github/geekbang/column/go-advanced/part3/source/ch28/gops_deadlock/main.go:41 +0x125
created by main.main in goroutine 1
/Users/tonybai/github/geekbang/column/go-advanced/part3/source/ch28/gops_deadlock/main.go:35 +0x193
goroutine 22 [sync.WaitGroup.Wait, 34 minutes]:
sync.runtime_SemacquireWaitGroup(0x0?)
/Users/tonybai/.bin/go1.24.3/src/runtime/sema.go:110 +0x25
sync.(*WaitGroup).Wait(0x0?)
/Users/tonybai/.bin/go1.24.3/src/sync/waitgroup.go:118 +0x48
main.main.func3()
/Users/tonybai/github/geekbang/column/go-advanced/part3/source/ch28/gops_deadlock/main.go:50 +0x25
created by main.main in goroutine 1
/Users/tonybai/github/geekbang/column/go-advanced/part3/source/ch28/gops_deadlock/main.go:49 +0x22c
如我们预期, gops stack 的输出清晰显示了有两个goroutine的堆栈顶部都处在 sync.Mutex.Lock:
goroutine 20 [sync.Mutex.Lock, 34 minutes]:
goroutine 21 [sync.Mutex.Lock, 34 minutes]:
这类输出直接揭示了经典的AB-BA死锁模式:G1持有mu1等待mu2,G2持有mu2等待mu1。接下来,对照着源码查看,便可以直接确认“死锁”逻辑的存在。
gops还支持一些与性能调优问题有关的子命令,包括:
-
gops trace <pid> [duration]:获取指定进程在接下来一段时间(默认5秒)的执行追踪数据(trace.out文件),可以用go tool trace分析。 -
gops pprof-cpu <pid> [duration]/gops pprof-heap <pid>:方便地获取CPU profile或heap profile,并(可选地)启动go tool pprof进行分析。 -
gops gc <pid>:手动触发一次GC(主要用于调试,生产环境慎用)。
我们看到, gops 是一个非常轻量且适合快速查看线上Go进程的运行时状态快照的工具。当 gops 提供的快照信息不足以完全理解并发行为,或者我们需要更持续的、可通过Web界面交互的剖析数据时, net/http/pprof 就派上用场了。
net/http/pprof 的goroutine剖析与死锁辅助判断
如果你的Go应用是一个HTTP服务,或者可以方便地启动一个内部HTTP服务来暴露诊断端点,那么匿名导入 net/http/pprof 包( _ "net/http/pprof")是获取详细运行时剖析数据的标准方式。它会在默认的 http.DefaultServeMux(或你指定的Mux)上注册一系列 /debug/pprof/ 开头的端点。我们还以上面的程序为基础,去掉gops agent,换为net/http/pprof:
// ch28/net_pprof_deadlock/main.go
package main
import (
"fmt"
"log"
"os"
"sync"
"time"
"net/http"
_ "net/http/pprof" // 导入 pprof 包
)
func main() {
// 启动 pprof 监控
go func() {
log.Println("Starting pprof server at :6060")
log.Println(http.ListenAndServe("localhost:6060", nil)) // pprof 端口
}()
// 后面与gops_deadlock一致。
... ...
}
将程序编译运行起来后,就可以利用localhost:6060这个暴露的服务地址进行并发问题诊断了。
以下几个pprof端点对于并发问题特别有用。
首先是 /debug/pprof/goroutine?debug=1。这个端点返回当前所有goroutine的堆栈跟踪的文本表示。你可以看到每个goroutine的ID、状态(如 [chan receive]、 [select]、 [IO wait]、 [syscall]、 [semacquire]——后者常与锁或channel阻塞相关)以及其调用栈。在排查死锁或goroutine泄漏时,仔细分析这个输出,找出那些处于非预期阻塞状态的goroutine,或者数量异常多的处于相同阻塞点的goroutine,往往能提供关键线索。
$curl http://localhost:6060/debug/pprof/goroutine\?debug\=1
goroutine profile: total 9
... ...
1 @ 0x659e40e 0x657ddbd 0x657dd94 0x659f6c5 0x65b7d3d 0x6784a45 0x6784a21 0x6784a20 0x65a6241
# 0x659f6c4 internal/sync.runtime_SemacquireMutex+0x24 /Users/tonybai/.bin/go1.24.3/src/runtime/sema.go:95
# 0x65b7d3c internal/sync.(*Mutex).lockSlow+0x15c /Users/tonybai/.bin/go1.24.3/src/internal/sync/mutex.go:149
# 0x6784a44 internal/sync.(*Mutex).Lock+0x124 /Users/tonybai/.bin/go1.24.3/src/internal/sync/mutex.go:70
# 0x6784a20 sync.(*Mutex).Lock+0x100 /Users/tonybai/.bin/go1.24.3/src/sync/mutex.go:46
# 0x6784a1f main.main.func3+0xff /Users/tonybai/github/geekbang/column/go-advanced/part3/source/ch28/net_pprof_deadlock/main.go:45
1 @ 0x659e40e 0x657ddbd 0x657dd94 0x659f6c5 0x65b7d3d 0x6784c85 0x6784c61 0x6784c60 0x65a6241
# 0x659f6c4 internal/sync.runtime_SemacquireMutex+0x24 /Users/tonybai/.bin/go1.24.3/src/runtime/sema.go:95
# 0x65b7d3c internal/sync.(*Mutex).lockSlow+0x15c /Users/tonybai/.bin/go1.24.3/src/internal/sync/mutex.go:149
# 0x6784c84 internal/sync.(*Mutex).Lock+0x124 /Users/tonybai/.bin/go1.24.3/src/internal/sync/mutex.go:70
# 0x6784c60 sync.(*Mutex).Lock+0x100 /Users/tonybai/.bin/go1.24.3/src/sync/mutex.go:46
# 0x6784c5f main.main.func2+0xff /Users/tonybai/github/geekbang/column/go-advanced/part3/source/ch28/net_pprof_deadlock/main.go:33
... ...
其次是 /debug/pprof/goroutine?debug=2(符号化文本格式,更易读)。
与 debug=1 类似,但 尝试将内存地址符号化为函数名和代码行号(如果程序编译时包含了符号信息)。这使得堆栈跟踪更易于人类阅读和理解,尤其是在分析复杂调用链时。
$curl http://localhost:6060/debug/pprof/goroutine\?debug\=2
... ...
goroutine 20 [sync.Mutex.Lock]:
internal/sync.runtime_SemacquireMutex(0xc000102008?, 0xc0?, 0x1e?)
/Users/tonybai/.bin/go1.24.3/src/runtime/sema.go:95 +0x25
internal/sync.(*Mutex).lockSlow(0xc0001181c8)
/Users/tonybai/.bin/go1.24.3/src/internal/sync/mutex.go:149 +0x15d
internal/sync.(*Mutex).Lock(...)
/Users/tonybai/.bin/go1.24.3/src/internal/sync/mutex.go:70
sync.(*Mutex).Lock(...)
/Users/tonybai/.bin/go1.24.3/src/sync/mutex.go:46
main.main.func2()
/Users/tonybai/github/geekbang/column/go-advanced/part3/source/ch28/net_pprof_deadlock/main.go:33 +0x125
created by main.main in goroutine 1
/Users/tonybai/github/geekbang/column/go-advanced/part3/source/ch28/net_pprof_deadlock/main.go:27 +0x110
goroutine 21 [sync.Mutex.Lock]:
internal/sync.runtime_SemacquireMutex(0xc000102008?, 0x40?, 0x1e?)
/Users/tonybai/.bin/go1.24.3/src/runtime/sema.go:95 +0x25
internal/sync.(*Mutex).lockSlow(0xc0001181c0)
/Users/tonybai/.bin/go1.24.3/src/internal/sync/mutex.go:149 +0x15d
internal/sync.(*Mutex).Lock(...)
/Users/tonybai/.bin/go1.24.3/src/internal/sync/mutex.go:70
sync.(*Mutex).Lock(...)
/Users/tonybai/.bin/go1.24.3/src/sync/mutex.go:46
main.main.func3()
/Users/tonybai/github/geekbang/column/go-advanced/part3/source/ch28/net_pprof_deadlock/main.go:45 +0x125
created by main.main in goroutine 1
/Users/tonybai/github/geekbang/column/go-advanced/part3/source/ch28/net_pprof_deadlock/main.go:39 +0x172
... ...
我们看到,这和gops stack的输出如出一辙,并且和gops stack的诊断方式一样,结合源码便可以很容易定位死锁问题。
还有两个端点对于分析并发问题也有一定的帮助,但对于上面已经处于死锁状态的程序而言,可能帮助没有 /debug/pprof/goroutine 端点那么大。
再来看 /debug/pprof/mutex(查看互斥锁竞争Profile)。 这个profile记录了那些曾导致goroutine阻塞在互斥锁( sync.Mutex) 上的调用点,以及它们的累积阻塞时间(contention time)。我们需要在代码中显式调用一个函数才能开启该分析:
runtime.SetMutexProfileFraction(1) // 开启 mutex分析
当死锁已经稳定发生(就像我们示例中那样),goroutine 永久阻塞时,mutex 分析器的输出可能不那么直观,因为它更关注动态的争用。有时它可能更多地显示 runtime 内部的锁争用,或者信息不够直接指向用户代码的死锁。
$curl http://localhost:6060/debug/pprof/mutex\?debug\=1
--- mutex:
cycles/second=1391999912
sampling period=1
12432 2 @ 0x82d12a1
# 0x82d12a0 runtime._LostContendedRuntimeLock+0x0 /Users/tonybai/.bin/go1.24.3/src/runtime/proc.go:5447
在进行锁争用性能的分析时,mutex profile的用处更大。
最后是 /debug/pprof/block(查看导致goroutine阻塞的操作Profile)。
这个profile记录了那些导致goroutine阻塞的同步操作的调用点和累积阻塞时间。 这些操作包括channel的发送/接收(如果channel已满或为空)、 select 语句(如果所有case都阻塞)、 sync.Cond.Wait 的调用,以及被运行时标记为阻塞的系统调用等。它可以帮助识别哪些同步原语或阻塞操作是并发执行的瓶颈,或者是潜在死锁的参与者。
和mutex profile一样,我们需要在代码中显式调用一个函数才能开启该分析:
runtime.SetBlockProfileRate(1) // 开启 block 分析
下面是采集的block profile的数据示例:
$curl http://localhost:6060/debug/pprof/block\?debug\=1
--- contention:
cycles/second=1391999912
2014210 1 @ 0x82d8a0e 0x83bf6b9 0x83bdd85 0x83ae025 0x83b0d9b 0x83b135a 0x84a0150 0x84e0ebb 0x84e0ebc 0x83022c1
# 0x82d8a0d runtime.selectgo+0x4ad /Users/tonybai/.bin/go1.24.3/src/runtime/select.go:535
# 0x83bf6b8 net.(*Resolver).lookupIPAddr+0x3d8 /Users/tonybai/.bin/go1.24.3/src/net/lookup.go:342
# 0x83bdd84 net.(*Resolver).internetAddrList+0x4c4 /Users/tonybai/.bin/go1.24.3/src/net/ipsock.go:289
# 0x83ae024 net.(*Resolver).resolveAddrList+0x3e4 /Users/tonybai/.bin/go1.24.3/src/net/dial.go:353
# 0x83b0d9a net.(*ListenConfig).Listen+0x7a /Users/tonybai/.bin/go1.24.3/src/net/dial.go:805
# 0x83b1359 net.Listen+0x59 /Users/tonybai/.bin/go1.24.3/src/net/dial.go:898
# 0x84a014f net/http.(*Server).ListenAndServe+0x4f /Users/tonybai/.bin/go1.24.3/src/net/http/server.go:3346
# 0x84e0eba net/http.ListenAndServe+0x9a /Users/tonybai/.bin/go1.24.3/src/net/http/server.go:3665
# 0x84e0ebb main.main.func1+0x9b /Users/tonybai/github/geekbang/column/go-advanced/part3/source/ch28/net_pprof_deadlock/main.go:22
1898986 1 @ 0x82d8a0e 0x83cda67 0x83abc85 0x83c0925 0x83d1749 0x83a9597 0x83bff77 0x83a86b4 0x83a8650 0x83022c1
# 0x82d8a0d runtime.selectgo+0x4ad /Users/tonybai/.bin/go1.24.3/src/runtime/select.go:535
# 0x83cda66 net.doBlockingWithCtx[...]+0x346 /Users/tonybai/.bin/go1.24.3/src/net/cgo_unix.go:75
# 0x83abc84 net.cgoLookupIP+0xa4 /Users/tonybai/.bin/go1.24.3/src/net/cgo_unix.go:236
# 0x83c0924 net.(*Resolver).lookupIP+0xe4 /Users/tonybai/.bin/go1.24.3/src/net/lookup_unix.go:66
# 0x83d1748 net.(*Resolver).lookupIP-fm+0x48 <autogenerated>:1
# 0x83a9596 net.init.func1+0x36 /Users/tonybai/.bin/go1.24.3/src/net/hook.go:21
# 0x83bff76 net.(*Resolver).lookupIPAddr.func1+0x36 /Users/tonybai/.bin/go1.24.3/src/net/lookup.go:334
# 0x83a86b3 internal/singleflight.(*Group).doCall+0x33 /Users/tonybai/.bin/go1.24.3/src/internal/singleflight/singleflight.go:93
# 0x83a864f internal/singleflight.(*Group).DoChan.gowrap1+0x2f /Users/tonybai/.bin/go1.24.3/src/internal/singleflight/singleflight.go:86
50680 7 @ 0x83140a5 0x8495c3d 0x849ae27 0x849bb05 0x84a0968 0x83022c1
# 0x83140a4 sync.(*Cond).Wait+0x84 /Users/tonybai/.bin/go1.24.3/src/sync/cond.go:71
# 0x8495c3c net/http.(*connReader).abortPendingRead+0x9c /Users/tonybai/.bin/go1.24.3/src/net/http/server.go:738
# 0x849ae26 net/http.(*response).finishRequest+0x86 /Users/tonybai/.bin/go1.24.3/src/net/http/server.go:1720
# 0x849bb04 net/http.(*conn).serve+0x664 /Users/tonybai/.bin/go1.24.3/src/net/http/server.go:2108
# 0x84a0967 net/http.(*Server).Serve.gowrap3+0x27 /Users/tonybai/.bin/go1.24.3/src/net/http/server.go:3454
4924 1 @ 0x8343ce5 0x8345045 0x8345056 0x83485ce 0x83485c9 0x83503af 0x84e0cdf 0x84e0ca8 0x83022c1
# 0x8343ce4 internal/poll.(*fdMutex).rwlock+0xc4 /Users/tonybai/.bin/go1.24.3/src/internal/poll/fd_mutex.go:154
# 0x8345044 internal/poll.(*FD).writeLock+0x64 /Users/tonybai/.bin/go1.24.3/src/internal/poll/fd_mutex.go:239
# 0x8345055 internal/poll.(*FD).Write+0x75 /Users/tonybai/.bin/go1.24.3/src/internal/poll/fd_unix.go:368
# 0x83485cd os.(*File).write+0x4d /Users/tonybai/.bin/go1.24.3/src/os/file_posix.go:46
# 0x83485c8 os.(*File).Write+0x48 /Users/tonybai/.bin/go1.24.3/src/os/file.go:195
# 0x83503ae fmt.Fprintln+0x6e /Users/tonybai/.bin/go1.24.3/src/fmt/print.go:305
# 0x84e0cde fmt.Println+0xfe /Users/tonybai/.bin/go1.24.3/src/fmt/print.go:314
# 0x84e0ca7 main.main.func2+0xc7 /Users/tonybai/github/geekbang/column/go-advanced/part3/source/ch28/net_pprof_deadlock/main.go:36
可以看到,这些信息对于我们调查因mutex死锁的问题并没有什么帮助。在AB-BA互斥锁导致的死锁场景中,block分析器不是首选的诊断工具。你应该继续依赖 goroutine 分析器。如果是因 channel 等同步原语导致的 goroutine 长时间阻塞,那么block profile则很可能会帮助你快速定位问题。
结合上述这些profile信息,我们通常可以有效地推断出是否存在并发问题,以及并发问题形成的具体原因。
如果需要更细致的、交互式的探查特定goroutine在特定时刻的状态,Delve依然是我们的有力工具。
Delve在并发调试中的应用
虽然Delve主要用于单步调试和状态检查,但它在并发调试中也能发挥重要作用,尤其是在需要交互式地深入探查特定goroutine状态时(这在前面讲解Delve交互式调试时已经做过一些展示)。
-
goroutines命令:在Delve中,输入goroutines可以列出当前所有goroutine及其ID、状态(如Running、Sleep、ChanRecv、Select、Mutex等)和当前执行位置(文件名和行号)。 -
goroutine <id>命令:输入goroutine <goroutine_id>可以将Delve的调试上下文切换到指定的goroutine。 -
切换后进行检查:一旦切换到某个goroutine的上下文,你就可以像调试单线程程序一样进行下面的操作。
-
使用
stack(或bt)查看其完整的函数调用栈。 -
使用
locals查看其当前栈帧的局部变量。 -
使用
args查看其当前函数的参数。 -
使用
print <expression>计算和查看该goroutine可见的变量或表达式的值。
-
-
观察交互与状态变迁:通过在不同goroutine的关键同步点(例如,channel发送/接收之前、获取/释放锁之前之后)设置断点,然后通过
continue命令让程序运行,当断点命中时,你可以逐个切换到感兴趣的goroutine,观察它们的状态、变量值,以及它们是如何相互等待或影响的。这对于理解复杂的并发逻辑或尝试复现特定的goroutine交错顺序非常有帮助。
使用Delve调试并发程序通常比调试串行程序更具挑战性,因为调试器本身的介入(如暂停一个goroutine)可能会影响其他goroutine的调度和行为,有时甚至可能“扰乱”原本的并发问题。因此,它更适合用于在已经对问题有一定猜测后,去验证特定goroutine在特定时刻的状态,或者理解一小部分goroutine之间的复杂交互。
最后,我们不能忘记在开发和测试阶段就能帮我们防范一类重要并发问题的工具。
数据竞争检测: go test -race 的辅助作用
正如我们在之前强调过的, go test -race 是开发和测试阶段发现数据竞争(Data Races)的黄金标准。数据竞争是指多个goroutine在没有适当同步的情况下并发访问同一内存位置,且至少有一个访问是写操作。
接下来,我们看看 go test -race 在诊断中的辅助作用具体是什么。
虽然 -race 标志主要用于测试阶段,但理解其机制对线上问题的诊断也有间接帮助。如果线上出现的问题(例如,数据不一致、偶发的panic、难以解释的行为)让你高度怀疑可能是由数据竞争引起的,那么首要的步骤是在你的测试环境中,尽可能地模拟线上的并发场景,并始终使用 go test -race 来运行相关的测试。很多时候,这就能直接捕获到潜在的数据竞争。
线上直接开启race编译版本的考量:通常不推荐在线上生产环境的常规部署中使用通过 -race 标志编译的程序。这是因为竞争检测器会给程序带来显著的性能开销(CPU和内存消耗都可能增加数倍),并且可能会改变程序的精确时序行为。
然而,在非常特殊的情况下,如果一个严重的数据竞争问题只在线上发生,且无法在测试环境稳定复现,作为一种“最后的诊断手段”,在征得同意并充分评估风险后,可能会考虑在一个隔离的、流量极小的生产实例上(或者一个与生产高度一致的预发/灰度环境)临时部署一个用 -race 编译的版本,以期捕获到竞争的证据。但这必须是短期的、目标明确的诊断行为,并且在诊断完成后立即恢复到正常的、非race编译的版本。
总而言之,诊断并发问题通常需要结合多种工具和方法: gops 用于快速获取进程状态和goroutine堆栈快照; net/http/pprof 的goroutine、block和mutex profile用于深入分析阻塞和竞争模式;Delve用于对特定goroutine进行交互式、细粒度的状态探查;而 -race 则作为数据竞争的权威检测手段(主要在测试阶段,审慎用于特定诊断场景)。
在解决了程序逻辑错误和并发问题之后,我们线上服务可能遇到的另一大类“拦路虎”就是性能问题。即使功能完全正确、并发逻辑也无懈可击,如果应用响应缓慢、CPU居高不下,或者内存像无底洞一样持续增长,那么用户体验依然会大打折扣,系统资源也会被快速耗尽。
诊断性能问题:持续剖析与瓶颈初步定位
性能问题直接影响线上服务质量,因此诊断性能问题的目标在于识别程序中的“热点”代码(CPU密集型)、不必要的内存分配或持有(内存泄漏型),以及导致长时间阻塞的同步操作。我们将重点讨论如何通过性能剖析(Profiling)来“诊断和定位”性能瓶颈的具体代码路径,而具体的“优化方法和技巧”将在下一节课深入探讨。
在实际应用中,我们可以通过 net/http/pprof 端点或 gops 手动抓取应用的CPU、内存等profile数据。这种方法对于已知且可稳定复现的性能问题非常有效。然而,许多线上性能问题是偶发的,与特定负载模式相关,或者是在长时间运行后逐渐累积的(例如,缓慢的内存泄漏)。一次性和短时间的 pprof 可能难以捕捉这些问题的全貌或在问题发生时的精确快照。因此,持续性能剖析(Continuous Profiling)的理念应运而生。
为什么要持续性能剖析?
持续性能剖析的价值在于其能够有效捕捉偶发与瞬时问题。
手动 pprof 难以抓到那些一闪而过或仅在特定条件下出现的性能瓶颈,而持续剖析通过定期、低频的采样,显著增加了捕捉这些问题的概率。此外,长期收集profile数据还能帮助我们建立应用在不同版本和负载下的性能基线,从而更容易发现性能回归或性能随时间逐渐恶化的趋势。例如,新版本上线后某个函数的CPU占比异常增加,或者缓慢的内存泄漏导致Heap Profile中某个对象类型持续增长。持续剖析就像为应用装上了一台7x24小时工作的X光机,可以在任何时候(包括问题发生时)回溯和分析当时的性能快照,而无需等到下一次手动触发。
持续性能剖析的数据可以与可观测性体系深度结合。通过将其与指标、日志和追踪信息关联起来,我们可以在监控系统告警某个API延迟飙升时,直接查看该时间段内与该API相关的CPU或阻塞profile,从而快速定位瓶颈函数,甚至结合TraceID找到导致慢请求的具体profile样本。
在生产环境中,持续性能剖析的一个核心要求是对应用本身的性能影响必须极小。如果剖析工具自身消耗大量CPU或内存就会失去意义,甚至可能成为新的性能问题源头。因此,现代持续剖析工具通常采用采样(Sampling)技术来实现低开销。例如,CPU Profiling通过以一定频率(如每秒100次)对所有运行中goroutine的调用栈进行采样,能够将对应用CPU的开销控制在1-5%以内,甚至更低。对于内存剖析,通常是在内存分配操作中进行采样,或者在GC发生时记录存活对象的信息,其开销同样可控。虽然具体的开销百分比会因工具实现、采样频率和应用负载等因素而异,但“低开销”始终是所有生产级持续剖析工具追求的目标。
那么目前业界有哪些低开销的持续剖析的思路和方案呢?我们接下来就重点说一下。
Go应用集成低开销持续剖析方案
目前,为Go应用集成持续剖析主要有以下几种思路:
-
基于net/http/pprof的定期抓取(结合外部工具)
-
集成第三方持续剖析服务
-
问题发生时自动触发Profile采集
下面,我们一一来看。
基于 net/http/pprof 的定期抓取
这是一种相对“原始”但可行的方式。就像前面示例那样,Go应用通过匿名导入 net/http/pprof 暴露profile端点。然后,你可以:
-
配置Prometheus定期抓取
/debug/pprof/profile(CPU)、/debug/pprof/heap等端点的数据,并将其存储到支持profile存储的后端(如Grafana Pyroscope的早期版本就支持从Prometheus target拉取pprof数据,或者使用专门的profile存储如Parca Agent的scrape模式)。 -
编写自定义脚本(如cron job)定期使用
curl或go tool pprof -proto http://...下载profile数据,并保存到文件系统或对象存储。
不过要注意,这个“原始”方案需要你仔细控制抓取频率和CPU profile的持续时间,以避免对生产应用造成过大影响。同时,需要你自行解决大量profile数据的存储、索引、可视化和对比分析问题。
如果你不想这么麻烦,可以借助第三方持续剖析服务来达成你的目标。
集成第三方持续剖析服务
这是目前更主流和推荐的方式,能提供更完善的开箱即用体验。这些服务通常提供一个轻量级的Go Agent(一个Go包,在应用中导入并初始化),Agent会在应用运行时以极低的开销持续收集profile数据,并将其发送到云端或自建的后端服务进行分析。
这里我们以Grafana的 Pyroscope 为例,来看看如何集成和使用第三方持续剖析服务。Pyroscope是一个流行的开源持续性能剖析平台,它后来被可观测巨头Grafana收购,并与Grafana的Phlare项目合并,现在是Grafana Labs支持的OSS项目,并能与Grafana深度集成。它支持包括Go在内的多种主流编程语言。
集成和使用Pyroscope非常简单。首先,在你的Go应用中集成Pyroscope的Go Agent( github.com/grafana/pyroscope-go)。Agent会定期(例如,每10秒收集100ms的CPU profile,或在每次GC后收集Heap Profile)对你的应用进行采样。接下来,Go应用集成的Agent,会将收集到的profile数据发送到Pyroscope Server进行存储和聚合。最后,你就可以通过Pyroscope的Web UI(或集成的Grafana面板)查看性能profile数据了,包括火焰图、对比不同时间段或不同版本的profile、下钻分析等。
下面是一个与Pyroscope集成的具体示例代码:
// ch28/profiling/pyroscope_example/main.go
package main
import (
"context"
"fmt"
"log"
"net/http"
"os" // For setting MutexProfileFraction etc.
"time"
"github.com/grafana/pyroscope-go"
)
// simulateSomeCPUWork performs some CPU-intensive work.
func simulateSomeCPUWork() {
for i := 0; i < 100000000; i++ {
_ = i * i
}
}
// simulateMemoryAllocations allocates some memory.
func simulateMemoryAllocations() {
for i := 0; i < 100; i++ {
_ = make([]byte, 1024*1024) // Allocate 1MB
time.Sleep(50 * time.Millisecond)
}
}
func main() {
// --- Pyroscope Configuration ---
// 这些通常来自配置或环境变量
pyroscopeServerAddress := os.Getenv("PYROSCOPE_SERVER_ADDRESS") // e.g., "http://pyroscope-server:4040"
if pyroscopeServerAddress == "" {
pyroscopeServerAddress = "http://localhost:4040" // Default for local demo
log.Println("PYROSCOPE_SERVER_ADDRESS not set, using default:", pyroscopeServerAddress)
}
appName := "my-go-app.pyroscope-demo"
// (可选) 开启Mutex和Block profiling, 对性能有一定影响, 按需开启
// runtime.SetMutexProfileFraction(5) // Report 1 out of 5 mutex contention events
// runtime.SetBlockProfileRate(5) // Report 1 out of 5 block events (e.g. channel send/recv, select)
// --- Start Pyroscope Profiler ---
profiler, err := pyroscope.Start(pyroscope.Config{
ApplicationName: appName,
ServerAddress: pyroscopeServerAddress, // Pyroscope Server URL
Logger: pyroscope.StandardLogger,
// (可选) Tags to attach to all profiles
Tags: map[string]string{"hostname": os.Getenv("HOSTNAME")},
ProfileTypes: []pyroscope.ProfileType{
// these profile types are enabled by default:
pyroscope.ProfileCPU,
pyroscope.ProfileAllocObjects,
pyroscope.ProfileAllocSpace,
pyroscope.ProfileInuseObjects,
pyroscope.ProfileInuseSpace,
// these profile types are optional:
pyroscope.ProfileGoroutines,
pyroscope.ProfileMutexCount,
pyroscope.ProfileMutexDuration,
pyroscope.ProfileBlockCount,
pyroscope.ProfileBlockDuration,
},
// (可选) HTTP client for pyroscope agent
// HTTPClient: &http.Client{Timeout: 10 * time.Second},
})
if err != nil {
log.Fatalf("Failed to start Pyroscope profiler: %v. Is Pyroscope server running at %s?", err, pyroscopeServerAddress)
}
defer profiler.Stop()
log.Printf("Pyroscope profiler started for app '%s', sending data to %s\n", appName, pyroscopeServerAddress)
// --- Your Application Logic ---
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
// Tag a specific piece of work with pyroscope.TagWrapper
// This will add "handler":"root" tag to profiles collected during this function's execution
pyroscope.TagWrapper(r.Context(), pyroscope.Labels("handler", "root"), func(ctx context.Context) {
fmt.Fprintf(w, "Hello from %s! Simulating work...\n", appName)
simulateSomeCPUWork() // Simulate some CPU load
})
})
go func() { // Simulate some background memory allocations
log.Println("Starting background memory allocation simulation...")
simulateMemoryAllocations()
log.Println("Background memory allocation simulation finished.")
}()
port := "8080"
log.Printf("HTTP server listening on :%s\n", port)
if err := http.ListenAndServe(":"+port, nil); err != nil {
log.Fatalf("Failed to start HTTP server: %v", err)
}
}
为了验证示例集成,我们可以通过容器方式快速启动一个Pyroscope Server:
$docker run -d -p 4040:4040 grafana/pyroscope:latest server
编译和运行Go应用:
$ cd ch28/profiling/pyroscope_example/
$ go mod init pyroscope_example
$ go mod tidy
$ go build
// 确保 PYROSCOPE_SERVER_ADDRESS 环境变量指向你的Pyroscope服务器,或者使用代码中的默认值
$$PYROSCOPE_SERVER_ADDRESS=http://<pyroscope-server-ip>:4040 ./pyroscope_example
[INFO] starting profiling session:
[INFO] AppName: my-go-app.pyroscope-demo
[INFO] Tags: map[hostname:]
[INFO] ProfilingTypes: [cpu alloc_objects alloc_space inuse_objects inuse_space goroutines mutex_count mutex_duration block_count block_duration]
[INFO] DisableGCRuns: false
[INFO] UploadRate: 15s
[DEBUG] profiling session reset 2025-06-06 15:19:15 +0800 CST
2025/06/06 15:19:26 Pyroscope profiler started for app 'my-go-app.pyroscope-demo', sending data to http://<pyroscope-server-ip>:4040
[DEBUG] starting cpu profile collector
2025/06/06 15:19:26 HTTP server listening on :8080
2025/06/06 15:19:26 Starting background memory allocation simulation...
2025/06/06 15:19:31 Background memory allocation simulation finished.
[DEBUG] profiling session reset 2025-06-06 15:19:15 +0800 CST
[DEBUG] uploading at http://<pyroscope-server-ip>:4040/ingest?aggregationType=&from=1749194355000000000&name=my-go-app.pyroscope-demo%7B__session_id__%3D3bdc14ebf314ea4c%7D&sampleRate=0&spyName=gospy&units=&until=1749194381193844652
[DEBUG] uploading at http://<pyroscope-server-ip>:4040/ingest?aggregationType=average&from=1749194355000000000&name=my-go-app.pyroscope-demo%7B__session_id__%3D3bdc14ebf314ea4c%7D&sampleRate=0&spyName=gospy&units=goroutines&until=1749194381193844652
[DEBUG] uploading at http://<pyroscope-server-ip>:4040/ingest?aggregationType=&from=1749194355000000000&name=my-go-app.pyroscope-demo%7B__session_id__%3D3bdc14ebf314ea4c%7D&sampleRate=100&spyName=gospy&units=&until=1749194381193844652
... ...
打开浏览器访问 http://<pyroscope-server-ip>:4040(Pyroscope Server的地址)。你应该能找到名为 my-go-app.pyroscope-demo 的应用,并可以查看其CPU、内存(inuse_objects、inuse_space、alloc_objects、alloc_space)、goroutine、mutex、block等类型的profile数据的火焰图(如下面示意图)。你可以选择时间范围,对比不同时间的profile,甚至通过 pyroscope.TagWrapper 添加的标签进行筛选。
市面上还有一些其他类似的第三方服务,比如, Parca 就是另一个流行的开源持续剖析项目,与Pyroscope类似,也提供了Go Agent。商业APM工具(如Datadog、Google Cloud Profiler、New Relic)通常将持续剖析功能作为其整体APM套件的一部分提供。
近些年,eBPF技术飞速发展,它允许在内核层面安全地执行自定义代码,无需修改应用代码或重启,即可实现非常低开销的性能监控和剖析,包括对Go应用的CPU、内存、网络、I/O等行为的深度洞察。一些新兴的可观测性工具(如Pixie、Cilium Hubble的某些功能,以及Pyroscope和Parca的eBPF模式)正在积极利用eBPF。这是未来性能诊断的一个重要发展方向。你了解一下就可以,我就不多说了。
其他考量:问题发生时自动触发Profile采集
虽然持续剖析能提供全时段的数据,但其采样特性可能无法捕捉到非常短暂的、极端尖峰的性能问题的所有细节。另一方面,如果对持续剖析(即使是低开销的)在某些极度敏感的环境中仍有顾虑,或者希望在问题发生时获得更“精确”的快照,可以考虑设计一种 告警驱动的Profile采集机制。
-
集成告警系统:当监控系统(如Prometheus + Alertmanager)检测到某个关键性能指标(如P99延迟超标、CPU使用率持续过高、错误率激增)触发告警时。
-
自动触发Profile:告警系统通过Webhook或其他机制,调用一个脚本或API,该脚本/API会连接到出问题的应用实例(例如,通过
gops或直接请求net/http/pprof端点,如果暴露在外网则需安全访问),抓取特定类型(如CPU profile几秒,或Heap profile)的profile数据。 -
数据保存与通知:将抓取到的profile数据保存到指定位置(如对象存储),并通知相关开发/运维人员进行分析。
这种方式的优点是只在问题实际发生(或疑似发生)时才进行profile采集,开销更集中。缺点是可能错过问题的初始阶段,且依赖于告警的准确性和及时性。
这种机制并不能完全替代7x24小时的持续剖析,因为后者能提供历史趋势和基线对比,对于发现缓慢的性能退化或在告警阈值之下的“亚健康”状态更有优势。使用哪一种,还是将两者结合使用,需要你根据实际项目情况进行抉择。
分析Profile数据,初步定位瓶颈
无论通过何种方式(手动 pprof、定期抓取、持续剖析服务)获取到性能剖析数据(通常是 .prof 文件或能在特定UI中查看),最终都需要使用工具进行分析,以找出性能瓶颈。Go官方提供的 go tool pprof 是最核心的本地分析工具,而持续剖析服务则通常自带强大的Web UI。
这里简单整理一下 go tool pprof 的核心可视化与分析步骤,供你参考:
-
启动交互式命令行:
go tool pprof <path_to_binary_if_available> <profile_data_file_or_url>。 -
topN命令:显示消耗资源最多的N个函数。这是快速定位热点函数的首选。 -
list FunctionNameRegex命令:显示匹配函数的源代码,并标注每行代码的资源消耗。 -
web命令(或svg、pdf等):生成可视化的调用图(Call Graph)。 -
火焰图(Flame Graph):(通过
pprof的HTTP接口或Web UI查看)非常直观,X轴表示样本占比,Y轴表示调用栈深度。 看顶层平坦宽阔的部分,通常是直接消耗资源较多的地方。
如上图所示,通过分析 pprof 的输出(例如, top 命令、火焰图),我们可以快速识别出哪些消耗了不成比例CPU时间的函数(如 expensiveFunc1 及其调用的 helperFuncY),或者哪些分配了大量内存的对象和调用路径。 在这节课中,我们的目标是学会如何通过这些工具和数据,“找到”这些可疑的性能瓶颈点,即回答“问题出在哪里?”。至于如何具体分析这些热点代码的逻辑,以及采用何种Go语言特性或编程技巧去优化它们,将是我们下节课深入探讨的内容。
这里可以看到:持续性能剖析与常规的 pprof 工具结合,为我们提供了一套从宏观趋势到微观代码定位性能问题的完整方法论。
小结
这两节课,我们从可观测性系统发出告警开始,学习了如何系统性地进行问题排查,直至定位到问题的根源。这节课,我们重点关注了如何诊断具体的并发问题和性能问题。
在诊断并发问题方面,我们介绍了轻量级的Go进程诊断工具 gops,学习了它如何通过Agent机制获取运行中Go进程的goroutine堆栈、运行时统计等信息,特别适合快速查看进程状态。我们还回顾了如何利用 net/http/pprof 暴露的goroutine、block和mutex profile来深入分析并发瓶颈和辅助判断死锁。此外,探讨了Delve在并发调试中查看和切换goroutine的交互式能力,并再次提及了 go test -race 在辅助诊断数据竞争方面的价值(主要用于可复现场景)。
最后,针对性能问题,我们引入了持续性能剖析(Continuous Profiling)的理念及其核心价值(捕捉偶发问题、理解性能趋势、低开销)。我们讨论了Go应用集成低开销持续剖析的几种方案:基于 net/http/pprof 的定期抓取、集成第三方服务/Agent(并以Grafana Pyroscope为例给出了具体集成示例),以及对eBPF应用前景的展望。我们还思考了在问题发生时自动触发Profile采集的策略。本节课的重点在于如何通过分析Profile数据(如使用 go tool pprof 的火焰图、top列表)来初步定位瓶颈,为下一节课的性能优化做好铺垫。
通过这两节课的学习,相信你已经拥有了一套更全面、更强大的Go故障诊断“兵器谱”。在未来面对线上服务的各种“疑难杂症”时,希望这些策略和工具能助你拨云见日,快速定位问题,更从容地保障服务的稳定运行。
思考题
你的Go应用在线上突然出现部分请求响应时间飙升,同时伴有少量goroutine数量缓慢增长的现象。错误日志没有明显指向。请描述你的诊断思路:你会如何对问题进行初步分类?会依次使用哪些工具或方法(从这两节课讨论的内容中选择)来尝试定位CPU耗时热点和潜在的goroutine泄漏源?并简述你期望从每个工具或方法中获得什么样的信息来帮助你推断问题。
欢迎在留言区分享你的思考和方案!我是Tony Bai,我们下节课见。
性能调优:定位瓶颈,优化Go程序的系统方法(上)
你好,我是Tony Bai。
在前面的课程中,我们已经学习了如何构建健壮的应用骨架,如何实现核心组件,如何进行有效的故障诊断,包括初步使用 pprof 等工具来定位问题。当我们的可观测性系统或故障诊断过程将矛头指向了“性能”这个维度时——例如,应用响应缓慢、CPU居高不下、内存持续增长——仅仅知道“哪里出了问题”是不够的。 真正的挑战在于,如何系统性地分析这些性能瓶颈,并运用恰当的优化手段来提升我们Go程序的效率和资源利用率。
Go语言以其出色的性能而闻名,其高效的并发模型、优化的编译器和低延迟的垃圾回收器为我们构建高性能应用打下了坚实的基础。然而,在复杂的业务场景和大规模部署下,即便是Go程序,也可能因为不当的编码实践、低效的算法选择,或者对Go运行时特性理解不足而遭遇性能瓶颈。
你是否也曾在性能调优中感到困惑?
-
面对性能问题,是应该立即修改代码,还是先做点别的?
-
pprof的各种profile眼花缭乱,如何从火焰图、top列表、调用图中准确解读出瓶颈所在? -
除了
pprof,Go还提供了哪些工具能帮助我们洞察更深层次的执行细节,比如goroutine调度和GC行为? -
针对CPU、内存、并发、I/O等不同类型的瓶颈,Go语言有哪些特有的、行之有效的优化技巧?
如果这些问题触动了你,那么接下来的两节课正是为你精心准备的,我们将一起深入Go程序的性能调优之旅。
这节课,我们先建立一套科学的性能分析方法论,然后再次深入实战Go的性能剖析利器 pprof(在不同维度上进行更细致的分析)。下节课再结合最新的Go运行时追踪工具 trace 来洞察执行细节,同时系统性地梳理Go中常见的性能瓶颈类型及其对应的、具有Go特色的优化技巧。
这两节课的核心理念,也是所有性能优化工作的金科玉律:“ 不要猜测,要测量!”(Measure, don’t guess!)只有基于真实的数据和科学的方法,我们的优化工作才能精准有效,避免盲目修改带来的风险。
准备好了吗?让我们一起揭开Go性能调优的神秘面纱,学习如何让你的Go程序跑得更快、更稳、更省资源!
在真正拿起 pprof 这样的“手术刀”对Go代码进行剖析和优化之前,我们必须先在脑海中建立起一套清晰、科学的性能调优方法论。这套方法论将作为我们后续所有行动的指南针,确保我们的努力不会偏离正确的方向。
Go性能调优方法论:科学的优化之路
性能调优绝非仅仅是修改几行代码那么简单,它是一项系统性的工程,需要严谨的态度和科学的方法。如果缺乏正确的方法论指导,我们很容易陷入一些误区,不仅效率低下,甚至可能引入新的问题使情况变得更糟或导致过度优化。
性能调优的常见误区与核心原则
在开始任何性能优化工作之前,我们首先需要警惕一些开发者容易陷入的常见误区。
“过早优化是万恶之源”,这句来自Donald Knuth的箴言,提醒我们不应在需求尚未明确、代码结构尚未稳定,甚至在没有数据证明存在性能瓶颈之前,就投入大量精力进行细枝末节的优化。这样做往往事倍功半,甚至可能因为需求变化而导致之前的努力付诸东流。
同样需要避免的是“凭感觉优化”,即仅根据直觉或以往经验猜测瓶颈所在,这往往是不准确的。此外,仅仅关注对某个函数的局部极致优化,如果该函数在系统整体性能中占比不高,那么对整体的提升也将微乎其微。最后,缺乏明确的优化目标(例如,P99延迟降低多少,吞吐量提升多少)会使优化工作失去方向,也难以评估其真实效果。
为了避免这些误区,并确保我们的性能调优工作卓有成效,我们应该始终遵循一些核心原则。
首先也是最重要的, 性能调优必须由数据驱动(Data-Driven)。所有的分析、决策和验证都必须基于真实的、可量化的性能数据,这些数据可以来自基准测试、压力测试或线上的性能剖析与监控。
其次,在开始优化之前,我们必须 明确具体的、可衡量的性能改进目标。再次,根据“木桶理论”,我们应该优先识别并优化对整体性能影响最大的瓶颈点。
最后,性能优化通常是一个迭代的过程,我们应遵循“小步快跑,持续验证”的原则,每次只做少量相关的改动,并立即验证其效果,同时也要充分考虑潜在的权衡,例如时间复杂度与空间复杂度之间,或性能提升与代码可读性、可维护性之间的平衡。
遵循这些原则,我们就能为性能调优工作打下坚实的方法论基础。接下来,我们将这些原则具象化为一个系统性的操作流程。
性能调优的系统化流程:测量、定位、优化、验证(MDOV)
一个科学的性能调优过程,可以概括为一个持续迭代的循环,我这里称之为MDOV流程:测量(Measure)、定位(Detect/Diagnose)、优化(Optimize)、验证(Verify)。这个流程确保了我们的每一步优化都是有据可依、目标明确且效果可评估的。
我们可以用下图来直观地展示这个流程:
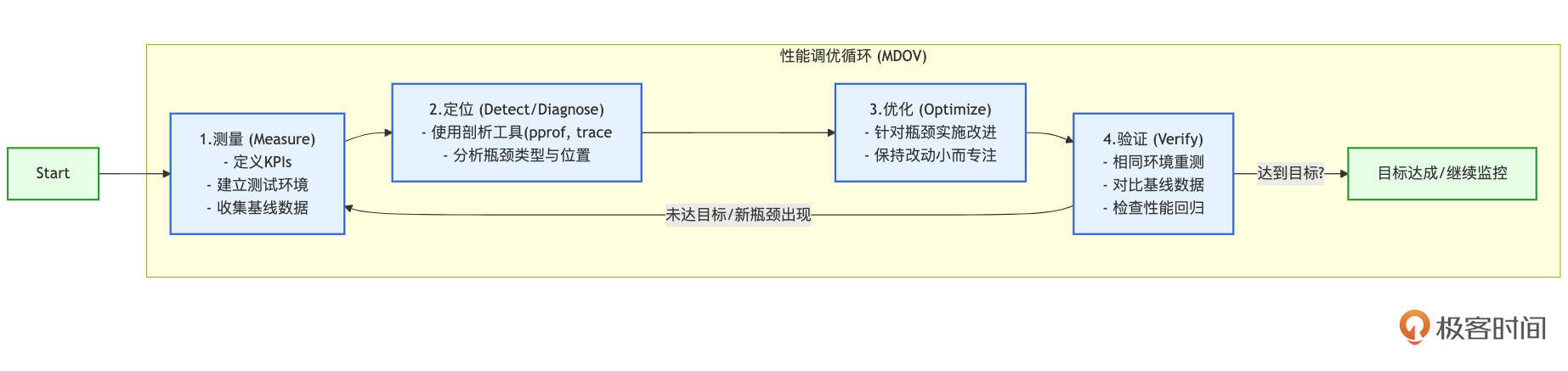
这个MDOV循环清晰地展示了性能调优的四个核心阶段及其迭代关系。
阶段一:测量——建立基线,收集数据
这是所有性能工作的起点。
首先,你需要定义清晰的关键性能指标,例如请求延迟(平均值、P95、P99等分位数)、吞吐量(QPS/TPS)、CPU和内存使用率、GC暂停时间、goroutine数量等,这些指标应该与你的业务目标和用户体验直接相关。
其次,你需要建立一个稳定、可重复的性能测试环境,这可能包括编写Go的基准测试( testing.B)、使用压力测试工具(如 k6、 vegeta 或 hey)模拟真实负载,或者(对于线上问题)配置好持续剖析和监控系统。
最重要的一步是在进行任何优化之前,务必在这个环境中运行测试并收集一组基线的性能数据,这将作为后续所有优化效果的参照标准。
阶段二:定位——识别瓶颈
当测量数据显示当前性能未达到预期目标,或者你希望进一步挖掘性能潜力时,就需要进入定位阶段。核心任务是使用性能剖析工具(如Go的 pprof 和 trace 工具,我们将在后面详细讲解)来深入分析应用的运行时行为,找出那些消耗了不成比例的资源(CPU时间、内存分配)、执行速度过慢,或者导致不必要阻塞的关键代码路径、函数或资源。
同时,还需要分析瓶颈的类型:是计算密集型问题,还是内存分配过多导致GC压力,或者是I/O等待,亦或是并发同步(如锁竞争、channel阻塞)引入的瓶颈?不同类型的瓶颈,其分析视角和后续的优化策略会有显著差异。
阶段三:优化——实施改进
在准确地定位到性能瓶颈之后,就可以针对性地实施优化了。这可能涉及改进算法的逻辑、优化数据结构的选择、减少不必要的内存分配、使用更高效的并发模式、引入缓存机制,或者对I/O操作进行批量处理等等。
在实施优化时,一个重要的原则是保持改动尽可能小而专注。避免一次性进行大量、不相关的代码修改,因为这会让你难以判断是哪个具体的改动带来了性能提升(或下降),也难以评估每个改动的独立效果,甚至可能引入新的问题。
阶段四:验证——评估效果,检查回归
优化完成后,绝不能想当然地认为问题已经解决或性能一定提升了。必须在与收集基线数据完全相同的测试环境下,重新运行性能测试,并收集新的性能数据。
然后,将新的数据与基线数据进行严格对比,以量化的方式评估这次优化是否达到了预期的目标(例如,P99延迟是否如期降低了20%)。
同时,还需要密切关注其他相关的性能指标,确保优化某个方面的同时,没有对其他方面造成不可接受的负面影响(即性能回归(Regression))。例如,一个旨在降低CPU占用的优化,不应该导致内存占用大幅增加或请求延迟显著上升。如果优化效果显著且无明显副作用,那么这次优化就是成功的,记录下优化前后的数据对比和所做的具体改动。如果效果不明显,或者引入了新的问题,可能需要回退这次改动,或者重新回到“定位”阶段,审视瓶颈分析是否准确,调整优化策略。
性能调优通常不是一次性的行为,而是一个 持续迭代的循环过程。解决了当前最主要的瓶颈后,系统的下一个(次要的)瓶颈点可能会浮现出来,你需要重复这个MDOV流程,不断地测量、定位、优化和验证,直到应用的性能达到既定目标,或者进一步优化的投入产出比不再具有吸引力。
掌握了这套科学的方法论,我们就有了进行性能调优的“导航系统”。接下来,我们将再次深入Go语言的性能剖析利器——pprof,学习如何更精细地用它来执行MDOV流程中的“定位”环节,从不同维度分析性能瓶颈。
pprof实战再深入:从概览到多维度瓶颈分析
在讲解“故障诊断”时,我们已经对 pprof 有了初步的了解,知道它可以帮助我们获取CPU、内存等方面的性能剖析数据。本节课,我们将从“性能调优”的视角出发,再次深入 pprof 的实战应用,重点学习如何解读其产生的不同类型的profile,并如何利用这些信息来精准定位各种常见的性能瓶颈。我们将不仅仅满足于“找到热点函数”,更要理解这些热点背后的原因,以及它们是如何影响系统整体性能的。
net/http/pprof 与 runtime/pprof:回顾与选择
Go语言原生支持的获取性能分析数据的方式主要有两种: net/http/pprof 和 runtime/pprof。它们各自有不同的使用场景和优缺点。
首先, net/http/pprof 通过HTTP服务来暴露分析端点,这种方式非常适合长期运行的HTTP服务。开发者只需在应用中匿名导入 _ "net/http/pprof" 包,这样就会自动在 http.DefaultServeMux 或指定的Mux上注册多个以 /debug/pprof/ 为前缀的端点。用户可以通过浏览器访问这些端点,例如访问 http://localhost:8080/debug/pprof/ 可查看可用的profile列表。此外,使用 go tool pprof 命令可以直接从这些端点抓取profile数据,例如通过 go tool pprof http://localhost:8080/debug/pprof/profile?seconds=30 抓取30秒的CPU profile。
该方法的优点在于,它允许在线上或测试环境中按需获取实时的profile数据,而不需要重启应用。然而,它的缺点是要求应用本身是一个HTTP服务,或者需要额外启动一个HTTP服务来专门提供pprof端点。
另一方面, runtime/pprof 提供了一套代码API,允许开发者手动控制profile的生成。这一标准库中的包提供了多种函数,可以精确地控制何时开始和停止收集特定类型的profile数据,并将结果写入文件。以下是CPU Profiling和Heap Profiling的示例代码片段:
import (
"os"
"runtime/pprof"
"runtime/trace" // trace也常与pprof结合
)
// CPU Profiling示例
fcpu, _ := os.Create("cpu.prof")
defer fcpu.Close()
pprof.StartCPUProfile(fcpu)
defer pprof.StopCPUProfile()
// ... 执行要剖析的代码 ...
// Heap Profiling示例
fheap, _ := os.Create("heap.prof")
defer fheap.Close()
pprof.WriteHeapProfile(fheap) // 写入当前时刻的堆快照
这种方法的优点在于能够精确控制剖析的范围和时机,特别适合于基准测试、命令行工具或在特定事件触发时进行剖析的场景。然而,它的缺点是需要对代码进行修改,以嵌入启动和停止profile的逻辑。
综上所述,对于线上服务和长期运行的应用,推荐使用 net/http/pprof 暴露端点的方式。而对于基准测试、短时任务或特定场景的深度剖析, runtime/pprof 的代码API提供了更多的灵活性。无论选择哪种方式,获取到的profile数据格式都是兼容的,都可以通过 go tool pprof 进行分析。
Go的 pprof 支持多种类型的profile,每种都对应着程序运行时的一个特定方面。理解不同profile的用途以及如何解读它们,是有效定位性能瓶颈的关键。接下来,我们将首先深入CPU Profile,它是识别计算密集型瓶颈最直接的工具。
CPU Profiling 深度解析:找到CPU的“时间小偷”
当你的Go应用表现出CPU使用率过高,或者某个操作执行缓慢且你怀疑是计算密集型任务导致的,CPU Profiling就能帮助我们精确定位那些消耗了最多CPU执行时间的函数和代码路径——也就是找出程序中的“CPU时间小偷”。
Go语言的CPU Profiler采用的是 基于采样的分析方法。当CPU Profiling被激活后,Go运行时会以一个固定的频率(在Linux、macOS等类Unix系统上,通常是每秒100次,由操作系统的 SIGPROF 定时器信号驱动)中断正在执行的Go程序。每次中断发生时,Profiler会记录下当前正在CPU上执行的每个goroutine的函数调用栈。通过在一段时间内(例如,抓取一个30秒的profile)收集大量的这类调用栈样本,那些在样本中出现频率越高的函数调用栈,就表明它们所代表的代码路径在CPU上执行的时间越长,消耗的CPU资源也越多。这种采样方式对应用的性能影响相对较小,使其适用于生产环境的诊断。
下面我们就通过一个示例深度解析一下cpu profiling的过程与技巧。这个示例程序包含一个进行大量哈希计算的函数和一个进行大量字符串拼接(低效方式)的函数。
// ch29/profiling/cpu_profiling_example/main.go
package main
import (
"crypto/sha256"
"fmt"
"log"
"net/http"
_ "net/http/pprof" // 匿名导入pprof包
"strconv"
"sync"
"time"
)
// calculateHashes: 一个CPU密集型任务,计算SHA256哈希多次
func calculateHashes(input string, iterations int) string {
data := []byte(input)
var hash [32]byte // sha256.Size
for i := 0; i < iterations; i++ {
hash = sha256.Sum256(data)
// 为了让每次迭代的输入都不同,从而避免一些编译器优化或缓存效应,
// 并且增加计算量,我们将上一次的哈希结果作为下一次的输入。
// 注意:这只是为了模拟CPU消耗,实际意义不大。
if i < iterations-1 { // 避免最后一次转换,因为我们只用hash
data = hash[:]
}
}
return fmt.Sprintf("%x", hash) // 返回最终哈希的十六进制字符串
}
// buildLongString: 另一个可能消耗CPU的函数,通过低效的字符串拼接
func buildLongString(count int) string {
var s string // 使用+=进行字符串拼接,效率较低
for i := 0; i < count; i++ {
s += "Iteration " + strconv.Itoa(i) + " and some more text to make it longer. "
}
return s
}
// handleRequest: 模拟一个HTTP请求处理器,它会并发执行上述两个任务
func handleRequest(w http.ResponseWriter, r *http.Request) {
iterations := 100000 // 哈希计算的迭代次数
stringBuildCount := 2000 // 字符串拼接的迭代次数
// 从查询参数中获取迭代次数,以便调整负载
if queryIters := r.URL.Query().Get("iters"); queryIters != "" {
if val, err := strconv.Atoi(queryIters); err == nil && val > 0 {
iterations = val
}
}
if queryStrCount := r.URL.Query().Get("strcount"); queryStrCount != "" {
if val, err := strconv.Atoi(queryStrCount); err == nil && val > 0 {
stringBuildCount = val
}
}
log.Printf("Handling request: iterations=%d, stringBuildCount=%d\n", iterations, stringBuildCount)
var wg sync.WaitGroup
wg.Add(2) // 我们要等待两个goroutine完成
var hashResult string
var stringResultLength int // 只关心长度以避免打印过长字符串
go func() { // Goroutine 1: 执行哈希计算
defer wg.Done()
startTime := time.Now()
hashResult = calculateHashes("some_initial_seed_data_for_hashing", iterations)
log.Printf("Hash calculation finished in %v. Result starts with: %s...\n",
time.Since(startTime), hashResult[:min(10, len(hashResult))])
}()
go func() { // Goroutine 2: 执行字符串拼接
defer wg.Done()
startTime := time.Now()
longStr := buildLongString(stringBuildCount)
stringResultLength = len(longStr)
log.Printf("String building finished in %v. Result length: %d\n",
time.Since(startTime), stringResultLength)
}()
wg.Wait() // 等待两个goroutine都完成
// 响应客户端
fmt.Fprintf(w, "Work completed.\nHash result (prefix): %s...\nString result length: %d\n",
hashResult[:min(10, len(hashResult))], stringResultLength)
}
// min是一个辅助函数
func min(a, b int) int {
if a < b {
return a
}
return b
}
func main() {
// 启动pprof HTTP服务器 (通常与业务服务器在同一端口,或一个单独的admin端口)
go func() {
log.Println("Starting pprof server on :6060")
// http.ListenAndServe的第二个参数是handler,nil表示使用http.DefaultServeMux
// _ "net/http/pprof" 会将其handlers注册到DefaultServeMux
if err := http.ListenAndServe("localhost:6060", nil); err != nil {
log.Fatalf("Pprof server failed: %v", err)
}
}()
// 启动业务HTTP服务器
http.HandleFunc("/work", handleRequest) // 注册我们的业务处理器
port := "8080"
log.Printf("Business server listening on :%s. Access /work to generate load.\n", port)
if err := http.ListenAndServe(":"+port, nil); err != nil { // 使用DefaultServeMux
log.Fatalf("Business server failed: %v", err)
}
}
接下来,我们运行一下该程序并对其进行剖析。
1. 运行Go应用
$cd ch29/profiling/cpu_profiling_example/ # 进入示例代码目录
$go build -gcflags '-N -l' -o cpu_app main.go # 编译和运行示例程序,这里关闭了编译器的一些优化,便于后续演示
$./cpu_app
2025/06/12 14:47:56 Business server listening on :8080. Access /work to generate load.
2025/06/12 14:47:56 Starting pprof server on :6060
示例应用会在8080端口提供业务服务,并在6060端口提供pprof服务。
2. 产生负载:在另一个终端,向 /work 端点发送一些请求以产生CPU负载。我们可以通过调整查询参数 iters 和 strcount 来控制计算的密集程度。
# 发送一个中等负载的请求
$curl "http://localhost:8080/work?iters=200000&strcount=5000"
# 可以多发几次,或者用hey, wrk等工具持续发送一段时间
3. 采集CPU Profile:在负载产生期间,从pprof端点抓取CPU profile数据。我们将抓取30秒的数据并保存到 cpu.prof 文件。
$curl -o cpu.prof "http://localhost:6060/debug/pprof/profile?seconds=30"
4. pprof交互分析:采集完成后,我们便可以使用 go tool pprof 进入交互式分析界面。
// 在cpu_profiling_example目录下
$go tool pprof ./cpu_app cpu.prof
File: cpu_app
Build ID: 874472e84348bbfbe3fdf905e2e0712051e7fbdd
Type: cpu
Time: 2025-06-12 07:28:18 UTC
Duration: 30.15s, Total samples = 14.82s (49.15%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)
现在我们进入了 (pprof) 提示符,使用 top10 查看自身消耗( flat)最多的函数:
(pprof) top10
Showing nodes accounting for 10650ms, 71.86% of 14820ms total
Dropped 201 nodes (cum <= 74.10ms)
Showing top 10 nodes out of 134
flat flat% sum% cum cum%
4190ms 28.27% 28.27% 4190ms 28.27% runtime.memmove
2360ms 15.92% 44.20% 2360ms 15.92% crypto/internal/fips140/sha256.blockAMD64
880ms 5.94% 50.13% 880ms 5.94% runtime.madvise
860ms 5.80% 55.94% 1020ms 6.88% runtime.typePointers.next
600ms 4.05% 59.99% 2050ms 13.83% runtime.scanobject
530ms 3.58% 63.56% 530ms 3.58% runtime.futex
500ms 3.37% 66.94% 670ms 4.52% runtime.scanblock
340ms 2.29% 69.23% 340ms 2.29% runtime.tgkill
200ms 1.35% 70.58% 290ms 1.96% runtime.findObject
190ms 1.28% 71.86% 240ms 1.62% runtime.unlock2
(pprof)
从 top10 的输出中(你的具体数字可能不同),我们可以看到: crypto/internal/fips140/sha256.blockAMD64 占据了最高的 flat(自身消耗)百分比。这符合预期,因为SHA256计算是CPU密集型的。
但在这里我们并没有看到字符串连接操作所在函数buildLongString的身影,这是因为示例代码使用的是 + 操作符进行的连接,Go编译器将 + 操作符转换为了runtime.concatstrings等函数,而后者也调用了其他一些函数,甚至是汇编实现的函数来完成的字符串连接功能。
在这种情况下,我们只能通过 cum(累计消耗)百分比来看一下buildLongString的排名了。通过 top10 -cum 可以看到累计消耗的排名:
(pprof) top10 -cum
Showing nodes accounting for 4.32s, 29.15% of 14.82s total
Dropped 201 nodes (cum <= 0.07s)
Showing top 10 nodes out of 134
flat flat% sum% cum cum%
0.02s 0.13% 0.13% 7.63s 51.48% main.buildLongString
0 0% 0.13% 7.63s 51.48% main.handleRequest.func2
0 0% 0.13% 7s 47.23% runtime.concatstring4
0.04s 0.27% 0.4% 7s 47.23% runtime.concatstrings
0.01s 0.067% 0.47% 6.02s 40.62% runtime.systemstack
4.19s 28.27% 28.74% 4.19s 28.27% runtime.memmove
0.01s 0.067% 28.81% 3.71s 25.03% runtime.mallocgc
0 0% 28.81% 2.82s 19.03% main.handleRequest.func1
0.05s 0.34% 29.15% 2.81s 18.96% main.calculateHashes
0 0% 29.15% 2.80s 18.89% runtime.rawstring (inline)
可以看到: main.buildLongString 的累计消耗排行首位,其 cum 值反映了字符串拼接操作的整体开销,而其 flat 自身开销占比则非常小,main.calculateHashes也是这个道理。 runtime.memmove 和 runtime.mallocgc 也出现在列表中,这通常与大量数据拷贝和内存分配有关,很可能与我们低效的字符串拼接方式( main.buildLongString)相关。
使用 list FunctionName 我们可以在源码级别进一步“下钻”,以main.buildLongString为例:
(pprof) list main.buildLongString
Total: 14.82s
ROUTINE ======================== main.buildLongString in /root/test/goadv/ch29/profiling/cpu_profiling_example/main.go
20ms 7.63s (flat, cum) 51.48% of Total
. . 32:func buildLongString(count int) string {
. . 33: var s string // 使用+=进行字符串拼接,效率较低
. . 34: for i := 0; i < count; i++ {
20ms 7.63s 35: s += "Iteration " + strconv.Itoa(i) + " and some more text to make it longer. "
. . 36: }
. . 37: return s
. . 38:}
. . 39:
. . 40:// handleRequest: 模拟一个HTTP请求处理器,它会并发执行上述两个任务
(pprof)
list 的输出清晰地指出了 s += "Iteration " + strconv.Itoa(i) + " and some more text to make it longer. " 这一行(第35行)是 buildLongString 函数内部CPU消耗的主要来源,这通常是因为每次 += 都会创建一个新的字符串,导致大量的内存分配和拷贝。
除了命令行交互模式之外,go tool pprof还支持以Web GUI形式进行可视化分析。在 pprof 交互模式下输入 web(或直接使用 go tool pprof -http=:8081 ./cpu_app cpu.prof 启动Web UI),浏览器会自动打开一个包含多种视图的页面(默认View是Graph):
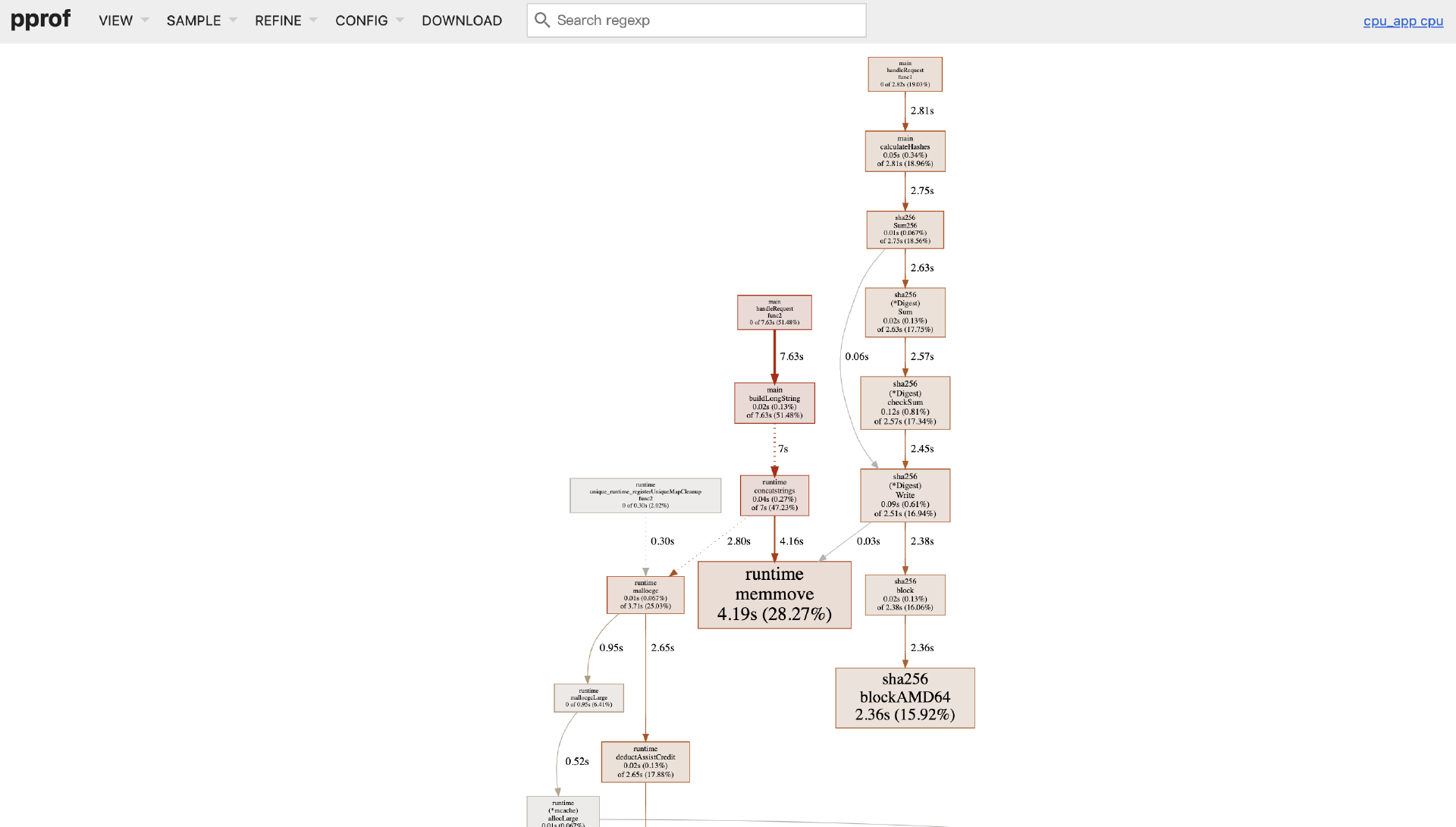
注:Web GUI形式进行可视化分析需要主机上安装graphviz工具。
通过上图我们可以一眼看到sha256.blockAMD64是一个CPU开销大户!
我们也可以通过View菜单选择"Flame Graph"进入火焰图分析视图:
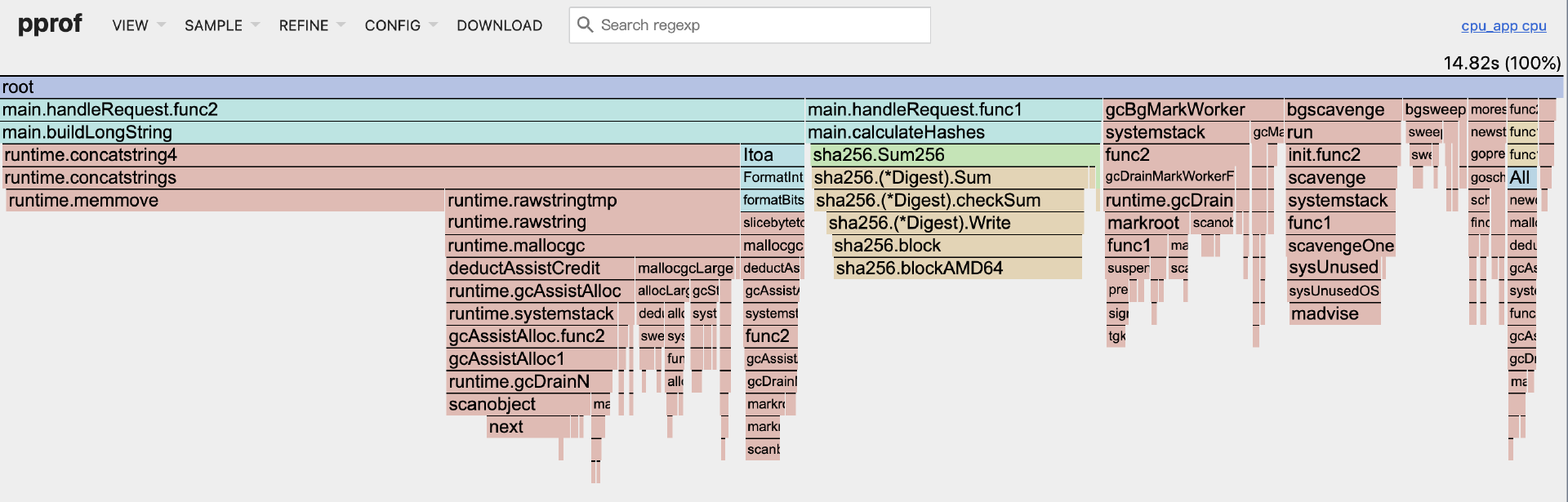
在火焰图中,你会看到一个非常宽的基座可能对应 main.handleRequest 或其启动的goroutine。在其下方, main.calculateHashes 会占据一个显著宽度的条块,并且它的下方大部分宽度会被 sha256.blockAMD64 占据,形成一个“高塔”。
main.buildLongString 也会形成一个相对较宽的条块,其下方可能会看到与字符串转换、内存分配和拷贝相关的运行时函数(如 runtime.concatstrings、 runtime.mallocgc、 runtime.memmove)。
火焰图能非常直观地展示CPU时间是如何在调用栈中分布的,帮助我们快速识别出那些“平顶宽条”(自身耗时多)或“宽底座高塔”(调用链耗时多)的函数。
如果你想更深入地了解某个热点函数(例如,一个你自己写的、没有调用其他库的复杂计算函数)为何耗CPU,可以使用 disasm 查看其汇编代码,并看到CPU样本在具体指令上的分布。这通常用于非常底层的性能优化。
通过这一系列分析,我们已经清晰地定位到 calculateHashes 中的SHA256计算和 buildLongString 中的低效字符串拼接是主要的CPU消耗源。这就为我们下一步的优化指明了方向。在后续讲解“常见性能瓶颈与Go特有的优化技巧”时,我们将针对性地讨论这些模式的优化方法。
CPU是重要的资源,但内存使用不当同样会导致严重的性能问题,甚至服务崩溃。例如,内存泄漏会导致应用可用内存越来越少直至OOM(Out Of Memory);而过于频繁的内存分配则会给垃圾回收器(GC)带来巨大压力,消耗大量CPU并可能引发长时间的STW(Stop-The-World)暂停,严重影响应用响应。Heap Profiling正是我们诊断这类内存问题的“侦探”。
Heap Profiling与内存分配分析:揪出“内存饕餮”
Heap Profile(堆剖析)用于分析Go程序在堆上内存的分配和当前持有情况。它可以帮助我们精准地回答以下问题:
-
哪些代码路径分配了最多的内存(识别内存分配热点)?
-
当前堆上主要是哪些类型的对象占用了内存?
-
这些占用了大量内存的对象,是在哪里被分配出来的(定位内存泄漏源头)?
-
应用的整体内存分配模式是怎样的?是否存在大量不必要的临时对象分配?
Go语言的Heap Profiler也是基于采样的。默认情况下,当程序运行时,Go的内存分配器每当累积分配达到512KB的新内存时就进行一次采样(这个采样率可以通过环境变量 GOMEMPROFILE 或代码 runtime.MemProfileRate 进行调整,例如 runtime.MemProfileRate = 1 表示对每次分配都采样,这会带来非常大的性能开销,仅用于特定调试;设置为0则关闭堆剖析)。每次采样时,Profiler会记录下导致这次(或这批)分配的函数调用栈,以及分配的对象大小和数量。 go tool pprof 在分析heap profile时,会根据这些采样数据和采样率,来估算出各个调用栈实际分配并持有的总内存大小和对象数量。
和cpu profile一样,下面我们也通过一个示例深度解析heap profiling的过程与技巧。在这个示例中,我们将创建两个goroutine,其中一个goroutine会持续向一个全局map中添加数据(模拟内存泄漏),另一个goroutine会高频地创建临时小对象(模拟高GC压力)。示例的代码如下:
// ch29/profiling/heap_profiling_example/main.go
package main
import (
"fmt"
"log"
"math/rand"
"net/http"
_ "net/http/pprof" // 匿名导入以注册pprof HTTP handlers
"runtime" // 用于 GC 和 MemStats
"strconv"
"sync"
"time"
)
var (
// globalCache 模拟一个可能导致内存泄漏的缓存
globalCache = make(map[string][]byte)
cacheMutex sync.Mutex // 保护 globalCache 的并发访问
randSrc = rand.New(rand.NewSource(time.Now().UnixNano())) // 用于生成随机数据
)
// addToCache 持续向全局缓存中添加数据,模拟内存泄漏
func addToCache() {
log.Println("Goroutine 'addToCache' started: continuously adding items to globalCache.")
for i := 0; ; i++ {
key := "cache_key_for_leak_simulation_" + strconv.Itoa(i)
// 模拟不同大小的数据,平均约0.75KB (512 + 1024/2)
dataSize := 512 + randSrc.Intn(512)
data := make([]byte, dataSize) // 分配[]byte
for j := 0; j < dataSize; j++ { // 填充随机数据
data[j] = byte(randSrc.Intn(256))
}
cacheMutex.Lock()
globalCache[key] = data // 将数据存入全局map
cacheMutex.Unlock()
if i%5000 == 0 && i != 0 { // 每5000次打印一次日志,避免刷屏
log.Printf("[addToCache] Added %d items to cache. Current cache size: %d items.\n", i+1, len(globalCache))
// 主动触发一次GC,以便pprof heap能看到更真实的inuse数据(可选)
runtime.GC()
}
time.Sleep(1 * time.Millisecond) // 控制添加速度,避免瞬间撑爆内存
}
}
// frequentSmallAllocs 模拟高频小对象分配
func frequentSmallAllocs() {
log.Println("Goroutine 'frequentSmallAllocs' started: frequently allocating small temporary objects.")
for {
// 模拟在请求处理或一些计算中创建临时对象
for i := 0; i < 1000; i++ {
// 分配一个小字符串(通常会在堆上,如果逃逸或足够大)
_ = fmt.Sprintf("temp_string_data_%d_and_some_padding", i)
// 分配一个小结构体 (如果它逃逸到堆)
// type TempStruct struct { A int; B string }
// _ = &TempStruct{A:i, B:"temp"}
}
time.Sleep(50 * time.Millisecond) // 每轮分配后稍作停顿
}
}
// handleStats 提供一个简单的HTTP端点来查看当前缓存大小和内存统计
func handleStats(w http.ResponseWriter, r *http.Request) {
cacheMutex.Lock()
numItems := len(globalCache)
cacheMutex.Unlock()
var m runtime.MemStats
runtime.ReadMemStats(&m)
fmt.Fprintf(w, "--- Cache Stats ---\n")
fmt.Fprintf(w, "Current cache items: %d\n\n", numItems)
fmt.Fprintf(w, "--- Memory Stats (runtime.MemStats) ---\n")
fmt.Fprintf(w, "Alloc (bytes allocated and not yet freed): %v MiB\n", m.Alloc/1024/1024)
fmt.Fprintf(w, "TotalAlloc (bytes allocated since program start): %v MiB\n", m.TotalAlloc/1024/1024)
fmt.Fprintf(w, "Sys (total bytes of memory obtained from OS): %v MiB\n", m.Sys/1024/1024)
fmt.Fprintf(w, "NumGC: %v\n", m.NumGC)
// ... 可以打印更多 MemStats 字段
}
func main() {
log.SetFlags(log.LstdFlags | log.Lmicroseconds) // 为日志添加微秒时间戳
// 启动pprof HTTP服务器
go func() {
log.Println("Starting pprof HTTP server on localhost:6060")
if err := http.ListenAndServe("localhost:6060", nil); err != nil {
log.Fatalf("Pprof server failed: %v", err)
}
}()
// 启动模拟内存泄漏的goroutine
go addToCache()
// 启动模拟高频小对象分配的goroutine
go frequentSmallAllocs()
// 启动业务HTTP服务器(用于查看stats和触发业务逻辑,如果未来添加)
http.HandleFunc("/stats", handleStats)
port := "8080"
log.Printf("Business server listening on :%s. Access /stats to see cache size.\n", port)
log.Println("Access http://localhost:6060/debug/pprof/heap to get heap profile.")
log.Println("Let the application run for a while to observe memory changes.")
if err := http.ListenAndServe(":"+port, nil); err != nil {
log.Fatalf("Business server failed: %v", err)
}
}
接下来,我们运行一下该程序并对其进行heap剖析。
首先运行Go应用。
$cd ch29/profiling/heap_profiling_example/
$go build -o heap_app -gcflags '-N -l' main.go
$./heap_app
2025/06/12 09:01:30.479049 Business server listening on :8080. Access /stats to see cache size.
2025/06/12 09:01:30.479226 Access http://localhost:6060/debug/pprof/heap to get heap profile.
2025/06/12 09:01:30.479237 Let the application run for a while to observe memory changes.
2025/06/12 09:01:30.479201 Goroutine 'frequentSmallAllocs' started: frequently allocating small temporary objects.
2025/06/12 09:01:30.479057 Starting pprof HTTP server on localhost:6060
2025/06/12 09:01:30.479121 Goroutine 'addToCache' started: continuously adding items to globalCache.
... ...
应用启动后, addToCache goroutine会持续向 globalCache 添加数据,模拟内存泄漏; frequentSmallAllocs goroutine会持续创建临时对象,模拟高GC压力。
然后观察与采集Heap Profile。 让程序运行一段时间(例如,1-2分钟),以便 globalCache 积累数据,并让 frequentSmallAllocs 执行多轮。然后我们采集不同时间点的Heap Profile(主要用于内存泄漏诊断)。在程序启动后不久(比如15-30秒),采集一次heap profile,命名为 heap_early.prof。
$curl -o heap_early.prof http://localhost:6060/debug/pprof/heap
让程序再继续运行1-2分钟,再次采集heap profile,命名为 heap_late.prof。
$curl -o heap_late.prof http://localhost:6060/debug/pprof/heap
接下来,我们先来使用命令行交互方式查看heap_late.prof这个profile:
$go tool pprof ./heap_app heap_late.prof
File: heap_app
Build ID: 8c4020aed8edca3dd41d1940732a66815866c048
Type: inuse_space
Time: 2025-06-12 09:16:20 UTC
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)
我们看到默认是inuse_space视图,即当前持有的内存空间。通过 top 查看内存持有排名:
(pprof) top
Showing nodes accounting for 65.35MB, 100% of 65.35MB total
flat flat% sum% cum cum%
65.35MB 100% 100% 65.35MB 100% main.addToCache
(pprof) top -cum
Showing nodes accounting for 65.35MB, 100% of 65.35MB total
flat flat% sum% cum cum%
65.35MB 100% 100% 65.35MB 100% main.addToCache
切换到alloc_space,可以查看采集的 allocs Profile,它记录的是从程序启动到采集时刻所有发生过的内存分配(包括那些已经被GC回收的),通常更能反映出哪些代码路径是“分配大户”。这可以用于诊断分配热点和GC压力:
(pprof) alloc_space
(pprof) top
Showing nodes accounting for 162.10MB, 99.39% of 163.10MB total
Dropped 5 nodes (cum <= 0.82MB)
Showing top 10 nodes out of 17
flat flat% sum% cum cum%
76.50MB 46.91% 46.91% 76.50MB 46.91% fmt.Sprintf
70.05MB 42.95% 89.85% 70.55MB 43.26% main.addToCache
13.50MB 8.28% 98.13% 90MB 55.18% main.frequentSmallAllocs
1.17MB 0.72% 98.85% 1.17MB 0.72% compress/flate.(*compressor).init
0.88MB 0.54% 99.39% 2.05MB 1.26% compress/flate.NewWriter (inline)
0 0% 99.39% 2.05MB 1.26% compress/gzip.(*Writer).Write
0 0% 99.39% 2.05MB 1.26% net/http.(*ServeMux).ServeHTTP
0 0% 99.39% 2.05MB 1.26% net/http.(*conn).serve
0 0% 99.39% 2.05MB 1.26% net/http.HandlerFunc.ServeHTTP
0 0% 99.39% 2.05MB 1.26% net/http.serverHandler.ServeHTTP
(pprof)
从top10列表来看,main.frequentSmallAllocs调用的fmt.Sprintf、main.addToCache是heap内存分配大户, flat 列显示了该函数自身直接分配的内存, cum 列显示的是该函数及其调用的所有函数分配的heap内存。main.frequentSmallAllocs就是一个自身分配排名第三,但 cum 排名第一的函数,这点从下面top -cum可以印证:
(pprof) top -cum
Showing nodes accounting for 160.94MB, 98.67% of 163.10MB total
Dropped 5 nodes (cum <= 0.82MB)
Showing top 10 nodes out of 17
flat flat% sum% cum cum%
13.50MB 8.28% 8.28% 90MB 55.18% main.frequentSmallAllocs
76.50MB 46.91% 55.18% 76.50MB 46.91% fmt.Sprintf
70.05MB 42.95% 98.13% 70.55MB 43.26% main.addToCache
0.88MB 0.54% 98.67% 2.05MB 1.26% compress/flate.NewWriter (inline)
0 0% 98.67% 2.05MB 1.26% compress/gzip.(*Writer).Write
0 0% 98.67% 2.05MB 1.26% net/http.(*ServeMux).ServeHTTP
0 0% 98.67% 2.05MB 1.26% net/http.(*conn).serve
0 0% 98.67% 2.05MB 1.26% net/http.HandlerFunc.ServeHTTP
0 0% 98.67% 2.05MB 1.26% net/http.serverHandler.ServeHTTP
0 0% 98.67% 2.05MB 1.26% net/http/pprof.Index
(pprof)
和cpu profile一样,通过 list function_name 可以继续向下“钻取”,得到分配内存的“真凶”,以main.frequentSmallAllocs为例:
(pprof) list main.frequentSmallAllocs
Total: 163.10MB
ROUTINE ======================== main.frequentSmallAllocs in /root/test/goadv/ch29/profiling/heap_profiling_example/main.go
13.50MB 90MB (flat, cum) 55.18% of Total
. . 49:func frequentSmallAllocs() {
. . 50: log.Println("Goroutine 'frequentSmallAllocs' started: frequently allocating small temporary objects.")
. . 51: for {
. . 52: // 模拟在请求处理或一些计算中创建临时对象
. . 53: for i := 0; i < 1000; i++ {
. . 54: // 分配一个小字符串(通常会在堆上,如果逃逸或足够大)
13.50MB 90MB 55: _ = fmt.Sprintf("temp_string_data_%d_and_some_padding", i)
. . 56: // 分配一个小结构体 (如果它逃逸到堆)
. . 57: // type TempStruct struct { A int; B string }
. . 58: // _ = &TempStruct{A:i, B:"temp"}
. . 59: }
. . 60: time.Sleep(50 * time.Millisecond) // 每轮分配后稍作停顿
(pprof)
我们看到实际上fmt.Sprintf才是分配内存的“大户”,这和alloc_space下top10的结果是一致的。
go tool pprof支持基于heap profile的增量分析,通过向go tool pprof传入-base选项,我们可以得到新增的内存分配量和持有量的数据:
$go tool pprof -base heap_early.prof ./heap_app heap_late.prof
File: heap_app
Build ID: 8c4020aed8edca3dd41d1940732a66815866c048
Type: inuse_space
Time: 2025-06-12 09:15:01 UTC
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 52.32MB, 100% of 52.32MB total
flat flat% sum% cum cum%
52.32MB 100% 100% 52.32MB 100% main.addToCache
(pprof) alloc_space
(pprof) top
Showing nodes accounting for 127.99MB, 99.61% of 128.49MB total
Dropped 3 nodes (cum <= 0.64MB)
Showing top 10 nodes out of 17
flat flat% sum% cum cum%
59.50MB 46.31% 46.31% 59.50MB 46.31% fmt.Sprintf
54.94MB 42.76% 89.07% 55.44MB 43.15% main.addToCache
11.50MB 8.95% 98.02% 71MB 55.26% main.frequentSmallAllocs
1.17MB 0.91% 98.92% 1.17MB 0.91% compress/flate.(*compressor).init
0.88MB 0.69% 99.61% 2.05MB 1.59% compress/flate.NewWriter (inline)
0 0% 99.61% 2.05MB 1.59% compress/gzip.(*Writer).Write
0 0% 99.61% 2.05MB 1.59% net/http.(*ServeMux).ServeHTTP
0 0% 99.61% 2.05MB 1.59% net/http.(*conn).serve
0 0% 99.61% 2.05MB 1.59% net/http.HandlerFunc.ServeHTTP
0 0% 99.61% 2.05MB 1.59% net/http.serverHandler.ServeHTTP
(pprof)
显然在这种“差值”状态下,fmt.Sprintf、main.addToCache和main.frequentSmallAllocs在持有增量和分配增量上依旧名列前茅。
和cpu profile一样,我们也可以通过Web GUI方式进行heap profile的分析。还是以对heap_late.prof的分析为例,通过下面命令便可以让分析结果以图形化形式呈现在浏览器页面上:
$go tool pprof -http=0.0.0.0:8082 ./heap_app heap_late.prof
打开的Web UI( http://localhost:8082)页面如下图所示:
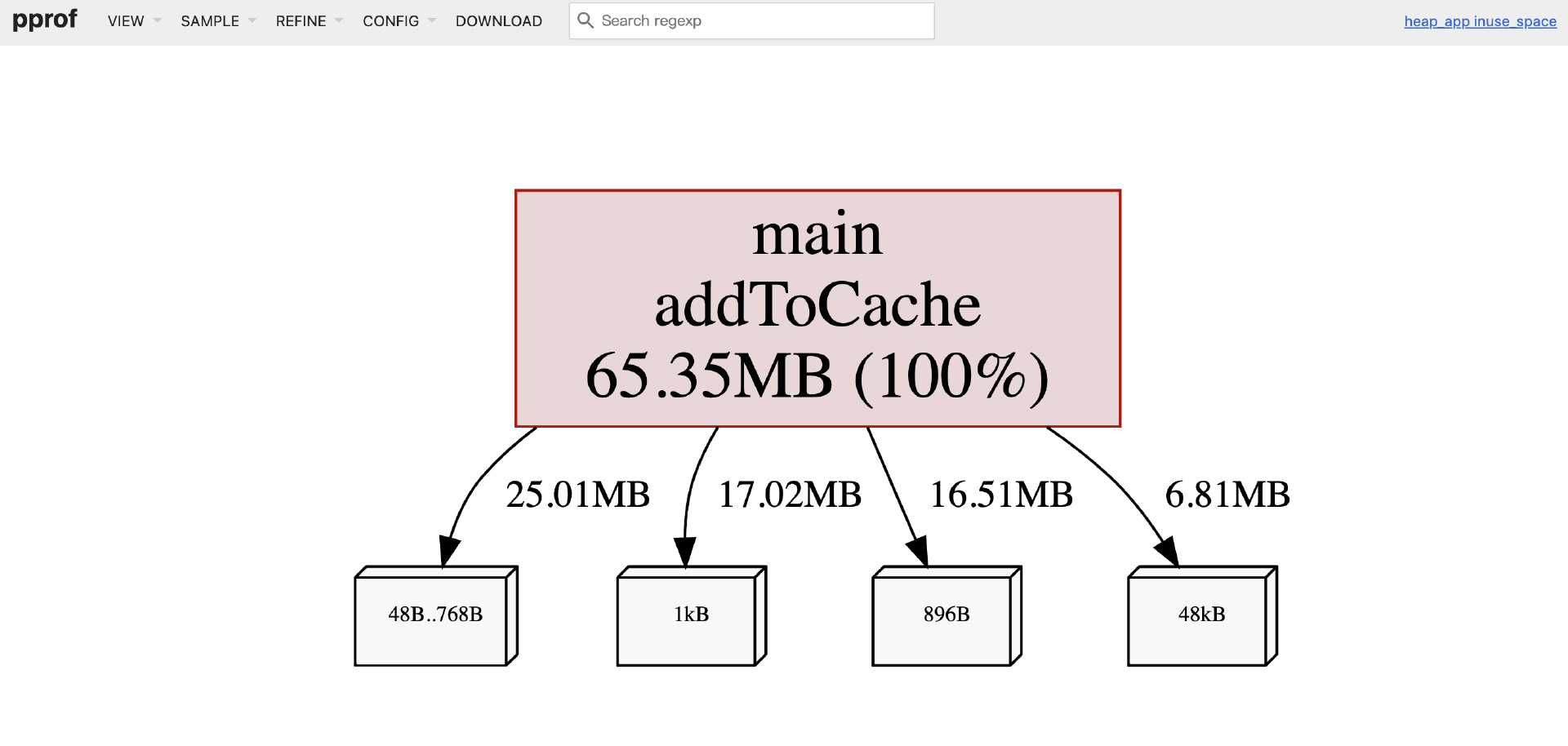
默认显示的是 inuse_space(当前持有的内存空间)的相关视图,你可以通过左上角 “VIEW” 菜单切换各种视图:Top视图、Flame Graph(火焰图)视图等。
你也可以通过 “SAMPLE” 菜单切换到 alloc_space 空间,并查看该空间的相关视图。我们也可以以GUI方式对比早期和晚期快照,诊断内存泄漏(使用 -base 选项):
$go tool pprof -http=0.0.0.0:8082 -base heap_early.prof ./heap_app heap_late.prof
这样打开的Web页面中的各种量就都是“增量”了,即从 heap_early.prof 时刻到 heap_late.prof 时刻之间,新增的内存持有量/分配量。这是诊断内存泄漏的利器。在Web UI的火焰图或Top视图中,那些显著增长的部分,就是在这段时间内泄漏或新分配且未释放的内存的来源。在我们的例子中, main.addToCache 导致的 globalCache 增长会非常明显,如下图所示:

通过Heap Profile的多维度分析——既关注当前持有的内存( inuse_space,用于查泄漏),也关注总分配量( alloc_space,用于查GC压力),我们就能够更全面地理解应用的内存使用模式,并找出需要优化的地方。
到这里,我们已经深入探讨了如何通过CPU Profile定位计算热点,以及如何通过Heap Profile诊断内存分配和泄漏问题。然而,Go程序的性能瓶颈往往不是孤立存在的。很多时候,CPU的繁忙可能源于过度的内存分配导致的GC压力;而应用的响应缓慢,除了CPU和内存因素外,更可能与Go强大的并发模型中goroutine的调度、阻塞以及同步原语(如锁和channel)的使用不当密切相关。
因此,要全面地理解和优化Go程序的性能,我们不能仅仅满足于分析单一类型的profile。更高级的性能调优,需要我们学会综合运用多种profile数据,将它们关联起来,从不同维度相互印证,从而更精准地定位到问题的根本原因。
综合运用多种Profile进行关联分析
虽然CPU Profile和Heap Profile为我们揭示了计算和内存方面的宏观性能瓶颈,但Go应用的性能还深受其并发行为的微观细节影响。当应用出现响应缓慢、吞吐量下降,但CPU和内存使用率看似并不极端时,问题往往潜藏在goroutine的调度、不必要的阻塞或低效的同步开销中。这时,我们就需要结合Goroutine Profile、Block Profile和Mutex Profile,甚至运行时追踪( go tool trace)来进行一次更全面的“会诊”。
Goroutine Profile
首先,让我们看看Goroutine Profile能提供哪些洞察。
正如我们之前讲过的,Goroutine Profile(可以通过 net/http/pprof 的 /debug/pprof/goroutine 端点获取,特别是使用 ?debug=1 或 ?debug=2 参数查看文本堆栈)能够捕获在某一时刻程序中所有存活goroutine的创建位置(即启动该goroutine的函数调用栈)及其当前正在执行(或阻塞)的位置的调用栈。
这份信息的核心价值在于 帮助我们理解应用的并发实体“众生相”。例如,在诊断Goroutine泄漏时,如果发现goroutine数量随时间持续异常增长,通过分析Goroutine Profile中那些大量处于相同阻塞点(比如,等待一个永远不会有数据的channel)且由相同代码路径创建的goroutine,就能快速定位到泄漏的源头。
同时,它也能帮助我们理解应用的整体并发结构和潜在瓶颈,比如哪些代码路径是goroutine的主要“孵化器”,以及这些goroutine当前主要阻塞在什么类型的操作上(如channel收发、select等待、系统调用或锁等待——状态通常会显示为 chan send/receive、 select、 IO wait、 syscall、 semacquire 等)。值得一提的是,Goroutine泄漏通常会伴随着内存泄漏,因为每个未能正常退出的goroutine所占用的栈内存(通常从几KB起步)以及它可能持有的堆上对象引用都无法被GC回收。因此,Goroutine Profile与Heap Profile的 -inuse_space 视图常常需要结合分析,相互印证泄漏的存在和具体影响。
Block Profile
在分析了goroutine的总体状态后,如果怀疑瓶颈在于同步等待,Block Profiling能为我们提供更聚焦的线索。
Go语言中的Block Profile(需要在代码中通过 runtime.SetBlockProfileRate(rate) 开启,并通过 /debug/pprof/block 端点获取)专门记录那些导致goroutine长时间阻塞在Go的核心同步原语上的调用点,以及它们的累积阻塞时间。这些原语主要包括channel的读写操作(当channel满或空时)、 select 语句(当所有case都无法立即满足时),以及 sync.Cond.Wait()。
通过分析Block Profile(例如,在 pprof 工具中使用 top 命令),我们可以识别出哪些特定的channel操作或 select 语句是导致goroutine等待时间最长的“瓶颈点”。例如,如果大量goroutine长时间阻塞在对同一个有缓冲channel的发送操作上,这通常意味着channel已满,表明下游的消费者处理速度跟不上上游的生产者;反之,如果阻塞在接收操作上,则表明channel为空,生产者供应不足。这些信息对于优化并发流程和调整channel缓冲策略至关重要。
Mutex Profile
与Block Profiling相辅相成的是Mutex Profiling,它专门用于揭示由互斥锁( sync.Mutex 和 sync.RWMutex)竞争导致的性能问题。
当多个goroutine频繁尝试获取同一个锁时,就会发生锁竞争,导致后来的goroutine不得不排队等待,这同样会引入显著的性能开销。Mutex Profile(需要在代码中通过 runtime.SetMutexProfileFraction(rate) 开启,并通过 /debug/pprof/mutex 端点获取)记录的正是这些因争用互斥锁而发生等待(阻塞)的调用点,以及它们累积的锁等待时间。通过分析Mutex Profile(同样可以使用 pprof 的 top、 list、火焰图等),我们可以清晰地识别出哪些锁是“热点锁”,即存在最激烈竞争的锁,以及哪些代码路径是这些锁竞争的主要贡献者。例如,如果一个保护了过大临界区的全局锁成为热点,这就强烈提示我们需要将锁的粒度细化,或者优化临界区内的逻辑以减少锁的持有时间。
值得注意的是,严重的锁竞争不仅直接导致goroutine的等待延迟,还可能因为频繁的goroutine上下文切换和调度器活动而间接消耗CPU资源。有时,CPU Profile中与锁获取相关的运行时函数(如 runtime.semaacquiremutex)如果占比较高,也从一个侧面印证了锁竞争的存在。
常见的综合分析场景示例
要真正做到庖丁解牛,往往需要我们将这些不同维度的Profile数据结合起来,进行综合的关联分析。因为性能问题很少是单一因素造成的,它们之间常常存在复杂的因果关系。这里提供一些常见的综合分析思路。
场景1:应用P99延迟很高,但CPU使用率和内存占用看似正常
初步诊断方向:这很可能不是计算密集或内存泄漏问题,而是由I/O等待、锁竞争或Channel阻塞等“等待型”瓶颈主导。
关联分析步骤:
-
首先,查看Goroutine Profile(特别是
debug=2的文本输出):观察是否有大量goroutine阻塞在网络I/O、文件I/O相关的系统调用上(状态通常显示为IO wait或syscall),或者阻塞在特定的channel操作(chan receive/send)或锁等待(semacquire)上。记录下这些阻塞点的代码位置。 -
如果goroutine主要阻塞在channel或
select上,接着分析Block Profile:查看哪些channel或select语句累积了最长的阻塞时间,确认是否与Goroutine Profile中观察到的一致。 -
如果goroutine主要阻塞在锁(
semacquire状态),则分析Mutex Profile:找出竞争最激烈的锁及其调用点。 -
如果怀疑是外部I/O慢(例如,数据库查询慢、调用下游HTTP API慢),此时分布式追踪数据(
go tool trace或OpenTelemetry Tracing)将变得非常关键,它可以清晰地展示外部调用的精确耗时。
场景2:CPU使用率持续高位运行
初步诊断方向:这可能是计算密集型任务,或者是高频内存分配导致的GC压力。
关联分析步骤:
-
首先,分析CPU Profile:使用火焰图和 top/list 命令定位消耗CPU最多的热点函数和代码路径。
-
同时,分析Heap Profile并切换到
-sample_index=alloc_space视图(查看总分配空间):检查是否存在内存分配的热点代码路径。如果某些函数(即使它们在CPU Profile的flat值不高)产生了巨量的内存分配(无论这些内存是否很快被回收),这都会给GC带来巨大压力,导致GC更频繁地运行,从而间接消耗大量CPU时间。 -
再结合
go tool trace:通过Trace视图中的GC事件(特别是STW暂停时长和频率)和Heap视图(堆大小变化),可以验证GC压力是否确实是导致CPU高的一个重要因素。Trace中的Goroutine视图也能显示goroutine在CPU上的实际运行情况,以及被GC抢占的情况。
场景3:内存使用量持续增长,疑似内存泄漏
初步诊断方向:最可能是Goroutine泄漏、未关闭的资源,或者某些全局数据结构只增不减。
关联分析步骤:
-
核心是分析Heap Profile,特别是通过对比不同时间点采集的
-inuse_space快照(使用pprof -base选项)。这能清晰地显示出哪些类型的对象以及它们的分配调用栈,在这段时间内其持有的内存量在持续增长。 -
同时,分析Goroutine Profile:检查goroutine的总数量是否也在不合理地持续增长。如果是,那么泄漏的goroutine本身(包括它们的栈空间)就是内存泄漏的一部分。更重要的是,这些泄漏的goroutine可能还会持有对其他堆上对象的引用,从而阻止这些对象被GC回收。找出泄漏goroutine的创建位置和它们当前阻塞(或卡死)的位置至关重要。
-
最后,根据profile定位到的可疑代码路径,进行深入的代码审查,仔细检查资源(如文件句柄、网络连接、
http.Response.Body)是否都通过defer Close()或类似机制确保了关闭,map或slice等集合类型是否存在只添加不清理的逻辑,以及goroutine的退出条件是否都能被正确触发。
这里的核心思想是:不要孤立地看待任何一种profile数据。每种profile都从一个特定的维度揭示了程序的运行时行为。将CPU、内存(in-use和allocs)、goroutine、block、mutex以及我们接下来要学习的trace数据结合起来,让它们相互印证、互为补充,通常能帮助我们更准确、更全面地理解性能问题的本质,从而避免“头痛医头、脚痛医脚”的片面优化。
小结
这节课,我们首先强调了性能调优的正确方法论(MDOV循环):始终基于数据(测量),明确目标,识别瓶颈,小步快跑并持续验证,避免了凭感觉或过早优化等常见误区。
然后,我们再次深入了Go性能剖析利器 pprof,不仅回顾了其基本用法,更从CPU Profile(定位计算热点)和Heap Profile(诊断内存分配与泄漏,包括 inuse_space 和 alloc_space 视图)两个核心维度进行了深度解析和实战演示。我们还强调了综合运用多种Profile进行关联分析的重要性,简要提及了Goroutine Profile、Block Profile和Mutex Profile在辅助诊断并发和内存问题时的价值,它们能与CPU和Heap Profile相互印证,帮助我们更全面地理解瓶颈。
欢迎在留言区分享你的思考和实践经验!我是Tony Bai,我们下节课见。
性能调优:定位瓶颈,优化Go程序的系统方法(下)
你好,我是Tony Bai。
上节课,通过对 pprof 各种维度的深入剖析和综合关联分析的思维训练,我们能够更精准地定位到Go程序中的绝大多数性能瓶颈,但这通常只是性能调优过程的第一步——定位问题。
pprof 为我们提供了关于资源消耗的聚合性统计视图,它告诉我们“哪些函数或代码路径是热点”。然而,有时 仅仅知道“哪里热”还不够,我们还需要理解“为什么热”以及“热的过程是怎样的”,特别是对于那些与goroutine调度、GC行为、并发交互时序,或细微的I/O等待相关的复杂性能问题。
这时,我们就需要一个能提供更细粒度执行追踪信息的“终极武器”——Go运行时追踪工具。
Go运行时追踪:洞察执行细节与并发交互
Go语言不仅提供了基于采样的 pprof 工具进行性能剖析,还提供了一种基于追踪(tracing)策略的工具。一旦开启,Go应用中发生的特定运行时事件便会被详细记录下来。这个工具就是Go Runtime Tracer(我们通常简称为Tracer),通过 go tool trace 命令进行分析。
Brendan Gregg在其性能分析的著作中曾指出,采样工具(如 pprof)通过测量子集来描绘目标的粗略情况可能会遗漏事件;而追踪则是基于事件的记录,能捕获所有原始事件和元数据。 pprof 的CPU分析基于操作系统定时器(通常每秒100次,即10ms一次采样),这在需要微秒级精度时可能不足。Go Runtime Tracer正是为了弥补这一环,为我们提供了更细致的、事件驱动的运行时洞察。
它由Google的Dmitry Vyukov设计并实现,自Go 1.5版本起便成为Go工具链的一部分,并在后续版本中持续改进,例如提高了数据收集效率和增加了对用户自定义追踪任务和区域的支持,以及更清晰的GC事件展示等。
那么,这个强大的Tracer究竟能为我们做什么呢?
Go Runtime Tracer的核心能力
go tool pprof 帮助我们找到代码中的“热点”,而Go Runtime Tracer则更侧重于揭示程序运行期间 goroutine的动态行为和它们与运行时的交互。Dmitry Vyukov在最初的设计中,期望Tracer能为Go开发者提供至少以下几个方面的详细信息:
-
Goroutine调度事件:
-
Goroutine的创建(
GoCreate)、开始执行(GoStart)、结束(GoEnd)。 -
Goroutine因抢占(
GoPreempt)或主动让出(GoSched)而暂停。 -
Goroutine在同步原语(如channel收发、
select、互斥锁——尽管锁的直接追踪不如Mutex Profile,但其导致的阻塞会反映在goroutine状态上)上的阻塞(GoBlockSend、GoBlockRecv、GoBlockSelect、GoBlockSync等)与被唤醒(GoUnblock)。
-
-
网络I/O事件:Goroutine在网络读写操作上的阻塞与唤醒。
-
系统调用事件:Goroutine进入系统调用(
GoSysCallEnter)与从系统调用返回(GoSysCallExit)。 -
垃圾回收器(GC)事件:
-
GC的开始(
GCSTWStart、GCMarkAssistStart)和停止(GCSTWDone、GCMarkAssistDone)。 -
并发标记(Concurrent Mark)和并发清扫(Concurrent Sweep)的开始与结束。
-
STW(Stop-The-World)暂停的精确起止。
-
-
堆内存变化:堆分配大小(HeapAllocs)和下次GC目标(NextGC)随时间的变化。
-
处理器(P)活动:每个逻辑处理器P在何时运行哪个goroutine,何时处于空闲,何时在执行GC辅助工作等。
-
用户自定义追踪(User Annotation,Go 1.11+):允许开发者在自己的代码中通过
runtime/trace包的API(如trace.WithRegion、trace.NewTask、trace.Logf)标记出特定的业务逻辑区域、任务或事件,这些标记会与运行时事件一起显示在追踪视图中。
有了这些纳秒级精度的事件信息,我们就可以从逻辑处理器P的视角(看到每个P在时间线上依次执行了哪些goroutine和运行时任务)和Goroutine G的视角(追踪单个goroutine从创建到结束的完整生命周期、状态变迁和阻塞点)来全面审视程序的并发执行流。通过对Tracer输出数据中每个P和G的行为进行细致分析,并结合详细的事件数据,我们就能诊断出许多 pprof 难以直接揭示的复杂性能问题。
-
并行执行程度不足的问题:例如,没有充分利用多核CPU资源,某些P长时间空闲,或者goroutine之间存在不必要的串行化。
-
因GC导致的具体应用延迟:可以精确看到GC的STW阶段何时发生、持续多久,以及它如何打断了哪些goroutine的执行。
-
Goroutine执行效率低下或异常延迟:分析特定goroutine为何长时间处于Runnable状态但未被调度,或者为何频繁阻塞在某个同步点、系统调用或网络I/O上。
可以看出,Tracer 与 pprof 工具的CPU、Heap等Profiling剖析是互补的:
-
pprof基于采样,给出的是聚合性统计,适合快速找到“热点”(消耗资源最多的地方)。 -
Tracer 基于事件追踪,记录的是详细的时序行为,适合深入分析“过程是怎样”以及“为什么会这样”。
Tracer 的开销通常比 pprof(尤其是CPU Profile)要大,因为它记录的事件非常多,产生的数据文件也可能大得多。Dmitry Vyukov最初估计Tracer可能带来35%的性能下降,后续版本虽有优化(如Go 1.7将开销降至约25%),但仍不建议在生产环境持续开启,更适合按需、短时间地进行。
了解了 Tracer 能做什么之后,我们来看看如何在Go应用中启用它并收集追踪数据。
为Go应用添加Tracer并收集数据
Go为在应用中启用Tracer并收集追踪数据提供了三种主要方法,它们最终都依赖于标准库的 runtime/trace 包。
手动通过 runtime/trace 包在代码中启停Tracer
这是最直接也最灵活的方式,允许你在代码的任意位置精确控制追踪的开始和结束。下面是一个典型的示例:
// ch29/tracing/manual_trace_start_stop/main.go
package main
import (
"fmt"
"log"
"os"
"runtime/trace"
"sync"
"time"
)
func worker(id int, wg *sync.WaitGroup) {
defer wg.Done()
fmt.Printf("Worker %d: starting\n", id)
time.Sleep(time.Duration(id*100) * time.Millisecond) // 模拟不同时长的任务
fmt.Printf("Worker %d: finished\n", id)
}
func main() {
// 1. 创建追踪输出文件
traceFile := "manual_trace.out"
f, err := os.Create(traceFile)
if err != nil {
log.Fatalf("Failed to create trace output file %s: %v", traceFile, err)
}
// 使用defer确保文件在main函数结束时关闭
defer func() {
if err := f.Close(); err != nil {
log.Printf("Failed to close trace file %s: %v", traceFile, err)
}
}()
// 2. 启动追踪,将数据写入文件f
if err := trace.Start(f); err != nil {
log.Fatalf("Failed to start trace: %v", err)
}
// 3. 核心:使用defer确保trace.Stop()在main函数退出前被调用,
// 这样所有缓冲的追踪数据才会被完整写入文件。
defer trace.Stop()
log.Println("Runtime tracing started. Executing some concurrent work...")
var wg sync.WaitGroup
numWorkers := 5
for i := 1; i <= numWorkers; i++ {
wg.Add(1)
go worker(i, &wg)
}
wg.Wait() // 等待所有worker完成
log.Printf("All workers finished. Stopping trace. Trace data saved to %s\n", traceFile)
fmt.Printf("\nTo analyze the trace, run:\ngo tool trace %s\n", traceFile)
}
这个例子中, trace.Start(f) 开启追踪, defer trace.Stop() 确保程序结束时停止追踪并将数据刷盘。在manual_trace_start_stop目录下,通过go run main.go即可运行起该示例程序。程序运行结束后,就会在当前目录下生成 manual_trace.out 文件。不过要注意: trace.Start 和 trace.Stop 必须成对出现,且 trace.Stop 必须在所有被追踪的活动基本结束后调用,以确保数据完整。如果程序意外崩溃而未能调用 trace.Stop,追踪文件可能不完整或损坏。
这种手动方式非常适合对程序中的特定代码段或整个应用的完整生命周期进行追踪。
通过 net/http/pprof 的HTTP端点动态启停Tracer
如果你的Go应用是一个HTTP服务,并且已经通过匿名导入 _ "net/http/pprof" 注册了pprof的HTTP Handler,那么你可以非常方便地通过其 /debug/pprof/trace 端点来动态地触发和收集追踪数据。
当客户端(如 curl 或浏览器)向该端点发送一个GET请求时, net/http/pprof 包中的 Trace 函数(位于 $GOROOT/src/net/http/pprof/pprof.go)会被调用。这个函数会:
-
解析请求中的
seconds查询参数(例如?seconds=5),如果未提供或无效,则默认为1秒。这个参数决定了追踪的持续时间。 -
设置HTTP响应头,表明将返回一个二进制流附件。
-
调用
trace.Start(w),其中w是http.ResponseWriter。这使得追踪数据直接写入HTTP响应体。 -
等待指定的
seconds时长。 -
调用
trace.Stop()。
假设你的Go Web服务(已导入 _ "net/http/pprof")监听在 localhost:8080,那么通过下面命令便可以抓取接下来5秒的追踪数据,并保存到 http_trace.out 文件中:
$curl -o http_trace.out "http://localhost:8080/debug/pprof/trace?seconds=5"
这种方式非常适合对线上正在运行的服务进行按需、短时间的追踪,以捕捉特定时间窗口内的行为,而无需重启服务或修改代码。但要注意,追踪期间对服务的性能影响。
通过 go test -trace 在测试执行期间收集Tracer数据
如果你想分析的是某个测试用例(单元测试或基准测试)的执行细节, go test 命令提供了一个便捷的 -trace 标志:
# 对当前包的所有测试执行期间进行追踪,结果保存到 trace.out
go test -trace=trace.out .
# 只对名为 TestMySpecificFunction 的测试进行追踪
go test -run=TestMySpecificFunction -trace=specific_test.trace .
# 对名为 BenchmarkMyAlgorithm 的基准测试进行追踪,并运行5秒
go test -bench=BenchmarkMyAlgorithm -trace=bench_algo.trace -benchtime=5s .
命令执行结束后,指定的trace输出文件中就包含了测试执行过程中的追踪数据。这对于分析测试本身的性能瓶颈,或者理解被测代码在测试场景下的并发行为非常有用。
掌握了如何收集追踪数据后,下一步就是如何解读这些数据,从中发掘有价值的信息。
Tracer数据分析:解读可视化视图
有了Tracer输出的数据后,我们接下来便可以使用go tool trace工具对存储Tracer数据的文件进行分析了:
$go tool trace trace.out
// $go tool trace -http=0.0.0.0:6060 trace.out // 可以通过浏览器远程打开Tracer的分析页面
go tool trace会解析并验证Tracer输出的数据文件,如果数据无误,它接下来会在默认浏览器中建立新的页面并加载和渲染这些数据,如下图所示:

我们看到首页显示了多个数据分析的超链接,每个链接将打开一个分析视图,其中:
- View trace by proc/thread:分别从P和thread视角以图形页面的形式渲染和展示tracer的数据(如下图所示),这也是我们最为关注/最常用的功能。
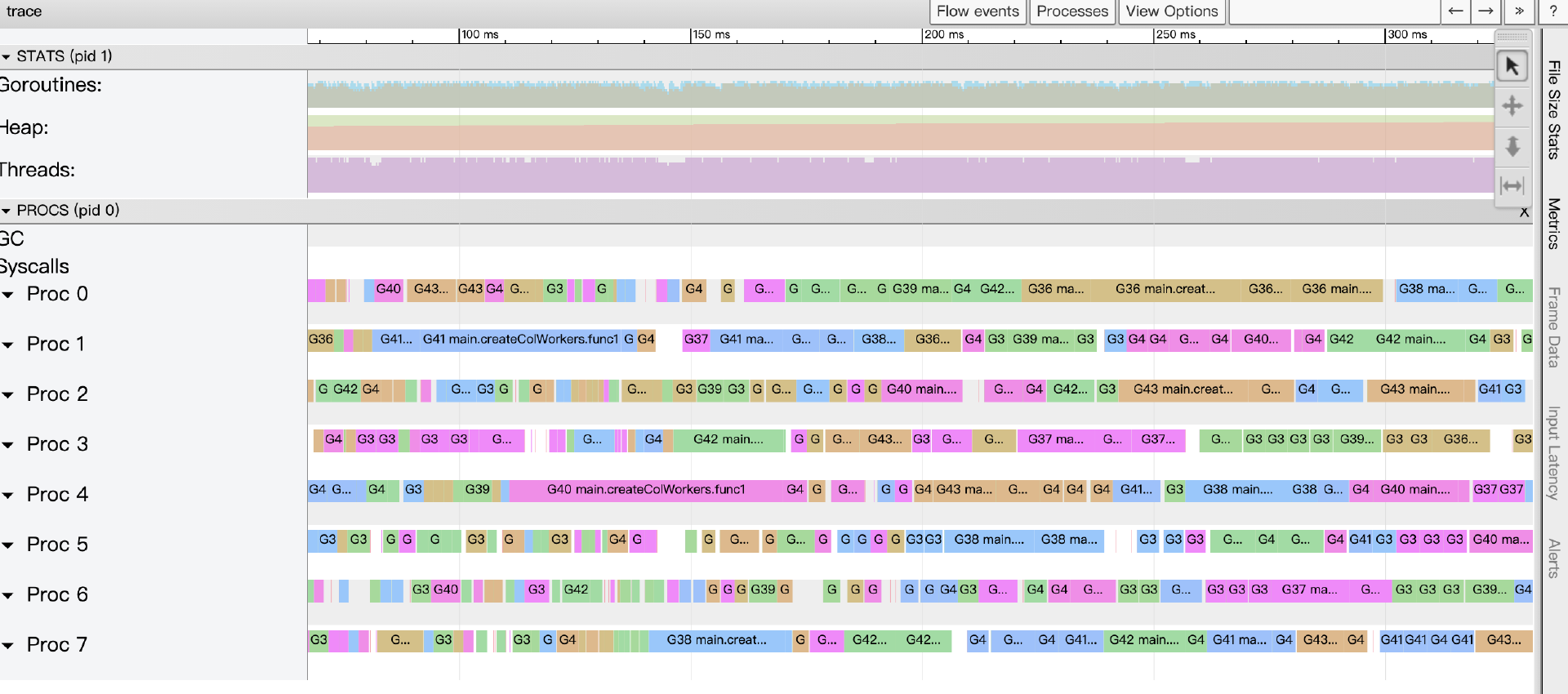
- Goroutine analysis:以表的形式记录执行同一个函数的多个goroutine的各项trace数据。下图的表格记录的是执行main.httpHandler.func3的几个goroutine的各项数据:
-
Network blocking profile:用pprof profile形式的调用关系图展示网络I/O阻塞的情况。
-
Synchronization blocking profile:用pprof profile形式的调用关系图展示同步阻塞耗时情况。
-
Syscall profile:用pprof profile形式的调用关系图展示系统调用阻塞耗时情况。
-
Scheduler latency profile:用pprof profile形式的调用关系图展示调度器延迟情况。
-
User-defined tasks和User-defined regions:用户自定义trace的task和region。
-
Minimum mutator utilization:分析GC对应用延迟和吞吐影响情况的曲线图。
通常我们最为关注的是View trace by proc/thread和Goroutine analysis,下面将详细说说这两项的用法。
View trace by proc/thread
点击 “View trace by proc” 进入Tracer数据分析视图,见下图:
View trace视图是基于google的 trace-viewer 实现的,其大体上可分为四个区域。
第一个区域是时间线(timeline)。 时间线为View trace提供了时间参照系,View trace的时间线始于Tracer开启时,各个区域记录的事件的时间都是基于时间线的起始时间的相对时间。
时间线的时间精度最高为纳秒,但View trace视图支持自由缩放时间线的时间标尺,我们可以在秒、毫秒的“宏观尺度”查看全局,亦可以将时间标尺缩放到微秒、纳秒的“微观尺度”来查看某一个极短暂事件的细节,如下图所示:
如果Tracer跟踪时间较长,trace.out文件较大,go tool trace会将View trace按时间段进行划分,避免触碰到trace-viewer的限制:

View trace使用快捷键来缩放时间线标尺:w键用于放大(从秒向纳秒缩放),s键用于缩小标尺(从纳秒向秒缩放)。我们同样可以通过快捷键在时间线上左右移动:s键用于左移,d键用于右移。如果你记不住这些快捷键,可以点击View trace视图右上角的问号?按钮,浏览器将弹出View trace操作帮助对话框,View trace视图的所有快捷操作方式都可以在这里查询到。
第二个区域是采样状态区(STATS)。 这个区内展示了三个指标:Goroutines、Heap和Threads,某个时间点上这三个指标的数据是这个时间点上的状态快照采样。
Goroutines表示某一时间点上应用中启动的goroutine的数量。当我们点击某个时间点上的goroutines采样状态区域时(我们可以用快捷键m来准确标记出那个时间点),事件详情区会显示当前的goroutines指标采样状态:
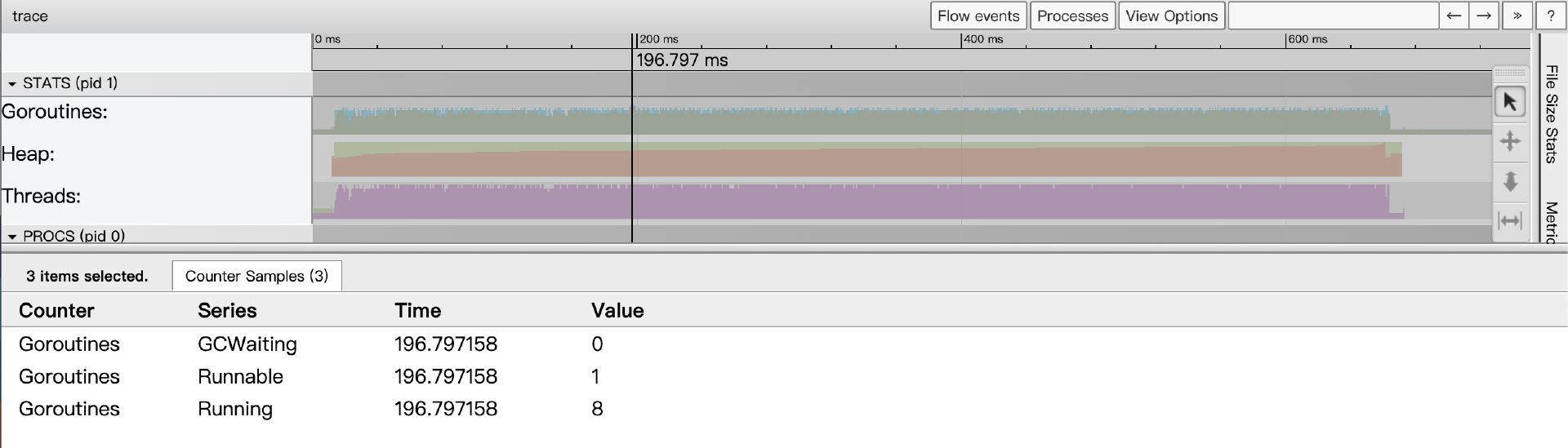
从上图中我们看到,那个时间点上共有9个goroutine,8个正在运行,另外1个准备就绪,等待被调度。处于GCWaiting状态的goroutine数量为0。
而Heap指标则显示了某个时间点上Go应用heap分配情况(包括已经分配的Allocated和下一次GC的目标值NextGC):
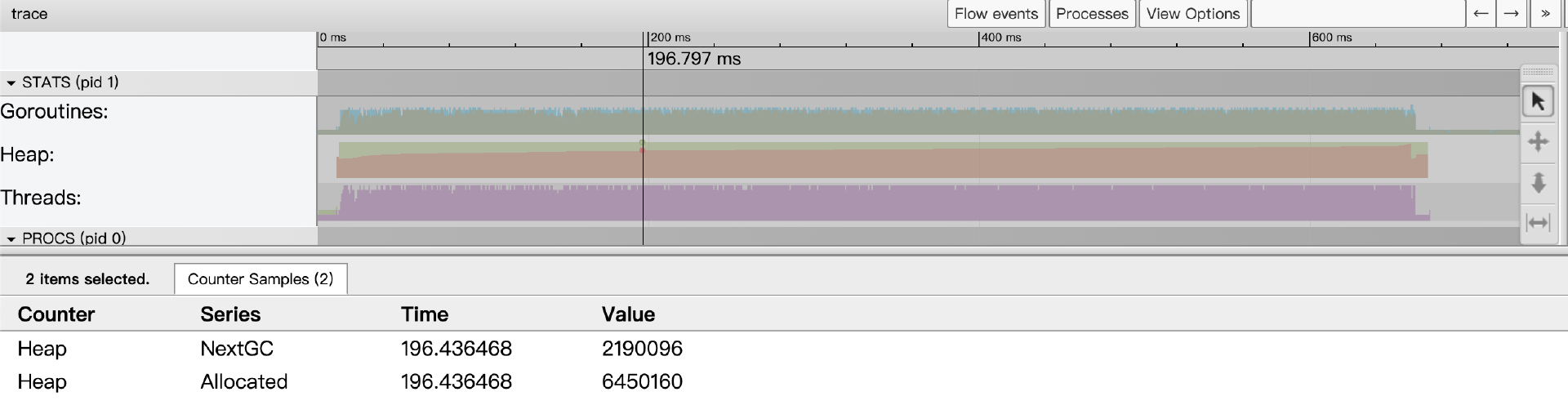
Threads指标显示了某个时间点上Go应用启动的线程数量情况,事件详情区将显示处于InSyscall(整阻塞在系统调用上)和Running两个状态的线程数量情况:
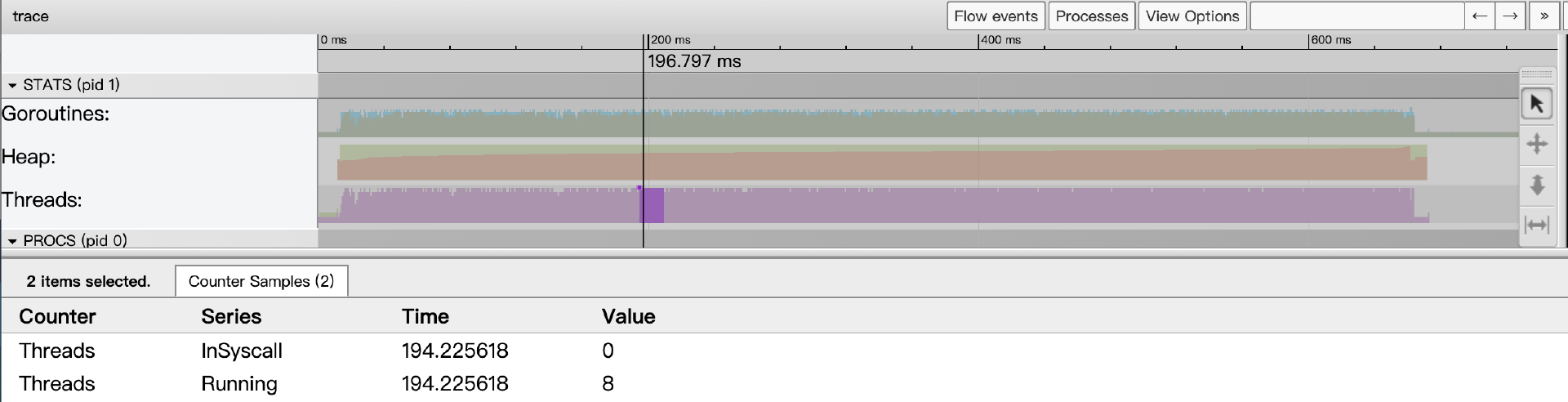
总的来说,连续的采样数据按时间线排列描绘出了各个指标的变化趋势情况。
第三个区域是P视角区(PROCS)。 这里将View trace视图中最大的一块区域称为“P视角区”。这是因为在这个区域,我们能看到Go应用中每个P(Goroutine调度概念中的P)上发生的所有事件,包括:EventProcStart、EventProcStop、EventGoStart、EventGoStop、EventGoPreempt、Goroutine辅助GC的各种事件,以及Goroutine的GC阻塞(STW)、系统调用阻塞、网络阻塞,以及同步原语阻塞(mutex)等事件。除了每个P上发生的事件,我们还可以看到以单独行显示的GC过程中的所有事件。
另外我们看到每个Proc对应的条带都有两行,上面一行表示的是运行在该P上的Goroutine的主事件,而第二行则是一些其他事件,比如系统调用、运行时事件等,或是goroutine代表运行时完成的一些任务,比如代表GC进行并行标记。下图展示了每个Proc的条带:

我们放大图像,看看Proc对应的条带的细节:
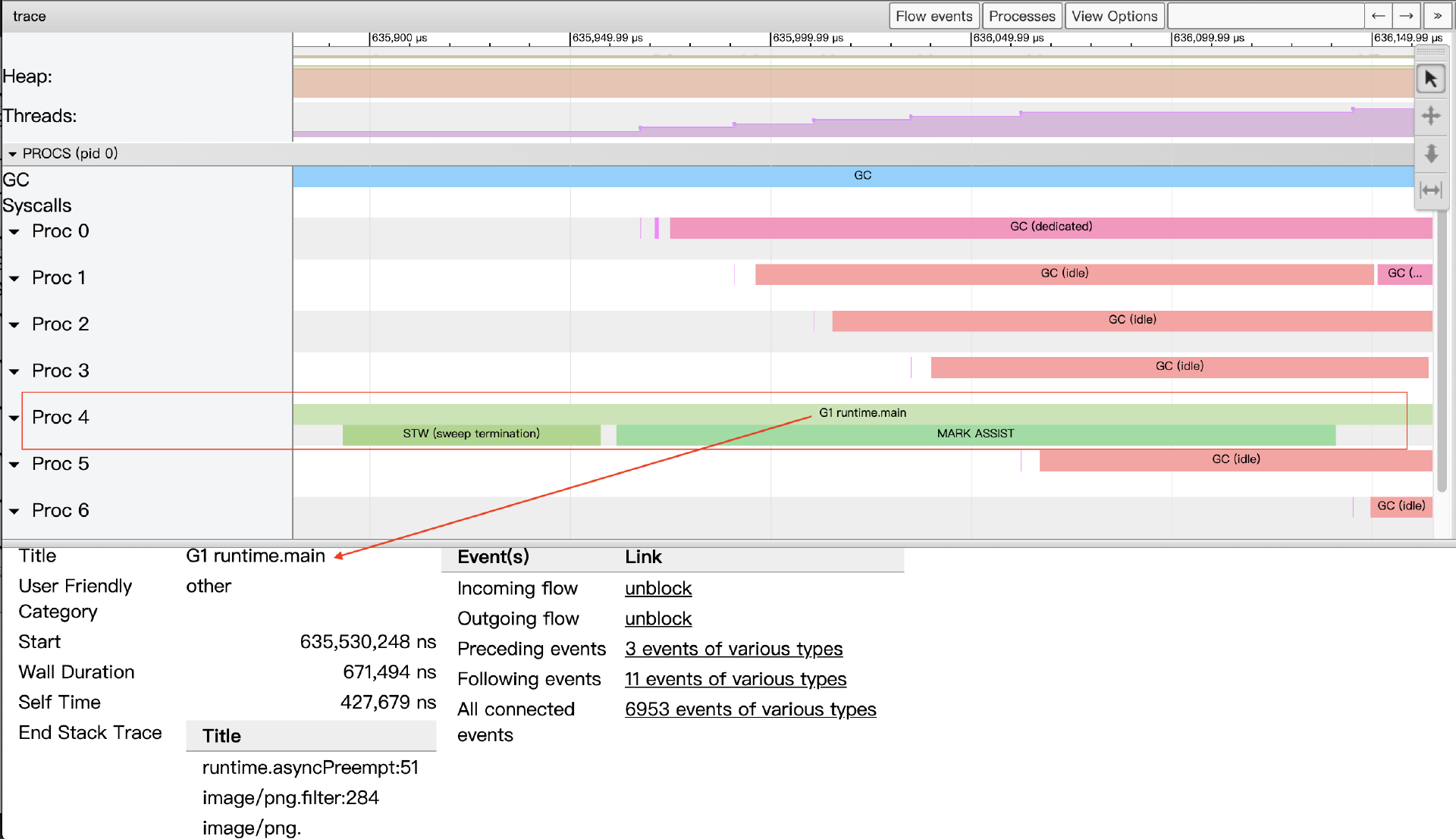
我们以上图proc4中的一段条带为例,这里包含三个事件。条带两行中第一行的事件表示的是,G1这个goroutine被调度到P4运行,选中该事件,在事件详情区可以看到该事件的详细信息:
-
Title:事件的可读名称。
-
Start:事件的开始时间,相对于时间线上的起始时间。
-
Wall Duration:这个事件的持续时间,这里表示的是G1在P4上此次持续执行的时间。
-
Start Stack Trace:当P4开始执行G1时G1的调用栈。
-
End Stack Trace:当P4结束执行G1时G1的调用栈;从上面End Stack Trace栈顶的函数为runtime.asyncPreempt来看,该Goroutine G1是被强行抢占了,这样P4才结束了其运行。
-
Incoming flow:触发P4执行G1的事件。
-
Outgoing flow:触发G1结束在P4上执行的事件。
-
Preceding events:与G1这个goroutine相关的之前的所有事件。
-
Follwing events:与G1这个goroutine相关的之后的所有事件。
-
All connected:与G1这个goroutine相关的所有事件。
proc4条带的第二行按顺序先后发生了两个事件,一个是stw,即GC暂停所有goroutine执行;另外一个是让G1这个goroutine辅助执行GC过程的并发标记(可能是G1分配内存较多较快,GC选择让其交出部分算力做gc标记)。
通过P视角区,我们可以可视化地显示整个程序(每个Proc)在程序执行时间线上的全部情况,尤其是按时间线顺序显示每个P上运行的各个goroutine(每个goroutine都有唯一独立的颜色)相关事件的细节。
P视角区显示的各个事件间存在关联关系,我们可以通过视图上方的“flow events”按钮打开关联事件流,这样在图中我们就能看到某事件的前后关联事件关系了(如下图):
第四个区域是事件详情区。 View trace视图的最下方为“事件详情区”,当我们点选某个事件后,关于该事件的详细信息便会在这个区域显示出来,就像上面Proc条带图示中的那样。
在宏观尺度上,每个P条带的第二行的事件因为持续事件较短而多呈现为一条竖线,我们点选这些事件不是很容易。点选这些事件的方法,要么将图像放大,要么通过左箭头或右箭头两个键盘键顺序选取,选取后可以通过m键显式标记出这个事件(再次敲击m键取消标记)。
Goroutine analysis
就像前面图中展示的Goroutine analysis的各个子页面那样,Goroutine analysis为我们提供了从G视角看Go应用执行的图景。
点击前面Goroutine analysis图中位于Goroutines表第一列中的任一个Goroutine id,我们将进入G视角视图:
我们看到与View trace不同,这次页面中最广阔的区域提供的G视角视图,而不再是P视角视图。在这个视图中,每个G都会对应一个单独的条带(和P视角视图一样,每个条带都有两行),通过这一条带我们可以按时间线看到这个G的全部执行情况。
通过熟练运用Tracer UI的这些视图,并结合对Go运行时基本原理的理解,我们就能够从海量的追踪事件中提取出有价值的信息,诊断出许多隐藏较深的性能问题。
为了更具体地理解Go Runtime Tracer如何帮助我们分析和优化并发程序的性能,让我们来看一个经典的实例。
实例理解:通过Trace优化并发分形图渲染
这个例子来源于早期Go社区中一篇广受欢迎的关于Tracer使用的文章,它通过逐步优化一个并发生成分形图像(曼德布洛特集)的程序,清晰地展示了 go tool trace 在分析并行度、goroutine行为和并发瓶颈方面的强大能力。
我们将跳过分形算法本身的数学细节,重点关注不同并发实现版本在Trace视图中的表现,以及如何根据Trace的反馈进行优化。
初始版本:串行计算
假设我们有一个第一版的代码,它串行地计算图像中的每一个像素点:
// ch29/tracing/fractal_example/versions/v1_sequential/main.go
package main
import (
"image"
"image/color"
"image/png"
"log"
"os"
"runtime/trace"
)
const (
output = "out.png"
width = 2048
height = 2048
numWorkers = 8
)
func main() {
trace.Start(os.Stdout)
defer trace.Stop()
f, err := os.Create(output)
if err != nil {
log.Fatal(err)
}
img := createSeq(width, height)
if err = png.Encode(f, img); err != nil {
log.Fatal(err)
}
}
// createSeq fills one pixel at a time.
func createSeq(width, height int) image.Image {
m := image.NewGray(image.Rect(0, 0, width, height))
for i := 0; i < width; i++ {
for j := 0; j < height; j++ {
m.Set(i, j, pixel(i, j, width, height))
}
}
return m
}
// pixel returns the color of a Mandelbrot fractal at the given point.
func pixel(i, j, width, height int) color.Color {
// Play with this constant to increase the complexity of the fractal.
// In the justforfunc.com video this was set to 4.
const complexity = 1024
xi := norm(i, width, -1.0, 2)
yi := norm(j, height, -1, 1)
const maxI = 1000
x, y := 0., 0.
for i := 0; (x*x+y*y < complexity) && i < maxI; i++ {
x, y = x*x-y*y+xi, 2*x*y+yi
}
return color.Gray{uint8(x)}
}
func norm(x, total int, min, max float64) float64 {
return (max-min)*float64(x)/float64(total) - max
}
这一版代码通过pixel函数算出待输出图片中的每个像素值,这版代码即便不用pprof也基本能定位出来程序热点在pixel这个关键路径的函数上,更精确的位置是pixel中的那个循环。那么如何优化呢?pprof已经没招了,我们用Tracer来看看。
运行这个版本并生成trace文件和分型图:
$go build -o mandelbrot_v1 main.go
$./mandelbrot_v1 > fractal_v1_seq.trace
$go tool trace fractal_v1_seq.trace
我们会在Trace UI的“View trace”中看到类似下图的数据:
我们看到: 只有一个P(逻辑处理器)在忙碌,其他P都处于空闲状态。Goroutines行上只有主goroutine在稳定地执行计算。这清晰地表明,这个串行版本完全没有利用多核CPU的并行能力。
第二版:极端并发 - 每像素一个Goroutine
为了利用多核,一个直接的想法是为每个像素点的计算都启动一个goroutine。
// ch29/tracing/fractal_example/v2_pixel_goroutine/main.go
func createPixelParallel(width, height int) image.Image {
m := image.NewGray(image.Rect(0, 0, width, height))
var wg sync.WaitGroup
wg.Add(width * height)
for i := 0; i < width; i++ {
for j := 0; j < height; j++ {
go func(px, py int) { // 注意捕获循环变量
defer wg.Done()
m.Set(px, py, pixel(px, py, width, height))
}(i, j)
}
}
wg.Wait()
return m
}
// main函数中调用 createPixelParallel 替换第一版中的 createSeq
运行这个版本并生成trace文件和分形图:
$go build -o mandelbrot_v2 main.go
$./mandelbrot_v2 > fractal_v2_goroutine.trace
$go tool trace fractal_v2_goroutine.trace
这一版性能上比第一版的纯串行思路的确有所提升,并且Trace视图会显示所有CPU核心都被利用起来了,但它也暴露了新的问题。
以261.954ms附近的事件数据为例,我们看到系统的8个cpu core都满负荷运转,但从goroutine的状态采集数据看到,仅有7个goroutine处于运行状态,而有21971个goroutine正在等待被调度,这给go运行时的调度带去很大压力;另外由于这一版代码创建了2048x2048个goroutine(400多w个),导致内存分配频繁,给GC造成很大压力,从视图上来看,每个Goroutine似乎都在辅助GC做并行标记。由此可见,我们不能创建这么多goroutine,即无脑地为每个最小单元都创建goroutine并非最佳策略。
接下来,我们来看第三版代码。
第三版:按列并发 - 每列一个Goroutine
于是作者又给出了第三版代码,仅创建2048个goroutine,每个goroutine负责一列像素的生成(用下面createCol替换createPixel)。
接下来一个自然而然的改进思路是减少goroutine的数量,让每个goroutine承担更多的工作。例如,为图像的每一列启动一个goroutine,由它负责计算该列所有像素,用下面createCol替换第二版的createPixel:
// ch29/tracing/fractal_example/v3_column_goroutine/main.go
func createColumnParallel(width, height int) image.Image {
m := image.NewGray(image.Rect(0, 0, width, height))
var wg sync.WaitGroup
wg.Add(width) // 为每一列启动一个goroutine
for i := 0; i < width; i++ {
go func(colIdx int) {
defer wg.Done()
for j := 0; j < height; j++ { // 该goroutine负责计算一整列
m.Set(colIdx, j, pixel(colIdx, j, width, height))
}
}(i)
}
wg.Wait()
return m
}
运行这个版本并生成trace文件和分形图:
$go build -o mandelbrot_v3 main.go
$./mandelbrot_v3 > fractal_v3_goroutine.trace
$go tool trace fractal_v3_goroutine.trace
这个版本的性能通常会比第二版好很多。Trace视图会显示数量可控的goroutine(例如,1024个)在各个P上稳定运行,GC压力也会显著降低。这证明了合理的并发粒度对于性能的重要性。
还可以再优化么?你可以回顾一下我们在并发设计那节课提到过的并发模式。没错!我们可以试试Worker池模式。接下来,我们看一下第四版代码。
第四版:固定Worker池模式
这一版代码使用了固定数量的Worker goroutine池,并通过channel向它们派发任务(每个任务是计算一个像素点)。
// ch29/tracing/fractal_example/v4_worker_pool_pixel_task/main.go
// createWorkers creates numWorkers workers and uses a channel to pass each pixel.
func createWorkers(width, height int) image.Image {
m := image.NewGray(image.Rect(0, 0, width, height))
type px struct{ x, y int }
c := make(chan px)
var w sync.WaitGroup
for n := 0; n < numWorkers; n++ {
w.Add(1)
go func() {
for px := range c {
m.Set(px.x, px.y, pixel(px.x, px.y, width, height))
}
w.Done()
}()
}
for i := 0; i < width; i++ {
for j := 0; j < height; j++ {
c <- px{i, j}
}
}
close(c)
w.Wait()
return m
}
运行这个版本并生成trace文件和分形图:
$go build -o mandelbrot_v4 main.go
$./mandelbrot_v4 > fractal_v4_goroutine.trace
$go tool trace fractal_v4_goroutine.trace
示例中预创建了8个worker goroutine(和主机核数一致),主goroutine通过一个channel c向各个goroutine派发工作。但这个示例并没有达到预期的性能,其性能还不如每个像素一个goroutine的版本。查看Tracer情况如下(这一版代码的Tracer数据更多,解析和加载时间更长):
适当放大View trace视图后,我们看到了很多大段的Proc暂停以及不计其数的小段暂停,显然goroutine发生阻塞了,我们接下来通过Synchronization blocking profile查看究竟在哪里阻塞时间最长:

我们看到,在channel接收上所有goroutine一共等待了近60s。从这版代码来看,main goroutine要进行近400多w次发送,而其他8个worker goroutine都得耐心阻塞在channel接收上等待,这样的结构显然不够优化,即便将channel换成带缓冲的也依然不够理想。
估计到这里,你也想到了第三版代码的的思路,即不将每个像素点作为一个task发给worker,而是将一个列作为一个工作单元发送给worker,每个worker完成一个列像素的计算,这样我们来到了最终版代码(使用下面的createColWorkersBuffered替换createWorkers)。
最终优化版:Worker池 + 每列一个任务
结合第三版和第四版的思路,一个更优的方案是:仍然使用固定数量的Worker goroutine池,但通过channel派发的任务不再是单个像素点,而是计算一整列像素的任务。
// ch29/tracing/fractal_example/v5_worker_pool_column_task/main.go
func createColWorkersBuffered(width, height int) image.Image {
m := image.NewGray(image.Rect(0, 0, width, height))
c := make(chan int, width)
var w sync.WaitGroup
for n := 0; n < numWorkers; n++ {
w.Add(1)
go func() {
for i := range c {
for j := 0; j < height; j++ {
m.Set(i, j, pixel(i, j, width, height))
}
}
w.Done()
}()
}
for i := 0; i < width; i++ {
c <- i
}
close(c)
w.Wait()
return m
}
这版代码的确是所有版本中性能最好的,并且这个版本的Trace视图也展现出近乎完美的并行执行效果:所有P都被充分利用,goroutine稳定运行,channel的同步开销因任务粒度增大而显著降低,GC压力也得到良好控制。
从这个分形图渲染的实例演进中,我们可以深刻体会到:
-
go tool trace能够直观地暴露并行度不足、goroutine调度压力过大,以及因同步原语(如channel)使用不当导致的性能瓶颈。 -
通过观察Trace视图中P的利用率、goroutine的状态和数量、GC活动以及同步阻塞情况,我们可以获得优化并发设计的宝贵线索。
-
性能调优往往是一个不断试错、测量、分析、再优化的迭代过程,Tracer是这个过程中不可或缺的重要工具。
这个实例清晰地展示了 go tool trace 在分析和指导并发程序优化方面的强大能力。理解了它的基本用法和解读方式后,我们来系统总结一下它在不同场景下的应用。
go tool trace 的应用场景
Go Runtime Tracer凭借其对运行时事件的细粒度捕捉和丰富的可视化分析能力,在性能调优和复杂问题诊断中扮演着不可或缺的角色,尤其擅长处理以下几类场景:
-
诊断并行执行程度不足:通过观察Trace UI中P时间线的利用率,以及Goroutine视图中大量goroutine是否处于Runnable状态但长时间得不到调度,可以判断应用是否未能充分利用多核CPU资源。
-
分析和优化GC导致的延迟:Trace视图中的GC行和Heap行,以及Minimum Mutator Utilization图表,可清晰地揭示了GC的STW暂停时长、并发标记/清扫阶段对应用goroutine的影响。
-
深入分析Goroutine执行效率与阻塞原因:当
pprof的Goroutine Profile显示大量goroutine存在,或者Block/Mutex Profile指示存在同步瓶颈时,go tool trace能提供更细致的上下文,展示goroutine具体阻塞在哪个同步原语、系统调用或网络I/O上,以及它们被唤醒的时机和后续行为。 -
理解和优化复杂的并发交互逻辑:对于包含多个goroutine通过channel、
select、sync.Cond等进行复杂协作的场景,Trace的时间线视图和事件流关联功能,能够帮助我们梳理清楚它们之间的实际交互时序,发现是否存在不必要的等待、竞争条件,甚至死锁/活锁的倾向。 -
精确追踪和分解长尾延迟请求(结合用户自定义追踪):通过在应用代码的关键业务逻辑路径上使用
runtime/trace.WithRegion、trace.NewTask、trace.Logf等API添加用户自定义的追踪标记,我们可以将一个端到端的请求分解为多个命名的子任务或区域。在Trace UI的“User-defined tasks”或“User-defined regions”视图中,可以清晰地看到这些自定义标记的层级关系和各自的精确耗时,这对于定位长尾延迟请求中的具体瓶颈环节非常有效。
总的来说, go tool trace 是 pprof 的重要补充。当 pprof 告诉我们“是什么”消耗了资源后, trace 能进一步帮助我们理解“为什么”以及“过程是怎样”的。它尤其擅长揭示与时间相关的动态行为、并发交互的细节,以及运行时(特别是GC和调度器)对应用性能的细微影响。虽然开启Trace的性能开销相对较大,不适合长时间在生产环境全量开启,但作为一种按需的、短时间的深度诊断工具,它在解决Go应用的疑难性能杂症方面具有不可替代的价值。
在掌握了 pprof 和 trace 这两大官方性能分析利器之后,我们就可以更系统地来看待Go中常见的性能瓶颈类型,并学习针对它们的、具有Go特色的优化技巧了。这正是我们下一部分要探讨的内容。
常见性能瓶颈与Go特有的优化技巧
理解常见的性能瓶颈模式,并掌握针对性的优化方法,是性能调优工作的核心。Go语言因其独特的运行时(如GC、goroutine调度器)和语言特性(如channel、interface、defer),也形成了一些特有的性能考量点和优化技巧。接下来,我们将概要性地梳理Go中常见的性能瓶颈类型及其对应的、具有Go特色的优化技巧和最佳实践,为你提供一个实用的优化“速查手册”。再次强调,所有优化都应遵循“测量-定位-优化-验证”的原则。
CPU密集型瓶颈:让计算更高效
当CPU Profile(如火焰图)显示程序的大部分时间消耗在计算而非等待时,我们就遇到了CPU瓶颈。
-
核心优化方向:优化算法与数据结构是根本。例如,对需要频繁查找的场景,使用
map通常优于slice遍历。 -
字符串操作:正如我们之前讲过的,Go中字符串是不可变的,频繁使用
+拼接字符串会产生大量临时对象和内存分配,严重影响性能。务必使用strings.Builder或bytes.Buffer进行高效拼接。尽可能在处理过程中使用[]byte,仅在最终需要时转换为string。对于简单的子串匹配,优先使用strings包内函数而非正则表达式。 -
序列化/反序列化:标准库
encoding/json等基于反射,在高频场景下可能成为瓶颈。若pprof证实如此,可考虑性能更高的第三方库(如bytedance/sonic、json-iterator/go)。 -
正则表达式:对需要反复使用的正则表达式,必须使用
regexp.Compile()进行预编译,复用编译后的*regexp.Regexp对象。 -
并发分解:对于可并行的计算任务,利用goroutine和channel将其分解到多核执行。但要注意避免为过细小的任务创建goroutine,以免调度开销过大。
-
避免热点路径的
interface{}:接口操作有运行时开销,在性能极度敏感的热点代码中,若构成瓶颈,可考虑使用具体类型或泛型(Go 1.18+)优化。 -
底层优化(进阶):在极少数情况下,如果上述优化仍不足,且
pprof -disasm显示瓶颈在非常底层的计算,可考虑手动进行循环展开、优化内存访问模式以提升缓存命中率,甚至(极罕见)使用汇编或SIMD指令。这些属于专家级优化,需极度谨慎并充分测试。
注: Go团队已正式提案在标准库里提供SIMD API,旨在为Go开发者提供一种无需编写汇编即可利用底层硬件加速能力的方式。
内存分配与GC:减少开销,避免泄漏
内存问题主要表现为内存泄漏( inuse_space 持续增长)或高频分配( alloc_space 过高导致GC压力大,CPU Profile中GC占比较高)。
-
诊断内存泄漏:核心是对比不同时间点的Heap Profile(
pprof -base),找出持续增长的对象及其分配来源。同时结合Goroutine Profile检查是否存在goroutine泄漏(其栈和持有对象无法回收)。代码审查时,特别关注资源是否正确关闭(defer Close())、全局集合是否只增不减、time.Ticker是否停止。 -
减少内存分配:
-
对象复用(
sync.Pool):对可重置的、频繁创建和销毁的临时对象(如缓冲区、临时结构体)使用sync.Pool,能显著减少分配和GC压力。 -
预分配容量:创建
slice和map时,如果能预估大小,通过make指定初始容量,避免多次扩容。 -
谨慎使用
defer在热点循环中:如果defer的操作(如资源释放)可以被安全地、显式地提前执行,可能比依赖defer栈在函数退出时处理要好,尤其是在长循环或高频短函数中。 -
指针传递大型结构体:避免不必要的值拷贝。
-
-
GC调优(审慎进行):
-
GOGC:控制GC触发的堆增长比例。减小值使GC更频繁(可能STW更短但总CPU消耗高),增大则相反。 -
GOMEMLIMIT(Go 1.19+):设置内存软上限,辅助GC决策,有助于在容器等内存受限环境中避免OOM。
-
务必注意:调整GC参数是最后手段,通常应优先优化代码自身的分配行为。
并发同步:降低竞争,提升并行度
Go的并发模型虽好,不当的同步原语使用也可能导致性能瓶颈。
- 锁竞争(
sync.Mutex、sync.RWMutex):-
细化锁粒度:只锁必要的数据,避免大范围的全局锁。
-
避免长时间持锁:临界区代码应尽可能快。绝不在持锁时进行I/O等耗时操作。
-
审慎使用
RWMutex:仅在“读远多于写且读临界区短”时才可能有优势。
-
- Channel使用:
-
合理缓冲:根据生产者/消费者速率选择合适的缓冲大小。
-
避免不必要的阻塞:在
select中使用default或超时case。 -
明确关闭时机:通常由发送方或唯一协调者关闭,以通知接收方。
-
- Goroutine管理:
- 避免高频创建销毁极短任务的goroutine:考虑使用Worker Pool模式复用goroutine。
- 原子操作(
sync/atomic):对简单共享标量(计数器、标志位)的无锁更新通常比锁高效。但要注意高并发下对同一缓存行的原子写也可能因“缓存行乒乓”成为瓶颈。
I/O操作:加速与外部世界的交互
当应用瓶颈在于等待外部I/O(网络、磁盘、数据库)时,优化重点在于 减少等待时间和提高I/O效率。
-
并发执行独立I/O:利用goroutine并发处理可并行的I/O任务。
-
设置超时与重试:对所有外部调用(特别是网络)使用
context.WithTimeout,并实现合理的重试逻辑(如指数退避)。 -
连接池:务必为数据库、Redis等使用连接池,并合理配置。
-
批量操作(Batching):将多个小的I/O操作聚合成批量操作,减少往返次数。
-
缓冲I/O(
bufio):处理文件或网络流时,使用bufio.Reader/Writer减少系统调用。
利用Go编译器与运行时优化:PGO及其他
除了我们自己通过改进代码逻辑和算法来实现性能优化外,Go编译器和运行时本身也在不断地进化,提供了越来越多的自动化或半自动化的性能优化手段。
-
Profile-Guided Optimization(PGO,Go 1.21+):PGO允许编译器利用程序在真实负载下收集到的性能剖析数据(CPU profile)来做出更优的优化决策,例如更积极的函数内联、改进的去虚拟化(devirtualization)和优化的代码布局。
-
流程:先在类生产环境收集CPU profile(
default.pgo),再使用go build -pgo=default.pgo编译。 -
效果:通常能带来2-7%的性能提升,几乎无需修改代码。关键在于profile数据的质量和代表性。
-
-
编译器的常规优化:Go编译器默认会进行函数内联、死代码消除、常量传播等多种优化。通常无需手动干预,但了解
-gcflags中的-N(禁用优化)和-l(禁用内联)有时可用于特定调试场景(生产构建不应使用)。 -
Go运行时的自适应优化:GC的Pacer调速、goroutine调度器的动态调整等,都是运行时为保障性能而做的自适应工作。
-
利用最新的Go版本:Go团队在每个新版本中都会对编译器、运行时和标准库进行性能优化。简单地升级到最新的稳定版Go,往往就能免费获得一些性能红利。
通过综合运用代码层面的优化技巧、强大的性能剖析工具,以及充分利用Go编译器和运行时的自身优化能力,我们就能系统性地提升Go应用的性能表现,使其更高效、更稳定地服务于业务需求。
小结
这节课,我们学习了Go运行时追踪工具 go tool trace 的妙用,理解了它如何通过细粒度的事件追踪,帮助我们洞察goroutine调度、GC行为、系统调用以及用户自定义任务的执行细节。通过一个并发分形图渲染的实例,我们看到了Trace工具在分析并行度、并发交互和指导优化方面的强大能力。
最后,我们系统性地梳理了Go程序中常见的性能瓶颈类型及其具有Go特色的优化技巧。我们分别从CPU密集型(如算法优化、高效字符串/序列化/正则处理、并发分解、避免热点 interface{}、底层优化简介)、内存分配与GC相关(如泄漏诊断、对象复用 sync.Pool、预分配容量、GC参数调优)、并发同步相关(如细化锁粒度、高效Channel使用、Worker Pool、原子操作),以及I/O操作相关(如并发I/O、超时重试、连接池、批量处理、缓冲I/O)等多个维度,详细讨论了问题成因和优化策略。我们还探讨了如何利用Go编译器与运行时的优化机制,特别是Go 1.21+引入的Profile-Guided Optimization(PGO),以及关注最新Go版本带来的性能红利。
通过这两节课的学习,你不仅掌握了Go性能分析的核心工具和方法,更重要的是建立了一套科学的性能调优思维框架,并了解了Go语言环境下特有的优化技巧以及如何利用语言和工具的最新进展。这将使你在面对Go应用的性能挑战时,能够更有信心、更有章法地去定位瓶颈、实施优化,打造出真正高性能的Go服务。
思考题
你的一个Go Web服务在进行压力测试时,通过 pprof 的CPU Profile发现GC占用了较高的CPU百分比(例如,超过20-30%),同时Heap Profile的 -alloc_space 视图显示某个处理JSON请求的Handler内部有非常高的内存分配量,尽管 -inuse_space 视图看起来内存并没有明显泄漏。请你分析一下,这可能是什么原因导致的。你会考虑从哪些方面入手去优化这个问题?
提示:可以结合这两节课所讨论的内存分配优化技巧和JSON处理优化
欢迎在留言区分享你的思考和实践经验!我是Tony Bai,我们下节课见。
AI集成:如何让大模型赋能你的Go应用?
你好,我是Tony Bai。
在前面的Go工程实践模块中,我们已经深入学习了如何构建健壮的应用骨架、核心组件(如配置、日志),如何进行部署、升级、观测、故障诊断和性能调优。这些知识帮助我们打造出高质量的、面向传统业务场景的Go应用。然而,一个不可忽视的技术浪潮正席卷全球——那就是以大语言模型(LLM)为代表的人工智能。
许多Go开发者可能正站在AI时代的门槛,心中充满好奇但也可能有些许困惑:AI大模型究竟是什么?它为软件开发带来了怎样的新范式?Go语言在这个新的生态中扮演什么角色?最重要的是,我如何才能将这些强大的AI能力,快速、有效地集成到现有或未来的Go应用中呢?
如果你也有这些疑问,这节课正是为你量身打造的。同时,你可以将它作为你进入AI应用开发领域的快速入门指南,帮助你:
-
理解LLM的基本概念和它所带来的应用开发新范式。
-
掌握与LLM进行交互的核心准则。
-
熟悉当前行业内与LLM通信的API事实标准。
-
并最终学会如何使用Go语言(通过直接调用API和更推荐的官方SDK)与这些强大的AI模型进行基础对话。
本节课的内容将高度凝练,旨在为你“扫盲”和“上手”打下概念基础,为你后续可能更深入的AI应用开发(例如构建基于RAG的AI系统、AI Agent等)或学习专门的AI课程做好铺垫和衔接,力求在有限的篇幅内,让你快速把握Go与AI集成的核心要点。
理解AI大模型与AI原生应用新范式
在我们开始用Go代码与AI交互之前,首先需要建立对当前这波AI浪潮核心驱动力——大语言模型——以及它所催生的新型应用形态有一个清晰的认知。
AI浪潮已至:Gopher的机遇与挑战
人工智能,特别是自2022年底ChatGPT惊艳亮相以来,以大语言模型为代表的生成式AI(Generative AI)技术,正以前所未有的速度和深度改变着各行各业,软件开发领域首当其冲。
大语言模型(Large Language Models,LLMs)是当前这波 AI 浪潮中最耀眼的明星,也是驱动 AI 原生应用实现其智能特性的核心引擎。简单来说,语言模型(Language Model,LM)是一种旨在理解、处理和生成人类语言的人工智能系统。它们通过从海量文本数据中学习语言的模式、结构和上下文关系,从而能够产生连贯且与上下文相关的文本,广泛应用于机器翻译、文本摘要、聊天机器人、内容创作、代码编写等诸多领域。
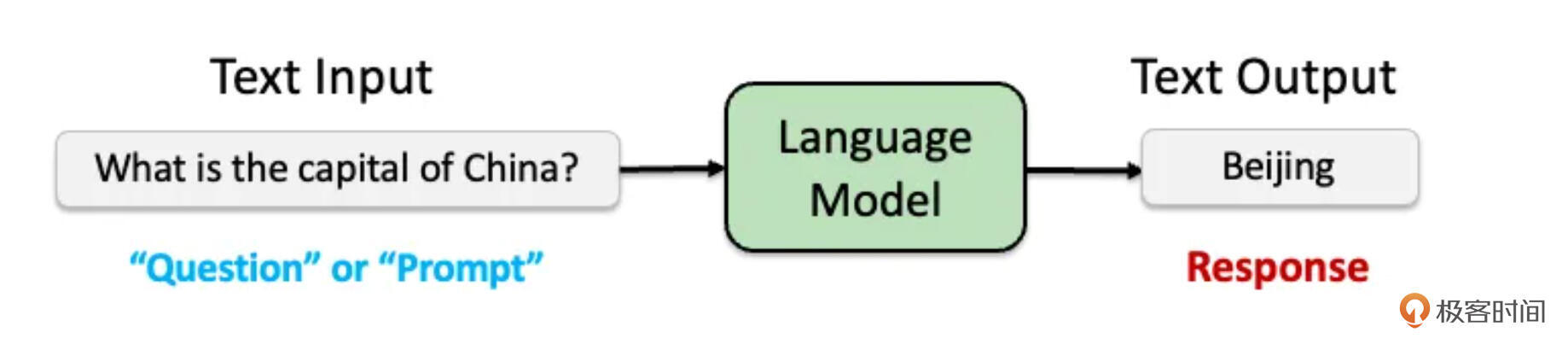
而大语言模型则是语言模型的一个重要子集,它们与传统 LM 的主要区别在于 其模型架构的革新(主要基于 Transformer 架构)和训练数据的海量性,以及由此带来的模型参数规模的急剧膨胀。LLM 通常拥有数十亿甚至数万亿级别的参数(例如,OpenAI 的 GPT-3 就拥有 1750 亿参数)。这种巨大的规模赋予了 LLM 前所未有的语言理解和生成能力,使其在广泛的任务中展现出卓越的性能,甚至催生出许多令人惊叹的“涌现能力”(Emergent Abilities)。
这几年来大语言模型飞速发展,下图是大语言模型发展历程的简单示意图:
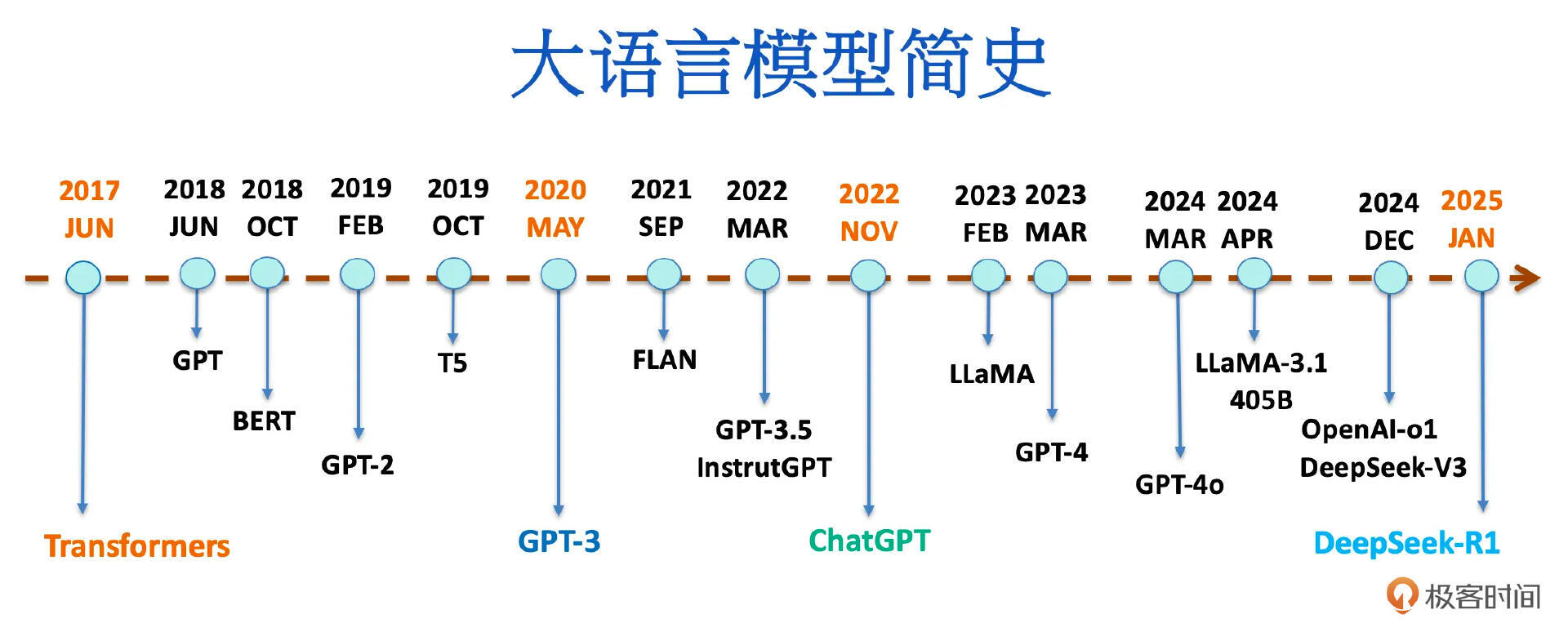
这波以LLM为代表的AI浪潮既带来了巨大的机遇,也对我们开发者(包括Gopher们)提出了新的挑战。
LLM的出现,使得机器具备了前所未有的自然语言理解、生成、推理和多模态处理能力。这为我们创造全新、更智能、更个性化的应用体验打开了大门。我们可以构建智能客服、代码助手、内容创作工具、自动化报告生成、复杂数据分析与洞察等以往难以想象的应用。
那么,如何理解这些AI模型的能力边界?如何有效地引导和控制它们的行为?如何将它们与我们现有的软件系统和业务流程相结合?这些都是我们需要学习和适应的新课题。
虽然Python凭借其丰富的科学计算库和AI框架生态,在AI算法研究和模型训练领域占据主导地位,但 Go语言在AI应用的工程化和落地层面,拥有其独特的优势。
-
高性能与高并发:Go的并发模型(goroutine和channel)和高效的执行性能,使其非常适合构建需要处理大量并发请求、进行实时数据处理的AI应用后端服务、API网关或中间件。
-
强大的网络库与工具链:Go在网络编程方面的优势,以及其简洁的部署方式(静态编译的单个二进制文件),使其非常适合构建与LLM API进行交互,以及部署在云原生环境中的AI应用。
-
快速增长的生态:虽然起步相对较晚,但Go在AI领域的生态系统(如SDK、框架、工具库)正在快速发展。
因此,对于我们Gopher而言,利用Go语言的工程优势,将强大的LLM能力集成到我们的应用中,赋能现有业务或开创新的智能服务,是一个非常值得抓住的机遇。
LLM即“操作系统”:理解AI应用开发的新范式
要理解如何开发基于LLM的AI原生应用,一个非常有洞察力的视角是将 大语言模型视为一种新型的“操作系统”(我们称之为“LLM OS”)。这个概念由AI领域大佬Andrej Karpathy提出,旨在帮助我们建立一个理解LLM及其应用开发生态的心智模型。
接下来,我们就自上而下理解这个新范式,先来看看什么是AI原生应用。
什么是AI原生应用?
我们先通过下面这张图来直观感受一下日常开发和使用的“经典应用”(Classic App)与AI原生应用的区别:
我们看到,与依赖固定、预定义逻辑的传统/经典应用不同,AI原生应用(AI-Native App)从底层设计上就将AI(特别是LLM)作为其核心驱动力和关键组件。它的核心逻辑不再是完全由开发者硬编码的规则,而是更多地依赖于AI模型的动态理解、推理和生成能力,能够根据上下文进行适应和响应。
LLM:“智能内核”
在这个新范式中,LLM扮演着如同传统操作系统内核一样的角色。它接收来自应用程序的“指令”(即我们稍后会详细讨论的Prompt),处理这些指令(利用其庞大的知识库和推理能力),并返回结果。
-
CPU类比:LLM本身(如Claude 3、Gemini 2.5 pro、DeepSeek等)可以看作是这个“LLM OS”的中央处理器(CPU),负责核心的“智能计算”。
-
内存类比:LLM的“上下文窗口”(Context Window)则像操作系统的内存(RAM)。它决定了LLM在一次交互中能够“记住”和处理多少信息(以Token数量衡量)。超出上下文窗口的信息,LLM通常会“忘记”。
-
存储类比:外部知识库,如向量数据库或传统文件系统,可以看作是LLM OS的“硬盘”,用于存储LLM自身训练数据之外的、持久化的私有知识。通过检索增强生成(RAG)等技术,LLM可以在需要时从这些“硬盘”中加载信息到其“内存”(上下文窗口)中。
-
I/O与系统调用类比:LLM通过工具调用(Function Calling)机制(或ModelContextProtocol、MCP协议)与外部世界(如API、数据库、代码解释器)进行交互,这非常类似于传统操作系统通过系统调用(Syscall)来访问硬件或执行特权操作。
理解 “LLM OS” 这个范式,能帮助我们更好地组织关于AI应用开发的知识,并认识到构建AI应用不仅仅是调用一个API那么简单,它更像是在围绕一个新的“计算平台”进行系统设计。
初识LLM的“说明书”:模型规格的重要性
每个LLM OS的具体“实例”(即某个特定的模型,如 gpt-4o 或 deepseek-chat)都有其自身的“说明书”——即 模型规格(Model Spec)。 OpenAI等公司提出的Model Spec 旨在明确模型应遵循的目标、规则和默认行为,力求在模型的有用性、诚实性和无害性之间取得平衡,并提升其可控性。
对于开发者而言,理解目标模型的Model Spec(或其类似文档)至关重要,因为它通常会包含以下关键信息:
-
模型的能力边界:它擅长什么任务?不擅长什么?
-
上下文窗口大小:这是设计对话历史管理和RAG策略的关键参数。
-
Tokenization方式:了解文本是如何被切分为Token的,有助于估算成本和优化Prompt。
-
训练数据截止日期:了解模型的知识库“有多新”。
-
行为准则与安全限制:模型被期望如何回应,以及有哪些内容生成限制。
-
API参数的特殊含义或支持情况。
在开始与任何一个LLM进行实际交互之前,花时间阅读其“说明书”,是确保我们能有效、安全地使用它的第一步。
了解了这些基础概念后,我们接下来深入探讨与LLM进行交互的核心准则。
与LLM交互的核心准则及API事实标准
掌握了LLM作为一种新型“操作系统”的基本概念后,我们需要学习如何与其进行有效的“沟通”。这种沟通遵循一套特定的规则和结构。
对话与消息:交互的基础
与LLM OS进行结构化交互的核心单元是对话(Conversation)。从技术角度看, 一个对话就是由一个有序的消息(Message)列表构成的序列。这个 messages 列表是我们与LLM进行一次完整沟通的“脚本”。
列表中的每一个消息对象通常包含两个核心字段:
-
role(角色):一个字符串,定义消息的发送者或类型。 -
content(内容):消息的具体承载,通常是文本字符串,对于多模态模型也可以是图像等数据。
常见的角色包括:
-
system(系统消息):用于设定LLM的角色、行为准则、输出格式等高级指令。它通常作为messages列表的第一条,为整个对话定下基调(在OpenAI的最新规范中,更倾向于使用developer角色来代表应用开发者设定的指令,但system因其历史悠久和广泛兼容性,在许多场景下仍被接受和使用)。 -
user(用户消息):代表最终用户提出的问题或指令。 -
assistant(助手消息):代表LLM(即“助手”)先前返回的回答。
正确地构造和维护这个包含不同角色消息的有序列表,是实现有效对话的关键。
理解LLM API的“无状态性”
一个对于初学者可能反直觉但至关重要的特性是, LLM API的交互在底层通常是无状态的(Stateless)。
这意味着,当你通过API向LLM发送一个 messages 列表并获得回应后,LLM本身 不会自动“记住”这次交互的任何内容 以供紧随其后的下一次独立API调用使用。每一次API请求,对于LLM来说,都是一次相对独立且全新的计算任务。它处理你当前提供的 messages “脚本”,生成回应,然后就“忘记”了这个脚本,等待处理下一个。
因此,实现连贯的多轮对话的责任落在了客户端(即我们的Go应用)身上。 我们的应用必须:
-
存储整个对话过程中所有角色的所有消息。
-
当用户发起新一轮交互时,将新的
user消息按严格的时间顺序追加到已存储的历史消息之后。 -
最终,将这个完整且有序的对话历史(即更新后的
messages列表)作为下一次API请求的输入。
正是这种应用层面的状态管理,才使得“无状态”的LLM API能够支持看起来“有记忆”的流畅多轮对话。
OpenAI兼容API:Chat Completions API的事实标准
幸运的是,在如何与LLM进行对话式交互方面,业界已经形成了一个事实上的API标准,它源自OpenAI的Chat Completions API(通常指其 POST /v1/chat/completions 端点)。
这个API规范因其设计的简洁性、灵活性和强大的功能(支持多轮对话、流式响应、函数调用/工具使用、JSON模式输出等),已被众多主流的商业LLM提供商(如Anthropic Claude、Google Gemini和DeepSeek等)和开源模型服务框架(如Ollama)所广泛采纳和兼容。
这意味着,我们一旦掌握了如何调用这套OpenAI兼容API,就拥有了一把能够与绝大多数LLM进行交互的“万能钥匙”。
Chat Completions API的核心请求结构通常包含:
-
model(string)指定要使用的LLM模型ID。 -
messages(array of message objects):包含完整对话历史的消息列表,每个消息有role和content。 -
可选参数如
temperature(控制随机性)、max_tokens(限制输出长度)、stream(是否启用流式响应)等。
身份认证通常通过以下方式进行:
-
API密钥(API Key):一个由服务商分配的字符串,通常通过HTTP请求的
Authorization: Bearer <YOUR_API_KEY>头部传递。 -
API基础URL(API Base URL):指定API服务的网络地址。例如,OpenAI官方是
https://api.openai.com/v1,DeepSeek是https://api.deepseek.com(或.../v1),本地Ollama通常是http://localhost:11434/v1。
这两个信息通常通过环境变量(如 OPENAI_API_KEY、 OPENAI_API_BASE)或在代码中配置给SDK客户端。
用Go发出第一个“Hello, AI”:裸调API实战
下面让我们亲自动手,使用Go的标准库 net/http 和 encoding/json 来向一个OpenAI兼容的API服务(我们以DeepSeek为例,它提供免费额度且与OpenAI API高度兼容)发送一个简单的“Hello, AI”请求。
- 准备:
-
注册DeepSeek平台( https://platform.deepseek.com/)并获取API Key。
-
设置环境变量:
export OPENAI_API_KEY="<YOUR_DEEPSEEK_API_KEY>"。
- 示例Go代码:
// ch30/hello_ai/hello_ai.go
package main
import (
"bytes"
"context"
"encoding/json"
"fmt"
"io"
"log"
"net/http"
"os"
"time"
)
// ChatMessage 定义了对话中单条消息的结构
type ChatMessage struct {
Role string `json:"role"` // 角色:system, user, 或 assistant
Content string `json:"content"` // 消息内容
}
// ChatCompletionRequest 定义了发送给聊天补全API的请求体结构
type ChatCompletionRequest struct {
Model string `json:"model"` // 使用的模型ID
Messages []ChatMessage `json:"messages"` // 对话消息列表
Stream bool `json:"stream,omitempty"` // 是否流式响应,omitempty表示如果为false则不序列化此字段
// 可以添加其他参数如 Temperature, MaxTokens 等
}
// ResponseChoice 定义了API响应中单个选择项的结构
type ResponseChoice struct {
Index int `json:"index"`
Message ChatMessage `json:"message"` // 助手返回的消息
FinishReason string `json:"finish_reason"` // 结束原因,如 "stop", "length"
}
// ChatCompletionResponse 定义了聊天补全API响应体的主结构
type ChatCompletionResponse struct {
ID string `json:"id"` // 响应ID
Object string `json:"object"` // 对象类型,如 "chat.completion"
Created int64 `json:"created"` // 创建时间戳
Model string `json:"model"` // 使用的模型ID
Choices []ResponseChoice `json:"choices"` // 包含一个或多个回复选项的列表
// Usage UsageInfo `json:"usage"` // Token使用情况 (在非流式时通常有)
}
// UsageInfo 定义了Token使用统计的结构 (为简化,此处可以先不详细定义)
// type UsageInfo struct { ... }
func main() {
apiKey := os.Getenv("OPENAI_API_KEY")
if apiKey == "" {
log.Fatal("错误:环境变量 OPENAI_API_KEY 未设置。")
}
// DeepSeek API端点 (OpenAI兼容)
apiURL := "https://api.deepseek.com/v1/chat/completions" // 使用与OpenAI SDK默认更接近的路径
modelID := "deepseek-chat" // DeepSeek提供的聊天模型
// 构造请求体
requestPayload := ChatCompletionRequest{
Model: modelID,
Messages: []ChatMessage{
{Role: "system", Content: "你是一个乐于助人的AI助手。"},
{Role: "user", Content: "你好AI,请问Go语言是什么时候发布的?"},
},
Stream: false, // 我们先尝试非流式
}
requestBodyBytes, err := json.Marshal(requestPayload)
if err != nil {
log.Fatalf("序列化请求体失败: %v", err)
}
// 创建HTTP请求
// 使用 context.WithTimeout 创建一个带超时的上下文
ctx, cancel := context.WithTimeout(context.Background(), 30*time.Second)
defer cancel() // 确保在函数结束时取消上下文,释放资源
req, err := http.NewRequestWithContext(ctx, "POST", apiURL, bytes.NewBuffer(requestBodyBytes))
if err != nil {
log.Fatalf("创建HTTP请求失败: %v", err)
}
req.Header.Set("Content-Type", "application/json")
req.Header.Set("Authorization", "Bearer "+apiKey)
// 发送请求
fmt.Println("正在发送请求到AI模型...")
client := &http.Client{} // 可以配置client的超时等参数
resp, err := client.Do(req)
if err != nil {
// 检查上下文是否已超时或被取消
if errors.Is(err, context.DeadlineExceeded) {
log.Fatalf("请求超时: %v", err)
}
log.Fatalf("发送HTTP请求失败: %v", err)
}
defer resp.Body.Close()
// 读取并处理响应
responseBodyBytes, err := io.ReadAll(resp.Body)
if err != nil {
log.Fatalf("读取响应体失败: %v", err)
}
if resp.StatusCode != http.StatusOK {
log.Fatalf("API请求失败,状态码: %d, 响应: %s", resp.StatusCode, string(responseBodyBytes))
}
var chatResponse ChatCompletionResponse
if err := json.Unmarshal(responseBodyBytes, &chatResponse); err != nil {
log.Fatalf("反序列化响应JSON失败: %v\n原始响应: %s", err, string(responseBodyBytes))
}
// 打印AI的回答
if len(chatResponse.Choices) > 0 {
assistantMessage := chatResponse.Choices[0].Message
fmt.Printf("AI助手的回答 (模型: %s):\n%s\n", chatResponse.Model, assistantMessage.Content)
fmt.Printf("(结束原因: %s)\n", chatResponse.Choices[0].FinishReason)
} else {
fmt.Println("AI未返回任何有效的回答选项。")
}
}
运行代码(确保已设置 OPENAI_API_KEY,并且你的网络可以访问 api.deepseek.com),你将会看到类似如下的输出(具体回答内容可能因模型版本和时间而异):
// 在ch30/hello_ai目录下
$go run hello_ai.go
正在发送请求到AI模型...
AI助手的回答 (模型: deepseek-chat):
Go语言(又称Golang)由Google开发,并于**2009年11月10日**正式对外发布。它的初始版本(Go 1.0)则在**2012年3月28日**推出,标志着语言的核心特性与API进入稳定阶段。以下是关键时间点:
1. **2007年**:Robert Griesemer、Rob Pike和Ken Thompson开始设计Go语言。
2. **2009年11月10日**:开源发布,并公开了编译器、工具链和早期标准库。
3. **2012年3月28日**:发布**Go 1.0**,提供长期兼容性承诺,成为生产环境可用版本。
4. **后续发展**:Go团队保持每半年发布一次增量更新(如Go 1.1、1.2等),逐步引入改进(如泛型在**Go 1.18**中加入)。
Go的简洁性、并发支持(goroutine)和高效编译使其在云计算、微服务等领域广受欢迎。如需更详细版本历史,可参考[Go官方博客](https://blog.golang.org)。
(结束原因: stop)
恭喜!你已经成功用Go语言通过裸调API的方式,与一个强大的LLM进行了第一次对话。这个例子覆盖了构造请求、认证、发送、接收和解析响应的核心流程。
在上面的例子中,我们设置了 Stream: false,所以是等待模型完全生成回答后一次性接收。如果将 Stream: true,API会以Server-Sent Events(SSE)协议逐步返回数据块。客户端需要处理这种事件流,从中提取并拼接 delta.content 片段来实时显示。这对于提升聊天等交互式应用的体验至关重要,但处理逻辑比非流式要复杂一些。
掌握了API的基本交互方式后,我们自然会思考如何更有效地“指导”LLM给出我们期望的输出,以及如何让我们的Go代码更简洁优雅。
Prompt工程与Go SDK:提升交互效率与优雅性
仅仅知道如何通过API发送和接收数据是不够的。要真正发挥LLM的威力,我们需要掌握两项关键技能:一是如何精心设计我们发送给LLM的“指令”(即Prompt工程),二是如何利用Go SDK来简化与API的交互,使代码更优雅、更健壮。
Prompt工程入门:与LLM高效沟通的“指令艺术”
Prompt是我们提供给LLM的输入文本,它既是指令(Instruction),也是上下文(Context)。一个设计良好的Prompt能够清晰地传达我们的意图,引导LLM准确、高质量地完成任务。反之,模糊或设计不当的Prompt则可能导致LLM给出无用甚至错误的输出。 Prompt工程(Prompt Engineering)就是设计、编写和优化Prompt的艺术与科学。
正如与人类沟通时,表达的清晰度和准确性直接影响沟通效果一样,与 LLM 进行“沟通”(或者更准确地说,进行“引导”)时, Prompt 的质量也直接决定了 LLM 输出结果的质量、相关性和可靠性。 一个含糊不清的 Prompt 往往导致 LLM 给出无用、错误甚至荒谬的答案,而一个精心设计的 Prompt 则能引导 LLM 发挥其惊人的潜力。
设计高质量、高效率的 Prompt 是一项需要经验积累和细致思考的工作,并且通常需要一些技巧或者说遵循一些原则,掌握这些技巧或原则,是 Gopher 们开启高效 Prompt Engineering 之旅的第一步。
下面我就介绍几种简单有效的Prompt技巧。
-
明确角色扮演(Role Playing):在
system或user消息中明确告诉LLM它应该扮演什么角色。例如:“你是一个经验丰富的Go语言技术文档审阅者,请检查以下文本的准确性和流畅性。” -
清晰的指令与期望输出格式:直接、具体地说明任务要求和期望的输出格式。例如:“请将以下英文段落翻译成简体中文,并以一个JSON对象的格式返回,包含
original_text和translated_text两个字段。” -
提供示例(Few-shot Learning):在Prompt中给出几个输入/输出的例子,帮助模型理解任务模式和期望风格。
指令:请将以下英文客户服务邮件翻译成简体中文,并保持礼貌和专业的语气。请参考以下示例的翻译风格和格式。
--- 示例 1 ---
英文邮件:
Subject: Urgent: Problem with recent software update
Body:
Hi team,
Our production system started experiencing frequent crashes after a_recent_update_v2.1. Could you please look into this ASAP? This is business critical.
Thanks,
Jane Doe
中文翻译:
主题:紧急:关于近期软件更新的问题
正文:
团队你们好,
我们的生产系统在最近的v2.1版本更新后开始频繁崩溃。能否请你们尽快调查此事?这对我们的业务至关重要。
谢谢,
简·杜
--- 示例 2 ---
英文邮件:
Subject: Question about API rate limits
Body:
Hello,
I'd like to understand more about the rate limits for your public API. Can you provide some documentation or details?
Regards,
John Smith
中文翻译:
主题:关于API速率限制的咨询
正文:
你好,
我想进一步了解贵公司公共API的速率限制情况。能否提供相关的文档或详细信息?
此致,
约翰·史密斯
--- 实际任务 ---
英文邮件:
Dear Valued Customer,
We received your inquiry regarding the shipment delay of order #12345. We sincerely apologize for any inconvenience this may have caused. Our logistics team is currently investigating the issue and we expect to have an update for you within 24 hours.
Thank you for your patience.
Sincerely,
Support Team
中文翻译:
- 思维链(Chain-of-Thought,CoT)提示:对于需要多步推理的任务(如数学应用题),引导模型先输出其思考步骤,再给出最终答案。通常在问题后加上一句“Let’s think step by step.”或类似的引导语。这能显著提高复杂推理的准确率。
下面是一个使用CoT提示词与大模型交互的示例:
问题:自助餐厅有 23 个苹果。他们用了 20 个来做午餐,然后又买了 6 个。他们现在有多少个苹果?
请一步一步思考,然后给出最终答案。
思考过程:
首先,我们知道餐厅开始时有 23 个苹果。
然后,他们用了 20 个苹果做午餐。所以剩下的苹果数量是 23 - 20 = 3 个。
之后,他们又买了 6 个苹果。所以现在的苹果总数是 3 + 6 = 9 个。
因此,他们现在有 9 个苹果。
最终答案:9
Prompt工程是一门实践性很强的技艺,需要通过不断的实验和迭代来优化。本节课仅作最基础的入门介绍,更深入的技巧通常在专门的AI课程中探讨。你也可以订阅极客时间上有关Prompt工程的专栏或视频课程继续深入学习。
为何需要SDK?告别繁琐的HTTP请求
回顾我们前面用Go标准库裸调API的例子,虽然它能工作,但也暴露了几个痛点。
-
代码冗长:需要手动构造JSON请求体、设置HTTP头部、发送请求、检查状态码、读取响应体、反序列化JSON等,样板代码很多。
-
易错:JSON的字段名、数据类型、HTTP头部的拼写等都容易出错。
-
缺乏类型安全:在构造请求和解析响应时,如果Go结构体与API的JSON结构不完全匹配,可能导致运行时错误或数据丢失。
-
高级功能处理复杂:例如,处理流式响应(SSE)、实现错误重试、管理API速率限制等,都需要编写大量额外的逻辑。
幸运的是,SDK(Software Development Kit,软件开发工具包)的出现正是为了解决这些痛点。大模型SDK可以提供如下价值:
-
封装底层细节:SDK将所有底层的HTTP交互、认证、JSON序列化/反序列化等都封装好了。
-
提供类型安全的接口:提供与API对应的Go结构体和方法,利用Go的类型系统在编译期就能发现很多错误。
-
简化API调用:开发者只需与SDK提供的更高级、更符合Go语言习惯的接口交互。
-
内置常用功能:通常会内置错误处理、重试机制、超时控制,并简化对流式响应等高级功能的使用。
-
易于维护:当API更新时,SDK维护者(尤其是官方)会负责更新SDK,开发者通常只需升级SDK版本并做少量适配即可。
对于任何严肃的AI应用开发,使用一个好的SDK几乎是必然选择。那么我们Gopher都有哪些高质量的大模型应用开发Go SDK可以选择呢?接下来,我们就来看看Go LLM SDK的生态。
Go LLM SDK生态概览
Go社区在LLM SDK方面发展迅速,无论是主流大模型厂商,还是社区第三方,都提供了高质量的Go SDK供我们使用。
- 主流大模型官方SDK:
-
github.com/openai/openai-go:由OpenAI官方维护,支持其所有API,包括Chat Completions、Embeddings、Images、Audio等。 这是我们本节课后续示例的重点,也是与OpenAI兼容API交互的首选。 -
github.com/anthropics/anthropic-sdk-go:Anthropic官方SDK,用于Claude系列模型。 -
https://github.com/googleapis/go-genai:Google官方SDK,用于Gemini系列模型。
-
- 通用/多模型SDK与框架内嵌SDK:
-
社区也有一些尝试封装多种LLM API的通用SDK或工具库。
-
更常见的是,像LangChainGo(
github.com/tmc/langchaingo)或Eino这样的Go LLM应用框架,它们内部会包含与多种LLM进行交互的SDK层或适配器。
-
最后,建议你优先选择官方SDK,它们通常能最快支持最新功能且维护有保障。对于OpenAI兼容API, openai/openai-go 是核心。
实战:使用OpenAI Go SDK与模型交互
现在,我们将使用官方的 github.com/openai/openai-go SDK来编写一个复杂一些的示例,演示如何使用SDK进行简单的非流式的多轮对话。这个示例程序会模拟用户与一个“Go语言编程助手”进行连续对话,用户可以在命令行输入问题,程序会将问题和模型的回答都记录下来,并在下次提问时一起发送。
// ch30/openai-go-sdk/multi-turn-no-stream/main.go
package main
import (
"bufio"
"context"
"errors"
"fmt"
"log"
"os"
"strings"
openai "github.com/openai/openai-go"
"github.com/openai/openai-go/option"
)
func main() {
// 1. 环境准备
apiKey := os.Getenv("OPENAI_API_KEY")
if apiKey == "" {
log.Fatal("错误:未设置 OPENAI_API_KEY 环境变量。")
}
baseURL := os.Getenv("OPENAI_API_BASE")
if baseURL == "" {
log.Fatal("Error: OPENAI_API_BASE environment variable not set.")
}
// 2. 客户端初始化 (同上)
client := openai.NewClient(option.WithAPIKey(apiKey),
option.WithBaseURL(baseURL))
ctx := context.Background()
// 3. 初始化对话历史
// 创建一个 openai.ChatCompletionMessageParamUnion 类型的切片来存储历史。
// 通常以一个 openai.SystemMessage 开始,设定助手的角色或行为。
messages := []openai.ChatCompletionMessageParamUnion{
openai.SystemMessage("你是一个乐于助人的 Go 语言编程助手。"),
}
fmt.Println("开始与 Go 助手对话 (输入 'quit' 退出):")
// 使用 bufio.NewReader 读取用户输入。
reader := bufio.NewReader(os.Stdin)
// 4. 进入对话循环
for {
fmt.Print("You: ")
userInput, _ := reader.ReadString('\n')
userInput = strings.TrimSpace(userInput)
// 输入 "quit" 退出循环。
if strings.ToLower(userInput) == "quit" {
fmt.Println("再见!")
break
}
// 5. 将用户输入添加到历史记录
// 使用 openai.UserMessage 将用户输入包装并追加到 messages 切片。
messages = append(messages, openai.UserMessage(userInput))
// 6. 构建包含完整历史的请求
params := openai.ChatCompletionNewParams{
Model: "deepseek-chat",
// 关键:将包含所有历史的 messages 切片传递给 Messages 字段。
Messages: messages,
}
fmt.Println("助手正在思考...")
// 7. 发起 API 请求 (非流式)
completion, err := client.Chat.Completions.New(ctx, params)
// 8. 处理 API 错误
if err != nil {
var apiErr *openai.Error
if errors.As(err, &apiErr) {
fmt.Printf("API 错误: Status=%d Type=%s Message=%s\n", apiErr.StatusCode, apiErr.Type, apiErr.Message)
} else {
fmt.Printf("API 错误: %v\n", err)
}
// 可选:如果调用失败,从历史记录中移除刚才添加的用户消息,避免错误累积。
messages = messages[:len(messages)-1]
continue // 继续下一次循环,等待用户再次输入。
}
// 9. 处理并添加助手响应到历史记录
if len(completion.Choices) > 0 {
// 获取助手的响应消息结构体 (openai.ChatCompletionMessage)。
assistantResponseMsg := completion.Choices[0].Message
fmt.Printf("Assistant: %s\n", assistantResponseMsg.Content)
// 关键步骤:将助手的响应消息转换回参数类型,并添加到历史记录中。
// 使用 assistantResponseMsg.ToParam() 方法!
messages = append(messages, assistantResponseMsg.ToParam())
} else {
fmt.Println("Assistant: 我暂时没有回应。")
// 可选:如果助手没有回应,也移除最后的用户消息。
messages = messages[:len(messages)-1]
}
// 10. 可选:历史记录截断逻辑
// 在实际应用中,需要检查 messages 的长度(或累计 token 数)
// 并根据需要移除旧的消息,以防止超出模型的上下文窗口限制。
// const maxHistoryItems = 10 // 例如保留最近 10 条(含系统消息)
// if len(messages) > maxHistoryItems {
// // 保留第一条(系统消息)和最后 maxHistoryItems-1 条
// messages = append(messages[:1], messages[len(messages)-(maxHistoryItems-1):]...)
// }
}
}
多轮非流式对话的代码逻辑在于维护对话的历史记录,通过创建一个[]openai.ChatCompletionMessageParamUnion类型的切片messages来存储系统消息、用户输入和助手回复。这与单轮非流式对话的逻辑不同,后者只处理一次用户请求。在对话循环中,程序不断获取用户输入并更新历史记录,确保每次请求都包含完整的对话内容,而非单轮对话中仅发送单一用户消息。此循环设计允许模拟持续对话,增强用户交互的连贯性。
下面是运行这个示例的一次输出结果(由于篇幅过长,省略了部分输出内容):
// 在ch30/openai-sdk/multi-turn-no-stream目录下
$go build
$export OPENAI_API_KEY=<your_api_key>
$export OPENAI_API_BASE=https://api.deepseek.com/v1
$./demo
开始与 Go 助手对话 (输入 'quit' 退出):
You: Write an example of go slice
助手正在思考...
Assistant: # Go Slice Example
Here's a comprehensive example demonstrating slices in Go:
package main
import "fmt"
func main() {
// 1. Creating slices
// Using a slice literal
fruits := []string{"Apple", "Banana", "Cherry"}
fmt.Println("Fruits:", fruits) // Output: Fruits: [Apple Banana Cherry]
// Creating from an array
arr := [5]int{10, 20, 30, 40, 50}
numbers := arr[1:4] // slice from index 1 to 3 (4 is exclusive)
fmt.Println("Numbers:", numbers) // Output: Numbers: [20 30 40]
// Using make() - length 3, capacity 5
names := make([]string, 3, 5)
names[0], names[1], names[2] = "Alice", "Bob", "Charlie"
fmt.Println("Names:", names) // Output: Names: [Alice Bob Charlie]
... ... //此处省略若干输出内容
// 7. Multi-dimensional slice
matrix := [][]int{
{1, 2, 3},
{4, 5, 6},
{7, 8, 9},
}
fmt.Println("Matrix:", matrix)
}
Key points demonstrated:
1. Different ways to create slices (literal, from array, with make)
2. Basic operations like append, length, capacity
3. Slicing operations
4. Copying slices
5. Modifying slices and their underlying arrays
6. Iteration
7. Multi-dimensional slices
Slices are more flexible than arrays in Go because they can grow and shrink as needed. They are reference types that point to an underlying array.
You: add a demo of slice auto growing to your example
助手正在思考...
Assistant: # Go Slice Example with Auto-Growth Demonstration
Here's an enhanced version of the slice example that includes a demonstration of slice auto-growth:
package main
import "fmt"
func main() {
// Initial slice with small capacity
nums := make([]int, 0, 2) // length 0, capacity 2
fmt.Printf("Initial - len: %d, cap: %d, %v\n", len(nums), cap(nums), nums)
// Append elements to demonstrate auto-growth
nums = append(nums, 1)
fmt.Printf("After append 1 - len: %d, cap: %d, %v\n", len(nums), cap(nums), nums)
... ... //此处省略若干输出内容
}
### Output Explanation:
When you run this program, you'll see output like:
Initial - len: 0, cap: 2, []
After append 1 - len: 1, cap: 2, [1]
After append 2 - len: 2, cap: 2, [1 2]
After append 3 (exceeds capacity) - len: 3, cap: 4, [1 2 3]
After append 4 - len: 4, cap: 4
After append 5 - len: 5, cap: 8
After append 6 - len: 6, cap: 8
After append 7 - len: 7, cap: 8
After append 8 - len: 8, cap: 8
After append 9 - len: 9, cap: 16
After append 10 - len: 10, cap: 16
Slice growth pattern:
Go typically doubles the capacity when a slice grows beyond its current capacity
until it reaches 1024 elements, after which it grows by 25% each time
Practical growth example:
Capacity changed from 0 to 1 at len=1
Capacity changed from 1 to 2 at len=2
Capacity changed from 2 to 4 at len=3
Capacity changed from 4 to 8 at len=5
Capacity changed from 8 to 16 at len=9
### Key Points:
1. **Auto-Growth Behavior**: When you append to a slice that's at capacity, Go automatically:
- Creates a new underlying array with larger capacity
- Copies all existing elements to the new array
- Returns a new slice with the expanded capacity
2. **Growth Algorithm**:
- For small slices (<1024 elements), capacity doubles each time
- For larger slices, it grows by 25% each time
3. **Performance Consideration**:
- Frequent resizing can impact performance
- If you know the approximate size needed, it's better to initialize with `make([]T, length, capacity)`
You: quit
再见!
这个示例清晰地展示了如何使用 openai/openai-go SDK来管理多轮对话的上下文,并通过简单的用户输入循环实现了基本的聊天交互。通过示例,我们可以看到SDK极大地简化了与API的通信过程。
通过这节课对 openai/openai-go 的实战演练,我们已经掌握了使用Go SDK与LLM进行对话的核心技能。对于Anthropic Claude或Google Gemini等其他主流模型,虽然它们的官方Go SDK在API细节和设计哲学上可能有所不同,但其核心的交互理念——构造请求、发送、处理响应——以及SDK所带来的便利性是相通的。这里鼓励你在需要时,查阅对应模型的官方Go SDK文档进行学习和使用。
掌握了如何通过SDK与LLM进行基础通信后,我们已经具备了将AI能力集成到Go应用中的第一块重要拼图。
展望Go在更高级AI应用中的角色
到目前为止,我们主要聚焦于如何通过Go语言与LLM进行基础的、对话式的API交互。这对于构建许多AI增强功能(如智能问答、文本摘要、简单内容生成)来说已经足够。然而,LLM的真正潜力远不止于此。当我们将LLM与外部知识、外部工具以及更复杂的控制流结合起来时,就能构建出更强大、更自主的AI应用。
虽然深入构建这些高级AI应用超出了本节课(作为Go进阶课中的AI集成引导)的范围,但了解它们的概念,以及Go语言在其中可能扮演的角色,对于我们Gopher把握未来的技术方向非常重要。
这里主要说一下检索增强生成(RAG)与AI Agent两种高级AI应用方向,以及Go在支撑整个AI生态系统的基础设施和工具链方面的结合点。
RAG:让LLM拥有“私有知识库”
检索增强生成(RAG,Retrieval Augmented Generation)是一种技术,通过从外部知识源(如公司的内部文档、产品手册和最新的行业报告等,通常存储在向量数据库中)检索相关信息,并将这些信息作为上下文提供给大语言模型,从而增强其生成回答的相关性、准确性和时效性。这种方法有效地解决了LLM在训练数据截止、特定领域知识不足以及容易产生“幻觉”(即编造事实)等问题。
在构建RAG流程中,Go语言可以发挥重要作用。
首先,在文档处理与嵌入方面,Go可以编写高效的工具,解析原始文档(如PDF、Markdown、HTML),并对其进行分块(chunking),随后调用嵌入模型(如OpenAI的Embeddings API)将文本块转换为向量。
其次,Go还提供了与主流向量数据库(如Pinecone、Weaviate、Milvus和Qdrant)的客户端库,可以用来存储和高效检索与用户查询最相关的向量化文档片段。
最后,Go应用的后端可以负责整个RAG流程的编排,包括接收用户查询、将查询向量化、从向量数据库中检索相关上下文、构建包含用户查询和检索到的上下文的提示(Prompt)、调用LLM API或使用SDK进行生成,以及处理并返回最终结果。Go的并发能力在这一过程中得到了良好的发挥,确保了高效的检索与生成。
除了让LLM“博闻强识”,AI领域的另一个热门探索方向是赋予LLM更强的自主行动能力,这就是我们要讨论的AI Agent。
AI Agent:构建能够自主思考和行动的智能体
AI Agent是当前人工智能领域一个非常令人兴奋的研究和应用方向,它不再仅仅满足于让LLM像一个问答机器人或文本生成器那样被动地响应用户输入,而是试图构建一种更高级的智能实体。
这种智能体能够基于大型语言模型强大的自然语言理解、知识推理和一定程度的逻辑规划能力,去 自主地设定目标、制定计划(Planning)、选择并使用外部工具(Tool Using)来执行任务,并能根据执行结果和环境反馈进行自我评估、学习和调整(Learning/Adaptation),最终以一种更主动、更智能的方式完成复杂的、多步骤的、需要与真实世界或外部系统动态交互的任务。
你可以将一个AI Agent想象成一个拥有“大脑”(通常是核心的LLM)和一套“工具箱”的智能助理。它的“工具箱”里可能包含代码解释器、搜索引擎、计算器、日历API客户端、数据库查询工具,甚至与其他AI模型交互的接口(比如Google的A2A协议)等。当Agent接收到一个高层级的任务(例如,“帮我规划下周末去北京的旅行,并预订往返机票和酒店”),它的“大脑”会首先理解任务,将其分解为一系列子步骤,然后决定在每个步骤需要使用哪个“工具”,调用工具获取信息或执行操作,再根据工具的返回结果评估进展,并规划下一步行动,直到最终完成整个任务。
Go语言在构建AI Agent的浪潮中,同样展现出其独特的工程优势和潜力。
Agent执行后端/运行时(Agent Runtime)。 一个Agent的核心通常是一个“思考-行动-观察”的循环(ReAct - Reason and Act - 框架就是一个典型例子)。Go语言以其卓越的性能、轻量级的并发(goroutine)以及高效的内存管理,使其非常适合构建Agent的核心执行引擎。这个引擎需要处理任务的分解与调度、工具的调用与结果的异步处理、Agent状态的维护(如记忆、历史记录),以及与LLM的频繁交互。Go的并发模型能让Agent同时处理多个子任务或与多个工具交互,而其性能则能保障Agent的响应速度和思考效率。
工具API的实现与标准化封装。 Agent的“工具箱”是其行动能力的关键。传统上,如果Agent需要调用外部API(无论是公司内部的业务API还是公共的互联网API)或执行特定的系统操作(如读写文件、执行命令),开发者会为每个这样的“工具”编写一个Go函数或服务,并将其接口暴露给Agent。Go强大的标准库(特别是 net/http、 os、 database/sql 等)和丰富的第三方生态,使得这种传统方式的工具API封装变得非常便捷。LLM通过其规划能力,理解何时需要调用这些工具,并通过某种机制(如函数调用、API请求)触发它们。
然而,随着Agent需要使用的工具种类和数量的增加,这种点对点的、非标准化的工具集成方式可能会带来维护和扩展上的挑战。 模型上下文协议(MCP - Model Context Protocol) 的出现,正是为了解决LLM与外部世界(包括数据源和工具)交互的标准化问题。MCP试图定义一套通用的“接口”规范,让LLM能够以一种统一的、结构化的方式发现、理解和调用外部工具或获取上下文数据。
Go语言在实现MCP Server方面同样具有显著优势。 一个MCP Server负责将一组工具或数据源按照MCP规范进行封装,并提供一个标准化的端点供LLM(或Agent核心)查询和交互。Go的高性能网络库、并发处理能力以及对JSONRPC(MCP通常基于JSONRPC)的良好支持,使其非常适合构建高效、可靠的MCP Server。通过这种方式,Go不再仅仅是实现单个工具API,而是能够构建一个 标准化的“工具上下文提供者”,LLM可以通过MCP协议来“理解”这个Server能提供哪些工具(函数签名、参数描述、功能说明),并请求执行它们。这不仅提升了工具的可发现性和互操作性,也为Agent的工具使用带来了更结构化和可管理的方式。因此,Go在为AI Agent提供“工具”支持时,既能胜任传统的API封装,也能完美承担起构建和实现MCP Server这一更高级、更标准化的角色。
在讨论AI Agent时,你可能还会听到一个相关的术语——Agentic AI。虽然这两个词经常被互换使用,但它们侧重点略有不同:
-
AI Agent通常更侧重于指代一个具体的、能够执行上述自主规划、工具使用和学习调整等行为的软件实体或系统。 它是一个可构建、可部署的“智能体程序”。
-
Agentic AI则更偏向于描述一种设计理念、研究方向或AI系统所展现出的类智能体(agent-like)特性。 它强调的是AI系统所具备的那种能够像一个有自主意识的代理人一样去感知环境、设定目标、采取行动并从经验中学习的能力和行为模式。可以说,AI Agent是实现Agentic AI理念的一种具体技术路径和产物。一个具备高度Agentic特性的AI系统,可能由一个或多个协同工作的AI Agent组成。
Go语言凭借其在系统编程、网络服务、并发处理和工程效率上的优势,无疑为构建强大的AI Agent和实现复杂的Agentic AI系统提供了坚实的工程基础。
当我们让LLM不仅能检索知识(如RAG),还能主动使用工具去行动(如AI Agent)时,AI应用的想象空间将被极大地拓展。
Go与AI生态的更多结合点
除了直接构建面向用户的AI应用外,Go语言在支撑整个AI生态系统的基础设施和工具链方面也大有可为:
-
数据处理与特征工程:虽然Python在此领域有优势,但对于需要高性能、大规模并发处理的特定数据预处理或特征提取任务,Go可以作为补充。
-
模型部署与服务化:使用Go构建高性能的HTTP/gRPC服务来包装和提供对已训练模型的推理(inference)API,或者作为AI模型服务的API网关、负载均衡器等。
-
AI基础设施与工具链开发:例如,开发用于模型管理、实验追踪、分布式训练协调(尽管训练本身可能不是Go)、AI数据管道编排等的平台和工具。
虽然本节课主要聚焦于基础的LLM API交互,但理解这些更高级的应用场景,能帮助我们更好地定位Go在未来AI版图中的价值。
小结
这节课,我们一起探索了如何将强大的AI大模型能力集成到Go应用中,为Go开发者进入激动人心的AI应用开发领域提供了坚实的入门基础。
我们首先理解了AI浪潮为Gopher带来的机遇与挑战,并明确了Go语言在AI工程化中的定位——凭借其高性能、高并发、强大的网络库和易于部署的特性,Go是构建AI应用后端、中间件和基础设施的理想选择。我们还引入了“LLM即操作系统”这一核心范式,以及模型规格的重要性,为理解AI应用开发建立了新的心智模型。
接着,我们深入学习了与LLM交互的核心准则,包括以对话和消息(包含 system、 user、 assistant 等角色)为基础的交互结构,以及LLM API在底层通常所具有的“无状态性”——这要求开发者必须在客户端(Go应用)负责维护和传递完整的对话历史以实现多轮对话。
我们重点介绍了目前行业内与LLM通信的API事实标准——OpenAI兼容API(特别是Chat Completions API),了解了其核心请求与响应结构,以及通过API密钥和Base URL进行身份认证的方式。我们还通过一个Go语言裸调API的实战示例,亲手完成了第一个“Hello, AI”程序。
为了提升交互效率和代码质量,我们探讨了Prompt工程的入门技巧(如明确角色、清晰指令、提供示例、思维链提示)和为何需要使用SDK。我们概览了Go LLM SDK的生态,并重点实战了官方的OpenAI Go SDK( github.com/openai/openai-go),通过示例学习了如何使用它进行多轮对话。
最后,我们简要展望了Go在更高级AI应用(如RAG、AI Agent)中的角色,以及在AI数据处理、模型服务化和基础设施开发等领域的更多结合点。
本节课为你打开了Go与AI集成的大门。虽然我们只触及了冰山一角(特别是像Prompt工程、RAG、Agent这些都足以构成独立的深度课程),但你现在已经拥有了开始在自己的Go项目中尝试和探索AI能力的基础知识和工具。希望你能带着这份初识的兴奋,勇敢地去探索Go+AI的无限可能!
思考题
假设你需要为一个已有的Go Web应用(例如,一个技术博客系统)集成一个简单的AI功能:当用户在搜索框输入问题时,如果站内搜索结果不理想,可以提供一个“问AI”的按钮,将用户的问题发送给一个LLM,并将模型的回答展示给用户。请思考:
-
你会选择直接调用LLM API(如本节课中的裸调API方式)还是使用Go SDK(如
openai/openai-go)来实现这个功能?请阐述你选择的理由。 -
在Go后端,你会如何设计一个简单的函数(或方法)来处理这个“问AI”的请求?它大致需要接收哪些参数?你会如何构造发送给LLM的
messages列表(特别考虑System Message和User Message的内容应该是什么)? -
对于用户提出的问题,如果你希望LLM的回答能更多地基于你博客中的现有文章内容,而不是仅仅依赖LLM的通用知识库(以减少幻觉,并使回答更具针对性),你会如何初步设想(不需要写完整代码,描述思路即可)让LLM在回答时能“参考”到相关的博客文章内容(这实际上是在为后续可能学习的RAG技术做一个最基础的思考铺垫)?
欢迎在留言区分享你的思考和见解!我是Tony Bai,我们下节课再见。
实战串讲(工程篇):“短链接服务”的工程化实践(上)
你好!我是Tony Bai。欢迎来到我们Go语言进阶课中“工程实践”模块的实战串讲。
在模块二“设计先行,奠定高质量代码基础”的实战部分,我们已经为“短链接服务”这个项目一同绘制了清晰的设计蓝图。我们确定了其分层架构,规划了项目应有的目录结构,定义了核心的业务接口(如 Store 接口、 ShortenerService 接口),设计了对外暴露的API端点,并为错误处理和API响应制定了初步的策略。可以说,我们已经有了“建筑图纸”。
现在,是时候拿起“工具”,将这些精心的设计思想转化为实实在在的、能够运行的Go代码了。更重要的是,我们不仅仅要让它“能跑起来”,更要为其注入生产环境所必需的“工程灵魂”。一个能在生产环境稳定运行、易于维护、问题可追溯的应用,远不止实现核心业务逻辑那么简单。它需要一个健壮的应用骨架来承载,需要灵活的配置管理来适应不同环境,需要清晰的日志记录来洞察运行状态,还需要完善的可观测性体系来保障其健康。这些,正是我们在 模块三“工程实践,锻造生产级Go服务” 中一直学习和强调的重点。
接下来的两节课,我们将亲自动手为“短链接服务”搭建起基础的工程框架,并集成一系列关键的工程化组件。这节课,我们先一起完成以下几个核心步骤:
-
搭建应用骨架:这包括创建程序的入口(
main.go),规划清晰的初始化流程,实现依赖的手动注入,并集成优雅的服务器退出机制。这部分内容将直接应用我们应用骨架这节课中学到的知识。 -
集成配置管理:我们将引入
spf13/viper库,让我们的服务能够从配置文件和环境变量中灵活加载所需的配置项,例如服务器端口、日志级别等。这对应了核心组件这一节课中关于配置管理的实践。 -
集成结构化日志:我们将使用Go 1.21+ 内置的
log/slog包,为服务实现结构化日志记录,确保日志信息既易于阅读,也便于机器解析和后续的集中式分析。这同样呼应了核心组件这一节课中关于日志最佳实践的内容。
注:这两节课的代码示例将侧重于这些工程实践的集成过程,核心的短链接业务逻辑(如短码生成算法、存储的具体实现等)会做相应的简化处理,以便我们能更聚焦于工程化本身。我们假设你已经对Go的基础语法和之前课程中涉及的包(如
net/http、context)有基本了解。
让我们开始动手,一步步地将“短链接服务”从设计图纸变为一个初具生产雏形的Go应用吧!
项目初始化与应用骨架搭建
任何一个Go项目的开始,都离不开合理的项目结构和清晰的应用入口。这将直接影响后续代码的组织、可维护性以及团队协作的效率。我们将首先为“短链接服务”奠定这个基础。
项目结构回顾与创建
在设计篇实战中,我们已经初步规划了项目的目录结构。现在,为了更好地配合后续的工程化实践,我们可以对其进行微调和确认。一个推荐的、符合社区习惯并适合我们实战的结构如下:
shortlink-service/
├── cmd/
│ └── server/ # HTTP服务的主程序入口
│ └── main.go
├── configs/ # 存放配置文件
│ └── config.yaml # 示例配置文件 (后续添加)
├── internal/ # 项目内部代码,不希望被外部项目直接导入
│ ├── app/ # (新增) 应用核心,封装启动、依赖注入、关闭等逻辑
│ │ └── app.go
│ ├── config/ # 配置加载与管理模块
│ │ └── config.go
│ ├── handler/ # HTTP请求处理器 (API层)
│ │ └── link_handler.go # (业务逻辑相关,本讲简化)
│ ├── service/ # 业务逻辑层
│ │ └── shortener_service.go # (业务逻辑相关,本讲简化)
│ ├── store/ # 数据存储层接口与实现
│ │ ├── store.go // Store接口定义 (业务逻辑相关,本讲简化)
│ │ └── memory/ // 内存存储实现 (用于本讲示例)
│ │ └── memory.go // (业务逻辑相关,本讲简化)
│ ├── middleware/ // HTTP中间件
│ │ ├── metrics.go // (后续添加)
│ │ └── logger.go // (可选,或直接在router/handler中使用slog)
│ ├── metrics/ // Prometheus Metrics定义
│ │ └── metrics.go // (后续添加)
│ └── tracing/ // OpenTelemetry Tracing 初始化
│ └── tracer.go // (后续添加)
├── pkg/ // (可选) 如果有可以被外部项目复用的库代码
│ └── lifecycle/ // 例如,通用的组件生命周期管理接口
│ └── lifecycle.go // (本讲将不直接使用,但为体现完整性保留)
├── go.mod
└── go.sum
这次的结构与设计篇相比,主要变化是新增 internal/app/app.go。我们将遵循应用骨架的建议,将核心的初始化、组件编排和生命周期管理逻辑从 main.go 中抽离出来,放到一个专门的 App 结构体及其方法中。这使得 main.go 变得非常“薄”,主要负责创建和运行这个 App 实例,也为后续的单元测试(如果需要测试启动和关闭逻辑)提供了便利。此外先前的idgen和shorten包都合并简化到了service包中。
你可以使用 mkdir -p 命令快速创建这些目录(除了 go.mod 和 go.sum,它们由Go模块命令生成)。然后在项目根目录( shortlink-service/)下运行 go mod init github.com/your_org/shortlink(请替换为你的实际模块路径)来初始化Go模块。
项目结构就绪后,我们来构建应用的入口和核心初始化流程。
构建应用入口与核心初始化流程
正如我们在应用骨架这节课中所强调的,一个良好的应用应该有一个清晰的启动流程。我们将 cmd/server/main.go 设计得非常简洁,它只负责引导和运行应用的核心逻辑,而将具体的初始化、组件编排和生命周期管理委托给 internal/app/app.go 中定义的 App 结构体。
应用核心 internal/app/app.go
我们先定义 App 结构体和其 Run 方法,其中 Run 方法内部会以注释的形式规划出后续要逐步填充的初始化和运行步骤。
// internal/app/app.go
package app
import (
"context"
"errors"
"fmt"
"io" // For store.Close
"log/slog"
"net/http"
"os"
"os/signal"
"strings"
"syscall"
"time"
// 应用内部包
"github.com/your_org/shortlink/internal/config"
"github.com/your_org/shortlink/internal/handler"
appMetrics "github.com/your_org/shortlink/internal/metrics"
"github.com/your_org/shortlink/internal/middleware"
"github.com/your_org/shortlink/internal/service"
"github.com/your_org/shortlink/internal/store" // Store接口
"github.com/your_org/shortlink/internal/store/memory" // 内存存储实现
appTracing "github.com/your_org/shortlink/internal/tracing"
// 第三方库
"github.com/prometheus/client_golang/prometheus/promhttp"
"go.opentelemetry.io/contrib/instrumentation/net/http/otelhttp"
sdktrace "go.opentelemetry.io/otel/sdk/trace"
)
// App 封装了应用的所有依赖和启动关闭逻辑
type App struct {
appName string
serviceVersion string
logger *slog.Logger
cfg *config.Config
store store.Store
shortenerSvc service.ShortenerService
tracerProvider *sdktrace.TracerProvider
httpServer *http.Server
}
// New 创建一个新的App实例,完成所有依赖的初始化和注入
func New(cfg *config.Config, logger *slog.Logger, appName, version string) (*App, error) {
app := &App{
cfg: cfg,
logger: logger.With("component", "appcore"), // App自身也可以有组件标识
appName: appName,
serviceVersion: version,
}
app.logger.Info("Creating new application instance...",
slog.String("appName", app.appName),
slog.String("version", app.serviceVersion),
)
// --- [App.New - 初始化阶段 1] ---
// 初始化可观测性组件 (Tracing & Metrics)
if app.cfg.Tracing.Enabled {
var errInitTracer error
// 1a. 初始化 Tracing (OpenTelemetry)
app.tracerProvider, errInitTracer = appTracing.InitTracerProvider(
app.appName,
app.serviceVersion,
app.cfg.Tracing.Enabled,
app.cfg.Tracing.SampleRatio,
)
if errInitTracer != nil {
app.logger.Error("Failed to initialize TracerProvider", slog.Any("error", errInitTracer))
return nil, fmt.Errorf("app.New: failed to init tracer provider: %w", errInitTracer)
}
}
// 1b. 初始化 Metrics (Prometheus Go运行时等)
appMetrics.Init()
app.logger.Info("Prometheus Go runtime metrics collectors registered.")
// --- [App.New - 初始化阶段 2] ---
// 初始化核心业务依赖 (层级:Store -> Service -> Handler)
app.logger.Debug("Initializing core dependencies...")
// 2a. 初始化 Store 层
switch strings.ToLower(app.cfg.Store.Type) {
case "memory":
app.store = memory.NewStore(app.logger.With("datastore", "memory"))
app.logger.Info("Initialized in-memory store.")
default:
err := fmt.Errorf("unsupported store type from config: %s", app.cfg.Store.Type)
app.logger.Error("Failed to initialize store", slog.Any("error", err))
return nil, err
}
// 2b. 初始化 Service 层 (注入Store)
app.shortenerSvc = service.NewShortenerService(app.store, app.logger.With("layer", "service"))
app.logger.Info("Shortener service initialized.")
// 2c. 初始化 Handler 层 (注入Service)
linkHdlr := handler.NewLinkHandler(app.shortenerSvc, app.logger.With("layer", "handler"))
app.logger.Info("Link handler initialized.")
// --- [App.New - 初始化阶段 3] ---
// 创建HTTP Router并注册所有路由
mux := http.NewServeMux()
// 3a. 注册业务路由
mux.HandleFunc("POST /api/links", linkHdlr.CreateShortLink)
mux.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
path := r.URL.Path
if path == "/metrics" || strings.HasPrefix(path, "/debug/pprof") {
return // 这些由诊断路由处理
}
if r.Method == http.MethodGet && len(path) > 1 && path[0] == '/' && !strings.Contains(path[1:], "/") {
shortCode := path[1:]
linkHdlr.RedirectShortLink(w, r, shortCode)
return
}
http.NotFound(w, r)
})
// 3b. 注册诊断路由 (Metrics, pprof)
mux.Handle("/metrics", promhttp.Handler())
mux.HandleFunc("/debug/pprof/", http.DefaultServeMux.ServeHTTP) // 假设pprof已注册到DefaultServeMux
app.logger.Info("HTTP routes registered.")
// --- [App.New - 初始化阶段 4] ---
// 应用HTTP中间件 (顺序很重要)
var finalHandler http.Handler = mux
// 4a. 应用 Metrics 中间件
finalHandler = middleware.Metrics(finalHandler)
app.logger.Info("Applied HTTP Metrics middleware.")
// 4b. 应用 Tracing 中间件
if app.tracerProvider != nil {
finalHandler = otelhttp.NewHandler(finalHandler, fmt.Sprintf("%s.http.server", app.appName),
otelhttp.WithMessageEvents(otelhttp.ReadEvents, otelhttp.WriteEvents),
)
app.logger.Info("Applied OpenTelemetry HTTP Tracing middleware.")
}
// 4c. 应用 Logging 中间件
finalHandler = middleware.RequestLogger(app.logger)(finalHandler)
app.logger.Info("Applied HTTP Request Logging middleware.")
// --- [App.New - 初始化阶段 5] ---
// 创建并配置最终的HTTP服务器
app.httpServer = &http.Server{
Addr: ":" + app.cfg.Server.Port,
Handler: finalHandler,
ReadTimeout: app.cfg.Server.ReadTimeout,
WriteTimeout: app.cfg.Server.WriteTimeout,
IdleTimeout: app.cfg.Server.IdleTimeout,
}
app.logger.Info("HTTP server and dependencies initialized successfully.", slog.String("listen_addr", app.httpServer.Addr))
return app, nil
}
// Run 启动应用并阻塞,直到接收到退出信号并完成优雅关闭
func (a *App) Run() error {
a.logger.Info("Starting application run cycle...",
slog.String("appName", a.appName),
slog.String("version", a.serviceVersion),
)
// --- [App.Run - 运行阶段 1] ---
// 异步启动HTTP服务器
errChan := make(chan error, 1)
go func() {
a.logger.Info("HTTP server starting to listen and serve...")
if err := a.httpServer.ListenAndServe(); err != nil && !errors.Is(err, http.ErrServerClosed) {
a.logger.Error("HTTP server ListenAndServe failed", slog.Any("error", err))
errChan <- err
}
close(errChan)
}()
a.logger.Info("HTTP server startup process initiated.")
// --- [App.Run - 运行阶段 2] ---
// 实现优雅退出:阻塞等待OS信号或服务器启动错误
quitChannel := make(chan os.Signal, 1)
signal.Notify(quitChannel, syscall.SIGINT, syscall.SIGTERM)
select {
case sig := <-quitChannel:
a.logger.Warn("Received shutdown signal, initiating graceful shutdown...",
slog.String("signal", sig.String()),
)
case err := <-errChan:
if err != nil {
a.logger.Error("HTTP server failed to start, initiating shutdown...", slog.Any("error", err))
}
}
// --- [App.Run - 运行阶段 3] ---
// 执行优雅关闭流程
shutdownCtx, cancelShutdown := context.WithTimeout(context.Background(), a.cfg.Server.ShutdownTimeout)
defer cancelShutdown()
a.logger.Info("Attempting to gracefully shut down the HTTP server...",
slog.Duration("shutdown_timeout", a.cfg.Server.ShutdownTimeout),
)
if err := a.httpServer.Shutdown(shutdownCtx); err != nil {
a.logger.Error("HTTP server graceful shutdown failed or timed out", slog.Any("error", err))
} else {
a.logger.Info("HTTP server stopped gracefully.")
}
// --- [App.Run - 运行阶段 4] ---
// 清理其他应用资源
a.logger.Info("Cleaning up other application resources...")
if a.store != nil {
if closer, ok := a.store.(io.Closer); ok {
if err := closer.Close(); err != nil {
a.logger.Error("Error closing store", slog.Any("error", err))
} else {
a.logger.Info("Store closed successfully.")
}
}
}
if a.tracerProvider != nil {
tpShutdownCtx, tpCancel := context.WithTimeout(context.Background(), 5*time.Second)
defer tpCancel()
a.logger.Info("Attempting to shut down TracerProvider...")
if err := a.tracerProvider.Shutdown(tpShutdownCtx); err != nil {
a.logger.Error("Error shutting down TracerProvider", slog.Any("error", err))
} else {
a.logger.Info("TracerProvider shut down successfully.")
}
}
a.logger.Info("Application has shut down completely.")
return nil // 优雅关闭完成,返回nil
}
我们来解释下代码。
App结构体:-
这是一个核心的容器(Container)或编排者(Orchestrator)结构体。
-
它封装了应用运行所需的所有关键依赖,如配置(
cfg)、日志记录器(logger)、数据存储实例(store)、业务服务实例(shortenerSvc)、HTTP服务器(httpServer)以及其他需要生命周期管理的组件(如tracerProvider)。 -
将所有依赖集中在一个结构体中,使得应用的状态和组件关系非常清晰,也便于在不同部分(如
New和Run方法)之间共享这些依赖。
-
New()函数:-
这是应用的构造器(Constructor),负责静态的、一次性的初始化工作。
-
它的核心职责是依赖注入(Dependency Injection)。它接收最基础的依赖(如配置和引导日志器),然后按照“被依赖者先于依赖者”的顺序,一步步创建和组装应用的所有组件。例如,它先创建
Store,然后将Store注入到Service的构造函数中,再将Service注入到Handler的构造函数中。 -
New()函数完成了所有组件的“准备工作”,包括创建HTTP Router、应用中间件,以及配置最终的http.Server实例。 -
如果任何关键的初始化步骤失败,
New()会返回一个错误,阻止应用启动。
-
Run()方法:-
这是应用的核心执行体(Executor),负责管理应用的运行时生命周期。
-
它的第一步是启动应用的主要服务(在我们的例子中,是异步启动HTTP服务器)。
-
然后,它会阻塞主goroutine,通过监听操作系统的
SIGINT和SIGTERM信号来等待退出指令。 -
一旦收到退出信号,它会启动一个优雅的关闭(Graceful Shutdown)流程。这包括:
-
调用
httpServer.Shutdown(),给正在处理的HTTP请求一个完成的时间窗口。 -
在服务器关闭后,清理其他需要释放的资源,如关闭数据库连接池、确保追踪数据被完全导出等。
-
-
Run()方法在整个优雅关闭流程完成后才会返回,向调用者(main()函数)表明应用已成功终止。
-
通过 New() 负责“组装”和 Run() 负责“运行与关闭”的明确职责划分,我们的 app.go 实现了一个清晰、健壮且符合Go应用骨架最佳实践的核心。
“薄” main 函数( cmd/server/main.go)
main.go 的职责变得非常简单:创建 App 实例并调用其 Run 方法。我们来看一下 main.go 的主要源码:
// cmd/server/main.go
package main
import (
"fmt"
"log/slog" // 用于在app.New失败时记录日志
"os"
"strings" // 用于initSlogLogger
"time" // 用于initSlogLogger
"github.com/your_org/shortlink/internal/app" // 导入app核心包
"github.com/your_org/shortlink/internal/config" // 导入配置包
)
const (
// defaultAppName 和 defaultAppVersion 作为硬编码的默认值,
// 它们可以在没有配置文件或配置项时的最终兜底。
// 在实际项目中,版本号更推荐通过编译时注入(ldflags)来设置。
defaultAppName = "ShortLinkService"
defaultAppVersion = "0.1.0"
)
// bootstrapLogger 是一个引导日志器,专门用于应用启动的极早期阶段。
// 它的主要目的是在`app.New()`函数执行过程中或失败时,能够以结构化的方式记录日志。
// 它直接从传入的(可能已加载的)配置中获取日志级别和格式,
// 如果配置未加载,则使用安全的默认值。
// 注意:这个logger是临时的,App实例创建成功后,会使用其内部更完善的、基于完整配置的logger。
func bootstrapLogger(cfg *config.Config) *slog.Logger {
var level slog.Level
logLevelStr := "info" // 安全的默认日志级别
logFormatStr := "text" // 默认使用text格式,便于在启动时直接在控制台阅读
// 如果配置文件已成功加载,则使用其中的设置
if cfg != nil {
logLevelStr = cfg.Server.LogLevel
logFormatStr = cfg.Server.LogFormat
}
switch strings.ToLower(logLevelStr) {
case "debug":
level = slog.LevelDebug
case "info":
level = slog.LevelInfo
case "warn":
level = slog.LevelWarn
case "error":
level = slog.LevelError
default:
// 如果配置中的日志级别无效,也使用安全的默认值
level = slog.LevelInfo
}
var handler slog.Handler
// 创建一个Handler,配置其日志级别和时间戳格式。
// 注意:AddSource设为false,因为引导日志通常不需要源码位置,且可以提升一点点性能。
// 日志输出到标准错误流(os.Stderr),这是记录启动过程错误的常见做法。
handlerOpts := &slog.HandlerOptions{AddSource: false, Level: level, ReplaceAttr: func(groups []string, a slog.Attr) slog.Attr {
if a.Key == slog.TimeKey {
a.Value = slog.StringValue(a.Value.Time().Format(time.RFC3339))
}
return a
}}
if strings.ToLower(logFormatStr) == "json" {
handler = slog.NewJSONHandler(os.Stderr, handlerOpts)
} else {
handler = slog.NewTextHandler(os.Stderr, handlerOpts)
}
// 返回一个带有"bootstrap_phase"标识的logger,便于区分这是启动阶段的日志。
return slog.New(handler).With(slog.String("bootstrap_phase", "main"))
}
// main 函数是整个应用程序的入口点。
// 它的职责被设计得非常“薄”,主要负责引导和协调应用的创建与运行。
func main() {
// --- 步骤 0: (可选) 解析最顶层的命令行参数 ---
// 例如,通过`flag`包解析`-config`参数来指定配置文件的路径。
// configFile := flag.String("config", "./configs/config.yaml", "Path to config file")
// flag.Parse()
// 为了保持本示例的简洁性,我们暂时直接使用固定的路径和名称。
// --- 步骤 1: 加载配置 ---
// 这是应用启动的第一步关键操作。后续所有组件的初始化都依赖于这份配置。
// LoadConfig内部会处理文件查找、读取、解析以及环境变量的覆盖。
cfg, err := config.LoadConfig("./configs", "config", "yaml")
if err != nil {
// 如果连配置都加载失败,这通常是一个致命错误,无法继续。
// 此时日志系统可能还未初始化,所以使用`fmt.Fprintf`直接向标准错误输出。
fmt.Fprintf(os.Stderr, "FATAL: Error loading initial application configuration: %v\n", err)
os.Exit(1) // 以非零状态码退出,表示启动失败。
}
// --- 步骤 2: 初始化引导日志器 ---
// 基于刚刚加载的配置(或其默认值),创建一个临时的引导日志器。
// 这个logger主要用于记录`app.New()`的执行过程,以及在`app.New()`失败时能输出结构化的错误信息。
mainLogger := bootstrapLogger(&cfg)
// 我们可以在这里选择是否立即将此logger设置为全局默认实例(`slog.SetDefault`)。
// 通常,更推荐的做法是在app.New()内部,当所有配置都最终确定后,
// 创建并设置最终的、功能完备的全局默认logger。
mainLogger.Info("Configuration loaded, attempting to create application instance...")
// --- 步骤 3: 创建App实例 ---
// 这是整个初始化过程的核心。我们将配置和引导日志器注入到`app.New()`函数中。
// `app.New()`内部会完成所有组件(如Store, Service, Handler, HTTP Server等)的实例化和依赖注入。
appNameFromConfig := cfg.AppName
if appNameFromConfig == "" { // 如果配置中未指定appName,则使用硬编码的默认值
appNameFromConfig = defaultAppName
}
application, err := app.New(&cfg, mainLogger, appNameFromConfig, defaultAppVersion)
if err != nil {
// 如果`app.New()`返回错误,说明应用的核心组件未能成功创建。
// 我们使用刚刚创建的引导日志器来记录这个致命错误,然后退出。
mainLogger.Error("FATAL: Failed to create application instance", slog.Any("error", err))
os.Exit(1)
}
mainLogger.Info("Application instance created successfully.")
// --- 步骤 4: 运行App ---
// `application.Run()`是一个阻塞调用,它封装了应用的整个运行时生命周期,
// 包括启动所有服务(如HTTP服务器)、监听操作系统信号及执行优雅关闭。
if err := application.Run(); err != nil {
// 如果`Run()`方法返回错误,表明应用在运行或关闭过程中遇到了未能处理的严重问题。
// 此时,应用内部的、功能完备的日志系统应该已经可用,我们可以通过它来记录最终的致命错误。
// (假设App实例有一个Logger()方法可以暴露其内部的logger)
application.Logger().Error("FATAL: Application run failed and terminated", slog.Any("error", err))
os.Exit(1)
}
// 如果`Run()`正常返回nil,说明应用已成功完成优雅关闭流程。
// 相关的成功日志应在app.Run()内部或组件的Stop方法中打印。
// main函数在此处正常结束,隐式返回os.Exit(0)。
mainLogger.Info("Application main function exiting cleanly.")
}
其中, cmd/server/main.go 文件是我们“短链接服务”的唯一入口点。遵循我们在应用骨架这节课中探讨的“薄 main ,厚 App ”的设计原则,这个 main 函数被设计得非常简洁,其核心职责可以概括为以下几个清晰的步骤:
-
引导与协调:
main函数的首要任务是作为应用的引导程序。它不包含任何具体的业务逻辑或复杂的组件初始化代码,而是负责协调整个应用的启动流程。 -
早期配置加载:它是应用中第一个执行实际操作的部分,即调用
config.LoadConfig()来加载应用的配置。这是后续所有初始化工作的基础。如果配置加载失败,main函数会立即以失败状态退出,因为没有配置,应用无法继续。 -
创建引导日志器:在加载完配置后,
main函数会立即利用这些配置(或其默认值)创建一个临时的“引导日志器”。这个日志器的主要作用是记录应用核心实例app.App的创建过程,特别是在app.New()函数执行失败时,能够以结构化的方式输出错误信息,这比简单的fmt.Fprintf更利于诊断。 -
实例化应用核心(
app.New):main函数将加载到的配置和创建的引导日志器,作为参数传递给app.New()函数,请求创建一个完整的应用实例。main函数将应用的创建和所有复杂依赖注入的职责完全委托给了app.App的构造器。 -
运行应用(
application.Run):一旦app.New()成功返回应用实例,main函数就调用其Run()方法。这是一个阻塞调用,它将程序的控制权完全交给了App实例,由App实例负责管理应用的整个运行时生命周期,包括启动服务、监听信号和执行优雅关闭。 -
处理致命错误与退出:
main函数是应用生命周期的最终守护者。它会检查app.New()和application.Run()的返回值。如果任何一个步骤返回了错误,main函数会记录一条致命错误日志,并调用os.Exit(1)以非零状态码退出,向操作系统或外部监控系统明确表示应用启动或运行失败。如果Run()正常返回(err == nil),则意味着应用已成功完成优雅关闭,main函数随之正常结束。
通过这种职责划分,我们的 main.go 保持了极高的可读性和单一职责,它只关心“如何正确地启动和结束应用”,而将“应用由什么组成以及如何运作”的复杂性完全封装在了 internal/app 包中。这不仅使得代码结构更清晰,也为后续对应用核心逻辑进行单元测试提供了可能。
同时,这种“薄 main,厚 App”的结构,使得核心的应用逻辑(在 internal/app/app.go 中)更容易进行单元测试(例如,我们可以测试 App.Run() 在不同配置或模拟依赖下的行为,而无需实际启动HTTP服务器或监听信号)。
为了更直观地理解我们规划的这个核心流程,可以用下图来表示上面 main函数 和 app 创建和运行的核心流程:
这个清晰的骨架和流程规划,为我们后续逐步集成各个工程组件提供了坚实的基础。在所有组件被启动之前,我们首先要确保应用具备一个核心的健壮性特征——优雅退出。
实现优雅退出机制
一个生产级的HTTP服务必须能够响应操作系统发送的终止信号(如用户在终端按下 Ctrl+C 时产生的 SIGINT,或者部署系统如Kubernetes停止Pod时发送的 SIGTERM),并执行一个“优雅”的关闭流程,而不是被粗暴地杀死。
优雅退出意味着:
-
服务器立即停止接受任何新的入站连接。
-
给当前正在处理的请求一个合理的时间窗口来完成它们的处理。
-
在程序最终退出前,有序地释放所有占用的关键资源(如数据库连接、文件句柄、追踪数据缓冲区等)。
Go标准库的 net/http.Server 类型提供了 Shutdown(ctx context.Context) 方法,它与Go的信号处理和 context 机制结合,可以完美地支持这一需求。我们已经在 internal/app/app.go 的 Run() 方法末尾规划并实现了优雅退出的逻辑,现在我们来详细解读这部分核心代码。
我们来解析下 internal/app/app.go 中优雅退出部分的实现,先来看 App.Run() 方法中是如何实现这个流程的。在异步启动HTTP服务器之后,主goroutine会执行以下逻辑:
// (在App.Run()方法内部,异步启动HTTP服务器之后)
// --- [App.Run - 运行阶段 2] ---
// 实现优雅退出:阻塞等待OS信号或服务器启动错误
quitChannel := make(chan os.Signal, 1)
// 通知channel监听指定的信号。缓冲为1确保即使信号连续快速发送,也不会丢失至少一个。
signal.Notify(quitChannel, syscall.SIGINT, syscall.SIGTERM)
// 阻塞等待以下两个事件之一发生:
// 1. 从quitChannel中接收到一个操作系统退出信号。
// 2. 从errChan中接收到一个错误,表明HTTP服务器在启动时就失败了。
select {
case sig := <-quitChannel:
a.logger.Warn("Received shutdown signal, initiating graceful shutdown...",
slog.String("signal", sig.String()), // 记录收到的具体信号
)
case err := <-errChan:
// 如果ListenAndServe在启动时就失败了(例如,端口被占用),
// 我们也需要触发后续的关闭和清理流程。
if err != nil {
a.logger.Error("HTTP server failed to start, initiating shutdown...", slog.Any("error", err))
}
}
// --- [App.Run - 运行阶段 3] ---
// 执行优雅关闭流程
// 从配置中获取优雅关闭的超时时间
shutdownCtx, cancelShutdown := context.WithTimeout(context.Background(), a.cfg.Server.ShutdownTimeout)
defer cancelShutdown() // 确保在函数退出时,即使是正常退出,也调用cancel释放context相关资源
a.logger.Info("Attempting to gracefully shut down the HTTP server...",
slog.Duration("shutdown_timeout", a.cfg.Server.ShutdownTimeout),
)
// 调用http.Server的Shutdown方法。
if err := a.httpServer.Shutdown(shutdownCtx); err != nil {
// 如果Shutdown方法返回错误(通常是因为提供的context超时了,但仍有连接未关闭),
// 则记录这个错误。此时,服务器可能没有完全优雅地关闭所有连接。
a.logger.Error("HTTP server graceful shutdown failed or timed out", slog.Any("error", err))
} else {
a.logger.Info("HTTP server stopped gracefully.")
}
// --- [App.Run - 运行阶段 4] ---
// 清理其他应用资源
a.logger.Info("Cleaning up other application resources...")
if a.store != nil { // 关闭Store (如果它实现了io.Closer)
if closer, ok := a.store.(io.Closer); ok {
if err := closer.Close(); err != nil {
a.logger.Error("Error closing store", slog.Any("error", err))
} else {
a.logger.Info("Store closed successfully.")
}
}
}
if a.tracerProvider != nil { // 关闭TracerProvider
// 为TracerProvider的Shutdown也设置一个独立的、较短的超时
tpShutdownCtx, tpCancel := context.WithTimeout(context.Background(), 5*time.Second)
defer tpCancel()
a.logger.Info("Attempting to shut down TracerProvider...")
if err := a.tracerProvider.Shutdown(tpShutdownCtx); err != nil {
a.logger.Error("Error shutting down TracerProvider", slog.Any("error", err))
} else {
a.logger.Info("TracerProvider shut down successfully.")
}
}
a.logger.Info("Application has shut down completely.")
return nil // 优雅关闭完成,返回nil
// } // App.Run() 方法结束
代码说明:
-
监听信号:我们创建了一个缓冲大小为1的channel
quitChannel,并通过signal.Notify让它监听syscall.SIGINT(通常由Ctrl+C触发)和syscall.SIGTERM(标准的终止信号)这两个最常见的退出信号。 -
阻塞等待:主goroutine通过一个
select语句阻塞,它会等待两个事件中的任何一个先发生:-
从
quitChannel接收到一个OS信号。 -
从
errChan接收到一个错误。errChan是我们用来从异步启动的HTTP服务器goroutine中接收启动错误的通道。如果服务器启动失败(例如,端口被占用),ListenAndServe会立即返回错误,这个错误会被发送到errChan,从而也能触发关闭流程。
-
-
超时控制的关闭:
-
一旦收到退出信号或启动错误,程序会继续执行。我们从配置中获取
shutdownTimeout,并使用context.WithTimeout创建一个带有此超时时间的shutdownCtx。这个context的作用是为整个优雅关闭过程设定一个总的最后期限。 -
调用
a.httpServer.Shutdown(shutdownCtx)。这个方法非常关键,它会平滑地关闭服务器:首先停止接受新连接,然后等待所有已建立的连接上的活动请求处理完毕。如果所有请求在shutdownCtx超时之前都处理完了,Shutdown会返回nil。如果超时了但仍有请求在处理,它会返回context.DeadlineExceeded错误,并强制关闭剩余连接。
-
-
清理其他资源:在HTTP服务器关闭之后,我们还预留了位置用于清理应用中的其他关键资源。这是一个非常重要的步骤,确保没有资源泄漏。
-
关闭Store:如果我们的
store实例(例如,一个数据库连接池)实现了io.Closer接口,我们应该在这里调用其Close()方法。 -
关闭TracerProvider:如果我们初始化了OpenTelemetry的
TracerProvider,必须在程序退出前调用其Shutdown()方法,以确保所有缓冲在内存中的追踪数据(spans)都被成功导出到后端。否则,可能会丢失最后的追踪信息。
-
要验证这个机制是否工作,你可以在本地运行你的服务:
-
在
shortlink-service项目根目录下,运行go run ./cmd/server/main.go。 -
服务启动后,在终端按下
Ctrl+C(这会发送SIGINT信号)。 -
观察控制台的日志输出,你应该能清晰地看到整个优雅关闭的流程日志:“Received shutdown signal…”, “Attempting to gracefully shut down…”, “HTTP server stopped gracefully.”, “Cleaning up other application resources…”, 直到最后的“Application has shut down completely.”。如果在关闭超时(例如,我们配置的20秒)内有正在处理的HTTP请求,服务器会尝试等待它们完成。
至此,我们的应用骨架不仅具备了清晰的初始化流程和依赖注入结构,更拥有了生产级服务所必需的、非常重要的优雅退出机制。这是构建一个健壮、可靠的Go服务的基础。
接下来,我们将为这个已经搭建好的骨架,逐步填充上同样重要的“神经系统”——配置管理和结构化日志。
配置管理与结构化日志构件集成
一个生产级的应用,其行为不能硬编码在代码中,而是需要通过外部配置来驱动。同时,它也需要以结构化的、易于分析的方式记录其运行时的关键信息。这两者是应用可运维性的核心,我们将逐步把这两大核心组件集成到我们 App.Run() 方法的初始化阶段。
集成Viper进行配置管理
我们选择 spf13/viper 作为配置管理库,它功能强大,支持多种配置源(文件、环境变量、远程等)和格式(YAML、JSON、TOML等)。在本例中,我们将主要使用YAML文件,并允许环境变量覆盖。
添加Viper依赖
在你的项目根目录下运行:
go get github.com/spf13/viper
# Viper 可能间接依赖其他库,go get 会处理
# 如果你需要支持特定格式如TOML,可能需要额外get对应的解析库的Viper驱动
# go get github.com/spf13/pflag # 通常与Viper一起使用处理命令行标志,但本例暂不直接用命令行覆盖Viper
go get gopkg.in/yaml.v3 # Viper 使用它来解析YAML
定义配置结构体( internal/config/config.go)
这个文件我们在之前的 App.Run() 的注释中已经规划了,现在我们来创建并完善它。
// internal/config/config.go
package config
import (
"fmt"
"os"
"strings"
"time"
"github.com/spf13/viper"
)
// Config 是应用的总配置结构体
type Config struct {
AppName string `mapstructure:"appName"`
Server ServerConfig `mapstructure:"server"`
Store StoreConfig `mapstructure:"store"`
Tracing TracingConfig `mapstructure:"tracing"`
}
// ServerConfig 包含HTTP服务器相关的配置
type ServerConfig struct {
Port string `mapstructure:"port"`
LogLevel string `mapstructure:"logLevel"`
LogFormat string `mapstructure:"logFormat"` // "text" or "json"
ReadTimeout time.Duration `mapstructure:"readTimeout"`
WriteTimeout time.Duration `mapstructure:"writeTimeout"`
IdleTimeout time.Duration `mapstructure:"idleTimeout"`
ShutdownTimeout time.Duration `mapstructure:"shutdownTimeout"`
}
// StoreConfig 包含与存储相关的配置
type StoreConfig struct {
Type string `mapstructure:"type"`
// DSN string `mapstructure:"dsn"` // Example for Postgres
}
// TracingConfig 包含与分布式追踪相关的配置
type TracingConfig struct {
Enabled bool `mapstructure:"enabled"`
OTELEndpoint string `mapstructure:"otelEndpoint"`
SampleRatio float64 `mapstructure:"sampleRatio"`
}
// LoadConfig 从指定路径加载配置文件并允许环境变量覆盖。
func LoadConfig(configSearchPath string, configName string, configType string) (cfg Config, err error) {
v := viper.New()
// 1. 设置默认值
v.SetDefault("appName", "ShortLinkServiceAppDefault")
v.SetDefault("server.port", "8080")
v.SetDefault("server.logLevel", "info")
v.SetDefault("server.logFormat", "json")
v.SetDefault("server.readTimeout", "5s")
v.SetDefault("server.writeTimeout", "10s")
v.SetDefault("server.idleTimeout", "120s")
v.SetDefault("server.shutdownTimeout", "15s")
v.SetDefault("store.type", "memory")
v.SetDefault("tracing.enabled", true)
v.SetDefault("tracing.otelEndpoint", "localhost:4317") // OTel Collector gRPC
v.SetDefault("tracing.sampleRatio", 1.0)
// 2. 设置配置文件查找路径、名称和类型
if configSearchPath != "" {
v.AddConfigPath(configSearchPath)
}
v.AddConfigPath(".")
v.SetConfigName(configName)
v.SetConfigType(configType)
// 3. 尝试读取配置文件
if errRead := v.ReadInConfig(); errRead != nil {
if _, ok := errRead.(viper.ConfigFileNotFoundError); !ok {
return cfg, fmt.Errorf("config: failed to read config file: %w", errRead)
}
fmt.Fprintf(os.Stderr, "[ConfigLoader] Warning: Config file '%s.%s' not found. Using defaults/env vars.\n", configName, configType)
} else {
fmt.Fprintf(os.Stdout, "[ConfigLoader] Using config file: %s\n", v.ConfigFileUsed())
}
// 4. 启用环境变量覆盖
v.SetEnvPrefix("SHORTLINK")
v.AutomaticEnv()
v.SetEnvKeyReplacer(strings.NewReplacer(".", "_"))
// 5. Unmarshal到Config结构体
if errUnmarshal := v.Unmarshal(&cfg); errUnmarshal != nil {
return cfg, fmt.Errorf("config: unable to decode all configurations into struct: %w", errUnmarshal)
}
fmt.Fprintf(os.Stdout, "[ConfigLoader] Configuration loaded successfully. AppName: %s\n", cfg.AppName)
return cfg, nil
}
在代码中:
-
我们定义了
Config总结构体,以及嵌套的ServerConfig、StoreConfig、TracingConfig。注意字段上的mapstructure标签,Viper在Unmarshal时会使用它们。 -
LoadConfig函数:-
创建了一个新的
viper.Viper实例(推荐,而不是使用全局的viper.Get())。 -
设置了各种配置项的默认值(这是最低优先级的)。
-
配置了查找路径、文件名和类型。
-
尝试读取配置文件,如果只是文件未找到,则忽略错误,否则返回错误。
-
通过
v.SetEnvPrefix、v.AutomaticEnv、v.SetEnvKeyReplacer启用了环境变量覆盖。环境变量名如SHORTLINK_SERVER_PORT会自动映射到配置路径server.port。 -
最后,调用
v.Unmarshal(&cfg)将所有来源(默认值、文件、环境变量,按优先级合并后)的配置数据填充到Config结构体实例中。
-
创建示例配置文件( shortlink-service/configs/config.yaml)
# shortlink-service/configs/config.yaml
appName: "MyShortLinkServiceFromYAML"
server:
port: "8081" # 覆盖默认的8080
logLevel: "debug" # 覆盖默认的info
logFormat: "text" # 覆盖默认的json,便于本地开发时直接在控制台查看
readTimeout: "10s"
writeTimeout: "15s"
idleTimeout: "180s"
shutdownTimeout: "20s" # 优雅关闭的超时时间
store:
type: "memory" # 明确使用内存存储 (虽然这也是默认值)
# dsn: "postgres://user:pass@host:port/db?sslmode=disable" # 如果用postgres
tracing:
enabled: true # 明确启用追踪
otelEndpoint: "localhost:4317" # OTel Collector的gRPC地址
sampleRatio: 0.8 # 采样80%的追踪
我们在之前 main 函数中调用了LoadConfig函数对来自于 ./configs/config.yaml 配置文件中的核心参数(如应用名、服务器端口、日志级别和格式、各种超时时间、存储类型、追踪设置等)进行了加载,并且其中的任何项都可以通过设置对应的环境变量(例如 SHORTLINK_SERVER_PORT=9000, SHORTLINK_TRACING_OTELENDPOINT="jaeger-agent:4317")来进行覆盖。Viper会自动处理这些优先级和类型转换。
有了灵活的配置管理,下一步就是确保我们的应用能输出高质量的、结构化的日志,以便于监控和问题排查。
集成 log/slog 进行结构化日志
我们在核心组件这节课中详细学习了Go 1.21版本引入的官方结构化日志库 log/slog。它让我们能够方便地记录带有键值对属性的日志,非常适合在云原生环境中被日志收集和分析系统处理。现在,我们将其集成到我们的“短链接服务”中。
在 main 函数中创建引导日志器( cmd/server/main.go)
正如我们在 main.go 的设计中所见,它的职责之一是在应用核心( app.App)创建之前,就基于已加载的配置初始化一个引导日志器(Bootstrap Logger)。这个日志器的主要作用是记录应用启动的极早期阶段,特别是 app.New() 函数的执行过程,以及在 app.New() 失败时能够以结构化的方式输出错误信息。
我们来看一下 cmd/server/main.go 中的 bootstrapLogger 函数和它在 main 函数中的调用:
// cmd/server/main.go (相关部分)
// bootstrapLogger 是一个引导日志器,专门用于应用启动的极早期阶段。
// 它的主要目的是在 `app.New()` 函数执行过程中或失败时,能够以结构化的方式记录日志。
// 它直接从传入的(可能已加载的)配置中获取日志级别和格式,
// 如果配置未加载,则使用安全的默认值。
func bootstrapLogger(cfg *config.Config) *slog.Logger {
var level slog.Level
logLevelStr := "info" // 安全的默认日志级别
logFormatStr := "text" // 默认使用text格式,便于在启动时直接在控制台阅读
// 如果配置文件已成功加载,则使用其中的设置
if cfg != nil {
logLevelStr = cfg.Server.LogLevel
logFormatStr = cfg.Server.LogFormat
}
switch strings.ToLower(logLevelStr) {
case "debug":
level = slog.LevelDebug
case "info":
level = slog.LevelInfo
case "warn":
level = slog.LevelWarn
case "error":
level = slog.LevelError
default:
level = slog.LevelInfo
}
var handler slog.Handler
// 创建一个Handler,配置其日志级别和时间戳格式。
// 注意:AddSource设为false,因为引导日志通常不需要源码位置。
// 日志输出到标准错误流(os.Stderr),这是记录启动过程错误的常见做法。
handlerOpts := &slog.HandlerOptions{AddSource: false, Level: level, ReplaceAttr: func(groups []string, a slog.Attr) slog.Attr {
if a.Key == slog.TimeKey {
a.Value = slog.StringValue(a.Value.Time().Format(time.RFC3339))
}
return a
}}
if strings.ToLower(logFormatStr) == "json" {
handler = slog.NewJSONHandler(os.Stderr, handlerOpts)
} else {
handler = slog.NewTextHandler(os.Stderr, handlerOpts)
}
// 返回一个带有"bootstrap_phase"标识的logger,便于区分这是启动阶段的日志。
return slog.New(handler).With(slog.String("bootstrap_phase", "main"))
}
func main() {
// ... (步骤 1: 加载配置 cfg) ...
// --- 步骤 2: 初始化引导日志器 ---
mainLogger := bootstrapLogger(&cfg)
mainLogger.Info("Configuration loaded, attempting to create application instance...")
// --- 步骤 3: 创建App实例,注入配置和引导日志器 ---
// ...
application, err := app.New(&cfg, mainLogger, appNameFromConfig, defaultAppVersion)
if err != nil {
mainLogger.Error("FATAL: Failed to create application instance", slog.Any("error", err))
os.Exit(1)
}
// ...
}
在代码中:
-
bootstrapLogger函数会根据从config.yaml(或环境变量)中加载的logLevel和logFormat来创建并返回一个*slog.Logger实例。 -
在
main函数中,我们在加载完配置后,立即调用bootstrapLogger创建mainLogger。 -
这个
mainLogger被用于记录后续app.New()的调用过程,并在app.New()失败时记录致命错误。 -
最重要的是,这个
mainLogger实例被作为参数注入到了app.New()函数中,App实例内部将基于这个引导日志器(或者重新创建一个更完善的)来构建其自身的日志能力。
在 App 核心中使用和传递Logger( internal/app/app.go)
app.New() 函数接收到引导日志器后,会将其保存为 App 实例的一个字段,并可能为其添加更多应用级别的上下文(如 component="appcore"),然后将其设置为全局默认logger。
// internal/app/app.go (New函数和App结构体相关部分)
// App 封装了应用的所有依赖...
type App struct {
// ...
logger *slog.Logger // 应用的主日志记录器
// ...
}
// New 创建一个新的App实例...
func New(cfg *config.Config, logger *slog.Logger, appName, version string) (*App, error) {
app := &App{
cfg: cfg,
// 使用传入的引导日志器,并为其添加一个固定的"component"属性
logger: logger.With("component", "appcore"),
appName: appName,
serviceVersion: version,
}
// (可选但推荐) 将App的最终logger设置为全局默认实例。
// 这样,在应用中任何未被显式注入logger的包中,都可以通过 slog.Info() 等函数进行日志记录。
slog.SetDefault(app.logger)
app.logger.Info("Creating new application instance...", /* ... */)
// --- 初始化核心依赖,并将logger注入 ---
// ...
// 2a. 初始化 Store 层
app.store = memory.NewStore(app.logger.With("datastore", "memory"))
app.logger.Info("Initialized in-memory store.")
// 2b. 初始化 Service 层 (注入Store和logger)
app.shortenerSvc = service.NewShortenerService(app.store, app.logger.With("layer", "service"))
app.logger.Info("Shortener service initialized.")
// 2c. 初始化 Handler 层 (注入Service和logger)
linkHdlr := handler.NewLinkHandler(app.shortenerSvc, app.logger.With("layer", "handler"))
app.logger.Info("Link handler initialized.")
// ... (后续的路由注册、中间件应用、服务器创建等)
return app, nil
}
代码说明:
-
app.New函数将传入的logger保存起来,并通过.With("component", "appcore")为其添加了新的上下文,表明后续由app实例直接打印的日志来自appcore组件。 -
依赖注入Logger:在初始化
store、service和handler等组件时,我们将app.logger(同样通过.With(...)为其添加了更具体的组件标识,如"datastore"、"layer")作为参数传递给了它们的构造函数。这确保了应用中的每个核心组件都拥有一个带有自身上下文的、配置统一的日志记录器。 -
设置全局默认Logger:
slog.SetDefault(app.logger)这一步非常关键。它使得在应用的任何地方,如果一个函数不方便(或没必要)通过参数接收logger实例,它依然可以通过调用包级别的slog.Info(...)、slog.Error(...)等函数来记录日志,这些日志会自动使用我们配置好的、带有全局属性的默认logger进行处理。
在业务逻辑中使用结构化日志(以Handler为例)
现在,我们的 LinkHandler 已经通过依赖注入获得了一个配置好的 slog.Logger 实例。它可以(也应该)在处理请求时,进一步为日志添加请求相关的上下文。
// internal/handler/link_handler.go (CreateShortLink方法示例)
func (h *LinkHandler) CreateShortLink(w http.ResponseWriter, r *http.Request) {
ctx := r.Context()
// 从handler持有的基础logger派生出一个与当前请求相关的logger
// 它会自动继承"component":"LinkHandler"等属性
requestLogger := h.logger.With(
slog.String("http_method", r.Method),
slog.String("http_path", r.URL.Path),
// 后续集成Tracing后,这里还可以从ctx中提取并添加TraceID
// slog.String("trace_id", trace.SpanFromContext(ctx).SpanContext().TraceID().String()),
)
// 使用这个requestLogger记录该请求生命周期内的所有日志
requestLogger.DebugContext(ctx, "Handler: Received request to create short link.")
var reqPayload CreateLinkRequest
if err := json.NewDecoder(r.Body).Decode(&reqPayload); err != nil {
requestLogger.ErrorContext(ctx, "Handler: Failed to decode request body.", slog.Any("error", err))
// ... 返回错误响应 ...
return
}
defer r.Body.Close()
requestLogger.InfoContext(ctx, "Handler: Processing create short link request.", slog.String("long_url", reqPayload.LongURL))
shortCode, err := h.svc.CreateShortLink(ctx, reqPayload.LongURL, reqPayload.UserID, reqPayload.OriginalURL, time.Time{})
if err != nil {
requestLogger.ErrorContext(ctx, "Handler: Service failed to create short link.",
slog.Any("error", err),
slog.String("long_url", reqPayload.LongURL),
)
// ... 返回错误响应 ...
return
}
// ... 返回成功响应 ...
requestLogger.InfoContext(ctx, "Handler: Successfully created short link.",
slog.String("short_code", shortCode),
slog.String("long_url", reqPayload.LongURL),
)
}
通过以上步骤,我们成功地将 slog 结构化日志系统深度集成到了我们的“短链接服务”中。现在,当服务运行时,它会根据我们的 config.yaml(或环境变量)的设置,输出格式统一、级别可控、并且富含上下文(全局、组件级、请求级)的日志。这些高质量的日志数据,为我们后续进行问题排查、行为审计和系统监控提供了坚实的基础。
小结
在这一节课中,我们迈出了将“短链接服务”从设计图纸变为实际工程的关键一步。我们一起:
-
搭建了应用的基本骨架(
main.go和internal/app/app.go),包含了清晰的初始化流程规划、手动依赖注入的结构,以及健壮的优雅退出机制。 -
集成了
spf13/viper进行灵活的配置管理,使得应用能够从YAML文件和环境变量中加载和合并配置。 -
引入了Go 1.21+的
log/slog进行结构化日志记录,并学习了如何在Handler和Service中添加丰富的上下文信息。
下一节课,我们将继续讲引入基础可观测性——Metrics和Tracing。
欢迎在留言区分享你的思考和见解!我是Tony Bai,我们下节课再见。
实战串讲(工程篇):“短链接服务”的工程化实践(中)
你好!我是Tony Bai。
上节课,我们有了合理的配置管理和高质量的结构化日志,为应用的稳定运行和可运维性打下了坚实的基础。这节课,我们将开始为应用装上“眼睛”和“耳朵”的另外两个重要部分:Metrics和Tracing,进一步增强其可观测性。
- 引入基础可观测性——Metrics:我们将使用
prometheus/client_golang库,在服务中暴露一些关键的性能指标(如HTTP请求计数和延迟),为后续的监控和告警打下基础。这部分内容关联可观测性这节课中关于Metrics的讲解。 - 引入基础可观测性——Tracing:我们将使用 OpenTelemetry Go SDK,为服务添加基本的分布式链路追踪能力,以便在未来更复杂的架构中追踪请求路径。为简化这两节课的实战环境,我们将使用标准输出(stdout)作为Trace的Exporter,让你能直观地在控制台看到追踪数据,而不必搭建复杂的外部追踪系统。这对应了可观测性这节课中关于Tracing的介绍。
接下来,我们一一来看。
引入基础可观测性——Metrics
配置和日志帮助我们理解应用的静态设置和离散事件,而Metrics(度量/指标)则为我们提供了量化应用宏观运行状态和性能趋势的能力。对于我们的“短链接服务”,我们关心诸如HTTP请求的总量、错误率、处理延迟等关键指标。
我们将使用Go社区的事实标准—— prometheus/client_golang 库,在应用中定义和暴露Prometheus格式的指标。这部分内容呼应了我们在可观测性这节课中关于Metrics的讨论,你也可以先复习相关内容,再继续学习。
使用 prometheus/client_golang 暴露应用指标
定义和注册核心Metrics( internal/metrics/metrics.go)
我们在这里定义一些对HTTP服务通用的基础指标,以及一些与“短链接服务”业务相关的特定指标。
// internal/metrics/metrics.go
package metrics
import (
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/collectors"
"github.com/prometheus/client_golang/prometheus/promauto"
)
// ---- HTTP Server Metrics ----
// HTTPRequestsTotal 是一个CounterVec,用于记录HTTP请求的总数。
// 它按请求方法(method)、请求路径(path)和响应状态码(status_code)进行区分。
var HTTPRequestsTotal = promauto.NewCounterVec(
prometheus.CounterOpts{
Namespace: "shortlink", // 指标的命名空间,有助于组织和避免冲突
Subsystem: "http_server",
Name: "requests_total", // 完整指标名将是 shortlink_http_server_requests_total
Help: "Total number of HTTP requests processed by the shortlink service.",
},
[]string{"method", "path", "status_code"}, // 标签名列表
)
// HTTPRequestDurationSeconds 是一个HistogramVec,用于观察HTTP请求延迟的分布情况。
var HTTPRequestDurationSeconds = promauto.NewHistogramVec(
prometheus.HistogramOpts{
Namespace: "shortlink",
Subsystem: "http_server",
Name: "request_duration_seconds",
Help: "Histogram of HTTP request latencies for the shortlink service.",
Buckets: prometheus.DefBuckets, // prometheus.DefBuckets 是一组预定义的、通用的延迟桶
// 或者,你可以根据你的服务特性自定义桶的边界,例如:
// Buckets: []float64{0.005, 0.01, 0.025, 0.05, 0.1, 0.25, 0.5, 1, 2.5, 5, 10},
},
[]string{"method", "path"}, // 按方法和路径区分
)
// ---- Application Specific Metrics (示例) ----
// ShortLinkCreationsTotal 记录成功创建的短链接总数
var ShortLinkCreationsTotal = promauto.NewCounter(
prometheus.CounterOpts{
Namespace: "shortlink",
Subsystem: "service",
Name: "creations_total",
Help: "Total number of short links successfully created.",
},
)
// ShortLinkRedirectsTotal 记录短链接重定向的总数,按状态(成功/未找到)区分
var ShortLinkRedirectsTotal = promauto.NewCounterVec(
prometheus.CounterOpts{
Namespace: "shortlink",
Subsystem: "service",
Name: "redirects_total",
Help: "Total number of short link redirects, by status.",
},
[]string{"status"}, // "success", "not_found", "error"
)
// Init 初始化并注册所有必要的收集器。
// 这个函数应该在应用启动的早期被调用,例如在main.go中。
func Init() {
// (可选) 注册构建信息指标 (go_build_info)
prometheus.MustRegister(collectors.NewBuildInfoCollector())
// 我们自定义的指标(如HTTPRequestsTotal, ShortLinkCreationsTotal等)
// 因为使用了promauto包,它们在定义时已经自动注册到prometheus.DefaultRegisterer了,
// 所以这里不需要再次显式调用 prometheus.MustRegister() 来注册它们。
// 如果我们没有用promauto,而是用 prometheus.NewCounterVec() 等,则需要在这里注册。
// 例如:
// httpRequestsTotalPlain := prometheus.NewCounterVec(...)
// prometheus.MustRegister(httpRequestsTotalPlain)
}
首先,我们为指标名称添加了 Namespace(shortlink)和 Subsystem(http_server或service),这是Prometheus推荐的命名约定,有助于组织和避免指标名称冲突,最终的指标名会是 namespace_subsystem_name。
然后,我们使用了 promauto 包来创建和自动注册指标到Prometheus的默认注册表( prometheus.DefaultRegisterer)。这简化了代码,避免了忘记调用 prometheus.MustRegister()。
HTTPRequestsTotal 和 HTTPRequestDurationSeconds 是通用的HTTP服务指标。 ShortLinkCreationsTotal 和 ShortLinkRedirectsTotal 是与我们“短链接服务”业务逻辑相关的自定义指标示例。
最后,在 metrics.Init() 函数中,我们显式注册了 NewBuildInfoCollector 返回的Go的构建信息的指标。而 collectors.NewGoCollector() 和 collectors.NewProcessCollector() 无需显式注册,在导入 client_golang 包时,这些Go运行时自身和进程状态的宝贵指标信息(如goroutine数量、GC统计、内存使用、CPU时间、打开的文件描述符等)就会自动注册。
初始化,并在HTTP服务中暴露 /metrics 端点
在服务中使用metrics,我们需要对metrics的设施进行初始化,并暴露一个HTTP端点,通常是 /metrics,Prometheus服务器可以从这个端点抓取(scrape)上述定义的指标数据。
下面是在 internal/app/app.go 中实现上述需求的代码片段:
// internal/app/app.go (New函数的相关部分)
// ... (导入 appMetrics "github.com/your_org/shortlink/internal/metrics") ...
// ... (导入 "github.com/prometheus/client_golang/prometheus/promhttp") ...
// New 创建一个新的App实例,完成所有依赖的初始化和注入
func New(cfg *config.Config, logger *slog.Logger, appName, version string) (*App, error) {
app := &App{
cfg: cfg,
logger: logger.With("component", "appcore"), // App自身也可以有组件标识
appName: appName,
serviceVersion: version,
}
... ...
// 1b. 初始化 Metrics (Prometheus Go运行时等)
appMetrics.Init()
app.logger.Info("Prometheus Go runtime metrics collectors registered.")
... ...
// 3b. 注册诊断路由 (Metrics, pprof)
mux.Handle("/metrics", promhttp.Handler())
... ...
}
在上面的 New 函数中:
-
我们调用了
appMetrics.Init()来确保需要的采集指标等都被注册。 -
在创建
mux后,我们修改了根路径HandleFunc的逻辑,使其能够将对/metrics路径的请求专门交给promhttp.Handler()来处理。promhttp.Handler()会自动从prometheus.DefaultRegisterer中收集所有已注册的指标,并以Prometheus期望的文本格式输出。
在实际项目中,你可能会使用更专业的路由库(如 chi、 gin、 echo),它们通常提供更灵活的方式来注册Handler和中间件。或者,你可以创建两个不同的 http.ServeMux 实例:一个用于业务API(它会被各种中间件包裹),另一个用于内部的诊断API(如 /metrics、 /debug/pprof/,它通常不需要业务中间件)。然后在主 http.Server 中,根据请求的Host或Path前缀,将请求分发到不同的Mux。为了本节课的简洁性,我们暂时将所有路由都放在同一个 mux 上,并通过路径判断来区分。
要真正让 HTTPRequestsTotal 和 HTTPRequestDurationSeconds 这些我们自定义的HTTP指标动起来,我们还需要在处理每个业务层面的HTTP请求时去主动更新它们。在Go中,实现这种对所有(或部分)请求进行通用处理的最佳方式,就是通过HTTP中间件。
编写HTTP中间件记录/更新请求指标
HTTP中间件是一种函数或结构体,它包装了另一个http.Handler,在调用被包装的Handler之前或之后(或两者都)执行一些通用逻辑,例如日志记录、认证鉴权、Metrics收集、Tracing注入/提取等。这种模式也常被称为“装饰器模式”或“洋葱模型”。
我们将创建一个专门的Metrics中间件来实现服务在处理业务请求时对业务指标的更新。我们在internal/middleware/metrics.go中实现这个中间件。下面是代码片段:
// internal/middleware/metrics.go
package middleware
import (
"net/http"
"strconv"
"strings"
"time"
appMetrics "github.com/your_org/shortlink/internal/metrics" // 导入我们定义的metrics包
)
// responseWriter 是 http.ResponseWriter 的一个包装器,
// 主要目的是为了能够捕获到最终写入的HTTP状态码。
// 标准的 http.ResponseWriter 接口没有提供直接获取状态码的方法。
type responseWriter struct {
http.ResponseWriter
statusCode int
}
// newResponseWriter 创建一个新的 responseWriter 实例,
// 默认状态码为 http.StatusOK (200),除非后续被显式调用 WriteHeader 修改。
func newResponseWriter(w http.ResponseWriter) *responseWriter {
return &responseWriter{w, http.StatusOK}
}
// WriteHeader 捕获状态码,并调用原始 ResponseWriter 的 WriteHeader 方法。
func (rw *responseWriter) WriteHeader(code int) {
rw.statusCode = code // 捕获状态码
rw.ResponseWriter.WriteHeader(code)
}
// Metrics 是一个标准的Go HTTP中间件。
// 它接收一个 http.Handler (next),并返回一个新的 http.Handler。
// 这个新的Handler会先执行Metrics记录逻辑,再调用原始的next handler。
func Metrics(next http.Handler) http.Handler {
// 返回一个 http.HandlerFunc,这是一种将普通函数适配为 http.Handler 的便捷方式。
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
path := r.URL.Path
// 跳过对诊断端点自身的指标记录,避免产生不必要的指标数据或潜在的循环。
if path == "/metrics" || strings.HasPrefix(path, "/debug/pprof") {
next.ServeHTTP(w, r) // 直接调用下一个处理器,不记录指标
return
}
startTime := time.Now() // 记录请求处理开始时间
// 创建我们包装的 responseWriter 来替换原始的 w,以便捕获状态码。
rw := newResponseWriter(w)
// 核心:调用链中的下一个处理器 (可能是另一个中间件,或者最终的业务handler)。
// 我们将包装后的 rw 传递下去。
next.ServeHTTP(rw, r)
// 在请求处理完毕后,执行指标更新逻辑
duration := time.Since(startTime).Seconds() // 计算请求总耗时,单位秒
statusCodeStr := strconv.Itoa(rw.statusCode) // 将捕获到的状态码转为字符串
// --- 路径规范化 (重要,但此处简化) ---
// 为了避免标签基数爆炸 (label cardinality explosion),
// 对于包含动态参数(如ID)的路径,我们需要将其规范化为一个模板。
// 例如,/users/123 和 /users/456 都应该被归类为 /users/{id}。
// 专业的路由库 (chi, gin, echo等) 通常能提供匹配到的路由模板。
// 对于标准库的http.ServeMux,我们需要自己实现这个逻辑。
// 为简化本实战示例,我们暂时使用了原始路径,但请务必在实际项目中解决此问题。
// if strings.HasPrefix(path, "/api/items/") { path = "/api/items/{id}" }
// 更新Prometheus指标
// 使用 WithLabelValues 获取带有特定标签组合的指标实例,然后进行操作。
appMetrics.HTTPRequestsTotal.WithLabelValues(r.Method, path, statusCodeStr).Inc()
appMetrics.HTTPRequestDurationSeconds.WithLabelValues(r.Method, path).Observe(duration)
})
}
然后,我们需要将这个中间件应用到HTTP请求处理链中。这个集成步骤通常在internal/app/app.go的New函数中完成,我们在那里构建和配置HTTP服务器。
// internal/app/app.go (New函数的相关部分)
// import "github.com/your_org/shortlink/internal/middleware" // 确保已导入
func New(cfg *config.Config, logger *slog.Logger, appName, version string) (*App, error) {
// ... (之前的初始化代码:可观测性、核心依赖、路由注册等) ...
// --- [App.New - 初始化阶段 4] ---
// 应用HTTP中间件 (顺序可能很重要)
var finalHandler http.Handler = mux // 从已注册好路由的mux开始
// 4a. 应用 Metrics 中间件
// 我们将mux(或其上层中间件处理后的handler)作为 `next` 参数传递给middleware.Metrics,
// 它返回一个新的、包装了Metrics记录逻辑的handler。
finalHandler = middleware.Metrics(finalHandler)
app.logger.Info("Applied HTTP Metrics middleware.")
// ... (后续可能还会应用Tracing和Logging中间件) ...
// --- [App.New - 初始化阶段 5] ---
// 创建并配置最终的HTTP服务器
app.httpServer = &http.Server{
Addr: ":" + app.cfg.Server.Port,
Handler: finalHandler, // 使用经过中间件包装过的最终handler
ReadTimeout: app.cfg.Server.ReadTimeout,
WriteTimeout: app.cfg.Server.WriteTimeout,
IdleTimeout: app.cfg.Server.IdleTimeout,
}
// ...
return app, nil
}
我们来解释下代码和其中的关键点。
-
中间件模式:
Metrics函数遵循了标准的Go HTTP中间件模式func(http.Handler) http.Handler。它接收一个next处理器,并返回一个新的处理器。这个新的处理器在内部执行自己的逻辑(记录开始时间、包装ResponseWriter),然后调用next.ServeHTTP将控制权传递给链中的下一个处理器,最后在next返回后执行自己的收尾逻辑(计算耗时、更新指标)。 -
捕获HTTP状态码:标准的
http.ResponseWriter接口在WriteHeader被调用后,无法再获取到已设置的状态码。为了在请求处理结束后能准确记录状态码,我们创建了一个responseWriter包装器。它内嵌了http.ResponseWriter(继承了其所有方法),但重写了WriteHeader方法,在调用原始的WriteHeader之前,先将状态码保存到自己的statusCode字段中。 -
指标更新逻辑:在
next.ServeHTTP执行完毕后,我们拥有了计算指标所需的所有信息。-
请求方法和路径:从
r.Method和r.URL.Path获取。 -
响应状态码:从我们包装的
rw.statusCode获取。 -
请求耗时:通过
time.Since(startTime)计算。 然后,我们调用之前在internal/metrics包中定义的Prometheus指标对象的.WithLabelValues(...)方法。这个方法会根据传入的标签值(如"GET"、"/api/links"、"201")返回一个具体的、带有一组特定标签的时间序列实例,然后我们再调用.Inc()(对Counter)或.Observe(duration)(对Histogram)来更新它的值。
-
-
中间件的应用:在
app.New()函数中,我们将创建好的mux(它包含了我们所有的业务和诊断路由)作为初始的http.Handler,然后用middleware.Metrics函数对其进行“包裹”,生成一个新的finalHandler。这个finalHandler现在就具备了自动记录请求指标的能力。如果未来还有其他中间件(如日志、追踪),它们会以类似的方式层层包裹。最终,这个被所有中间件包装过的finalHandler被设置为了http.Server的主处理器。
现在,当我们的“短链接服务”运行时,所有经过 finalHandler 的HTTP请求(除了被我们明确跳过的 /metrics 和 /debug/pprof)都会被Metrics中间件自动记录下来,我们可以随时通过访问 /metrics 端点来查看这些实时更新的、带有丰富标签的业务指标。
运行与验证:
-
确保所有代码已保存,并且
app.go中的finalHandler确实应用了middleware.Metrics。 -
在shortlink-service目录下运行
go run ./cmd/server/main.go。 -
发送一些HTTP请求到你的业务端点,例如:
-
curl -X POST -H "Content-Type: application/json" -d '{"long_url":"https://example.com"}' http://localhost:8081/api/links(假设端口是8081) -
curl http://localhost:8081/somecode -
curl http://localhost:8081/anothercode -
curl http://localhost:8081/notfoundpath
-
-
然后,在浏览器或用
curl访问Metrics端点:http://localhost:8081/metrics。 你应该能看到类似以下的输出(部分):
# HELP shortlink_http_request_duration_seconds Histogram of HTTP request latencies for the shortlink service.
# TYPE shortlink_http_request_duration_seconds histogram
shortlink_http_request_duration_seconds_bucket{method="POST",path="/api/links",le="0.005"} 0
shortlink_http_request_duration_seconds_bucket{method="POST",path="/api/links",le="0.01"} 1
...
shortlink_http_request_duration_seconds_sum{method="POST",path="/api/links"} 0.008
shortlink_http_request_duration_seconds_count{method="POST",path="/api/links"} 1
shortlink_http_request_duration_seconds_bucket{method="GET",path="/somecode",le="0.005"} 1
...
shortlink_http_request_duration_seconds_sum{method="GET",path="/somecode"} 0.003
shortlink_http_request_duration_seconds_count{method="GET",path="/somecode"} 1
# HELP shortlink_http_requests_total Total number of HTTP requests processed by the shortlink service.
# TYPE shortlink_http_requests_total counter
shortlink_http_requests_total{method="POST",path="/api/links",status_code="201"} 1
shortlink_http_requests_total{method="GET",path="/somecode",status_code="302"} 1
shortlink_http_requests_total{method="GET",path="/anothercode",status_code="302"} 1
shortlink_http_requests_total{method="GET",path="/notfoundpath",status_code="404"} 1
# HELP go_goroutines Number of goroutines that currently exist.
# TYPE go_goroutines gauge
go_goroutines 7
... (其他Go运行时指标) ...
这表明我们的自定义HTTP指标和Go运行时指标都已成功暴露。Prometheus服务器现在就可以配置来抓取这些数据了。
通过以上步骤,我们为“短链接服务”集成了基础的Metrics能力,使其能够量化关键的HTTP服务质量。这为后续的监控、告警和性能分析打下了坚实的数据基础。
在Metrics为我们提供了宏观状态的“仪表盘”之后,我们还需要一种方法来理解单个请求在系统内部(甚至跨多个服务)的完整“旅行轨迹”和耗时细节,这就是分布式追踪(Tracing)的用武之地。
引入基础可观测性——Tracing
当一个请求在我们的“短链接服务”内部流转,从接收HTTP请求,到调用业务逻辑服务,再到与存储层交互时,我们希望能够清晰地看到这个流程中每一步的耗时和上下文。我们将使用OpenTelemetry(OTel)Go SDK来实现这种应用内的链路追踪。
为了简化本实战串讲的环境搭建,我们将使用OTel的 stdouttrace Exporter,它会将追踪数据以人类可读的格式直接打印到标准输出。 这使得我们无需搭建和配置像Jaeger、Tempo或OpenTelemetry Collector这样的外部追踪后端,就能直观地在控制台看到生成的Trace Span信息。在真实的生产环境中,你会将其替换为OTLP Exporter,将数据发送到专业的追踪系统。
这部分内容呼应了可观测性这节中关于Tracing的详细讨论。
使用OpenTelemetry Go SDK实现基本链路追踪
初始化TracerProvider( internal/tracing/tracer.go)
我们将创建一个函数来配置和创建全局的 TracerProvider。这个Provider是所有追踪活动的源头,负责创建Tracer实例、管理采样策略和将完成的Span数据发送给Exporter。
// internal/tracing/tracer.go
package tracing
import (
"fmt"
"log/slog" // 使用slog记录初始化日志
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/exporters/stdout/stdouttrace"
"go.opentelemetry.io/otel/propagation"
"go.opentelemetry.io/otel/sdk/resource"
sdktrace "go.opentelemetry.io/otel/sdk/trace"
semconv "go.opentelemetry.io/otel/semconv/v1.26.0"
)
// InitTracerProvider initializes an OpenTelemetry TracerProvider with a stdout exporter.
// This is suitable for demos and local development to see traces in the console.
func InitTracerProvider(serviceName, serviceVersion string, enabled bool, sampleRatio float64) (*sdktrace.TracerProvider, error) {
if !enabled {
slog.Info("Distributed tracing is disabled by configuration.", slog.String("service_name", serviceName))
// 如果禁用,返回nil,main函数中将不会设置全局TracerProvider,
// otel.Tracer() 将返回一个NoOpTracer,不会产生实际的trace数据。
return nil, nil
}
slog.Info("Initializing TracerProvider...",
slog.String("service_name", serviceName),
slog.String("exporter_type", "stdout"),
slog.Float64("sample_ratio", sampleRatio),
)
// 1. 创建一个Exporter,这里使用标准输出 (stdouttrace)
// WithPrettyPrint 使控制台输出的trace信息更易读。
exporter, err := stdouttrace.New(stdouttrace.WithPrettyPrint())
if err != nil {
return nil, fmt.Errorf("tracing: failed to create stdout trace exporter: %w", err)
}
slog.Debug("Stdout trace exporter initialized.")
// 2. 定义资源 (Resource),包含服务名、版本等通用属性
// 这些属性会附加到所有由此Provider产生的Span上。
res, err := resource.Merge(
resource.Default(), // 包含默认属性如 telemetry.sdk.language, .name, .version
resource.NewWithAttributes(
semconv.SchemaURL, // OTel语义约定schema URL
semconv.ServiceName(serviceName),
semconv.ServiceVersion(serviceVersion),
// 可以添加更多环境或部署相关的属性,例如:
// attribute.String("deployment.environment", "development"),
),
)
if err != nil {
return nil, fmt.Errorf("tracing: failed to create OTel resource: %w", err)
}
slog.Debug("OTel resource defined.", slog.Any("resource_attributes", res.Attributes()))
// 3. 配置采样器 (Sampler)
var sampler sdktrace.Sampler
if sampleRatio >= 1.0 {
sampler = sdktrace.AlwaysSample() // 采样所有
} else if sampleRatio <= 0.0 {
sampler = sdktrace.NeverSample() // 不采样
} else {
// 根据给定的比例进行采样
sampler = sdktrace.TraceIDRatioBased(sampleRatio)
}
// ParentBased确保如果上游服务(在分布式场景下)已经做出了采样决策,则遵循该决策;
// 如果是根Trace(没有父Span),则使用我们上面配置的本地采样器(sampler)。
finalSampler := sdktrace.ParentBased(sampler)
slog.Debug("OTel sampler configured.", slog.Float64("effective_sample_ratio", sampleRatio))
// 4. 创建TracerProvider,并配置SpanProcessor和Resource
// NewBatchSpanProcessor将span批量异步导出,性能更好,是生产推荐(即使是对stdout exporter)。
// NewSimpleSpanProcessor会同步导出每个span,仅用于非常简单的测试或调试。
bsp := sdktrace.NewBatchSpanProcessor(exporter) // (可选) 配置批处理器参数,例如批处理超时、队列大小等
// sdktrace.WithBatchTimeout(5*time.Second),
// sdktrace.WithMaxQueueSize(2048),
tp := sdktrace.NewTracerProvider(
sdktrace.WithSampler(finalSampler),
sdktrace.WithResource(res),
sdktrace.WithSpanProcessor(bsp), // 注册BatchSpanProcessor
)
slog.Debug("OTel TracerProvider created.")
// 5. 设置为全局TracerProvider和全局TextMapPropagator
// 这使得我们可以在应用的其他地方通过otel.Tracer("instrumentation-name")获取tracer实例,
// 并通过otel.GetTextMapPropagator()进行上下文传播(主要用于分布式场景,但在单体内规范使用也有好处)。
otel.SetTracerProvider(tp)
otel.SetTextMapPropagator(
propagation.NewCompositeTextMapPropagator(
propagation.TraceContext{}, // W3C Trace Context propagator (这是HTTP Headers的标准)
propagation.Baggage{}, // W3C Baggage propagator (可选,用于传递业务数据)
),
)
slog.Info("OpenTelemetry TracerProvider initialized and set globally with stdout exporter.", slog.String("service_name", serviceName))
return tp, nil
}
代码说明:
-
InitTracerProvider函数负责创建和配置一个sdktrace.TracerProvider。 -
Exporter:为了本实战的简单性和快速验证,我们使用了
stdouttrace.New(stdouttrace.WithPrettyPrint())。它会将所有收集到的Trace Span以人类可读的JSON格式直接打印到应用的标准输出。这让我们无需搭建任何外部追踪系统,就能在控制台直观地看到追踪数据。在生产环境中,你会将这个Exporter替换为例如otlptracegrpc.New(),以便将数据通过OTLP协议发送到OpenTelemetry Collector或兼容的后端服务(如Jaeger、Tempo)。 -
Resource:通过
resource.NewWithAttributes,我们为所有从这个Provider产生的Span都附加了一些通用的元数据,如服务名(semconv.ServiceNameKey)和服务版本。使用semconv(Semantic Conventions)中预定义的键名是OpenTelemetry的最佳实践,有助于在不同的可观测性工具间保持数据的一致性。 -
Sampler(采样器):我们配置了采样策略。
TraceIDRatioBased可以按比例采样(例如,只记录50%的请求追踪),而AlwaysSample则会记录所有请求的追踪(这在开发和调试时非常有用)。ParentBased包装器确保我们的服务会遵循上游服务(在分布式场景下)传递过来的采样决策,保持整个Trace的采样一致性。 -
SpanProcessor(Span处理器):我们使用了
sdktrace.NewBatchSpanProcessor。这是一个生产推荐的处理器,它会批量、异步地将已完成的Span发送给Exporter,相比于同步发送每个Span的SimpleSpanProcessor,性能更好,对应用主逻辑的影响更小。 -
全局设置:通过
otel.SetTracerProvider(tp)和otel.SetTextMapPropagator(...),我们将创建好的TracerProvider和上下文传播器(我们使用了标准的W3C Trace Context和Baggage)设置为全局默认实例。这使得我们可以在应用的其他任何地方,通过otel.Tracer("instrumentation-name")方便地获取到一个Tracer实例,并由otelhttp等库自动使用全局的传播器。
在 internal/app/app.go 中初始化并确保关闭TracerProvider
我们需要在应用启动的早期调用 InitTracerProvider,并在应用优雅退出时调用 TracerProvider.Shutdown() 以确保所有缓冲的Span都被正确导出(对于stdout exporter,主要是确保日志被刷出)。和metrics一样,这些工作也都在 internal/app/app.go 的New函数和Run方法中实现:
// internal/app/app.go
func New(cfg *config.Config, logger *slog.Logger, appName, version string) (*App, error) {
... ...
// --- [App.New - 初始化阶段 1] ---
// 初始化可观测性组件 (Tracing & Metrics)
if app.cfg.Tracing.Enabled {
var errInitTracer error
// 1a. 初始化 Tracing (OpenTelemetry)
app.tracerProvider, errInitTracer = appTracing.InitTracerProvider(
app.appName,
app.serviceVersion,
app.cfg.Tracing.Enabled,
app.cfg.Tracing.SampleRatio,
)
if errInitTracer != nil {
app.logger.Error("Failed to initialize TracerProvider", slog.Any("error", errInitTracer))
return nil, fmt.Errorf("app.New: failed to init tracer provider: %w", errInitTracer)
}
}
... ...
// 4b. 应用 Tracing 中间件
if app.tracerProvider != nil {
finalHandler = otelhttp.NewHandler(finalHandler, fmt.Sprintf("%s.http.server", app.appName),
otelhttp.WithMessageEvents(otelhttp.ReadEvents, otelhttp.WriteEvents),
)
app.logger.Info("Applied OpenTelemetry HTTP Tracing middleware.")
}
}
func (a *App) Run() error {
a.logger.Info("Starting application run cycle...",
slog.String("appName", a.appName),
slog.String("version", a.serviceVersion),
)
... ...
if a.tracerProvider != nil {
tpShutdownCtx, tpCancel := context.WithTimeout(context.Background(), 5*time.Second)
defer tpCancel()
a.logger.Info("Attempting to shut down TracerProvider...")
if err := a.tracerProvider.Shutdown(tpShutdownCtx); err != nil {
a.logger.Error("Error shutting down TracerProvider", slog.Any("error", err))
} else {
a.logger.Info("TracerProvider shut down successfully.")
}
}
a.logger.Info("Application has shut down completely.")
return nil // 优雅关闭完成,返回nil
}
关键改动说明:
- 在
app.New()中初始化:-
我们在应用的构造函数
New()中,紧随日志系统初始化之后,调用了appTracing.InitTracerProvider()。这样可以确保在后续所有核心组件(Store, Service, Handler等)初始化之前,追踪系统已经就绪。 -
根据配置文件中的
tracing.enabled标志,我们决定是否真正启用追踪。如果禁用,tracerProvider字段将保持为nil。
-
- 在
app.Run()中优雅关闭:-
在
Run()方法的优雅退出逻辑中,我们在关闭HTTP服务器之后,明确地调用了a.tracerProvider.Shutdown(tpShutdownCtx)。 -
这是至关重要的一步! 因为我们使用了
BatchSpanProcessor,它会在内存中缓冲Span。调用Shutdown()会强制处理器将所有缓冲的Span导出。如果忘记调用Shutdown,在应用快速退出时可能会丢失最近产生的追踪数据。我们还为这个关闭操作设置了一个独立的短超时(5秒)。
-
- 应用
otelhttp中间件:-
在
New()函数配置HTTP处理链时,我们加入了go.opentelemetry.io/contrib/instrumentation/net/http/otelhttp包提供的otelhttp.NewHandler中间件。 -
这个中间件会自动为每个进入的HTTP请求:
-
尝试从入站请求头中提取Trace Context(如果上游服务传递了追踪信息)。
-
如果不存在入站Trace Context,则开始一个新的Trace。
-
创建一个代表整个HTTP请求处理过程的根Span(Server Span)。
-
将这个Span的信息注入到
request.Context()中。 -
在请求处理结束时,自动结束这个Span,并记录HTTP相关的标准属性(如状态码、方法、路径等)。
-
-
通过使用这个中间件,我们极大地简化了对HTTP请求入口的追踪插桩工作。
-
在Service层或更深层逻辑中手动创建子Span
上面的 otelhttp.NewHandler 中间件为我们处理了HTTP请求的入口Span/根Span。但要获得更深入的洞察,我们需要在应用内部的关键逻辑单元(如Service层的方法)中手动创建子Span(Child Spans),以形成更详细的调用链。例如 ShortenerService 中的方法调用了 Store 层的方法,或者执行了一些其他有意义的独立操作单元,我们应该在这些地方手动创建子Span(Child Spans),以获得更细致的追踪信息和耗时分解。下面以shortener_service.go中的处理逻辑为例,看看如何手工创建子Span:
// internal/service/shortener_service.go
package service
type shortenerServiceImpl struct {
store store.Store // 存储接口的依赖
logger *slog.Logger // 日志记录器
tracer trace.Tracer // OpenTelemetry Tracer,用于手动创建子Span
}
// NewShortenerService 创建一个新的ShortenerService实例
func NewShortenerService(s store.Store, logger *slog.Logger) ShortenerService {
return &shortenerServiceImpl{
store: s,
logger: logger,
// 获取一个Tracer实例。Tracer的名称通常使用其所属的库或模块的导入路径。
tracer: otel.Tracer("github.com/your_org/shortlink/internal/service"),
}
}
// generateSecureRandomCode 生成一个指定长度的、URL安全的随机字符串作为短码
func (s *shortenerServiceImpl) generateSecureRandomCode(ctx context.Context, length int) (string, error) {
// 为这个内部操作创建一个子Span
_, span := s.tracer.Start(ctx, "service.generateSecureRandomCode")
defer span.End()
randomBytes := make([]byte, length)
if _, err := rand.Read(randomBytes); err != nil {
s.logger.ErrorContext(ctx, "Failed to read random bytes for short code generation", slog.Any("error", err))
span.RecordError(err)
span.SetStatus(codes.Error, "rand.Read failed")
return "", fmt.Errorf("service: failed to generate random bytes: %w", err)
}
// 使用URLEncoding可以避免/和+字符,使其更适合用在URL路径中
// 并取其前length个字符
shortCode := base64.URLEncoding.EncodeToString(randomBytes)
shortCode = strings.ReplaceAll(shortCode, "_", "A") // 替换下划线
shortCode = strings.ReplaceAll(shortCode, "-", "B") // 替换连字符
if len(shortCode) < length { // 理论上不太可能,除非length非常小
err := fmt.Errorf("generated base64 string too short")
span.RecordError(err)
span.SetStatus(codes.Error, "base64 string too short")
return "", err
}
finalCode := shortCode[:length]
span.SetAttributes(attribute.String("generated_code", finalCode))
return finalCode, nil
}
// CreateShortLink 为给定的长URL创建一个短链接
func (s *shortenerServiceImpl) CreateShortLink(ctx context.Context, longURL string, userID string, originalURL string, expireAt time.Time) (string, error) {
// 1. 从传入的ctx启动一个新的子Span,用于追踪这个方法的执行
ctx, span := s.tracer.Start(ctx, "ShortenerService.CreateShortLink", trace.WithAttributes(
attribute.String("long_url", longURL),
attribute.String("user_id", userID),
attribute.String("original_url", originalURL),
))
defer span.End() // 确保Span在函数退出时被结束
s.logger.DebugContext(ctx, "Service: Attempting to create short link.",
slog.String("longURL", longURL), slog.String("userID", userID))
// 校验输入
if strings.TrimSpace(longURL) == "" {
err := errors.New("long URL cannot be empty")
span.RecordError(err)
span.SetStatus(codes.Error, err.Error())
s.logger.WarnContext(ctx, "Validation failed for CreateShortLink: long URL empty")
return "", err
}
// (可以添加更多对longURL格式的校验)
// 如果originalURL为空,则使用longURL
if originalURL == "" {
originalURL = longURL
}
// 如果expireAt是零值,设置一个默认的过期时间
if expireAt.IsZero() {
expireAt = time.Now().Add(time.Hour * defaultExpiryHours)
span.SetAttributes(attribute.String("default_expiry_applied", expireAt.Format(time.RFC3339)))
}
span.SetAttributes(attribute.String("expire_at", expireAt.Format(time.RFC3339)))
var shortCode string
var err error
for attempt := 0; attempt < maxGenerationAttempts; attempt++ {
// 为生成和检查短码的每次尝试创建一个更细粒度的子Span
attemptCtx, attemptSpan := s.tracer.Start(ctx, fmt.Sprintf("ShortenerService.CreateShortLink.Attempt%d", attempt+1))
shortCode, err = s.generateSecureRandomCode(attemptCtx, defaultCodeLength) // 使用内部方法
if err != nil {
// 这个错误通常是内部生成随机串失败,比较严重,直接返回
s.logger.ErrorContext(attemptCtx, "Service: Failed to generate random string for short code.", slog.Any("error", err))
attemptSpan.RecordError(err)
attemptSpan.SetStatus(codes.Error, "short code internal generation failed")
attemptSpan.End()
span.RecordError(err) // 在父Span也记录这个严重错误
span.SetStatus(codes.Error, "short code internal generation failed")
return "", fmt.Errorf("service: internal error generating short code: %w", err)
}
attemptSpan.SetAttributes(attribute.String("generated_code_attempt", shortCode))
s.logger.DebugContext(attemptCtx, "Service: Generated short code attempt.", slog.String("short_code", shortCode))
// 检查短码是否已存在 (这个store调用也应该被追踪)
// 我们将在Store的实现中添加Tracing (如果需要更细粒度)
// 这里,我们假设FindByShortCode是Store接口的一部分
existingEntry, findErr := s.store.FindByShortCode(attemptCtx, shortCode) // 将attemptCtx传递下去
if errors.Is(findErr, store.ErrNotFound) {
s.logger.InfoContext(attemptCtx, "Service: Generated short code is unique.", slog.String("short_code", shortCode))
entryToSave := &store.LinkEntry{
ShortCode: shortCode,
LongURL: longURL,
OriginalURL: originalURL,
UserID: userID,
CreatedAt: time.Now(), // 在Service层设置创建时间
ExpireAt: expireAt,
}
saveErr := s.store.Save(attemptCtx, entryToSave)
if saveErr == nil {
s.logger.InfoContext(ctx, "Service: Successfully created and saved short link.",
slog.String("short_code", shortCode),
slog.String("long_url", longURL),
)
span.SetAttributes(attribute.String("final_short_code", shortCode))
span.SetStatus(codes.Ok, "short link created")
attemptSpan.SetStatus(codes.Ok, "short code unique and saved")
attemptSpan.End()
return shortCode, nil
}
s.logger.WarnContext(attemptCtx, "Service: Failed to save unique short code, retrying if possible.",
slog.String("short_code", shortCode), slog.Any("save_error", saveErr))
err = saveErr
attemptSpan.RecordError(saveErr)
attemptSpan.SetStatus(codes.Error, "failed to save short code")
} else if findErr != nil {
s.logger.ErrorContext(attemptCtx, "Service: Store error checking short code existence.",
slog.String("short_code", shortCode), slog.Any("find_error", findErr))
err = findErr
attemptSpan.RecordError(findErr)
attemptSpan.SetStatus(codes.Error, "store error checking short code")
} else {
// findErr is nil and existingEntry is not nil, means shortCode already exists
s.logger.DebugContext(attemptCtx, "Service: Short code collision.", slog.String("short_code", shortCode), slog.String("existing_long_url", existingEntry.LongURL))
err = fmt.Errorf("short code %s collision (attempt %d)", shortCode, attempt+1)
attemptSpan.SetAttributes(attribute.Bool("collision", true))
attemptSpan.SetStatus(codes.Error, "short code collision")
}
attemptSpan.End()
// 如果是存储错误(而不是未找到或冲突),则不应继续重试
if !errors.Is(findErr, store.ErrNotFound) && findErr != nil {
span.RecordError(err) // 将store错误记录到父span
span.SetStatus(codes.Error, "failed due to store error during creation")
return "", fmt.Errorf("service: failed to create short link after store error: %w", err)
}
}
// 如果循环结束仍未成功 (通常是多次冲突)
finalErr := ErrIDGenerationFailed
s.logger.ErrorContext(ctx, "Service: Failed to generate a unique short code after multiple attempts.",
slog.Int("max_attempts", maxGenerationAttempts),
)
span.RecordError(finalErr)
span.SetStatus(codes.Error, finalErr.Error())
return "", finalErr
}
// GetOriginalURL 根据短码查找原始长链接
func (s *shortenerServiceImpl) GetOriginalURL(ctx context.Context, shortCode string) (*store.LinkEntry, error) {
ctx, span := s.tracer.Start(ctx, "ShortenerService.GetOriginalURL", trace.WithAttributes(
attribute.String("short_code", shortCode),
))
defer span.End()
s.logger.InfoContext(ctx, "Service: Attempting to retrieve original URL for short code.", slog.String("short_code", shortCode))
if strings.TrimSpace(shortCode) == "" {
err := errors.New("short code cannot be empty")
span.RecordError(err)
span.SetStatus(codes.Error, err.Error())
s.logger.WarnContext(ctx, "Validation failed for GetOriginalURL: short code empty")
return nil, err
}
entry, err := s.store.FindByShortCode(ctx, shortCode)
if err != nil {
s.logger.WarnContext(ctx, "Service: Failed to find original URL for short code.",
slog.String("short_code", shortCode),
slog.Any("error", err), // 这个err可能是store.ErrNotFound或者其他DB错误
)
span.RecordError(err)
if errors.Is(err, store.ErrNotFound) {
span.SetStatus(codes.Error, "short code not found") // 更具体的错误状态
} else {
span.SetStatus(codes.Error, "store error retrieving short code")
}
return nil, err
}
// 检查是否过期
if !entry.ExpireAt.IsZero() && time.Now().After(entry.ExpireAt) {
s.logger.InfoContext(ctx, "Service: Short code found but has expired.",
slog.String("short_code", shortCode),
slog.Time("expire_at", entry.ExpireAt),
)
// (可选) 在这里可以从存储中删除过期的条目 (异步或同步)
// s.store.Delete(ctx, shortCode)
span.SetAttributes(attribute.Bool("expired", true))
span.SetStatus(codes.Error, "short code expired")
return nil, store.ErrNotFound // 对外表现为未找到
}
s.logger.InfoContext(ctx, "Service: Successfully retrieved original URL.",
slog.String("short_code", shortCode),
slog.String("original_url", entry.OriginalURL), // 假设LinkEntry有OriginalURL
)
span.SetAttributes(attribute.String("retrieved_original_url", entry.OriginalURL))
span.SetStatus(codes.Ok, "original URL retrieved")
// 可以在这里异步增加访问计数 (如果Store.IncrementVisitCount是异步安全的,或者用另一个goroutine)
// go s.store.IncrementVisitCount(context.Background(), shortCode) // 简单示例,实际要考虑错误处理
// 或者,如果IncrementVisitCount是快速的,也可以同步调用
// visitCtx, visitSpan := s.tracer.Start(ctx, "ShortenerService.IncrementVisitCount")
// if errVisit := s.store.IncrementVisitCount(visitCtx, shortCode); errVisit != nil {
// s.logger.ErrorContext(visitCtx, "Failed to increment visit count", slog.String("short_code", shortCode), slog.Any("error", errVisit))
// visitSpan.RecordError(errVisit)
// visitSpan.SetStatus(codes.Error, "failed to increment visit count")
// }
// visitSpan.End()
return entry, nil
}
代码说明:
-
获取Tracer实例:在
NewShortenerService构造函数中,我们通过otel.Tracer("...")获取了一个专属于service包的Tracer实例。Tracer的名称通常使用其所属的库或模块的导入路径,这是一个好习惯,有助于在追踪后端区分Span的来源。 -
创建子Span:在
CreateShortLink和GetOriginalURL这两个核心业务方法的开始,我们都调用了s.tracer.Start(ctx, "span-operation-name", ...)。-
关键:我们将从上层(Handler层,经由
otelhttp中间件)传递过来的context.Context作为第一个参数传入。 OTel SDK会自动检测到这个ctx中已存在的父Span(由otelhttp创建),并使新创建的Span成为其子Span,从而将它们链接到同一个Trace中。 -
Start方法会返回一个新的、嵌入了新创建的子Span信息的context.Context,以及trace.Span对象本身。 后续在这个方法内部的所有操作,特别是调用其他需要被追踪的函数(如s.store的方法), 都应该使用这个新的ctx,以确保追踪上下文能够正确地向下传播。
-
-
确保Span结束(
defer span.End()):这是手动创建Span时最容易忘记但又至关重要的一步。defer span.End()确保了无论函数是正常返回还是因panic退出,Span都会被标记为结束,其结束时间和持续时长才会被正确记录。 -
丰富Span内容:
-
属性(Attributes):我们使用
span.SetAttributes(...)为Span添加了有意义的业务或技术上下文,例如输入的longURL、生成的shortCode、userID等。这些属性在后续的Trace查询和分析中非常有用。 -
事件(Events):虽然本示例中没有直接使用,但你可以通过
span.AddEvent("event-name", ...)在Span的生命周期内记录一些离散的、有时间戳的事件(例如,“Cache Hit”或“Retrying…”)。 -
错误与状态(Errors & Status):当操作发生错误时,我们使用
span.RecordError(err)来记录具体的错误信息,并使用span.SetStatus(codes.Error, err.Error())将Span的状态明确标记为错误。对于成功的操作,用span.SetStatus(codes.Ok, ...)标记。这在追踪后端的可视化界面中通常会以不同的颜色或图标醒目地展示出来。
-
-
细粒度追踪:在
CreateShortLink的重试循环中,我们甚至为每一次生成和检查短码的尝试创建了更细粒度的子Span(ShortenerService.CreateShortLink.AttemptN),并在其中模拟了对Store层方法的调用(也创建了模拟的Store Span)。这使得我们在分析Trace时,能够清晰地看到重试的次数、每次尝试生成的代码,以及每次模拟的数据库查询耗时,对于诊断复杂的重试逻辑或性能问题非常有帮助。
运行与观察(单体应用,输出到stdout):
-
确保你的
main.go中已经正确初始化了TracerProvider(使用stdouttraceExporter)并应用了otelhttp.NewHandler中间件。 -
确保
shortener_service.go中的NewShortenerService和其方法已按上述方式插桩。 -
运行
go run ./cmd/server/main.go。 -
通过浏览器或
curl访问你的API端点,例如:-
curl -X POST -H "Content-Type: application/json" -d '{"long_url":"https://example.com/very/long/url"}' http://localhost:8081/api/links(假设端口是8081) -
然后用返回的shortCode访问
http://localhost:8081/{shortCode}
-
-
观察控制台的输出。你应该能看到类似这样的(经过美化的)Trace Span信息被打印出来:
{
"Name": "shortlink.http.server.requests", // 来自otelhttp中间件的根Span (或你指定的名字)
"SpanContext": { ... "TraceID": "TRACE_ID_A", "SpanID": "SPAN_ID_ROOT", ... },
"Parent": {}, ...
}
{
"Name": "ShortenerService.CreateShortLink", // service层的子Span
"SpanContext": { ... "TraceID": "TRACE_ID_A", "SpanID": "SPAN_ID_SERVICE_CREATE", ... },
"Parent": {"TraceID": "TRACE_ID_A", "SpanID": "SPAN_ID_ROOT", ...}, ...
}
{
"Name": "ShortenerService.CreateShortLink.Attempt1", // 更深层子Span
"SpanContext": { ... "TraceID": "TRACE_ID_A", "SpanID": "SPAN_ID_ATTEMPT_1", ... },
"Parent": {"TraceID": "TRACE_ID_A", "SpanID": "SPAN_ID_SERVICE_CREATE", ...}, ...
}
{
"Name": "Store.FindByShortCode", // 模拟的store层span
"SpanContext": { ... "TraceID": "TRACE_ID_A", "SpanID": "SPAN_ID_STORE_FIND", ... },
"Parent": {"TraceID": "TRACE_ID_A", "SpanID": "SPAN_ID_ATTEMPT_1", ...}, ...
}
// ...
你会看到一个Trace(由相同的 TraceID 标识)包含了多个Span,它们之间通过 Parent.SpanID 形成了调用树,清晰地展示了请求从HTTP入口到Service层(包括内部重试和模拟的Store调用)的执行路径和耗时。
通过集成OpenTelemetry并进行适当的手动/自动插桩,我们就为“短链接服务”(即使是单体)赋予了基础的链路追踪能力。虽然本节课我们只用了 stdout 输出,但在生产环境中,只需将 InitTracerProvider 中的Exporter替换为指向Jaeger、Tempo或OTel Collector的Exporter,就能将这些宝贵的追踪数据发送到专业的后端系统进行分析和可视化了。
小结
这一节课,我们在上节课的基础上,继续完善“短链接服务”从设计图纸到实际工程的过程,引入了基础可观测性—— Metrics和Tracing。
-
使用
prometheus/client_golang为应用暴露了基础的Metrics指标(HTTP请求计数和延迟),并通过HTTP中间件进行了自动收集。 -
利用
OpenTelemetry Go SDK实现了基础的链路追踪,通过otelhttp中间件自动追踪了HTTP服务器请求,并在Service层演示了如何手动创建和管理子Span,最后通过标准输出Exporter直观地展示了追踪数据。
通过这两节课讲的所有步骤,我们的服务已经不再是简单的业务逻辑堆砌,而是开始具备了现代Go应用应有的工程化基础和初步但关键的可观测性能力。它能够灵活配置,输出结构化、带上下文的日志,暴露核心性能指标,并能追踪请求在其内部主要组件间的流转路径和耗时。
下一节课,我们将聚焦于进一步提升这个“短链接服务”的质量和可维护性,将它打磨得更加完善和专业,并为最终的部署做好准备。
思考题
在我们的“短链接服务”实战中,我们努力地通过依赖注入,将一个统一配置的、带有服务上下文的 slog.Logger 实例传递给了各个核心组件(如Store、Service、Handler)。
然而,请你仔细观察一下 internal/tracing/tracer.go 中的 InitTracerProvider 函数。你会发现,它在初始化过程中打印日志时,并没有使用我们精心构建的应用级 logger 实例,而是可能直接使用了 log/slog 的默认行为(或者一个在函数内部创建的临时logger)。这会导致这部分的启动日志可能缺少我们期望的全局上下文(如 service_name),或者其格式/级别与应用其他部分的日志不完全一致。
请你动手实践一下,如何重构代码,使得 InitTracerProvider 函数也能够使用我们从 main 函数开始创建和传递的应用级日志记录器?
完成这个小重构,你将更深刻地体会到在整个应用中保持依赖注入和日志记录一致性的重要性,这是构建清晰、可维护的Go应用的一个关键细节。欢迎在留言区分享你的修改思路或代码片段!
欢迎在留言区分享你的思考和见解!我是Tony Bai,我们下节课再见。
实战串讲(工程篇):“短链接服务”的工程化实践(下)
你好!我是Tony Bai。欢迎回到我们“短链接服务”的工程化实践之旅。
在上两节课中,我们已经为“短链接服务”成功搭建了坚实的应用骨架,集成了灵活的配置管理(使用 viper)、强大的结构化日志系统(使用 log/slog),并引入了基础的可观测性能力——通过 prometheus/client_golang 暴露了关键的Metrics指标,以及通过 OpenTelemetry Go SDK(配合标准输出Exporter)实现了初步的分布式链路追踪。可以说,我们的服务已经具备了初步的“内省”能力,能够告诉我们它“正在做什么”以及“感觉怎么样”。
然而,一个能够自信地上线、在复杂的生产环境中稳定运行,并且易于长期维护和迭代的Go应用,还需要在更多方面进行加固。 虽然我们的服务现在能跑起来,并且有了一定的可观测性,但距离一个真正“生产就绪”的状态,还缺少了几个关键的质量保障、诊断能力和交付准备环节。
这节课,作为工程篇的下篇,我们将补齐这些至关重要的环节,继续完善我们的“短链接服务”,使其更接近生产标准。具体来说,我们将重点关注以下几个方面:
-
测试实践:我们将为服务的核心逻辑编写单元测试(包括如何Mock依赖),为API端点编写集成测试,并学习如何查看和理解测试覆盖率。这部分内容将直接应用我们在测试进阶这节课中学到的知识。
-
诊断准备:我们将在HTTP服务中集成Go语言强大的
pprof工具,为其开启运行时性能剖析和故障排查的“后门”。这呼应了故障诊断这节课中关于pprof的深入讨论。 -
静态代码分析:我们将引入并配置
golangci-lint这一主流的Linter聚合器,以在编码阶段就发现潜在的Bug、不规范的写法和风格问题,从而保障代码的整体质量和一致性。这对应了静态代码分析这节课的内容。 -
容器化部署准备:最后,我们将为“短链接服务”编写一个优化的
Dockerfile,将其打包成轻量、可移植的容器镜像,为后续在Docker Compose(开发环境)或Kubernetes(生产环境)中的部署做好准备。这关联到部署与升级这节课中关于容器化的实践。
学完这节课后,我们的“短链接服务”将具备更高的代码质量、更强的诊断能力,以及标准化的交付产物,使其在健壮性、可维护性和部署便捷性上都迈上一个新的台阶。
好了,话不多说,让我们开始这最后的“精装修”工作吧!
测试实践:单元测试、集成测试与覆盖率
测试是软件质量的生命线。没有经过充分测试的代码,就像在没有安全网的情况下走钢丝,风险极高。对于我们的“短链接服务”,我们需要至少覆盖单元测试和集成测试两个层面,以确保其各个部分的功能正确性以及它们组合在一起时的协同工作能力。
为核心业务逻辑编写单元测试
单元测试针对的是我们系统中最小的可测试单元,通常是单个函数或一个类型的方法。 在进行单元测试时,一个核心原则是隔离被测单元,即将其依赖的外部组件(如数据库、其他服务,甚至文件系统或时间)替换为受控的测试替身(如Stubs、Fakes或Mocks)。
我们将以 internal/service/shortener_service.go 中的核心业务逻辑——特别是短码的生成和确保其唯一性的过程——作为单元测试的示例对象。回顾一下,我们的 ShortenerService 依赖一个 store.Store 接口来与数据存储层交互。 更进一步, CreateShortLink 方法内部还有一个关键的依赖:短码的生成逻辑。 这个生成逻辑通常带有随机性,这在单元测试中是不可接受的,因为它会导致测试结果不可预测。
为了解决这个问题,我们将遵循依赖注入的设计原则,不会让 ShortenerService 直接在内部实现随机ID的生成,而是将其抽象为一个 IDGenerator 接口,并在创建 ShortenerService 实例时,将这个生成器的具体实现注入进去。在生产代码中,我们会注入一个真正产生随机ID的实现;而在测试代码中,我们则可以注入一个完全受控的Mock实现,让它返回我们预设好的ID,从而使测试变得确定和可预测。
定义 Store 和 IDGenerator 接口的Mock实现
我们使用 stretchr/testify/mock 库来方便地创建Mock对象。首先,在 internal/service/shortener_service_test.go 中定义 MockStore 和我们新增的 MockIDGenerator。
// internal/service/shortener_service_test.go
package service
import (
"context"
"errors"
"fmt"
"io"
"log/slog"
"os"
"testing"
"time"
// 导入真实的Store接口定义和错误
"github.com/your_org/shortlink/internal/store"
// 使用testify进行Mock和断言
"github.com/stretchr/testify/assert"
"github.com/stretchr/testify/mock"
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/trace"
)
// MockStore 是 store.Store 接口的一个Mock实现。
// 它内嵌了mock.Mock,用于记录方法调用和返回预设值。
type MockStore struct {
mock.Mock
}
// Save 为Store接口的Save方法实现Mock。
func (m *MockStore) Save(ctx context.Context, entry *store.LinkEntry) error {
args := m.Called(ctx, entry)
return args.Error(0)
}
// FindByShortCode 为Store接口的FindByShortCode方法实现Mock。
func (m *MockStore) FindByShortCode(ctx context.Context, shortCode string) (*store.LinkEntry, error) {
args := m.Called(ctx, shortCode)
// Get(0)获取第一个返回值,并尝试类型断言。
entry, _ := args.Get(0).(*store.LinkEntry)
return entry, args.Error(1)
}
// 为其他Store接口方法提供满足接口的Mock实现。
func (m *MockStore) FindByOriginalURLAndUserID(ctx context.Context, originalURL, userID string) (*store.LinkEntry, error) {
// 在这个测试中不使用,返回nil即可。
args := m.Called(ctx, originalURL, userID)
entry, _ := args.Get(0).(*store.LinkEntry)
return entry, args.Error(1)
}
func (m *MockStore) IncrementVisitCount(ctx context.Context, shortCode string) error {
return m.Called(ctx, shortCode).Error(0)
}
func (m *MockStore) GetVisitCount(ctx context.Context, shortCode string) (int64, error) {
args := m.Called(ctx, shortCode)
val, _ := args.Get(0).(int64)
return val, args.Error(1)
}
func (m *MockStore) Close() error { return m.Called().Error(0) }
// MockIDGenerator 是我们为IDGenerator接口创建的Mock实现。
type MockIDGenerator struct {
mock.Mock
}
// Generate 为IDGenerator接口的Generate方法实现Mock。
func (m *MockIDGenerator) Generate(ctx context.Context, length int) (string, error) {
args := m.Called(ctx, length)
return args.String(0), args.Error(1)
}
// getTestLogger 返回一个用于测试的、不输出任何内容的slog.Logger。
func getTestLogger() *slog.Logger {
return slog.New(slog.NewTextHandler(io.Discard, nil))
}
接下来解释下代码。
-
我们为
store.Store接口创建了MockStore,并为其中关键的Save和FindByShortCode方法实现了Mock逻辑。 -
同样,我们为新增的
IDGenerator接口创建了MockIDGenerator,并为其Generate方法实现了Mock。 -
在每个Mock方法中,我们都调用了
m.Called(...)来告诉testify/mock框架这个方法被以哪些参数调用了,然后通过args.String(0)、args.Error(1)等来返回我们将在测试用例中预先设置好的期望返回值。
编写针对 CreateShortLink 的单元测试(使用表驱动)
现在,我们可以使用 MockStore 和 MockIDGenerator 来测试 shortenerServiceImpl 的 CreateShortLink 方法。我们将使用表驱动测试来组织多个测试场景。
注意:以下测试代码是假设你已经按照“依赖注入ID生成器”的思路重构了 shortener_service.go*,\* 即 shortenerServiceImpl 结构体包含了 idGenerator IDGenerator 字段,并且 NewShortenerService 接收 IDGenerator 作为参数。
// internal/service/shortener_service_test.go (续)
func TestShortenerServiceImpl_CreateShortLink(t *testing.T) {
logger := getTestLogger()
// 为测试设置一个NoOp TracerProvider,这样service中的otel.Tracer()调用不会panic。
otel.SetTracerProvider(trace.NewNoopTracerProvider())
// 定义表驱动测试的用例结构体。
testCases := []struct {
name string
longURL string
userID string
mockStoreSetup func(mockStore *MockStore) // 用于设置Mock Store的行为。
mockIdGenSetup func(mockIdGen *MockIDGenerator) // 用于设置Mock ID生成器的行为。
expectedShortCode string
expectError bool
expectedErrorType error
}{
{
name: "SuccessfulCreation_FirstAttempt",
longURL: "https://example.com/a-very-long-url",
userID: "user-123",
mockStoreSetup: func(mockStore *MockStore) {
// 期望FindByShortCode被调用一次,参数是"abcdefg",并返回ErrNotFound。
mockStore.On("FindByShortCode", mock.Anything, "abcdefg").Return(nil, store.ErrNotFound).Once()
// 期望Save被调用一次,参数是一个*store.LinkEntry,并返回nil (无错误)。
// 使用mock.MatchedBy进行更灵活的参数匹配,检查entry的关键字段。
mockStore.On("Save", mock.Anything, mock.MatchedBy(func(e *store.LinkEntry) bool {
return e.ShortCode == "abcdefg" && e.LongURL == "https://example.com/a-very-long-url"
})).Return(nil).Once()
},
mockIdGenSetup: func(mockIdGen *MockIDGenerator) {
// 期望ID生成器的Generate方法被调用一次,并返回"abcdefg"。
mockIdGen.On("Generate", mock.Anything, defaultCodeLength).Return("abcdefg", nil).Once()
},
expectedShortCode: "abcdefg",
expectError: false,
},
{
name: "Collision_RetryOnce_ThenSuccess",
longURL: "https://another-example.com",
userID: "user-456",
mockStoreSetup: func(mockStore *MockStore) {
// 第一次FindByShortCode,模拟冲突。
mockStore.On("FindByShortCode", mock.Anything, "collide").Return(&store.LinkEntry{}, nil).Once()
// 第二次FindByShortCode,模拟成功。
mockStore.On("FindByShortCode", mock.Anything, "unique1").Return(nil, store.ErrNotFound).Once()
// 随后的Save应该成功。
mockStore.On("Save", mock.Anything, mock.MatchedBy(func(e *store.LinkEntry) bool { return e.ShortCode == "unique1" })).Return(nil).Once()
},
mockIdGenSetup: func(mockIdGen *MockIDGenerator) {
// 期望Generate被调用两次,并按顺序返回不同的值。
mockIdGen.On("Generate", mock.Anything, defaultCodeLength).Return("collide", nil).Once()
mockIdGen.On("Generate", mock.Anything, defaultCodeLength).Return("unique1", nil).Once()
},
expectedShortCode: "unique1",
expectError: false,
},
{
name: "AllAttemptsCollide_Fails",
longURL: "https://collision.com",
userID: "user-789",
mockStoreSetup: func(mockStore *MockStore) {
// 期望FindByShortCode被调用maxGenerationAttempts次,每次都返回已存在。
mockStore.On("FindByShortCode", mock.Anything, mock.AnythingOfType("string")).Return(&store.LinkEntry{}, nil).Times(maxGenerationAttempts)
},
mockIdGenSetup: func(mockIdGen *MockIDGenerator) {
// 期望Generate也被调用maxGenerationAttempts次。
mockIdGen.On("Generate", mock.Anything, defaultCodeLength).Return("any-colliding-code", nil).Times(maxGenerationAttempts)
},
expectError: true,
expectedErrorType: ErrIDGenerationFailed,
},
// 可以添加更多测试用例,如Store.Save失败、输入校验失败等。
}
for _, tc := range testCases {
currentTC := tc // 捕获range变量。
t.Run(currentTC.name, func(t *testing.T) {
// t.Parallel() // 如果测试用例之间完全独立,可以并行。
// 1. 创建Mock实例
mockStore := new(MockStore)
mockIdGen := new(MockIDGenerator)
// 2. 设置Mock期望
currentTC.mockStoreSetup(mockStore)
currentTC.mockIdGenSetup(mockIdGen)
// 3. 创建被测Service实例,并注入Mock依赖
serviceImpl := NewShortenerService(mockStore, logger, mockIdGen)
// 4. 执行被测方法
// 注意:CreateShortLink的完整签名可能需要更多参数,这里简化调用。
shortCode, err := serviceImpl.CreateShortLink(context.Background(), currentTC.longURL, currentTC.userID, "", time.Time{})
// 5. 断言结果
if currentTC.expectError {
assert.Error(t, err, "Expected an error for test case: %s", currentTC.name)
if currentTC.expectedErrorType != nil {
assert.ErrorIs(t, err, currentTC.expectedErrorType, "Error type mismatch for test case: %s", currentTC.name)
}
} else {
assert.NoError(t, err, "Did not expect an error for test case: %s", currentTC.name)
}
if !currentTC.expectError && currentTC.expectedShortCode != "" {
assert.Equal(t, currentTC.expectedShortCode, shortCode, "Short code mismatch for test case: %s", currentTC.name)
}
// 6. 验证所有Mock期望都已满足
mockStore.AssertExpectations(t)
mockIdGen.AssertExpectations(t)
})
}
}
代码说明与关键点:
-
依赖注入
IDGenerator:通过将ID生成逻辑抽象为接口并注入,我们彻底解决了测试中随机性带来的不可预测问题。这是编写可测试代码的关键一步。 -
表驱动测试(
testCases):我们定义了一个测试用例表,每个用例包含了输入、用于设置Mock行为的mockSetup函数,以及期望的结果。这种方式使得添加新的测试场景(例如,测试Store.Save失败的情况)变得非常简单,只需在表中增加一个新的结构体实例即可。 -
Mock行为设置(
mockStore.On、mockIdGen.On):在每个测试用例的mockSetup函数中,我们使用testify/mock的On方法来精确地声明期望哪个方法被调用、以什么参数被调用、返回什么结果,以及被调用几次。-
参数匹配:我们可以使用
mock.Anything、mock.AnythingOfType进行模糊参数匹配,也可以使用mock.MatchedBy提供一个自定义函数来对复杂参数(如*store.LinkEntry)进行更精细的校验。 -
调用次数:
.Once()表示期望被调用一次,.Times(n)表示期望被调用n次。
-
-
验证Mock期望(
AssertExpectations):在每个子测试的最后,调用mockStore.AssertExpectations(t)和mockIdGen.AssertExpectations(t)至关重要。它会检查所有通过On设置的期望是否都已在测试执行过程中被满足。如果有任何一个期望未被满足(例如,一个期望被调用的方法没有被调用,或者调用次数不对),测试将失败。 -
隔离性:通过在
t.Run的闭包内部创建新的MockStore和MockIDGenerator实例,我们确保了每个测试用例都有自己独立的、干净的Mock环境,避免了测试间的相互干扰。
单元测试的核心在于 隔离被测单元的逻辑并精确控制其依赖的行为。通过依赖注入、 testify/mock 和表驱动测试的结合,我们可以为 ShortenerService 的核心功能编写出覆盖多种成功和失败场景的、高度可维护的单元测试。
仅仅有单元测试是不够的,我们还需要更高层级的测试来确保各个组件能够正确地协同工作。
为API端点编写集成测试
集成测试用于验证我们应用中多个组件(例如,HTTP Handler层、Service层,以及一个真实但可能是简化的Store层实现)在一起协同工作时的正确性。对于Web服务,最常见的集成测试就是针对其API端点进行的。
我们将使用标准库的 net/http/httptest 包来模拟HTTP客户端请求和捕获服务器响应,并使用我们已经引入的内存存储实现( internal/store/memory.NewStore)作为集成测试的后端存储,这样测试就不依赖外部数据库,运行速度快且环境易于搭建。
创建 internal/handler/link_handler_integration_test.go
注意,集成测试通常放在被测包的外部包,例如 package handler_test,以进行黑盒测试,但如果需要访问包内未导出的辅助函数进行setup,也可以放在同包下但用 _integration_test.go 后缀区分。这里我们采用 package handler_test 的方式。
// internal/handler/link_handler_integration_test.go
package handler_test // 使用 _test 包名,表示从包外部进行测试 (黑盒)
import (
"bytes" // 引入context
"encoding/json"
"io" // 用于 slog 的 io.Discard
"log/slog"
"net/http"
"net/http/httptest"
"strings"
"testing"
// 用于 context.WithTimeout
// 导入被测试的包和依赖 (路径根据你的go.mod)
"github.com/your_org/shortlink/internal/handler" // 我们的handler
"github.com/your_org/shortlink/internal/service" // 我们的service
"github.com/your_org/shortlink/internal/store/memory" // 使用内存存储
// "github.com/your_org/shortlink/internal/store" // 如果需要 store.ErrNotFound
"github.com/stretchr/testify/assert"
"github.com/stretchr/testify/require"
"go.opentelemetry.io/otel" // 为了service能获取tracer
)
// setupIntegrationTestServer 创建一个包含真实(内存)依赖的测试服务器。
// 返回一个 http.Handler,可以直接用于 httptest.Server 或直接调用其 ServeHTTP。
func setupIntegrationTestServer(t *testing.T) http.Handler {
// 1. 创建 Logger (在测试中,我们可能不关心日志输出,使用Discard Handler)
testLogger := slog.New(slog.NewTextHandler(io.Discard, nil)) // 忽略所有日志输出
// 2. 创建真实的内存 Store 实例
memStore := memory.NewStore(testLogger.With("component", "memory_store_integ_test"))
// t.Cleanup(func() { memStore.Close() }) // 如果 memStore 需要清理
// 3. 创建真实的 Service 实例,注入内存 Store 和 Logger
// 假设NewShortenerService现在也接收一个tracer,但对于集成测试,我们可以用NoopTracer
// otel.SetTracerProvider(trace.NewNoopTracerProvider()) // 确保有一个Provider
// tracer := otel.Tracer("integ-test-tracer")
// shortenerSvc := service.NewShortenerService(memStore, testLogger.With("component", "service_integ_test"), tracer)
// For simplicity, let's assume our existing NewShortenerService in service.go can be used.
// If it strictly requires a global tracer to be set, TestMain or a test setup func should do it.
// For this test, we'll re-use the NewShortenerService from service package.
// Make sure the NewShortenerService in `service` package is compatible.
// It expects (store.Store, *slog.Logger). The tracer is acquired via otel.Tracer() internally.
// Ensure a global tracer provider is set for the service to pick up a tracer,
// even if it's a NoOp one for tests not focusing on tracing.
// (This would ideally be in a TestMain or a setup helper for all integration tests)
// For now, we ensure it's callable.
if otel.GetTracerProvider() == nil {
// In a real setup, you might initialize a NoOp tracer provider here for tests
// or ensure your InitTracerProvider from tracing package is test-friendly.
// For this example, we'll assume the service's otel.Tracer() call will get a NoOp if none is set.
}
shortenerSvc := service.NewShortenerService(memStore, testLogger.With("component", "service_integ_test"), nil)
// 4. 创建真实的 Handler 实例,注入 Service 和 Logger
linkHdlr := handler.NewLinkHandler(shortenerSvc, testLogger.With("component", "handler_integ_test"))
// 5. 创建一个 HTTP Mux 并注册路由 (与app.go中类似,但更简化)
mux := http.NewServeMux()
mux.HandleFunc("POST /api/links", linkHdlr.CreateShortLink) // 路径与app.go中一致
// 模拟 /{shortCode} 的重定向路由
mux.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
if r.Method == http.MethodGet && len(r.URL.Path) > 1 && !strings.HasPrefix(r.URL.Path, "/api/") {
shortCode := strings.TrimPrefix(r.URL.Path, "/")
linkHdlr.RedirectShortLink(w, r, shortCode) // 调用 RedirectShortLink
} else {
http.NotFound(w, r)
}
})
return mux
}
func TestIntegration_CreateAndRedirectLink(t *testing.T) {
// 1. 设置测试服务器
testServerHandler := setupIntegrationTestServer(t)
// 定义测试场景的输入
longURL := "https://www.example.com/a-very-long-url-for-integration-testing"
createPayload := handler.CreateLinkRequest{LongURL: longURL} // 使用handler中定义的结构体
payloadBytes, err := json.Marshal(createPayload)
require.NoError(t, err, "Failed to marshal create link request payload")
// --- 步骤1: 创建短链接 ---
reqCreate := httptest.NewRequest(http.MethodPost, "/api/links", bytes.NewReader(payloadBytes))
reqCreate.Header.Set("Content-Type", "application/json")
rrCreate := httptest.NewRecorder() // httptest.ResponseRecorder 用于捕获响应
testServerHandler.ServeHTTP(rrCreate, reqCreate) //直接调用Handler的ServeHTTP
// 断言创建请求的响应
require.Equal(t, http.StatusCreated, rrCreate.Code, "CreateLink: Unexpected status code")
var createResp handler.CreateLinkResponse // 使用handler中定义的结构体
err = json.Unmarshal(rrCreate.Body.Bytes(), &createResp)
require.NoError(t, err, "CreateLink: Failed to unmarshal response body")
require.NotEmpty(t, createResp.ShortCode, "CreateLink: Short code in response should not be empty")
shortCodeGenerated := createResp.ShortCode
t.Logf("CreateLink: Successfully created short code '%s' for URL '%s'", shortCodeGenerated, longURL)
// --- 步骤2: 使用生成的短链接进行重定向 ---
// 这里我们直接访问 /{shortCode} 路径
redirectPath := "/" + shortCodeGenerated
reqRedirect := httptest.NewRequest(http.MethodGet, redirectPath, nil)
// 为了能正确获取 Location header,我们需要一个能处理重定向的客户端,
// 或者检查 ResponseRecorder 的 Header。httptest.Recorder 不会自动跟随重定向。
rrRedirect := httptest.NewRecorder()
testServerHandler.ServeHTTP(rrRedirect, reqRedirect)
// 断言重定向请求的响应
// 对于短链接服务,我们通常期望301 (永久)或302 (临时/找到)重定向
// 在我们的 RedirectShortLink handler 中,我们使用了 http.StatusFound (302)
assert.Equal(t, http.StatusFound, rrRedirect.Code, "RedirectShortLink: Unexpected status code")
// 检查 Location 响应头是否指向原始的长链接
redirectLocation := rrRedirect.Header().Get("Location")
assert.Equal(t, longURL, redirectLocation, "RedirectShortLink: Redirect Location mismatch")
t.Logf("RedirectShortLink: Successfully redirected from '%s' to '%s'", redirectPath, redirectLocation)
// --- (可选) 步骤3: 尝试获取一个不存在的短链接 ---
reqNotFound := httptest.NewRequest(http.MethodGet, "/nonexistentcode", nil)
rrNotFound := httptest.NewRecorder()
testServerHandler.ServeHTTP(rrNotFound, reqNotFound)
assert.Equal(t, http.StatusNotFound, rrNotFound.Code, "GetNonExistentLink: Expected HTTP 404 Not Found")
t.Logf("GetNonExistentLink: Correctly received 404 for '/nonexistentcode'")
}
// 可以添加更多集成测试用例,例如:
// - 测试无效输入 (如创建时long_url为空)
// - 测试并发创建 (如果store支持并发)
// - 测试短码大小写不敏感 (如果业务逻辑如此定义)
// - 等等
func TestIntegration_CreateLink_InvalidInput(t *testing.T) {
testServerHandler := setupIntegrationTestServer(t)
t.Run("EmptyLongURL", func(t *testing.T) {
createPayload := handler.CreateLinkRequest{LongURL: ""}
payloadBytes, _ := json.Marshal(createPayload)
reqCreate := httptest.NewRequest(http.MethodPost, "/api/links", bytes.NewReader(payloadBytes))
reqCreate.Header.Set("Content-Type", "application/json")
rrCreate := httptest.NewRecorder()
testServerHandler.ServeHTTP(rrCreate, reqCreate)
assert.Equal(t, http.StatusBadRequest, rrCreate.Code, "Expected 400 Bad Request for empty long_url")
})
// 可以添加其他无效输入的测试用例
}
代码说明与关键点:
-
package handler_test:将集成测试放在一个以_test为后缀的包名中,表明这是对handler包的黑盒测试。这意味着测试代码不能访问handler包内未导出的成员,只能通过其公开的API(即HTTP端点)进行交互。 -
setupIntegrationTestServer辅助函数:这个函数负责创建和组装集成测试所需的所有组件实例(内存Store、Service、Handler、HTTP Mux)。这样做可以避免在每个测试用例中重复这些设置代码。我们传入了*testing.T,这样可以在setup过程中使用t.Helper()或t.Cleanup()。 -
真实的依赖(内存版):我们使用了
memory.NewStore()来创建一个真实的,但在内存中运行的存储实现。这使得测试不依赖外部数据库,运行快速且环境隔离。Service层和Handler层也都是真实的实例。 -
net/http/httptest包:-
httptest.NewRequest(...):用于构造一个模拟的*http.Request对象。 -
httptest.NewRecorder():创建一个*httptest.ResponseRecorder,它实现了http.ResponseWriter接口,并会捕获所有写入到它的数据(状态码、头部、响应体),方便我们后续进行断言。 -
testServerHandler.ServeHTTP(rr, req):我们不启动一个真实的HTTP服务器监听端口,而是直接调用我们Mux(或Handler)的ServeHTTP方法,将模拟的请求和响应记录器传入。这使得测试执行非常快速。
-
-
测试流程:
TestIntegration_CreateAndRedirectLink覆盖了一个完整的用户场景,也就是先调用创建短链接的API,从响应中获取生成的短码,然后再用这个短码去调用重定向的API,并验证重定向是否指向了原始的长链接。 -
断言:同样使用了
testify/assert和testify/require进行断言,检查HTTP状态码、响应体内容及Location响应头等。
集成测试通过模拟真实的用户请求,验证了我们系统中多个组件(从HTTP Handler到Service再到Store)能否正确地协同工作,完成端到端的业务流程。
完成了单元测试和集成测试的编写后,我们自然会关心:我们的测试到底覆盖了多少代码?
运行测试与查看覆盖率
Go语言内置了强大的代码覆盖率分析工具,它可以帮助我们了解在运行测试时,被测源代码中有多大比例的代码行(或语句)至少被执行过一次。
1. 运行测试并生成覆盖率数据。 在项目根目录(或任何你想计算覆盖率的包目录下)运行:
# 运行当前包及其子包的所有测试,并计算覆盖率,结果打印到控制台
go test ./... -cover
# 运行所有测试,并将覆盖率数据输出到 coverage.out 文件
go test ./... -coverprofile=coverage.out
# 如果你只想针对特定包,例如service包:
# go test github.com/your_org/shortlink/internal/service -coverprofile=service_coverage.out
-cover 标志会在测试执行完毕后,在控制台输出每个被测试包的覆盖率百分比。 -coverprofile=filename 标志则会将详细的覆盖率数据(每个语句是否被覆盖)写入到指定的文件中。
2. 查看可视化的覆盖率报告。 一旦有了 coverage.out 这样的覆盖率数据文件,我们可以使用 go tool cover 命令将其转换为更易读的可视化报告:
go tool cover -html=coverage.out -o coverage.html
这条命令会生成一个名为 coverage.html 的HTML文件。用浏览器打开它,你会看到一个按包组织的源代码列表,点击文件名可以进入源码视图。在源码视图中:
-
绿色高亮 的行表示该行代码在测试中至少被执行过一次。
-
红色高亮 的行表示该行代码在测试中从未被执行过。
-
灰色 的行通常是声明、注释或不可执行的代码。通过这个可视化的报告,我们可以清晰地看到哪些代码路径缺乏测试覆盖,从而有针对性地补充测试用例。
关于测试覆盖率的思考:
-
覆盖率是一个有用的指标,但不是银弹。 高覆盖率(例如80-90%以上)通常是代码质量的一个积极信号,它表明大部分代码逻辑都经过了测试的“洗礼”。低覆盖率则明确地提示测试不充分。
-
不要盲目追求100%的覆盖率。 某些代码(如极其简单的getter/setter、无法在单元测试中轻易触发的极端错误处理或某些标准库调用的封装)可能不值得花费巨大精力去达到100%覆盖,其投入产出比较低。
-
覆盖率衡量的是“执行过”,而非“验证过”。 一行代码被覆盖,不代表它的所有逻辑分支、边界条件或并发场景都被正确地验证了。测试用例的质量(断言是否充分、场景是否全面)比单纯的覆盖率数字更重要。
-
将覆盖率作为发现测试盲点的工具。 当看到未覆盖的代码时,应思考:是测试用例设计遗漏了某个场景,还是这部分代码确实难以通过单元测试覆盖(可能需要集成测试或端到端测试),或者它甚至是“死代码”?
通过编写单元测试和集成测试,并关注测试覆盖率,我们为“短链接服务”的质量提供了第一道坚实的保障。
测试保证了我们代码在已知场景下的行为符合预期。但当服务在线上运行时,我们还需要有能力洞察其内部状态,以便在出现性能问题或未知故障时进行诊断。
诊断准备:开启 pprof 端点
在故障诊断和性能调优这两节课中,我们深入学习了Go语言强大的性能剖析和运行时诊断工具—— pprof。为了能够在需要时对我们的“短链接服务”进行性能分析(如CPU、内存瓶颈)和故障排查(如goroutine泄漏),我们必须在服务启动时就集成并暴露 pprof 的HTTP端点。这就像为我们的应用安装了一个永久的“诊断接口”,是生产级服务不可或缺的一部分。
在HTTP服务中集成 pprof
Go标准库的 net/http/pprof 包使得在HTTP服务中集成 pprof 变得异常简单。在我们的“短链接服务”中,我们采用了最快捷且常用的方式来实现这一点。
我们来回顾下集成代码。在 cmd/server/main.go 中,我们通过匿名导入(blank import)的方式引入了 pprof 包:
// cmd/server/main.go (import区域)
import (
// ... 其他import语句 ...
_ "net/http/pprof" // 关键:匿名导入pprof包,自动注册handlers到http.DefaultServeMux
)
这个匿名导入会在其包的 init() 函数中,将所有 pprof 相关的HTTP Handler自动注册到Go标准库的 http.DefaultServeMux 上。
接着,在 internal/app/app.go 的 New() 函数中,我们创建HTTP路由时,确保了对 /debug/pprof/ 路径的请求能够被正确处理:
// internal/app/app.go (New函数中注册路由部分)
// ...
// --- [App.New - 初始化阶段 3] ---
// 创建HTTP Router并注册所有路由
mux := http.NewServeMux()
// ... (注册业务路由和/metrics路由) ...
// 将对 /debug/pprof/ 路径及其子路径的请求,
// 直接代理给已经注册了pprof handlers的http.DefaultServeMux。
// 这是一个简洁而有效的集成方式,当你的应用使用自定义mux时。
mux.HandleFunc("/debug/pprof/", http.DefaultServeMux.ServeHTTP)
// (在较新版本中,pprof.Index等也能直接用,但代理DefaultServeMux更通用)
// mux.HandleFunc("/debug/pprof/", pprof.Index)
// mux.HandleFunc("/debug/pprof/cmdline", pprof.Cmdline)
// ...
app.logger.Info("Diagnostic routes (/metrics, /debug/pprof/) registered.")
// ...
通过这两步,我们的“短链接服务”在启动后,就会在其监听的HTTP端口上,自动暴露出一整套 pprof 诊断端点。
验证 pprof 端点
一旦服务启动,验证 pprof 端点是否正常工作就非常简单。 首先,启动服务。 在项目根目录下运行我们的“短链接服务”:
go run ./cmd/server/main.go
接着访问 pprof 首页。 打开浏览器,访问 http://localhost:<你的服务端口>/debug/pprof/。根据我们 configs/config.yaml 中的配置,端口是 8081,所以访问地址是 http://localhost:8081/debug/pprof/。
-
如果页面成功加载,并显示出一个列出了多种可用profile(如
allocs、block、goroutine、heap、mutex、profile等)的链接列表,那就说明pprof已经成功集成并正在运行。 -
获取一个Profile示例(验证功能),你可以在终端尝试获取一个heap profile,以进一步确认功能可用:
bash go tool pprof http://localhost:8081/debug/pprof/heap。如果命令成功执行并进入了pprof的交互式命令行界面(提示符为(pprof)),则表明我们的服务已经完全具备了通过pprof进行运行时诊断的能力。你可以输入top或web等命令来初步探索。
通过这简单几步,我们就为“短链接服务”安装了强大的“诊断接口”。当未来遇到性能瓶颈或复杂的运行时问题时,这些 pprof 端点将是我们进行深度分析和定位问题的宝贵工具。
有了测试保障代码逻辑的正确性,有了 pprof 作为运行时诊断的后盾,我们还需要在代码提交前就尽可能发现潜在的问题,这就是静态代码分析的用武之地。
静态代码分析:使用 golangci-lint 保障代码质量
静态代码分析是一种在不实际执行代码的情况下,通过分析源代码来检测潜在错误、代码风格问题、不规范写法以及性能隐患等的技术。它是保障代码质量、提升代码可维护性和团队协作效率的重要手段。在静态代码分析这节课中,我们学习了多种Go语言的静态分析工具,其中 golangci-lint 作为一个集大成的Linter聚合器,因其易用性、可配置性和广泛的检查能力而备受推崇。
引入 golangci-lint 的价值
-
早期发现问题:在代码合并到主分支之前,甚至在开发者本地提交之前,就能发现许多潜在的问题。
-
自动化代码审查:它可以自动化许多原本需要在代码审查(Code Review)中由人工指出的风格、规范和简单错误问题,让审查者能更专注于业务逻辑和架构设计。
-
提升代码一致性:通过强制执行统一的编码风格和规范,使得整个项目的代码库更易读、更易维护。
-
集成多种Linter:
golangci-lint集成了大量优秀的社区linter(如go vet、staticcheck、errcheck、unused、gofmt、goimports、misspell、gosec等),你无需单独安装和配置它们,只需通过一个配置文件就能统一管理和运行。
为项目配置 .golangci.yml
golangci-lint 的行为主要通过项目根目录下的一个名为 .golangci.yml(或 .golangci.yaml、 .golangci.json、 .golangci.toml)的配置文件来控制。
安装 golangci-lint
如果你还没有安装,可以参考其官方GitHub仓库的安装指南: https://golangci-lint.run/welcome/install/。通常可以使用 go install 或下载预编译的二进制文件。
# 例如,使用go install
go install github.com/golangci/golangci-lint/cmd/golangci-lint@latest
创建 .golangci.yml 配置文件
golangci-lint 的行为主要通过项目根目录下的一个名为 .golangci.yml(或 .golangci.yaml 等)的配置文件来控制。随着 golangci-lint 的版本迭代,其配置格式也在演进。 我们这里采用的是 v2 版本的配置格式,它结构更清晰,将linter和formatter的设置分别归类。
下面是一个推荐的、基于v2格式的、精简但实用的 .golangci.yml 配置示例:
# .golangci.yml (v2版本配置)
# 配置文件格式版本,v1.54.0+ 推荐使用 v2
version: "2"
# run: # (可选) v2版本中,run下的配置(如timeout, skip-dirs)被移到更具体的位置或有默认值
# timeout: 5m
# skip-dirs: # v2中,目录排除通常在 linters.exclusions 或 formatters.exclusions 中定义
# - vendor/
# Linters section: 配置所有linter的行为
linters:
# 启用特定的linter列表
enable:
- bodyclose
- dogsled
- dupl
- goconst
- gocritic
- gocyclo
- misspell
- nakedret
- predeclared
- revive
- staticcheck
- unconvert
- unparam
- whitespace
# 注意:govet, errcheck, unused 通常被staticcheck包含或有更好的替代,
# 但如果需要它们的特定行为,也可以显式启用。
# 这里的列表是一个示例,你可以根据团队规范调整。
# 禁用特定的linter(即使它们可能被某个预设或 `enable-all` 启用)
disable:
- funlen # 检查函数长度
- godot # 检查注释结尾的标点
- lll # 检查行长度
- testpackage # 检查测试包命名
# settings: 为特定linter提供详细参数配置
settings:
errcheck:
check-type-assertions: true
check-blank: true # 也检查 _ = myFunc() 中的错误
gocyclo:
min-complexity: 15 # 函数圈复杂度阈值
gosec:
# 配置安全扫描器的规则
excludes:
- G101 # 排除潜在的硬编码凭证检查 (需谨慎)
- G307 # 排除对 defer rows.Close() 的不安全警告 (如果确认代码正确)
misspell:
locale: US
staticcheck:
# 'all' 是一个简写,代表启用所有推荐的 staticcheck 检查器
checks: ["all"]
# exclusions: 定义linter的排除规则
exclusions:
# `lax` (宽松) 或 `strict` (严格) 模式来处理自动生成的代码。
# `lax` 会跳过对已知生成器(如 Mocker, Stringer)生成的代码的检查。
generated: lax
# 排除特定路径下的所有linter检查
paths:
- "third_party$" # 以 third_party 结尾的目录
- "builtin$"
- "examples$"
# - "internal/mocks/.*" # 也可以用正则表达式排除mocks目录
# issues: 控制问题的报告方式
issues:
# 每个linter报告的最大问题数量 (0表示无限制)
max-issues-per-linter: 0
# 相同问题的最大报告数量 (0表示无限制)
max-same-issues: 0
# formatters section: 配置所有代码格式化工具的行为
formatters:
# 启用特定的格式化工具
enable:
- gofmt
- goimports
# 格式化工具的排除规则 (与linters的类似)
exclusions:
generated: lax
paths:
- "third_party$"
- "builtin$"
- "examples$"
配置说明:
-
version: "2":这是v2配置格式的明确声明,对于v1.54.0+版本的golangci-lint是必需的。 -
linterssection:这是v2配置的核心变化之一,所有与linter相关的配置都被整合到了这个顶层键下。-
enable/disable:用于启用或禁用linter。这里的策略是“明确启用”,即只运行enable列表中指定的linter。这是一种推荐的做法,可以让你从一个可控的、有价值的linter集合开始,而不是被大量默认启用的linter淹没。 -
settings:原v1配置中的linters-settings现在被移到了linters.settings下。它用于为启用的linter提供详细的参数配置。例如,我们为gocyclo设置了圈复杂度阈值,为gosec排除了某些规则的检查。 -
exclusions:v2版本新增了更结构化的排除规则。你可以方便地配置对自动生成的代码(generated: lax)进行宽松检查,并可以按路径(paths)或文本内容(text)等排除特定文件或目录的linter检查。
-
-
formatterssection:这是v2配置的另一个核心变化,将代码格式化工具(如gofmt、goimports)的配置与linter分离开来,这使得它们的配置更清晰。formatters下同样有enable和exclusions等子配置项。 -
issuessection:这部分与v1版本类似,用于控制问题的报告方式,例如限制每个linter或每个相同问题的报告数量。
有了一个可用的 .golangci.yml 后,我们就可以运行golangci-lint对我们的shortlink-service进行静态检查了!
运行 golangci-lint 并解读结果
配置好 .golangci.yml 后,就可以在项目根目录下运行静态分析了:
# 运行所有启用的linter,检查当前目录及其所有子包
golangci-lint run ./...
# 如果想让它尝试自动修复一些简单问题 (如格式化、import排序、部分拼写错误等)
# 注意:--fix 选项需要谨慎使用,务必在版本控制下进行,并审查其修改。
# golangci-lint run ./... --fix
golangci-lint 会扫描你的代码,并输出所有发现的问题:
$golangci-lint run ./...
internal/config/config.go:78:14: Error return value of `fmt.Fprintf` is not checked (errcheck)
fmt.Fprintf(os.Stdout, "[ConfigLoader] Using config file: %s\n", v.ConfigFileUsed())
^
internal/config/config.go:91:13: Error return value of `fmt.Fprintf` is not checked (errcheck)
fmt.Fprintf(os.Stdout, "[ConfigLoader] Configuration loaded successfully. AppName: %s\n", cfg.AppName)
^
... ...
internal/service/shortener_service_test.go:77:25: SA1019: trace.NewNoopTracerProvider is deprecated: Use [go.opentelemetry.io/otel/trace/noop.NewTracerProvider] instead. (staticcheck)
otel.SetTracerProvider(trace.NewNoopTracerProvider())
^
internal/service/shortener_service.go:93:32: func (*shortenerServiceImpl).generateSecureRandomCode is unused (unused)
func (s *shortenerServiceImpl) generateSecureRandomCode(ctx context.Context, length int) (string, error) {
^
32 issues:
* errcheck: 7
* gocritic: 4
* revive: 19
* staticcheck: 1
* unused: 1
如何处理报告:
-
逐条分析:对于每个报告的问题,仔细阅读其信息和规则ID,理解它为何被认为是问题。
-
修复代码:如果确实是问题,修改代码以符合linter的建议。
-
配置调整:如果某个linter的规则过于严苛或不适用于你的项目,可以在
.golangci.yml中调整其参数或禁用该特定规则。 -
合理忽略(Nolint):对于某些确实无法避免或不值得修改,但会被linter报告的特殊情况,可以使用行内注释
//nolint:lintername1,lintername2 // reason来忽略特定行的特定linter告警。但应尽量少用,并给出充分理由。
接着我们来看集成到开发流程。 为了最大化静态分析的效果,应将其融入日常开发流程。
- 本地开发环境:
-
IDE集成:许多主流IDE(如GoLand、VS Code的Go插件)都支持集成
golangci-lint,可以在你保存文件时自动运行检查并提示问题。 -
Git Pre-commit Hook:设置一个Git提交前的钩子,在每次
git commit时自动运行golangci-lint,如果检查不通过则阻止提交。这能确保进入版本库的代码至少通过了静态分析。可以使用如pre-commit框架( https://pre-commit.com/)来方便地管理这类钩子。
-
- CI/CD流水线:在持续集成(CI)服务器上(如Jenkins、GitLab CI、GitHub Actions),将
golangci-lint作为一个强制的代码质量检查步骤。在代码合并到主分支(如main或master)之前,或者在构建发布版本之前,必须通过静态分析检查。
通过有效地使用 golangci-lint 并将其集成到开发流程中,我们可以显著提升“短链接服务”的代码质量、可读性和可维护性,并在早期阶段就捕获大量潜在问题。
在我们对代码质量进行了静态层面的保障之后,最后一步就是准备将我们的应用打包成标准化的交付物,以便在各种环境中轻松部署。
容器化部署准备:编写Dockerfile
我们已经在部署与升级这节课中详细学习了Go应用的容器化最佳实践。现在,我们将为“短链接服务”编写一个生产级的 Dockerfile,目标是构建一个体积小、安全性高、启动快速的容器镜像。
为Go应用编写优化的Dockerfile
我们将采用多阶段构建(multi-stage build)的策略,这是Go镜像优化的核心。
-
构建阶段(builder stage):使用一个包含完整Go编译环境的镜像(如
golang:1.21-alpine)来编译我们的应用。我们将进行静态链接,并剥离调试信息,以获得最小的二进制产物。 -
运行阶段(final stage):使用一个极小的基础镜像(如
scratch或alpine,或者Google的distroless/static)作为最终的运行时环境,只从构建阶段拷贝编译好的二进制文件和任何绝对必要的运行时依赖(例如,CA证书,如果应用需要发起HTTPS调用)。
在项目根目录( shortlink-service/)创建 Dockerfile:
# Dockerfile
# --- Build Stage (builder) ---
# 使用一个包含Go编译环境的官方Alpine镜像作为构建基础,它体积较小。
# 请确保这里的Go版本与你项目go.mod中指定的版本或你本地开发使用的版本一致或兼容。
FROM golang:1.21.7-alpine3.19 AS builder
# (或者你可以用一个更精确的 patch 版本,如 golang:1.21.5-alpine)
# 设置Go环境变量,确保模块模式开启,并为静态链接做准备
ENV CGO_ENABLED=0 GOOS=linux GOARCH=amd64
# (GOARCH可以根据你的目标部署平台调整,amd64是常见的)
# 设置工作目录
WORKDIR /build
# 优化依赖下载:先拷贝go.mod和go.sum,运行go mod download。
# 这样,如果这两个文件没有变化,Docker可以利用缓存,跳过重新下载依赖。
COPY go.mod go.sum ./
RUN go mod download && go mod verify
# 拷贝项目的其他所有源代码到工作目录
COPY . .
# 编译Go应用。
# 我们将编译 cmd/server/main.go 作为我们服务的主入口。
# -ldflags="-w -s":
# -w: 省略DWARF调试信息。
# -s: 省略符号表。
# 这两个标志可以显著减小最终二进制文件的大小。
# -o /app/shortlink-server: 指定编译输出的二进制文件名为shortlink-server,并放在/app目录下。
# (注意:/app目录是在这个builder阶段创建的,与最终运行阶段的WORKDIR可以不同)
RUN go build -ldflags="-w -s" -o /app/shortlink-server ./cmd/server/main.go
# --- Runtime Stage (final) ---
# 使用一个极小的基础镜像。
# scratch 是一个完全空的镜像,如果你的二进制是完全静态链接且无任何外部文件依赖,这是最佳选择。
FROM scratch
# 或者,如果你的应用需要一些基础的系统工具或CA证书,可以使用alpine:
# FROM alpine:latest
# RUN apk --no-cache add ca-certificates tzdata # 添加CA证书和时区数据
# 或者使用Google的distroless镜像,它只包含运行时依赖,安全性更高:
# FROM gcr.io/distroless/static:nonroot # 用于静态链接的Go应用,并以非root用户运行
# 设置最终镜像中的工作目录
WORKDIR /app
# 从构建阶段 (builder) 拷贝编译好的二进制文件到当前阶段的/app目录下
COPY --from=builder /app/shortlink-server /app/shortlink-server
# (可选) 如果你的应用依赖配置文件,并且你希望将它们打包到镜像中
# (虽然更推荐的做法是通过ConfigMap或Secret在运行时挂载配置)
# COPY --from=builder /build/configs/config.production.yaml /app/configs/config.yaml
# (可选) 如果你在builder阶段创建了非root用户,并希望用它运行
# 例如,在builder阶段: RUN addgroup -S appgroup && adduser -S appuser -G appgroup
# 然后在这里:
# COPY --from=builder /etc/passwd /etc/passwd
# COPY --from=builder /etc/group /etc/group
# USER appuser:appgroup
# 声明应用在容器内监听的端口 (与应用配置中的端口一致)
# 这只是一个元数据声明,实际端口映射在docker run或Kubernetes Service中定义
EXPOSE 8080
# (假设我们的shortlink-service默认或通过配置监听8080端口)
# 定义容器启动时执行的命令
# ENTRYPOINT使得容器像一个可执行文件一样运行。
# CMD可以为ENTRYPOINT提供默认参数,或在ENTRYPOINT未定义时作为主命令。
# 对于Go应用,通常直接将编译好的二进制文件作为ENTRYPOINT。
ENTRYPOINT ["/app/shortlink-server"]
# (可选) 如果你的应用需要启动参数,可以在这里提供默认值
# CMD ["-config", "/app/configs/config.yaml"]
# 或者,这些参数通常在运行时(docker run 或 K8s manifest)中提供。
Dockerfile说明:
-
多阶段构建:清晰地分为了
builder阶段和最终的runtime阶段。 -
构建缓存优化:先
COPY go.mod go.sum并执行go mod download,利用Docker的层缓存机制,只有在依赖变化时才会重新下载。 -
静态链接与裁剪:
CGO_ENABLED=0确保静态链接(如果无CGO依赖),-ldflags="-w -s"去除调试信息和符号表,减小二进制体积。 -
最小基础镜像:运行阶段推荐使用
scratch(如果二进制完全静态且无文件依赖)、alpine(如果需要CA证书或时区数据等少量系统文件)或distroless/static(兼顾小体积和安全性)。 -
USER指令(可选):如果基础镜像支持且应用不需要root权限,切换到非root用户运行是安全最佳实践。 -
EXPOSE:声明应用监听的端口。 -
ENTRYPOINT/CMD:定义容器启动命令。
构建Docker镜像并本地运行验证
编写好 Dockerfile 后,我们就可以构建镜像并在本地运行它来验证了。
1. 构建Docker镜像。 在项目根目录(包含 Dockerfile 的目录)下运行:
$docker build -t shortlink-service:v0.1.0 .
# -t shortlink-service:v0.1.0 : 为镜像打上标签,名称为shortlink-service,版本为v0.1.0
# . : 表示Dockerfile在当前目录
你也可以使用你的Docker Hub用户名作为前缀,如 yourusername/shortlink-service:v0.1.0,方便后续推送到仓库。
2. 本地运行容器验证:
# 假设我们的应用(在Dockerfile的ENTRYPOINT中启动)会读取位于容器内
# /app/configs/config.yaml 的配置文件,并且监听8081端口。
# 我们需要将本地的配置文件挂载到容器中,并将容器的8081端口映射到主机的某个端口(例如8080)。
# 首先,确保你本地有一个 `configs/config.yaml` 文件供容器使用。
# (如果Dockerfile中已经COPY了配置文件,则此处的卷挂载会覆盖它,这在开发时常用)
docker run \
-p 8080:8081 \
--name shortlink-dev \
-v $(pwd)/configs:/app/configs \
shortlink-service:v0.1.0 \
-config /app/configs/config.yaml # 通过命令行参数告诉应用配置文件的路径
# 参数说明:
# -p 8080:8080 : 将主机的8080端口映射到容器的8081端口。
# --name shortlink-dev : 给容器取一个名字,方便管理。
# -v $(pwd)/configs:/app/configs : (可选) 将主机当前目录下的configs子目录挂载到容器的/app/configs目录。
# 这样,容器内的应用可以读取到主机上的配置文件。
# 注意:$(pwd) 在Linux/macOS下表示当前路径,Windows下可能需要用 %cd%。
# 如果Dockerfile中已COPY配置文件,且运行时不需要覆盖,则此卷挂载可以省略。
# shortlink-service:v0.1.0 : 要运行的镜像名称和标签。
# -config /app/configs/config.yaml : 这是传递给容器内ENTRYPOINT(即我们的Go应用)的命令行参数。
# 假设我们的Go应用支持通过-config标志指定配置文件路径。
# 如果应用设计为从固定路径(如/app/config.yaml)或环境变量读取,
# 则此参数可能不同或不需要。
3. 验证应用:容器启动后,尝试从浏览器或使用 curl 访问应用暴露的API端点(例如, http://localhost:8080/api/links),并检查 /metrics 和 /debug/pprof/ 端点是否按预期工作。查看 docker logs shortlink-dev 的输出来确认应用日志。
这个经过优化的 Dockerfile 为我们的“短链接服务”提供了一个标准化的、轻量级的、可移植的交付物。它已经为后续在更复杂的环境(如使用Docker Compose进行本地多服务开发,或部署到Kubernetes生产集群)中运行做好了充分的准备。
小结
在这一节课中,我们为“短链接服务”的工程化实践画上了圆满的句号。我们一起:
-
构建了测试体系:通过单元测试(使用
testify/mock)隔离验证了核心业务逻辑,通过集成测试(使用httptest和内存存储)确保了API端点与服务层、存储层的协同工作。我们还学习了如何生成和解读测试覆盖率报告,并强调了其作为辅助工具的意义。 -
开启了诊断之门:我们在HTTP服务中集成了Go语言强大的
pprof工具,为其开启了运行时性能剖析和故障排查的“后门”,为未来的性能分析和问题诊断(如goroutine泄漏、内存问题)提供了必要的运行时工具。 -
加固了代码质量:我们引入并配置了
golangci-lint这一主流的Linter聚合器,通过静态代码分析,能够在编码阶段就发现潜在的Bug、不规范的写法和风格问题,从而保障代码的整体质量和一致性。 -
准备了交付载体:我们为“短链接服务”编写了一个生产级的、采用多阶段构建的
Dockerfile,将其打包成了一个轻量、可移植、安全性较高的容器镜像,为后续的部署铺平了道路。
回顾整个工程实践篇的实战串讲,我们从一个设计蓝图出发,一步步地为“短链接服务”搭建了坚实的应用骨架(初始化、手动DI、优雅退出),集成了灵活的配置管理(Viper)、强大的结构化日志系统(slog),引入了基础的可观测性能力(Prometheus Metrics 和 OpenTelemetry Tracing),构建了必要的测试(单元、集成),开启了运行时诊断(pprof),实施了静态代码分析(golangci-lint),并最终将其容器化,准备好进行交付。
这个过程完整地演示了如何将一个Go项目从简单的业务逻辑实现,提升为一个具备基本工程素养、更接近生产标准的应用程序。我们不仅应用了模块三中学习到的各项工程化理论知识,也体会了这些技术实践是如何相互配合、共同服务于构建高质量软件这一最终目标的。
当然,一个真正的、复杂的生产级应用,其工程化的深度和广度远不止于此。例如,我们可能还需要更完善的CI/CD自动化流水线、更精细的权限控制与安全加固、更复杂的数据库选型与高可用方案、更全面的告警与应急响应机制,甚至引入服务网格进行流量管理等。
但通过这几节课的实战演练,我们已经为你打通了从代码设计到工程化落地的大部分关键环节,为你将来构建自己的高质量Go应用,或者参与到更大型的Go项目中,提供了一个坚实的起点和可供参考的实践蓝本。
希望这个完整的实战串讲能让你对Go语言在工程实践中的应用有更清晰的认识和更强的信心!
思考题
现在,是时候将我们学到的工程实践成果完整地运行起来,并进行一次全面的“出厂检验”了。
请你动手完成以下操作,并思考相关问题:
-
本地完整运行与验证:
a. 启动服务:在你的本地环境中,不使用Docker,直接通过
go run ./cmd/server/main.go命令启动我们的“短链接服务”。b. 功能测试:使用
curl或其他HTTP客户端工具,调用POST /api/links接口创建一个短链接,然后用返回的短码访问GET /{shortCode}接口,验证是否能成功重定向到原始的长链接。c. 诊断端点检查:
i. 在浏览器中打开
http://localhost:<port>/metrics,确认你能看到Prometheus格式的指标输出,并且在执行API调用后,shortlink_http_requests_total等指标的计数是否增加了。ii. 在浏览器中打开
http://localhost:<port>/debug/pprof/,确认pprof的首页能够正常显示。 -
静态代码分析:
a. 在项目根目录下运行
golangci-lint run ./...命令。b. 思考:如果命令报告了任何问题,尝试根据提示去理解和修复它们。如果没有报告问题,思考一下我们启用的这套linter规则主要帮助我们避免了哪些类型的潜在问题?
-
容器化运行:
a. 使用项目根目录下的
Dockerfile构建一个Docker镜像:docker build -t shortlink-service:final .。b. 使用
docker run命令启动这个镜像的容器,确保通过-p参数映射端口,并通过环境变量(-e)或挂载配置文件(-v)的方式为容器内的应用提供配置。c. 再次使用
curl等工具,测试运行在容器中的服务是否功能正常。
综合思考:
在完成以上所有操作后,请回顾整个过程。从一个纯粹的Go源代码项目,到最终拥有一个可以运行在任何Docker环境中的、标准化的容器镜像,我们主要为这个“短链接服务”添加了哪些关键的“工程化属性”?这些属性分别解决了软件开发和运维生命周期中的哪些具体问题?
我是Tony Bai,感谢你的一路陪伴,我们的 Go 语言进阶课主体内容就到此结束了!在后续特别放送的加餐中或许我们还会再见!期待在结束语中与你再次交流总结!
结束语|技术之路无止境,持续学习与实践
你好,我是Tony Bai。
时光荏苒,我们的“Go语言进阶课”也即将画上一个圆满的句号。
在过去的几十节课中,我们一同启程,从Go语言的核心语法机制出发,逐步深入到优雅的软件设计,最终将这些理论付诸构建生产级服务的工程实践之中。此刻,当你站在这段学习旅程的终点回望,我希望你看到的不仅仅是Go语言的特性和技巧的简单集合,更是一幅关于如何思考、设计、构建并维护高质量、高可用Go应用的、逐渐清晰且日趋完整的系统性蓝图。这不仅仅是知识的传递,更是工程思维的锤炼。
那么,在这次携手共进的探索之后,我们究竟一同走过了哪些关键的里程碑,收获了哪些宝贵的“装备”呢?下面我们一起先来对Go进阶之旅做个回顾和总结。
回顾与总结:我们的Go进阶之旅
我们的Go进阶之旅如同一幅精心绘制的地图,指引我们从语言的细微之处逐步走向构建复杂系统的宏伟蓝图。下面,让我们一同回顾这幅地图的核心脉络。
专栏核心知识地图再现
我们的旅程可以大致分为三个紧密相连的核心模块,每个模块都为我们解锁了Go语言不同层面的认知与能力。
首先,旅程的起点是 模块一“语法强化,突破语法认知瓶颈”。在这里,我们不仅仅是复习了Go的基础语法,更是深入到了这些语法特性背后所蕴含的Go语言设计的“为什么”和“怎么样”。
我们一同探讨了Go独特的类型系统,理解了它在简洁性与表达力之间的精妙平衡。
我们剖析了Go的兼容性承诺,学会了如何利用 GODEBUG 与 GOEXPERIMENT 拥抱未来特性。
我们辨析了值传递与指针传递在内存和性能层面的细微差别,掌握了数组与切片、字符串与rune(以及UTF-8编码)、map这些核心数据结构的高效用法与常见陷阱。
我们还重新审视了函数与方法的角色区分,深刻领会了Go语言通过结构体与接口所倡导的“组合优于继承”这一核心设计哲学。
不仅如此,我们还跟上了语言的最新进展,一起学习了for循环的进化(特别是Go 1.22+的循环变量新语义)和Go 1.18引入的泛型,理解了它们如何为Go的表达力和代码复用性注入新的活力。
更重要的是,我们深入了Go并发编程的“灵魂”——goroutine、channel与Context的最佳实践,探讨了垃圾回收(GC)的机制、对程序性能的影响以及如何编写GC友好的代码。
最后,我们还勇敢地揭开了反射(Reflection)与unsafe这两把强大但需要审慎使用的“双刃剑”的神秘面纱,学习了它们的应用场景与潜在风险。可以说,模块一为我们后续的所有进阶学习打下了最坚实的语言层面基础。
之后,我们昂首进入了模块二“设计先行,奠定高质量代码基础”。 在这一模块,我们的视角从语言特性转向了更高层次的软件设计原则与工程组织。
我们从宏观的项目布局规范和模块化的包设计理念入手,学习了如何构建一个清晰、可维护、易于团队协作的Go应用基石,并将SOLID等设计原则融入其中。我们开始用并发思维去重新审视应用的整体结构骨架,而不仅仅是局部的并发任务,并探讨了goroutine的生命周期管理和优雅退出策略。
我们再次深入了Go语言的精髓——接口设计,学习了如何从需求中“发现”而非凭空“发明”接口,以及如何运用小接口、正交组合的原则来定义出真正优雅、灵活的组件契约。我们还系统性地掌握了Go的错误处理设计,从简单的错误返回到构建和解构包含丰富上下文的错误链,再到对panic与error的正确区分和使用。
最后,我们还专注于如何设计出用户喜爱、健壮可靠的Go包API,并强调了API设计中的易用性、安全性、兼容性、高效性和Go语言惯例性这五大核心要素。
通过贯穿整个模块的“短链接服务”设计篇实战,我们将这些抽象的设计理念和原则具象化,完整体验了从解读需求、设计架构草图到细化核心模块、发现接口、设计API,以及初步构思并发模型和错误处理策略的全过程。模块二让我们真正开始像一位软件架构师一样思考。
理论与设计最终要服务于实践,将蓝图变为现实。在 模块三“工程实践,锻造生产级Go服务” 中,我们将模块一和模块二的所学融会贯通,聚焦于将Go代码转化为能够在生产环境中稳定运行、高效运维的真实服务。
我们从零开始为“短链接服务”搭建了健壮的应用骨架,集成了灵活的配置管理(使用Viper)、强大的结构化日志系统(使用 log/slog)。我们为应用装上了“眼睛”和“耳朵”——构建了包含Metrics(使用Prometheus客户端库)、Logging(为对接Loki/VictoriaLogs做准备)和Tracing(使用OpenTelemetry SDK)在内的可观测性体系。
我们学习了如何为代码编写高质量的单元测试和集成测试,如何利用静态分析工具(如 golangci-lint)在编码阶段就保障代码质量。
我们还深入掌握了如何通过Go的性能剖析利器 pprof 和运行时追踪工具 trace 来进行线上应用的故障诊断和性能调优,并系统梳理了Go中常见的性能瓶颈及其优化技巧。
我们探讨了Go应用在云原生时代的容器化部署(使用Docker和优化的Dockerfile),学习了如何使用Docker Compose简化本地多服务开发环境的搭建,以及如何在Kubernetes这个“标准舞台”上部署和管理我们的Go服务,并掌握了滚动更新、蓝绿部署、金丝雀发布等平滑升级策略。
最后,我们还初步展望了Go在AI集成方面的应用潜力,为未来的技术拓展埋下了伏笔。通过“短链接服务”的工程实践篇实战,我们将这些关键的工程化组件和最佳实践一一落地,完整体验了将一个Go应用从开发到准生产的过程。
可以说,本专栏不仅仅是Go语言特性和库函数的简单罗列,我们更努力地试图为你呈现一套 从深入理解Go语言语法的独特设计,到掌握编写高质量代码的设计原则,再到实施构建生产级服务的全套工程实践的系统性方法论。这是一个从“术”到“道”,再从“道”回归到“术”的完整学习闭环。
那么,经过这段旅程,你具体收获了哪些关键的成长呢?
你在本专栏中收获了什么?
我衷心希望,通过这段时间的系统学习和实践,你能够:
-
从仅仅“能写出可以运行的Go代码”,显著提升到“能写出符合Go语言设计哲学、遵循工程标准、易于长期维护、易于团队协作、并且具备良好扩展性的高质量Go代码”。
-
技术视角从关注孤立的语言特性或库函数用法,扩展到了更宏观的软件设计原则(如SOLID、接口隔离、依赖倒置)、架构思维(如分层、模块化、面向接口),以及覆盖从开发到运维全生命周期的工程化实践。
-
系统性掌握了构建和运维一个生产级Go服务所必需的一系列关键技能、核心工具和行业最佳实践。
-
Go语言的整体能力(从其独特的底层机制如GC、调度器,到其强大的标准库,再到其在上层应用构建中的优势)和其在软件工程中的应用边界,以及其在当前最热门的技术浪潮——云原生和人工智能(特别是AI工程化)中所扮演的重要角色和发展潜力,都有了更清晰、更深入的认识。
这些收获不仅仅是知识的填充,更是思维方式的转变和工程能力的跃迁。
作为一名Gopher,尤其是掌握了本专栏进阶知识的Gopher,你应该对自己的技术前景充满信心。我们正处在一个技术大变革的时代,而Go语言,正是我们手中一把能够乘风破浪、开创未来的利器。
技术之路无止境:持续学习与实践的蓝图
当然,技术的道路永无止境。本专栏为你打开了Go语言进阶的大门,但门后的世界更为广阔,等待你去持续探索。那么,在本专栏之后,你还可以向哪些方向继续深耕,构建更全面的技术能力呢?
本专栏之后,你的进阶学习方向建议
首先,向深处探索,夯实底层,追求极致。
- 如果你想真正成为Go语言专家,那么深入理解Go运行时(Runtime)的内部机制是必经之路。这包括:
-
Goroutine调度器(Scheduler):理解GMP模型的运作原理、goroutine的抢占式调度、work-stealing算法等。
-
垃圾回收(GC):深入三色标记清除法、并发GC的实现细节、写屏障(Write Barrier)、Pacer调速机制,以及如何进一步编写GC高度友好的代码。
-
内存模型(Memory Model):理解Go的内存模型如何保证并发操作的可见性和顺序性,以及
sync/atomic包的底层实现。 -
编译器(Compiler)与链接器(Linker):了解Go代码是如何被编译成机器码,以及链接过程是如何工作的,这有助于理解编译优化和最终二进制文件的构成。推荐阅读Go官方的源码(特别是
runtime包)、官方博客上的相关文章,以及社区中一些经典的深度分析,如William Kennedy(Ardan Labs)的一些分享,或一些剖析Go运行时的书籍。
-
- 根据你的兴趣和工作方向,可以在某些与Go密切相关的技术领域进行更深入的钻研。例如:
-
网络编程:深入学习TCP/IP协议栈的细节、理解HTTP/2和HTTP/3的核心机制、探索新兴的QUIC协议、研究和使用高性能网络库(如
cloudwego/netpoll、gnet等)的设计与实现。 -
分布式系统:系统性学习分布式系统的核心理论(如CAP、FLP不可能原理、一致性模型),掌握共识算法(如Raft、Paxos)、分布式事务的解决方案(如Saga、TCC、两阶段提交/三阶段提交的优缺点)、分布式锁的实现、消息队列的原理与应用等。
-
数据库技术:不仅仅是会用ORM或写SQL,更要深入理解关系型数据库(如MySQL、PostgreSQL)和NoSQL数据库(如Redis、MongoDB、Elasticsearch、TiDB)的内部原理、存储引擎、索引优化、SQL调优、事务隔离级别,以及高可用和分布式架构等。
-
操作系统与Linux内核:对于追求极致性能和底层系统理解的Gopher来说,操作系统原理和Linux内核知识是宝贵的财富。理解进程/线程调度、内存管理、文件系统、网络栈等,能让你在性能调优和故障诊断时有更深的洞察力。
-
- 持续学习和实践更高级的软件架构模式,提升架构设计能力。例如:
-
微服务架构:服务拆分原则、服务治理、API网关、容错与弹性设计、分布式配置管理、服务发现等。
-
领域驱动设计(DDD):如何通过限界上下文、聚合、实体、值对象等概念来指导复杂业务系统的建模和设计。
-
事件驱动架构(EDA):理解其核心模式(如发布/订阅、事件溯源、CQRS),以及它在构建高可扩展、松耦合系统中的应用。
-
Serverless架构:探索FaaS(Function-as-a-Service)和BaaS(Backend-as-a-Service)的理念与实践。
-
其次,向广度拓展,拥抱变化,融汇贯通。
-
云原生生态持续追踪:云原生技术仍在飞速发展,新的项目和标准层出不穷。你需要持续关注Kubernetes及其庞大的生态系统(如Service Mesh - Istio、Linkerd;Serverless框架—— Knative、OpenFaaS;CI/CD与GitOps工具链—— GitLab CI、ArgoCD、Tekton、FluxCD;以及可观测性领域的新进展——特别是eBPF技术的应用,如Cilium、Pixie、Grafana Beyla等)的最新动态、版本迭代和最佳实践。
-
AI与机器学习工程化:如果你对人工智能领域充满热情,本专栏的AI集成部分仅仅是一个引子。你可以进一步深入学习:
-
大型语言模型(LLM)的应用开发:包括更高级的Prompt工程、Fine-tuning(微调)技术、LLM评估方法等。
-
RAG(检索增强生成)的深入实践:包括文档处理与分块策略、向量数据库(如Pinecone、Weaviate、Milvus)的选择与优化、检索算法、以及生成环节的控制与优化。
-
AI Agent的构建:学习Agent的常见架构模式(如ReAct、Plan-and-Execute)、工具使用与函数调用(Function Calling)、多Agent协作等。
-
LLM应用框架:深入研究LangChain、LlamaIndex等主流框架(及其Go版本的移植如LangChainGo、Ollama),理解它们如何加速LLM应用的开发。
-
最后,软技能的提升同样重要,甚至更为关键。 随着你技术生涯的发展,软技能的重要性会日益凸显:
-
技术领导力与影响力:如何有效地带领技术团队、做出明智的技术选型和架构决策、在组织内部推动技术愿景和变革。
-
项目管理与高效协作:如何规划项目、管理风险、保证交付质量,以及如何与产品经理、设计师、测试工程师、运维工程师等不同角色的同事进行高效顺畅的沟通与协作。
-
技术写作与公开分享:将自己的学习心得、实践经验以及对技术的深度思考,通过撰写技术博客、在团队内或公开场合进行技术分享、参与技术图书或课程的创作等方式输出出来。这不仅能帮助他人成长,更是对自己知识体系进行梳理、检验和升华的最佳方式。
-
问题解决与批判性思维:培养独立分析和解决复杂技术问题的能力,以及对新技术和方案进行批判性思考和评估的能力。
技术之路,既要仰望星空,也要脚踏实地。
如何保持学习的动力与有效性?
在漫长而充满挑战的技术学习道路上,如何才能持续保持学习的热情,并确保学习的有效性呢?以下是一些或许能对你有所启发的建议:
-
动手实践是王道:理论学习固然重要,但只有将学到的知识真正应用到实际的项目(无论是你的工作项目,还是个人的Side Project,甚至是为开源项目贡献代码)中,去解决真实的问题,你才能真正理解和掌握它。在实践中遇到的每一个Bug、每一次重构、每一次性能优化,都是最宝贵的学习机会。所以,多写代码,多动手,不要怕犯错。
-
阅读优秀源码:Go语言本身就是开源的,其标准库是学习Go语言特性、设计哲学和编码风格的绝佳范本。此外,花时间去阅读社区中那些广受好评的、被大规模应用的开源项目(例如,Docker、Kubernetes、etcd、Prometheus、Gin、Cobra,甚至是一些小而美的库)的源码,能让你学到许多优秀的设计思想、精妙的工程实践和解决特定问题的具体方案。尝试理解它们为何这样设计,而不是那样设计。AI时代像deepwiki.com这样的AI助手可以让你的阅读和学习事半功倍。
-
积极参与社区,与人交流,技术的发展离不开社区的滋养。
-
关注官方动态:定期阅读Go官方博客( https://go.dev/blog/)、Go官方邮件列表(如golang-nuts),以及Go在GitHub上的官方仓库( https://github.com/golang/go)的Issues和Proposals,能让你第一时间了解Go语言的最新进展、版本特性和未来发展方向。当然,你也可以订阅我的《 Gopher Daily》,第一时间了解Go生态的新鲜事儿。
-
参与线上线下交流:积极参与本地或线上的Go Meetup、技术沙龙、开发者大会等活动,与其他Gopher面对面或在线交流学习心得、实践经验和遇到的问题。在交流中碰撞思想,往往能获得新的启发。
-
利用好问答平台和论坛:Stack Overflow、Reddit的r/golang子版块等都是非常好的提问、解答和学习平台。
-
-
持续输出倒逼输入:
-
写技术博客或笔记:将自己学到的新知识、解决问题的过程或者对某个技术点的深度思考,通过撰写技术博客、学习笔记、或者在团队内部知识库中分享的方式记录下来。这个“输出”的过程,会迫使你对知识进行更系统、更深入的思考、梳理和总结,从而达到更好的学习和记忆效果。
-
进行技术分享:尝试在团队内部、Meetup或小型技术沙龙上,就你感兴趣或擅长的Go技术点进行分享。准备分享的过程,本身就是一次绝佳的知识复习和深化机会。
-
参与开源项目贡献:哪怕只是从提交一个小的文档修正、修复一个简单的Bug或者参与issue的讨论开始,参与到你喜欢的Go开源项目中,都能让你在实践中学习,并为社区做出贡献获得成就感。
-
-
保持好奇心与开放心态:技术的世界日新月异,新的编程语言、新的框架、新的工具、新的设计理念层出不穷。永远保持对新技术的好奇心,对不同的观点和方法持开放和学习的心态,不固步自封,才能在这个快速变化的技术浪潮中持续保持竞争力,并享受技术探索带来的乐趣。
感谢与展望
此刻,当我们的“Go语言进阶课”即将落下帷幕之际,我的心中充满了感激。我要衷心感谢购买并坚持学完(或者正在努力学完)本专栏的你,感谢你在过去的这段时间里,投入了宝贵的时间和精力,与我一同在Go语言的进阶之路上探索和前行。你在学习过程中的积极思考,在留言区提出的深刻问题,以及与其他同学分享的精彩讨论,不仅极大地丰富了专栏的内容和价值,也给了我很多意想不到的启发和持续创作、打磨课程的强大动力。
作为一名Gopher,我们是幸运的,因为我们选择了一门既能优雅地应对当前互联网时代复杂工程挑战,又充满未来发展潜力、能够让我们在新的技术浪潮中乘风破浪的语言。我希望本专栏能够为你在这条充满机遇与挑战的Go语言进阶之路上,提供一些有益的指引、坚实的技能和持续的助力。
再次感谢你的信任与一路相伴!期待在未来的某个技术分享的场合,或者在开源社区的某个角落,我们能再次相遇,交流新的学习心得与技术感悟。
祝你,在Go语言的世界里,编程愉快,探索无限,前程似锦!

结课测试|来赴一场满分之约!
你好!我是Tony Bai。
《Go语言进阶课》正式结课了,为认真学习的你点赞!为了帮你检验自己的学习成果,我特意准备了一套结课测试题。题目共有 25 道多选题,满分 100 分,快来挑战一下吧!
